yelp数据集上试验SVD,SVDPP,PMF,NMF 推荐算法
SVD、SVD++、PMF 和 NMF 是几种常见的推荐算法,它们主要用于协同过滤和矩阵分解方法来生成个性化推荐。下面是对每种算法的简要介绍:
1. SVD(Singular Value Decomposition)
- 用途:SVD 是一种矩阵分解技术,通常用于降维和数据压缩。在推荐系统中,SVD 用于分解用户-物品评分矩阵,从而识别潜在的特征。
- 原理:SVD 将评分矩阵分解为三个矩阵的乘积:用户矩阵、奇异值矩阵和物品矩阵。通过保留前几个最大的奇异值,可以捕捉到用户和物品之间的隐含关系。
- 优势:能够处理稀疏数据,提取潜在特征,生成个性化推荐。
- 缺点:对缺失值敏感,且需要较大的计算量。
2. SVD++(SVD Plus Plus)
- 用途:SVD++ 是对 SVD 的扩展,考虑了用户对未评分物品的潜在偏好。
- 原理:除了使用传统的 SVD 方法外,SVD++ 还引入了隐式反馈(如用户浏览、点击等行为),将这些信息融入模型中,增强了对用户偏好的捕捉能力。
- 优势:比传统 SVD 更加准确,能够更好地利用隐式反馈信息,适应性更强。
- 缺点:模型复杂度增加,训练时间较长。
3. PMF(Probabilistic Matrix Factorization)
- 用途:PMF 是一种基于概率的矩阵分解方法,用于推荐系统。
- 原理:PMF 假设用户和物品的特征遵循正态分布,通过最大化似然函数来学习这些特征。与 SVD 不同,PMF 通过引入概率模型来捕捉用户和物品之间的关系。
- 优势:能够处理缺失值,适应性强,适用于稀疏数据。
- 缺点:计算复杂度较高,可能需要较长的训练时间。
4. NMF(Non-negative Matrix Factorization)
- 用途:NMF 是一种非负矩阵分解方法,常用于推荐系统和特征学习。
- 原理:NMF 将原始评分矩阵分解为两个非负矩阵的乘积,这些非负特征使得模型在解释上更具可解释性。
- 优势:生成的特征可以更直观地理解,适合处理非负数据(如评分、计数等)。
- 缺点:可能会收敛到局部最优解,且在稀疏数据上表现不如 SVD 和 PMF。
各个推荐算法具有的特点是
- SVD:利用矩阵分解捕捉用户和物品的隐含特征。
- SVD++:在 SVD 的基础上引入隐式反馈,增强推荐精度。
- PMF:基于概率模型的矩阵分解,适应性强。
- NMF:非负矩阵分解,生成可解释的特征表示。
安装scikit-surprise
pip install pandas scikit-surprise使用SVD
import pandas as pd
from surprise import Reader, Dataset, SVD
from surprise.model_selection import train_test_split
from surprise import accuracy
import json# 1. 加载Yelp数据集
# 假设数据文件名为 'yelp_academic_dataset_review.json'
file_path = 'yelp_academic_dataset_review.json'# 加载JSON文件到DataFrame
with open(file_path, 'r') as f:data = [json.loads(line) for line in f]# 将数据转换为pandas DataFrame
df = pd.DataFrame(data)# 2. 选择必要的字段:user_id, business_id, rating
df = df[['user_id', 'business_id', 'stars']] # 假设评分字段是 'stars'# 3. 数据预处理:将DataFrame转换为适合Surprise库的格式
reader = Reader(rating_scale=(1, 5)) # 假设评分是1到5
dataset = Dataset.load_from_df(df[['user_id', 'business_id', 'stars']], reader)# 4. 划分训练集和测试集
trainset, testset = train_test_split(dataset, test_size=0.2)# 5. 使用SVD训练模型
svd = SVD()
svd.fit(trainset)# 6. 在测试集上进行预测并评估
predictions = svd.test(testset)
print(f'RMSE: {accuracy.rmse(predictions)}')# 7. 获取每个用户的Top-N推荐商家
def get_top_n(predictions, n=10):top_n = {}for uid, iid, true_r, est, _ in predictions:if uid not in top_n:top_n[uid] = []top_n[uid].append((iid, est))# 对每个用户推荐列表按照评分进行排序for uid, user_ratings in top_n.items():user_ratings.sort(key=lambda x: x[1], reverse=True)top_n[uid] = user_ratings[:n]return top_n# 获取推荐结果
top_n = get_top_n(predictions, n=10)# 8. 为特定用户推荐商家
user_id = 'fB3jbHi3m0L2KgGOxBv6uw' # 替换为目标用户ID
recommended_businesses = top_n.get(user_id, [])
print(f"Top 10 recommended businesses for user {user_id}:")
for business_id, rating in recommended_businesses:print(f"Business ID: {business_id}, Predicted Rating: {rating}")这个示例假设评分值在1到5之间(即rating_scale=(1, 5)),如果评分范围不同,请修改为适合你的数据集的范围。
运行结果
RMSE: 1.2863
RMSE: 1.2862955370267326
Top 10 recommended businesses for user fB3jbHi3m0L2KgGOxBv6uw

使用 SVD++
import pandas as pd
from surprise import Reader, Dataset, SVDpp
from surprise.model_selection import train_test_split
from surprise import accuracy
import json# 1. 加载Yelp数据集
# 假设数据文件名为 'yelp_academic_dataset_review.json'
file_path = 'yelp_academic_dataset_review.json'# 加载JSON文件到DataFrame
with open(file_path, 'r') as f:data = [json.loads(line) for line in f]# 将数据转换为pandas DataFrame
df = pd.DataFrame(data)# 2. 选择必要的字段:user_id, business_id, rating
df = df[['user_id', 'business_id', 'stars']] # 假设评分字段是 'stars'# 3. 数据预处理:将DataFrame转换为适合Surprise库的格式
reader = Reader(rating_scale=(1, 5)) # 假设评分是1到5
dataset = Dataset.load_from_df(df[['user_id', 'business_id', 'stars']], reader)# 4. 划分训练集和测试集
trainset, testset = train_test_split(dataset, test_size=0.2)# 5. 使用SVD++训练模型
svdpp = SVDpp()
svdpp.fit(trainset)# 6. 在测试集上进行预测并评估
predictions = svdpp.test(testset)
print(f'RMSE: {accuracy.rmse(predictions)}')# 7. 获取每个用户的Top-N推荐商家
def get_top_n(predictions, n=10):top_n = {}for uid, iid, true_r, est, _ in predictions:if uid not in top_n:top_n[uid] = []top_n[uid].append((iid, est))# 对每个用户推荐列表按照评分进行排序for uid, user_ratings in top_n.items():user_ratings.sort(key=lambda x: x[1], reverse=True)top_n[uid] = user_ratings[:n]return top_n# 获取推荐结果
top_n = get_top_n(predictions, n=10)# 8. 为特定用户推荐商家
user_id = 'fB3jbHi3m0L2KgGOxBv6uw' # 替换为目标用户ID
recommended_businesses = top_n.get(user_id, [])
print(f"Top 10 recommended businesses for user {user_id}:")
for business_id, rating in recommended_businesses:print(f"Business ID: {business_id}, Predicted Rating: {rating}")
数据集的规模: SVD++比SVD复杂,所以如果数据集非常大,可能会需要更长时间进行训练,尤其是在计算资源有限的情况下。
运行结果

RMSE: 1.2947
RMSE: 1.2947410246403837
Top 10 recommended businesses for user fB3jbHi3m0L2KgGOxBv6uw:
使用PMF
PMF 在 Surprise 中实现为 SVD,因此我们可以直接使用 SVD 作为 PMF, 代码参见SVD
使用NMF
import pandas as pd
from surprise import Reader, Dataset, NMF
from surprise.model_selection import train_test_split
from surprise import accuracy
import json# 1. 加载Yelp数据集
# 假设数据文件名为 'yelp_academic_dataset_review.json'
file_path = 'yelp_academic_dataset_review.json'# 加载JSON文件到DataFrame
with open(file_path, 'r') as f:data = [json.loads(line) for line in f]# 将数据转换为pandas DataFrame
df = pd.DataFrame(data)# 2. 选择必要的字段:user_id, business_id, rating
df = df[['user_id', 'business_id', 'stars']] # 假设评分字段是 'stars'# 3. 数据预处理:将DataFrame转换为适合Surprise库的格式
reader = Reader(rating_scale=(1, 5)) # 假设评分是1到5
dataset = Dataset.load_from_df(df[['user_id', 'business_id', 'stars']], reader)# 4. 划分训练集和测试集
trainset, testset = train_test_split(dataset, test_size=0.2)# 5. 使用NMF(Non-negative Matrix Factorization)进行矩阵分解
nmf = NMF()
nmf.fit(trainset)# 6. 在测试集上进行预测并评估
predictions = nmf.test(testset)
print(f'RMSE: {accuracy.rmse(predictions)}')# 7. 获取每个用户的Top-N推荐商家
def get_top_n(predictions, n=10):top_n = {}for uid, iid, true_r, est, _ in predictions:if uid not in top_n:top_n[uid] = []top_n[uid].append((iid, est))# 对每个用户推荐列表按照评分进行排序for uid, user_ratings in top_n.items():user_ratings.sort(key=lambda x: x[1], reverse=True)top_n[uid] = user_ratings[:n]return top_n# 获取推荐结果
top_n = get_top_n(predictions, n=10)# 8. 为特定用户推荐商家
user_id = 'fB3jbHi3m0L2KgGOxBv6uw' # 替换为目标用户ID
recommended_businesses = top_n.get(user_id, [])
print(f"Top 10 recommended businesses for user {user_id}:")
for business_id, rating in recommended_businesses:print(f"Business ID: {business_id}, Predicted Rating: {rating}")NMF与SVD的区别:
NMF(非负矩阵分解)不同于SVD(奇异值分解),它强制矩阵的分解结果为非负值。适用于当数据有明显非负约束(例如评分数据)的情况。- 如果数据中包含负值,
NMF可能无法正常工作,这时可以考虑使用SVD。 - 性能问题: 如果数据集非常大,矩阵分解模型可能需要较长时间训练。可以考虑在大规模数据集上进行性能优化(例如使用并行计算或使用分布式计算框架)。
运行结果
RMSE: 1.4577
RMSE: 1.4577314669222752
Top 10 recommended businesses for user fB3jbHi3m0L2KgGOxBv6uw
相关文章:
yelp数据集上试验SVD,SVDPP,PMF,NMF 推荐算法
SVD、SVD、PMF 和 NMF 是几种常见的推荐算法,它们主要用于协同过滤和矩阵分解方法来生成个性化推荐。下面是对每种算法的简要介绍: 1. SVD(Singular Value Decomposition) 用途:SVD 是一种矩阵分解技术,通…...

计算机视觉常用数据集Cityscapes的介绍、下载、转为YOLO格式进行训练
我在寻找Cityscapes数据集的时候花了一番功夫,因为官网下载需要用公司或学校邮箱邮箱注册账号,等待审核通过后才能进行下载数据集。并且一开始我也并不了解Cityscapes的格式和内容是什么样的,现在我弄明白后写下这篇文章,用于记录…...

Flink和Spark在实时计算方面有何异同
Flink和Spark在实时计算方面既有相似之处,也存在显著的差异。以下是对它们之间异同的详细分析: 一、设计理念与世界观 Flink: 专注于流处理,认为批是流的特例。数据流分为有限流(Bounded)和无限流…...

纵然千万数据流逝,唯独vector长存
公主请阅 1.vector的一些方法1vector和stringpush_back 插入以及三种遍历数组的方式一些方法vector中的一些常见的方法1. push_back()2. pop_back()3. size()4. clear()5. empty()6. resize()7. insert()8. erase()9. at()10. front和 back()11. data()12. capacity()13. shrin…...

【LeetCode】【算法】739. 每日温度
LeetCode 739. 每日温度 题目描述 给定一个整数数组 temperatures ,表示每天的温度,返回一个数组 answer ,其中 answer[i] 是指对于第 i 天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用 0…...
2025年知识管理新方案:十款前沿知识库搭建工具详解
随着企业信息化和智能化的发展,知识管理已成为提升企业竞争力的关键要素。一个高效的知识库不仅能促进内部沟通,还能展示企业的专业形象。以下是2025年十款前沿知识库搭建工具的详解。 1. HelpLook AI知识库 HelpLook AI知识库是一款专注于为企业提供高…...

WebSocket实现消息实时推送
文章目录 websocket介绍特点工作原理 用websocket实现实时推送引入依赖WebSocket 函数定义变量声明初始化 WebSocket 连接WebSocket 连接的初始化和事件处理连接打开事件接收消息处理连接关闭和重连机制心跳机制使用 WebSocket代码完整显示 websocket介绍 WebSocket 是一种网络…...

flink 内存配置(三):设置JobManager内存
flink 内存配置(一):设置Flink进程内存 flink 内存配置(二):设置TaskManager内存 flink 内存配置(三):设置JobManager内存 flink 内存配置(四)…...
)
蓝桥杯 Python组-神奇闹钟(datetime库)
神奇闹钟 传送门: 0神奇闹钟 - 蓝桥云课 问题描述 小蓝发现了一个神奇的闹钟,从纪元时间(1970 年 11 日 00:00:00)开始,每经过 x 分钟,这个闹钟便会触发一次闹铃 (…...
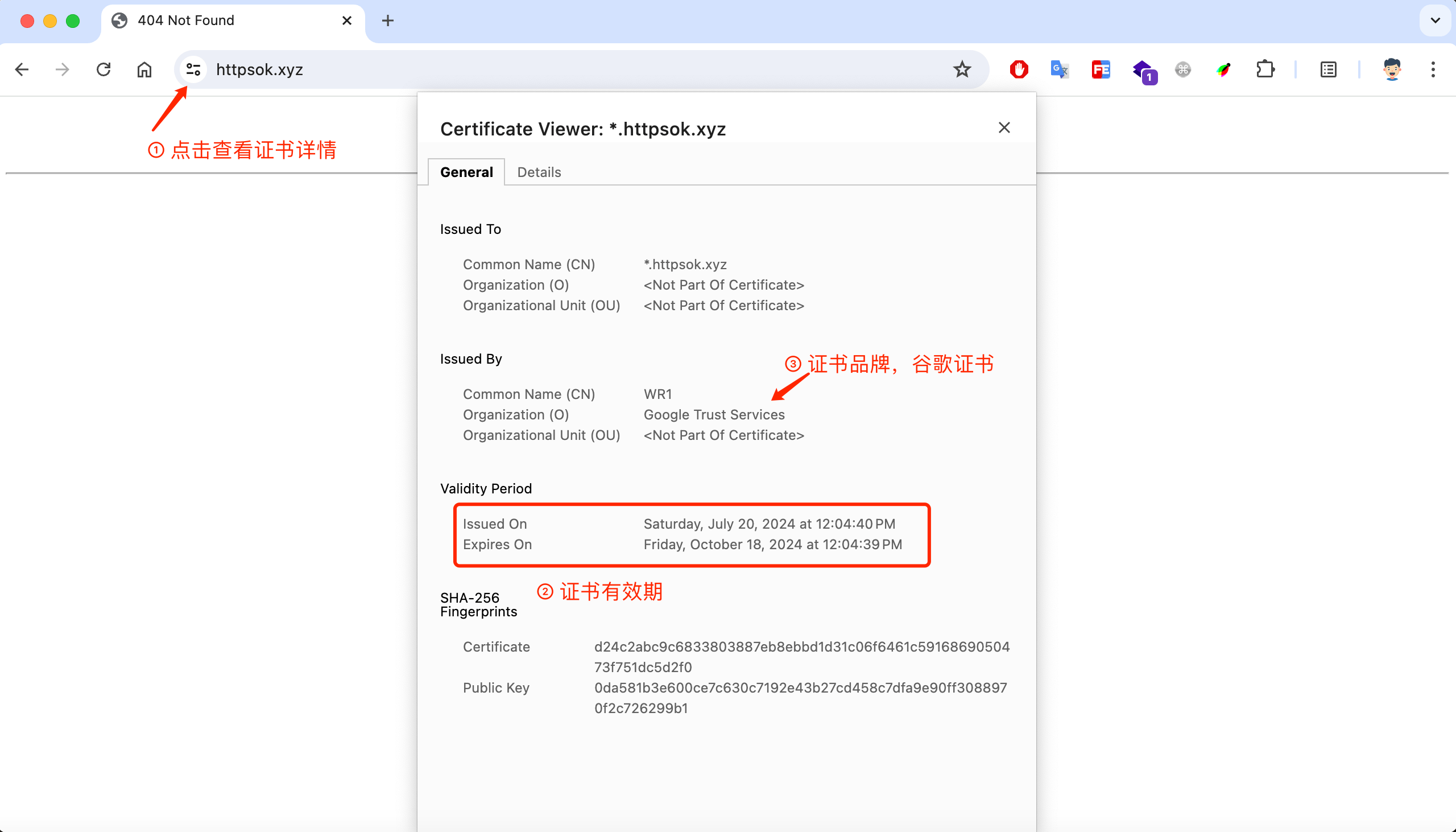
解决阿里云三个月证书过期 免费SSL证书部署教程
相信有上线过自己的网站、小程序经验的同学深有体会,给服务加上 SSL 证书还挺麻烦的,尤其是没有运维经验的同学。本来最省事的方法是买个证书,但是一看价格,还是算了吧,动辄就是几万块一年。作为个人来说,这…...

VBA03-变量
一、什么是变量 变量是一个自定义名称的储存单位,变量是一个载体。 二、代码调试 在代码逐句运行的过程中查看变量的存储内容。 2-1、示例1 2-2、示例 三、变量的数据类型 若是定义的数据类型的变量,存储了超出了她范围的数,则会报溢出。 注…...

docker-ce-stable‘ 下载元数据失败 : Cannot download repomd.xml: Cannot download
看起来你在尝试安装 containerd.io-1.6.32 时遇到了问题,因为 docker-ce-stable 仓库的元数据下载失败。以下是一些可能的解决方案: 1. 检查仓库配置 确保你的 /etc/yum.repos.d/ 目录下的 docker-ce.repo 文件配置正确。你可以尝试手动编辑该文件&…...

C中定义字符串有下列几种形式
字符串常量,char数组,char指针之间的差异 1、字符串常量: 位于一对双括号中的任何字符。双引号里的字符加上编译器自动提供的结束标志\0字符,作为一个字符串存储在内存中。 例如: printf("%s","hello"); /…...

写一个小日历
以下是一个示例,展示了如何创建一个基本的日历 日历 1. HTML 结构 首先,创建一个基本的 HTML 结构,用于展示日历。 <!DOCTYPE html> <html lang"zh"> <head><meta charset"UTF-8"><meta na…...

【数据库】elasticsearch
1、架构 es会为每个索引创建一定数量的主分片和副本分片。 分片(Shard): 将索引数据分割成多个部分,每个部分都是一个独立的索引。 主要目的是实现数据的分布式存储和并行处理,从而提高系统的扩展性和性能。 在创建索…...

Rust 构建 TCP/UDP 网络服务
第四章 异步编程与网络通信 第二节 构建 TCP/UDP 网络服务 在现代应用程序中,网络通信是核心功能之一。本节将重点介绍如何在 Rust 中构建基本的 TCP 和 UDP 网络服务,涵盖实际的代码示例、最佳实践以及最新的技术方案,以帮助开发者掌握网络…...

docker镜像文件导出导入
1. 导出容器(包含内部服务)为镜像文件(docker commit方法) 原理:docker commit命令允许你将一个容器的当前状态保存为一个新的镜像。这个新镜像将包含容器内所有的文件系统更改,包括安装的软件、配置文件等…...

ViT面试知识点
文章目录 VITCLIPBlipSAMLSegFast TransformerYOLO系列问题 BatchNorm是对一个batch-size样本内的每个特征做归一化,LayerNorm是对每个样本的所有特征做归一化。 Layer Normalization(层归一化,简称LayerNorm)是一种在深度学习中…...
的区别;ChatGPT 和 RAG 的联系)
ChatGPT 和 RAG(检索增强生成)的区别;ChatGPT 和 RAG 的联系
目录 ChatGPT 和 RAG(检索增强生成)的区别 知识来源与利用方式 回答准确性和可靠性 模型架构和复杂性 适用场景 ChatGPT 和 RAG 的联系 ChatGPT 和 RAG(检索增强生成)的区别 知识来源与利用方式 ChatGPT:是基于大规模预训练的语言模型,知识是在预训练过程中从大量的…...

qt获取本机IP和定位
前言: 在写一个天气预报模块时,需要一个定位功能,在网上翻来翻去才找着,放在这里留着回顾下,也帮下有需要的人 正文: 一开始我想着直接调用百度地图的API来定位, 然后我就想先获取本机IP的方…...

【NotebookLM视频转文字实战指南】:20年AI工程师亲测的5大避坑技巧与98.7%准确率实现路径
更多请点击: https://intelliparadigm.com 第一章:NotebookLM视频转文字的核心原理与能力边界 NotebookLM 的视频转文字功能并非直接处理原始视频流,而是依赖 Google Cloud Speech-to-Text API 的增强版语音识别管道,并结合 YouT…...

深度解析ZXing.Net:.NET生态中的企业级条码识别与生成解决方案
深度解析ZXing.Net:.NET生态中的企业级条码识别与生成解决方案 【免费下载链接】ZXing.Net .Net port of the original java-based barcode reader and generator library zxing 项目地址: https://gitcode.com/gh_mirrors/zx/ZXing.Net ZXing.Net作为Java版…...

Monocle性能监控与优化:确保高并发访问的稳定性
Monocle性能监控与优化:确保高并发访问的稳定性 【免费下载链接】monocle Link and news sharing 项目地址: https://gitcode.com/gh_mirrors/mon/monocle Monocle作为一个链接和新闻分享平台,在面对高并发访问时的稳定性至关重要。本文将分享一些…...

Jenga框架双引擎设计:视频生成效率优化解析
1. Jenga框架核心设计解析Jenga视频生成框架的核心创新在于其双引擎设计:渐进式分辨率(ProRes)和动态块稀疏注意力(AttenCarve)。这两种技术协同工作,解决了Transformer架构在视频生成中的计算效率瓶颈。1.1 渐进式分辨率技术(ProRes)ProRes采用分阶段生…...

3分钟免费解锁B站大会员4K视频:终极B站视频下载器完整指南
3分钟免费解锁B站大会员4K视频:终极B站视频下载器完整指南 【免费下载链接】bilibili-downloader B站视频下载,支持下载大会员清晰度4K,持续更新中 项目地址: https://gitcode.com/gh_mirrors/bil/bilibili-downloader 还在为无法下载…...

AssetStudio Unity资源提取终极指南:精准解析SerializedFile与AssetBundle
1. 为什么AssetStudio是Unity资源提取的“第一把刀”——不是因为它最强,而是因为它最准你有没有遇到过这样的场景:刚下载一个热门Unity手游的APK,兴致勃勃地解包,结果在assets/bin/Data/Managed/目录下看到一堆Assembly-CSharp.d…...

别再找组策略了!Windows 11家庭版/专业版通用,一条命令搞定密码永不过期
Windows 11密码永不过期终极指南:告别繁琐设置,一条命令解决所有版本难题 每次开机都被"密码即将过期"的提示烦扰?作为Windows 11用户,你可能已经尝试过各种图形界面设置却无功而返。特别是家庭版用户,面对缺…...

模块型OLT跟光模块有什么区别?
模块型OLT跟光模块有什么区别?明明是同一个 SFP 接口,插上去长得也差不多,为什么有的叫“光模块”,有的叫“模块型 OLT”? 它们到底有什么区别?能不能互换?选错了会怎样?同样是 SFP …...

Python 的 C 扩展,本质上就是“去中心化的 COM”
全球占比25%的第一编程语言:Python 的内存管理:用的是引用计数(Reference Counting)加垃圾回收。C 库(如 NumPy)在运行过程中,会直接去修改 Python 对象的引用计数.这套做法恰好是微软原来最好的…...

TSC打印机Java开发避坑指南:从DLL配置到中文乱码,一次讲清楚
TSC打印机Java开发避坑指南:从DLL配置到中文乱码,一次讲清楚 第一次用Java调用TSC打印机时,那种挫败感至今难忘。明明照着官方文档一步步操作,却总是卡在DLL加载失败、中文变成乱码这些看似简单的问题上。这篇文章就是把我踩过的坑…...