ViT面试知识点
文章目录
- VIT
- CLIP
- Blip
- SAM
- LSeg
- Fast Transformer
- YOLO系列问题
BatchNorm是对一个batch-size样本内的每个特征做归一化,LayerNorm是对每个样本的所有特征做归一化。

Layer Normalization(层归一化,简称LayerNorm)是一种在深度学习中常用的归一化技术,它与Batch Normalization(批归一化)不同,LayerNorm是在单个样本的特征上进行归一化,而不是在批次上。LayerNorm的目的是减少模型训练过程中的内部协变量偏移(Internal Covariate Shift),即减少模型参数更新时的规模和方向的变化,从而加速收敛并提高模型性能。
LayerNorm的计算步骤如下:


LayerNorm的优势在于它不依赖于批次的大小,因此可以很好地应用于RNNs和LSTMs等序列模型中,这些模型的批次大小可能会变化。此外,LayerNorm也有助于减少模型对初始化权重的敏感性,从而提高模型的稳定性和性能。
VIT
介绍一下Visual Transformer?
介绍一下自注意力机制?
介绍一下VIT的输出方式
介绍一下VIT做分割任务
VIT是将NLP的transformer迁移到cv领域,他的整个流程大概如下:将一张图片切成很多个patch,每个patch为16x16的大小,然后将这些patch拉直,并添加一个位置编码,然后将这个向量序列输入到标准的transformer encoder中,这里的transformer encoder由多个transformer 标准块构成,包括multi head attention 然后相加并进行层归一化,以及后面的FFN(前馈神经网络)
FFN层就是feed forward层。他本质上就是一个两层的MLP,第一层会将输入的向量升维,第二层将向量重新降维。这样子就可以学习到更加抽象的特征。
Transformer encoder 的输出和输入一样,有多个输出,我们应该拿哪个输出去做最后的分类呢?所以说再次借鉴BERT,用extra learnable embedding,也就是一个特殊字符叫cls,叫分类字符,它也有一个位置编码0,因为所有的token都在跟所有的token做交互信息,所以第一个class embedding 可以从别的embedding里面学到有用的信息,从而我们只需要根据它的输出做一个MLP Head,做最后的判断。





class Attention(nn.Module):def __init__(self,dim, # 输入token的dimnum_heads=8,qkv_bias=False,qk_scale=None,attn_drop_ratio=0.,proj_drop_ratio=0.):super(Attention, self).__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop_ratio)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop_ratio)def forward(self, x):# [batch_size, num_patches + 1, total_embed_dim]B, N, C = x.shape# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim]# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]# reshape: -> [batch_size, num_patches + 1, total_embed_dim]x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)return x
CLIP
介绍一下CLIP
CLIP的网络结构
CLIP的损失函数
CLIP的优势
CLIP为什么可以做零样本学习
CLIP的不足?
1、文本对过于简单,只能实现对图片的简单描述,当图片场景复杂时,CLIP的图文匹配效果不佳。
2、结构化表征能力弱,例如:黑色帽子白衬衫和白帽子黑衬衫,他们的在CLIP中得到的语义相似度都会很高。
3、CLIP的训练依赖大量的优质文本对。
CLIP(Contrastive Language-Image Pre-Training)模型是一种多模态预训练神经网络,该模型的核心思想是使用大量图像和文本的配对数据进行预训练,以学习图像和文本之间的对齐关系,CLIP模型有两个模态,一个是文本模态,一个是视觉模态:
- Text Encoder:用于将文本转换为低维向量表示Embeding。
- Image Encoder:用于将图像转换为类似的向量表示Embedding。
在预测阶段,CLIP模型通过计算文本和图像向量之间的余弦相似度来生成预测。这种模型特别适用于零样本学习任务,即模型不需要看到新的图像或文本的训练示例就能进行预测。CLIP模型在多个领域表现出色,如图像文本检索、图文生成等。

模型中使用visual_embedding 叉乘 text_embedding,得到一个[N, N]的矩阵,那么对角线上的值便是成对特征内积得到的,如果visual_embedding和对应的text_embedding越相似,那么它的值便越大。
选取[N, N]矩阵中的第一行,代表第1个图片与N个文本的相似程度,其中第1个文本是正样本,将这一行的标签设置为1,那么就可以使用交叉熵进行训练,尽量把第1个图片和第一个文本的内积变得更大,那么它们就越相似。
[交叉熵]:一种用于衡量两个概率分布之间差异的度量方式。其定义为

,其中P(x)为实际概率分布,Q(x)为预测概率分布。
交叉熵刻画的是两个概率分布的距离,也就是说交叉熵值越小(相对熵的值越小),两个概率分布越接近
Blip






SAM
在NLP的领域中,存在一些被称为基础模型的模型,他们通过预测句子中的下一个词进行训练,称为顺序预测。通过这些基础的模型可以轻松地适应到其他的NLP的任务上,比如翻译或者是文本摘要,这种实现方式也可以称为是零样本迁移学习。其中比较著名的方法就是prompting,通过聊天的形式来进行交互。NLP有效的前提是网络上存在大量的文本,而对于序列的预测,比如说知道一些词然后预测后面的词是什么,这种不需要人工标注的标签就能完成训练。但是问题转化到计算机视觉的任务上,尽管网络上存在数十亿的图像,但是由于缺乏有效标注的mask的信息,所以在计算机视觉的任务上建立这样模型成为了挑战。开门见山,作者首先提出了三个问题。

针对上面提出的3个问题,作者给出的解决方案。作者的目标是通过引入三个相互关联的组件来构建一个分割的基础模型:一个可提示的分割任务、一个通过数据标注提供动力并能够通过提示工程实现一系列任务零样本迁移的分割模型(SAM),以及一个用于收集我们的数据集SA-1B(包含超过10亿个掩码)的数据引擎。
可提示的分割任务和实际使用目标对模型架构施加了约束。具体而言,模型必须支持灵活的提示,需要以分摊的实时方式计算掩码以允许交互式使用,并且必须具备处理歧义的能力。令人惊讶的是,我们发现一个简单的设计就能满足所有这三个约束条件:一个强大的图像编码器计算图像嵌入,一个提示编码器嵌入提示,然后将这两个信息源在一个轻量级的掩码解码器中结合起来,预测分割掩码。
图像的编码器:
图像编码器。出于可扩展性和强大的预训练方法的考虑,我们使用了一个经过最小调整以适应高分辨率输入的MAE预训练视觉Transformer(ViT)[33][62]。图像编码器每张图像运行一次,并可在提示模型之前应用,这里使用的mae来进行预训练。
提示词的编码器:
提示编码器。我们考虑两组提示:稀疏提示(点、框、文本)和密集提示(掩码)。我们用位置编码[95]来表示点和框,并将其与每种提示类型的学习嵌入和来自CLIP的现成文本编码器中的自由格式文本相加。密集提示(即掩码)使用卷积进行嵌入,并与图像嵌入进行逐元素相加。
掩码的解码器:
掩码解码器能够高效地将图像嵌入、提示嵌入和输出标记映射到一个掩码。采用了一个经过修改的Transformer解码器块,后面跟着一个动态掩码预测头。我们修改后的解码器块在两个方向上(从提示到图像嵌入和从图像嵌入到提示)使用提示自注意力和交叉注意力来更新所有嵌入。运行两个块之后,我们对图像嵌入进行上采样,并且一个多层感知机(MLP)将输出标记映射到一个动态线性分类器,然后该分类器计算图像每个位置的前景掩码概率。
解决歧义的问题:
解决歧义问题。如果给定一个模糊的提示,模型将平均多个有效的掩码作为一个输出。为了解决这个问题,我们修改了模型,使其能够针对单个提示预测多个输出掩码(见图3)。我们发现,3个掩码输出足以处理大多数常见情况(嵌套掩码通常最多有三层:整体、部分和子部分)。比如上面的剪刀的图像,其实由三个有效的掩码。
我们的数据引擎有三个阶段:辅助手动、半自动和全自动。在第一阶段,SAM辅助标注者标注掩码,类似于经典的交互式分割设置。在第二阶段,SAM可以通过提示可能的对象位置自动为一部分对象生成掩码,而标注者则专注于标注剩余的对象,这有助于增加掩码的多样性。在最后阶段,我们使用前景点的常规网格提示SAM,平均每张图像生成约100个高质量掩码。
介绍一下SAM模型?
SAM的创新性在哪里?
详细介绍一下SAM的网络结构
SAM的加速和量化你有了解吗?
SAM的应用场景
LSeg

Image Encoder : dense prediction transformers (DPT)
Fast Transformer


分别对encoder only decoder only encoder-decoder3类transformer模型进行加速优化
对encoder only主要是做算子融合,因为encoder涉及到很大小算子的计算,包括 transpose、concat 这些简单算子以及softmax(涉及到ex指数计算)layernorm(均值方差)gelu(tanh非线性计算)等非线性计算,
YOLO系列问题
前处理和后处理具体包括什么?
前处理你是如何加速的?
YOLOv8的改进点有哪些?
Yolov8换成了目前主流的解耦头结构(Decoupled-Head),将分类和检测头分离,同时也从Anchor-Based换成了Anchor-Free。
Yolov8使用C2f模块代替C3模块。具体改进如下:
第一个卷积层的Kernel size从6×6改为3x3。
所有的C3模块改为C2f模块,如下图所示,多了更多的跳层连接和额外Split操作。
Block数由C3模块3-6-9-3改为C2f模块的3-6-6-3。
相关文章:
ViT面试知识点
文章目录 VITCLIPBlipSAMLSegFast TransformerYOLO系列问题 BatchNorm是对一个batch-size样本内的每个特征做归一化,LayerNorm是对每个样本的所有特征做归一化。 Layer Normalization(层归一化,简称LayerNorm)是一种在深度学习中…...
的区别;ChatGPT 和 RAG 的联系)
ChatGPT 和 RAG(检索增强生成)的区别;ChatGPT 和 RAG 的联系
目录 ChatGPT 和 RAG(检索增强生成)的区别 知识来源与利用方式 回答准确性和可靠性 模型架构和复杂性 适用场景 ChatGPT 和 RAG 的联系 ChatGPT 和 RAG(检索增强生成)的区别 知识来源与利用方式 ChatGPT:是基于大规模预训练的语言模型,知识是在预训练过程中从大量的…...

qt获取本机IP和定位
前言: 在写一个天气预报模块时,需要一个定位功能,在网上翻来翻去才找着,放在这里留着回顾下,也帮下有需要的人 正文: 一开始我想着直接调用百度地图的API来定位, 然后我就想先获取本机IP的方…...
-CodeQL for Java(AST、元数据、调用图))
CodeQL学习笔记(5)-CodeQL for Java(AST、元数据、调用图)
最近在学习CodeQL,对于CodeQL就不介绍了,目前网上一搜一大把。本系列是学习CodeQL的个人学习笔记,根据个人知识库笔记修改整理而来的,分享出来共同学习。个人觉得QL的语法比较反人类,至少与目前主流的这些OOP语言相比&…...

服装品牌零售业态融合中的创新发展:以开源 AI 智能名片 S2B2C 商城小程序为视角
摘要:本文以服装品牌零售业态融合为背景,探讨信息流优化和资金流创新的重要作用,并结合开源 AI 智能名片 S2B2C 商城小程序,分析其如何进一步推动服装品牌在零售领域的发展,提高运营效率和用户体验,实现商业…...

前端将网页转换为pdf并支持下载与上传
1.pdf下载 handleExport() {const fixedH document.getElementById("fixed-h");const pageOne document.getElementById("mix-print-box-one");const pageTwo document.getElementById("mix-print-box-two");fixedH.style.height 30vh;pageO…...
)
Android 依赖统一配置管理(Version Catalogs)
最近升级了Android Studio版本到Koala Feature Drop | 2024.1.2,新建项目后发现项目配置又有变化,默认开始使用了一个名叫 Gradle 版本目录的东西,当然也可以称之为依赖统一配置管理,一开始还有点陌生,但是经过一番了解…...

如何为数据看板产品接入实时行情接口并展示行情
在金融科技领域,实时数据是分析和决策的关键因素。通过AllTick的实时行情API,您可以轻松将实时市场数据集成到数据看板产品中,为用户提供丰富的市场洞察。本文将详细介绍如何使用AllTick API,通过WebSocket协议接收并展示实时市场…...

数据结构 C/C++(实验一:线性表)
(大家好,今天分享的是数据结构的相关知识,大家可以在评论区进行互动答疑哦~加油!💕) 目录 提要:实验题目 一、实验目的 二、实验内容及要求 三、算法思想 实验1 实验2 四、源程序及注释 …...

使用WebStorm开发Vue3项目
记录一下使用WebStorm开发Vu3项目时的配置 现在WebStorm可以个人免费使用啦!🤩 基本配置 打包工具:Vite 前端框架:ElementPlus 开发语言:Vue3、TypeScript、Sass 代码检查:ESLint、Prettier IDE…...

Linux高阶——1103——Signal信号机制
1、信号机制 在linux和unix系统下,如果想要处置(挂起,结束)进程,可以使用信号,经典消息机制,所以进程包括系统进程都是利用信号处置进程的 kill -l——查看所有系统支持的信号 1-31号信号——Unix经典信号ÿ…...

如何编写STM32的定时器程序
编写STM32的定时器程序通常涉及以下步骤: 1. 选择定时器和时钟配置 首先,你需要选择一个可用的定时器(TIM),并配置其时钟源。时钟源可以是内部时钟或外部时钟,通常通过RCC(Reset and Clock Con…...

【C++】C++的单例模式、跟踪内存分配的简单方法
二十四、C的单例模式、跟踪内存分配的简单方法 1、C的单例模式 本小标题不是讨论C的语言特性,而是一种设计模式,用于确保一个类在任何情况下都只有一个实例,并提供一个全局访问点来获取这个实例。即C的单例模式。这种模式常用于资源管理&…...
构建一个导航栏web
<!DOCTYPE html> <html><head><meta charset"utf-8"><title></title><style>*{margin: 0;padding: 0;}#menu{background-color:purple;width: 100px;height: 50px;}.item{float: left;/* 浮动标签可以让块标签,…...

【Linux】Linux安全与密钥登录指南
在使用Linux服务器时,确保服务器的安全至关重要。本文将为你介绍一些关键的Linux安全措施,包括开启密钥登录、查看登录日志、限制登录IP以及查看系统中能够登录的账号。以下内容适合小白用户,通过简单的操作就能有效提升服务器的安全性。 目录…...

数据采集之scrapy框架
本博文使用基本框架完成搜房网或者其他网站的数据爬取(重点理解 scrapy 框架的构建过程,使用回调函数,完成数据采集和数据处理) 包结构目录如下图所示: 主要代码: (sfw.py) # -*- …...

ReactPress—基于React的免费开源博客CMS内容管理系统
ReactPress Github项目地址:https://github.com/fecommunity/reactpress 欢迎提出宝贵的建议,感谢Star。 
Android 解决飞行模式下功耗高,起伏波动大的问题
根据现象抓log如下: 10-31 15:26:16.149066 940 3576 I android.hardware.usb1.2-service-mediatekv2: uevent_event change/devices/platform/soc/10026000.pwrap/10026000.pwrap:mt6366/mt6358-gauge/power_supply/battery 10-31 15:26:16.149245 940 3576 …...

2024第三次随堂测验参考答案
7-1 求一组数组中的平均数 输入10个整数,输出这10个整数的的平均数,要求输出的平均数保留2位小数 输入样例: 1 2 3 4 5 6 7 8 9 10 输出样例: 5.50 参考答案: #include <stdio.h> int main(){int sum 0;…...
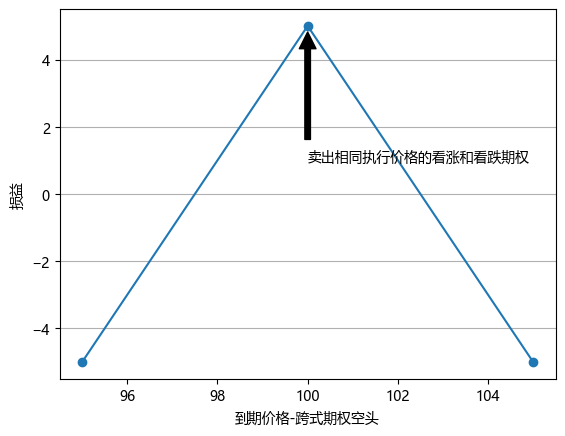
期权交易策略 v0.1
一.概述 1.参考 <期权波动率与定价> 2.期权价格 标的现价100元,到期日价格可能情况如下。 价格 80 90 100 110 120 概率 20% 20% 20% 20% 20% 持有标的时,期望收益为0.如果持有100的看涨期权,忽略期权费,期望收益为(100-100)*0.2…...

机器学习实战地形图:从问题定义到模型监控的端到端闭环
1. 项目概述:这不是一本“速成手册”,而是一张机器学习领域的实操地形图 “Machine Learning A-Z Briefly Explained”——光看标题,很多人第一反应是“又一本入门书?”、“是不是那种翻两页就堆满公式、第三章就开始推导梯度下降…...
)
用正点原子Nano开发板,5分钟搞定RT-Thread Nano的MDK5工程配置(附串口调试技巧)
正点原子Nano开发板极速上手RT-Thread实战指南 1. 开箱即用的开发环境搭建 刚拿到正点原子Nano开发板时,最令人兴奋的莫过于快速验证硬件是否正常工作。这款基于STM32F103RBT6的开发板,以其72MHz主频和丰富的外设资源,成为嵌入式入门学习的…...

Webdash社区贡献指南:如何参与开源项目并开发优质插件
Webdash社区贡献指南:如何参与开源项目并开发优质插件 【免费下载链接】webdash 🔥 Orchestrate your web project with Webdash the customizable web dashboard 项目地址: https://gitcode.com/gh_mirrors/we/webdash Webdash作为一款可定制的W…...

如何高效使用开源视频下载插件:专业用户的终极指南
如何高效使用开源视频下载插件:专业用户的终极指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper VideoDownloadHelper是一款专为…...

Hermes Agent对接Taotoken自定义Provider的配置要点详解
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent对接Taotoken自定义Provider的配置要点详解 1. 理解对接的基本前提 Hermes Agent是一个支持多种大模型提供方的开发工…...

让中国开源的声音被全球听见——开源社诚邀您参与Linux基金会开源商业化调研
大家好!近期,我们收到了Linux基金会的联系。一直以来,Linux基金会作为全球开源生态的核心推动者,持续通过专业的调研与权威报告,为全球开源的发展指明方向。根据其2026年最新研究,企业积极贡献开源可获得平…...

从CST到ADS/Keysight:手把手教你导出精准的Touchstone文件做联合仿真
从CST到ADS/Keysight:手把手教你导出精准的Touchstone文件做联合仿真 在射频和微波系统设计中,电磁仿真与电路仿真的无缝衔接是提升设计效率的关键。许多工程师都曾遇到过这样的困境:在CST中精心优化的天线或滤波器模型,导出后却无…...

从瑞芯微与飞凌嵌入式合作,看嵌入式核心板选型与产业协同
1. 项目概述:一次合作背后的产业逻辑最近,飞凌嵌入式在瑞芯微的合作伙伴大会上,拿下了“2024年度优秀合作奖”。这事儿在圈内不算大新闻,但如果你拆开来看,会发现它背后其实是一套非常经典的产业合作范本。它讲的不是某…...

Flutter集成Unity真机黑屏崩溃的6大硬性结构契约
1. 这不是“加个插件就能跑”的事:为什么90%的Flutter Unity集成在真机上直接失败“flutter-unity-view-widget”这名字听起来很友好——一个View、一个Widget、一个“view widget”,仿佛只是把Unity渲染的画面塞进Flutter的Widget树里,像放一…...

G-Helper:释放华硕笔记本性能的免费开源轻量控制神器
G-Helper:释放华硕笔记本性能的免费开源轻量控制神器 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exp…...