数据采集之scrapy框架

# -*- coding: utf-8 -*-
import scrapy
import re
from fang.items import NewHouseItem,ESFHouseItem
class SfwSpider(scrapy.Spider):
name = 'sfw' allowed_domains = ['fang.com']
start_urls = ['http://www.fang.com/SoufunFamily.htm']
def parse(self, response):
trs =response.xpath("//div[@class='outCont']//tr")
province =None
for tr in trs:
tds =tr.xpath(".//td[not(@class='font01')]")
province_td=tds[0]
province_text =province_td.xpath(".//text()").get()
province_text =re.sub(r"\s","",province_text)
if province_text:
province=province_text
#不爬取海外
if province =='其它':
continue
city_td = tds[1]
city_links =city_td.xpath(".//a")
for city_link in city_links:
city_name = city_link.xpath(".//text()").get()
city_url = city_link.xpath(".//@href").get()
# print("省份",province)
# print('城市',city_name)
# print('城市 url',city_url)
url_module =city_url.split(".")
scheme =url_module[0]
fang =url_module[1]
com = url_module[2]
if 'http://bj' in scheme:
newhouse_url="http://newhouse.fang.com/house/s/?from=db" esf_url="http://esf.fang.com/?ctm=1.bj.xf_search.head.105" else:
#新房 url
if "/" in com:
newhouse_url =scheme+'.'+"newhouse."+fang+"."+com+"house/s/" else:
newhouse_url = scheme + '.' + "newhouse." + fang + "." + com +
"/house/s/" #旧房 url
esf_url =scheme+'.'+"esf."+fang+"."+com
yield
scrapy.Request(url=newhouse_url,callback=self.parse_newhouse,meta={"info":(province,city_na
me)})
yield scrapy.Request(url=esf_url, callback=self.parse_esf, meta={"info":
(province, city_name)})
def parse_newhouse(self,response):
province,city =response.meta.get('info')
#获取 yield 中的元组
lis = response.xpath("//div[contains(@class,'nl_con clearfix')]/ul/li[not(@id)]")
for li in lis:
name = "".join(li.xpath(".//div[contains(@class,'nlcd_name')]/a/text()").getall())
name = re.sub(r"\s","",name)
# if name!=None:
# name=name.strip()
# print(name)
house_type_list = li.xpath(".//div[contains(@class,'house_type')]/a/text()").getall()
house_type_list=list(map(lambda x:re.sub(r"\s","",x),house_type_list))
rooms_list = list(filter(lambda x:x.endswith("居"),house_type_list))
rooms = "".join(rooms_list)
#print(rooms)
area="".join(li.xpath(".//div[contains(@class,'house_type')]/text()").getall())
area = re.sub(r"\s|-|/","",area)
#print(area)
address = "".join(li.xpath(".//div[@class = 'address']/a/@title").getall())
#print(address)
district_text = "".join(li.xpath(".//div[@class ='address']/a//text()").getall())
try:
district = re.search(r".*\[(.+)\].*",district_text).group(1)
except Exception:
district = "" #print(district)
sale = li.xpath(".//div[contains(@class,'fangyuan')]/span/text()").get()
#售楼状态是第一个,只需要一个 get
#print(sale)
price = "".join(li.xpath(".//div[contains(@class,'nhouse_price')]//text()").getall())
price = re.sub(r"\s|广告","",price)
#print(price)
origin_url_p = "".join(li.xpath(".//div[@class='nlcd_name']/a/@href").getall())
origin_url = response.urljoin(origin_url_p)
# detail_url = "".join(dl.xpath(".//h4[@class='clearfix']/a/@href").getall())
# item['origin_url'] = response.urljoin(detail_url)
#print(origin_url)
item
=NewHouseItem(province=province,city=city,name=name,rooms=rooms,address=address,area=a
rea,district=district,price=price,sale=sale,origin_url=origin_url)
yield item
next_url = response.xpath("//div[@class='page']/a[@class='next']/@href").get()
if next_url:
yield
scrapy.Request(url=response.urljoin(next_url),callback=self.parse_newhouse,meta={"info":(provi
nce,city)})
def parse_esf(self,response):
province,city =response.meta.get('info')
#print(name)
dls = response.xpath("//dl[contains(@dataflag,'bg')]")
for dl in dls:
item = ESFHouseItem(province=province,city=city)
name = ''.join(dl.xpath(".//dd//p[@class='add_shop']/a/@title").getall())
name = re.sub(r"\s", "", name)
item['name']=name
infos = dl.xpath(".//dd//p[@class='tel_shop']//text()").getall()
infos = list(map(lambda x:re.sub(r"\s|\|",'',x),infos))
infos = list(filter(None,infos))
for info in infos:
if "厅" in info:
item['rooms']=info
elif '层' in info:
item['floor']=info
elif '年' in info:
item['year']=info
elif '向' in info:
item['toward']=info
elif '㎡' in info:
item['area']=info
address = "".join(dl.xpath(".//dd//p[@class='add_shop']//span//text()").getall())
item['address']=address
price =
"".join(dl.xpath(".//dd[@class='price_right']//span[@class='red']//text()").getall())
item['price'] = price
unit = "".join(dl.xpath(".//dd[@class='price_right']//span[2]//text()").getall())
item['unit'] = unit
detail_url = "".join(dl.xpath(".//h4[@class='clearfix']/a/@href").getall())
item['origin_url']=response.urljoin(detail_url)
yield item
next_url = response.xpath("//div[@class='page_al']//p[1]/a/@href").get()
yield
scrapy.Request(url=response.urljoin(next_url),callback=self.parse_esf,meta={"info":{province,city}
})(item.py)
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class NewHouseItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#省份
province = scrapy.Field()
#城市
city = scrapy.Field()
#小区名
name = scrapy.Field()
#价格
price = scrapy.Field()
#X 居,列表
rooms = scrapy.Field()
#面积
area = scrapy.Field()
#地址
address = scrapy.Field()
#行政区
district = scrapy.Field()
#是否在售
sale = scrapy.Field()
#房天下详情页面 url
origin_url = scrapy.Field()
class ESFHouseItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 省份
province = scrapy.Field()
# 城市
city = scrapy.Field()
# 小区名
name = scrapy.Field()
# 价格
price = scrapy.Field()
# 几室几厅
rooms = scrapy.Field()
# 层
floor = scrapy.Field()
# 朝向
toward = scrapy.Field()
# 年份
year = scrapy.Field()
# 面积
area = scrapy.Field()
# 地址
address = scrapy.Field()
#单价
unit = scrapy.Field()
# #联系人
# people = scrapy.Field()
# 房天下详情页面 url
origin_url = scrapy.Field()爬取数据如图所示

相关文章:
数据采集之scrapy框架
本博文使用基本框架完成搜房网或者其他网站的数据爬取(重点理解 scrapy 框架的构建过程,使用回调函数,完成数据采集和数据处理) 包结构目录如下图所示: 主要代码: (sfw.py) # -*- …...

ReactPress—基于React的免费开源博客CMS内容管理系统
ReactPress Github项目地址:https://github.com/fecommunity/reactpress 欢迎提出宝贵的建议,感谢Star。 
Android 解决飞行模式下功耗高,起伏波动大的问题
根据现象抓log如下: 10-31 15:26:16.149066 940 3576 I android.hardware.usb1.2-service-mediatekv2: uevent_event change/devices/platform/soc/10026000.pwrap/10026000.pwrap:mt6366/mt6358-gauge/power_supply/battery 10-31 15:26:16.149245 940 3576 …...

2024第三次随堂测验参考答案
7-1 求一组数组中的平均数 输入10个整数,输出这10个整数的的平均数,要求输出的平均数保留2位小数 输入样例: 1 2 3 4 5 6 7 8 9 10 输出样例: 5.50 参考答案: #include <stdio.h> int main(){int sum 0;…...
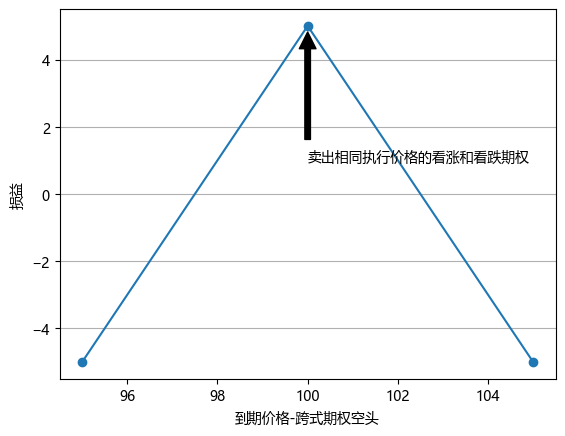
期权交易策略 v0.1
一.概述 1.参考 <期权波动率与定价> 2.期权价格 标的现价100元,到期日价格可能情况如下。 价格 80 90 100 110 120 概率 20% 20% 20% 20% 20% 持有标的时,期望收益为0.如果持有100的看涨期权,忽略期权费,期望收益为(100-100)*0.2…...

pytorch学习:矩阵分解:奇异值分解(SVD分解)
前言 矩阵分解(Matrix Decomposition)是将一个矩阵分解成多个矩阵的乘积的过程,这种分解方法在计算、机器学习和线性代数中有广泛应用。不同的分解方式可以简化计算、揭示矩阵的内在结构或提高算法的效率。 奇异值分解 奇异值分解…...

接口测试用例设计的关键步骤与技巧解析!
简介 接口测试在需求分析完成之后,即可设计对应的接口测试用例,然后根据用例进行接口测试。接口测试用例的设计也需要用到黑盒测试用例设计方法,和测试流程与理论章节的功能测试用例设计的方法类似,设计过程中还需要增加与接口特…...

CSS画icon图标系列(一)
目录 前言: 一、向右箭头 1.原理: 2.代码实现 3.结果展示: 二、钟表 1.原理: 2.代码展示: 3.最终效果: 三、小手机 1.原理: 2.代码展示: 3.最后效果: 四、结…...

【数据结构-合法括号字符串】【华为笔试题】力扣1190. 反转每对括号间的子串
给出一个字符串 s(仅含有小写英文字母和括号)。 请你按照从括号内到外的顺序,逐层反转每对匹配括号中的字符串,并返回最终的结果。 注意,您的结果中 不应 包含任何括号。 示例 1: 输入:s “…...

qt QFileInfo详解
1、概述 QFileInfo是Qt框架中用于获取文件信息的工具类。它提供了与操作系统无关的文件属性,如文件的名称、位置(路径)、访问权限、类型(是否为目录或符号链接)等。此外,QFileInfo还可以获取文件的大小、创…...

金华迪加 现场大屏互动系统 mobile.do.php 任意文件上传漏洞复现
0x01 产品简介 金华迪加现场大屏互动系统是一种集成了先进技术和创意设计的互动展示解决方案,旨在通过大屏幕和多种交互方式,为观众提供沉浸式的互动体验。该系统广泛应用于各类活动、展览、会议等场合,能够显著提升现场氛围和参与者的体验感。 0x02 漏洞概述 金华迪加 现…...

探寻5G工业网关市场,5G工业网关品牌解析
随着5G技术的浪潮席卷全球,工业领域正经历着一场前所未有的变革。5G工业网关,作为连接工业设备与云端的桥梁,以其高速、低延迟的数据传输能力和强大的边缘计算能力,成为推动工业数字化转型的关键力量。那么,在众多5G工…...

RK3568开发板静态IP地址配置
1. 连接SSH MYD-LR3568 开发板设置了静态 eth0:1 192.168.0.10 和 eth1:1 192.168.1.10,在没有串口时调试开发板,可以用工具 SSH 登陆到开发板。 首先需要用一根网线直连电脑和开发板,或者通过路由器连接到开发板,将电脑 IP 手动设…...

element-plus table tableRowClassName 无效
官网上给的是 .el-table .warning-row {--el-table-tr-bg-color: var(--el-color-warning-light-9); } .el-table .success-row {--el-table-tr-bg-color: var(--el-color-success-light-9); } 但是 如果 加上了 scoped 这样样式是无效的 在 vue3 中用样式穿透 即可生…...

商务英语学习柯桥学外语到泓畅-老外说“go easy on me”是什么意思?
在口语中“go easy on sb ”这个短语是很常见的 01 go easy on me 怎么理解? 在口语中,“go easy on me”是一个非常常见的表达,通常表示请求对方在某方面对自己宽容一些,不要对自己太过苛刻或严厉。 短语(goÿ…...

【Python爬虫基础】基于 Python 的反爬虫机制详解与代码实现
基于 Python 的反爬虫机制详解与代码实现 在如今的信息时代,数据的重要性不言而喻。许多企业网站都包含着宝贵的数据,这些数据可能会被网络爬虫恶意抓取,这种行为不仅影响服务器的正常运行,还可能泄露商业机密。为了应对这种情况,网站开发人员需要了解并应用有效的反爬虫…...

HTB:PermX[WriteUP]
目录 连接至HTB服务器并启动靶机 1.How many TCP ports are listening on PermX? 使用nmap对靶机TCP端口进行开放扫描 2.What is the default domain name used by the web server on the box? 使用curl访问靶机80端口 3.On what subdomain of permx.htb is there an o…...

uniapp 整合 OpenLayers - 使用modify修改要素
import { Modify } from "ol/interaction"; 修改点、线、面的位置和形状核心代码: // 修改要素核心代码modifyFeature() {this.modify new Modify({source: this.lineStringLayer.getSource(),});this.map.addInteraction(this.modify);}, 完整代码&am…...

JMeter快速造数之数据导入导出
导入数据 输入表格格式如下 创建CSV Data Set Config 在Body Data中调用 { "username": "${email}", "password": "123456", "client_id": "00bb9dbfc67439a5d42e0e19f448c7de310df4c7fcde6feb5bd95c6fac5a5afc"…...

框架学习01-Spring
一、Spring框架概述 Spring是一个开源的轻量级Java开发框架,它的主要目的是为了简化企业级应用程序的开发。它提供了一系列的功能,包括控制反转(IOC)、注入(DI)、面向切面编程(AOP)…...

Cursor Pro破解工具终极指南:5步解锁AI编程助手完整功能
Cursor Pro破解工具终极指南:5步解锁AI编程助手完整功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your t…...

Unity 2D跑酷开发全链路实战:从物理帧到对象池的工程化落地
1. 这不是“又一个跑酷游戏”,而是Unity 2D开发能力的完整压力测试 很多人点开“Unity跑酷游戏教程”时,心里想的是:拖几个Sprite,加个Rigidbody2D,写个Input.GetKeyDown(KeyCode.Space)跳一下,再配个背景滚…...

Docker Login 报错“unauthorized”怎么办?从排查到解决的完整指南
Docker登录报错"unauthorized"全解析:从根因定位到企业级解决方案 当你满心欢喜地敲下docker login准备拉取镜像时,终端突然跳出刺眼的红色错误提示——"unauthorized: authentication required"。这种场景对开发者而言绝不陌生&…...

YooAsset实战指南:Unity热更新架构重构与AB包管理
1. 为什么热更新不是“加个插件就能跑”,而是Unity项目上线前必须重做的一次架构手术 在Unity游戏开发里,"热更新"这三个字,听上去像是一键开启的魔法开关——版本发出去了,发现UI错位、数值写反、新活动脚本没加载&…...

解锁智能电网通信:libiec61850如何重塑电力自动化架构
解锁智能电网通信:libiec61850如何重塑电力自动化架构 【免费下载链接】libiec61850 Official repository for libIEC61850, the open-source library for the IEC 61850 protocols 项目地址: https://gitcode.com/gh_mirrors/li/libiec61850 在电力系统自动…...

Display Driver Uninstaller完整攻略:显卡驱动清理的终极解决方案
Display Driver Uninstaller完整攻略:显卡驱动清理的终极解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-drivers-u…...

Mac应用卸载不干净?Pearcleaner帮你彻底清理,释放存储空间
Mac应用卸载不干净?Pearcleaner帮你彻底清理,释放存储空间 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾发现,…...

如何在Chrome中轻松下载视频?VideoDownloadHelper开源插件完全指南
如何在Chrome中轻松下载视频?VideoDownloadHelper开源插件完全指南 【免费下载链接】VideoDownloadHelper Chrome Extension to Help Download Video for Some Video Sites. 项目地址: https://gitcode.com/gh_mirrors/vi/VideoDownloadHelper 还在为无法下载…...

让中国开源的声音被全球听见——开源社诚邀您参与Linux基金会开源商业化调研
大家好!近期,我们收到了Linux基金会的联系。一直以来,Linux基金会作为全球开源生态的核心推动者,持续通过专业的调研与权威报告,为全球开源的发展指明方向。根据其2026年最新研究,企业积极贡献开源可获得平…...
)
Graphormer实战:用最短路径和虚拟节点搞定分子性质预测(附PyTorch代码)
Graphormer实战:从分子结构到性质预测的完整实现指南 在药物发现和材料科学领域,准确预测分子的物理化学性质可以大幅加速研发进程。传统方法依赖昂贵的实验测量或复杂的量子化学计算,而图神经网络(GNN)和Transformer的结合——Graphormer&a…...