【大模型LLM面试合集】大语言模型架构_chatglm系列模型
chatglm系列模型
1.ChatGLM
1.1 背景
主流的预训练框架主要有三种:
- autoregressive自回归模型(AR模型):代表作GPT。本质上是一个left-to-right的语言模型。通常用于生成式任务,在长文本生成方面取得了巨大的成功,比如自然语言生成(NLG)领域的任务:摘要、翻译或抽象问答。当扩展到十亿级别参数时,表现出了少样本学习能力。缺点是单向注意力机制,在NLU任务中,无法完全捕捉上下文的依赖关系。
- autoencoding自编码模型(AE模型):代表作BERT。是通过某个降噪目标(比如MLM)训练的双向文本编码器。编码器会产出适用于NLU任务的上下文表示,但无法直接用于文本生成。
- encoder-decoder(Seq2seq模型):代表作T5。采用双向注意力机制,通常用于条件生成任务,比如文本摘要、机器翻译等。
三种预训练框架各有利弊,没有一种框架在以下三种领域的表现最佳:自然语言理解(NLU)、无条件生成以及条件生成。T5曾经尝试使用MTL的方式统一上述框架,然而自编码和自回归目标天然存在差异,简单的融合自然无法继承各个框架的优点。
在这个天下三分的僵持局面下,GLM诞生了。
GLM模型基于autoregressive blank infilling方法,结合了上述三种预训练模型的思想。
1.2 GLM预训练框架
GLM特点
- 自编码思想:在输入文本中,随机删除连续的tokens。
- 自回归思想:顺序重建连续tokens。在使用自回归方式预测缺失tokens时,模型既可以访问corrupted文本,又可以访问之前已经被预测的spans。
- span shuffling + 二维位置编码技术。
- 通过改变缺失spans的数量和长度,自回归空格填充目标可以为条件生成以及无条件生成任务预训练语言模型。
(1)自回归空格填充任务
给定一个输入文本 x = [ x 1 , … x n ] x=\left[x_{1}, \ldots x_{n}\right] x=[x1,…xn],可以采样得到多个文本spans { s 1 , … s m } \left\{s_{1}, \ldots s_{m}\right\} {s1,…sm}。为了充分捕捉各spans之间的相互依赖关系,可以对spans的顺序进行随机排列,得到所有可能的排列集合 Z m Z_m Zm,其中: S z < i = [ s z 1 , … , s z i − 1 ] S_{z<i}=\left[s_{z_{1}}, \ldots, s_{z_{i-1}}\right] Sz<i=[sz1,…,szi−1]。所以预训练目标很清晰:
max θ E z ∼ Z m [ ∑ i = 1 m log p θ ( s z i ∣ x corrupt , s z < i ) ] \max _{\theta} \mathbb{E}_{\boldsymbol{z} \sim Z_{m}}\left[\sum_{i=1}^{m} \log p_{\theta}\left(\boldsymbol{s}_{z_{i}} \mid \boldsymbol{x}_{\text {corrupt }}, \boldsymbol{s}_{\boldsymbol{z}_{<i}}\right)\right] θmaxEz∼Zm[i=1∑mlogpθ(szi∣xcorrupt ,sz<i)]
GLM自回归空格填充任务的技术细节:
- 输入 x x x可以被分成两部分:Part A是被mask的文本 x corrupt x_{\text {corrupt }} xcorrupt ,Part B由masked spans组成。假设原始输入文本是 [ x 1 , x 2 , x 3 , x 4 , x 5 , x 6 ] [x1, x2, x3, x4, x5, x6] [x1,x2,x3,x4,x5,x6],采样的两个文本片段是 [ x 3 ] [x3] [x3]以及 [ x 5 , x 6 ] [x5, x6] [x5,x6]。那么mask后的文本序列是: x 1 , x 2 , [ M ] , x 4 , [ M ] x1, x2, [M], x4, [M] x1,x2,[M],x4,[M],即Part A;同时我们需要对Part B的片段进行shuffle。每个片段使用
[S]填充在开头作为输入,使用[E]填充在末尾作为输出。 - 二维位置编码:Transformer使用位置编码来标记tokens中的绝对和相对位置。在GLM中,使用二维位置编码,第一个位置id用来标记Part A中的位置,第二个位置id用来表示跨度内部的相对位置。这两个位置id会通过embedding表被投影为两个向量,最终都会被加入到输入token的embedding表达中。
- 观察GLM中自定义attention mask的设计,非常巧妙:
- Part A中的tokens彼此可见,但是不可见B中的任意tokens。
- Part B tokens可见Part A。
- Part B tokens可见B中过去的tokens,不可见B中未来的tokens。
- 采样方式:文本片段的采样遵循泊松分布,重复采样,直到原始tokens中有15%被mask。
- 总结:模型可以自动学习双向encoder(Part A)以及单向decoder(Part B)。

(2)多目标预训练
上述方法适合于NLU任务。作者希望可以训练一个既可以解决NLU任务,又具备文本生成能力的模型。因此除了空格填充目标之外,还需要增加一个生成长文本目标的任务。具体包含以下两个目标:
- 文档级别。从文档中采样一个文本片段进行mask,且片段长度为文档长度的50%~100%。这个目标用于长文本生成。
- 句子级别。限制被mask的片段必须是完整句子。多个片段需覆盖原始tokens的15%。这个目标是用于预测完整句子或者段落的seq2seq任务。
(3)模型结构
GLM在原始single Transformer的基础上进行了一些修改:
- 重组了LN和残差连接的顺序;
- 使用单个线性层对输出token进行预测;
- 激活函数从ReLU换成了GeLU。
但我觉得这部分的修改比较简单常见。核心和亮点还是空格填充任务的设计。
(4)GLM微调
对于下游NLU任务来说,通常会将预训练模型产出的序列或tokens表达作为输入,使用线性分类器预测label。所以预训练与微调之间存在天然不一致。
作者按照PET的方式,将下游NLU任务重新表述为空白填充的生成任务。具体来说,比如给定一个已标注样本(x, y),将输入的文本x转换成一个包含mask token的完形填空问题。比如,情感分类任务可以表述为:“{SENTENCE}. It’s really [MASK]”。输出label y也同样会被映射到完形填空的答案中。“positive” 和 “negative” 对应的标签就是“good” 和 “bad。
其实,预训练时,对较长的文本片段进行mask,以确保GLM的文本生成能力。但是在微调的时候,相当于将NLU任务也转换成了生成任务,这样其实是为了适应预训练的目标。但难免有一些牵强。

| BERT | XLNet | T5 | UniLM |
| 1、无法捕捉mask tokens的相互依赖性。2、不能准确填充多个连续的tokens。为了推断长度为l的答案概率,BERT需要执行l次连续预测。 | 与GLM相同,使用自回归目标预训练。1、使用文本mask之前的原始位置编码,推理过程中,需要事先知晓或枚举答案长度,与BERT的问题相同。2、双流自注意力机制,使预训练时间成本增加了一倍。 | 使用类似的空格填充目标预训练encoder-decoder Transformer。在编码和解码阶段使用独立的位置编码,使用多个哨兵token来区分mask片段。而在下游任务中,仅使用一个哨兵token,造成模型能力的浪费以及预训练-微调的不一致。 | 通过改变双向、单向以及交叉注意力之间的注意力mask,统一不同的预训练目标。1、总是使用[mask] token替代mask片段,限制了它对mask片段及其上下文的依赖关系进行建模的能力。2、在下游任务微调时,自编码比自回归更加低效。 |
2.ChatGLM-2
2.1 主要创新
- 更长的上下文:基于 FlashAttention 技术,将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练。对于更长的上下文,发布了 ChatGLM2-6B-32K 模型。LongBench 的测评结果表明,在等量级的开源模型中,ChatGLM2-6B-32K 有着较为明显的竞争优势。
- 更强大的性能:基于 ChatGLM 初代模型的开发经验,全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
- 更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
- 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在填写问卷进行登记后亦允许免费商业使用。
2.2 与ChatGLM的变化
- 使用了RoPE替换二维位置编码。这也是GLM中提出的亮点设计之一。但是目前大部分主流的LLMs都在使用RoPE,所以大势所趋。当前版本仍然采用了最初的RoPE设计,事实上现在的RoPE经过了xPOS→线性内插→NTK-Aware Scaled RoPE→…若干次进化。
- Multi-Query Attention:这是一种共享机制的Attention,相比Multi-Head Attention,其Query部分没有区别,Key和Value可以只用一个Head。计算时,对Key和Value进行expand或者repeat操作,使它们填充到与Query一样的维度,后续计算就与Multi-Head Attention没区别。
- Attention Mask: V1的attention mask分了2部分,Part A和Part B,Part A部分是双向Attention(代码中的prefix_attention_mask),Part B部分是Causal Attention(原代码文件中的get_masks函数)。在V2版本,全部换成了Causal Attention,不再区分是Part A还是Part B,完全变成了decoder-only的架构。
- 多目标任务:Chat版本主要还是用的gMask生成式任务,但是在V1版本的代码还能看到mask、gMask等字样,V2已经摒弃了这些特殊token,原因与Attention Mask一致,均因为变成了decoder-only的架构,不再需要区分Part A和Part B。
3.ChatGLM-3
省流:ChatGLM2与ChatGLM3模型架构是完全一致的,ChatGLM与后继者结构不同。可见ChatGLM3相对于ChatGLM2没有模型架构上的改进。
相对于ChatGLM,ChatGLM2、ChatGLM3模型上的变化:
- 词表的大小从ChatGLM的150528缩小为65024 (一个直观的体验是ChatGLM2、3加载比ChatGLM快不少)
- 位置编码从每个GLMBlock一份提升为全局一份
- SelfAttention之后的前馈网络有不同。ChatGLM用GELU(Gaussian Error Linear Unit)做激活;ChatGLM用Swish-1做激活。而且ChatGLM2、3应该是修正了之前的一个bug,因为GLU(Gated Linear Unit)本质上一半的入参是用来做门控制的,不需要输出到下层,所以ChatGLM2、3看起来前后维度不一致(27392->13696)反而是正确的。
4.模型架构比较
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).float().to('mps')
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
# from utils import load_model_on_gpus
# model = load_model_on_gpus("THUDM/chatglm3-6b", num_gpus=2)
model = model.eval()print(model)
ChatGLM的模型结构:
ChatGLMForConditionalGeneration((transformer): ChatGLMModel((word_embeddings): Embedding(150528, 4096)(layers): ModuleList((0-27): 28 x GLMBlock((input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(attention): SelfAttention((rotary_emb): RotaryEmbedding()(query_key_value): Linear(in_features=4096, out_features=12288, bias=True)(dense): Linear(in_features=4096, out_features=4096, bias=True))(post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)(mlp): GLU((dense_h_to_4h): Linear(in_features=4096, out_features=16384, bias=True)(dense_4h_to_h): Linear(in_features=16384, out_features=4096, bias=True))))(final_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True))(lm_head): Linear(in_features=4096, out_features=150528, bias=False)
)
ChatGLM2的模型结构:
ChatGLMForConditionalGeneration((transformer): ChatGLMModel((embedding): Embedding((word_embeddings): Embedding(65024, 4096))(rotary_pos_emb): RotaryEmbedding()(encoder): GLMTransformer((layers): ModuleList((0-27): 28 x GLMBlock((input_layernorm): RMSNorm()(self_attention): SelfAttention((query_key_value): Linear(in_features=4096, out_features=4608, bias=True)(core_attention): CoreAttention((attention_dropout): Dropout(p=0.0, inplace=False))(dense): Linear(in_features=4096, out_features=4096, bias=False))(post_attention_layernorm): RMSNorm()(mlp): MLP((dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False))))(final_layernorm): RMSNorm())(output_layer): Linear(in_features=4096, out_features=65024, bias=False))
)
ChatGLM3的模型结构:
ChatGLMForConditionalGeneration((transformer): ChatGLMModel((embedding): Embedding((word_embeddings): Embedding(65024, 4096))(rotary_pos_emb): RotaryEmbedding()(encoder): GLMTransformer((layers): ModuleList((0-27): 28 x GLMBlock((input_layernorm): RMSNorm()(self_attention): SelfAttention((query_key_value): Linear(in_features=4096, out_features=4608, bias=True)(core_attention): CoreAttention((attention_dropout): Dropout(p=0.0, inplace=False))(dense): Linear(in_features=4096, out_features=4096, bias=False))(post_attention_layernorm): RMSNorm()(mlp): MLP((dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False))))(final_layernorm): RMSNorm())(output_layer): Linear(in_features=4096, out_features=65024, bias=False))
)
相关文章:
【大模型LLM面试合集】大语言模型架构_chatglm系列模型
chatglm系列模型 1.ChatGLM 1.1 背景 主流的预训练框架主要有三种: autoregressive自回归模型(AR模型):代表作GPT。本质上是一个left-to-right的语言模型。通常用于生成式任务,在长文本生成方面取得了巨大的成功&a…...

深入理解 Kafka:分布式消息队列的强大力量
一、引言 在现代分布式系统中,消息队列扮演着至关重要的角色,而 Kafka 作为其中的佼佼者,以其高吞吐量、可扩展性和持久性等特点被广泛应用。无论是处理海量的日志数据、实时的用户交互信息,还是复杂的微服务间通信,Ka…...
LabVIEW 离心泵机组故障诊断系统
开发了一套基于LabVIEW图形化编程语言设计的离心泵机组故障诊断系统。系统利用先进的数据采集技术和故障诊断方法,通过远程在线监测与分析,有效提升了离心泵的预测性维护能力,保证了石油化工生产的连续性和安全性。 项目背景及意义 离心泵作…...

GEE土地分类——土地分类的原始remap转化原始的土地分类名称
简介 GEE土地分类——土地分类的原始remap转化原始的土地分类名称 函数 first(image2) Selects the value of the first value for each matched pair of bands in image1 and image2. If either image1 or image2 has only 1 band, then it is used against all the bands…...

一些关于云电脑与虚拟化东西
前言 好久没有更新了,在进行自我校准。 云计算是什么? 云计算是一种模型,它使得用户能够随时随地、方便地、按需访问共享的可配置计算资源池(例如,网络、服务器、存储、应用程序和服务),这些资…...

Java实现图片转pdf
该方法可以选择多个图片是否合并为一个pdf输出,也可以选择图片为横向或者纵向输出,也可以选择pdf页面为A3或者A4 第一步 <dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version…...

【iOS】使用AFNetworking进行网络请求
文章目录 前言AFNetworkingAFNetworking 的核心组件AKNetworking库的常用方法使用AKNetworking进行网络请求的步骤和代码示例 总结 前言 在暑假写天气预报项目时,我们已经接触到网络请求,当时我们是使用URLSession类,即Foundation框架中用于管…...

ThingsBoard规则链节点:RPC Call Reply节点详解
引言 1. RPC Call Reply 节点简介 2. 节点配置 2.1 基本配置示例 3. 使用场景 3.1 设备控制 3.2 状态查询 3.3 命令执行 4. 实际项目中的应用 4.1 项目背景 4.2 项目需求 4.3 实现步骤 5. 总结 引言 ThingsBoard 是一个开源的物联网平台,提供了设备管理…...
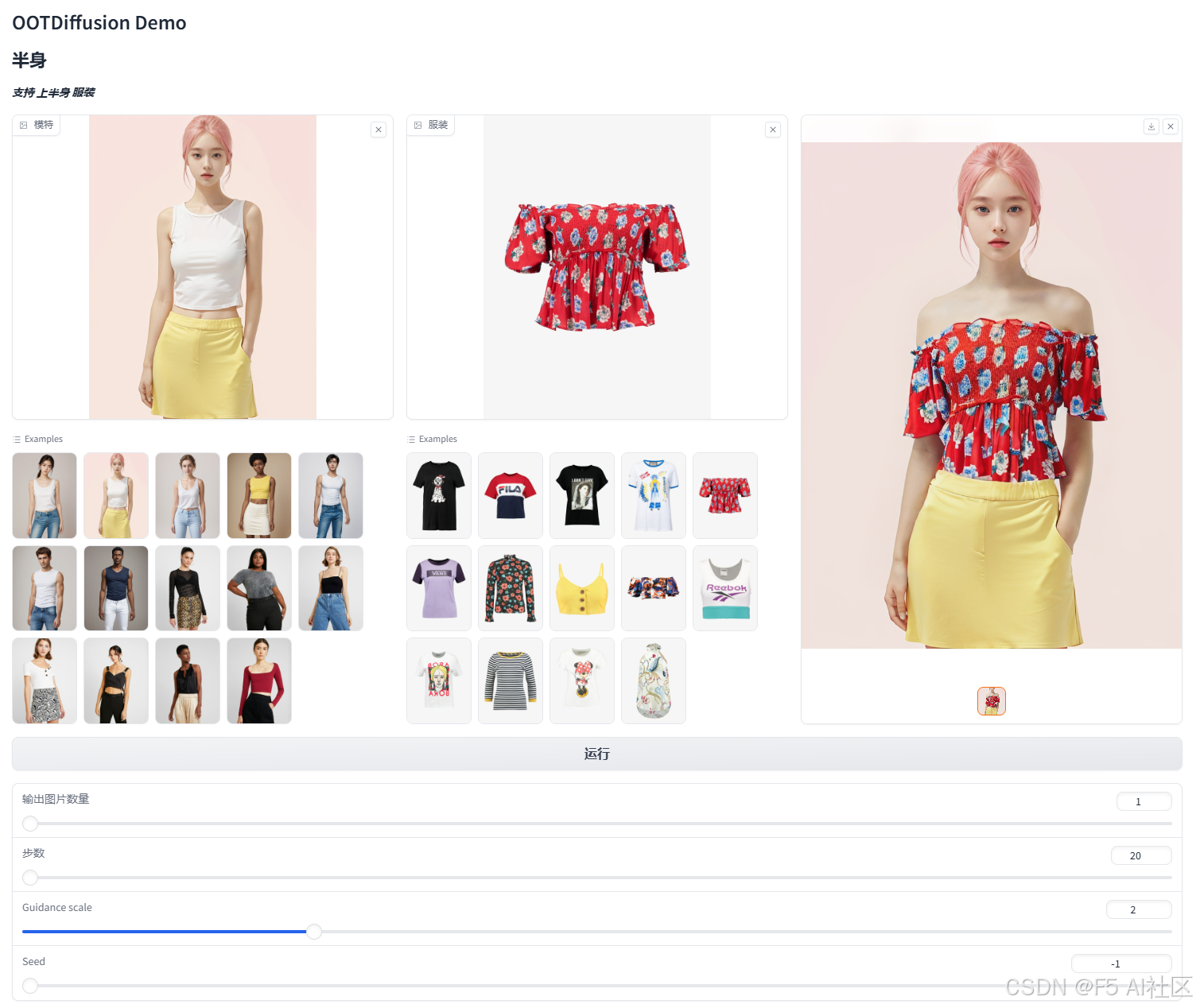
【AI换装整合包及教程】OOTDiffusion:以AI技术引领的时尚换装革命
在当今数字化快速发展的时代,人工智能(AI)技术正以前所未有的速度改变着我们的生活。从智能家居到自动驾驶,从在线教育到虚拟现实,AI的应用范围正在不断扩展。而在时尚领域,一款名为OOTDiffusion࿰…...

排序算法详细总结
算法 定义:算法是解决特定问题的明确步骤集合。算法的效率通常用时间复杂度和空间复杂度来衡量。 排序算法 定义:排序算法是计算机科学中用于对元素序列进行排序的一系列算法。排序算法在各种应用中都非常常见,从简单的数据处理到复杂的数…...

uniapp MD5加密
安装: npm install js-md5 -D 引入: import Md5 from js-md5 需求加密一个对象, login_form: {openId: 123456789,phone: ,scenario: 656677,phoneSessionKey: ,openIdSessionKey: ,timeStamp: , }, //10位时间戳(秒)…...

提升视觉回归测试体验:Cypress 插件推荐
项目介绍 在现代前端开发中,视觉回归测试是确保用户界面在不同版本之间保持一致性的关键步骤。然而,传统的视觉回归测试工具往往复杂且难以使用。为了解决这一问题,我们推荐一款专为 Cypress 设计的插件:Cypress Plugin Visual Re…...

fastbootd模式刷android固件的方法
1. fastbootd追根溯源 Google在Android 10上正式引入了动态分区机制来提升OTA的可扩展性。动态分区使能后:andorid系统可以在开机阶段动态地进行分区创建、分区销毁、分区大小调整等操作,下游厂商只需要规划好super分区的总大小,其内部的各个…...

基于C#实现Windows后台窗口操作与图像处理技术分析
在Windows编程中,操作后台窗口是一项复杂而有用的技术。它可以用来自动化用户界面测试、应用程序机器人等场景。本文将深入探讨如何在C#中绑定后台窗口、获取后台窗口界面图片,以及在图片中寻找指定图标并获取坐标。本技术文章结合最先进的资料与实践经验…...
戴尔电脑 Bios 如何进入?Dell Bios 进入 Bios 快捷键是什么?
BIOS(基本输入输出系统)是计算机启动时运行的第一个程序,它负责初始化硬件并加载操作系统。对于戴尔电脑用户来说,有时可能需要进入 BIOS 进行一些特定的设置调整,比如更改启动顺序、调整性能选项或解决硬件兼容性问题…...

数据结构之二叉树——堆 详解(含代码实现)
1.堆 如果有一个关键码的集合 K { , , , … ,},把它的所有元素按完全二叉树的顺序存储方式存储 在一个一维数组中,则称为小堆( 或大堆 ) 。将根节点最大的堆叫做最大堆或大根堆,根节点最小的…...
推荐一款面向增材制造的高效设计平台:nTopology
nTopology是一款面向增材制造的高效设计平台,平台预置了大量增材制造常用的设计工具包,工程师通过调用若干个预置工具包、或自主开发定制的工具包,建立一个工作流,实现复杂几何结构的参数化设计。nTopology集合了的强大几何建模和…...

SQL,力扣题目1767,寻找没有被执行的任务对【递归】
一、力扣链接 LeetCode_1767 二、题目描述 表:Tasks ------------------------- | Column Name | Type | ------------------------- | task_id | int | | subtasks_count | int | ------------------------- task_id 具有唯一值的列。 ta…...

JavaScript数据类型- Symbol 详解
文章目录 前言1.唯一性2. 描述3. 作为对象属性键4. 全局注册6. 不可变性7. 隐式转换 前言 Symbol是ES6新增内容,代表创建后独一无二且不可变的数据类型,它主要是为了解决可能出现的全局变量冲突的问题 在JavaScript发展的过程中,其中的ES6带…...

WordPress网站添加嵌入B站视频,自适应屏幕大小,取消自动播放
结合bv号 改成以下嵌入式代码(自适应屏幕大小,取消自动播放) <iframe style"width: 100%; aspect-ratio: 16/9;" src"//player.bilibili.com/player.html?isOutsidetrue&bvidBV13CSVYREpr&p1&autoplay0" scrolling…...

Cortex-M3/M4处理器模式判断与调试技巧
1. Cortex-M3/M4处理器模式判断原理在嵌入式开发中,理解Cortex-M3和Cortex-M4处理器的运行模式对调试和异常处理至关重要。这两种处理器架构都采用了两级特权等级和两种执行模式的组合设计:特权等级(Privilege Level):…...

UDS_自动化脚本生成_10服务_V01
1、原子元素 1.1 会话原子 Session.Default() Session.Extended() Session.Programming() Session.Developer() 1.2 请求原子 10 01 10 02 10 03 10 76 10 81 10 82 10 83 10 F6 10 04 10 84 10 / 10 01 00 / 10 02 00 / 10 03 00 / 10 76 00 1.3 响应原子 50 01 00 32 01 F4 …...
)
Klogg实战:5分钟搞定海量日志中的Error排查(颜色标记+正则过滤技巧)
Klogg实战:5分钟搞定海量日志中的Error排查(颜色标记正则过滤技巧) 日志分析是每个开发者、测试和运维人员日常工作中不可或缺的一部分。面对动辄几个GB的日志文件,如何快速定位到关键的error信息,往往决定了问题解决的…...

SAR ADC工作原理、设计挑战与工程实践全解析
1. 项目概述:从“快枪手”到“精算师”的转换艺术在模拟信号与数字世界之间架起桥梁,是ADC(模数转换器)的核心使命。而在众多ADC架构中,SAR ADC(逐次逼近寄存器型模数转换器)因其独特的“二分搜…...

Office技巧速成:3个让效率翻倍的实用方法
表格操作总出错怎么办众多人于运用Excel开展数据处理工作之际,时常会被合并单元格以及公式报错等情形搞得疲惫不堪,焦头烂额。实际上,要是认真细细探究一番,便会发觉,大部分这类问题均是起因于对 Excel 基本功能欠缺熟…...

西安家谱企业服务商
如果你还认为家谱印刷只是老年市场的“老古董”,那你就错得离谱了。2024年,中国家谱印刷市场规模已突破58亿元,年复合增长率达21.3%,远超普通印刷行业。这背后,是新一代家庭对姓氏文化、家族记忆的数字化与实体化需求爆…...

harmonyos-ai-skill:让 Cursor 按 ArkTS 规范写鸿蒙,不再瞎编 API
端侧 Kit、MCP 接线都写过之后,写代码的人仍会遇到:Cursor 生成「像 React 的 ArkTS」、编造不存在的 Kit 名。社区项目 harmonyos-ai-skill 用可安装知识包,把 API 11 / DevEco 6 约束塞进 AI 工具链。 1. 问题:通用大模型不懂你…...

C#从零开始学习笔记---第九天
又是新的一天,欢迎大家继续查看我的学习笔记,这两天确实状态一般,今天内容我们也不记录太多,主要分为两大块,第一块是对之前提到过的数组进行一个复习,第二块就是在记录一下集合和哈希表的一些内容。话不多…...
)
从零开发游戏需要学习的c#模块,第二十章(2D 敌人与战斗触发)
本节课我们要学习的内容在地图上随机生成红色敌人玩家碰到敌人后,进入战斗模式战斗胜利后敌人消失,获得分数屏幕显示敌人数量using Microsoft.Xna.Framework; using Microsoft.Xna.Framework.Graphics; using Microsoft.Xna.Framework.Input; using Syst…...

千问 LeetCode 2561. 重排水果 Python3实现
这道题的核心是贪心 利用全局最小值做中介交换。下面给出Python3实现,附带详细注释。from typing import List from collections import Counterclass Solution:def minCost(self, basket1: List[int], basket2: List[int]) -> int:# 1. 统计每个水果在两个篮子…...