Redis学习:BitMap/HyperLogLog/GEO案例 、布隆过滤器BloomFilter、缓存预热+缓存雪崩+缓存击穿+缓存穿透
Redis学习
文章目录
- Redis学习
- 1、BitMap/HyperLogLog/GEO案例
- 2. 布隆过滤器BloomFilter
- 3. 缓存预热+缓存雪崩+缓存击穿+缓存穿透
1、BitMap/HyperLogLog/GEO案例
-
真实需求+面试题
- 亿级数据的收集+清洗+统计+展现
- 对集合中数据进行统计,基数统计,二值统计,排序统计
![,![[PastedImage/Pasted image 20241031072313.png]]![[PastedImage/Pasted image 20241031072517.png]]](https://i-blog.csdnimg.cn/direct/6ef728927d864bbcb236ff2119597288.png)
-
亿级数据统计的类型
- 聚合统计:对SET进行交并差运算
-
对多个集合SET进行交并差等集合运算
![![[PastedImage/Pasted image 20241031072840.png]]![[PastedImage/Pasted image 20241031072853.png]]](https://i-blog.csdnimg.cn/direct/f63270bc34b14d278e58058ad4c71a5a.png)
-
共同好友、猜你喜欢。。。
-
- 排序统计:使用ZSET对数据排序并分页展示
- 可以使用ZSET对数据进行排序并分页展示
- 对评论根据时间进行排序
- 二值统计:使用bitmap存储二值0/1
- 如使用二值记录是否签到等
- 基数统计:统计集合中不重复的元素个数,使用HyperLogLog
- 基数就是去除重复后的数的个数
- HyperLogLog不存储数据,只记录不重复数的个数,HyperLogLog有误差,在0.8125%
- 聚合统计:对SET进行交并差运算
-
HyperLogLog:基数统计
- 常见名词:UV、PV、DAU、MAU
- UV(Unique Visitor):独立访客,一般为客户端IP,要去重
- PV(Page View):页面浏览量,不用去重
- DAU(Daily Active User):日活跃用户量,当天登录或者使用某个产品的用户数,要去掉重复登录的用户,多次登录只记录一次
- MAU(Monthly Active User):月活跃用户
- 需求:只统计巨量数据,不考虑统计对象的内容和精确性,只统计不重复元素个数,不考虑内容和精确性
- HyperLogLog基数统计
- 基数统计就是统计集合去重后的元素个数,只统计个数
- 基数是集合中所有元素去重后的数量,HyperLogLog就是用于基数统计,只统计巨量数据,不考虑内容和精确性
- HyperLogLog只使用12KB就可以计算 2^ 64 个元素的基数(去重后元素个数),使用16384* 6bit就可以对2^64 个元素进行去重统计,共12kB就可以,底层基于伯努利实验
- HyperLogLog只统计输入元素的基数,不会存储数据本身,不会返回输入的元素,只统计不重复元素的个数,可以添加数据,但不可以取出数据,也可以合并两个集合,得到两个集合合并后去重后基数
- 命令
- HyperLogLog只记录key中所有元素去重后的个数,添加元素后不可以再取元素,只可以查看当前集合的基数
- HyperLogLog原理
- 去重复统计方式
- Java可以使用HashSet去重复,然后返回个数就是去重后的元素个数,但会存储元素本身,占用内存过大,HyperLogLog不需要记录元素本身,只统计不重复元素的个数
- 也可以使用bitmap,对每个元素均对应一位bit标记,但当基数过大时,仍会占用过多的空间,是精确计算的,但要计算唯一映射
- HyperLogLog使用12KB就可以大致统计 2^ 64 个元素的基数,但不会非常精确,只可以大致估计,故适用于只考虑基数,不考虑内容和精确性,有0.8125%的误差,是概率算法
- HyperLogLog是概率算法,通过牺牲准确性来换取空间,不要钱绝对准确性,不存储数据本身,可以大大减少内存占用,但不会准确
- 原理:概率算法(有误差0.8125%)
- HyperLogLog只进行不精确的基数统计,牺牲精确率来换取空间,不是集合也不会保存数据,只大致记录数量,**有误差!!!0.8125% **
- 底层原理使用了伯努利实验,n次伯努利实验中,每次记录第一次遇到正面向上的次数k,则n次中最大的k_max与n存在一定的关系,但有很大误差
- 所以要进行优化改进误差,可以多进行几轮n次实验,每轮得到这n次的最大k_max,然后hyperLogLog取这几轮k_max的调和平均数(倒数平均数的倒数),然后用多轮k_max的调和平均数来估计n,HyperLogLog就是根据数据前14位分为了16384轮,每轮用6位记录当前轮内数据后50位第一个1出现的最大位置(故使用6位就可以记录),此时对每轮的k_max求调和平均数来估计集合元素的基数,故共使用16384 * 6 = 12KB 就可以对 2^ 64 个数据进行基数统计
- HyperLogLog就是使用了该原理,对于每个元素可以看做64位,然后根据前14位分为16384轮,在每轮中只记录后50位的最大k_max(使用6位就可以记录当前轮中所有元素第一个1在50位中出现的位置),然后求每轮第一个1出现位置的调和平均数,再来估计基数
- 因为共16384个桶(轮),每个桶里要6位来存放后50位中第一个1的位置,故共需要(16384 * 6)/8=12KB的数据就可以对 2^64 个元素进行基数统计
- 因为使用的是概率算法,故会有一定的误差,在**0.8125%**左右
- 去重复统计方式
- 亿级UV的Redis统计方案:使用HyperLogLog对IP去重
- 需求:UV是独立访客,一般是客户端IP,要去重,只保存大致数量即可,故可以使用hyperloglog来基数统计
- 方案
- MySQL、Redis的HSET(存放的字符串)
- HyperLogLog:不精确的技术统计,使用12KB就可以统计 2^64 个元素的基数
- 常见名词:UV、PV、DAU、MAU
-
GEO:地理坐标系统
-
面试题
- 要使用MySQL存放位置的经纬度,然后用Redis的GEO数据类型对位置进行处理
- MySQL存放的是二维平面,难以计算半径的圆形覆盖
-
经纬度
- 东西经,南北纬,通过地图获得经纬度
- 使用经纬度可以唯一确定在地图中的一个位置,使用经纬度可以将球面转换为平面
-
GEO命令:
- GEO底层使用的是ZSET,用位置的经纬度作为score,向GEO中添加经纬度位置,计算两个位置的距离、求所有距离指定经纬度一定范围的位置(以半径圆形式)、将经纬度转换为hash编码一维
- GEODIST key value1 value2 单位:返回指定key中两个位置的距离,以指定的单位返回
- GEORADIUS BYMEMBER,以给定的经纬度或者位置为中心,返回指定半径内的元素或者按照距离顺序返回全部元素
- GEOHASH key 位置:可以将位置的经纬度转换为一维hash编码![[PastedImage/Pasted image 20241031090428.png]]
- GEO底层是ZSET类型,通过经纬度来对元素进行打分,bitmap是string类型
- GEOADD key 经度 纬度 value

-
美团地图附近酒店推送GEO
- 美团查找酒店,按照位置距离:先获得当前位置的经纬度,然后在酒店的GEO集合中通过GEORADIUS指令查找距离当前位置经纬度指定距离范围内的所有酒店位置信息:GEORADIUS hotels 当前位置经纬度 距离
-
-
Bitmap:二值统计
-
面试题
- 对于二值统计要使用bitmap进行统计

- 对于二值统计要使用bitmap进行统计
-
Bitmap
- BitMap底层使用string数据类型,GEO底层使用ZSET类型
- 二进制数组,用string类型作为底层数据结构实现的统计二值状态的数组,支持的最大位数是2^32 位
- 用于二值状态统计,二值状态统计
- bitmap偏移量从0开始计算!
-
京东用户签到记录,二值统计要用bit统计一位
- 不可以使用MySQL每次签到添加一条记录,会占用大量空间,可以使用一个int32位表示一个月的签到数量,每一位代表一天
- 基于bitmap二进制数组实现签到日历,用一个二进制bit位代表一天的签到状态
-
bitmap也可以实现布隆过滤器
- 用bitmap实现布隆过滤器,在海量数据中快速查找某个数据是否存在,用一个bit数组和几个哈希函数进行实现,因为哈希冲突,所有会存在误判率,但有一个为0则一定不存在,全为1时不一定存在,可以用来处理缓存穿透(刚开始Redis和MySQL都没有数据,此时访问会直接打到MySQL造成缓存穿透,使用空缓存设置缺省值和布隆过滤器来解决(Guava过滤器:与Redis解耦合且可以自定义fpp误判率,默认0.03,且越小越精确,但会占用大量的bit数组和多个hash函数))
- 布隆过滤器底层使用一个初值全为0的bit数组和多个hash函数,每次查找时,先将key根据hash函数映射到某个位置,判断是否为0,为0说明该数据不存在,直接返回,可以添加和快速查找元素是否存在,添加时先对key经过所有的hash并对长度取模得到多个位置并对每个位置设置为1,然后查询时仍是得到多个位置,只要有一个为0,则该key不存在,全为1时也不一定存在,因为存在哈希冲突,此时要去Redis中查找,可能会存在缓存穿透(Redis和MySQL都不存在,但请求仍然进行),但不可避免
-
2. 布隆过滤器BloomFilter
-
面试题:在海量数据中判断某个元素是否存在
-
在海量数据中判断某个元素是否存在,会存在误判:将不存在的数据判断为存在
-
在海量数据中判断某些数据是否存在;黑白名单校验

-
黑名单的使用,防止重复推荐视频,将推送过得加入黑名单中,此时会存在误判,将未推荐过的也看做黑名单,误判就是将不存在的判断为存在
![![[Pasted image 20241031203318.png]]](https://i-blog.csdnimg.cn/direct/4a1abccdb26443e6a4885b63370b8f30.png)
-
-
布隆过滤器
- 让一个数据key经过多个哈希函数进行映射,对映射的bit位进行标记,由此记录这个数据已经存在,再次访问时可以查找
- 快速判断海量数据中是否存在某个数据,由一个初值为0的bit数组和多个哈希函数构成,海量数据时有缺陷,因为哈希函数有冲突,会存在误判,将一个不存在的数据判断为存在,是一个类似于set(数组+链表+红黑树)的数据结构
- 由一个初值都为0的bit数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素
- 本质就是判断具体数据是否存在于一个大的集合中,就是将key映射到bit数组中进行标记,下次再看这个key是否在数组中,如果在则一定存在,会存在误判,误判就是不存在的判断为存在
- 使用bit数组是为了减少内存占用,不保存数据,只是做一个标记,使用bit数组来标记是否存在,不保存数据,判断时不存在就是不存在,会存在误判将不存在的误判为存在
- 布隆过滤器bloomfilter就是用一个初值全为0的数组以及几个哈希函数,将数据先通过哈希函数映射到对应的bit位,由bit位的状态来判断是否存在,不保存数据,只判断是否存在
-
特点:有不一定有,无则一定无
- 有是可能有,无则一定无,不存在一定不存在,存在的可能是映射相同导致误判,误判就是将不存在的误判为存在的,故存在不一定存在,要去Redis中查找,可能会缓存穿透:两者都不存在
- 只可以添加和查找,占用空间少,但存在不确定性,添加数据key就是标记该数据的key存在,查找时就是看该数据key是否存在
- 能够高效的添加和查询,占用空间少,但返回的结果是不确定的,存在误判,将不存在的误判为存在
- 底层使用bitmap数组,不保存数据信息,只是做一个是否存在的标记,用一些列哈希函数映射到bit数组中,可能出现哈希冲突,多个数据映射到一个bit位上,存在误判,不可以删除元素,会导致误判率提高
- 结果:存在时,元素不一定存在,不存在时,元素一定不存在
- 布隆过滤器可以添加元素,但不能删除元素,删掉元素会增加误判率
-
底层原理和数据结构
-
布隆过滤器是快速判断大量数据中某些元素是否存在,而HyperLogLog是基数统计,统计大量数据中去重后的元素个数
-
实质就是一个大型bitmap二进制数组和几个不同的无偏hash函数(无偏表示分布均匀),用于快速判断某个元素是否存在

-
布隆过滤器只是快速判断某个元素是否存在,HyperLogLog是基数统计,统计去重后的数据个数

-
添加key、查询key,不可以删除
- 添加key时会使用多个hash函数对key进行hash运算得到索引值,然后对bit数组取模得到位置,每个hash函数都会得到一个不同的位置,将该key对应的所有位置全部取1就完成了add操作,查询时必须全为1时才会认为存在,而且此时也不一定存在,只要有一个为0则一定不存在,误判率越低,bit数组越大,hash函数越多
- 查询key时,仍是先由hash函数得到所有的索引值,只要有一个不为1则说明不存在,只要有一个位置为0则不存在,当全为1时也不一定存在
-
哈希冲突导致数据不精准,全为1时也不一定存在,且不可以随便删除key,会导致别的key的映射也被删除,当**多个key通过hash函数后映射的位置相同时就会出现哈希冲突,**故要使用多个哈希函数来尽可能避免哈希冲突
-
哈希冲突是不可避免的(不同的key映射的位置相同),就算哈希值不一样,但要对bit数组取模,也会造成冲突,故不可以随便删除某个key,因为可能存在冲突导致别的key也会被删除而被认为不存在
-
可以在Redis和MySQL之前加一层布隆过滤器,先判断是否存在,不存在时直接返回null,从而避免缓存穿透,当缓存没有时,先判断MySQL中是否存在,如果不存在则不用访问MySQL了,此时就可以避免缓存穿透(刚开始Redis和MySQL都没有才是缓存穿透)

-
-
使用3步骤
- 初始化bitmap,在Redis中创建一个bitmap类型的key即可
- 初值全为0的bit数组
- 添加元素:对每个key求hash值后取模,然后对bitmap对应设置为1
- 为了尽可能避免哈希冲突,所以使用多个哈希函数对key进行映射,然后对数组长度进行取模,把所有位置全部设置为1 ![[Pasted image 20241031132526.png]]
- 判断是否存在,对key求hash值取模后看bit位置是否为1,为0一定不存在,为1一定存在
- 对于要判断的key也进行多个hash映射并取模,然后判断指定位置是否为1,只要有一个为0则一定不存在(不为0一定不存在),全为1时也不一定存在(可能有哈希冲突导致)
- 初始化bitmap,在Redis中创建一个bitmap类型的key即可
-
小总结
- 不要轻易删除key,因为多个key映射的位置可能相同,如果删除一个,可能导致本来存在的也会被认为不存在,因为存在哈希冲突,可能添加的两个元素占一个坑位,此时如果删除其中一个则另一个的该坑位也为0,也会被认为删除,就会导致误判率增加,故不要轻易删除key
- 全为1不一定存在,有一个0则一定不存在,误判就是把不存在的(0)认为存在(1)
- 使用时要尽可能使得初始bit数组足够大,不要后续扩容,后续要进行重建
- 当bitmap过小时,要进行重建,重新创建一个更大的bitmap,然后将数据重新加入
- 当实际元素过大时,远远大于初始数组,则必须对布隆过滤器重建,否则误判率会非常大,此时重新分配一个更大的bit数组,然后将原来的元素重新添加进入,再继续判断
![![[Pasted image 20241031133329.png]]](https://i-blog.csdnimg.cn/direct/c0fb6fcbcbd941e083ff8c94a4793cbc.png)
-
使用场景
- 解决缓存穿透问题,和Redis结合bitmap使用,
- 缓存穿透是指刚开始Redis和MySQL都不存在,则会直接请求MySQL,使用布隆过滤器在Redis之前将不存在的数据直接过滤掉,但可能存在误判,使得不存在被认为存在,仍然会存在缓存穿透
- 缓存穿透
- 可以在Redis前加一个布隆过滤器,并将数据库中存在的key加入布隆过滤器,查询前先判断是否存在,没有则一定不存咋直接返回,有则不一定存在,再去缓存中查找,找不到再去MySQL
- 黑名单校验,识别垃圾邮件
- 在布隆过滤器中存放黑名单的地址,没有则一定是白名单,有则不一定是黑名单
- 安全连接网址,网址判断
- 解决缓存穿透问题,和Redis结合bitmap使用,
-
手写布隆过滤器(简历加分)
- 整体架构
- 在Redis前加一个布隆过滤器,每次查询前先查询布隆过滤器是否存在,不存在则一定不存在,存在则不一定存在,此时再去Redis中查找
- 布隆过滤器实现:先构建二进制bit数组,初值全为0,然后对每个key分别求各个hash函数的值并取模,然后对指定位置设置为1
- 查找元素时,还是先求出各个位置,有一个为0则一定不存在,全为1时不一定存在,再去Redis中查找
- 大大避免了缓存穿透,只有误判时才会出现缓存传统
- 必须设置初始数组的长度足够大,否则全为1时就没有作用了
- 设计步骤
- 先在Redis中创建一个bitmap类型的key表示bloomfilter,每次Java客户端向Redis读取数据时(双检加锁(可以避免缓存击穿)),先计算数据key所对应的hash值,然后去bloomfilter中获得指定位置的元素,如果为0则一定不存在,如果为1则不一定存在,就去Redis中查找指定的key,从而实现布隆过滤器,当添加一个key时,仍是先计算key的hash,然后将布隆过滤器指定的位置设置为1,然后再添加进入Redis中(先更新数据库再删除缓存)
- 实现
- SpringBoot+Redis+MyBatis案例基础与一键编码环境整合
- mybatis一键生成:
- 通用Mapper4,要在使用的springboot微服务中引入Mapper4的依赖!!!并创建配置文件生成对应的Entity和mapper
- mybatis-generator
- 搭建SpringBoot微服务
- 建项目
- 改POM:要引入通用Mapper4的依赖
- 写YML:MyBatis和数据库的配置
- 主启动:要在主启动类上加上扫描包的注解
- 业务类:entity、mapper、mapper.xml、service接口和实现类、controller
- 在业务类中分别访问Redis和MySQL,使用RedisTemplate访问Redis,使用mapper访问MyBatis操作数据库
- 在service中编写对Redis和MySQL的操作,要分别调用Redis和MySQL
- 使用RedisTemplate来访问Redis,使用mapper实现类来通过MyBatis访问MySQL
- 查询时Redis不存在MySQL存在时要回写进入Redis,更新时先更新数据库再删除缓存,此时不更新Redis,因为如果更新会存在最终数据不一致
- 新增bloomFilter
- bitmap实质是string类型的,但用来存放bit二进制数组
- 使用@PostContruct注解标注布隆过滤器初始化函数,则启动微服务时就会自动初始化布隆过滤器,其功能是在Redis中创建一个bitmap,然后添加一些白名单,先计算hash值,然后对bitmap指定位置设置为1,当查找数据时,先计算hash值,然后查找bitmap对应位置是否为1,为0则一定不存在,为1则不一定存在
- 因为布隆过滤器是使用Redis的bitmap二进制数组进行实现,而且要加在Redis之前
- 每次查询数据时,先计算当前key的hash值,然后使用RedisTemplate去Redis查找布隆过滤器所在的key查看指定的位置是否为1,如果为0则一定不存在,直接返回null,为1时再去Redis中查找指定的key
- 添加数据时,仍是先计算key的hash,然后将Redis中布隆过滤器所在的key的指定位置设置为1,然后再添加数据,使用先更新数据库再更新缓存就可以,就算缓存不存在也可以使用双检加锁来防止大量数据达到MySQL
- 测试
- bloomfilter是利用Redis的bitmap数组实现的,每次访问数据时先访问bloomfilter,使用getbit查看指定key对应的hash位置是否存在,如果不存在则说明一定不在Redis中,直接返回,如果存在不一定在Redis中,要去Redis中查找
- 如果为0则一定不存在,直接返回,如果为1,因为存在哈希冲突,故不一定是该key的标识,故可能不存在
- mybatis一键生成:
- SpringBoot+Redis+MyBatis案例基础与一键编码环境整合
- 整体架构
-
优缺点
- 优点:可以高效的插入和查找,不存放具体的数据,内存占用bit空间少
- 只需要在Redis中配置一个bitmap数组,然后对每个key计算hash后在指定位置进行标记,不是存放具体的内容,而是对key的hash值进行标记标识已经存在
- 缺点:存在哈希冲突,不可以删除key,否则误判率会变大;当数据量很大时要加大bitmap的长度,不够时要重建
-
布谷鸟过滤器:优于布隆过滤器
1. 布隆过滤器虽然存在误判,但是够用了
2. 为0一定不存在,为1不一定存在
3. 缓存预热+缓存雪崩+缓存击穿+缓存穿透
-
面试题
- 缓存预热是将MySQL中有但Redis中没有的数据加载到Redis中,可以不操作当访问Redis没有时再加载,也可以使用中间件canal或者程序初始化Redis;缓存雪崩指Redis突然宕机或者大面积key失效,可以使用主从复制+哨兵或者集群来提高高可用,使用永不过期或者本地缓存;缓存穿透是指一开始Redis和MySQL都没有数据key时对key进行访问,可以使用第一次穿透后设置缺省值或者使用布隆过滤器实现不存在时直接过滤,但可能存在误判(不存在的误判为存在的)导致仍出现缓存穿透;缓存击穿指刚开始都正常,Redis和MySQL都存在数据key,但突然Redis的热点key过期,导致大量请求到达MySQL,可以使用永不过期或者双检加锁来预防。
- 缓存穿透和缓存击穿截然不同
- 预热、雪崩、穿透、击穿是四种不同的
![![[Pasted image 20241031193153.png]]](https://i-blog.csdnimg.cn/direct/c61463fe864946f19aaaa87f0d978736.png)
-
缓存预热
- 缓存预热就是当MySQL中有数据但Redis中没有数据时,要先把数据加载进入Redis中
- 当MySQL数据库存在新的数据但Redis没有时
- 此时可以什么也不做,当访问数据Redis没有时再访问MySQL,然后将数据回写进入Redis,会导致第一个用户体验不佳
- 故可以进行缓存预热,由中间件或者程序自动将MySQL中的数据同步到Redis中,此时就不会第一次还要访问MySQL进行回写
- 可以使用canal中间件实现,也可以使用@PostContruct注解来标注初始化函数来对布隆过滤器添加白名单数据
-
缓存雪崩
- 有两种:Redis直接宕机(硬件)、Redis大量的key同时失效(软件)
- 预防+解决
- 对于软件多key同时失效,可以设置key永不过期,或者过期时间错开
- 对于硬件Redis宕机,可以**使用主从复制+哨兵或者集群实现高可用
- 也可以在用户客户端添加一个本地缓存,使得不用再去Redis中查找
- 也可以服务降级fallback,不让用户进行访问,返回一个友好的错误界面
- 或者使用阿里云Redis集群一劳永逸!

-
缓存穿透:Redis和MySQL均不存在
- 缓存穿透就是指Redis和MySQL查询数据都不存在,此时就是缓存穿透,查询都不存在,但会对MySQL进行查询,故要设置bloomfilter过滤不存在的数据,但可能会存在误判仍会出现缓存穿透
- 查询数据时Redis和MySQL都不存在但都进行了查询,每次都会查询数据库导致数据库压力暴增,Redis成了摆设,就是对于不存在的数据进行了查询导致数据库被多次访问
- 偶尔一次缓存穿透是不可避免的,而且也无所谓,但如果存在恶意攻击则数据库会直接宕机
- 解决:空对象缓存缺省值+Guava-bloomfilter
- 当Redis和MySQL都不存在时会造成缓存穿透,可能会被黑客恶意攻击,故可以当出现后回写一个缺省值来保证当前key不会再出现缓存穿透,也可以设置bloomfilter直接拒绝不存在的key的访问,但会出现误判从而缓存穿透
- 空对象缓存或者缺省值(第一次缓存穿透后回写一个缺省值,只可以防止相同key的缓存穿透)
- 增强回写:第一次发生缓存穿透时,MySQL也没有数据,将key回写一个缺省值存入Redis中,此时再访问就不会去访问MySQL,但只可以解决key相同的缓存穿透
- 对于key不同的缓存穿透,增强回写(第一次缓存穿透后回写一个缺省值)是无效的,而且会使得垃圾的key(value为缺省值)越写越多,可以设置一个过期时间很短的key并设置缺省值
- Google的Guava过滤器(bloomfilter)(为0时一定不存在,不会访问Redis和MySQL数据库)
- bloomfilter也会存在误判,因为哈希冲突导致两个key映射到同一个位置,此时一个存在则另一个即使不存在也会存在,就出现了误判,但误判率很低,可以通过加大bit数组以及多个hash函数来降低误判,且不要删除key,否则误判率会更大
- Guava过滤器(与Redis解耦合)实战
- Guava可以自定义误判率fpp(默认fpp是0.03),但会根据fpp以及样本数来设置hash函数的个数以及底层bit数组的长度,当设置的fpp越小时,越精确,但所需要的hash函数个数以及bit数组长度就越大
- Guava过滤器不需要与Redis进行交互,之前的bloomfilter就是Redis中的一个bitmap类型的key,需要与Redis进行交互,而Guava不需要与Redis进行交互,直接在客户端进行创建即可,Guava不需要与Redis交互,解耦合,之前的bloomfilter要在Redis中进行实现,而且要访问Redis才能查看是否存在
-
缓存击穿:Redis热点key突然无效
- 缓存击穿(Redis的key突然失效) != 缓存穿透(Redis和MySQL都不存在)
- 热点key突然失效了,导致大量请求打向MySQL
- 缓存穿透是Redis和MySQL都不存在数据key,导致访问MySQL,但缓存击穿是Redis的热点key突然失效,导致全部访问MySQL,此时MySQL中有数据
- 缓存穿透是从头到尾Redis和MySQL都没有该数据key,而缓存击穿是刚开始正常,Redis和MySQL都有数据key,但突然Redis的key失效
- 缓存预热是将MySQL中的数据提前加载到Redis中;缓存雪崩是Redis突然宕机或者大面积的key失效或不可用
- 缓存击穿会导致MySQL数据库请求量过大,压力暴增
- 预防和解决:永不过期、双检加锁
- 预防和解决Redis的热点key突然失效,如过期时间到了或者刚刚del的key又被访问
- 差异失效时间:对于热点key设置永不过期
- 互斥更新:采用双检加锁策略来读取key,此时就可保证当key失效时只访问一次MySQL就读取到了数据
- 缓存击穿(Redis的key突然失效) != 缓存穿透(Redis和MySQL都不存在)
相关文章:
Redis学习:BitMap/HyperLogLog/GEO案例 、布隆过滤器BloomFilter、缓存预热+缓存雪崩+缓存击穿+缓存穿透
Redis学习 文章目录 Redis学习1、BitMap/HyperLogLog/GEO案例2. 布隆过滤器BloomFilter3. 缓存预热缓存雪崩缓存击穿缓存穿透 1、BitMap/HyperLogLog/GEO案例 真实需求面试题 亿级数据的收集清洗统计展现对集合中数据进行统计,基数统计,二值统计…...

Lua数据类型
Lua 语言 数据类型 Lua 有以下数据类型: nil:表示一个无效值,相当于 NULL。boolean:true 或 false。number:整数或浮点数。string:字符串。function:函数。userdata:用户数据。th…...

CSS中的背景色和前景色
目录 1 对比度的计算1.1 亮度计算1.2 对比度比率 2 在线计算对比度 在我们的样式设计中,通常会有背景色和前景色的概念。前景色我们通常用来设置文本的颜色,而背景色通常是文本的所在容器的颜色。比如如果我们把文本放在普通容器里,那普通容器…...
《复分析》与《实分析》教材)
伊莱亚斯 M. 斯坦恩(Elias M. Stein)《复分析》与《实分析》教材
分析学大师Elias M. Stein(曾是陶哲轩的老师),写了四本分析学系列教材,统称为普林斯顿分析学讲座(Princeton Lectures in Analysis)。他们分别是: I Fourier Analysis:An Introduct…...

UCLA、MIT数学家推翻39年经典数学猜想!AI证明卡在99.99%,人类最终证伪
39年来一个看似理所当然的数学理论,刚刚被数学家证伪!UCLA和MIT的研究者证实:概率论中众所周知的假设「上下铺猜想」是错的。有趣的是,他们用AI已经证明到了99.99%的程度,但最终,靠的还是理论论证。 又一个…...

大厂面试真题-很多系统会使用netty进行长连接,连接太多会有问题吗
使用Netty进行长连接时,机器数量过多确实可能会因为连接数量过多而引发问题。这些问题主要涉及系统资源消耗、连接管理、性能优化等方面。以下是对这些潜在问题的详细分析: 一、系统资源消耗 文件句柄限制: 在Linux等操作系统中,…...

Android RecyclerView ,使用ItemDecoration设置边距的大坑:左右边距不均匀/不同,已解决。
写在前面:最近有一个需求,在长宽固定的一块区域内,使用RecyclerView实现APP显示界面,考虑一下使用了网格布局GridLayoutManager,弄成5列的网格。设置边距的时候,使用ItemDecoration设置上、左边距。但是恶心的事情发生了,明明所有Item都设置了同样的左边距,但是只有第一…...

系统上云-流量分析和链路分析
优质博文:IT-BLOG-CN 一、流量分析 【1】流量组成: 按协议划分,流量链路可分为HTTP、SOTP、QUIC三类。 HTTPSOTPQUIC场景所有HTTP请求,无固定场景国内外APP等海外APP端链路选择DNS/CDN(当前特指Akamai)APP端保底IP列表/动态IP下…...

Apache 配置出错常见问题及解决方法
Apache 配置出错常见问题及解决方法 一、端口被占用问题 问题描述:在启动 Apache 时,出现“Address already in use”或类似的错误提示,这意味着 Apache 想要使用的端口已经被其他程序占用,导致 Apache 无法正常启动。原因分析: 系统中已经有其他的应用程序在使用 Apache…...

DGL库之dgl.function.u_mul_e(代替dgl.function.src_mul_edge)
DGL库之dgl.function.u_mul_e 语法格式例子 语法格式 dgl.function.u_mul_e代替了dgl.function.src_mul_edge dgl.function.u_mul_e(lhs_field, rhs_field, out)一个用于计算消息传递的内置函数,它通过对源节点(u)和边(e&#x…...

题目练习之二叉树那些事儿
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥ ♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥ ♥♥♥我们一起努力成为更好的自己~♥♥♥ ♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥ ♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥ 知道了二叉树的结…...

数字马力二面面试总结
24.03.07数字马力二面面试总结 前段时间找工作,做的一些面试笔记总结 大家有面试录音或者记录的也可以发给我,我来整理答案呀 数字马力二面面试总结 24.03.07数字马力二面面试总结你可以挑一个你的最有挑战性的,有难度的,最具有复杂性的项目,可以简单说一下。有没有和算…...

优化图片大小的方法
不能起到优化图片大小的方法有(C) A.减少每个像素点能够显示的颜色 B.减少像素点 C.使用ajax加载 D.使用WebP格式 C. 使用Ajax加载 Ajax是一种用于在网页中异步加载数据的技术,与图片大小的优化关系不大。它主要用于提高网页的加载效率&…...

DevOps-课堂笔记
各种 aaS 类比于计算机网络的 OSI 参考模型,一个软件应用项目需要不同的支撑层,例如从下至上大概需要: 硬件层面的服务器针对硬件做弹性分配的虚拟化机制,例如虚拟机在虚拟化环境内运行的 OS支撑软件应用的中间件,例…...

Redis - Hash 哈希
一、基本认识 ⼏乎所有的主流编程语⾔都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数 组、映射。在Redis中,哈希类型是指值本⾝⼜是⼀个键值对结构,形如key"key",value{{ field1, v…...
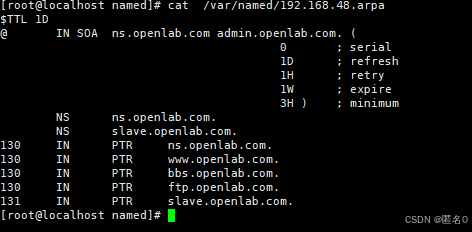
dns服务部署
配置主文件,编辑主配置文件设置监听IP , 重启服务:[rootlocalhost ~]# systemctl restart network 安装bind 主服务器IP信息: [rootlocalhost ~]# nmcli c modify ens160 ipv4.method manual ipv4.addresses 129.168.160.131/24…...

【Hadoop和Hbase集群配置】3台虚拟机、jdk+hadoop+hbase下载和安装、环境配置和集群测试
目录 一、环境 二、虚拟机配置 三、 JDK、Hadoop、HBase的安装和配置 【安装和配置JDK】 【安装和配置Hadoop】 【安装和配置Hbase】 四、 Hadoop和HBase集群测试 【Hadoop启动测试】 【Hbase启动测试】 一、环境 OS: CentOS-7 JDK: v1.8.0_131 Hadoop: v2.7.6 Hb…...

超萌!HTMLCSS:超萌卡通熊猫头
效果演示 创建了一个卡通风格的熊猫头 HTML <div class"box"><div class"head"><div class"head-copy"></div><div class"ears-left"></div><div class"ears-right"></di…...

人脑与机器连接:神经科技的伦理边界探讨
内容概要 在当今科技飞速发展的时代,人脑与机器连接已成为一个引人注目的前沿领域。在这一背景下,神经科技的探索为我们打开了一个全新的世界,从脑机接口到人工智能的飞跃应用,不仅加速了技术的进步,更触动了我们内心…...

Mac M1 Docker创建Rocketmq集群并接入Springboot项目
文章目录 前言Docker创建rocketmq集群创建rocketmq目录创建docker-compose.yml新增broker.conf文件启动容器 Springboot 接入 rocketmq配置maven依赖修改appplication.yml新增消息生产者新增消费者测试发送消息 总结 前言 最近公司给配置了一台mac,正好有时间给装一…...

不止于画图:用@antv/g6-editor的Command系统打造可撤销/重做的智能流程设计器
超越基础绘图:利用antv/g6-editor构建企业级智能流程设计器 在当今快速发展的数字化时代,流程设计工具已成为企业数字化转型的核心组件。从简单的审批流程到复杂的业务编排,一个功能完备的流程设计器不仅能提升工作效率,更能确保…...

玩转西门子S7-1200气力输送仿真系统
气力输送系统管道气力输送系统 (21)采用西门子S7-1200博图WinCC画面组态,博图V16及以上版本都可以仿真运行,无需硬件。 系统带有手动/自动模式,运行数据动态实时显示,带压力实时曲线显示&#x…...

FreeRTOS任务切换时,Cortex-M内核的PSP和MSP指针到底怎么变?一个动画讲清楚
FreeRTOS任务切换时Cortex-M内核PSP与MSP指针变化全解析 当你在调试一个嵌入式系统时,突然遇到栈溢出导致的崩溃,那种感觉就像在黑夜里摸索——你知道问题出在哪里,但就是看不清细节。作为一名嵌入式开发者,理解FreeRTOS在Cortex-…...

LabelImg图像标注工具:3分钟掌握高效目标检测数据标注技巧
LabelImg图像标注工具:3分钟掌握高效目标检测数据标注技巧 【免费下载链接】labelImg LabelImg is now part of the Label Studio community. The popular image annotation tool created by Tzutalin is no longer actively being developed, but you can check ou…...

别再为小程序合法域名发愁了!手把手教你用宝塔+FRP搞定内网穿透与HTTPS配置
微信小程序合法域名配置实战:从内网穿透到HTTPS全流程指南 当你兴致勃勃地开发完微信小程序的后端接口,准备在真机测试时,却遭遇"不在合法域名列表中"的报错——这种挫败感我深有体会。三年前我的第一个小程序项目就卡在这个环节整…...

解锁RO游戏自动化工具:从效率瓶颈到智能辅助的实践指南
解锁RO游戏自动化工具:从效率瓶颈到智能辅助的实践指南 【免费下载链接】openkore A free/open source client and automation tool for Ragnarok Online 项目地址: https://gitcode.com/gh_mirrors/op/openkore 在MMORPG游戏领域,重复刷怪、繁琐…...

TestNet资产管理平台:从安装到实战,全面超越灯塔的解决方案
1. TestNet资产管理平台:为什么你需要它? 如果你是一名网络安全工程师或者渗透测试人员,肯定对资产管理的繁琐深有体会。传统的资产管理工具要么功能单一,要么操作复杂,而TestNet资产管理系统的出现,彻底改…...

51单片机之按键控制RGB灯
51单片机之按键控制RGB灯描述:利用KEIL5编程,使AT89C52通过按键输入控制RGB灯显示不同颜色。硬件:电路仿真图(未运行)电路仿真图(运行)程序:主要是按键消抖,机械按键按下…...

【雷达信号优化】第八章 阵列校准与误差补偿
目录 第八章 阵列校准与误差补偿 8.1 阵列误差模型 8.1.1 幅相误差 8.1.1.1 互耦效应建模 8.1.1.1.1 互耦矩阵的逆矩阵简化 8.2 阵列自校准算法 8.2.1 信号子空间拟合算法 8.2.1.1 交替优化策略 8.2.1.1.1 信源方向与误差参数的迭代更新 8.2.2 辅助源校准 8.2.2.1 单…...

AML启动器:智能管理XCOM 2模组的一站式解决方案
AML启动器:智能管理XCOM 2模组的一站式解决方案 【免费下载链接】xcom2-launcher The Alternative Mod Launcher (AML) is a replacement for the default game launchers from XCOM 2 and XCOM Chimera Squad. 项目地址: https://gitcode.com/gh_mirrors/xc/xcom…...