深度学习-迁移学习
深度学习中的迁移学习是通过在大规模数据上训练的模型,将其知识迁移到数据相对较少的相关任务中,能显著提升目标任务的模型性能。
一、迁移学习的核心概念
-
源任务(Source Task)与目标任务(Target Task):
(1)源任务:通常拥有大量标注数据以及预训练好的模型,模型可以从中提取到通用特征。(2)目标任务:数据量相对有限,与源任务有相似性,但需要迁移模型知识适应特定的需求。 -
特征迁移:
(1)深度学习模型的层级结构有“自下而上”的特征表示,底层(如边缘、形状特征)更通用,高层特征(如复杂纹理、特定形状)更具体。(2)迁移学习通过保留底层特征,并微调高层特征以适应新任务。 -
微调与冻结:
(1)冻结:冻结模型底层权重,保留已学到的底层特征,适合用于不同数据但相似的任务。(2)微调:对高层权重进行少量训练,使其适应目标任务,适用于源、目标任务有一定关联的情况。 -
模型剪枝与特征选择:
(1)剪枝可以减少模型复杂度,提升推理速度,适合在特定硬件上优化迁移模型的性能。
二、迁移学习的策略及示意图
迁移学习主要有以下策略,每个策略适用于不同场景。
1. 特征提取策略(Feature Extraction)
- 使用预训练模型的卷积层作为固定的特征提取器,只在输出部分添加新的全连接层或分类层。
- 应用于源任务和目标任务相似度较高的情况(如图像分类任务)。
代码示例:
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Flatten# 加载预训练的 VGG16 模型,不包含顶层
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))# 将卷积层的权重冻结
for layer in base_model.layers:layer.trainable = False# 添加新的全连接层
x = Flatten()(base_model.output)
output = Dense(10, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=output)
2. 微调策略(Fine-tuning)
- 在预训练模型的基础上保留底层特征,微调高层特征,适应新的目标任务。适合在源任务和目标任务高度相似时使用。
代码示例:
# 微调部分卷积层
for layer in base_model.layers[:15]:layer.trainable = False
for layer in base_model.layers[15:]:layer.trainable = True
3. 跨领域迁移(Cross-domain Transfer)
- 针对不同领域任务的特征迁移策略,如图像到文本、语音到文本的跨领域迁移。需要添加或替换特定的适应层以完成不同领域的转换。
三、迁移学习的代码实现示例
以下代码展示了在 ImageNet 预训练的 VGG16 模型上,通过冻结部分卷积层并添加自定义全连接层,用于一个新的分类任务(如猫狗分类)。
import torch
import torch.nn as nn
import torchvision.models as models
from torchvision import datasets, transforms
from torch.utils.data import DataLoader# 1. 加载预训练的 VGG16 模型
vgg16 = models.vgg16(pretrained=True)# 2. 冻结前面的卷积层
for param in vgg16.features.parameters():param.requires_grad = False# 3. 修改分类器部分,适应猫狗二分类任务
# 获取 VGG16 的输入特征数,并替换最后一层为适合二分类的线性层
num_features = vgg16.classifier[6].in_features
vgg16.classifier[6] = nn.Linear(num_features, 2) # 2 classes for binary classification# 4. 定义训练参数
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
vgg16 = vgg16.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(vgg16.classifier[6].parameters(), lr=0.001) # 只更新最后一层参数# 5. 定义数据预处理和加载
data_transforms = {'train': transforms.Compose([transforms.Resize((224, 224)),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'val': transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}train_dataset = datasets.ImageFolder(root='data/train', transform=data_transforms['train'])
val_dataset = datasets.ImageFolder(root='data/val', transform=data_transforms['val'])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False)# 6. 训练模型
def train_model(model, criterion, optimizer, num_epochs=10):for epoch in range(num_epochs):model.train()running_loss = 0.0correct = 0for inputs, labels in train_loader:inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad()# 前向传播outputs = model(inputs)loss = criterion(outputs, labels)loss.backward()optimizer.step()# 统计损失和准确率running_loss += loss.item() * inputs.size(0)_, preds = torch.max(outputs, 1)correct += torch.sum(preds == labels)epoch_loss = running_loss / len(train_loader.dataset)epoch_acc = correct.double() / len(train_loader.dataset)print(f'Epoch {epoch}/{num_epochs - 1} - Loss: {epoch_loss:.4f}, Acc: {epoch_acc:.4f}')# 7. 调用训练函数
train_model(vgg16, criterion, optimizer, num_epochs=10)
冻结卷积层:使用
for param in vgg16.features.parameters(): param.requires_grad = False冻结了vgg16.features中的参数,使其在训练中不更新。修改分类层:更改
vgg16.classifier[6]中的最后一个线性层,使其适应二分类任务(猫狗分类)。数据预处理与加载:利用
transforms进行图像的标准化和尺寸调整,确保模型输入一致,加载后的数据放入DataLoader中便于批量处理。训练循环:在
train_model函数中进行批次训练,计算损失并更新模型参数。
四、迁移学习的实际应用场景
- 图像分类:用于医疗影像分析、卫星图像识别等。例如使用 ImageNet 预训练模型进行皮肤癌检测。
- 目标检测与分割:自动驾驶中的行人检测、视频监控中的异常事件检测等。
- 自然语言处理:在 BERT、GPT-3 等预训练模型基础上微调,以适应情感分析、文本分类等任务。
- 语音识别:预训练语音模型可用于语音情感识别、口音识别等任务。
五、迁移学习的优缺点
优点:
- 数据需求少:不需要大量标注数据,可以显著缩短模型开发时间。
- 训练高效:利用已有模型权重,减少训练时间。
- 泛化能力强:预训练模型在大数据上学到的特征更具普适性,提高目标任务的泛化能力。
缺点:
- 源任务与目标任务的相似性要求:源任务和目标任务若差异较大,迁移效果会明显下降。
- 存在偏差风险:源任务的偏差可能会迁移到目标任务中,对任务结果产生负面影响。
- 额外存储开销:需要存储源模型的权重,对计算和存储资源有额外要求。
六、迁移学习的注意事项
- 选择合适的源任务:尽量选择与目标任务具有相似特征的源任务模型。
- 调整学习率:微调时的学习率应小于源任务,避免过度改变预训练模型的特征。
- 慎重选择微调层数:微调的层数应考虑目标任务的复杂性,避免过拟合。
- 数据预处理保持一致:确保源任务和目标任务的数据预处理方式一致,否则会影响模型性能。
七、总结
迁移学习在深度学习应用中已成为提升模型训练效率和性能的关键技术,尤其在目标任务与源任务具有一定关联性、且标注数据有限的情况下效果尤为显著。迁移学习通过利用在大规模数据集(如 ImageNet)上预训练的模型知识,将其迁移到新任务中,减少了对大规模数据和计算资源的需求。不同的迁移学习策略(如特征提取、微调、参数冻结等)能够针对性地调整模型层级的学习参数,实现高效的模型适应性。深入理解和灵活应用这些策略是深度学习项目开发的重要技能,能够在分类、检测、分割、文本分析等领域中有效缩短训练周期,并在数据有限的情况下显著提升模型的泛化性能和准确性。
相关文章:

深度学习-迁移学习
深度学习中的迁移学习是通过在大规模数据上训练的模型,将其知识迁移到数据相对较少的相关任务中,能显著提升目标任务的模型性能。 一、迁移学习的核心概念 源任务(Source Task)与目标任务(Target Task)&…...

6.0、静态路由
路由器最主要的功能就是转发数据包。路由器转发数据包时需要查找路由表(你可以理解为地图),管理员可以直接手动配置路由表,这就是静态路由。 1.什么是路由? 在网络世界中,路由是指数据包在网络中的传输路…...

Redis学习:BitMap/HyperLogLog/GEO案例 、布隆过滤器BloomFilter、缓存预热+缓存雪崩+缓存击穿+缓存穿透
Redis学习 文章目录 Redis学习1、BitMap/HyperLogLog/GEO案例2. 布隆过滤器BloomFilter3. 缓存预热缓存雪崩缓存击穿缓存穿透 1、BitMap/HyperLogLog/GEO案例 真实需求面试题 亿级数据的收集清洗统计展现对集合中数据进行统计,基数统计,二值统计…...

Lua数据类型
Lua 语言 数据类型 Lua 有以下数据类型: nil:表示一个无效值,相当于 NULL。boolean:true 或 false。number:整数或浮点数。string:字符串。function:函数。userdata:用户数据。th…...

CSS中的背景色和前景色
目录 1 对比度的计算1.1 亮度计算1.2 对比度比率 2 在线计算对比度 在我们的样式设计中,通常会有背景色和前景色的概念。前景色我们通常用来设置文本的颜色,而背景色通常是文本的所在容器的颜色。比如如果我们把文本放在普通容器里,那普通容器…...
《复分析》与《实分析》教材)
伊莱亚斯 M. 斯坦恩(Elias M. Stein)《复分析》与《实分析》教材
分析学大师Elias M. Stein(曾是陶哲轩的老师),写了四本分析学系列教材,统称为普林斯顿分析学讲座(Princeton Lectures in Analysis)。他们分别是: I Fourier Analysis:An Introduct…...

UCLA、MIT数学家推翻39年经典数学猜想!AI证明卡在99.99%,人类最终证伪
39年来一个看似理所当然的数学理论,刚刚被数学家证伪!UCLA和MIT的研究者证实:概率论中众所周知的假设「上下铺猜想」是错的。有趣的是,他们用AI已经证明到了99.99%的程度,但最终,靠的还是理论论证。 又一个…...

大厂面试真题-很多系统会使用netty进行长连接,连接太多会有问题吗
使用Netty进行长连接时,机器数量过多确实可能会因为连接数量过多而引发问题。这些问题主要涉及系统资源消耗、连接管理、性能优化等方面。以下是对这些潜在问题的详细分析: 一、系统资源消耗 文件句柄限制: 在Linux等操作系统中,…...

Android RecyclerView ,使用ItemDecoration设置边距的大坑:左右边距不均匀/不同,已解决。
写在前面:最近有一个需求,在长宽固定的一块区域内,使用RecyclerView实现APP显示界面,考虑一下使用了网格布局GridLayoutManager,弄成5列的网格。设置边距的时候,使用ItemDecoration设置上、左边距。但是恶心的事情发生了,明明所有Item都设置了同样的左边距,但是只有第一…...

系统上云-流量分析和链路分析
优质博文:IT-BLOG-CN 一、流量分析 【1】流量组成: 按协议划分,流量链路可分为HTTP、SOTP、QUIC三类。 HTTPSOTPQUIC场景所有HTTP请求,无固定场景国内外APP等海外APP端链路选择DNS/CDN(当前特指Akamai)APP端保底IP列表/动态IP下…...

Apache 配置出错常见问题及解决方法
Apache 配置出错常见问题及解决方法 一、端口被占用问题 问题描述:在启动 Apache 时,出现“Address already in use”或类似的错误提示,这意味着 Apache 想要使用的端口已经被其他程序占用,导致 Apache 无法正常启动。原因分析: 系统中已经有其他的应用程序在使用 Apache…...

DGL库之dgl.function.u_mul_e(代替dgl.function.src_mul_edge)
DGL库之dgl.function.u_mul_e 语法格式例子 语法格式 dgl.function.u_mul_e代替了dgl.function.src_mul_edge dgl.function.u_mul_e(lhs_field, rhs_field, out)一个用于计算消息传递的内置函数,它通过对源节点(u)和边(e&#x…...

题目练习之二叉树那些事儿
♥♥♥~~~~~~欢迎光临知星小度博客空间~~~~~~♥♥♥ ♥♥♥零星地变得优秀~也能拼凑出星河~♥♥♥ ♥♥♥我们一起努力成为更好的自己~♥♥♥ ♥♥♥如果这一篇博客对你有帮助~别忘了点赞分享哦~♥♥♥ ♥♥♥如果有什么问题可以评论区留言或者私信我哦~♥♥♥ 知道了二叉树的结…...

数字马力二面面试总结
24.03.07数字马力二面面试总结 前段时间找工作,做的一些面试笔记总结 大家有面试录音或者记录的也可以发给我,我来整理答案呀 数字马力二面面试总结 24.03.07数字马力二面面试总结你可以挑一个你的最有挑战性的,有难度的,最具有复杂性的项目,可以简单说一下。有没有和算…...

优化图片大小的方法
不能起到优化图片大小的方法有(C) A.减少每个像素点能够显示的颜色 B.减少像素点 C.使用ajax加载 D.使用WebP格式 C. 使用Ajax加载 Ajax是一种用于在网页中异步加载数据的技术,与图片大小的优化关系不大。它主要用于提高网页的加载效率&…...

DevOps-课堂笔记
各种 aaS 类比于计算机网络的 OSI 参考模型,一个软件应用项目需要不同的支撑层,例如从下至上大概需要: 硬件层面的服务器针对硬件做弹性分配的虚拟化机制,例如虚拟机在虚拟化环境内运行的 OS支撑软件应用的中间件,例…...

Redis - Hash 哈希
一、基本认识 ⼏乎所有的主流编程语⾔都提供了哈希(hash)类型,它们的叫法可能是哈希、字典、关联数 组、映射。在Redis中,哈希类型是指值本⾝⼜是⼀个键值对结构,形如key"key",value{{ field1, v…...
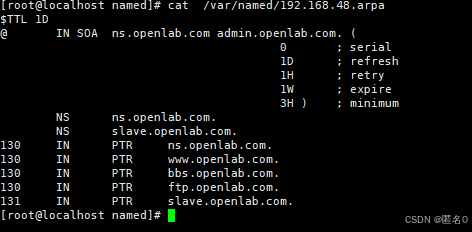
dns服务部署
配置主文件,编辑主配置文件设置监听IP , 重启服务:[rootlocalhost ~]# systemctl restart network 安装bind 主服务器IP信息: [rootlocalhost ~]# nmcli c modify ens160 ipv4.method manual ipv4.addresses 129.168.160.131/24…...

【Hadoop和Hbase集群配置】3台虚拟机、jdk+hadoop+hbase下载和安装、环境配置和集群测试
目录 一、环境 二、虚拟机配置 三、 JDK、Hadoop、HBase的安装和配置 【安装和配置JDK】 【安装和配置Hadoop】 【安装和配置Hbase】 四、 Hadoop和HBase集群测试 【Hadoop启动测试】 【Hbase启动测试】 一、环境 OS: CentOS-7 JDK: v1.8.0_131 Hadoop: v2.7.6 Hb…...

超萌!HTMLCSS:超萌卡通熊猫头
效果演示 创建了一个卡通风格的熊猫头 HTML <div class"box"><div class"head"><div class"head-copy"></div><div class"ears-left"></div><div class"ears-right"></di…...

电气工程优化调度Matlab代码优化与注释那些事儿
优化调度修改、注释、matlab代码,主要为但不限于电气工程优化调度相关方向 主要包括,但不限于: 1、在原有程序基础上替换算法; 2、修改优化调度程序yalmip求解器ipopt; 3、新买的代码没注释,可以注释并可以…...

如何使用usearch进行水资源分配优化:用水数据的向量分析完整指南
如何使用usearch进行水资源分配优化:用水数据的向量分析完整指南 【免费下载链接】usearch Fastest Open-Source Search & Clustering engine for Vectors & 🔜 Strings in C, C, Python, JavaScript, Rust, Java, Objective-C, Swift, C#, Go…...

实战调试:段页式内存管理中的首次页故障剖析
1. 段页式内存管理基础概念 段页式内存管理是现代操作系统的核心机制之一,它巧妙结合了分段和分页两种技术的优势。简单来说,就像我们整理衣柜时既按季节(分段)又用收纳盒(分页)来管理衣物。CPU看到的线性地…...

【MATLAB实战:从BCI Competition IV 2a数据加载到预处理全流程】
1. 初识BCI Competition IV 2a数据集 第一次接触脑机接口(BCI)研究时,最让人头疼的就是数据预处理。BCI Competition IV 2a数据集作为入门级黄金标准,包含了9名受试者的EEG数据,记录了左手、右手、双脚和舌头四种运动想…...

ColorControl开源显示调校工具:从新手到专家的HDR优化之路
ColorControl开源显示调校工具:从新手到专家的HDR优化之路 【免费下载链接】ColorControl Easily change NVIDIA display settings and/or control LG TVs 项目地址: https://gitcode.com/gh_mirrors/co/ColorControl 在数字显示技术快速发展的今天ÿ…...

【Serverless架构生死线】:Java函数冷启动超时率>17%?2024最新CNCF基准测试下的3层防御体系构建
第一章:Serverless架构下Java函数冷启动的生死挑战在Serverless平台(如AWS Lambda、阿里云函数计算、腾讯云SCF)中,Java函数因JVM初始化、类加载、字节码验证及Spring等框架启动开销,常面临数百毫秒至数秒级的冷启动延…...

Ostrakon-VL-8B开发资源:GitHub优秀开源项目与工具推荐
Ostrakon-VL-8B开发资源:GitHub优秀开源项目与工具推荐 如果你正在研究Ostrakon-VL-8B这个多模态大模型,想用它做点实际的东西,比如开发个智能点餐助手或者商品识别工具,那你来对地方了。自己从头开始搞,从环境搭建到…...

突破性网络资源嗅探解决方案:从技术困境到智能下载的革命性跨越
突破性网络资源嗅探解决方案:从技术困境到智能下载的革命性跨越 【免费下载链接】res-downloader 资源下载器、网络资源嗅探,支持微信视频号下载、网页抖音无水印下载、网页快手无水印视频下载、酷狗音乐下载等网络资源拦截下载! 项目地址: https://gi…...

Qwen2.5-7B LoRA微调入门:十分钟快速指南,轻松上手模型定制
Qwen2.5-7B LoRA微调入门:十分钟快速指南,轻松上手模型定制 1. 前言:为什么选择LoRA微调 在当今大模型技术快速发展的背景下,如何高效地对预训练模型进行定制化调整成为开发者面临的关键挑战。LoRA(Low-Rank Adaptat…...

OpenClaw自动化测试实践:GLM-4.7-Flash驱动脚本执行与结果分析
OpenClaw自动化测试实践:GLM-4.7-Flash驱动脚本执行与结果分析 1. 为什么选择OpenClaw做测试自动化? 上个月接手一个新项目时,我遇到了一个典型的技术矛盾:作为独立开发者,既需要保证代码质量,又没精力手…...