打造完整 Transformer 编码器:逐步实现高效深度学习模块
11. encoder
打造完整 Transformer 编码器:逐步实现高效深度学习模块
在深入理解了编码器块的核心结构后,下一步就是实现一个完整的 Transformer 编码器。该编码器将输入序列转换为高级语义向量,并为后续的解码或其他任务模块提供高质量的特征表示。今天我们将详细解析编码器的每一部分,并附上代码示例,助你轻松掌握 Transformer 的编码器构建。
Transformer 编码器的主要组成部分
一个完整的 Transformer 编码器通常包含以下几个步骤:
- 输入嵌入层(Embedding Layer):将输入的词索引转换为高维向量表示。
- 位置编码(Positional Encoding):为每个词加上位置信息,使模型能够捕捉词序关系。
- 多个编码器块(Encoder Blocks):编码器块堆叠以提取深层次特征,通常包括 6-12 层,视任务而定。
- 输出:编码器最终输出的特征向量,将传递给解码器或下游任务模块。
实现完整的 Transformer 编码器类
以下代码实现了一个 TransformerEncoder 类,其中包含输入嵌入、位置编码、多个编码器块和 Dropout 层:
import torch
import torch.nn as nn
import mathclass PositionalEncoding(nn.Module):def __init__(self, embed_size, max_length=100):super(PositionalEncoding, self).__init__()self.encoding = torch.zeros(max_length, embed_size)position = torch.arange(0, max_length, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, embed_size, 2).float() * (-math.log(10000.0) / embed_size))self.encoding[:, 0::2] = torch.sin(position * div_term)self.encoding[:, 1::2] = torch.cos(position * div_term)self.encoding = self.encoding.unsqueeze(0) # Shape: (1, max_length, embed_size)def forward(self, x):return x + self.encoding[:, :x.size(1), :].to(x.device)class TransformerEncoder(nn.Module):def __init__(self, src_vocab_size, embed_size, num_layers, heads, forward_expansion, dropout, max_length):super(TransformerEncoder, self).__init__()# 输入嵌入层self.word_embedding = nn.Embedding(src_vocab_size, embed_size)self.position_encoding = PositionalEncoding(embed_size, max_length)# 堆叠编码器层self.layers = nn.ModuleList([EncoderBlock(embed_size, heads, forward_expansion, dropout) for _ in range(num_layers)])# Dropout 层self.dropout = nn.Dropout(dropout)def forward(self, x, mask):# 1. 添加词嵌入和位置编码out = self.word_embedding(x)out = self.position_encoding(out)out = self.dropout(out)# 2. 逐层通过编码器块for layer in self.layers:out = layer(out, mask)return out代码解析:逐步了解 Transformer 编码器
1. 输入嵌入和位置编码
self.word_embedding = nn.Embedding(src_vocab_size, embed_size)
self.position_encoding = PositionalEncoding(embed_size, max_length)word_embedding:将输入的词(以整数索引表示)转换成嵌入向量。position_encoding:为每个词嵌入向量加上位置编码,帮助模型识别词的顺序。
2. 堆叠多个编码器块
self.layers = nn.ModuleList([EncoderBlock(embed_size, heads, forward_expansion, dropout) for _ in range(num_layers)]
)- 使用
ModuleList创建多个EncoderBlock。每个EncoderBlock包含多头自注意力层、前馈神经网络层、残差连接和正则化。 num_layers控制编码器块的数量。通常的设置是 6 层,但可以根据任务需求进行调整。
3. Dropout 层
self.dropout = nn.Dropout(dropout)- 使用 Dropout 增强泛化能力,通过随机丢弃一些神经元的输出来防止过拟合。
前向传播过程解析
-
词嵌入和位置编码
out = self.word_embedding(x) out = self.position_encoding(out) out = self.dropout(out)- 将输入序列转换为嵌入向量。
- 添加位置编码,保留输入序列的顺序信息。
- 使用 Dropout 防止过拟合。
-
通过编码器块层层提取特征
for layer in self.layers:out = layer(out, mask)- 将嵌入后的输出依次传递给每一个编码器块。
mask参数用于在注意力机制中屏蔽掉填充符(padding)等不相关部分,避免模型关注无关信息。
测试 Transformer 编码器
为了确保我们的编码器可以正常工作,编写一些简单的测试代码:
# 设置测试参数
src_vocab_size = 10000 # 假设词汇表大小
embed_size = 512
num_layers = 6
heads = 8
forward_expansion = 4
dropout = 0.1
max_length = 100
seq_length = 20
batch_size = 2# 输入序列
x = torch.randint(0, src_vocab_size, (batch_size, seq_length)) # (batch_size, seq_length)
mask = None # 暂不使用 mask# 实例化 Transformer 编码器并进行前向传播
encoder = TransformerEncoder(src_vocab_size, embed_size, num_layers, heads, forward_expansion, dropout, max_length)
out = encoder(x, mask)print("编码器的输出形状:", out.shape) # 预期输出: (batch_size, seq_length, embed_size)- 输出形状:
(batch_size, seq_length, embed_size),例如(2, 20, 512)。
接下来的步骤
- 实现解码器块(Decoder Block):
- 解码器块和编码器类似,但会增加编码器-解码器注意力层,用于从编码器的输出中提取信息。
- 实现完整的解码器(Decoder):
- 将多个解码器块堆叠,构成完整的解码器结构。
- 组装完整的 Transformer 模型:
- 结合编码器和解码器,实现完整的 Transformer 模型。
通过这篇文章,我们构建了一个完整的 Transformer 编码器,并了解了编码器的每个模块如何协同工作以提取输入序列的深层次特征。希望这些知识帮助你在 Transformer 的实现和理解上更进一步!如果你对解码器或 Transformer 其他部分感兴趣,欢迎继续阅读或留言讨论!
相关文章:
打造完整 Transformer 编码器:逐步实现高效深度学习模块
11. encoder 打造完整 Transformer 编码器:逐步实现高效深度学习模块 在深入理解了编码器块的核心结构后,下一步就是实现一个完整的 Transformer 编码器。该编码器将输入序列转换为高级语义向量,并为后续的解码或其他任务模块提供高质量的特…...

软件对象粒度控制与设计模式在其中作用的例子
在软件设计中,确定对象的粒度(Granularity)是一个重要的考量因素,它决定了对象的职责范围和复杂程度。粒度过细或过粗都可能影响系统的可维护性和性能。设计模式可以帮助我们在不同层面控制粒度和管理对象之间的交互。以下是对每种…...

代码随想录算法训练营Day.3| 移除链表元素 设计链表 反转链表
长沙出差ing,今天的核心是链表,一个比较基础且重要的数据结构。对C的指针的使用,对象的创建,都比较考察,且重要。 203.移除链表元素 dummyNode虚拟头节点很重要,另外就是一个前后节点记录的问题。但是Leet…...

基于SSM的学生考勤管理系统的设计与实现
项目描述 临近学期结束,还是毕业设计,你还在做java程序网络编程,期末作业,老师的作业要求觉得大了吗?不知道毕业设计该怎么办?网页功能的数量是否太多?没有合适的类型或系统?等等。这里根据疫情当下,你想解决的问…...

制作gif动图并穿插到CSDN文章中
在我们编写文档时,需要放一些动图来增加我们文章的阅读性,在这里为大家推荐一款好用的软件LICEcap 一、下载LICEcap软件 安装包以百度网盘的形式放在了文章末尾,下载完成后,会出现下面的图标 二、如何操作 双击图标运行 会出现…...

字段值为null就不返回的注解
1. 导包 <dependency><groupId>com.fasterxml.jackson.module</groupId><artifactId>jackson-module-kotlin</artifactId> </dependency>2. 类上加注解 JsonInclude(value JsonInclude.Include.NON_NULL)3. 示例 Data JsonInclude(valu…...
)
spring-boot(整合aop)
第一步导入依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency> 日志依赖 <dependency><groupId>org.springframework.boot</groupI…...

qt QStatusBar详解
1、概述 QStatusBar是Qt框架提供的一个小部件,用于在应用程序窗口底部显示状态信息。它可以显示一些固定的文本和图标,并且可以通过API动态更新显示内容。QStatusBar通常是一个水平的窗口部件,能够显示多行文本内容,非常适合用于…...

Docker Compose部署Powerjob
整个工具的代码都在Gitee或者Github地址内 gitee:solomon-parent: 这个项目主要是总结了工作上遇到的问题以及学习一些框架用于整合例如:rabbitMq、reids、Mqtt、S3协议的文件服务器、mongodb github:GitHub - ZeroNing/solomon-parent: 这个项目主要是…...

前端使用PDF.js把返回的base64或二进制文件流格式,实现pdf文件预览
pdf文件预览 简单了解PDF.js代码实现首先,引入依赖实现预览逻辑 简单了解PDF.js PDF.js是一个JavaScript库,可在浏览器中无插件显示PDF文件,提供缩放、翻页、文本搜索等功能。本文介绍了其基本使用方法和示例代码,如添加翻页和搜…...

如何利用 Python 的爬虫技术获取淘宝天猫商品的价格信息?
以下是使用 Python 的爬虫技术获取淘宝天猫商品价格信息的两种常见方法: 方法一:使用 Selenium 一、环境准备: 安装 selenium 库:在命令行中运行 pip install selenium。下载浏览器驱动:如 ChromeDriver(确…...

论文阅读笔记:Activating More Pixels in Image Super-Resolution Transformer
论文阅读笔记:Activating More Pixels in Image Super-Resolution Transformer 1 背景1.1 问题1.2 提出的方法 2 创新点3 方法4 模块4.1 混合注意力模块(HAB)4.2 重叠交叉注意力模块(OCAB)4.3 同任务预训练 5 效果5.1 …...

VSCode 与 HBuilderX 介绍
Visual Studio Code (VSCode) Visual Studio Code (VSCode) 是一款由 Microsoft 开发的源代码编辑器,支持多种编程语言,并且是免费和开源的。它在开发者社区中非常受欢迎,因其强大的功能和高度的可定制性而受到赞誉。 特点 轻量级且强大&am…...
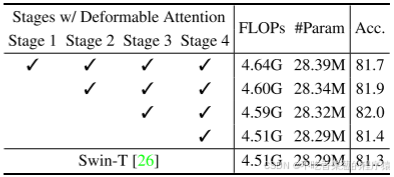
《Vision Transformer with Deformable Attention》论文翻译
原文链接:https://doi.org/10.1109/cvpr52688.2022.00475 author{Zhuofan Xia and Xuran Pan and Shiji Song and Li Erran Li and Gao Huang} 一、介绍 Transformer最初是为了处理自然语言处理任务而提出的。最近,它在计算机视觉领域展示了巨大的潜力。先锋工作V…...

爬虫下载网页文夹
爬虫下载网页pdf文件 import os import requests from bs4 import BeautifulSoup from urllib.parse import urljoin from urllib.parse import urljoin, unquote from tqdm import tqdm # 设置网页的URL base_url "http://119/download/dzz/pdf/"# 创建保存文件的…...
深入探讨钉钉与金蝶云星空的数据集成技术
钉钉报销数据集成到金蝶云星空的技术案例分享 在企业日常运营中,行政报销流程的高效管理至关重要。为了实现这一目标,我们采用了轻易云数据集成平台,将钉钉的行政报销数据无缝对接到金蝶云星空的付款单系统。本次案例将重点介绍如何通过API接…...

小语言模型介绍与LLM的比较
小模型介绍 小语言模型(SLM)与大语言模型(LLM)相比,具有不同的特点和应用场景。大语言模型通常拥有大量的参数(如 GPT-3 拥有 1750 亿个参数),能够处理复杂的自然语言任务ÿ…...

ThreadLocal从入门到精通
1.ThreadLocal是什么 ThreadLocal 是 Java 提供的一个用于线程存储本地变量的类。它为每个线程提供独立的变量副本,确保变量在多线程环境下的线程安全。每个线程访问 ThreadLocal 时,都会有自己专属的变量副本,互不干扰,避免了并…...

小新学习k8s第六天之pod详解
一、资源限制 Pod是k8s中的最小的资源管理组件,pod也是最小化运行容器化应用的资源对象。一个Pod代表着集群中运行的一个进程。k8s中其他大多数组件都是围绕着Pod来进行支撑和扩展Pod功能的,例如,用于管理Pod运行的StatefulSet和Deployment等…...

9、node.js和Lowdb
六、Lowdb 一个简单的Json数据库 6.1安装lowdb npm i lowdb1.0.06.2初始化 //引入lowdb const low require(lowdb) const FileSync require(lowdb/adapters/FileSync) //指定数据文件 const adapter new FileSync(db.json) //创建db对象 const db low(adapter)//初始化…...

Fast-F1数据洞察:赛车数据分析实战的非传统路径
Fast-F1数据洞察:赛车数据分析实战的非传统路径 【免费下载链接】Fast-F1 FastF1 is a python package for accessing and analyzing Formula 1 results, schedules, timing data and telemetry 项目地址: https://gitcode.com/GitHub_Trending/fa/Fast-F1 你…...

别再手动发卡了!2025新版ZFAKA搭配宝塔面板,30分钟搞定你的专属自动售卡站
2025年ZFAKA自动售卡系统:零基础30分钟搭建全攻略 在数字商品交易日益火爆的今天,手动处理订单不仅效率低下,还容易出错。想象一下凌晨三点被订单提醒吵醒,手忙脚乱地复制卡密发给买家——这种场景对于个体创业者来说再熟悉不过了…...

告别Git命令行烦恼:Tig工具让版本控制效率提升3倍
告别Git命令行烦恼:Tig工具让版本控制效率提升3倍 【免费下载链接】tig Text-mode interface for git 项目地址: https://gitcode.com/gh_mirrors/ti/tig 作为开发者,你是否也曾面临这些Git操作痛点:记不住复杂的git log参数组合、在命…...

HTTP自动化测试架构:基于QD框架的HAR模板规模化治理策略
HTTP自动化测试架构:基于QD框架的HAR模板规模化治理策略 【免费下载链接】templates 基于开源新版 QD 框架站发布的公共har模板库,仅供示例 项目地址: https://gitcode.com/GitHub_Trending/templa/templates 在当今云原生和微服务架构盛行的时代…...

AsyncAPI通道管理终极指南:如何高效组织消息流的关键技巧
AsyncAPI通道管理终极指南:如何高效组织消息流的关键技巧 【免费下载链接】spec The AsyncAPI specification allows you to create machine-readable definitions of your asynchronous APIs. 项目地址: https://gitcode.com/gh_mirrors/spec/spec AsyncAPI…...

比迪丽WebUI保姆级教程:从服务器IP获取到首张图生成全过程
比迪丽WebUI保姆级教程:从服务器IP获取到首张图生成全过程 1. 前言:为什么选择比迪丽WebUI? 如果你对《龙珠》里的比迪丽(Videl)这个角色情有独钟,想用AI画出她的各种形象,那么今天这个教程就…...

Fish Speech 1.5开源大模型落地:为乡村学校定制方言普通话双语教学语音
Fish Speech 1.5开源大模型落地:为乡村学校定制方言普通话双语教学语音 想象一下,在偏远山区的教室里,孩子们正跟着一个亲切的“本地老师”学习普通话。这位老师不仅能说一口标准的普通话,还能用孩子们熟悉的家乡方言进行解释和互…...

3步实现Mac微信防撤回:零配置本地化解决方案
3步实现Mac微信防撤回:零配置本地化解决方案 【免费下载链接】WeChatIntercept 微信防撤回插件,一键安装,仅MAC可用,支持v3.7.0微信 项目地址: https://gitcode.com/gh_mirrors/we/WeChatIntercept 告别消息遗憾࿱…...

OpenSSL实战:手把手教你创建自签名根证书
1. 为什么需要自签名根证书? 想象一下你正在搭建一个内部测试环境,或者为公司的内部系统建立一套专属的安全通信机制。这时候你会发现,所有涉及HTTPS的环节都需要SSL/TLS证书。如果直接购买商业CA颁发的证书,不仅成本高ÿ…...

Cadence Virtuoso仿真避坑指南:从网表生成到FFT分析的20个常见错误解决方案
Cadence Virtuoso仿真避坑指南:从网表生成到FFT分析的20个常见错误解决方案 在集成电路设计领域,Cadence Virtuoso作为行业标准工具链的核心组件,其仿真功能的正确使用直接关系到设计效率与结果可靠性。本文将系统梳理从网表生成到FFT分析全流…...