《Vision Transformer with Deformable Attention》论文翻译
原文链接:https://doi.org/10.1109/cvpr52688.2022.00475
author={Zhuofan Xia and Xuran Pan and Shiji Song and Li Erran Li and Gao Huang}
一、介绍
Transformer最初是为了处理自然语言处理任务而提出的。最近,它在计算机视觉领域展示了巨大的潜力。先锋工作Vision Transformer(ViT)通过堆叠多个Transformer块处理非重叠的图像块(即视觉标记)序列,构建了一种无卷积的图像分类模型。与卷积神经网络(CNN)相比,基于Transformer的模型具有更大的感受野,能够更好地建模长距离依赖关系,已被证明在大量训练数据和模型参数的情况下表现出色。然而,视觉识别中冗余的注意力机制是把双刃剑,存在多个缺点。具体来说,每个查询块需要关注的键的过多数量导致了高计算成本和慢收敛,同时增加了过拟合的风险。
为了避免过度的注意力计算,现有的研究工作[6, 11, 26, 36, 43, 49]采用精心设计的高效注意力模式来降低计算复杂性。在这些方法中,Swin Transformer [26]采用基于窗口的局部注意力,限制注意力在局部窗口内,而Pyramid Vision Transformer (PVT) [36]则通过下采样键和值特征图来节省计算。尽管这些方法有效,但手工设计的注意力模式是与数据无关的,可能并非最佳选择。这可能导致相关的键/值被忽略,而不重要的键/值却被保留。
理想情况下,我们希望给定查询的候选键/值集能够灵活并适应每个输入,从而缓解手工稀疏注意力模式的问题。实际上,在卷积神经网络的文献中,学习可变形感受野的卷积滤波器已被证明在基于数据的选择性关注更有信息的区域方面非常有效[9]。最显著的工作是可变形卷积网络(Deformable Convolution Networks)[9],在许多具有挑战性的视觉任务上取得了显著的成果。这激励我们在视觉Transformer中探索可变形注意力模式。然而,这一思想的简单实现会导致不合理的高内存/计算复杂度:可变形偏移所带来的开销与补丁的数量呈平方关系。因此,尽管一些近期的研究[7, 46, 54]探讨了Transformer中的可变形机制,但由于计算成本高,没有将其视为构建强大骨干网络的基本构件,如DCN。相反,它们的可变形机制要么应用于检测头[54],要么用作预处理层以对后续骨干网络进行补丁采样[7]。
在本文中,我们提出了一种简单而高效的可变形自注意力模块,基于此构建了一个强大的金字塔骨干网络,命名为可变形注意力Transformer(Deformable Attention Transformer, DAT),用于图像分类和各种密集预测任务。与可变形卷积网络(DCN)为整个特征图的不同像素学习不同的偏移量不同,我们建议学习少量与查询无关的偏移量组,以将键和值移动到重要区域(如图1(d)所示)。这一设计基于观察[3, 52],即全局注意力通常对不同查询产生几乎相同的注意力模式。该设计具有线性空间复杂度,并为Transformer骨干网络引入了可变形注意力模式。
具体来说,对于每个注意力模块,首先生成参考点作为均匀网格,这些网格在输入数据中保持一致。然后,偏移网络以查询特征为输入,为所有参考点生成相应的偏移量。通过这种方式,候选键/值被移动到重要区域,从而增强了原始自注意力模块的灵活性和效率,以捕捉更多有信息的特征。
总结而言,我们的贡献如下:我们提出了首个可变形自注意力骨干网络,用于视觉识别,其中数据依赖的注意力模式提供了更高的灵活性和效率。在ImageNet [10]、ADE20K [51]和COCO [25]上的大量实验证明,我们的模型在图像分类的top-1准确率上比竞争基线(包括Swin Transformer)提高了0.7,在语义分割的mIoU上提高了1.2,在目标检测的框AP和掩码AP上均提高了1.1。对小物体和大物体的优势更加明显,差距达到2.1。
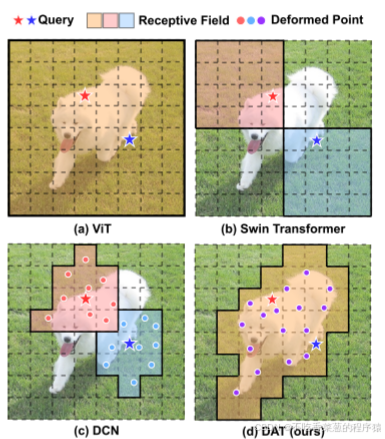
DAT与其他Vision Transformer模型和CNN模型中的DCN的比较。红色星星和蓝色星星表示不同的查询,而具有实线边界的掩码表示查询所涉及的区域。在数据不可知的方式:(a)ViT [12]对所有查询采用完全注意。(b)Swin Transformer [26]使用分区窗口注意。以数据相关的方式:(c)DCN [9]为每个查询学习不同的变形点。(d)DAT学习所有查询的共享变形点。
二、相关工作
Transformer视觉骨干网络。
自从ViT [12]的引入以来,改进工作[6, 11, 26, 28, 36, 43, 49]主要集中在学习多尺度特征以应对密集预测任务和高效的注意力机制。这些注意力机制包括窗口注意力[11, 26]、全局标记[6, 21, 32]、聚焦注意力[43]以及动态标记大小[37]。最近,基于卷积的方法也被引入到视觉Transformer模型中。其中一些研究致力于通过卷积操作补充Transformer模型,以引入额外的归纳偏置。CvT [39]在标记化过程中采用卷积,并利用步幅卷积来降低自注意力的计算复杂性。带卷积前缀的ViT [41]提出在早期阶段加入卷积,以实现更稳定的训练。CSwin Transformer [11]采用基于卷积的位置信息编码技术,并在下游任务中显示出改进。这些基于卷积的技术有可能在DAT的基础上进一步提升性能。
可变形卷积和注意力。
可变形卷积[9, 53]是一种强大的机制,能够根据输入数据关注灵活的空间位置。最近,它已被应用于视觉Transformer中[7, 46, 54]。可变形DETR [54]通过为每个查询选择少量键来改善DETR [4]的收敛性,这一方法建立在卷积神经网络(CNN)骨干之上。然而,其可变形注意力并不适合用于特征提取的视觉骨干,因为键的不足限制了表示能力。此外,可变形DETR中的注意力来自简单学习的线性投影,且键在查询标记之间并未共享。DPT [7]和PS-ViT [46]构建了可变形模块来细化视觉标记。具体来说,DPT提出了一种可变形补丁嵌入方法,用于在不同阶段细化补丁,而PS-ViT则在ViT骨干之前引入了一种空间采样模块以改善视觉标记。然而,它们都未将可变形注意力纳入视觉骨干网络。相比之下,我们的可变形注意力采用了一种强大而简单的设计,学习一组在视觉标记之间共享的全局键,可以作为各种视觉任务的通用骨干网络。我们的方法也可以视为一种空间自适应机制,这在多项研究中已被证明有效[16, 38]。
三、Deformable Attention Transformer
1.Preliminaries
我们首先回顾最近的视觉Transformer的注意力机制。以平坦化的特征映射x ∈ RN×C作为输入,具有M个头部的多头自注意(MHSA)块被公式化为:
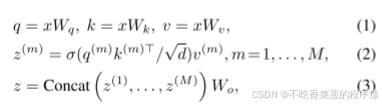
其中,σ(·)表示softmax函数,d =C/M是每个头部的尺寸。z(m)表示从第m个注意头输出的嵌入,q(m),k(m),v(m)∈ RN×d分别表示查询,键和值嵌入。Wq,Wk,Wv,Wo ∈ RC×C是投影矩阵。为了构建Transformer块,通常采用具有两个线性变换和GELU激活的MLP块来提供非线性。使用规范化层和标识快捷方式,第l个Transformer块被公式化为
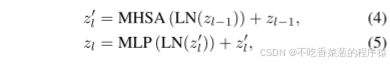
其中LN是层归一化[1]。
2.Deformable Attention
现有分层视觉变换器的下采样技术,特别是PVT [36]和Swin Transformer [26],试图解决过度关注的挑战。前者会导致严重的信息丢失,而后者的移位窗口注意力则导致感受野的增长速度显著减慢,限制了对大型对象的建模潜力。因此,需要一种数据依赖的稀疏注意力来灵活地建模相关特征,从而引出最初在 DCN [9] 中提出的可变形机制。然而,简单地将 DCN 实现到 Transformer 模型中并非易事。在 DCN 中,特征图上的每个元素都单独学习其偏移量,其中在H×W×C特征图上的 3 x 3 可变形卷积的空间复杂度为 9HWC 。如果直接将相同的机制应用到注意力模块中,空间复杂度将急剧上升至 NqNkC,其中 Nq,Nk分别是查询和键的数量,通常与特征图大小 HW 具有相同的尺度,带来近似二次复杂度。尽管 Deformable DETR [54] 通过在每个尺度上设置较少的键数量(即 Nk=4)并作为检测头有效地工作,从而成功地减少了此开销,但在主干网络中使用如此少的键进行注意力会导致不可接受的信息损失(详见附录中的比较)。与此同时,文献 [3, 52] 中的观察结果表明,不同查询在视觉注意模型中具有相似的注意力图。因此,我们选择了一种更简单的解决方案,为每个查询共享移位的键和值,以实现高效的权衡。
具体来说,我们提出了可变形注意力,在特征图中重要区域的指导下,有效地建模 token 之间的关系。这些重点区域由多个组的变形采样模式确定,并由多个组管理。每个模式表示特征图中的一组可变形采样点,以跨越不同尺度捕获依赖性。
从特征图中采样的特征被传递给键和值的投影,以生成变形的键和值。最后,标准的多头注意力被应用于将查询与采样键关联起来,并从变形后的值中聚合特征。此外,变形点的位置提供了更强大的相对位置偏差,以促进变形注意力的学习,这将在后续部分中讨论。
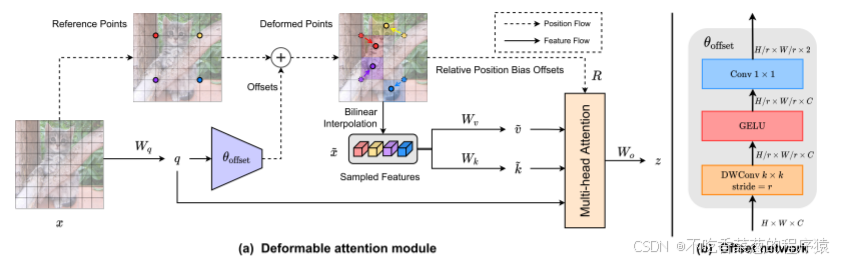
这是我们的变形注意机制的一个例子。(a)给出了可变形注意的信息流。在左侧部分,一组参考点均匀地放置在要素图上,其偏移量通过偏移网络从查询中获知。然后根据变形点从采样特征中投影出变形的关键帧和值,如右图所示。通过计算变形点的相对位置偏差,增强了输出变换特征的多头注意力。我们只展示了4个参考点,以便清楚地介绍,事实上在真实的实施中还有更多的点。(b)显示了偏移生成网络的详细结构,用特征图的大小标记。
变形注意力模块。 如图 2(a) 所示,给定输入特征图 x∈RH×W×C,生成一个均匀的点网格 p∈RHG×WG×2 作为参考点。具体来说,网格大小通过因子 r 从输入特征图大小下采样,HG=H/r、WG=W/r。参考点的值是线性分布的二维坐标 {(0,0),…,(HG−1,WG−1)},然后根据网格形状 HG×WG 将其归一化到范围 [−1,+1],其中 (−1,−1)表示左上角,(+1,+1) 表示右下角。为了获得每个参考点的偏移量,将特征图线性投影到查询 token q=xWq,然后输入到轻量级子网络 θoffset(⋅)中以生成偏移量 Δp=θoffset(q)。为稳定训练过程,我们通过预设的因子 s来缩放 Δp 的幅度,以生成更大的偏移值,即 Δp←stanh(Δp)。然后使用调整后的参考点对特征图进行索引,获得采样特征。作为键和值,然后是投影矩阵:
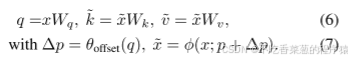
k˜和˜v分别表示变形的键和值嵌入。具体来说,我们将采样函数φ(·; ·)设置为双线性插值以使其可微:
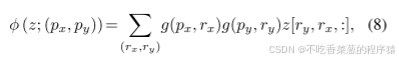
其中g(a,b)= max(0,1 - |a −b|)和(rx,ry)索引z∈RH×W×C上的所有位置。由于g仅在最接近(px,py)的4个积分点上为非零,因此简化了等式(1)。(8)到4个位置的加权平均值。与现有方法类似,我们对q,k,v执行多头注意,并采用相对位置偏移R。注意力头的输出被公式化为:
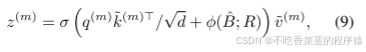
其中φ(B; R)∈ RHW×HGWG对应于先前工作[26]中的位置嵌入,但有几个修改。详细信息将在本节稍后进行解释。每个头部的特征被连接在一起并通过Wo投影以得到如等式(3)所示的最终输出z。如前所述,采用子网络来生成偏移,该子网络消耗查询特征并分别输出参考点的偏移值。考虑到每个参考点覆盖一个局部 s×s 区域(其中 s 是最大的偏移范围),生成网络还需要具备局部特征的感知能力,以学习合理的偏移。因此,我们将子网络实现为两个卷积模块,并使用非线性激活函数,如图 2(b) 所示。输入特征首先通过一个 5×5 深度卷积来捕获局部特征。然后,使用 GELU 激活和 1×1卷积以获得 2D 偏移。值得注意的是,在 1×1卷积中移除了偏置项,以缓解所有位置的强制位移。
偏移组。 为了增加变形点的多样性,我们遵循与 MHSA 类似的方式,将特征通道分成 G 个组。每组特征使用共享的子网络生成相应的偏移值。在实际应用中,注意力模块中的头数 M设置为偏移组大小 G 的倍数,确保多个注意力头分配给一组变形后的键和值。
可变形相对位置偏置。 相对位置偏置编码了每个查询和键对之间的相对位置,从而在原始注意力中增加了空间信息。对于形状为 H×W的特征图,相对坐标位移在两个维度上分别位于 [−H,H]和 [−W,W]的范围内。在 Swin Transformer [26] 中,构建了一个相对位置偏置表 B^∈R(2H−1)×(2W−1),通过在两个方向上使用相对位移对该表进行索引,以获得相对位置偏置 B。由于我们的可变形注意力允许键的位置连续,因此我们在归一化范围 [−1,+1]内计算相对位移,并根据连续的相对位移对参数化的偏置表 B^∈R(2H−1)×(2W−1)进行插值 ϕ(B^;R)以覆盖所有可能的偏移值。
计算复杂度。 可变形多头注意力(DMHA)的计算成本与 PVT 或 Swin Transformer 中的注意力模块相似。唯一的额外开销来自用于生成偏移的子网络。整个模块的复杂度可以总结为:

其中 Ns=HGWG=HW/r2是采样点的数量。可以立即看出,偏移网络的计算成本相对于通道大小具有线性复杂度,这相对于注意力模块来说相对较小。例如,考虑用于图像分类的 Swin-T 模型的第三阶段,其中 H=W=14,Ns=49,C=384,单个块中注意力模块的计算成本为 79.63M FLOPs。当配备我们的可变形模块(k=5)时,额外的开销为5.08M Flops,仅占整个模块的6.0%。此外,通过选择较大的下采样因子r,复杂度将进一步降低,这使得它对具有更高分辨率输入的任务(如对象检测和实例分割)非常友好。
3.3. Model Architectures
我们将标准的 MHSA 替换为 Transformer 中的可变形注意力(Eq.(4)),并将其与 MLP(Eq.(5))结合,以构建一个可变形视觉 Transformer 模块。在网络架构方面,我们的模型——可变形注意力 Transformer(DAT)具有与 [7, 26, 31, 36] 相似的金字塔结构,这广泛适用于需要多尺度特征图的各种视觉任务。如图 3 所示,形状为 H×W×3 的输入图像首先通过一个步幅为 4 的 4×4非重叠卷积嵌入,然后通过归一化层获得 H/4×W/4×C的 patch 嵌入。为了构建层次化的特征金字塔,主干网络包含 4 个阶段,步幅逐步增加。在两个连续的阶段之间,有一个步幅为 2 的非重叠 2×2卷积,将特征图下采样以使空间尺寸减半并使特征维度加倍。
在分类任务中,我们首先对最后阶段输出的特征图进行归一化,然后采用具有池化特征的线性分类器来预测 logits。在目标检测、实例分割和语义分割任务中,DAT 作为集成视觉模型中的主干,以提取多尺度特征。我们为每个阶段的特征添加一个归一化层,然后将其输入到后续模块中,如目标检测中的 FPN [23] 或语义分割中的解码器。
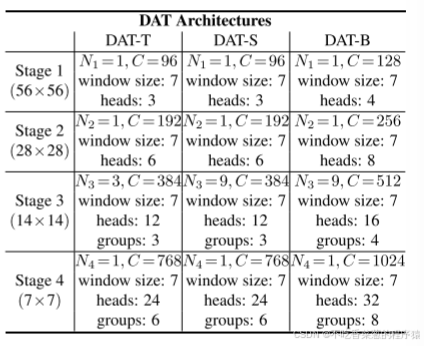
我们在 DAT 的第三和第四阶段引入了连续的局部注意力和可变形注意力模块。特征图首先通过基于窗口的局部注意力处理,以在局部聚合信息,然后通过可变形注意力模块来建模局部增强 token 之间的全局关系。该注意力模块交替设计了局部和全局特征替换,以增强模型的表示能力,尤其是在 GLiT [5]、TNT [15] 和Point former [29]中共享类似的模式。由于前两个阶段主要学习局部特征,因此这些早期阶段的可变形注意力不太受欢迎。此外,前两个阶段中的键和值具有相当大的空间尺寸,这大大增加了可变形注意力中的点积和双线性插值的计算开销。因此,为了实现模型容量和计算负担之间的权衡,我们仅将可变形注意力置于第三和第四阶段,并采用Swin Transformer [26]中的移位窗口注意力,以便在早期阶段具有更好的表示。我们以不同的参数和FLOP构建了DAT的三种变体,以便与其他Vision Transformer模型进行公平的比较。我们通过在第三阶段堆叠更多的块并增加隐藏维度来改变模型大小。表1中报告了详细的体系结构。注意,DAT的前两个阶段还有其他设计选择,例如,我们在表7中显示了比较结果。
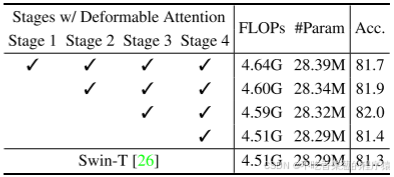
表7.不同阶段应用可变形注意的消融研究。意味着该阶段由连续的局部注意和可变形注意Transformer块组成。注意,我们的模型将所有局部和shiftwindow注意力的相对位置索引以及所有可变形注意力的参考网格点纳入参数计数中,这可能导致更高数量的参数。
相关文章:
《Vision Transformer with Deformable Attention》论文翻译
原文链接:https://doi.org/10.1109/cvpr52688.2022.00475 author{Zhuofan Xia and Xuran Pan and Shiji Song and Li Erran Li and Gao Huang} 一、介绍 Transformer最初是为了处理自然语言处理任务而提出的。最近,它在计算机视觉领域展示了巨大的潜力。先锋工作V…...

爬虫下载网页文夹
爬虫下载网页pdf文件 import os import requests from bs4 import BeautifulSoup from urllib.parse import urljoin from urllib.parse import urljoin, unquote from tqdm import tqdm # 设置网页的URL base_url "http://119/download/dzz/pdf/"# 创建保存文件的…...
深入探讨钉钉与金蝶云星空的数据集成技术
钉钉报销数据集成到金蝶云星空的技术案例分享 在企业日常运营中,行政报销流程的高效管理至关重要。为了实现这一目标,我们采用了轻易云数据集成平台,将钉钉的行政报销数据无缝对接到金蝶云星空的付款单系统。本次案例将重点介绍如何通过API接…...

小语言模型介绍与LLM的比较
小模型介绍 小语言模型(SLM)与大语言模型(LLM)相比,具有不同的特点和应用场景。大语言模型通常拥有大量的参数(如 GPT-3 拥有 1750 亿个参数),能够处理复杂的自然语言任务ÿ…...

ThreadLocal从入门到精通
1.ThreadLocal是什么 ThreadLocal 是 Java 提供的一个用于线程存储本地变量的类。它为每个线程提供独立的变量副本,确保变量在多线程环境下的线程安全。每个线程访问 ThreadLocal 时,都会有自己专属的变量副本,互不干扰,避免了并…...

小新学习k8s第六天之pod详解
一、资源限制 Pod是k8s中的最小的资源管理组件,pod也是最小化运行容器化应用的资源对象。一个Pod代表着集群中运行的一个进程。k8s中其他大多数组件都是围绕着Pod来进行支撑和扩展Pod功能的,例如,用于管理Pod运行的StatefulSet和Deployment等…...

9、node.js和Lowdb
六、Lowdb 一个简单的Json数据库 6.1安装lowdb npm i lowdb1.0.06.2初始化 //引入lowdb const low require(lowdb) const FileSync require(lowdb/adapters/FileSync) //指定数据文件 const adapter new FileSync(db.json) //创建db对象 const db low(adapter)//初始化…...

WebAPI编程(第五天,第六天,第七天)
WebAPI编程(第五天,第六天,第七天) **day05 - Web APIs****1.1. **元素偏移量 offset 系列1.1.1 offset 概述1.1.2 offset 与 style 区别offsetstyle 1.1.3 案例:获取鼠标在盒子内的坐标1.1.4 案例:模态框拖…...

香港服务器网络延迟的测量指标包括哪些?
网络延迟是影响香港服务器性能和用户体验的关键因素。网络延迟是指数据包从源头传输到目的地所需的时间。延迟的产生可能受到多种因素的影响,包括网络拥塞、传输媒介、路由器处理时间等。理解延迟的不同测量指标是评估和优化网络性能的重要基础。 主要测量指标&…...

【综合案例】使用React编写B站评论案例
一、效果展示 默认效果,一开始默认按照最热进行排序 发布了一条评论 按照最新进行排序 按照最新进行排序 二、效果说明 页面上默认有3条评论,且一开始进入页面的时候是按照点赞数量进行倒序排列展示,可以点击【最热 、最新】进行排序的切换。…...

【AIGC】腾讯云语音识别(ASR)服务在Spring Boot项目中的集成与实践
腾讯云语音识别(ASR)服务在Spring Boot项目中的集成与实践 引言 在现代软件开发中,语音识别技术的应用越来越广泛,从智能助手到自动客服系统,语音识别技术都在发挥着重要作用。腾讯云提供了强大的语音识别服务&#…...

基于 Vue3、Vite 和 TypeScript 实现开发环境下解决跨域问题,实现前后端数据传递
引言 本文介绍如何在开发环境下解决 Vite 前端(端口 3000)和后端(端口 80)之间的跨域问题: 在开发环境中,前端使用的 Vite 端口与后端端口不一致,会产生跨域错误提示: Access to X…...

前端面筋(持续更新)
额外面筋 get和post的区别?怎么理解get能被缓存? get请求和post同属于http中的两种请求,在传输上没有什么区别,只是约定有所不同get请求一般用于向服务器请求数据 post请求一般用于向服务器提交数据get请求的参数一般不安全&…...

深度学习-迁移学习
深度学习中的迁移学习是通过在大规模数据上训练的模型,将其知识迁移到数据相对较少的相关任务中,能显著提升目标任务的模型性能。 一、迁移学习的核心概念 源任务(Source Task)与目标任务(Target Task)&…...

6.0、静态路由
路由器最主要的功能就是转发数据包。路由器转发数据包时需要查找路由表(你可以理解为地图),管理员可以直接手动配置路由表,这就是静态路由。 1.什么是路由? 在网络世界中,路由是指数据包在网络中的传输路…...

Redis学习:BitMap/HyperLogLog/GEO案例 、布隆过滤器BloomFilter、缓存预热+缓存雪崩+缓存击穿+缓存穿透
Redis学习 文章目录 Redis学习1、BitMap/HyperLogLog/GEO案例2. 布隆过滤器BloomFilter3. 缓存预热缓存雪崩缓存击穿缓存穿透 1、BitMap/HyperLogLog/GEO案例 真实需求面试题 亿级数据的收集清洗统计展现对集合中数据进行统计,基数统计,二值统计…...

Lua数据类型
Lua 语言 数据类型 Lua 有以下数据类型: nil:表示一个无效值,相当于 NULL。boolean:true 或 false。number:整数或浮点数。string:字符串。function:函数。userdata:用户数据。th…...

CSS中的背景色和前景色
目录 1 对比度的计算1.1 亮度计算1.2 对比度比率 2 在线计算对比度 在我们的样式设计中,通常会有背景色和前景色的概念。前景色我们通常用来设置文本的颜色,而背景色通常是文本的所在容器的颜色。比如如果我们把文本放在普通容器里,那普通容器…...
《复分析》与《实分析》教材)
伊莱亚斯 M. 斯坦恩(Elias M. Stein)《复分析》与《实分析》教材
分析学大师Elias M. Stein(曾是陶哲轩的老师),写了四本分析学系列教材,统称为普林斯顿分析学讲座(Princeton Lectures in Analysis)。他们分别是: I Fourier Analysis:An Introduct…...

UCLA、MIT数学家推翻39年经典数学猜想!AI证明卡在99.99%,人类最终证伪
39年来一个看似理所当然的数学理论,刚刚被数学家证伪!UCLA和MIT的研究者证实:概率论中众所周知的假设「上下铺猜想」是错的。有趣的是,他们用AI已经证明到了99.99%的程度,但最终,靠的还是理论论证。 又一个…...

Chrome for Testing 战略深度解析:构建确定性测试环境的架构决策
Chrome for Testing 战略深度解析:构建确定性测试环境的架构决策 【免费下载链接】chrome-for-testing 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-for-testing 想象一下这个场景:你的团队刚刚完成了一个重要的功能开发,CI…...

单物体最优抓取轨迹生成
基于 3D 位姿规划直线平滑抓取轨迹,包含趋近 - 抓取 - 复位三段最优运动路径,适配机械臂点位运动核心规划逻辑基准位:机械臂初始安全待机点趋近段:直线匀速靠近物体上方预备抓取点抓取段:垂直下落至物体抓取中心位姿抬…...

Claude Code 终端命令完整指南
引言最初是为了方便我个人学习使用Claude Code才去网络上收集各种终端命令,但想到可能有人同样需要知道这些命令,便打算将其整理发到CSDN上,希望能帮到大家。 有点标题党的是本文并不是真的完整指南,毕竟完整的命令太多了…...

解锁答辩新方式:依托 paperxie 智能 AI 轻松打造高质量毕业论文答辩 PPT
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPThttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 前言 临近毕业阶段,毕业论文定稿之后,答辩 PPT 制作就成为同学们首要攻克的任务。答辩 PPT 承载着整…...

2026年AI论文写作工具实测排行,哪款真正适合写论文?
2026 年学术 AI 论文工具已形成全流程、理工 / 社科、英文 / 中文、免费 / 付费的清晰分化。综合实测排行与场景适配,千笔AI 是中文全能首选,DeepSeek 学术版是理工开源首选,毕业之家是国内毕业专属首选。 一、2026 年实测排行 TOP5ÿ…...

深度解析OBS Mac虚拟摄像头插件的架构设计与性能优化
深度解析OBS Mac虚拟摄像头插件的架构设计与性能优化 【免费下载链接】obs-mac-virtualcam ARCHIVED! This plugin is officially a part of OBS as of version 26.1. See note below for info on upgrading. 🎉🎉🎉Creates a virtual webcam…...

BilibiliDown:3分钟掌握B站视频批量下载的终极解决方案
BilibiliDown:3分钟掌握B站视频批量下载的终极解决方案 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors/…...

职场新人不会写自我介绍怎么办?AI三分钟帮你搞定,面试邀约直接翻倍!
嘿,各位刚踏入职场的小萌新、想跳槽但又苦于没新项目亮点的打工人!你是不是也遇到过这种尴尬:辛辛苦苦写完简历,最后却卡在“自我介绍”或者“个人总结”那块? 要么就是寥寥几句套话,像“本人性格开朗&…...

3个关键技术方案:如何系统化解决Navicat Premium试用期限制
3个关键技术方案:如何系统化解决Navicat Premium试用期限制 【免费下载链接】navicat_reset_mac navicat mac版无限重置试用期脚本 Navicat Mac Version Unlimited Trial Reset Script 项目地址: https://gitcode.com/gh_mirrors/na/navicat_reset_mac 本文旨…...

深度解析 StoreClaw:面向电商全域的 “懂销售” 智能体技术架构与核心实现原理
摘要随着大语言模型、多智能体协同、实时数据分析与自动化决策技术的快速迭代,AI 正从辅助工具向业务执行主体演进。传统电商平台数字化工具多停留在数据统计、报表展示、基础客服层面,缺乏具备自主感知、自主分析、自主决策、自主执行的闭环能力&#x…...