论文阅读笔记:Activating More Pixels in Image Super-Resolution Transformer
论文阅读笔记:Activating More Pixels in Image Super-Resolution Transformer
- 1 背景
- 1.1 问题
- 1.2 提出的方法
- 2 创新点
- 3 方法
- 4 模块
- 4.1 混合注意力模块(HAB)
- 4.2 重叠交叉注意力模块(OCAB)
- 4.3 同任务预训练
- 5 效果
- 5.1 消融实验
- 5.2 和SOTA方法对比
论文:https://arxiv.org/pdf/2205.04437
代码:https://github.com/xpixelgroup/hat
1 背景
1.1 问题
虽然Transformer based的超分模型效果比CNN好,但是原因还是不得而知。一个直观的解释是,这种网络可以受益于自注意力机制并利用远距离信息。
因此作者采用归因分析方法LAM来考察SwinIR中用于重建的信息所涉及的范围,发现SwinIR并没有比基于CNN的方法在超分辨率上利用更多的输入像素,如图2所示。

此外,虽然SwinIR获得了更高的量化性能,但由于使用的信息范围有限,在一些样本中产生了不如RCAN的结果,这些现象说明Transformer对局部信息的建模能力更强,但其利用信息的范围还有待扩大。作者还发现在SwinIR的中间特征会出现块状伪影,如图3所示。论证了平移窗口机制无法完美实现跨窗信息交互。

1.2 提出的方法
为了解决上述问题,进一步挖掘Transformer在超分辨率重建中的潜力,本文提出了一种混合注意力Transformer,即 HAT。
-
HAT结合了通道注意力和自注意力机制,以利用前者获取全局信息的能力和后者强大的表征能力。
-
此外,引入重叠交叉注意力模块,以实现相邻窗口特征更直接的交互,受益于这些设计,模块可以激活更多的像素重建,从而获得更显著的性能提升。
2 创新点
-
设计了一种新颖的混合注意力Transformer( Hybrid Attention Transformer,HAT ),将自注意力、通道注意力和一种新的重叠交叉注意力相结合,以激活更多的像素,从而更好地进行重建。
-
提出了一种有效的同任务预训练策略来进一步挖掘SR Transformer的潜力,并表明了大规模数据预训练对于该任务的重要性。
-
方法达到了最先进的性能。通过进一步扩展HAT构建大模型,极大地扩展了SR任务的性能上界。
3 方法

整体网络由3部分组成,包括浅层特征提取、深层特征提取和图像重建。对于给定的低分辨率输入 I L R ∈ R H × W × C i n I_{LR}∈R^{H×W×C_{in}} ILR∈RH×W×Cin,首先利用一个卷积层来提取浅层特征 F 0 ∈ R H × W × C F_0∈R^{H×W×C} F0∈RH×W×C,其中 C i n C_{in} Cin 和 C C C 是输入图像和中间特征的通道数。然后利用一系列残差混合注意力组 RHAG 和一个 3×3 卷积层 H C o n v ( ⋅ ) H_{Conv}(·) HConv(⋅) 进行深度特征提取。之后,使用一个全局残差来融合浅层特征 F 0 F_0 F0 和深层特征 F D ∈ R H × W × C F_D∈R^{H×W×C} FD∈RH×W×C,在最后通过重建模块对高分辨率结果进行重建,如图4。
4 模块
4.1 混合注意力模块(HAB)
如图2中所示,当采用通道注意力时,更多的像素被激活,因为全局信息参与计算通道注意力权重。此外,还有很多工作表明卷积可以帮助Transformer获得更好的视觉表示或实现更简单的优化。因此,作者在标准Transformer块中融入基于通道注意力的卷积块来增强网络的表达能力。
如图4所示,在第一个Layer Norm层后的标准Swin Transformer块中并联一个通道注意力模块CAB,该模块与基于窗口的多头自注意力模块W-MSA并联,在连续的HAB块中,间隔使用基于移动窗口的自注意力模块SW-MSA。为了避免CAB和MSA在优化和可视化表达上可能存在冲突,在CAB的输出上乘以一个较小的常数 α \alpha α。对于给定的输入特征 X X X,整个HAB的计算过程如下:

其中 X N X_N XN 和 X M X_M XM 表示中间特征。 Y Y Y 表示HAB的输出。将每一个像素看作是一个块的嵌入的token。给定输入特征 H × W × C H×W×C H×W×C,现将其划分成 H W M 2 \frac{HW}{M^2} M2HW 个尺寸为 M × M M×M M×M 的局部窗口,然后在每个窗口内部计算自注意力:

其中 d d d 表示 query 和 key 的维度。 B B B 表示相对位置编码。作者发现扩大窗口大小可以显著的扩大使用像素的范围,于是使用了一个大的窗口大小来计算自注意力。同时为了建立相邻非重叠窗口之间的联系,作者还是用窗口移动划分方法,并将窗口移动大小设置为窗口大小的一半。
CAB由两个带有GELU激活的标准卷积层和一个通道注意力模块组成,如图4所示。由于基于Transformer的结构往往需要较多的嵌入,直接使用宽度不变的卷积会产生较大的计算开销,所以作者使用一个常数 β \beta β 来压缩两个卷积层将通道数。对于一个具有 C C C 个通道的输入特征,将第一个卷积层后的输出特征的通道数压缩为 C β \frac{C}{\beta} βC。然后通过第二层将输出通道扩展为 C C C。其次,利用一个标准的CA模块自适应的缩放通道特征。
4.2 重叠交叉注意力模块(OCAB)

作者引入OCAB直接建立跨窗口连接,增强窗口自注意力的表示能力。OCAB类似于一个标准的Swin Transformer,由一个重叠交叉注意力层OCA和MLP层组成。但是对于OCA,如图5所示,作者使用不同的窗口大小对投影后的特征进行划分。具体来说,对于输入特征 X X X 的 X Q , X K , X V ∈ R H × W × C X_Q,X_K,X_V∈R^{H×W×C} XQ,XK,XV∈RH×W×C, X Q X_Q XQ 被划分成大小为 M × M M×M M×M 的 H W M 2 \frac{HW}{M^2} M2HW 个非重叠区域,而 X K , X V X_K,X_V XK,XV 被划分成大小为 M o × M o M_o×M_o Mo×Mo 的 H W M 2 \frac{HW}{M^2} M2HW 个重叠窗口,其计算公式为:

其中 γ \gamma γ 是控制重叠尺寸的常数。为了更好的理解这个操作,标准的窗口划分可以为认为是一个滑动划分,其核大小和步长都等于窗口大小 M M M,相比之下,重叠窗口划分可以看做是一个滑动划分,其核大小等于等于 M o M_o Mo,而步长等于 M M M。窗口超出的尺寸采用补零的方式来填充。计算注意力矩阵的方式同式2,同样采样相对位置偏差 B 属于 R M × M o B属于R^{M×M_o} B属于RM×Mo。与WSA不同的是,WSA的query,key和value都是通过相同窗口特征的计算得到,而OCA从更大的视野中计算key和value,query可以利用更多有用的信息。
4.3 同任务预训练
预训练在许多高级视觉任务上被证明是有效的。最近的工作也证明了预训练对低级视觉任务是有益的。IPT 强调使用各种低级任务,如去噪、去雨、超分辨率等,而EDT则利用特定任务的不同退化程度进行预训练。这些工作集中于考察针对某一目标任务的多任务预训练的效果。相比之下,作者基于同样的任务直接在更大规模的数据集(即ImageNet )上进行预训练,表明预训练的有效性更依赖于数据的规模和多样性。例如,当我们想要训练一个× 4 SR的模型时,我们首先在ImageNet上训练一个× 4 SR的模型,然后再对其进行微调,如在DF2K上。所提出的策略,即同任务预训练,更简单的同时带来更多的性能提升。值得一提的是,足够的训练迭代次数进行预训练和合适的小学习率进行微调对于预训练策略的有效性非常重要。我们认为这是由于Transformer需要更多的数据和迭代次数来学习任务的一般性知识,但需要较小的学习率进行微调,以避免对特定数据集的过拟合。
5 效果
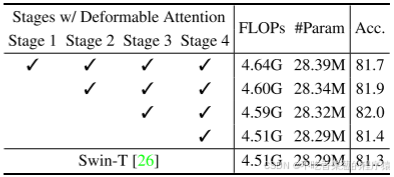
5.1 消融实验
不同窗口尺寸的消融实验和可视化效果对比。


提出的OCAB和CAB模块的消融实验和可视化效果。



同任务预训练策略消融实验的效果。


5.2 和SOTA方法对比
和SOTA方法的指标对比。

和SOTA方法的可视化效果对比。

相关文章:
论文阅读笔记:Activating More Pixels in Image Super-Resolution Transformer
论文阅读笔记:Activating More Pixels in Image Super-Resolution Transformer 1 背景1.1 问题1.2 提出的方法 2 创新点3 方法4 模块4.1 混合注意力模块(HAB)4.2 重叠交叉注意力模块(OCAB)4.3 同任务预训练 5 效果5.1 …...

VSCode 与 HBuilderX 介绍
Visual Studio Code (VSCode) Visual Studio Code (VSCode) 是一款由 Microsoft 开发的源代码编辑器,支持多种编程语言,并且是免费和开源的。它在开发者社区中非常受欢迎,因其强大的功能和高度的可定制性而受到赞誉。 特点 轻量级且强大&am…...
《Vision Transformer with Deformable Attention》论文翻译
原文链接:https://doi.org/10.1109/cvpr52688.2022.00475 author{Zhuofan Xia and Xuran Pan and Shiji Song and Li Erran Li and Gao Huang} 一、介绍 Transformer最初是为了处理自然语言处理任务而提出的。最近,它在计算机视觉领域展示了巨大的潜力。先锋工作V…...

爬虫下载网页文夹
爬虫下载网页pdf文件 import os import requests from bs4 import BeautifulSoup from urllib.parse import urljoin from urllib.parse import urljoin, unquote from tqdm import tqdm # 设置网页的URL base_url "http://119/download/dzz/pdf/"# 创建保存文件的…...
深入探讨钉钉与金蝶云星空的数据集成技术
钉钉报销数据集成到金蝶云星空的技术案例分享 在企业日常运营中,行政报销流程的高效管理至关重要。为了实现这一目标,我们采用了轻易云数据集成平台,将钉钉的行政报销数据无缝对接到金蝶云星空的付款单系统。本次案例将重点介绍如何通过API接…...

小语言模型介绍与LLM的比较
小模型介绍 小语言模型(SLM)与大语言模型(LLM)相比,具有不同的特点和应用场景。大语言模型通常拥有大量的参数(如 GPT-3 拥有 1750 亿个参数),能够处理复杂的自然语言任务ÿ…...

ThreadLocal从入门到精通
1.ThreadLocal是什么 ThreadLocal 是 Java 提供的一个用于线程存储本地变量的类。它为每个线程提供独立的变量副本,确保变量在多线程环境下的线程安全。每个线程访问 ThreadLocal 时,都会有自己专属的变量副本,互不干扰,避免了并…...

小新学习k8s第六天之pod详解
一、资源限制 Pod是k8s中的最小的资源管理组件,pod也是最小化运行容器化应用的资源对象。一个Pod代表着集群中运行的一个进程。k8s中其他大多数组件都是围绕着Pod来进行支撑和扩展Pod功能的,例如,用于管理Pod运行的StatefulSet和Deployment等…...

9、node.js和Lowdb
六、Lowdb 一个简单的Json数据库 6.1安装lowdb npm i lowdb1.0.06.2初始化 //引入lowdb const low require(lowdb) const FileSync require(lowdb/adapters/FileSync) //指定数据文件 const adapter new FileSync(db.json) //创建db对象 const db low(adapter)//初始化…...

WebAPI编程(第五天,第六天,第七天)
WebAPI编程(第五天,第六天,第七天) **day05 - Web APIs****1.1. **元素偏移量 offset 系列1.1.1 offset 概述1.1.2 offset 与 style 区别offsetstyle 1.1.3 案例:获取鼠标在盒子内的坐标1.1.4 案例:模态框拖…...

香港服务器网络延迟的测量指标包括哪些?
网络延迟是影响香港服务器性能和用户体验的关键因素。网络延迟是指数据包从源头传输到目的地所需的时间。延迟的产生可能受到多种因素的影响,包括网络拥塞、传输媒介、路由器处理时间等。理解延迟的不同测量指标是评估和优化网络性能的重要基础。 主要测量指标&…...

【综合案例】使用React编写B站评论案例
一、效果展示 默认效果,一开始默认按照最热进行排序 发布了一条评论 按照最新进行排序 按照最新进行排序 二、效果说明 页面上默认有3条评论,且一开始进入页面的时候是按照点赞数量进行倒序排列展示,可以点击【最热 、最新】进行排序的切换。…...

【AIGC】腾讯云语音识别(ASR)服务在Spring Boot项目中的集成与实践
腾讯云语音识别(ASR)服务在Spring Boot项目中的集成与实践 引言 在现代软件开发中,语音识别技术的应用越来越广泛,从智能助手到自动客服系统,语音识别技术都在发挥着重要作用。腾讯云提供了强大的语音识别服务&#…...

基于 Vue3、Vite 和 TypeScript 实现开发环境下解决跨域问题,实现前后端数据传递
引言 本文介绍如何在开发环境下解决 Vite 前端(端口 3000)和后端(端口 80)之间的跨域问题: 在开发环境中,前端使用的 Vite 端口与后端端口不一致,会产生跨域错误提示: Access to X…...

前端面筋(持续更新)
额外面筋 get和post的区别?怎么理解get能被缓存? get请求和post同属于http中的两种请求,在传输上没有什么区别,只是约定有所不同get请求一般用于向服务器请求数据 post请求一般用于向服务器提交数据get请求的参数一般不安全&…...

深度学习-迁移学习
深度学习中的迁移学习是通过在大规模数据上训练的模型,将其知识迁移到数据相对较少的相关任务中,能显著提升目标任务的模型性能。 一、迁移学习的核心概念 源任务(Source Task)与目标任务(Target Task)&…...

6.0、静态路由
路由器最主要的功能就是转发数据包。路由器转发数据包时需要查找路由表(你可以理解为地图),管理员可以直接手动配置路由表,这就是静态路由。 1.什么是路由? 在网络世界中,路由是指数据包在网络中的传输路…...

Redis学习:BitMap/HyperLogLog/GEO案例 、布隆过滤器BloomFilter、缓存预热+缓存雪崩+缓存击穿+缓存穿透
Redis学习 文章目录 Redis学习1、BitMap/HyperLogLog/GEO案例2. 布隆过滤器BloomFilter3. 缓存预热缓存雪崩缓存击穿缓存穿透 1、BitMap/HyperLogLog/GEO案例 真实需求面试题 亿级数据的收集清洗统计展现对集合中数据进行统计,基数统计,二值统计…...

Lua数据类型
Lua 语言 数据类型 Lua 有以下数据类型: nil:表示一个无效值,相当于 NULL。boolean:true 或 false。number:整数或浮点数。string:字符串。function:函数。userdata:用户数据。th…...

CSS中的背景色和前景色
目录 1 对比度的计算1.1 亮度计算1.2 对比度比率 2 在线计算对比度 在我们的样式设计中,通常会有背景色和前景色的概念。前景色我们通常用来设置文本的颜色,而背景色通常是文本的所在容器的颜色。比如如果我们把文本放在普通容器里,那普通容器…...
)
Java 面向对象 - 触发类的初始化,执行其中的 static 块(包含不会触发初始化的情况)
触发类的初始化,执行其中的 static 块 访问 static 字段 public class SomeClass {static {System.out.println("static block executed");}public static int num 100; }int num SomeClass.num;访问 static 方法,可以使用空方法(…...
及72小时补救路径)
企业AI项目紧急叫停!DeepSeek许可证新增限制条款(2024.06.18生效)及72小时补救路径
更多请点击: https://kaifayun.com 第一章:DeepSeek许可证紧急变更事件全景速览 2024年7月12日,DeepSeek官方突然宣布对其开源模型系列(包括DeepSeek-V2、DeepSeek-Coder、DeepSeek-MoE等)的许可证进行紧急修订&#…...

Windows热键冲突终结者:Hotkey Detective一键定位占用程序
Windows热键冲突终结者:Hotkey Detective一键定位占用程序 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是…...

长期使用Taotoken的Token Plan套餐在成本控制上的实际效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken的Token Plan套餐在成本控制上的实际效果 在项目开发与测试阶段,模型API的调用成本是团队需要持续关注…...

5分钟快速上手:通达信缠论可视化插件ChanlunX实战指南
5分钟快速上手:通达信缠论可视化插件ChanlunX实战指南 【免费下载链接】ChanlunX 缠中说禅炒股缠论可视化插件 项目地址: https://gitcode.com/gh_mirrors/ch/ChanlunX 你是否为复杂的缠论分析感到头疼?面对密密麻麻的K线图,如何快速识…...

XCOM 2模组管理器终极指南:为什么AML是你的最佳选择?
XCOM 2模组管理器终极指南:为什么AML是你的最佳选择? 【免费下载链接】xcom2-launcher The Alternative Mod Launcher (AML) is a replacement for the default game launchers from XCOM 2 and XCOM Chimera Squad. 项目地址: https://gitcode.com/gh…...

Photoshop到URP的法线验证闭环:跨引擎法线贴图精准调试指南
1. 这不是个“一键生成法线”的玩具,而是一套跨引擎、跨工作流的材质验证闭环你有没有遇到过这样的情况:在 Photoshop 里辛苦调出一张完美的 Normal Map,导入 Unity 后却发现高光方向反了、边缘发灰、贴图在 Decal 上拉伸变形,甚至…...

网页视频抓取终极指南:猫抓工具让你轻松收藏全网精彩内容
网页视频抓取终极指南:猫抓工具让你轻松收藏全网精彩内容 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 还在为网页上的精彩视频无法保…...

我用AI一周做了个口播视频平台,现在开源了
做独立开发这两年,我一直在想一个问题:一个人到底能做到什么程度? 上周我给出了自己的答案——我用 DeepSeek 定义需求 CodeBuddy 辅助编码,一个人从零搞了一个 AI 口播视频生成平台,取名智播坊。输入文案࿰…...

惠普tank 2606屏幕显示 er-08 ,加了粉还是报错er08,黄灯闪烁成像鼓接近寿命期限?亲测完美修复。
下载:点这里下载 备用下载:https://pan.baidu.com/s/1J7PN4m4fbIzku9DqBFg_nw?pwd0000...