flink 内存配置(五):网络缓存调优
flink 内存配置(一):设置Flink进程内存
flink 内存配置(二):设置TaskManager内存
flink 内存配置(三):设置JobManager内存
flink 内存配置(四):内存调优和问题处理
flink 内存配置(五):网络缓存调优
1. Network Buffer总览
Flink中的每条记录都会与网络缓冲区(network buffer)中的其他记录一起发送给下一个子任务,网络缓冲区是子任务之间通信的最小单位。为了保持一致的高吞吐量,Flink在传输过程的输入和输出侧使用网络缓冲队列(也被称为传输中数据 in-flight data)。
每个子任务都有一个等待消费数据的输入队列和一个等待将数据发送到下一个子任务的输出队列。拥有更多的传输中数据(in-flight data)意味着Flink可以在管道中提供更高、更有弹性的吞吐量。然而,这将导致检查点时间更长。
Flink中的检查点只能在所有子任务接收到所有注入的检查点屏障(checkpoint barriers)后才能完成。在对齐的检查点中,这些检查点屏障与网络缓冲区一起在作业图中移动。传输中的数据量越大,检查点屏障传播时间越长。在未对齐的检查点中,传输中的数据量越大,检查点的大小就越大,因为所有捕获的传输中数据都必须作为检查点的一部分进行持久化。
2. 缓冲区去膨胀(debloat)机制
在以前,配置传输中数据量的唯一方法是指定缓冲区数量和缓冲区大小。然而,理想值可能很难选择,因为它们对于每个部署应用都是不同的。Flink 1.14中添加的缓冲区去膨胀机制试图通过自动将传输中的数据量调整到合理的值来解决这个问题。
缓冲区去膨胀功能计算子任务的最大可能吞吐量(在它总是繁忙的情况下),并调整正在传输的数据量,使这些正在传输数据的消耗时间等于配置值。
通过将属性taskmanager.network.memory.buffer-debloat.enabled设置为true,可以启用缓冲区去膨胀机制。可以通过属性 taskmanager.network.memory.buffer-debloat.target配置传输中数据的目标消耗时间。buffer-debloat.target配置的默认值应该要适应大多数的情况。
此功能使用过去的吞吐量数据来预测消耗剩余传输中数据所需的时间。如果预测不正确,去膨胀机制可能会以以下两种方式之一失败:
- 没有足够的缓冲数据来提供完整的吞吐量。
- 缓存的传输中数据过多,会对对齐检查点屏障的传播时间或非对齐检查点大小产生负面影响。
如果你有一个负载会随着时间变化的作业(比如输入的记录突然激增,周期性地触发窗口聚合或连接),你可能就需要调整以下设置:
- taskmanager.network.memory.buffer-debloat.period - 这是重新计算缓冲区大小的最小时间间隔。周期越短,去膨胀机制的反应时间越快,但所需计算的CPU开销越高。
- taskmanager.network.memory.buffer-debloat.samples - 调整吞吐量测量的平均样本数量。收集样本的频率可以通过taskmanager.network.memory.buffer-debloat.period进行调整。样本越少,去膨胀机制的反应时间越快,但吞吐量突然上升或下降的可能性越大,这可能导致缓冲区去膨胀机制错误计算最佳传输数据量。
- taskmanager.network.memory.buffer-debloat.threshold-percentages - 防止频繁改变缓冲区大小的优化(例如,如果新的大小与旧的大小没有太大的不同)。
以下是可用于监控当前缓冲区大小的指标:
- estimatedTimeToConsumeBuffersMs - 消耗所有输入通道数据的总时间
- debloatedBufferSize - 当前缓冲区大小
3. 限制
目前,有一些情况不是由缓冲区去膨胀机制自动处理的。
Multiple inputs and unions
目前,吞吐量计算和缓冲区去膨胀都发生在子任务级别。
如果你的子任务有多个不同的输入,或者只有一个但是是union的输入,那么缓冲区去膨胀可能会导致低吞吐量的输入有太多缓冲的传输中数据,而高吞吐量的输入可能有太小的缓冲区,无法维持该吞吐量。如果不同的输入具有不同的吞吐量,这可能特别明显。我们建议在测试此功能时特别注意此类子任务。
Buffer size and number of buffers
当前,缓冲区去膨胀只会限制使用的最大缓冲区大小。实际的缓冲区大小和缓冲区数量保持不变。这意味着去膨胀机制不能减少作业的内存使用。你必须手动减少缓冲区的数量或大小。
此外,如果你希望将缓冲的传输数据量减少到缓冲区去膨胀当前允许的范围以下,则可能需要手动配置缓冲区的数量。
High parallelism
目前,使用默认配置,缓冲区去膨胀机制可能无法在高并行性(高于~200)下正确执行。如果你观察到吞吐量降低或检查点时间高于预期,我们建议将浮动缓冲区的数量(taskmanager.network.memory.floating-buffers-per-gate)从默认值增加到至少等于并行度的数量。
该问题发生的并行性的实际值因作业而异,但通常应该超过几百。
4. Network Buffer生命周期
Flink有几个本地缓冲池(buffer pools)——一个用于输出流,一个用于每个输入门。每个缓冲池的目标大小由以下公式计算:
channels * taskmanager.network.memory.buffers-per-channel + taskmanager.network.memory.floating-buffers-per-gate
缓冲区的大小可以通过设置taskmanager.memory.segment-size来配置。
输入网络缓冲区
目标缓冲池的大小并不总是达到。有一个阈值控制着Flink在无法获得缓冲区时是否会失败。在缓冲区的目标数目中,低于该阈值的部分被认为是必需的。剩下的(如果有的话)是可选的。没有获得所需的缓冲区将导致任务失败。如果无法获得可选的缓冲区,任务不会失败,但可能会降低性能。
这个阈值的默认值是Integer.MAX_VALUE用于流工作负载,1000用于批处理工作负载。我们不建议用户改变这个阈值,除非用户有很好的理由并且知道他/她做得很好。相关的配置选项是taskmanager.network.memory.read-buffer.required-per-gate.max。一般来说,阈值越小,出现“insufficient number of network buffers”异常的可能性越小,而工作负载可能会悄无声息地受到性能影响,反之亦然。
输出网络缓冲区
与输入缓冲池不同,输出缓冲池只有一种类型的缓冲区,它在所有子分区之间共享。
为了避免过度的数据倾斜,每个子分区的缓冲区数量受到taskmanager.network.memory.max-buffers-per-channel设置的限制。
与输入缓冲池不同,配置的独占缓冲区和浮动缓冲区的数量只被视为推荐值。如果没有足够的缓冲区可用,Flink可以在每个输出子分区只有一个独占缓冲区、没有浮动缓冲区的情况下继续工作。
透支缓冲区
对于每个输出子任务,也可以请求taskmanager.network.memory.max-overdraft-buffers-per-gate(默认为5)额外的透支缓冲区。只有当子任务受到下游子任务的反向压力,并且子任务需要多个网络缓冲区来完成其当前工作时,才会使用这些缓冲区。这种情况可能发生在:
- 序列化一个网络缓冲区容纳不了的非常大的记录。
- 类似于Flat Map操作符,每个输入记录产生许多输出记录。
- 周期性地或根据某些事件(例如WindowOperator的触发器)输出许多记录的操作符。
在这种情况下,如果缓冲区没有透支,Flink的子任务线程就会因为负载压力而阻塞,从而导致未对齐的检查点无法完成。为了缓解这个问题,我们添加了透支缓冲区的概念。这些透支缓冲区是严格可选的,Flink可以逐步只使用普通缓冲区进行处理,这意味着对于taskmanager.network.memory.max-overdraft-buffers-per-gate来说,0是一个可以接受的配置。注意透支缓冲区只对 Pipelined Shuffle有用。
5. 传输种缓冲区的数量
独占缓冲区和浮动缓冲区的默认设置应足以满足最大吞吐量需求。如果需要设置最小的传输中数据量(in-flight data),可以将独占缓冲区设置为0,并减小内存段大小。
选择缓冲区大小
缓冲区收集记录,以便在将数据部分发送给下一个子任务时优化网络开销。下一个子任务应接收记录的所有部分,然后再使用它。
如果缓冲区大小过小,或者缓冲区刷新过于频繁(通过execution.buffer-timeout配置参数设置),这可能会导致吞吐量下降,因为在Flink的运行时环境中,每个缓冲区的开销明显高于每条记录的开销。
一般来说,除非在实际工作负载中观察到网络瓶颈(下游操作符空闲、上游背压、输出缓冲区队列已满、下游输入队列为空),否则我们不建议考虑增加缓冲区大小或缓冲区超时。
如果缓冲区大小过大,可能会导致:
- 内存使用率高
- (针对未对齐检查点的)大量检查点数据
- (对齐检查点)的检查点时间较长
- 由于刷新后的缓冲区仅会发送部分填充的内容,导致执行缓冲区超时,从而造成分配的内存使用效率低下
选择缓冲区计数
缓冲区的数量由taskmanager.network.memory.buffers-per-channel和taskmanager.network.memory.floating-buffers-per-gate这两个设置来配置。
为了获得最佳吞吐量,我们建议使用默认的独占缓冲区和浮动缓冲区数量(除非您遇到限制情况)。如果传输中的数据量导致问题,建议启用缓冲区去膨胀功能。
你可以手动调整网络缓冲区的数量,但请考虑以下几点:
1. 你应该根据预期吞吐量(以字节/秒为单位)来调整缓冲区的数量。分配信用和发送缓冲区需要一些时间(大约是两个节点之间来回两次的消息传输)。延迟还取决于你的网络状况。
利用缓冲区的往返时间(在健康的本地网络中约为1毫秒)、缓冲区大小以及预期吞吐量,你可以通过以下公式计算出维持该吞吐量所需的缓冲区数量:
缓冲区数量 = 预期吞吐量 * 缓冲区往返次数 / 缓冲区大小
例如,在预期吞吐量为320MB/s、往返延迟为1ms以及默认内存段大小的情况下,要实现预期吞吐量,需要10个活动使用的缓冲区:
缓冲区数量 = 320MB/s * 1ms / 32KB = 10
2. 浮动缓冲区的目的是处理数据倾斜的情况。理想情况下,属于该通道的浮动缓冲区(默认数量:8)和独占缓冲区(默认数量:2)的数量应足以满足网络吞吐量。但这并不总是可行或必要的。在任务管理器中的所有子任务中,仅使用一个通道的情况非常罕见。
3. 独占缓冲区的目的是为了提供流畅的数据吞吐量。当一个缓冲区正在传输数据时,另一个缓冲区正在被填充。在高吞吐量设置中,独占缓冲区的数量是决定Flink使用的在途数据量的主要因素。
在低吞吐量设置中遇到背压时,您应考虑减少专用缓冲区的数量。
总结
通过启用缓冲区去膨胀机制,可以简化Flink中网络的内存配置调优。您可能需要对其进行调优。
如果这不起作用,你可以禁用缓冲区去膨胀机制,并手动配置内存段大小和缓冲区数量。对于第二种情况,我们建议:
- 使用最大吞吐量的默认值
- 减小内存段大小和/或减少独占缓冲区数量,以加快检查点操作速度并降低网络堆栈的内存消耗
相关文章:
:网络缓存调优)
flink 内存配置(五):网络缓存调优
flink 内存配置(一):设置Flink进程内存 flink 内存配置(二):设置TaskManager内存 flink 内存配置(三):设置JobManager内存 flink 内存配置(四)…...

set和map的使用
目录 1.关联式容器 2.键值对 3.set 3.1set的模版参数列表 3.2对set的修改 3.2.1insert 3.2.2 erase 3.2.3clear 3.2.4swap 3.2.5 find 3.3set的迭代器 3.4set的容量 4.map 4.1对map的修改 4.1.1insert 4.1.2erase 4.1.3swap 4.1.4clear 4.2map的迭代器 4.3opera…...

LCL三相并网逆变器simulink仿真+说明文档
背景描述: 详细解析了LCL三相并网逆变器的工作原理,强调了准PR比例谐振控制的重要性,讨论了电感、电容参数选择及保护电路设计。通过仿真结果展示了逆变器性能优化的方法,以提升系统效率和稳定性。 模型介绍: 整体模…...

从0开始深度学习(24)——填充和步幅
1 填充 在上一节中,我们的卷积步骤如下: 可以发现输入是 3 3 3\times3 33,输出是 2 2 2\times2 22,这样可能会导致原始图像的边界丢失了许多有用信息,如果应用多层卷积核,累积丢失的像素就更多了&#…...

CPU Study - Instructions Fetch
参考来源:《超标量处理器设计》—— 姚永斌 N-Way CPU 取指问题 如果CPU可以在每个周期内同时解码N条指令,则此类CPU为N-Way超标量处理器。 N-Way超标量处理器需要每个周期从I-Cache中至少取得N条指令,这N条指令成为一组Fetch Group。 为了…...
 Round 1~7)
GJ Round (2024.9) Round 1~7
前言: 点此返回 GJ Round 目录 博客园可能食用更佳 Round 1 (9.10) A 洛谷 P10059 Choose 不难发现结论:记长度为 L L L 时对应的 X X X 最大值为 f ( L ) f(L) f(L),则 f ( L ) f(L) f(L) 单调不降 那么就可以考虑使用二分求出最小的…...
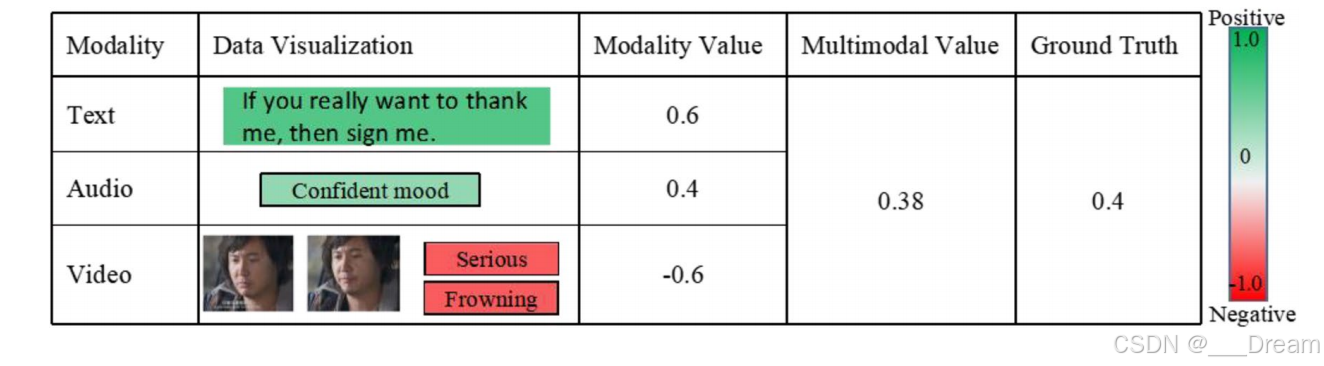
【CMCL】多模态情感识别的跨模态对比学习
abstract 近年来,多模态情感识别因其能够通过整合多模态信息来提高情感识别的准确性而受到越来越多的关注。然而,模态差异导致的异质性问题对多模态情感识别提出了重大挑战。在本文中,我们提出了一个新的框架——跨模态对比学习(…...

输入/输出系统
一、I/O 系统基本概念(了解即可) 1. 输入/输出系统 【总结】: “I/O” 就是 “输入 / 输出”(Input/Output),I/O 设备就是可以将数据输入到计算机,或者可以接收计算机输出数据的外部设备。 输…...

asp.net+uniapp养老助餐管理系统 微信小程序
文章目录 项目介绍具体实现截图技术介绍mvc设计模式小程序框架以及目录结构介绍错误处理和异常处理java类核心代码部分展示详细视频演示源码获取 项目介绍 以往流浪猫狗的救助网站相关信息的管理,都是工作人员手工统计。这种方式不但时效性低,而且需要查…...

部署istio应用未能产生Envoy sidecar代理
1. 问题描述及原因分析 在部署Prometheus、Grafana、Zipkin、Kiali监控度量Istio的第2.2章节,部署nginx应用,创建的pod并没有产生Envoy sidecar代理,仅有一个应用容器运行中 故在随后的prometheus中也没有产生指标istio_requests_total。通…...

使用YOLO 模型进行线程安全推理
使用YOLO 模型进行线程安全推理 一、了解Python 线程二、共享模型实例的危险2.1 非线程安全示例:单个模型实例2.2 非线程安全示例:多个模型实例 三、线程安全推理3.1 线程安全示例 四、总结4.1 在Python 中运行多线程YOLO 模型推理的最佳实践是什么&…...
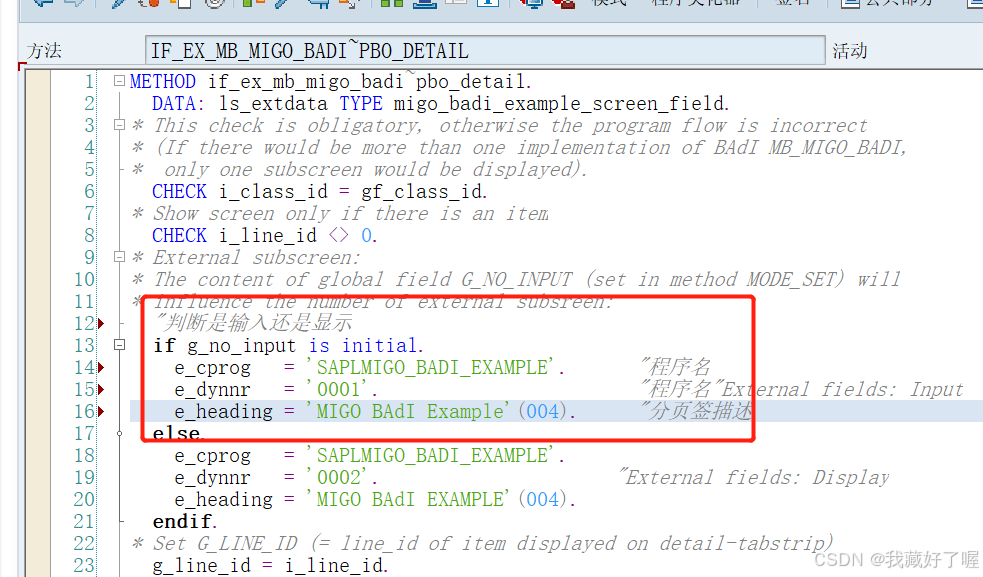
ABAP 增强
一、增强 基于SAP源代码的增强:对SAP所预留的空的子过程进行编码,用户可以编辑此子过程,并在这个子过程中添加自定义的代码,以增加SAP标准程序的控制功能 PERFORM 基于函数的增强:SAP为此类出口提供了相应的函数&am…...

vue使用方法创建组件
vue 中 创建 组件 使用 方法创建组件 vue2 中 import vueComponent from xxxx function createFn(){const creator Vue.extend(vueComponent);const instance new creator();document.appendChild(instance.$el); }vue3 中 import { createApp } from "vue"; im…...

HTML 基础标签——链接标签 <a> 和 <iframe>
文章目录 1. `<a>` 标签属性详细说明示例2. `<iframe>` 标签属性详细说明示例注意事项总结链接标签在HTML中是实现网页导航的重要工具,允许用户从一个页面跳转到另一个页面或嵌入外部内容。主要的链接标签包括 <a> 标签和<iframe> 标签。本文将深入探…...

@SpringBootApplication源码解析
1 简介 1.1 什么是自动装配? 自动装配是指 Spring Boot 在启动时,根据类路径上的依赖项自动配置应用程序。例如,如果你的应用程序依赖于 Spring Data JPA,Spring Boot 会自动配置一个 DataSource、EntityManagerFactory 和其他必…...

【实战篇】requests库 - 有道云翻译爬虫 【附:代理IP的使用】
目录 〇、引言一、目标二、请求参数分析三、响应分析四、编写爬虫脚本【隧道代理的使用】 〇、引言 无论是学习工作、旅游出行、跨境电商、日常交流以及一些专业领域都离不开翻译工具的支持。本文就带大家通过爬虫的方式开发一款属于自己的翻译工具~ 一、目标 如下的翻译接口…...

法语动词变位
法语动词变位是法语语法的核心内容之一,因为法语动词的形式会根据人称(谁做某事)、时态(动作发生的时间)、语气(说话人的态度)和语态(动作的执行者和接受者)发生变化。接…...

Excel:vba实现批量插入图片
实现的效果: 实现的代码: Sub InsertImageNamesAndPictures()Dim PicPath As StringDim PicName As StringDim PicFullPath As StringDim RowNum As IntegerDim Pic As ObjectDim Name As String 防止表格里面有脏数据Cells.Clear 遍历工作表中的每个图…...

Vue3的router和Vuex的学习笔记整理
一、路由的基本搭建 1、安装 npm install vue-router --registryhttps://registry.npmmirror.com 2、配置路由模块 第一步:src/router/index.js创建文件 第二步:在src/view下面创建两个vue文件,一个叫Home.vue和About.vue 第三步&#x…...

设置JAVA以适配华为2288HV2服务器的KVM控制台
华为2288HV2服务器比较老旧了,其管理控制台登录java配置比较麻烦,华为的ibmc_kvm_client_windows客户端测试了几个版本,连接控制台也有问题,最终安装JDK解决。 一、测试环境 主机为WindowsServer2012R2,64位系统 二、Java软件包…...

Frida检测绕过本质:四大系统级锚点与工程化规避策略
1. 这不是“反检测”,而是对 Frida 运行机制的诚实理解很多人一看到“Frida 检测绕过”就本能地往“对抗”“隐藏”“伪装”上想,甚至直接去搜“frida hide”“frida stealth bypass”,结果踩进一堆过时、失效、逻辑错乱的 patch 坑里。我做过…...

终极显卡风扇控制指南:用FanControl彻底解决NVIDIA风扇异常
终极显卡风扇控制指南:用FanControl彻底解决NVIDIA风扇异常 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trendi…...
缺陷识别数据集,识别率99.1%,可识别卡死,锈迹,合格,凹痕缺陷,20580张图,支持yolo,coco json,voc xml,文末有模型训练代码)
带标注的焊接型球头杆端关节轴承(鱼眼接头)缺陷识别数据集,识别率99.1%,可识别卡死,锈迹,合格,凹痕缺陷,20580张图,支持yolo,coco json,voc xml,文末有模型训练代码
带标注的焊接型球头杆端关节轴承(鱼眼接头)缺陷识别数据集,识别率99.1%,可识别卡死,锈迹,合格,凹痕缺陷,20580张图,支持yolo,coco json,voc xml,文末有模型训练代码 …...

如何免费使用ColabFold进行蛋白质结构预测:面向新手的终极指南
如何免费使用ColabFold进行蛋白质结构预测:面向新手的终极指南 【免费下载链接】ColabFold Making Protein folding accessible to all! 项目地址: https://gitcode.com/gh_mirrors/co/ColabFold ColabFold蛋白质结构预测是生物信息学领域的一项革命性技术&a…...

解决VMware安装macOS后分辨率锁死的烦恼:手把手教你安装VMware Tools并自定义显示设置
突破VMware中macOS显示限制:从工具安装到完美适配的全流程指南 当你在VMware中成功安装macOS系统后,可能会立刻遇到一个令人沮丧的问题——屏幕分辨率被锁定在低分辨率状态,窗口无法自由缩放,操作体验大打折扣。这种显示限制不仅…...

WeChatFerry微信机器人完整指南:构建企业级智能自动化助手
WeChatFerry微信机器人完整指南:构建企业级智能自动化助手 【免费下载链接】WeChatFerry 微信机器人,可接入DeepSeek、Gemini、ChatGPT、ChatGLM、讯飞星火、Tigerbot等大模型。微信 hook WeChat Robot Hook. 项目地址: https://gitcode.com/GitHub_Tr…...
)
别再手动拼图了!用Godot4的TileMap快速搭建2D游戏场景(附图层与相机跟随技巧)
别再手动拼图了!用Godot4的TileMap快速搭建2D游戏场景(附图层与相机跟随技巧) 在独立游戏开发中,场景搭建往往是耗时最长的环节之一。许多新手开发者习惯用Sprite节点逐个摆放场景元素,这不仅效率低下,后期…...

创业团队如何建立技术文化
创业团队如何建立技术文化 前言 我们团队从3个人发展到10个人,文化问题开始凸显: 有人觉得应该追求代码完美,有人觉得快速上线更重要有人喜欢加班赶进度,有人坚持 Work-Life Balance有人保守求稳,有人激进创新 后来我意…...
)
【Game】Powerful——Martial Arts Challenge(6)
文章目录攻略关卡一(虎子)关卡二关卡三关卡四关卡五关卡六——奇穷妖魔羽灵火地仙人雷攻略 关卡一(虎子) 参战选手 出手顺序 关卡二 参战选手 出手顺序 关卡三 参战选手 出手顺序 上面是追求极限,但是没有容错率&…...

深度技术解析:Lenovo Legion Toolkit 高级性能调优与系统集成指南
深度技术解析:Lenovo Legion Toolkit 高级性能调优与系统集成指南 【免费下载链接】LenovoLegionToolkit Lightweight Lenovo Vantage and Hotkeys replacement for Lenovo Legion laptops. 项目地址: https://gitcode.com/gh_mirrors/le/LenovoLegionToolkit …...