[论文粗读][REALM: Retrieval-Augmented Language Model Pre-Training
引言
今天带来一篇检索增强语言模型预训练论文笔记——REALM: Retrieval-Augmented Language Model Pre-Training。这篇论文是在RAG论文出现之前发表的。
为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。
语言模型预训练能够捕获世界知识,但这些知识隐含地存储在神经网络的参数中。为了以更模块化和可解释性的方式捕获知识,我们在语言模型预训练中加入了一个潜在知识检索器,允许模型在预训练、微调和推理过程中检索和关注来自大型语料库的文档。
1. 总体介绍
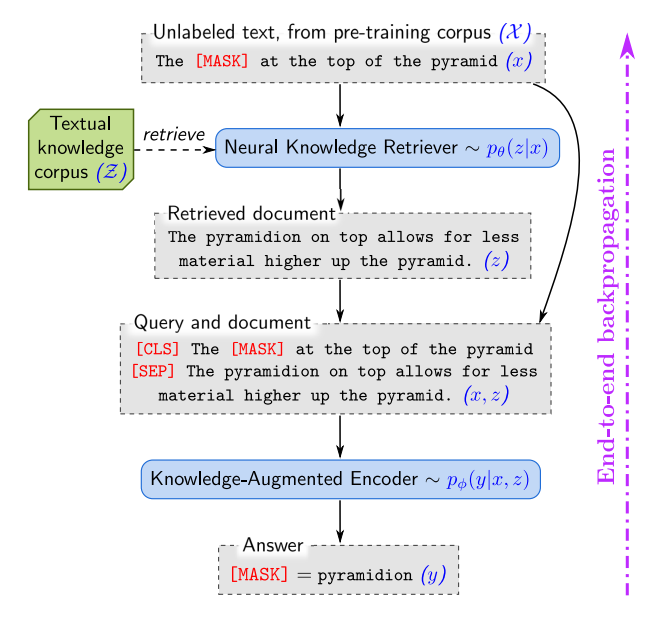
图 1. REALM 通过一个神经知识检索器增强了语言模型的预训练,该检索器从文本知识库 Z \mathcal Z Z中检索知识。语言建模目标的信号反向传播到检索器,检索器必须考虑 Z \mathcal Z Z 中的数百万个文档——这是一个我们解决的重大计算挑战。
为了以更可解释和模块化的方式捕捉知识,我们提出了一种新颖的框架,检索增强语言模型(Retrieval-Augmented Language Model, REALM)预训练,通过学习文本知识检索器来增强语言模型预训练算法。这种方法要求模型在推理过程汇总决定要检索和使用哪些知识来明确地揭示世界知识的作用。每次预测之前,语言模型使用检索器从维基百科等大型语料库中检索文档,然后关注这些文档以帮助其预测。学习这个模型的端到端需要通过考虑整个文本知识语料库的检索步骤进行反向传播,如图1所示。
在预训练期间整合大规模神经检索模块是一个大的计算挑战,因为检索器必须在每个预训练步骤中考虑数百万个候选文档。为了解决这个问题,我们构建检索器使得对每个文档执行的计算可以被缓存并异步更新,并且最佳文档的旋转可以被表述为最大内积搜索(Maximun Inner Product Search, MIPS)。
2. 背景知识
我们关注BERT的掩码语言建模(MLM)变体,用于预测输入文本段落中缺失的标记。
专注于利用文本知识库 Z \mathcal Z Z作为知识来源的开放式问答系统,给定一个问题 x x x,从知识库 Z \mathcal Z Z中检索可能相关的文档 z z z,然后从这些文档中提取答案 y y y。
3. 方法
3.1 REALM的生成过程
在预训练和微调中,REALLM都接收一些输入 x x x并学习一个关于可能输出 y y y的分布 p ( y ∣ x ) p(y|x) p(y∣x)。在预训练中,任务是掩码语言建模: x x x是来自预训练语料库 X \mathcal X X的一个句子,其中一些词被掩码,模型必须预测这些缺失词的值 y y y。任务是开放式问答: x x x是问题, y y y是答案。
将 p ( y ∣ x ) p(y|x) p(y∣x)分解为两个步骤:检索和预测。给定输入 x x x,从知识库 Z \mathcal Z Z中检索可能有帮助的文档 z z z,将此建模为从分布 p ( z ∣ x ) p(z|x) p(z∣x)中采样。然后,根据检索到的 z z z和原始输入 x x x来生成输出 y y y,建模为 p ( y ∣ z , x ) p(y|z,x) p(y∣z,x),将 z z z视为一个隐含变量,并在所有可能的文档 z z z上进行边缘化:
p ( y ∣ x ) = ∑ z ∈ Z p ( y ∣ z , x ) p ( z ∣ x ) (1) p(y|x) = \sum_{z \in \mathcal Z} p(y|z,x)p(z|x) \tag 1 p(y∣x)=z∈Z∑p(y∣z,x)p(z∣x)(1)
3.2 模型架构
神经知识检索器对 p ( z ∣ x ) p(z|x) p(z∣x)进行建模;知识增强编码器对 p ( y ∣ z , x ) p(y|z,x) p(y∣z,x)进行建模。
知识检索器 使用密集内积建模定义:
p ( z ∣ x ) = exp f ( x , z ) ∑ z ′ exp f ( x , z ′ ) f ( x , z ) = Embed input ( x ) ⊤ Embed doc ( z ) p(z|x) = \frac{\exp f(x,z)}{\sum_{z^\prime} \exp f(x,z^\prime)} \\ f(x,z) = \text{Embed}_\text{input}(x)^\top \text{Embed}_\text{doc}(z) p(z∣x)=∑z′expf(x,z′)expf(x,z)f(x,z)=Embedinput(x)⊤Embeddoc(z)
其中 Embed input \text{Embed}_\text{input} Embedinput和 Embed doc \text{Embed}_\text{doc} Embeddoc是将 x x x和 z z z分别映射到 d d d维向量空间的嵌入函数; x x x和 z z z之间的相关性分数定义为向量嵌入的内积。
使用BERT实现嵌入函数,通过将 文本片段连接起来,用[SEP]标记分隔它们,在前面加上[CLS]标记,并在最后附加一个[SEP]标记:
join BERT ( x ) = [CLS] x [SEP] join BERT ( x 1 , x 2 ) = [CLS] x 1 [SEP] x 2 [SEP] \text{join}_\text{BERT} (x) = \text{[CLS]}x\text{[SEP]}\\ \text{join}_\text{BERT} (x_1,x_2) = \text{[CLS]}x_1\text{[SEP]}x_2\text{[SEP]} joinBERT(x)=[CLS]x[SEP]joinBERT(x1,x2)=[CLS]x1[SEP]x2[SEP]
然后将此输入到BERT总,为每个词元生成一个向量,用[CLS]对应的向量做序列的池化表示。最后,执行线性投影以降低向量的维数,表示为投影矩阵 W W W:
Embed input ( x ) = W input BERT CLS ( join BERT ( x ) ) Embed doc ( x ) = W doc BERT CLS ( join BERT ( z title , z body ) ) \text{Embed}_\text{input} (x) =W_\text{input}\text{BERT}_\text{CLS}(\text{join}_\text{BERT}(x)) \\ \text{Embed}_\text{doc} (x) =W_\text{doc}\text{BERT}_\text{CLS}(\text{join}_\text{BERT}(z_\text{title},z_\text{body})) Embedinput(x)=WinputBERTCLS(joinBERT(x))Embeddoc(x)=WdocBERTCLS(joinBERT(ztitle,zbody))
其中 z title z_\text{title} ztitle是文档的标记; z body z_\text{body} zbody是正文;用 θ \theta θ表示与检索器相关的所有参数。
知识增强编码器 给定一个输入 x x x和检索到的文档 z z z,知识增强编码器定义了 p ( y ∣ z , x ) p(y|z,x) p(y∣z,x),我们将 x x x和 z z z合并成一个单一序列,并将其输入到Transformer中。这使我们能在预测 y y y之前,在 x x x和 z z z之间执行丰富的交叉注意力,如图1所示。
在该阶段,预训练和微调的架构略有不同,对于掩码语言模型预训练任务,我们必须预测 x x x中每个[MASK]标记的原始值,为此我们使用掩码语言建模损失:
p ( y ∣ z , x ) = ∏ j = 1 J x p ( y j ∣ z , x ) p ( y j ∣ z , x ) ∝ exp ( w j ⊤ BERT MASK ( j ) ( join BERT ( x , z body ) ) ) p(y|z,x) = \prod_{j=1}^{J_x} p(y_j|z,x) \\ p(y_j|z,x) ∝ \exp(w_j^\top \text{BERT}_{\text{MASK}(j)}(\text{join}_\text{BERT}(x,z_\text{body}))) p(y∣z,x)=j=1∏Jxp(yj∣z,x)p(yj∣z,x)∝exp(wj⊤BERTMASK(j)(joinBERT(x,zbody)))
其中 BERT MASK ( j ) \text{BERT}_{\text{MASK}(j)} BERTMASK(j)表示对应于第j个掩码标记的Transformer输出向量; J x J_x Jx是 x x x中[MASK]标记的总数; w j w_j wj是针对标记 y j y_j yj学习到的词嵌入。
对于开放式问答微调,我们希望生成答案字符串 y y y。假设答案 y y y可以作为某个文档 z z z中的连续标记序列找到。令 S ( z , y ) S(z,y) S(z,y)为匹配 y y y在 z z z中的跨度的集合,可以定义 p ( y ∣ z , x ) p(y|z,x) p(y∣z,x)为:
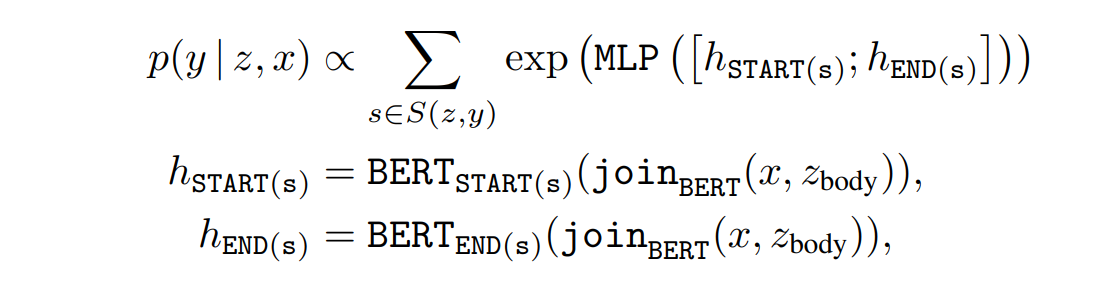
其中 BERT START ( s ) \text{BERT}_{\text{START}(s)} BERTSTART(s)和 BERT END ( s ) \text{BERT}_{\text{END}(s)} BERTEND(s)分别表示跨度 s s s的起始和结束标记对应的Transformer输出向量;MLP是一个前馈神经网络;用 ϕ \phi ϕ表示与知识增强编码器相关的所有参数。
3.3 训练
在预训练和微调中,通过最大化正确输出 y y y的对数似然 log p ( y ∣ x ) \log p(y|x) logp(y∣x)来训练。
关键的计算挑战在于边缘概率 p ( y ∣ x ) = ∑ z ∈ Z p ( y ∣ x , z ) p ( z ∣ x ) p(y|x)=\sum_{z \in \mathcal Z} p(y|x,z)p(z|x) p(y∣x)=∑z∈Zp(y∣x,z)p(z∣x)涉及对知识语料库 Z \mathcal Z Z中所有文档 z z z的求和。我们通过对 p ( z ∣ x ) p(z|x) p(z∣x)下概率最高的 k k k个文档进行求和来近似这个概率。
那我们需要一种有效方法来找到排名前 k k k的文档。文档在 p ( z ∣ x ) p(z|x) p(z∣x)下的排序与在相关性得分 f ( x , z ) = Embed input ( x ) ⊤ Embed doc ( z ) f(x,z)=\text{Embed}_\text{input}(x)^\top \text{Embed}_\text{doc}(z) f(x,z)=Embedinput(x)⊤Embeddoc(z)下的排序相同,后者是一个内积。因此我们可以使用最大内积搜索(Maximum Inner Product Search, MIPS)算法来找到近似的前 k k k个文档。
为了计算MIPS,我们预先计算每个 z ∈ Z z \in \mathcal Z z∈Z的 Embed doc ( z ) \text{Embed}_\text{doc}(z) Embeddoc(z),并在这些嵌入上构建一个高效的搜索索引。然而,如果 Embed doc ( z ) \text{Embed}_\text{doc}(z) Embeddoc(z)的参数 θ \theta θ之后更新了,那么这个数据结构将不再与 p ( z ∣ x ) p(z|x) p(z∣x)一致,因此,搜索索引在每次对 θ \theta θ进行梯度更新后都会过时。
我们的解决方案是通过异步重新嵌入和重新索引所有文档,每隔几百个训练步骤刷新一次索引。MIPS索引在刷新之间略微过时,但它仅用于选择前 k k k个文档。我们使用新的 θ \theta θ重新计算 p ( z ∣ x ) p(z|x) p(z∣x)及其梯度,用于检索到的前 k k k个文档。只要刷新频率足够高,该过程就能实现稳定的优化。
实现异步MIPS刷新 通过并行运行两个作业来异步刷新MIPS索引:一个主训练作业,它对参数执行梯度更新;一个辅助索引构建作业,它嵌入并索引文档。如下所示,训练器将参数的快照 θ ′ \theta^\prime θ′发送给索引构建器。然后训练器继续训练,而索引构建器使用 θ ′ \theta^\prime θ′在后台构建新索引。一旦索引构建完成,它会将新索引发送回训练器,然后重复该过程。
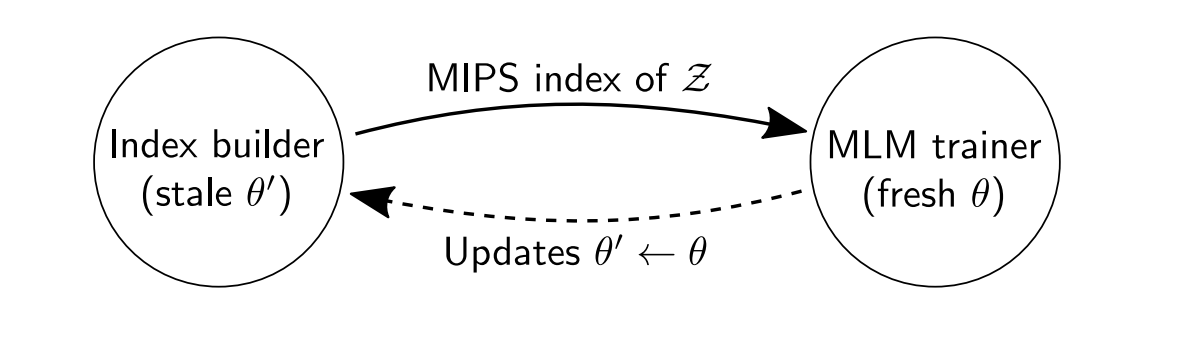
图 3. 使用异步 MIPS 刷新进行 REALM 预训练。
检索器学到了什么? 对于给定的查询 x x x和文档 z z z, f ( x , z ) f(x,z) f(x,z)是知识检索器分配给文档 z z z的相关性得分,可以通过分析关于知识检索器参数 θ \theta θ的梯度,来观察REALM预训练期间单步梯度下降如何改变该得分:
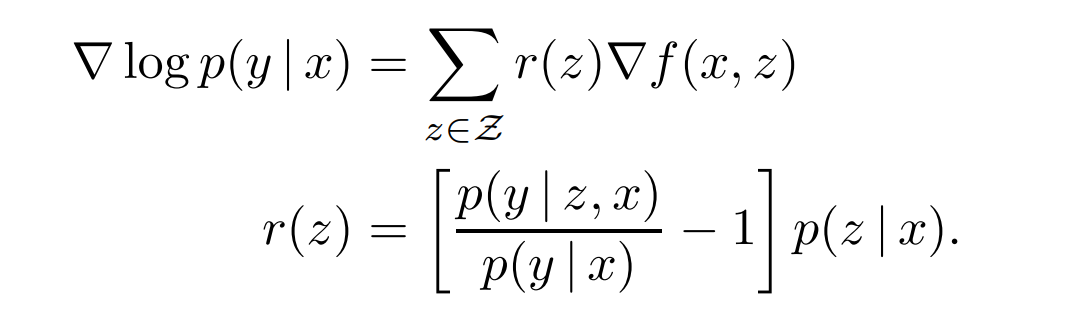
对于每个文档 z z z,梯度鼓励检索器通过 r ( z ) r(z) r(z)改变分数 f ( x , z ) f(x,z) f(x,z)——如果 r ( z ) r(z) r(z)为正则增加,否则减少。当且仅当 p ( y ∣ z , x ) > p ( y ∣ x ) p(y|z,x) > p(y|x) p(y∣z,x)>p(y∣x)时,乘数 r ( z ) r(z) r(z)为正。
p ( y ∣ z , x ) p(y|z,x) p(y∣z,x)表示使用文档 z z z时预测正确输出 y y y的概率; p ( y ∣ x ) p(y|x) p(y∣x)表示从 p ( z ∣ x ) p(z|x) p(z∣x)中随机抽取文档时, p ( y ∣ x , z ) p(y|x,z) p(y∣x,z)的期望值。因此,只要文档 z z z的表现超出预期,它就会收到正向更新。
3.4 在预训练中注入归纳偏差
显著跨度掩码 类似整词掩码,希望关注需要世界知识来预测掩码标记的示例 x x x,掩码了显著跨度(salient span),例如United Kingdom或1967年7月。
空文档 即使使用显著跨度,也并非所有被掩码的词元都需要世界知识来预测。通过在top k检索到的文档中添加一个空维度 ∅ \empty ∅来模拟这种情况,允许在不需要检索时将适当的credit分配给一致的汇聚点。
禁止琐碎检索 如果预训练语料库 X \mathcal X X和知识语料库 Z \mathcal Z Z相同,则存在一个过于信息丰富的琐碎(trivial)检索候选 z z z:如果掩码句子 x x x来自文档 z z z,则知识增强编码器可以通过查看 z z z中 x x x的未掩码版本来预测 y y y。这回导致知识检索器学会在 x x x和 z z z之间寻找精确的字符串匹配,而无法捕捉到其他形式的相关性。因此,在预训练期间排除了这种琐碎(微不足道)的候选者。
初始化 在训练开始时,如果检索器没有为 Embed input ( x ) \text{Embed}_\text{input}(x) Embedinput(x)和 Embed doc ( z ) \text{Embed}_\text{doc}(z) Embeddoc(z)生成好的嵌入,则检索到的文档 z z z很可能与 x x x无关。这会导致知识增强编码器学习忽略检索到的文档。为了避免这种冷启动问题,使用一个简单的训练目标,即逆向完形填空任务,对 Embed input \text{Embed}_\text{input} Embedinput和 Embed doc \text{Embed}_\text{doc} Embeddoc进行预热。在该任务重,给定一个句子,模型被训练以检索该句子来自的文档。
总结
⭐ 为了以更可解释和模块化的方式捕捉知识,作者提出了REALM预训练框架,通过学习文本知识检索器来增强语言模型预训练算法。
相关文章:
[论文粗读][REALM: Retrieval-Augmented Language Model Pre-Training
引言 今天带来一篇检索增强语言模型预训练论文笔记——REALM: Retrieval-Augmented Language Model Pre-Training。这篇论文是在RAG论文出现之前发表的。 为了简单,下文中以翻译的口吻记录,比如替换"作者"为"我们"。 语言模型预训练…...
:网络缓存调优)
flink 内存配置(五):网络缓存调优
flink 内存配置(一):设置Flink进程内存 flink 内存配置(二):设置TaskManager内存 flink 内存配置(三):设置JobManager内存 flink 内存配置(四)…...

set和map的使用
目录 1.关联式容器 2.键值对 3.set 3.1set的模版参数列表 3.2对set的修改 3.2.1insert 3.2.2 erase 3.2.3clear 3.2.4swap 3.2.5 find 3.3set的迭代器 3.4set的容量 4.map 4.1对map的修改 4.1.1insert 4.1.2erase 4.1.3swap 4.1.4clear 4.2map的迭代器 4.3opera…...

LCL三相并网逆变器simulink仿真+说明文档
背景描述: 详细解析了LCL三相并网逆变器的工作原理,强调了准PR比例谐振控制的重要性,讨论了电感、电容参数选择及保护电路设计。通过仿真结果展示了逆变器性能优化的方法,以提升系统效率和稳定性。 模型介绍: 整体模…...

从0开始深度学习(24)——填充和步幅
1 填充 在上一节中,我们的卷积步骤如下: 可以发现输入是 3 3 3\times3 33,输出是 2 2 2\times2 22,这样可能会导致原始图像的边界丢失了许多有用信息,如果应用多层卷积核,累积丢失的像素就更多了&#…...

CPU Study - Instructions Fetch
参考来源:《超标量处理器设计》—— 姚永斌 N-Way CPU 取指问题 如果CPU可以在每个周期内同时解码N条指令,则此类CPU为N-Way超标量处理器。 N-Way超标量处理器需要每个周期从I-Cache中至少取得N条指令,这N条指令成为一组Fetch Group。 为了…...
 Round 1~7)
GJ Round (2024.9) Round 1~7
前言: 点此返回 GJ Round 目录 博客园可能食用更佳 Round 1 (9.10) A 洛谷 P10059 Choose 不难发现结论:记长度为 L L L 时对应的 X X X 最大值为 f ( L ) f(L) f(L),则 f ( L ) f(L) f(L) 单调不降 那么就可以考虑使用二分求出最小的…...
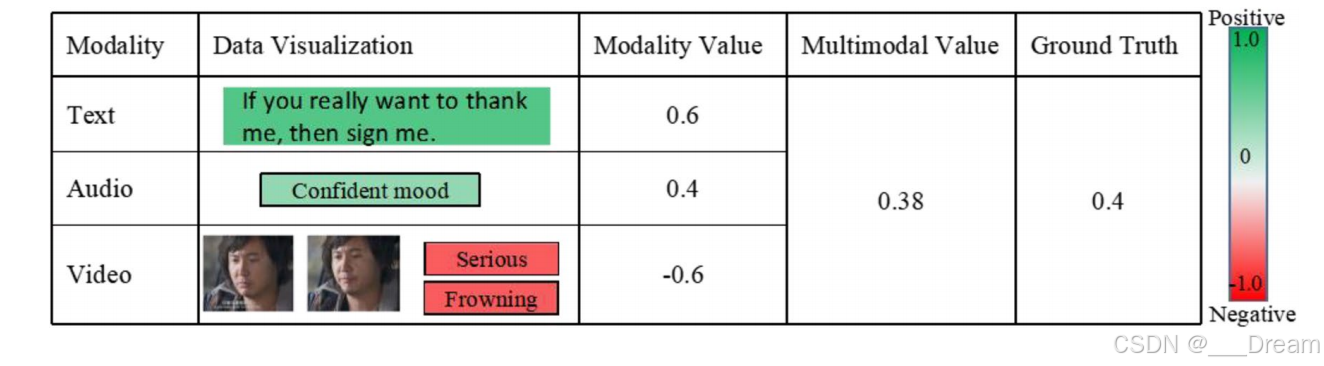
【CMCL】多模态情感识别的跨模态对比学习
abstract 近年来,多模态情感识别因其能够通过整合多模态信息来提高情感识别的准确性而受到越来越多的关注。然而,模态差异导致的异质性问题对多模态情感识别提出了重大挑战。在本文中,我们提出了一个新的框架——跨模态对比学习(…...

输入/输出系统
一、I/O 系统基本概念(了解即可) 1. 输入/输出系统 【总结】: “I/O” 就是 “输入 / 输出”(Input/Output),I/O 设备就是可以将数据输入到计算机,或者可以接收计算机输出数据的外部设备。 输…...

asp.net+uniapp养老助餐管理系统 微信小程序
文章目录 项目介绍具体实现截图技术介绍mvc设计模式小程序框架以及目录结构介绍错误处理和异常处理java类核心代码部分展示详细视频演示源码获取 项目介绍 以往流浪猫狗的救助网站相关信息的管理,都是工作人员手工统计。这种方式不但时效性低,而且需要查…...

部署istio应用未能产生Envoy sidecar代理
1. 问题描述及原因分析 在部署Prometheus、Grafana、Zipkin、Kiali监控度量Istio的第2.2章节,部署nginx应用,创建的pod并没有产生Envoy sidecar代理,仅有一个应用容器运行中 故在随后的prometheus中也没有产生指标istio_requests_total。通…...

使用YOLO 模型进行线程安全推理
使用YOLO 模型进行线程安全推理 一、了解Python 线程二、共享模型实例的危险2.1 非线程安全示例:单个模型实例2.2 非线程安全示例:多个模型实例 三、线程安全推理3.1 线程安全示例 四、总结4.1 在Python 中运行多线程YOLO 模型推理的最佳实践是什么&…...
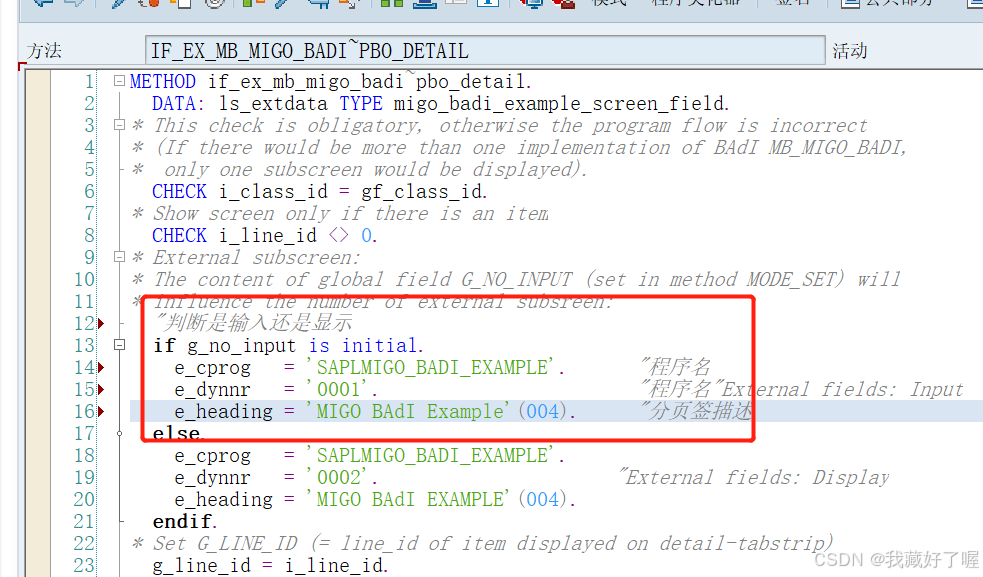
ABAP 增强
一、增强 基于SAP源代码的增强:对SAP所预留的空的子过程进行编码,用户可以编辑此子过程,并在这个子过程中添加自定义的代码,以增加SAP标准程序的控制功能 PERFORM 基于函数的增强:SAP为此类出口提供了相应的函数&am…...

vue使用方法创建组件
vue 中 创建 组件 使用 方法创建组件 vue2 中 import vueComponent from xxxx function createFn(){const creator Vue.extend(vueComponent);const instance new creator();document.appendChild(instance.$el); }vue3 中 import { createApp } from "vue"; im…...

HTML 基础标签——链接标签 <a> 和 <iframe>
文章目录 1. `<a>` 标签属性详细说明示例2. `<iframe>` 标签属性详细说明示例注意事项总结链接标签在HTML中是实现网页导航的重要工具,允许用户从一个页面跳转到另一个页面或嵌入外部内容。主要的链接标签包括 <a> 标签和<iframe> 标签。本文将深入探…...

@SpringBootApplication源码解析
1 简介 1.1 什么是自动装配? 自动装配是指 Spring Boot 在启动时,根据类路径上的依赖项自动配置应用程序。例如,如果你的应用程序依赖于 Spring Data JPA,Spring Boot 会自动配置一个 DataSource、EntityManagerFactory 和其他必…...

【实战篇】requests库 - 有道云翻译爬虫 【附:代理IP的使用】
目录 〇、引言一、目标二、请求参数分析三、响应分析四、编写爬虫脚本【隧道代理的使用】 〇、引言 无论是学习工作、旅游出行、跨境电商、日常交流以及一些专业领域都离不开翻译工具的支持。本文就带大家通过爬虫的方式开发一款属于自己的翻译工具~ 一、目标 如下的翻译接口…...

法语动词变位
法语动词变位是法语语法的核心内容之一,因为法语动词的形式会根据人称(谁做某事)、时态(动作发生的时间)、语气(说话人的态度)和语态(动作的执行者和接受者)发生变化。接…...

Excel:vba实现批量插入图片
实现的效果: 实现的代码: Sub InsertImageNamesAndPictures()Dim PicPath As StringDim PicName As StringDim PicFullPath As StringDim RowNum As IntegerDim Pic As ObjectDim Name As String 防止表格里面有脏数据Cells.Clear 遍历工作表中的每个图…...

Vue3的router和Vuex的学习笔记整理
一、路由的基本搭建 1、安装 npm install vue-router --registryhttps://registry.npmmirror.com 2、配置路由模块 第一步:src/router/index.js创建文件 第二步:在src/view下面创建两个vue文件,一个叫Home.vue和About.vue 第三步&#x…...

深度解析OBS Mac虚拟摄像头插件的架构设计与性能优化
深度解析OBS Mac虚拟摄像头插件的架构设计与性能优化 【免费下载链接】obs-mac-virtualcam ARCHIVED! This plugin is officially a part of OBS as of version 26.1. See note below for info on upgrading. 🎉🎉🎉Creates a virtual webcam…...

通过 curl 命令快速测试 Taotoken 各大模型接口连通性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过 curl 命令快速测试 Taotoken 各大模型接口连通性 在接入大模型服务时,直接使用 curl 命令进行接口测试是一种高效…...

显卡驱动清理终极指南:为什么你的系统需要Display Driver Uninstaller深度清理?
显卡驱动清理终极指南:为什么你的系统需要Display Driver Uninstaller深度清理? 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirr…...

如何完整破解Cursor Pro限制:终极免费激活方案全解析
如何完整破解Cursor Pro限制:终极免费激活方案全解析 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tria…...

OpenClaw 换 “大脑”!DeepSeek V4 默认集成,离线私有 AI 自由
OpenClaw 接入 DeepSeek 模型完整配置教程 一、前置准备 已安装并正常运行 OpenClaw Windows 客户端;OpenClaw 顶部 Gateway 状态保持在线;电脑网络正常,可稳定访问 DeepSeek 开放平台;准备可接收验证码的手机号或微信账号&…...
 的中间结果,怎么还能算对梯度?)
FlashAttention 反向传播:删掉 O(N²) 的中间结果,怎么还能算对梯度?
FlashAttention 反向传播:删掉 O(N) 的中间结果,怎么还能算对梯度? 之前有人跟我争:FlashAttention 反向传播不存注意力矩阵,那梯度从哪来?你前向传播的时候 Softmax 的分母、分子都扔了,反向传…...

3分钟掌握Windows驱动管理的终极利器:DriverStore Explorer完全指南
3分钟掌握Windows驱动管理的终极利器:DriverStore Explorer完全指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦恼?是否发…...

Steam创意工坊下载难题终结者:WorkshopDL让你的模组下载从未如此简单
Steam创意工坊下载难题终结者:WorkshopDL让你的模组下载从未如此简单 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为想玩Steam创意工坊的模组却没有Steam账号…...

DownGit:3分钟掌握GitHub精准下载的必备技能
DownGit:3分钟掌握GitHub精准下载的必备技能 【免费下载链接】DownGit github 资源打包下载工具 项目地址: https://gitcode.com/gh_mirrors/dow/DownGit 还在为下载GitHub上的单个文件而烦恼吗?每次都需要克隆整个仓库,占用大量磁盘空…...

Scarab终极教程:2024年最完整的空洞骑士模组管理器使用指南
Scarab终极教程:2024年最完整的空洞骑士模组管理器使用指南 【免费下载链接】Scarab An installer for Hollow Knight mods written with Avalonia. 项目地址: https://gitcode.com/gh_mirrors/sc/Scarab 还在为空洞骑士模组安装而烦恼吗?Scarab模…...