【机器学习】聚类算法分类与探讨
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢迎在文章下方留下你的评论和反馈。我期待着与你分享知识、互相学习和建立一个积极的社区。谢谢你的光临,让我们一起踏上这个知识之旅!

文章目录
- 🍋聚类算法基础
- 🍋K均值聚类算法
- 🍋DBSCAN及其派生算法
- 🍋AGNES(自底向上聚类)算法
- 🍋聚类评估指标
- 🍋示例完整代码(CoNLL-2003数据集)
- 🍋总结
🍋聚类算法基础
- 定义及重要性:聚类是一种无监督的机器学习方法,旨在将数据集划分为若干簇,使得同一簇内的数据点相似度高,不同簇之间的数据点差异大。聚类在客户分群、图像分割、文本分类和生物信息学等领域有广泛应用。
- 聚类算法的种类:
- 划分式算法(如K均值):基于数据点之间的距离,直接将数据划分为若干簇。
- 密度式算法(如DBSCAN):根据数据密度分布,将密度较高的区域识别为簇。
- 层次式算法(如AGNES):通过层次结构进行聚类,可以生成树状的层次结构。
- 网格式算法:将空间划分为网格,以网格为单位进行聚类(如CLIQUE算法)。
🍋K均值聚类算法
-
概述:K均值是一种基于划分的方法。首先选择K个初始质心,然后通过迭代优化,将每个数据点分配到距离最近的质心,更新质心位置,直到收敛。其目标是最小化簇内的方差。
-
工作原理:
- 选择K个初始质心。
- 计算每个数据点与质心的距离,将数据点分配到最近的质心所在的簇中。
- 更新每个簇的质心,重新计算每个簇的平均值。
- 重复步骤2和3,直到质心位置不再变化或达到最大迭代次数。
-
优缺点:K均值在处理大规模数据时效率高,但其对初始质心的选择敏感,可能陷入局部最优;另外,K的值需要提前确定。
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np# 生成一些示例数据
X = np.random.rand(100, 2)# 初始化K均值模型
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(X)# 获取聚类结果
labels = kmeans.labels_# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels)
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=300, c='red', marker='X')
plt.title("K-Means Clustering")
plt.show()
扩展:可进一步介绍K均值++初始化方法(K-means++),通过优化初始质心选择来提高收敛性和结果质量。
🍋DBSCAN及其派生算法
-
概述:DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,通过定义邻域半径(eps)和最小样本数(min_samples)来识别簇。密度足够高的区域被识别为簇,而密度不足的点则被视为噪声。
-
工作原理:
- 对于每个点,如果在其邻域半径内的点数超过min_samples,则将其标记为核心点。
- 将核心点的邻域扩展为一个簇,将所有能够通过密度连接的点归入此簇。
- 重复此过程,直到所有点都被分配到某个簇或标记为噪声。
-
优缺点:DBSCAN能够识别任意形状的簇,适合含有噪声的数据集,但对参数eps和min_samples敏感。
from sklearn.cluster import DBSCAN
import matplotlib.pyplot as plt
import numpy as np# 生成一些示例数据
X = np.random.rand(100, 2)# 初始化DBSCAN模型
dbscan = DBSCAN(eps=0.1, min_samples=5)
dbscan.fit(X)# 获取聚类结果
labels = dbscan.labels_# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels)
plt.title("DBSCAN Clustering")
plt.show()
派生算法:可介绍HDBSCAN(基于密度的层次聚类算法),它能在不同密度下自动调节,适用于密度变化较大的数据集。
🍋AGNES(自底向上聚类)算法
-
概述:AGNES(Agglomerative Nesting)是一种层次聚类算法,通过自底向上合并每个样本或簇,构建树状的层次结构。它不需要提前设定簇的数量。
-
工作原理:
- 将每个数据点视为一个独立的簇。
- 计算每对簇之间的距离,合并最近的两个簇。
- 重复步骤2,直到只剩下一个簇,或者达到预设的簇数。
-
连接方法:可以采用不同的连接方法,包括单连接(Single Linkage)、全连接(Complete Linkage)、平均连接(Average Linkage)和Ward连接。
from scipy.cluster.hierarchy import dendrogram, linkage
import matplotlib.pyplot as plt
import numpy as np# 生成一些示例数据
X = np.random.rand(10, 2)# 使用AGNES(层次聚类)
Z = linkage(X, method='ward')# 可视化层次聚类的树状图
plt.figure(figsize=(10, 5))
dendrogram(Z)
plt.title("AGNES Hierarchical Clustering Dendrogram")
plt.show()
扩展:还可以介绍如何确定层次聚类的最佳分割点,比如通过树状图的“拐点”或使用轮廓系数评估分割效果。
🍋聚类评估指标
常用指标:
- 轮廓系数(Silhouette Score):衡量簇内一致性和簇间分离度的指标,范围为-1到1,值越大越好。
- DBI指数(Davies-Bouldin Index):计算每个簇的离散性和簇间的相似性,值越小聚类效果越好。
- SSE(Sum of Squared Errors):用于K均值聚类,衡量簇内方差的总和。
from sklearn.metrics import silhouette_score# 计算轮廓系数
score = silhouette_score(X, labels)
print(f'Silhouette Score: {score}')
🍋示例完整代码(CoNLL-2003数据集)
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans, DBSCAN, AgglomerativeClustering
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import silhouette_score
from nltk.corpus import conll2003
from nltk import download# 下载 CoNLL-2003 数据集
download('conll2003')# 提取 CoNLL-2003 数据集
def load_conll_data():sentences = []for sentence in conll2003.iob_sents():words = [word for word, _, _ in sentence]sentences.append(" ".join(words))return sentences# 特征提取
def extract_features(texts):vectorizer = TfidfVectorizer(stop_words='english')return vectorizer.fit_transform(texts)# 聚类评估
def evaluate_clustering(model, X):labels = model.labels_ if hasattr(model, 'labels_') else model.predict(X)return silhouette_score(X, labels)# 加载数据
texts = load_conll_data()# 提取特征
X = extract_features(texts)# 初始化不同的聚类算法
kmeans = KMeans(n_clusters=5, random_state=42)
dbscan = DBSCAN(eps=0.5, min_samples=5)
agg_clustering = AgglomerativeClustering(n_clusters=5)# 聚类模型训练
kmeans.fit(X)
dbscan.fit(X)
agg_clustering.fit(X)# 聚类评估
kmeans_score = evaluate_clustering(kmeans, X)
dbscan_score = evaluate_clustering(dbscan, X)
agg_score = evaluate_clustering(agg_clustering, X)# 输出评估结果
print(f"K-means Silhouette Score: {kmeans_score:.4f}")
print(f"DBSCAN Silhouette Score: {dbscan_score:.4f}")
print(f"Agglomerative Clustering Silhouette Score: {agg_score:.4f}")
- CoNLL-2003 数据集:我们通过 nltk.corpus.conll2003 来加载 CoNLL-2003 数据集。每个句子的词语通过 iob_sents() 提取并合并成文本形式。
- 特征提取:我们使用 TfidfVectorizer 将文本转换为 TF-IDF 特征表示,移除英文停用词。
- 聚类算法:我们使用三种不同的聚类算法:
- K-means:我们指定 n_clusters=5(你可以根据需要调整)。
- DBSCAN:这里我们指定了 eps=0.5 和 min_samples=5,这两个参数可以调节以优化聚类效果。
- 层次聚类:使用 AgglomerativeClustering 进行层次聚类,并设置 n_clusters=5。
- 评估:使用 轮廓系数(Silhouette Score)来评估聚类效果。轮廓系数越接近 1 表示聚类效果越好,接近 -1 表示聚类效果差。
🍋总结
如何选择合适的聚类算法:
- 对于大规模、结构简单的数据集,K均值可能更合适。
- 含有噪声或非凸形状的数据集,DBSCAN表现较好。
- 层次结构明显或需要层次划分的数据,可以选择AGNES。
实际应用场景:
- 客户分群:使用K均值或层次聚类对客户数据进行分类,提供个性化服务。
- 图像分割:利用DBSCAN识别图像中的物体轮廓。
- 文本聚类:通过层次聚类对新闻或文档进行分组,形成主题集群。

挑战与创造都是很痛苦的,但是很充实。
相关文章:
【机器学习】聚类算法分类与探讨
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢…...

MySQL中distinct与group by之间的性能进行比较
在 MySQL 中,DISTINCT 和 GROUP BY 都是用于去重或汇总数据的常用 SQL 语法。尽管它们在某些情况下能产生相同的结果,但它们的内部工作方式和性能表现可能有所不同。理解这两者的差异,对于选择正确的语法非常重要,尤其是在处理大量…...

计算机视觉读书系列(1)——基本知识与深度学习基础
研三即将毕业,后续的工作可能会偏AI方向的计算机视觉方面,因此准备了两条线来巩固计算机视觉基础。 一个是本系列,阅读经典《Deep Learning for Vision System》,做一些总结跑一些例子,也对应本系列文章 二是OpenCV实…...

怎么查看navicat的数据库密码
步骤1:打开navicat连接数据库工具,顶部的文件栏-导出结果-勾选导出密码-导出 步骤2:导出结果使用NotePad或文本打开,找到,数据库对应的的Password"995E66F64A15F6776“”的值复制下来 <Connection ConnectionName"…...

webrtc前端播放器完整案例
https://download.csdn.net/download/jinhuding/89961792...

GORM优化器和索引提示
在使用 GORM 进行数据库操作时,优化器和索引提示可以帮助你提高查询性能。GORM 提供了一些方法来利用这些特性。 优化器提示 优化器提示(Optimizer Hints)是数据库系统提供的功能,用于指导查询优化器如何处理查询。不同的数据库…...

linux驱动-i2c子系统框架学习(1)
可以将整个 I2C 子系统用下面的框图来描述: 可以将上面这一 I2C 子系统划分为三个层次,分别为用户空间、内核空间和硬件层,内核空间就包括 I2C 设备驱动层、I2C 核心层和 I2C 适配器驱动层, 本篇主要内容就是介绍 I2C 子系统框架中…...

元戎启行嵌入式面试题及参考答案
介绍下 CAN 通信原理 控制器局域网(CAN)是一种串行通信协议,主要用于汽车、工业自动化等领域的电子控制单元(ECU)之间的通信。 其通信原理是基于多主站架构。在总线上,多个节点(设备)都可以主动发起通信。CAN 协议使用差分信号来传输数据,通过两条信号线 CAN_H 和 CAN…...

【EasyExcel】EasyExcel导出表格包含合计行、自定义样式、自适应列宽
目录 0 EasyExcel简介1 Excel导出工具类设置自定义表头样式设置自适应列宽添加合计行 2 调用导出工具类导出Excel表3 测试结果 0 EasyExcel简介 在数据处理和报表生成的过程中,Excel是一个非常常用的工具。特别是在Java开发中,EasyExcel库因其简单高效而…...

es数据同步(仅供自己参考)
数据同步的问题分析: 当MySQL进行增删改查的时候,数据库的数据有所改变,这个时候需要修改es中的索引库的值,这个时候就涉及到了数据同步的问题 解决方法: 1、同步方法: 当服务对MySQL进行增删改的时候&…...

apt镜像源制作-ubuntu22.04
# 安装必要的软件 sudo apt-get install -y apt-mirror # 编辑/etc/apt/mirror.list,添加以下内容 set base_path /var/spool/apt-mirror # 指定要镜像的Ubuntu发布和组件-null dir jammy-updates main restricted universe multiverse # 镜像的Ubuntu发布和组件的URL-n…...

libaom 源码分析: 预测编码过程梳理
AV1 预测编码中核心技术 AV1(AOMedia Video 1)作为一种开源的视频编码格式,其预测编码核心技术主要包括以下几个方面: 分区树分割模块: AV1利用多类型分割模式,递归地对图像/视频序列进行分区,以捕捉更丰富的空间信息,从而提升编码效率。这包括新的方向预测分割模式及…...

从0开始学习Linux——Yum工具
往期目录: 从0开始学习Linux——简介&安装 从0开始学习Linux——搭建属于自己的Linux虚拟机 从0开始学习Linux——文本编辑器 上一个章节我们简单了解了Linux中常用的一些文本编辑器,本次教程我们将学习yum工具。 一、Yum简介 Yum(全名…...

【Linux】Linux管道揭秘:匿名管道如何连接进程世界
🌈个人主页:Yui_ 🌈Linux专栏:Linux 🌈C语言笔记专栏:C语言笔记 🌈数据结构专栏:数据结构 🌈C专栏:C 文章目录 1.什么是管道 ?2. 管道的类型2.1 匿…...

【LeetCode】【算法】155. 最小栈
LeetCode 155. 最小栈 题目描述 设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。 实现 MinStack 类: MinStack() 初始化堆栈对象。 void push(int val) 将元素val推入堆栈。 void pop() 删除堆栈顶部的元素。 int …...

3.3 windows,ReactOS系统中页面的换出----1
系列文章目录 文章目录 系列文章目录3.3 页面的换出MiBalancerThread()MmTrimUserMemory()MmPageOutVirtualMemory() 3.3 页面的换出 在前一节中我们看到,如果有映射的页面已经被倒换到磁盘上即倒换文件中,…...
)
QCustomPlot添加自定义的图例,实现隐藏、删除功能(二)
文章目录 实现步骤:详细代码示例:实现原理和解释:使用方法:其他参考要实现一个支持复选框来控制曲线显示和隐藏的自定义 QCPLegend 类,可以通过继承 QCPLegend 并重写绘制和事件处理方法来实现,同时发出信号通知曲线的状态变更。 实现步骤: 继承 QCPLegend 类,添加绘…...

Linux云计算 |【第五阶段】CLOUD-DAY8
主要内容: 掌握DaemonSet控制器、污点策略(NoSchedule、Noexecute)、Job / CronJob资源对象、掌握Service服务、服务名解析CluterIP(服务名自动发现)、(Nodeport、Headless)、Ingress控制器 一…...
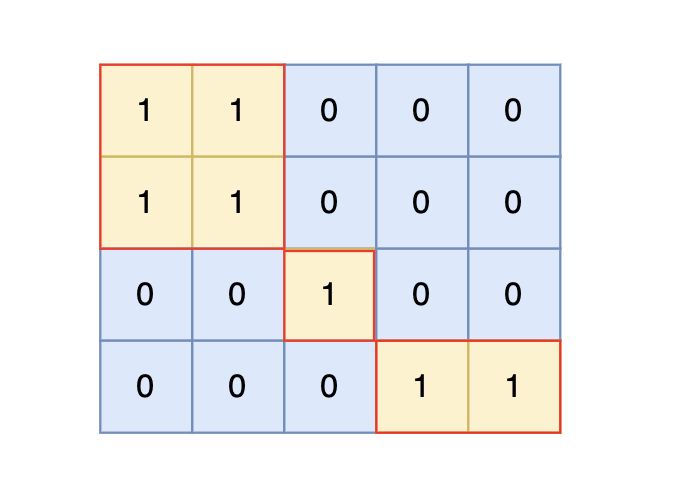
岛屿数量 广搜版BFS C#
和之前的卡码网深搜版是一道题 力扣第200题 99. 岛屿数量 题目描述 给定一个由 1(陆地)和 0(水)组成的矩阵,你需要计算岛屿的数量。岛屿由水平方向或垂直方向上相邻的陆地连接而成,并且四周都是水域。…...

hive切换表底层文件类型以及分隔符
1、改底层文件存储类型,但是一般只会在数据文件与期望类型一致的时候使用,比如load等方式时发现建表时没指定对这样的,因为这个语句不会更改具体的底层文件内容,只改元数据 ALTER TABLE 表名 SET FILEFORMAT 希望类型;2、更改数据…...

注意力机制:多头注意力机制、分组查询注意力机制、多查询注意力机制理论+代码
文章目录导语1.注意力机制2.多头注意力机制3.多查询注意力机制4.分组查询注意力机制5.三者对比导语 注意力机制作为transformer体系中最核心的方法,是NLP、LLM等都绕不开的一部分,多头注意力机制是transformer模型提出的“基石”,分组查询注…...

Spring Boot Actuator生产级监控与管理工具包
Spring Boot Actuator 是 Spring Boot 提供的生产级监控与管理工具包,帮你把应用“可观测化”。它提供了一系列内置的端点(Endpoint),用来查看应用的内部状态,比如健康情况、配置信息、内存指标等。你可以把它理解成为…...

Arty S7 FPGA开发板:从入门到进阶的硬件加速与嵌入式开发实战
1. 项目概述:为什么是Arty S7?如果你是一名嵌入式开发者、数字电路设计的学生,或者对硬件加速、实时信号处理感兴趣,那么“FPGA开发板”这个词对你来说一定不陌生。但面对市场上琳琅满目的开发板,从几百元到上万元不等…...

WTEW的操作记录
WTEW的操作记录WTEW事务代码的操作记录WTEW事务代码的操作记录 1、查询贸易合同信息 如果是自己创建可以使用WB21、WB22、WB23事务码,如果是税码更新用WBRP更新价格 2、创建后续单据,采购TC创建采购订单,销售TC创建销售订单,注…...

1987年6月14日下午13-15点出生性格、运势和命运
这篇文章讨论终极命题:出生时间只是一个随机数据点,真正的命运由你自己书写。我们将探讨如何利用“1987年5月27日中午11-13点”这个符号,作为自我激励的起点,而非束缚。第一步:解构“出生时间”的神秘性 请明确&#x…...

我的日常开发工具迭代|MonkeyCode实测存档
做开发日常,其实大部分编码需求都很琐碎,根本用不上繁杂的专业工具。但市面上的AI编程软件,要么收费贵、额度抠搜,要么功能臃肿、操作繁琐,用起来处处受限。我一直在找一款适配个人日常使用、不折腾、无套路的轻量化编…...

专栏导读:为什么需要从 MM 理解 HMM
一个真实的困境 假设你是一个 GPU 计算框架的开发者。用户写了这样一段代码: float *data malloc(1GB); // ... 填充数据 ... gpu_kernel<<<grid, block>>>(data); // 希望 GPU 直接访问 data在传统编程模型下,这不可能工作——GPU …...

Agent 系统全景图
This Chapter Solves 你已经学了 7 个独立概念:agent、tool、memory、skill、MCP、hook、planning。这一章把它们串成一张图,让你看清楚这些部件在一个真实系统里是怎么组合在一起的。 In One Sentence 一个完整的 agent 系统 推理核心 工具层 记忆…...

CANN/PyPTO hypot函数API文档
pypto.hypot 【免费下载链接】pypto PyPTO(发音: pai p-t-o):Parallel Tensor/Tile Operation编程范式。 项目地址: https://gitcode.com/cann/pypto 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系列产品/At…...

linuxcnc开发环境搭建
linux cnc ,数控机床开源控制软件,实时系统。下载linuxcnc.iso镜像,在虚拟机里安装。安装成功运行起来。安装了amd64版本的qtcreator运行提示少libxcb:sudo apt update sudo apt install libxcb-cursor0打开窗口成功新建 一个工程…...