图神经网络初步实验
实验复现来源
https://zhuanlan.zhihu.com/p/603486955
该文章主要解决问题:
1.加深对图神经网络数据集的理解
2.加深对图神经网络模型中喂数据中维度变化的理解
原理问题在另一篇文章分析:
介绍数据集:cora数据集
其中的主要内容表示为一堆文章,有自己的特征内容,有自己的编号,有自己的类别(标签),相互引用的关系构成了图。
cora.content:包含特征编号,特征内容,特征类别(标签)
31336 0 0 0 0 0 0 ....0 Neural_Networks
1061127 0 0 0 0 0 0 ....0 Rule_Learning
1106406 0 0 0 0 0 0 ....0 Reinforcement_Learning
13195 0 0 0 0 0 0 ....0 Reinforcement_Learning
37879 0 0 0 0 0 0 ....0 Probabilistic_Methods1.其中左面第一列表示特征编号
2.中间的内容表示特征内容(1433维)
3.右面的最后一列表示标签
cora.cite:引用关系,也称作边
35 1033
35 103482
35 103515
35 1050679
35 1103960
35 1103985
35 1109199
35 1112911左面第一列表示起始点(序号),右面表示终止点(序号),其中一行表示一个边,表示两个点的连接
以点作为主要特征进行分类
首先先看一下GCN网络的参数部分


self.conv1 = GCNConv(in_channels=16, out_channels=32, add_self_loops=True, normalize=True)
主要参数就是输入的维度,输出的维度

# 前向传播时调用
output = self.conv1(x, edge_index, edge_weight)
主要的参数为结点的特征矩阵与图的连接关系
也就是说数据需要预处理成结点的特征矩阵,然后单独的标签,再预处理出图的连接关系
分为三个部分。
1.数据预处理
from plistlib import Data
from torch_geometric.data import Data
import torch
#print(torch.__version__)
import torch.nn.functional as F
# import sys
# print(sys.executable)
# import torch_geometric
# print(torch_geometric.__version__)
datasetPath = 'E:/pytorch/pytorch exercise/Graph neural network/Cora dataset/cora'
node_feature_file = 'E:/pytorch/pytorch exercise/Graph neural network/Cora dataset/cora/Cora.content'
edge_file = 'E:/pytorch/pytorch exercise/Graph neural network/Cora dataset/cora/Cora.cites'
label_mapping = {}
node_features = []
node_labels = []
node_ids = {} #特征数
# 定义一个计数器,遍历所有可能的标签
current_label = 0with open(node_feature_file,'r') as f:for line in f:parts = line.strip().split('\t')node_id = int(parts[0])features = list(map(float, parts[1:-1])) # 特征label_str = parts[-1]if label_str not in label_mapping:label_mapping[label_str] = current_labelcurrent_label +=1# 将标签转换为整数label = label_mapping[label_str]node_ids[node_id] = len(node_features) #补充结点索引node_features.append(features) #将节点特征依次按照数量拼接在一起node_labels.append(label)
#print(node_ids)
# 将节点特征和标签转换为 tensor
node_features = torch.tensor(node_features, dtype=torch.float)
# 输出张量的形状
print(node_features.shape)
# 或者使用 .size() 也能得到相同的结果
print(node_features.size())node_labels = torch.tensor(node_labels, dtype=torch.long)
print("node_labels size = ",node_labels.size())
edge_index = []
with open(edge_file, 'r') as f:for line in f:parts = line.strip().split('\t')source = int(parts[0]) # 源节点target = int(parts[1]) # 目标节点source_idx = node_ids[source] # 获取节点ID的索引target_idx = node_ids[target]edge_index.append([source_idx, target_idx])#引用边的信息,生成边的索引集合
# print(source_idx)
# print(target_idx)
edge_index = torch.tensor(edge_index, dtype=torch.long).t().contiguous()
print("edge_index size = ",edge_index.size())
#print(edge_index.shape())
data = Data(x=node_features, edge_index=edge_index, y=node_labels)
# 输出数据的一些信息
print(f'节点特征矩阵 shape: {data.x.shape}')
print(f'边的连接关系 (edge_index) shape: {data.edge_index.shape}')
print(f'节点标签 shape: {data.y.shape}')# 输出第一个节点的特征和标签
print(f'节点 0 的特征: {data.x[0]}')
print(f'节点 0 的标签: {data.y[0]}')其中
node_features表示所有点的特征结合在一起
node_labels表示所有标签集中在一起
node_ids表示特征点的个数
首先是从数据集中抽取特征矩阵的过程
with open(node_feature_file,'r') as f: #打开文件for line in f: #按照行为单位,开始进行遍历parts = line.strip().split('\t')#删除其他空格与回车node_id = int(parts[0]) #将第一个元素放入node_idfeatures = list(map(float, parts[1:-1])) # 将第二个到倒数第二个元素一并放入featureslabel_str = parts[-1] #最后一个元素放入标签if label_str not in label_mapping: #处理标签为null的情况label_mapping[label_str] = current_labelcurrent_label +=1# 将标签转换为整数label = label_mapping[label_str] node_ids[node_id] = len(node_features) #补充结点索引
#为新的node_id分配一个新的整数索引,比如第一个元素node-id=35422,那么就是node_ids[35422] = 1
#也就是为第一个名字为35422的节点编辑了一个序号1,表示第一个元素node_features.append(features) #将节点特征依次按照数量拼接在一起node_labels.append(label) #拼接标签到一个集合中 从数据集中提取边的集合
edge_index = []
with open(edge_file, 'r') as f:for line in f:parts = line.strip().split('\t')source = int(parts[0]) # 源节点target = int(parts[1]) # 目标节点source_idx = node_ids[source] # 获取节点ID的索引target_idx = node_ids[target]edge_index.append([source_idx, target_idx])#引用边的信息,生成边的索引集合转换成data对象
edge_index = torch.tensor(edge_index, dtype=torch.long).t().contiguous()
data = Data(x=node_features, edge_index=edge_index, y=node_labels)简易的模型
class Net(torch.nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = GCNConv(data.x.size(1), 16) # 输入特征维度是 data.x.size(1),输出 16 个特征# 计算类别数,假设 data.y 是节点标签num_classes = data.y.max().item() + 1 # 获取类别数# 第二层卷积层,输出类别数个特征self.conv2 = GCNConv(16, num_classes)def forward(self,x,edge_index):x = self.conv1(x, edge_index) #输入特征矩阵与边的索引集合x = F.relu(x) #卷积后激活x = self.conv2(x, edge_index)return F.log_softmax(x, dim=1)相关文章:
图神经网络初步实验
实验复现来源 https://zhuanlan.zhihu.com/p/603486955 该文章主要解决问题: 1.加深对图神经网络数据集的理解 2.加深对图神经网络模型中喂数据中维度变化的理解 原理问题在另一篇文章分析: 介绍数据集:cora数据集 其中的主要内容表示为…...

创建线程时传递参数给线程
在C中,可以使用 std::thread 来创建和管理线程,同时可以通过几种方式将参数传递给线程函数。这些方法包括使用值传递、引用传递和指针传递。下面将对这些方法进行详细讲解并给出相应的代码示例。 1. 值传递参数 当你创建线程并希望传递参数时ÿ…...
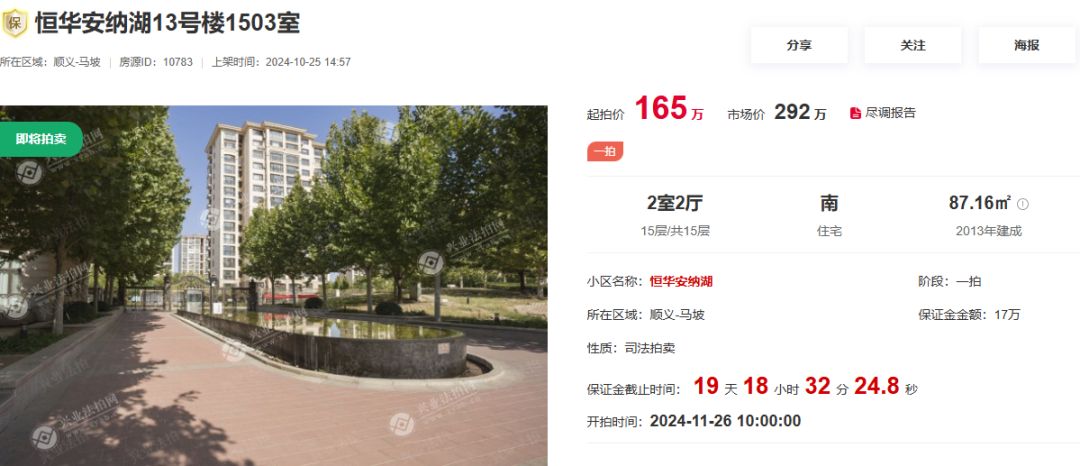
兴业严选|美国总统都是不良资产出身 法拍市场是否将大众化
北京时间11月6日,特朗普赢得美国大选。 说起特朗普那就不得不提他的发家史,那可真是一笔笔不良资产投资堆出来的。 没错,特朗普就是处理不良资产的高手,战果丰硕。 改造斯威夫特小镇、 康莫德酒店、打造特朗普(TRUM…...

C#-拓展方法
概念:为现有的非静态变量类型,添加方法 语法: 访问修饰符 static 返回值 函数名(this 拓展类名 参数名, 参数类型 参数名,参数类型 参数名....){} 而public static void F(this Console()){ }是错的。Console是静态类不可以为静态类添加方…...

加锁失效,非锁之过,加之错也|京东零售供应链库存研发实践
本文导读 从事京东零售供应链库存业务,库存数量操作增减十分频繁,并且项目开发中会常常遇到各种并发情况,一旦库存数量操作有误,势必给前台销售产生损失影响,因此需要关注对库存数量并发操作下的一致性问题。 大部分…...

vue3 传值的几种方式
一.父组件传子组件 父组件 //父组件 <Decisionobject :Decisionselected"Decisionselected"></Decisionobject> <script lang"ts" setup> let Decisionselected ref(false); </script>子组件 <script lang"ts" s…...

AUTOSAR CP NVRAM Manager规范导读
一、NVRAM Manager功能概述 NVRAM Manager是AUTOSAR(AUTomotive Open System ARchitecture)框架中的一个模块,负责管理非易失性随机访问存储器(NVRAM)。它提供了一组服务和API,用于在汽车环境中存储、维护和恢复NV数据。以下是NVRAM Manager的一些关键功能: 数据存储和…...
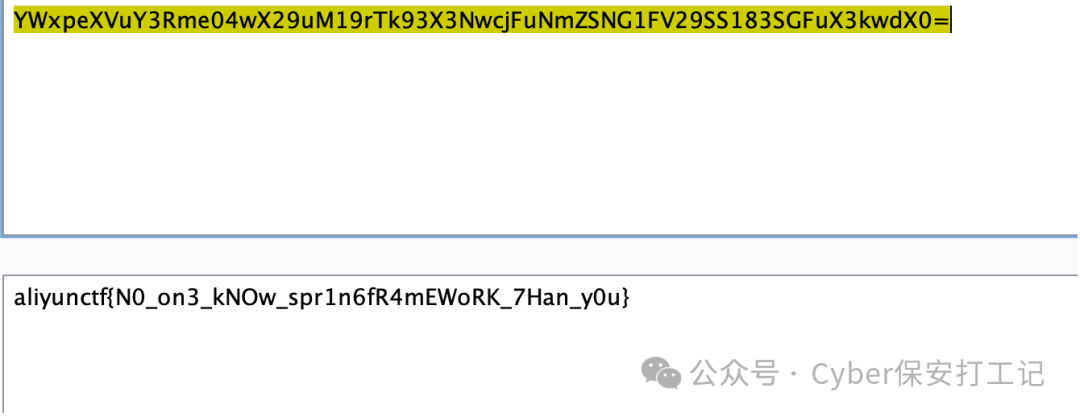
2024阿里云CTF Web writeup
《Java代码审计》http://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247484219&idx1&sn73564e316a4c9794019f15dd6b3ba9f6&chksmc0e47a67f793f371e9f6a4fbc06e7929cb1480b7320fae34c32563307df3a28aca49d1a4addd&scene21#wechat_redirect 前言 又是周末…...

软件著作权申请教程(超详细)(2024新版)软著申请
目录 一、注册账号与实名登记 二、材料准备 三、申请步骤 1.办理身份 2.软件申请信息 3.软件开发信息 4.软件功能与特点 5.填报完成 一、注册账号与实名登记 首先我们需要在官网里面注册一个账号,并且完成实名认证,一般是注册【个人】的身份。中…...

三维测量与建模笔记 - 3.2 直接线性变换法标定DLT
DLT - Direct Linear Transform 上图中,透视成像对应的公式是共线方程,可以参考以下链接: https://zhuanlan.zhihu.com/p/101549821https://zhuanlan.zhihu.com/p/101549821 对于标定来说,需要找到。已知量是。 (u,v)是…...

Whisper AI视频(音频)转文本
在信息化时代,如何高效处理丰富的音频和视频内容成为了一个重要课题。将这些内容转化为文本不仅能提高信息的可获取性,还能促进更广泛的传播。Whisper Desktop作为一款先进的语音识别工具,能够帮助用户轻松实现音频和视频的转文本功能。 什么…...
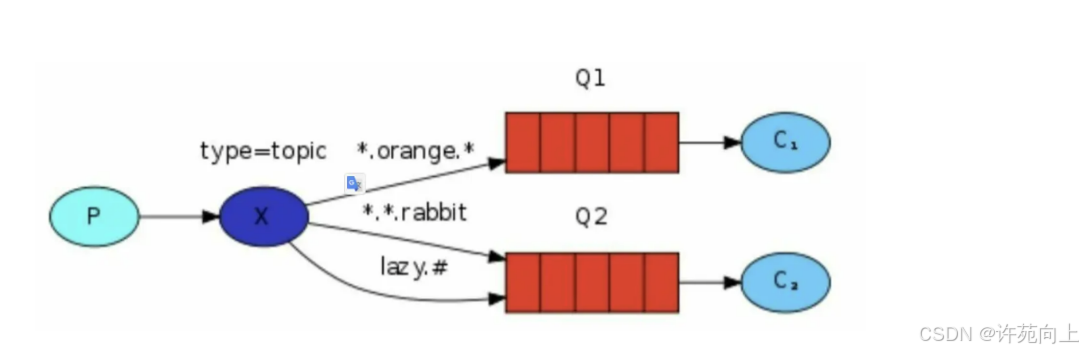
全网最详细RabbitMQ教学包括如何安装环境【RabbitMQ】RabbitMQ + Spring Boot集成零基础入门(基础篇)
目录 一、初始Rabbitmq1、什么是Rabbitmq,它的概述是什么?2、RabbitMQ的应用场景3、RabbitMQ主要组件4、RabbitMQ 的优点5、与其他消息队列性能比较 二、RabbitMQ环境安装初始化三、SpringAMQPRabbitMQ实战入门(基本API)1、实战入…...

esp32记录一次错误
报错信息 PS C:\XingNian\GeRen\4Gdownload\wireless-esp8266-dap> idf.py build Executing action: all (aliases: build) Running cmake in directory c:\xingnian\geren\4gdownload\wireless-esp8266-dap\build Executing "cmake -G Ninja -DPYTHON_DEPS_CHECKED1 …...

Moonshine - 新型开源ASR(语音识别)模型,体积小,速度快,比OpenAI Whisper快五倍 本地一键整合包下载
Moonshine 是由 Useful Sensors 公司推出的一系列「语音到文本(speech-to-text, STT)转换模型」,旨在为资源受限设备提供快速而准确的「自动语音识别(ASR)服务」。Moonshine 的设计特别适合于需要即时响应的应用场景&a…...

java-web-苍穹外卖-day1:软件开发步骤简化版+后端环境搭建
软件开发 感觉书本上和线上课程, 讲的太抽象, 不好理解, 但软件开发不就是为了开发应用程序吗?! 干嘛搞这么抽象,对吧, 下面个人对于软件开发的看法, 主打简单易懂, 当然,我一IT界小菜鸟, 对软件开发的认识也很浅显, 这个思维导图也仅仅是现阶段我的看法, 我以后会尽力…...

一个国产 API 开源项目,在 ProductHunt 杀疯了...
随着AI 大模型技术的兴起,全球产品更新和面市进程速度肉眼可见的加快,Product Hunt 作为全球知名的产品发现平台,每日都会精选出一系列产品能力强劲的新产品,这些产品不仅代表了技术前沿,还反映了市场的发展趋势。 上…...

斗破QT编程入门系列之二:认识Qt:编写一个HelloWorld程序(四星斗师)
斗破Qt目录: 斗破Qt编程入门系列之前言:认识Qt:Qt的获取与安装(四星斗师) 斗破QT编程入门系列之一:认识Qt:初步使用(四星斗师) 斗破QT编程入门系列之二:认识…...
木马病毒相关知识
1、 木马的定义 相当于一个远控程序(一个控制端[hack]、一个被控端[受害端]) 在计算机系统中,“特洛伊木马”指系统中被植入的、人为设计的程序,目的包括通过网终远程控制其他用户的计算机系统,窃取信息资料࿰…...

用 Python 写了一个天天酷跑(附源码)
Hello,大家好,给大家说一下,我要开始装逼了 这期写个天天酷跑玩一下叭! 制作一个完整的“天天酷跑”游戏涉及很多方面,包括图形渲染、物理引擎、用户输入处理、游戏逻辑等。由于Python是一种高级编程语言,…...

【网络-交换机】生成树协议、环路检测
路由优先级 路由优先级决定了在多种可达的路由类型中,哪种路由将被用来转发数据包。路由优先级值越低,对应路由的优先级越高,优先级值255表示对应的路由不可达。一般情况下,静态路由的优先级为1,OSPF路由优先级为110&a…...

别再死记硬背GitFlow命令了!用SourceTree图形化工具5分钟搞定团队协作流程
告别GitFlow命令行恐惧:用SourceTree可视化工具高效管理团队协作 在中小型技术团队中,版本控制是日常开发不可或缺的环节,但传统的GitFlow工作流常常让非命令行爱好者望而生畏。当团队成员水平参差不齐时,频繁的git merge --no-ff…...

Java 数组
Java 数组详细教程数组是 Java 中一种基本且重要的数据结构,用于存储固定大小的同类型元素的集合。所有元素在内存中是连续存储的,可以通过索引(下标)快速访问。1. 数组的基本概念元素: 数组中存储的每一个数据项。长度…...

别再死记硬背了!用打王者荣耀掉帧的例子,5分钟搞懂视频编码里的I/P/B帧
游戏卡顿背后的秘密:用王者荣耀掉帧理解视频编码中的I/P/B帧 当你正沉浸在王者荣耀的激烈团战中,手指在屏幕上飞速滑动,准备释放关键技能时,画面突然卡顿——右上角的FPS数值从60骤降到20。这种令人抓狂的体验背后,隐藏…...

DeepSeek推理服务崩溃频发?3类隐蔽内存泄漏Bug的精准捕获与48小时修复方案
更多请点击: https://kaifayun.com 第一章:DeepSeek推理服务崩溃频发?3类隐蔽内存泄漏Bug的精准捕获与48小时修复方案 典型泄漏模式识别 DeepSeek-R1/V2推理服务在高并发长周期运行中频繁OOM,经pprof火焰图与heap profile交叉分…...

金融项目实战:用sm-crypto为你的Vue/React前端和Node后端加上国密‘安全锁’
金融级数据安全实战:基于SM国密算法的前后端全链路加密方案 在金融科技和政务系统等对数据安全有严格要求的领域,国密算法(SM系列算法)正逐渐成为行业标配。不同于传统的AES、RSA等国际通用算法,国密算法针对中文环境进…...

从ADC采样到FFT分析:手把手教你用STM32F407的DSP库搞定频谱计算
从ADC采样到FFT分析:手把手教你用STM32F407的DSP库搞定频谱计算 在工业振动监测、音频信号处理和电源质量分析等场景中,频谱分析是理解信号特征的关键技术。STM32F407凭借其Cortex-M4内核和硬件FPU,配合CMSIS-DSP库,能够高效实现实…...

5大技术突破:Unity Figma Bridge如何革命性改变游戏UI开发流程
5大技术突破:Unity Figma Bridge如何革命性改变游戏UI开发流程 【免费下载链接】UnityFigmaBridge Easily bring your Figma Documents, Components, Assets and Prototypes to Unity 项目地址: https://gitcode.com/gh_mirrors/un/UnityFigmaBridge Unity F…...

软件开发开源日报
📌 今日概览今日软件开发开源领域呈现多元化发展态势,各大科技公司持续推进AI基础设施、云原生平台和开发者工具的开源进程。字节跳动DeerFlow 2.0成为社区焦点,腾讯混元Hy3开源引发行业热议,华为openEuler发布超节点OS重大更新。…...

CH340G模块除了下载程序,还能这么玩?一个硬件调试小技巧分享
CH340G模块的隐藏技能:用串口调试提升硬件开发效率 当你拿到一片CH340G模块时,第一反应可能是"这是个下载程序的好工具"。确实,这个价格亲民的小模块在51单片机开发中扮演着重要角色。但今天,我要分享的是它另一个被低估…...

在Taotoken控制台清晰观测各模型用量与成本消耗情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken控制台清晰观测各模型用量与成本消耗情况 接入多个大语言模型进行开发时,一个常见的困扰是成本不透明。调用…...