<Project-20 YT-DLP> 给视频网站下载工具 yt-dlp/yt-dlp 加个页面 python web
介绍 yt-dlp
Github 项目:https://github.com/yt-dlp/yt-dlp
A feature-rich command-line audio/video downloader
一个功能丰富的视频与音频命令行下载器
原因与功能
之前我用的 cobalt 因为它不再提供Client Web功能,只能去它的官网使用。 翻 reddit 找到这个 YT-DLP,但它是个命令行工具,考虑参数大多很少用到,给它加个web 壳子,又可以放到docker里面运行。
在网页填入url,只列出含有视频+音频的文件。点下载后,文件可以保存在本地。命令的运行输出也在页面上显示。占用端口: 9012
YT-DLP 程序
代码在 Claude AI 帮助下完成,前端全靠它,Nice~
界面


目录结构
20.YT-DLP/
├── Dockerfile
├── app.py
├── static/
│ ├── css/
│ │ └── style.css
│ └── js/
│ └── script.js
├── templates/
│ └── index.html
└── temp_downloads/完整代码
1. app.py
# app.py
from flask import Flask, render_template, request, jsonify, send_file
import yt_dlp
import os
import shutil
from werkzeug.utils import secure_filename
import time
import logging
import queue
from datetime import datetime
import sysapp = Flask(__name__)# 创建固定的临时目录
TEMP_DIR = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'temp_downloads')
if not os.path.exists(TEMP_DIR):os.makedirs(TEMP_DIR)# 存储下载信息的字典
DOWNLOADS = {}# 创建日志队列
log_queue = queue.Queue(maxsize=1000)class QueueHandler(logging.Handler):def __init__(self, log_queue):super().__init__()self.log_queue = log_queuedef emit(self, record):try:# 过滤掉 Werkzeug 的常规访问日志if record.name == 'werkzeug' and any(x in record.getMessage() for x in ['127.0.0.1','GET /api/logs','GET /static/','"GET / HTTP/1.1"']):return# 清理消息格式msg = self.format(record)if record.name == 'app':# 移除 "INFO:app:" 等前缀msg = msg.split(' - ')[-1]log_entry = {'timestamp': datetime.fromtimestamp(record.created).isoformat(),'message': msg,'level': record.levelname.lower(),'logger': record.name}# 如果队列满了,移除最旧的日志if self.log_queue.full():try:self.log_queue.get_nowait()except queue.Empty:passself.log_queue.put(log_entry)except Exception as e:print(f"Error in QueueHandler: {e}")# 配置日志格式
log_formatter = logging.Formatter('%(message)s')# 配置队列处理器
queue_handler = QueueHandler(log_queue)
queue_handler.setFormatter(log_formatter)# 配置控制台处理器
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setFormatter(log_formatter)# 配置 Flask 日志
app.logger.handlers = []
app.logger.addHandler(queue_handler)
app.logger.addHandler(console_handler)
app.logger.setLevel(logging.INFO)# Werkzeug 日志只输出错误
werkzeug_logger = logging.getLogger('werkzeug')
werkzeug_logger.handlers = []
werkzeug_logger.addHandler(console_handler)
werkzeug_logger.setLevel(logging.WARNING)def cleanup_old_files():"""清理超过10分钟的临时文件"""current_time = time.time()for token, info in list(DOWNLOADS.items()):if current_time - info['timestamp'] > 600: # 10分钟try:file_path = info['file_path']if os.path.exists(file_path):os.remove(file_path)del DOWNLOADS[token]except Exception as e:app.logger.error(f"清理文件失败: {str(e)}")def get_video_info(url):"""获取视频信息,包括可用的格式"""ydl_opts = {'quiet': True,'no_warnings': True,'format': None,'youtube_include_dash_manifest': True,'format_sort': ['res:2160', # 4K'res:1440', # 2K'res:1080', # 1080p'res:720', # 720p'res:480', # 480p'fps:60', # 优先60fps'fps', # 然后是其他fps'vcodec:h264', # 优先H.264编码'vcodec:vp9', # 然后是VP9'acodec' # 最后是音频编码]}with yt_dlp.YoutubeDL(ydl_opts) as ydl:try:info = ydl.extract_info(url, download=False)formats = []def safe_number(value, default=0):try:return float(value or default)except (TypeError, ValueError):return default# 处理视频格式for f in info.get('formats', []):vcodec = f.get('vcodec', 'none')acodec = f.get('acodec', 'none')has_video = vcodec != 'none'has_audio = acodec != 'none'height = safe_number(f.get('height', 0))width = safe_number(f.get('width', 0))fps = safe_number(f.get('fps', 0))tbr = safe_number(f.get('tbr', 0))if has_video: # 只处理包含视频的格式format_notes = []# 添加分辨率标签if height >= 2160:format_notes.append("4K")elif height >= 1440:format_notes.append("2K")# 详细的分辨率信息if height and width:format_notes.append(f"{width:.0f}x{height:.0f}p")# FPS信息if fps > 0:format_notes.append(f"{fps:.0f}fps")# 编码信息if vcodec != 'none':codec_name = {'avc1': 'H.264','vp9': 'VP9','av01': 'AV1'}.get(vcodec.split('.')[0], vcodec)format_notes.append(f"Video: {codec_name}")# 比特率信息if tbr > 0:format_notes.append(f"{tbr:.0f}kbps")# 音频信息if has_audio and acodec != 'none':format_notes.append(f"Audio: {acodec}")format_data = {'format_id': f.get('format_id', ''),'ext': f.get('ext', ''),'filesize': f.get('filesize', 0),'format_note': ' - '.join(format_notes),'vcodec': vcodec,'acodec': acodec,'height': height,'width': width,'fps': fps,'resolution_sort': height * 1000 + fps}if format_data['format_id']:formats.append(format_data)# 按分辨率和FPS排序formats.sort(key=lambda x: x['resolution_sort'], reverse=True)# 移除重复的格式seen_resolutions = set()unique_formats = []for fmt in formats:res_key = f"{fmt['height']:.0f}p-{fmt['fps']:.0f}fps"if res_key not in seen_resolutions:seen_resolutions.add(res_key)unique_formats.append(fmt)return {'title': info.get('title', 'Unknown'),'duration': info.get('duration', 0),'thumbnail': info.get('thumbnail', ''),'formats': unique_formats,'description': info.get('description', ''),'channel': info.get('channel', 'Unknown'),'view_count': info.get('view_count', 0),}except Exception as e:app.logger.error(f"获取视频信息失败: {str(e)}")return {'error': str(e)}def log_progress(d):if d['status'] == 'downloading':try:percent = d.get('_percent_str', 'N/A').strip()speed = d.get('_speed_str', 'N/A').strip()eta = d.get('_eta_str', 'N/A').strip()# 每5%记录一次进度if percent != 'N/A' and float(percent.rstrip('%')) % 5 < 1:app.logger.info(f"下载进度: {percent} | 速度: {speed} | 剩余时间: {eta}")except Exception:passelif d['status'] == 'finished':app.logger.info("下载完成,开始处理文件...")@app.route('/')
def index():"""渲染主页"""return render_template('index.html')@app.route('/api/info', methods=['POST'])
def get_info():"""获取视频信息的API端点"""url = request.json.get('url')if not url:return jsonify({'error': 'URL is required'}), 400info = get_video_info(url)return jsonify(info)@app.route('/api/download', methods=['POST'])
def download_video():"""下载视频的API端点"""url = request.json.get('url')format_id = request.json.get('format_id')if not url or not format_id:app.logger.error('缺少URL或格式ID')return jsonify({'error': 'URL and format_id are required'}), 400try:cleanup_old_files()temp_file = os.path.join(TEMP_DIR, f'download_{time.time_ns()}')app.logger.info(f"创建临时文件: {os.path.basename(temp_file)}")ydl_opts = {'format': f'{format_id}+bestaudio/best','outtmpl': temp_file + '.%(ext)s','quiet': True,'merge_output_format': 'mp4','postprocessors': [{'key': 'FFmpegVideoConvertor','preferedformat': 'mp4',}],'prefer_ffmpeg': True,'keepvideo': False,'progress_hooks': [log_progress],}app.logger.info("开始下载视频...")with yt_dlp.YoutubeDL(ydl_opts) as ydl:info = ydl.extract_info(url, download=True)final_file = ydl.prepare_filename(info)filename = secure_filename(info['title'] + '.mp4')filesize = os.path.getsize(final_file)filesize_mb = filesize / (1024 * 1024)app.logger.info(f"下载完成: {filename} ({filesize_mb:.1f}MB)")download_token = os.urandom(16).hex()DOWNLOADS[download_token] = {'file_path': final_file,'filename': filename,'timestamp': time.time()}return jsonify({'status': 'success','download_token': download_token,'filename': filename})except Exception as e:app.logger.error(f"下载失败: {str(e)}")return jsonify({'error': str(e)}), 500@app.route('/api/get_file/<token>')
def get_file(token):"""获取下载文件的API端点"""if token not in DOWNLOADS:app.logger.error("无效的下载令牌")return 'Invalid or expired download token', 400download_info = DOWNLOADS[token]file_path = download_info['file_path']filename = download_info['filename']if not os.path.exists(file_path):app.logger.error(f"文件未找到: {filename}")return 'File not found', 404try:filesize = os.path.getsize(file_path)filesize_mb = filesize / (1024 * 1024)app.logger.info(f"开始发送: {filename} ({filesize_mb:.1f}MB)")return send_file(file_path,as_attachment=True,download_name=filename,mimetype='video/mp4')except Exception as e:app.logger.error(f"发送文件失败: {str(e)}")return str(e), 500finally:def cleanup():try:if token in DOWNLOADS:os.remove(file_path)del DOWNLOADS[token]app.logger.info(f"临时文件已清理: {filename}")except Exception as e:app.logger.error(f"清理文件失败: {str(e)}")import threadingthreading.Timer(60, cleanup).start()@app.route('/api/logs')
def get_logs():"""获取日志的API端点"""logs = []temp_queue = queue.Queue()try:while not log_queue.empty():log = log_queue.get_nowait()logs.append(log)temp_queue.put(log)while not temp_queue.empty():log_queue.put(temp_queue.get_nowait())return jsonify(sorted(logs, key=lambda x: x['timestamp'], reverse=True))except Exception as e:app.logger.error(f"获取日志失败: {str(e)}")return jsonify([])if __name__ == '__main__':# 确保临时目录存在os.makedirs(TEMP_DIR, exist_ok=True)# 启动时清理旧文件cleanup_old_files()# 运行应用app.run(host='0.0.0.0', port=9012, debug=True)2. index.html
<!-- templates/index.html -->
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>YouTube Video Downloader</title><link rel="stylesheet" href="{{ url_for('static', filename='css/style.css') }}">
</head>
<body><div class="container"><h1>YouTube Video Downloader</h1><div class="input-group"><input type="text" id="url-input" placeholder="Enter YouTube URL"><button id="fetch-info">Get Video Info</button></div><div id="video-info" class="hidden"><div class="info-container"><img id="thumbnail" src="" alt="Video thumbnail"><div class="video-details"><h2 id="video-title"></h2><p id="video-duration"></p></div></div><div class="formats-container"><h3>Available Formats</h3><div id="format-list"></div></div></div><div id="status" class="hidden"></div><!-- 日志显示区域 --><div class="log-container"><div class="log-header"><h3>Operation Logs</h3><button id="clear-logs" title="Clear logs">Clear</button><label class="auto-scroll"><input type="checkbox" id="auto-scroll" checked>Auto-scroll</label></div><div id="log-display"></div></div></div><script src="{{ url_for('static', filename='js/script.js') }}"></script>
</body>
</html>3. style.css
有了 AI 后, style 产生得太简单
/* static/css/style.css */
body {font-family: Arial, sans-serif;margin: 0;padding: 20px;background-color: #f5f5f5;
}.container {max-width: 800px;margin: 0 auto;background-color: white;padding: 20px;border-radius: 8px;box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);
}h1 {text-align: center;color: #333;margin-bottom: 20px;
}.input-group {display: flex;gap: 10px;margin-bottom: 20px;
}input[type="text"] {flex: 1;padding: 10px;border: 1px solid #ddd;border-radius: 4px;font-size: 16px;
}button {padding: 10px 20px;background-color: #007bff;color: white;border: none;border-radius: 4px;cursor: pointer;font-size: 16px;
}button:hover {background-color: #0056b3;
}.hidden {display: none;
}.info-container {display: flex;gap: 20px;margin-bottom: 20px;padding: 15px;background-color: #f8f9fa;border-radius: 4px;
}#thumbnail {max-width: 200px;border-radius: 4px;
}.video-details {flex: 1;
}.video-details h2 {margin: 0 0 10px 0;color: #333;
}.formats-container {border-top: 1px solid #ddd;padding-top: 20px;
}#format-list {display: grid;gap: 10px;
}.format-item {padding: 10px;background-color: #f8f9fa;border-radius: 4px;display: flex;justify-content: space-between;align-items: center;
}#status {margin: 20px 0;padding: 10px;border-radius: 4px;text-align: center;
}#status.success {background-color: #d4edda;color: #155724;
}#status.error {background-color: #f8d7da;color: #721c24;
}/* 日志容器样式 */
.log-container {margin-top: 20px;border: 1px solid #ddd;border-radius: 4px;background-color: #1e1e1e;
}.log-header {padding: 10px;background-color: #2d2d2d;border-bottom: 1px solid #444;display: flex;align-items: center;gap: 10px;
}.log-header h3 {margin: 0;flex-grow: 1;color: #fff;
}.auto-scroll {display: flex;align-items: center;gap: 5px;font-size: 14px;color: #fff;
}#clear-logs {padding: 5px 10px;background-color: #6c757d;color: white;border: none;border-radius: 4px;cursor: pointer;
}#clear-logs:hover {background-color: #5a6268;
}#log-display {height: 300px;overflow-y: auto;padding: 10px;font-family: 'Consolas', 'Monaco', monospace;font-size: 13px;line-height: 1.4;background-color: #1e1e1e;color: #d4d4d4;
}.log-entry {margin: 2px 0;padding: 2px 5px;border-radius: 2px;white-space: pre-wrap;word-wrap: break-word;
}.log-timestamp {color: #888;margin-right: 8px;font-size: 0.9em;
}.log-info {color: #89d4ff;
}.log-error {color: #ff8989;
}.log-warning {color: #ffd700;
}/* 滚动条样式 */
#log-display::-webkit-scrollbar {width: 8px;
}#log-display::-webkit-scrollbar-track {background: #2d2d2d;
}#log-display::-webkit-scrollbar-thumb {background: #888;border-radius: 4px;
}#log-display::-webkit-scrollbar-thumb:hover {background: #555;
}4. script.js
// static/js/script.js
document.addEventListener('DOMContentLoaded', function() {const urlInput = document.getElementById('url-input');const fetchButton = document.getElementById('fetch-info');const videoInfo = document.getElementById('video-info');const thumbnail = document.getElementById('thumbnail');const videoTitle = document.getElementById('video-title');const videoDuration = document.getElementById('video-duration');const formatList = document.getElementById('format-list');const status = document.getElementById('status');// 日志系统class Logger {constructor() {this.logDisplay = document.getElementById('log-display');this.autoScrollCheckbox = document.getElementById('auto-scroll');this.clearLogsButton = document.getElementById('clear-logs');this.lastLogTimestamp = null;this.setupEventListeners();}setupEventListeners() {this.clearLogsButton.addEventListener('click', () => this.clearLogs());this.startLogPolling();}formatTimestamp(isoString) {const date = new Date(isoString);return date.toLocaleTimeString('en-US', { hour12: false,hour: '2-digit',minute: '2-digit',second: '2-digit',fractionalSecondDigits: 3});}addLogEntry(entry) {const logEntry = document.createElement('div');logEntry.classList.add('log-entry');if (entry.level === 'error') {logEntry.classList.add('log-error');} else if (entry.level === 'warning') {logEntry.classList.add('log-warning');} else {logEntry.classList.add('log-info');}const timestamp = document.createElement('span');timestamp.classList.add('log-timestamp');timestamp.textContent = this.formatTimestamp(entry.timestamp);const message = document.createElement('span');message.classList.add('log-message');message.textContent = entry.message;logEntry.appendChild(timestamp);logEntry.appendChild(message);this.logDisplay.appendChild(logEntry);if (this.autoScrollCheckbox.checked) {this.scrollToBottom();}}clearLogs() {this.logDisplay.innerHTML = '';this.lastLogTimestamp = null;}scrollToBottom() {this.logDisplay.scrollTop = this.logDisplay.scrollHeight;}async fetchLogs() {try {const response = await fetch('/api/logs');const logs = await response.json();const newLogs = this.lastLogTimestamp ? logs.filter(log => log.timestamp > this.lastLogTimestamp): logs;if (newLogs.length > 0) {newLogs.forEach(log => this.addLogEntry(log));this.lastLogTimestamp = logs[0].timestamp;}} catch (error) {console.error('Failed to fetch logs:', error);}}startLogPolling() {setInterval(() => this.fetchLogs(), 500);}}// 初始化日志系统const logger = new Logger();function formatDuration(seconds) {const hours = Math.floor(seconds / 3600);const minutes = Math.floor((seconds % 3600) / 60);const remainingSeconds = seconds % 60;if (hours > 0) {return `${hours}:${minutes.toString().padStart(2, '0')}:${remainingSeconds.toString().padStart(2, '0')}`;}return `${minutes}:${remainingSeconds.toString().padStart(2, '0')}`;}function formatFileSize(bytes) {if (!bytes) return 'Unknown size';const sizes = ['Bytes', 'KB', 'MB', 'GB'];const i = Math.floor(Math.log(bytes) / Math.log(1024));return `${(bytes / Math.pow(1024, i)).toFixed(2)} ${sizes[i]}`;}function showStatus(message, isError = false) {status.textContent = message;status.className = isError ? 'error' : 'success';status.classList.remove('hidden');}async function downloadVideo(url, formatId) {try {logger.addLogEntry({timestamp: new Date().toISOString(),level: 'info',message: `Starting download preparation for format: ${formatId}`});showStatus('Preparing download...');const response = await fetch('/api/download', {method: 'POST',headers: {'Content-Type': 'application/json',},body: JSON.stringify({ url, format_id: formatId })});const data = await response.json();if (response.ok && data.download_token) {logger.addLogEntry({timestamp: new Date().toISOString(),level: 'success',message: `Download token received: ${data.download_token}`});showStatus('Starting download...');const iframe = document.createElement('iframe');iframe.style.display = 'none';iframe.src = `/api/get_file/${data.download_token}`;iframe.onload = () => {logger.addLogEntry({timestamp: new Date().toISOString(),level: 'success',message: `Download started for: ${data.filename}`});showStatus('Download started! Check your browser downloads.');setTimeout(() => document.body.removeChild(iframe), 5000);};iframe.onerror = () => {logger.addLogEntry({timestamp: new Date().toISOString(),level: 'error',message: 'Download failed to start'});showStatus('Download failed. Please try again.', true);document.body.removeChild(iframe);};document.body.appendChild(iframe);} else {const errorMessage = data.error || 'Download failed';logger.addLogEntry({timestamp: new Date().toISOString(),level: 'error',message: `Download failed: ${errorMessage}`});showStatus(errorMessage, true);}} catch (error) {logger.addLogEntry({timestamp: new Date().toISOString(),level: 'error',message: `Network error: ${error.message}`});showStatus('Network error occurred', true);console.error(error);}}fetchButton.addEventListener('click', async () => {const url = urlInput.value.trim();if (!url) {showStatus('Please enter a valid URL', true);return;}showStatus('Fetching video information...');try {const response = await fetch('/api/info', {method: 'POST',headers: {'Content-Type': 'application/json',},body: JSON.stringify({ url })});const data = await response.json();if (response.ok) {thumbnail.src = data.thumbnail;videoTitle.textContent = data.title;videoDuration.textContent = formatDuration(data.duration);formatList.innerHTML = data.formats.filter(format => format.format_id && format.ext).map(format => `<div class="format-item"><span>${format.format_note} (${format.ext}) - ${formatFileSize(format.filesize)}</span><button onclick="downloadVideo('${url}', '${format.format_id}')">Download</button></div>`).join('');videoInfo.classList.remove('hidden');status.classList.add('hidden');logger.addLogEntry({timestamp: new Date().toISOString(),level: 'info',message: `Video information retrieved: ${data.title}`});} else {showStatus(data.error || 'Failed to fetch video info', true);logger.addLogEntry({timestamp: new Date().toISOString(),level: 'error',message: `Failed to fetch video info: ${data.error || 'Unknown error'}`});}} catch (error) {showStatus('Network error occurred', true);logger.addLogEntry({timestamp: new Date().toISOString(),level: 'error',message: `Network error: ${error.message}`});}});window.downloadVideo = downloadVideo;// 支持回车键触发获取视频信息urlInput.addEventListener('keypress', (e) => {if (e.key === 'Enter') {fetchButton.click();}});});以上文件放到相应目录,库文件参考 requirements.txt 即可。
Docker 部署
1. Dockerfile
FROM python:3.11-slimWORKDIR /appRUN apt-get update && \apt-get install -y --no-install-recommends \ffmpeg \&& rm -rf /var/lib/apt/lists/*COPY app.py ./
COPY static/css/style.css ./static/css/
COPY static/js/script.js ./static/js/
COPY templates/index.html ./templates/RUN pip install --no-cache-dir \flask \yt-dlp \werkzeugRUN mkdir -p /app/temp_downloads && \chmod 777 /app/temp_downloadsENV FLASK_APP=app.py
ENV PYTHONUNBUFFERED=1
ENV FLASK_RUN_HOST=0.0.0.0
ENV FLASK_RUN_PORT=9012EXPOSE 9012CMD ["python", "-c", "from app import app; app.run(host='0.0.0.0', port=9012)"]2. requirements.txt
flask
Werkzeug==3.0.1
yt-dlp==2024.3.10
gunicorn==21.2.0如果你使用这个 .txt, 可以去掉版本号。我指定版本号,是因我 NAS 的 wheel files 存有多个版本
3. 创建 Image 与 Container
# docker build -t yt-dlp .
# docker run -d -p 9012:9012 --name yt-dlp_container yt-dlp我使用了与 Github 上面项目的相同名字,只是为了方便,字少。
注:在 docker 命令中没有 加入 --restart always, 要编辑一下容器自己添加。
总结:
yt-dlp 是一个功能超强的工具,可以用 cookie file获取身份认证来下载视频,或通过 Mozila 浏览器直接获得 cookie 内容(只是说明上这么说,我没试过)。 Douyin 有 bug 不能下载 , 其它网站没有试。
我有订阅 youtube ,这个工具只是娱乐,或下载 民国 及以前的,其版权已经放弃的影像内容。
请尊重版权

相关文章:
<Project-20 YT-DLP> 给视频网站下载工具 yt-dlp/yt-dlp 加个页面 python web
介绍 yt-dlp Github 项目:https://github.com/yt-dlp/yt-dlp A feature-rich command-line audio/video downloader 一个功能丰富的视频与音频命令行下载器 原因与功能 之前我用的 cobalt 因为它不再提供Client Web功能,只能去它的官网使用。 翻 redd…...

【Android】Gradle 7.0+ 渠道打包配置
声明 该配置主要解决打包apk/aab需要动态修改渠道字段,方便区分渠道上架国内商店。 暂不支持批量打包(7.4版本无法通过只修改outputFileName的形式批量处理) 因为构建时需要拷贝/创建Output,然后修改outputFileName才能处理批量打包,但拷贝/创建在高版本中失效了。 目前的…...

Web应用性能测试工具 - httpstat
在数字化时代,网站的性能直接影响用户体验和业务成功。你是否曾经在浏览网页时,遇到加载缓慢的困扰?在这个快速变化的互联网环境中,如何快速诊断和优化Web应用的性能呢?今天,我们将探讨一个强大的工具——h…...

MySQL 【流程控制】函数
目录 1、CASE 语句用于流程控制中的多分支情况。 2、IF() 函数根据测试条件是否为真分别返回指定的值。 3、IFNULL() 函数,如果第一个参数为 NULL,返回第二个参数,否则返回第一个参数。 4、NULLIF() 函数根据两个参数是否相等决定返回 NUL…...

python 天气数据可视化
Python爬取天气数据及可视化分析 https://blog.csdn.net/weixin_69423932/article/details/135184643...

【HarmonyOS Next】数据本地存储:@ohos.data.preferences
【HarmonyOS Next】数据本地存储:ohos.data.preferences 在开发现代应用程序时,数据存储是一个至关重要的过程。应用程序为了保持某些用户设置、应用状态以及其他小量数据信息通常需要一个可靠的本地存储解决方案。在 HarmonyOS Next 环境下,…...

使用BaGet快速搭建nuget服务
BaGet是基于 asp.net core编写的一个轻量级的 nuget管理服务,安装部署非常简单。 * Nuget版本号规范:https://learn.microsoft.com/zh-cn/nuget/concepts/package-versioning。 环境准备 下载 BaGet安装包。 https://loic-sharma.github.io/BaGet/ 下…...
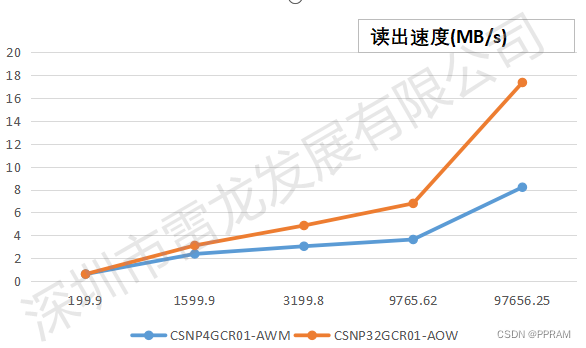
基于Zynq FPGA的雷龙SD NAND存储芯片性能测试
文章目录 前言一、SD NAND特征1.1 SD卡简介1.2 SD卡Block图 二、SD卡样片三、Zynq测试平台搭建3.1 测试流程3.2 SOC搭建 四、软件搭建五、测试结果六、总结 前言 随着嵌入式系统和物联网设备的快速发展,高效可靠的存储解决方案变得越来越重要。雷龙发展推出的SD NA…...
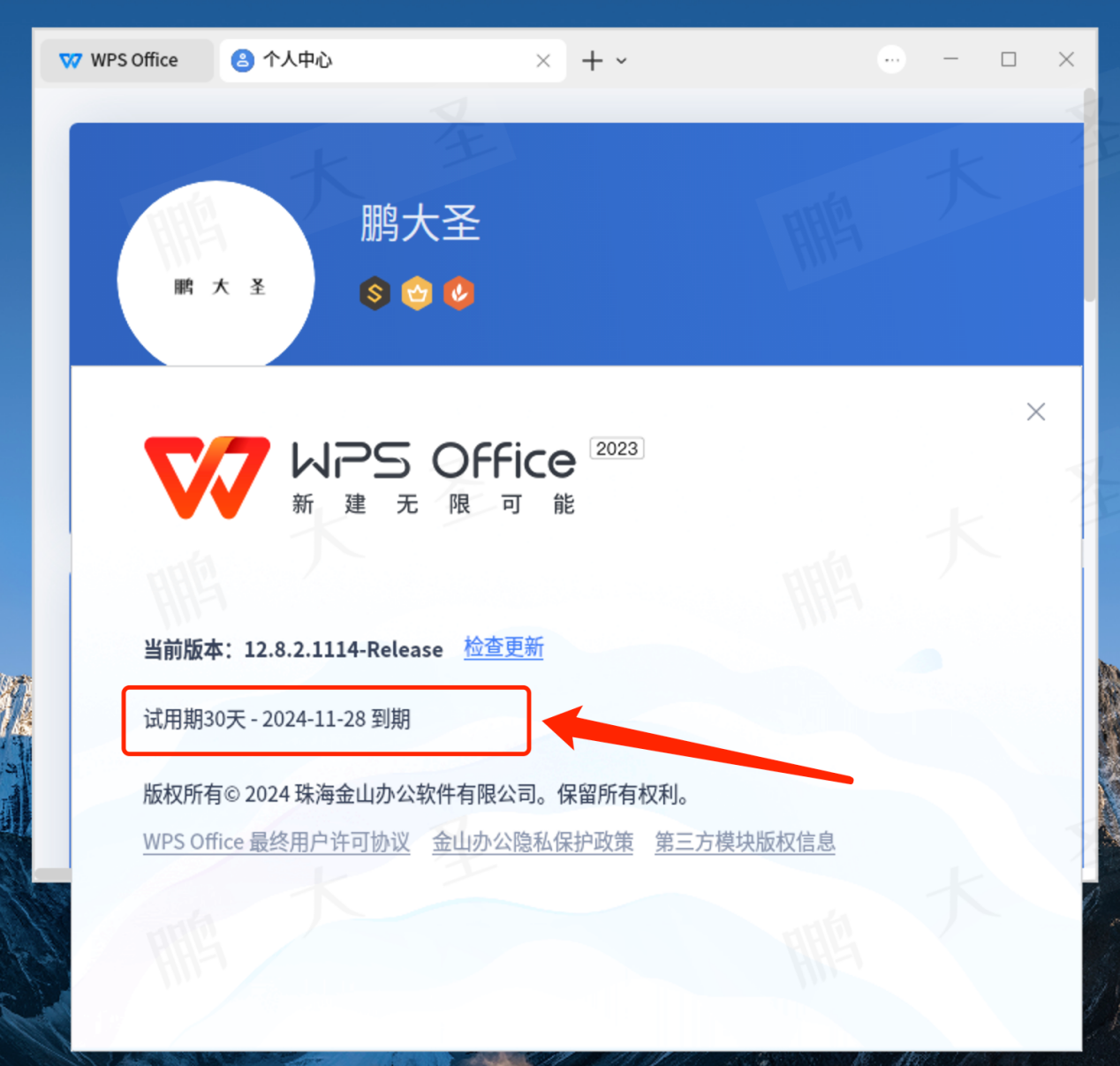
【功能介绍】信创终端系统上各WPS版本的授权差异
原文链接:【功能介绍】信创终端系统上各WPS版本的授权差异 Hello,大家好啊!今天给大家带来一篇关于信创终端操作系统上WPS Office各版本(不包括政务版、企业版等)之间的差异的文章。WPS Office作为国内广泛使用的办公软…...

Neo4j 和 Python 初学者指南:如何使用可选关系匹配优化 Cypher 查询
Neo4j 和 Python 初学者指南:如何使用可选关系匹配优化 Cypher 查询 查询需求分析目标查询结构 编写 Cypher 查询查询解析OPTIONAL MATCH 和 COALESCE 的作用 在 Python 中使用 Neo4j 驱动执行查询使用 neo4j 驱动的 Python 示例代码代码解析示例输出 总结 在使用 N…...
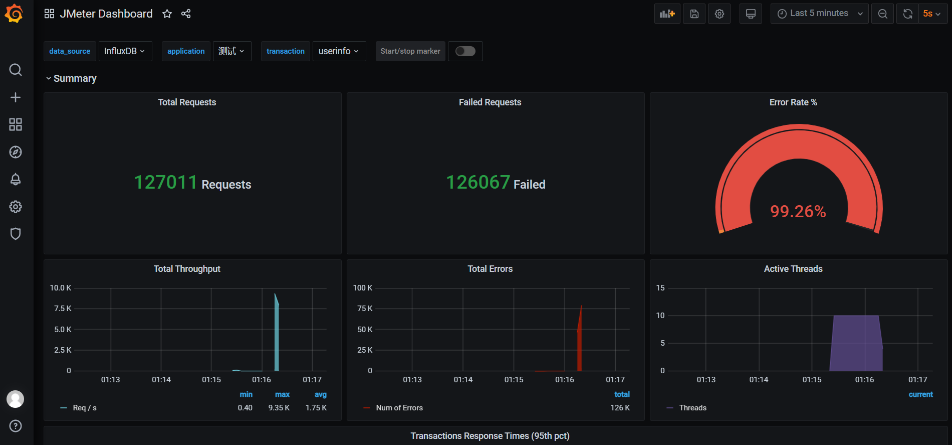
性能测试|docker容器下搭建JMeter+Grafana+Influxdb监控可视化平台
前言 在当前激烈的市场竞争中,创新和效率成为企业发展的核心要素之一。在这种背景下,如何保证产品和服务的稳定性、可靠性以及高效性就显得尤为重要。 而在软件开发过程中,性能测试是一项不可或缺的环节,它可以有效的评估一个系…...
在Pinia Store中正确使用Vue I18n)
(vue3)在Pinia Store中正确使用Vue I18n
引言 在Vue 3和Pinia的开发过程中,我们经常需要在store中使用国际化(i18n)功能。然而,这个看似简单的任务可能会导致一些棘手的问题。本文将深入探讨在Pinia store中使用Vue I18n时可能遇到的挑战,解释问题的根源&…...

如何开发查找附近地点的微信小程序
我开发的是找附近卫生间的小程序。 在现代城市生活中,找到一个干净、方便的公共卫生间有时可能是一个挑战。为了解决这个问题,我们可以开发一款微信小程序,帮助用户快速找到附近的卫生间。本文将介绍如何开发这样一款小程序,包…...
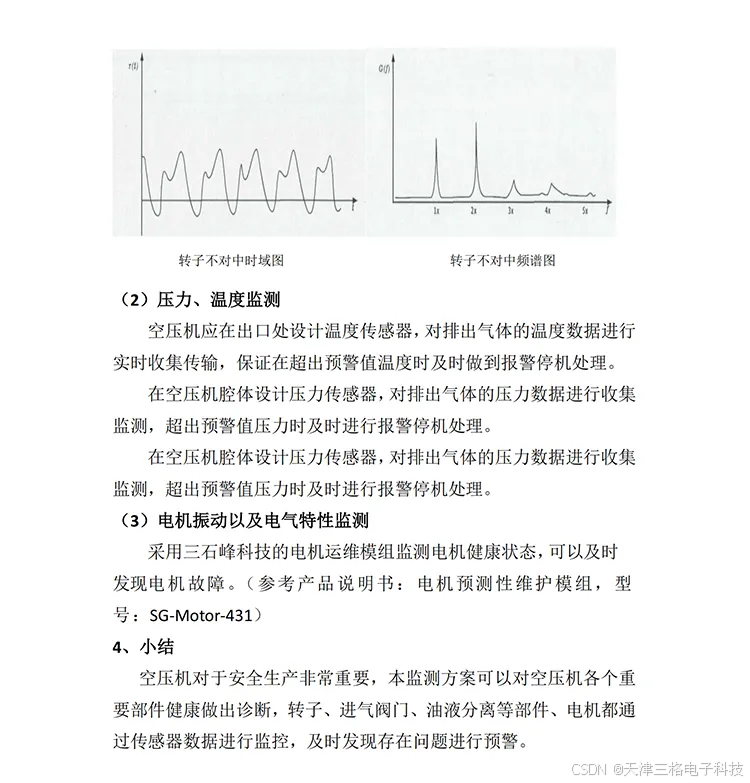
三格电子——电梯监测状态项目
方案介绍...

C#-运算符重载
关键词:operator 语法: public static void operator 运算符(参数列表){} 作用:让自定义类或结构体对象,可以使用运算符进行运算 注意: 参数的数量:与所重载的运算符的运算规则有关。如加法只能有2个参数…...

6.qsqlquerymodel源码分析
目录 继承关系入口浅析qsqlquery刷新数据 扩展列或者移除列以及取别名读取数据与增减行读取数据 下一章节:如何使用qsqlquerymodel 与 qtableview实现自定义表格 继承关系 qsqlquerymodel 继承与qabstracttablemodel 入口 负责填充数据 void QSqlQueryModel::s…...

【人工智能】ChatGPT多模型感知态识别
目录 ChatGPT辅助细化知识增强!一、研究背景二、模型结构和代码任务流程一:启发式生成 三、数据集介绍三、性能展示实现过程运行过程训练过程 ChatGPT辅助细化知识增强! 多模态命名实体识别(MNER)最近引起了广泛关注。…...

2.ARM_ARM是什么
CPU工作原理 CPU与内存中的内容: 内存中存放了指令,每一个指令存放的地址不一样,所需的内存空间也不一样。 运算器能够进行算数运算和逻辑运算,这些运算在CPU中都是以运算电路的形式存在,一个运算功能对应一种运算电…...

深入学习指针(5)!!!!!!!!!!!!!!!
文章目录 1.回调函数是什么?2.qsort使用举例2.1使用qsort函数排序整形数据2.2使用sqort排序结构数据 3.qsort函数的模拟实现 1.回调函数是什么? 回调函数就是⼀个通过函数指针调⽤的函数。 如果你把函数的指针(地址)作为参数传递…...

离散无记忆信道
目录 离散无记忆信道输入概率输出概率联合分布概率信道逆向概率一些记号示例1示例2 离散无记忆信道 离散:输入输出字母表都是有限的 无记忆:输出字符 d i d_i di 被接收到的概率只依赖于当前的输入 c i c_i ci, 而与前面的输入无关。 一个离散无记…...

Ubuntu 16.04 32位系统下RT-Thread开发环境搭建全攻略
1. 项目概述:为何要重温一个“过时”的旧系统环境?如果你在2024年看到这个标题,第一反应可能是:“Ubuntu 16.04?还是32位?这都什么年代的配置了,现在不都用Ubuntu 22.04或者24.04了吗࿱…...

英雄联盟个性化工具终极指南:3分钟免费打造专属游戏身份
英雄联盟个性化工具终极指南:3分钟免费打造专属游戏身份 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 想要在英雄联盟中展示与众不同的个人资料吗?LeaguePrank是一款开源免费的英雄联盟个性化工具&am…...

IT6520:USB‑C 转 MIPI 芯片方案 4K@120Hz 高清显示
一、前言平板、便携屏、AR/VR 头显、车载中控、会议终端等设备,对USB‑C 一线通视频输出的需求越来越强。 传统方案必须用:PD 控制器 DP 接收芯片 MIPI 桥接芯片 外置 MCU Flash,多芯片拼凑导致电路复杂、成本高、兼容性差、开发周期长。…...
的实战选型指南)
别再纠结选哪种了!一文讲透无人机测深三剑客(激光雷达/测深仪/GPR)的实战选型指南
无人机测深技术三剑客:激光雷达、测深仪与探地雷达的深度选型指南 当无人机遇上水深测量,技术选型往往成为项目成败的关键。在河道整治、水库清淤、海岸线测绘等场景中,工程师们常面临一个核心难题:如何在激光雷达、测深仪和探地雷…...

基于Arduino与V-USB的红外转USB键盘接收器设计与实现
1. 项目概述:从游戏抢答器到通用输入设备的蜕变几年前,我在一个教育科技展会上看到了那种用于课堂抢答的无线按钮系统,一套动辄上千元的价格让我这个喜欢折腾硬件的玩家直摇头。当时我就在想,这玩意儿的核心不就是个红外发射接收加…...

前端开发从入门到精通:Vue3+TypeScript实战教程
一、为什么软件测试从业者要学Vue3TypeScript在软件测试领域,尤其是自动化测试和性能测试方向,懂前端开发技术早已不是加分项,而是必备技能。作为测试从业者,掌握Vue3TypeScript能为你的职业发展带来多重优势:…...
)
【JPCS出版、EI检索稳定】2026年航空航天工程与空天信息国际学术会议(ICAEAI 2026)
2026年航空航天工程与空天信息国际学术会议(ICAEAI 2026)将于2026年6月26-28日在哈尔滨召开。会议旨在为从事航空航天工程与空天信息领域研究的专家学者、工程技术人员、技术研发人员提供一个共享科研成果和前沿技术,加强学术研究和探讨&…...

【Autosar】MCAL - 从零到一的工程配置实战
1. 工程创建:从零搭建MCAL开发环境 第一次打开Autosar配置工具时,面对满屏的选项确实容易发懵。记得我刚接触MCAL配置时,光是工程创建就反复折腾了好几次。下面我就把踩过的坑和验证过的正确姿势分享给大家。 创建新工程时,工程名…...

保姆级教程:用Mermaid手绘CPU流水线时空图,理解数据冒险与阻塞
可视化解析CPU流水线:用代码绘制时空图理解数据冒险 在计算机体系结构的学习中,CPU流水线技术是提升处理器性能的核心机制之一。但对于初学者而言,理解流水线中的数据冒险(Data Hazard)及其导致的阻塞现象往往充满挑战…...

基于AM62x异构多核与RPMsg的工业HMI实时控制系统设计
1. 项目概述:为什么是AM62x?最近在做一个工业HMI(人机界面)的升级项目,客户对成本、功耗和实时性提出了近乎苛刻的要求。传统的方案要么性能过剩、成本高昂,要么实时性跟不上,要么功耗是个大问题…...