线性表之链表详解

欢迎来到我的:世界
希望作者的文章对你有所帮助,有不足的地方还请指正,大家一起学习交流 !
目录
- 前言
- 线性表的概述
- 链表的概述
- 内容
- 链表的结构
- 链表节点的定义
- 链表的基本功能
- 单向链表的初始化
- 链表的插入操作
- 头插操作
- 尾插操作
- 链表的删除操作
- 头删操作
- 尾删操作
- 链表的查找操作
- 链表的在指定位置的插入
- 在指定位置之前插入
- 在指定位置之后插入
- 链表在指定位置的删除
- 删除指定位置的结点
- 删除指定位置之后的结点
- 链表的销毁
- 额外的知识:带头单向链表的初始化
- 总结
前言
线性表的概述
线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串…
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。
链表的概述
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
内容
链表的结构
链表的结构跟⽕⻋⻋厢相似,并且每节⻋厢都是独⽴存在的;
那么思考一个问题:既然每个车厢都是独立的,那怎么样把他们链接起来?
想要把每节车厢都链起来,就是依赖每节车厢之间的接口,以方便链接;
而在链表中,就需要依赖指针域来将节点都链接起来;

在现实中数据结构的链表实现:

链表节点的定义
链表一共可以分为八种类型(在后面有详解),在这里我以结构最简单的一种来介绍链表的结构:这种结构叫做:无头单向不循环链表 简称 单向链表
但是链表中的每个节点怎么定义,为什么呢?
这里我们需要运用结构体来定义节点;
原因:
1.结构体可以将不同类型的数据组合在一起,根据上述的分析:对于链表的结点,需要存储数据元素(int,float…)和下一个节点的地址;结构体的话就可以很好的将这两种不同类型的数据(数据域和指针域)封装在一起;
2.并且我们要了解:结构体可以比较方便的表示一种复杂的数据结构;而链表的结构也相对比较复杂,所以用结构体定义链表的结构在合适不过了;
//链表的实现
//单向链表的结点的定义
typedef int typeList;//将int类型重命名为typeList
typedef struct SListNode
{typeList data;//这样定义数据域的好处就是,可以随时更改任意类型如:char、short...struct SListNode* next;//定义指针域,存放下一个节点的地址,以便找到下一个节点
}SLNode;
链表的基本功能
最基础的功能
增 删 查 改
单向链表的初始化
链表开始的时候需要初始化链表,因为初始化能建立一个稳定的起始状态,就像盖房子之前需要先打好地基一样,以确保数据结构符合预期的初始性质;
//直接这样定义即可;
int main()
{SLNode*phead=NULL;return 0;
}链表的插入操作
对于单向链表,插入操作可以分为四种:
头插,尾插,在查找到的位置之后插入,在查找到的位置之前插入
在这里我先介绍:头插,尾插,其余在后续有介绍
头插操作
头插概述:就是将一个新节点插入到单向链表的头部,使得新节点成为链表的新头部。
- 头插操作是将新节点插入到链表的头部。在单链表中,头节点( phead )是访问链表的入口。
- 头插操作需要改变头节点 phead 的指向。新插入的节点将成为新的头节点,原来的头节点将成为新节点的下一个节点。
询问:若将头插操作封装成一个函数,请问怎么传参呢?
- 由于C语言函数参数是值传递,如果只传递一级指针
phead,在函数内部对phead的修改只是修改了函数内部的一个副本。例如,在函数内phead = newNode;(newNode是新插入的节点)这样的操作,只是改变了函数内部phead副本的指向,而不会改变函数外部真正的phead。- 传递二级指针
&phead,函数接收的是头节点指针phead的地址。这样在函数内部可以通过解引用二级指针来修改真正的头节点phead。比如,*pphead = newNode;(pphead是接收二级指针的参数),这种操作会改变函数外部的phead的值,使得新插入的节点成为链表的新头节点,从而实现了正确的头插操作。但是头插要分情况讨论,若本来链表中就没有节点呢?
若有节点怎么办?若没有又该怎么样?
若有节点,就先让新的节点的next域指向头结点*pphead,再让头结点*pphead重新指向这个新的结点,
若没有节点,就直接让*pphead指向新的结点
//头插
void FrontSLNode(SLNode** pphead, typeList n)
{assert(pphead);//断言:就是当pphead为NULL,会自动报错,并结束程序;//创建新的节点,并将其指针域和数据域都要进行初始化;SLNode* newnode = (SLNode*)malloc(sizeof(SLNode));if (newnode == NULL){perror("malloc");return;}//初始化指针域和数据域newnode->data = n;newnode->next = NULL;//当链表为空,直接将新的结点插入链表头部if (*pphead == NULL){*pphead = newnode;return;}//链表不为空,新插入的节点将成为新的头节点,原来的头节点将成为新节点的下一个节点。newnode->next = *pphead;*pphead = newnode;return 0;
}尾插操作
尾插就是指在单链表的末尾插入一个新节点;
- 在单链表中,当进行尾插操作时,需要考虑两种情况:一是链表为空时插入第一个节点,二是链表非空时插入新节点到尾部。
- 首先你要知道,尾插如果当链表一开始为空时,要尾插的话,你就需要改变phead的指向,此时你就需要传入二级指针;(可以这样想:当链表非空时,这时尾插不需要改变phead指针的指向,此时传一级指针就可以)
为什么需要传二级指针:因为
- 当链表为空时,头节点
phead本身为NULL。如果只传一级指针,在函数内部修改phead的值(让它指向新插入的节点),这种修改在函数结束后不会影响到函数外部的phead变量。因为C语言中函数参数传递是值传递,对于指针变量也不例外。- 传递二级指针
( &phead )就可以在函数内部真正地修改头节点phead本身的值。例如,在插入第一个节点时,函数内部可以通过*pphead = newNode;(假设pphead是二级指针接收的参数,newNode是新插入的节点)这样的操作来让外部的phead指向新节点。- 当链表非空时,通过二级指针也可以方便地遍历到链表的尾部进行插入操作,并且保证对链表结构的修改(如更新尾节点的 next 指针)能够在函数外部生效。
//尾插
void BackSLNode(SLNode** pphead, typeList n)
{assert(pphead);//创建新节点SLNode* newnode = (SLNode*)malloc(sizeof(SLNode));if (newnode == NULL){perror("malloc");return;}初始化指针域和数据域newnode->data = n;newnode->next = NULL;if (*pphead == NULL){*pphead = newnode;return;}//链表不为空,找到尾巴SLNode* tem = *pphead;while (tem->next){tem = tem->next;}//更新尾结点指向tem->next = newnode;
}
链表的删除操作
对于单向链表,删除操作可分为很多种比如:
头删,尾删,删除指定位置的结点,删除指定位置之后的结点;接下来我来分别介绍:头删,尾删,后面的会在后续介绍;当删除头结点时:
- 当要删除头节点时,首先要判断链表是否为空。如果链表为空,那就没有节点可删除。
- 若链表不为空,将头节点指针 phead 指向下一个节点( *pphead = *pphead->next ),此时改变了phead的头节点的指向,所以要传二级指针,然后释放原来头节点的内存空间,这样就完成了头节点的删除。
当不是删除头结点时:
- 首先需要遍历链表找到要删除节点的前驱节点。从链表头开始,逐个节点检查,直到找到一个节点(设为 pre ),它的下一个节点( pre->next )是要删除的节点。
- 然后将前驱节点 pre 的指针域跳过要删除的节点,即 pre->next = pre->next->next 。
- 最后释放要删除节点的内存空间。
头删操作
头删:就是将第一个节点删掉,然后让第二个节点变成新的节点;
//头删
void FrontDelSLNode(SLNode** pphead)
{assert(pphead);assert(*pphead);//当链表为空时,最好断言一下,否则下面的(*pphead)->next 会报错//作为前驱节点,最后要删除SLNode* pre = *pphead;//只有一个节点的情况if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;return;}//两个以上的结点的情况SLNode* ret = pre->next;*pphead = ret;free(pre);pre = NULL;
}
尾删操作
尾删:就是删除链表的最后一个节点,让倒数第二个节点的指针域指向NULL;
//尾删
void BackDelSLNode(SLNode** pphead)
{assert(pphead);assert(*pphead);SLNode* pre = *pphead;//只有一个节点的情况if ((*pphead)->next == NULL){free(*pphead);*pphead = NULL;return;}//两个以上的结点的情况,找到尾结点的前一个节点while (pre->next->next){pre = pre->next;}//释放掉最后一个节点free(pre->next->next);pre->next->next = NULL;//再让倒数第二个节点的next域指向NULLpre->next = NULL;
}
链表的查找操作
查找:就是在单链表中寻找特定元素或节点,也就是说,传参的时候,可以传数据值或传地址进行查找;
注意:查找就是负责查找,并且返回那个节点而已,并不会改变phead头结点指针的方向,所以此时传一级指针即可;按值查找:
- 从链表的头节点开始,通过遍历链表逐个比较节点的数据域与目标值。
- 设链表头节点为 phead ,可以使用一个指针 p = phead ,然后在循环中比较 p->data (假设 data 是存储数据的成员)和目标值。如果相等,就找到了目标节点;如果不相等,就将 p = p->next ,继续检查下一个节点,直到 p 为 NULL (表示遍历完链表未找到目标值)。
按址查找:
- 同样从头节点开始,要查找第 n 个位置的节点。定义一个计数变量 count = 1 ,一个指针 p = phead 。
- 当 count < n 且 p 不为 NULL 时,执行 p = p->next 和 count++ 操作。如果 count == n ,此时 p 指向的就是第 n 个节点;如果 p 为 NULL 且 count < n ,则表示链表长度小于 n ,不存在第 n 个节点。
这里我就偷个懒,就实现 按值查找 喽😊
//查找
SLNode* FindSLNode(SLNode* phead, typeList n)
{assert(phead);SLNode* p = phead;while (p){if (p->data == n)return cour;p = p->next;}return NULL;
}
链表的在指定位置的插入
其实原理也是和
头插,尾插原理相同;唯一需要理解的是什么叫在特定位置?这里我们就需要和之前的那个查找操作相结合了,先找到你需要插入的节点,再在对这个节点之前,节点之后进行插入新的节点;
注意,当你在在查找到的位置之前插入,就有可能会改变头结点phead指针的指向,需要传二级指针;但是当你在在查找到的位置之后插入,就不会改变头结点phead指针的指向,所以不需要传二级指针,一级指针就可以了;
在指定位置之前插入
此时传参不但需要查找到的那个节点,还需要将头结点传入进来,是为了遍历链表找到指定的那个节点
//在指定位置之前插入数据
void InsertSLNode(SLNode** pphead, SLNode* pos, typeList n)
{assert(pphead);assert(*pphead);assert(pos);//此时还要对指定位置的结点断言//创建新节点,并进行初始化SLNode* newnode = (SLNode*)malloc(sizeof(SLNode));newnode->data = n;newnode->next = NULL;//当在第一个节点之前插入if ((*pphead) == pos){//就是头插,直接将头插的代码拿过来,Ctrl C V真的很快乐😍FrontSLNode(pphead, n);return;}//其他节点,找到指定位置之前的那个节点SLNode* tem = *pphead;while (tem->next != pos){tem = tem->next;}//插进来tem->next = newnode;newnode->next = pos;
}在指定位置之后插入
在指定位置之后插入,就不存在改变头节点phead的可能性,不需要遍历就能找到指定的那个节点;
//在指定位置之后插入数据
void InsertAfterSLNode(SLNode* pos, typeList n)
{assert(pos);//创建新节点,并进行初始化SLNode* newnode = (SLNode*)malloc(sizeof(SLNode));newnode->data = n;newnode->next = pos->next;pos->next = newnode;
}
链表在指定位置的删除
其实和
链表的在指定位置的插入的原理相同,先找到这个指定位置,在进行删除操作;
链表在指定位置的删除:可以删除指定位置的结点,删除指定位置之后的结点;
删除指定位置的结点
删除指定位置的结点,需要传头结点用来遍历找到特定位置的结点,也有可能删除头结点phead,所以需要传二级指针;
进行特殊情况的判断:
- 首先判断链表是否为空,如果为空,则无法进行删除操作,直接返回。
- 如果指定位置是第 1 个节点,即删除头节点,这时候只需要将头指针指向头节点的下一个节点,并释放原来头节点的内存空间即可。
步骤:
1.查找要删除节点的前驱节点
2.再删除节点
//删除pos节点
void SLTErase(SLNode** pphead, SLNode* pos)
{assert(pphead);assert(*pphead);assert(pos);//当为第一个节点,进行头删if (pos == (*pphead)){//相当于进行头删操作FrontDelSLNode(pphead);return;}SLNode* tem = *pphead;while (tem->next != pos){tem = tem->next;}tem->next = pos->next;free(pos);pos = NULL;
}
删除指定位置之后的结点
删除指定位置之后的结点,不存在改变头节点phead指针的可能性,所以传一级指针即可;
//删除pos之后的节点
void SLTEraseAfter(SLNode* pos)
{assert(pos);assert(pos->next);SLNode* tem = pos;pos = tem->next->next;free(tem->next);tem->next = NULL;
}
链表的销毁
链表的销毁就是指释放链表中所有节点占用的内存空间,使链表不再使用;
所以要改变头结点phead指针的指向,所以传二级指针;
- 首先需要一个指针
ptr来遍历链表,接着使用一个临时指针next来保存当前节点ptr的下一个节点的位置,然后释放当前节点ptr所占用的内存空间,最后将ptr指针更新为next;重复上述步骤,直到ptr==NULL,这意味着已经办理并释放了链表的所有节点;
//销毁链表
void SListDesTroy(SLNode** pphead)
{assert(pphead);assert(*pphead);SLNode* ptr = *pphead;while (ptr != NULL){SLNode* next = ptr->next;free(ptr);ptr = NULL;}*pphead = NULL;
}
额外的知识:带头单向链表的初始化
链表开始的时候需要初始化链表,因为初始化能建立一个稳定的起始状态,就像盖房子之前需要先打好地基一样,以确保数据结构符合预期的初始性质;
当面对传参问题:
带头链表的初始化可以有两种形式:
1.无参数形式;2.参数形式;
当为无参数形式 :因为链表的初始化主要是创建一个节点,并将指针域设置成
NULL;
例如:这里的InitSLNode函数没有参数;
SLNode* InitSLNode() {SLNode* head = (SLNode*)malloc(sizeof(SLNode));if (head == NULL) {//这里的malloc向堆区中开辟空间可能失败,所以这边进行判断;return NULL;}//这里最好就将数据域也进行初始化一下,要不然你这个结点的数据域就是一个随机值head -> data = 0;//将指针域设为NULL,变成一个独立的节点head -> next = NULL;return head;
}
//无参数形式这样进行初始化
int main()
{SLNode*phead=InitSLNode();return 0;
}
当为参数形式 :其实传参数可以根据自身需求进行不同的设置:比如我这时传入的是一个整数为初始值来初始化链表的节点;
这里我们想的是把结构体变成一个链表的结点,所以我们直接传结构体的地址就可以了;我们就可以将这个结构体直接就变成节点;例如:这里的
InitSLNode函数有参数;
//初始化
void InitSLNode(SLNode* phead)
{//这里最好就将数据域也进行初始化一下,要不然你这个结点的数据域就是一个随机值phead->data = 0;//将指针域设为NULL,变成一个独立的节点phead->next = NULL;
}
//有参形式这样进行初始化
int main()
{SLNode head;InitSLNode(&head);return 0;
}
这里对于参数形式的传参问题:为什么传结构体的地址?
因为,只有传地址调用的时候可以直接修改结构体的成员(数据域和指针域);若你只是传结构体变量进来,不能改变结构体的成员(数据域和指针域)
如果还有不太懂的东西,可以去了解一下:传值调用和传址调用的区别;
总结
到了最后:感谢支持
------------对过程全力以赴,对结果淡然处之
也是对我自己讲的
相关文章:
线性表之链表详解
欢迎来到我的:世界 希望作者的文章对你有所帮助,有不足的地方还请指正,大家一起学习交流 ! 目录 前言线性表的概述链表的概述 内容链表的结构链表节点的定义 链表的基本功能单向链表的初始化链表的插入操作头插操作尾插操作 链表的删除操作头…...

C/C++使用AddressSanitizer检测内存错误
AddressSanitizer 是一种内存错误检测工具,编译时添加 -fsanitizeaddress 选项可以在运行时检测出非法内存访问,当发生段错误时,AddressSanitizer 会输出详细的错误报告,包括出错位置的代码行号和调用栈,有助于快速定位…...

【EI和Scopus检索】国际人工智能创新研讨会(IS-AII 2025)
国际人工智能创新研讨会(IS-AII 2025)将于2025年1月11日-1月14日在贵阳盛大举行。会议将聚焦计算机科学、人工智能、机器人科学与工程等相关研究领域,广泛邀请国内外知名专家学者,共同探讨相关学科领域的最新发展方向及行业前沿动…...

在OceanBase 中,实现自增列的4种方法
本文作者:杨敬博,爱可生 DBA 团队成员。 背景描述 在OceanBase数据库中,存在MySQL租户与Oracle租户两种模式,本文主要讲解在 OceanBase 的Oracle模式(以下简称OB Oracle),创建自增列的4种方式&…...

LWE算法分类及基本加解密算法示例
LWE(Learning With Errors)算法是一种基于格(lattice)的密码学原语,广泛应用于构建抗量子计算的加密方案。LWE算法的安全性基于最坏情况下的格问题(如最短向量问题SVP和最近向量问题CVP)&#x…...

【论文阅读】Learning dynamic alignment via meta-filter for few-shot learning
通过元滤波器学习动态对齐以实现小样本学习 引用:Xu C, Fu Y, Liu C, et al. Learning dynamic alignment via meta-filter for few-shot learning[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 5182-5191. 论文…...

蓝牙 SPP 协议详解及 Android 实现
文章目录 前言一、 什么是蓝牙 SPP 协议?SPP 的适用场景 二、SPP的工作流程1. 蓝牙设备初始化2. 设备发现与配对3. 建立 SPP 连接4. 数据传输5. 关闭连接 三、进阶应用与常见问题蓝牙连接中断与重试机制数据传输中的延迟与错误处理电池消耗和蓝牙优化 总结 前言 蓝…...

系统学习领域驱动设计-感悟-高尚名词篇
高尚名词 高尚名词通俗意思知识消化开发代码过程中的业务理解持续学习团队角度,持续沉淀文档沉淀业务理解,教会更多的新人,不让某些员工掌握知识壁垒...

人工智能(AI)和机器学习(ML)技术学习流程
目录 人工智能(AI)和机器学习(ML)技术 自然语言处理(NLP): Word2Vec: Seq2Seq(Sequence-to-Sequence): Transformer: 范式、架构和自注意力: 多头注意力: 预训练、微调、提示工程和模型压缩: 上下文学习、思维链、全量微调、量化、剪枝: 思维树、思维…...

<Project-20 YT-DLP> 给视频网站下载工具 yt-dlp/yt-dlp 加个页面 python web
介绍 yt-dlp Github 项目:https://github.com/yt-dlp/yt-dlp A feature-rich command-line audio/video downloader 一个功能丰富的视频与音频命令行下载器 原因与功能 之前我用的 cobalt 因为它不再提供Client Web功能,只能去它的官网使用。 翻 redd…...

【Android】Gradle 7.0+ 渠道打包配置
声明 该配置主要解决打包apk/aab需要动态修改渠道字段,方便区分渠道上架国内商店。 暂不支持批量打包(7.4版本无法通过只修改outputFileName的形式批量处理) 因为构建时需要拷贝/创建Output,然后修改outputFileName才能处理批量打包,但拷贝/创建在高版本中失效了。 目前的…...

Web应用性能测试工具 - httpstat
在数字化时代,网站的性能直接影响用户体验和业务成功。你是否曾经在浏览网页时,遇到加载缓慢的困扰?在这个快速变化的互联网环境中,如何快速诊断和优化Web应用的性能呢?今天,我们将探讨一个强大的工具——h…...

MySQL 【流程控制】函数
目录 1、CASE 语句用于流程控制中的多分支情况。 2、IF() 函数根据测试条件是否为真分别返回指定的值。 3、IFNULL() 函数,如果第一个参数为 NULL,返回第二个参数,否则返回第一个参数。 4、NULLIF() 函数根据两个参数是否相等决定返回 NUL…...

python 天气数据可视化
Python爬取天气数据及可视化分析 https://blog.csdn.net/weixin_69423932/article/details/135184643...

【HarmonyOS Next】数据本地存储:@ohos.data.preferences
【HarmonyOS Next】数据本地存储:ohos.data.preferences 在开发现代应用程序时,数据存储是一个至关重要的过程。应用程序为了保持某些用户设置、应用状态以及其他小量数据信息通常需要一个可靠的本地存储解决方案。在 HarmonyOS Next 环境下,…...

使用BaGet快速搭建nuget服务
BaGet是基于 asp.net core编写的一个轻量级的 nuget管理服务,安装部署非常简单。 * Nuget版本号规范:https://learn.microsoft.com/zh-cn/nuget/concepts/package-versioning。 环境准备 下载 BaGet安装包。 https://loic-sharma.github.io/BaGet/ 下…...
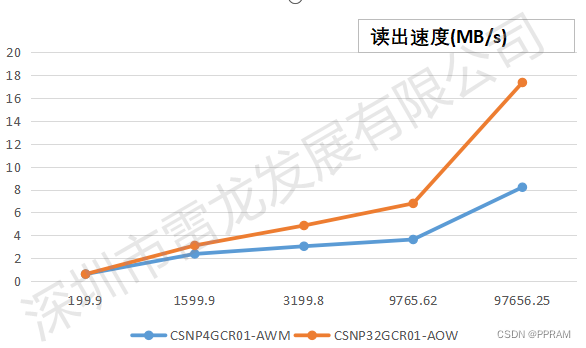
基于Zynq FPGA的雷龙SD NAND存储芯片性能测试
文章目录 前言一、SD NAND特征1.1 SD卡简介1.2 SD卡Block图 二、SD卡样片三、Zynq测试平台搭建3.1 测试流程3.2 SOC搭建 四、软件搭建五、测试结果六、总结 前言 随着嵌入式系统和物联网设备的快速发展,高效可靠的存储解决方案变得越来越重要。雷龙发展推出的SD NA…...
【功能介绍】信创终端系统上各WPS版本的授权差异
原文链接:【功能介绍】信创终端系统上各WPS版本的授权差异 Hello,大家好啊!今天给大家带来一篇关于信创终端操作系统上WPS Office各版本(不包括政务版、企业版等)之间的差异的文章。WPS Office作为国内广泛使用的办公软…...

Neo4j 和 Python 初学者指南:如何使用可选关系匹配优化 Cypher 查询
Neo4j 和 Python 初学者指南:如何使用可选关系匹配优化 Cypher 查询 查询需求分析目标查询结构 编写 Cypher 查询查询解析OPTIONAL MATCH 和 COALESCE 的作用 在 Python 中使用 Neo4j 驱动执行查询使用 neo4j 驱动的 Python 示例代码代码解析示例输出 总结 在使用 N…...
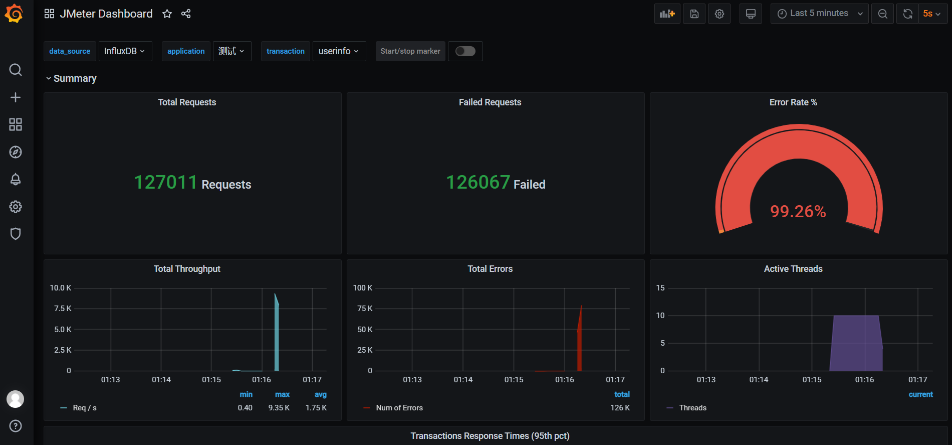
性能测试|docker容器下搭建JMeter+Grafana+Influxdb监控可视化平台
前言 在当前激烈的市场竞争中,创新和效率成为企业发展的核心要素之一。在这种背景下,如何保证产品和服务的稳定性、可靠性以及高效性就显得尤为重要。 而在软件开发过程中,性能测试是一项不可或缺的环节,它可以有效的评估一个系…...

告别信号失真!手把手教你理解PCIe均衡中的预加重与去加重
PCIe信号均衡技术:预加重与去加重的实战解析 在高速串行通信领域,信号完整性始终是工程师面临的核心挑战。当PCIe总线速率从2.5GT/s演进到32GT/s甚至更高时,信号在传输过程中遭遇的高频衰减和码间干扰(ISI)问题变得尤为突出。预加重(Pre-emph…...

免费开源AMD Ryzen调试工具:SMUDebugTool完整使用指南与性能调优实战
免费开源AMD Ryzen调试工具:SMUDebugTool完整使用指南与性能调优实战 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地…...

3步彻底解决Windows程序启动失败:VisualCppRedist AIO终极修复指南
3步彻底解决Windows程序启动失败:VisualCppRedist AIO终极修复指南 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否遇到过新安装的软件无法启动…...

混合模拟技术革新ML系统性能评估
1. 项目概述:混合模拟技术如何革新ML系统性能评估 在大型语言模型训练场景中,工程师常常面临这样的困境:要评估不同并行策略(如数据并行、流水线并行)对训练速度的影响,传统方法要么需要搭建昂贵的多GPU测试…...

3种创新方案解决抖音视频保存难题
3种创新方案解决抖音视频保存难题 【免费下载链接】douyin_downloader 抖音短视频无水印下载 win编译版本下载:https://www.lanzous.com/i9za5od 项目地址: https://gitcode.com/gh_mirrors/dou/douyin_downloader 你是否曾遇到过这样的困扰:在抖…...

别再只调库了!手写KNN算法识别MNIST数字,从距离计算到加权投票的完整实现与性能对比
从零构建KNN算法:MNIST手写数字识别的底层实现与深度优化 在机器学习入门阶段,K最近邻(KNN)算法往往是第一个接触的经典分类方法。大多数教程止步于调用sklearn的几行代码,却忽略了算法底层的精妙设计。本文将带您从数…...

GitHub 协作完全指南:从“傻瓜”到专家的保姆级教程
引言:为什么协作会让人头疼?想象一下,你和其他几个人要一起画一幅巨大的壁画。每个人都在自己的小画板上画一部分。问题来了:怎么保证大家用的颜色一致?怎么把每个人的画拼到一起时严丝合缝?如果两个人画了…...

【无人机协同】联合优化无人机轨迹、发射功率与地面用户-MEC关联的多无人机多地面用户系统 附matlab代码✅
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量m…...

从零到告警:用Prometheus+SNMP监控华为交换机,并配置Grafana看板与告警规则
从零构建华为交换机智能监控体系:PrometheusSNMP实战指南 当机房里的华为交换机突然宕机时,运维团队往往要面对业务部门的连环追问。传统的人工巡检方式就像用体温计量火山喷发——既滞后又无力。本文将手把手带您搭建从数据采集到告警响应的完整监控闭环…...

机器学习入门实战指南:从零搭建环境到完成第一个分类项目
1. 项目概述:从零开始的机器学习之旅“机器学习”这个词,听起来是不是既酷炫又让人望而生畏?你可能在新闻里看到它驱动着自动驾驶汽车,在手机里体验过它带来的智能推荐,甚至听说它正在改变各行各业。但当你真正想自己动…...