【Python TensorFlow】入门到精通

TensorFlow 是一个开源的机器学习框架,由 Google 开发,广泛应用于机器学习和深度学习领域。本篇将详细介绍 TensorFlow 的基础知识,并通过一系列示例来帮助读者从入门到精通 TensorFlow 的使用。
1. TensorFlow 简介
1.1 什么是 TensorFlow?
TensorFlow 是一个开源的软件库,主要用于数值计算,特别是在机器学习和深度学习领域。它提供了一个灵活的架构来定义复杂的数据流图,并在多种平台上高效执行。
1.2 TensorFlow 的特点
- 灵活性:可以轻松构建复杂的计算图。
- 可移植性:可以在多种平台上运行,如桌面、服务器、移动设备等。
- 高性能:支持 GPU 和 TPU 加速计算。
- 丰富的 API:提供了多种 API,如 Keras 高层接口,方便开发者快速搭建模型。
2. 安装 TensorFlow
2.1 安装环境
确保安装了 Python(推荐版本 3.6 及以上),并安装 pip 包管理工具。
2.2 安装 TensorFlow
通过 pip 命令安装 TensorFlow:
pip install tensorflow
如果需要支持 GPU 加速,还需安装额外的依赖,并指定安装支持 GPU 的版本:
pip install tensorflow-gpu
3. TensorFlow 基本概念
3.1 张量(Tensor)
在 TensorFlow 中,数据是以张量的形式存储的,张量可以看作是一个 n 维数组。例如,标量是一维张量,向量是二维张量,矩阵是三维张量,依此类推。
3.2 计算图(Graph)
TensorFlow 中的计算是在图中进行的,图由节点(Nodes)组成,节点代表数学运算,节点之间通过边(Edges)相连,边传递张量。
3.3 会话(Session)
会话是用来执行图中的运算的上下文。所有的运算必须在一个会话中执行。在 TensorFlow 2.x 中,会话的概念已经被简化,默认情况下,所有的操作都会立即执行。
4. 第一个 TensorFlow 程序
让我们编写一个简单的 TensorFlow 程序来演示基本的使用。
4.1 创建张量
import tensorflow as tf# 创建两个常量张量
a = tf.constant(5)
b = tf.constant(3)# 执行加法运算
result = tf.add(a, b)# 打印结果
print(result)
4.2 在会话中执行
在 TensorFlow 2.x 中,不需要显式地创建会话来执行运算,因为默认会在当前默认图中执行。
import tensorflow as tf# 创建两个常量张量
a = tf.constant(5)
b = tf.constant(3)# 执行加法运算
result = tf.add(a, b)# 打印结果
print(result.numpy()) # 使用 .numpy() 方法获取具体数值
5. 使用 Keras API
Keras 是一个用户友好的神经网络 API,它简化了 TensorFlow 的使用,使得构建和训练模型变得更加简单。
5.1 构建一个简单的模型
import tensorflow as tf
from tensorflow.keras import layers# 创建一个简单的线性模型
model = tf.keras.Sequential([layers.Dense(1, input_shape=(1,))
])# 编译模型
model.compile(optimizer='sgd', loss='mean_squared_error')# 生成一些模拟数据
xs = np.array([1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([1.0, 3.0, 5.0, 7.0], dtype=float)# 训练模型
model.fit(xs, ys, epochs=500)# 预测
print(model.predict([10.0]))
6. 构建更复杂的模型
TensorFlow 不仅可以用来创建简单的线性模型,还可以用来构建复杂的神经网络模型。
6.1 构建一个卷积神经网络(CNN)
import tensorflow as tf
from tensorflow.keras import layers# 定义输入形状
input_shape = (28, 28, 1)# 创建一个简单的 CNN 模型
model = tf.keras.Sequential([layers.Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape),layers.MaxPooling2D(pool_size=(2, 2)),layers.Conv2D(64, kernel_size=(3, 3), activation='relu'),layers.MaxPooling2D(pool_size=(2, 2)),layers.Flatten(),layers.Dense(128, activation='relu'),layers.Dense(10, activation='softmax')
])# 编译模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 加载 MNIST 数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()# 数据预处理
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]# 训练模型
model.fit(x=x_train, y=y_train, epochs=5)# 测试模型
model.evaluate(x_test, y_test)
7. 高级主题
7.1 模型保存与加载
# 保存模型
model.save('my_model.h5')# 加载模型
model = tf.keras.models.load_model('my_model.h5')
7.2 自定义层与模型
在某些情况下,预定义的层可能无法满足需求,这时可以自定义层。
import tensorflow as tfclass MyLayer(layers.Layer):def __init__(self, output_dim, **kwargs):self.output_dim = output_dimsuper(MyLayer, self).__init__(**kwargs)def build(self, input_shape):self.kernel = self.add_weight(name='kernel', shape=(input_shape[1], self.output_dim),initializer='uniform',trainable=True)super(MyLayer, self).build(input_shape)def call(self, x):return tf.matmul(x, self.kernel)def get_config(self):config = super(MyLayer, self).get_config()config.update({'output_dim': self.output_dim})return config@classmethoddef from_config(cls, config):return cls(**config)custom_layer = MyLayer(output_dim=32)
7.3 使用 TensorBoard 进行可视化
TensorBoard 是 TensorFlow 提供的一个可视化工具,可以用来查看模型的结构、训练过程中的指标变化等。
# 启动 TensorBoard
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")# 训练模型
model.fit(x=x_train, y=y_train, epochs=5, callbacks=[tensorboard_callback])
然后在命令行启动 TensorBoard:
tensorboard --logdir logs
并在浏览器中访问 http://localhost:6006/ 来查看可视化结果。
8. 深入理解 TensorFlow
8.1 动态图(Eager Execution)
在 TensorFlow 2.x 中,默认启用了 Eager Execution,这意味着操作立即被执行并返回结果。这种模式使得调试变得更容易,也更接近于 Python 的常规编程方式。
import tensorflow as tfa = tf.constant(5)
b = tf.constant(3)
result = a + b
print(result)
8.2 数据管道(Data Pipeline)
TensorFlow 提供了 tf.data API 来构建高效的数据输入管道。这对于处理大规模数据集尤其有用。
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train)).shuffle(10000).batch(32)model.fit(dataset, epochs=5)
8.3 分布式训练
对于大规模数据集或大型模型,分布式训练可以显著提高训练速度。TensorFlow 支持多种分布式训练策略。
strategy = tf.distribute.MirroredStrategy()with strategy.scope():model = tf.keras.Sequential([layers.Dense(1, input_shape=(1,))])model.compile(optimizer='sgd', loss='mean_squared_error')
9. 实战案例
9.1 文本分类
文本分类是自然语言处理中的一个重要任务。下面是一个简单的文本分类模型的例子。
import tensorflow as tf
from tensorflow.keras import layers# 构建一个简单的文本分类模型
model = tf.keras.Sequential([layers.Embedding(input_dim=10000, output_dim=16),layers.GlobalAveragePooling1D(),layers.Dense(16, activation='relu'),layers.Dense(1, activation='sigmoid')
])# 编译模型
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])# 加载 IMDB 数据集
imdb = tf.keras.datasets.imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)# 将数据转换为向量
def vectorize_sequences(sequences, dimension=10000):results = np.zeros((len(sequences), dimension))for i, sequence in enumerate(sequences):results[i, sequence] = 1.return resultsx_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')# 训练模型
model.fit(x_train, y_train, epochs=10, batch_size=512)# 评估模型
results = model.evaluate(x_test, y_test)
9.2 图像识别
图像识别是计算机视觉中的一个重要应用。下面是一个简单的图像识别模型的例子。
import tensorflow as tf
from tensorflow.keras import layers# 构建一个简单的图像识别模型
model = tf.keras.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(128, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(128, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Flatten(),layers.Dense(512, activation='relu'),layers.Dense(1, activation='sigmoid')
])# 编译模型
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy'])# 加载图像数据
from tensorflow.keras.preprocessing.image import ImageDataGeneratortrain_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory('data/train',target_size=(150, 150),batch_size=20,class_mode='binary')validation_generator = test_datagen.flow_from_directory('data/validation',target_size=(150, 150),batch_size=20,class_mode='binary')# 训练模型
history = model.fit(train_generator,steps_per_epoch=100,epochs=30,validation_data=validation_generator,validation_steps=50)
10. 结论
通过本篇的学习,你已经掌握了 TensorFlow 的基本概念和使用方法,并通过一系列示例了解了如何构建和训练不同的机器学习模型。随着不断的实践和探索,你将能够更加熟练地应用这些技术来解决实际问题。希望这篇文章能够帮助你在机器学习和深度学习的道路上迈出坚实的一步。
相关文章:
【Python TensorFlow】入门到精通
TensorFlow 是一个开源的机器学习框架,由 Google 开发,广泛应用于机器学习和深度学习领域。本篇将详细介绍 TensorFlow 的基础知识,并通过一系列示例来帮助读者从入门到精通 TensorFlow 的使用。 1. TensorFlow 简介 1.1 什么是 TensorFlow…...

数据结构:七种排序及总结
文章目录 排序一插入排序1直接插入排序2希尔排序二选择排序3直接选择排序4堆排序三 交换排序5冒泡排序6快速排序四 归并排序7归并排序源码 排序 我们数据结构常见的排序有四大种,四大种又分为七小种,如图所示 排序:所谓排序,就是…...
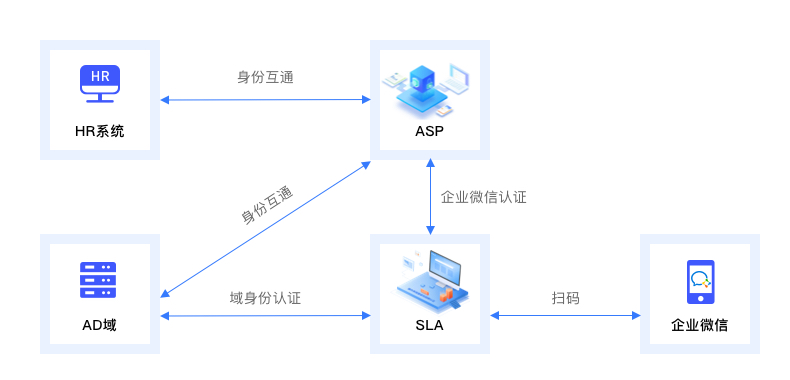
【安当产品应用案例100集】030-使用企业微信登录Windows,实现工作电脑与业务系统登录方式统一
随着越来越多的企业信息系统从intranet开放到internet,企业员工的办公接入方式也越发多样,信息系统面临的数据安全问题也呈现爆发的趋势。一些大企业,比如Google、Microsoft、Huawei有强大的开发能力、IT能力,可以构建出自己的零信…...

大数据数据存储层MemSQL, HBase与HDFS
以下是对 MemSQL、HBase 和 HDFS 的详细介绍,这些工具在分布式数据存储和处理领域有着重要作用。 1. MemSQL MemSQL(现称为 SingleStore)是一种分布式内存数据库,兼具事务处理(OLTP)和分析处理(OLAP)的能力,专为高性能实时数据处理设计。 1.1 核心特点 内存优先存储…...

【HarmonyOS】鸿蒙应用设置控件通用样式AttributeModifier, @Styles
【HarmonyOS】鸿蒙应用设置控件通用样式AttributeModifier, Styles 前言 在鸿蒙中UI开发经常需要对控件样式进行统一的封装,在API早前版本,一般是通过 Styles进行样式封装复用: Entry Component struct Index {build() {Column(…...

Scala IF...ELSE 语句
Scala IF...ELSE 语句 Scala 是一种多范式的编程语言,它结合了面向对象和函数式编程的特点。在 Scala 中,if...else 语句是一种基本且常用的控制结构,用于根据条件执行不同的代码块。与 Java 或 Python 等其他语言中的 if...else 语句类似&a…...
快速上手vue3+js+Node.js
安装Navicat Premium Navicat Premium 创建一个空的文件夹(用于配置node) 生成pakeage.json文件 npm init -y 操作mysql npm i mysql2.18.1 安装express搭建web服务器 npm i express4.17.1安装cors解决跨域问题 npm i cors2.8.5创建app.js con…...

06 网络编程基础
目录 1.通信三要素 1. IP地址(Internet Protocol Address) 2. 端口号(Port Number) 3. 协议(Protocol) 2.TCP与UDP协议 三次握手(Three-Way Handshake) 四次挥手(…...
)
Python 的 FastApi 如何在request 重复取request.body()
需求背景: 需要再中间件中获取body 中的信息 但是 又想要在之后 还可以重复取 这个body 因为有的接口写法是直接从body中获取参数,然而这个body是数据流的形式,一旦取一次就导致后面取不到里面的值了 。 解决方式: 1.保存请求体: 在中间件中读取请求…...

qt QFontDialog详解
1、概述 QFontDialog 是 Qt 框架中的一个对话框类,用于选择字体。它提供了一个可视化的界面,允许用户选择所需的字体以及相关的属性,如字体样式、大小、粗细等。用户可以通过对话框中的选项进行选择,并实时预览所选字体的效果。Q…...

AI时代,通才可能会占据更有利的地位
在AI时代,通才不仅有生存的可能,而且根据多个参考内容,他们实际上可能占据更有利的地位。以下几点解释了为什么通才在人工智能时代具有重要性和生存空间: 适应性和灵活性:通才因其广泛的知识基础和跨领域的技能&#x…...
qt QHeaderView详解
1、概述 QHeaderView 是 Qt 框架中的一个类,它通常作为 QTableView、QTreeView 等视图类的一部分,用于显示和管理列的标题(对于水平头)或行的标题(对于垂直头)。QHeaderView 提供了对这些标题的排序、筛选…...

探索PickleDB:Python中的轻量级数据存储利器
文章目录 探索PickleDB:Python中的轻量级数据存储利器1. 背景:为什么选择PickleDB?2. PickleDB是什么?3. 如何安装PickleDB?4. 简单的库函数使用方法创建和打开数据库设置数据获取数据删除数据保存数据库 5. 应用场景与…...

yocto下编译perf失败的解决方法
文章目录 问题分析库没有安装?文件缺少?解决参考问题 在新环境使用yocto编译镜像时,发现最后一直编译不过perf,具体的编译提示错误如下 ERROR: perf-1.0-r9 do_compile: oe_runmake failed ERROR: perf-1.0-r9 do_compile: Execution of /home/ub-1001/work/as66/imx8LBV…...

丹摩征文活动|详解 DAMODEL(丹摩智算)平台:为 AI 开发者量身打造的智算云服务
本文 什么是 DAMODEL(丹摩智算)?DAMODEL 的平台特性快速上手 DAMODEL 平台GPU 实例概览创建 GPU 云实例 储存选项技术支持与社区服务结语 在人工智能领域的飞速发展中,计算资源与平台的选择变得尤为重要。为了帮助 AI 开发者解决高…...

ORACLE _11G_R2_ASM 常用命令
--------查看磁盘组,(空间情况) select name,state,free_mb,total_mb,usable_file_mb from v$asm_diskgroup; --------查看磁盘情况 select GROUP_NUMBER,free_mb,total_mb,disk_number,MOUNT_STATUS,mode_status, HEADER_STATUS,name,PATH from v$asm_disk order …...

掌握Rust模式匹配:从基础语法到实际应用
本篇文章将探讨 Rust 编程语言中至关重要的特性之一——模式匹配。Rust 语言的模式匹配功能强大,不仅能处理简单的值匹配,还能解构和操作复杂的数据结构。通过深入学习模式匹配,程序员可以更加高效地编写出清晰、简洁且易于维护的代码。 Rus…...

HFSS 3D Layout中Design setting各个选项的解释
从HFSS 3D LAYOUT菜单中,选择Design Settings打开窗口,会有六个选项:DC Extrapolation, Nexxim Options, Export S Parameters, Lossy Dielectrics, HFSS Meshing Method, and HFSS Adaptive Mesh. DC Extrapolation 直流外推 直流外推分为标…...

线性表之链表详解
欢迎来到我的:世界 希望作者的文章对你有所帮助,有不足的地方还请指正,大家一起学习交流 ! 目录 前言线性表的概述链表的概述 内容链表的结构链表节点的定义 链表的基本功能单向链表的初始化链表的插入操作头插操作尾插操作 链表的删除操作头…...

C/C++使用AddressSanitizer检测内存错误
AddressSanitizer 是一种内存错误检测工具,编译时添加 -fsanitizeaddress 选项可以在运行时检测出非法内存访问,当发生段错误时,AddressSanitizer 会输出详细的错误报告,包括出错位置的代码行号和调用栈,有助于快速定位…...

生物信息学流水线效率翻倍:在Linux集群上为fastp v0.23.4配置多线程与批量处理脚本
生物信息学流水线效率翻倍:在Linux集群上为fastp v0.23.4配置多线程与批量处理脚本 当实验室的测序仪每天吐出TB级的FASTQ文件时,生物信息工程师的终端里往往挤满了等待处理的nohup进程。我们曾用三台服务器连续运行72小时才完成某批800个样本的质控——…...

Linux包管理核心:yum机制详解与实战配置指南
1. 项目概述:为什么你需要掌握yum?在Linux的世界里,尤其是以Red Hat、CentOS、Fedora为代表的发行版中,yum(Yellowdog Updater, Modified)是每一位系统管理员和开发者绕不开的核心工具。你可以把它想象成一…...

uniapp监听PDA扫码,除了广播还能怎么玩?聊聊H5+扩展与原生插件的选择
Uniapp中PDA扫码方案深度对比:从广播监听走向原生封装 在工业级移动应用开发中,PDA(便携式数据采集器)的扫码功能集成一直是刚需场景。霍尼韦尔EDA50P等专业设备虽然提供了默认的广播机制,但随着业务复杂度提升&#x…...

推理服务为什么一上模型压缩组合就开始精度雪崩:从量化-剪枝-蒸馏的叠加效应到恢复策略的工程实战
一、精度雪崩的生产现场 🔥 某团队部署 LLaMA-2-7B 推理服务时,为降低显存、提升吞吐,同时对模型做 W4A16 量化、30% 结构化剪枝与层蒸馏。单独测试时,量化版困惑度上升 8%,剪枝版上升 12%,蒸馏版上升 15%。…...

细胞的“近距离对话大师”——Notch信号通路
在我们身体里,细胞并非孤立存在,它们通过信号通路精准沟通,其中Notch信号通路堪称细胞间的“近距离对话大师”,从果蝇到人类都高度保守,不靠远距离信号扩散,仅靠相邻细胞“面对面接触”,就能掌控…...

别再浪费主板上的PCIE插槽了!手把手教你用VL805芯片打造高速USB3.0扩展坞
释放主板潜能:基于VL805芯片的USB3.0扩展方案实战指南 当你的工作台摆满外设却苦于主板接口不足时,那些闲置的PCIE插槽正等待被唤醒。本文将从芯片选型到性能调优,完整呈现如何将一块VL805-QFN68芯片转化为高性能USB3.0扩展方案。 1. 硬件选型…...
)
Perplexity教育信息检索效率提升70%:从零到精通的4步优化法(附实测数据)
更多请点击: https://kaifayun.com 第一章:Perplexity教育信息检索效率提升70%:从零到精通的4步优化法(附实测数据) Perplexity 作为面向研究与教育场景的AI原生搜索引擎,其语义理解深度与引用溯源能力显著…...

Captain AI助力Ozon大卖店群高效管理,实现规模化运营
随着Ozon商家运营规模的扩大,多店铺运营(店群)成为很多资深大卖的选择,通过多店铺布局,可扩大市场覆盖、分散运营风险、提升整体销量。但店群运营过程中,商家常常面临“管理繁琐、数据混乱、效率低下”的问…...

ASML财报解析:EUV光刻机如何驱动半导体产业高增长
1. 财报数据深度拆解:高毛利与利润倍增的背后ASML刚刚发布的第二季度财报,无疑是全球半导体产业的一剂强心针。当看到毛利率稳稳站在50%以上,每股净利润几乎翻倍增长时,我第一反应不是惊讶,而是“果然如此”。这组数据…...
怎么选?实测对比告诉你答案)
Ollama三大嵌入模型(mxbai/nomic/all-minilm)怎么选?实测对比告诉你答案
Ollama三大嵌入模型深度评测:mxbai/nomic/all-minilm技术选型实战指南 当你在构建RAG(检索增强生成)系统时,嵌入模型的选择往往决定了整个应用的核心性能。Ollama作为当前最热门的本地大模型运行框架,支持mxbai-embed-…...