操作系统页面置换算法Java实现(LFU,OPT,LRU,LFU,CLOCK)
FIFO先进先出算法
```java import java.util.LinkedList; import java.util.Queue;public class Main {
//先进先出的思想 是 用一个队列去模拟数据 如果当前不存在就是发生缺页中断了 就需要添加 如果已经满了 将队头的元素出队 即可
//先进先出 就是一个数组 frameCount
public static int FIFO(int[] pages, int frameCount) {
Queue queue = new LinkedList<>();
int pagesFaults = 0; //页面终端的次数
for (int page : pages) {
if (!queue.contains(page)) {
//不存在就缺页了
pagesFaults++;
// 如果页面框架已满,则移除最早进入的页面
if (queue.size() == frameCount) {
queue.poll(); // 移除最早的页面)
}
queue.add(page);
}
System.out.println("页面: " + page + " -> 内存框架: " + queue);
}
return pagesFaults;
}
public static void main(String[] args) {int arr1[] = {3, 2, 1, 0, 3, 2, 4, 3, 2, 1, 0, 4};System.out.println(FIFO(arr1, 3));System.out.println("验证bleady现象");int arr2[] = {3, 2, 1, 0, 3, 2, 4, 3, 2, 1, 0, 4};System.out.println(FIFO(arr2, 4));
}
}
<h3 id="OikGZ">OPT最佳置换算法</h3>
选择淘汰以后永远不使用的页面或者在最长时间内不再被使用的页面。双层for 循环当前的页面内元素,找到一个不存在或者位置最后的```java
import java.util.LinkedList;
import java.util.Queue;public class Main {public static int OPT(int[] pages, int frameCount) {Queue<Integer> queue = new LinkedList<>();int pageFaults = 0;int n = pages.length;for (int i = 0; i < n; i++) {if (!queue.contains(pages[i])) {pageFaults++; //发生页面中断了if (queue.size() == frameCount) {//考虑淘汰谁出去int page = findPage(queue, pages, i); //往后看queue.remove(page); // 删除需要置换的页面}queue.add(pages[i]);}System.out.println("页面: " + pages[i] + " -> 内存框架: " + queue);}return pageFaults;}private static int findPage(Queue<Integer> pageFrames, int[] pages, int currentIndex) {int farthestIndex = -1;int pageToReplace = -1;// 遍历当权的queuefor (int page : pageFrames) {int nextUseIndex = Integer.MAX_VALUE; //假设最远的位置// 找出页面下次访问的索引位置for (int j = currentIndex + 1; j < pages.length; j++) {if (pages[j] == page) {nextUseIndex = j;break;}}// 找到下次使用最远的页面if (nextUseIndex > farthestIndex) {farthestIndex = nextUseIndex;pageToReplace = page;}}return pageToReplace;}public static void main(String[] args) {int[] a = {7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1};System.out.println(OPT(a, 3));}
}

LRU缓存算法
```java import java.util.LinkedList; import java.util.Queue;public class Main {
public static int LRU(int[] pages, int frameCount) {Queue<Integer> queue = new LinkedList<>();int frageCount = 0;int n = pages.length;for (int i = 0; i < n; i++) {int page = pages[i];boolean flag=false;if (!queue.contains(page)) {flag=true;frageCount++;//移除头部 添加到末尾去if (queue.size() == frameCount) {queue.poll(); //弹出最久没有使用的}queue.add(page);} else {//先移除queue.remove(page);//再加到末尾queue.add(page);}System.out.print("页面: " + page + " -> 内存框架: " + queue);if (flag==true){System.out.println(" 发生缺页中断");}else{System.out.println();}}return frageCount;
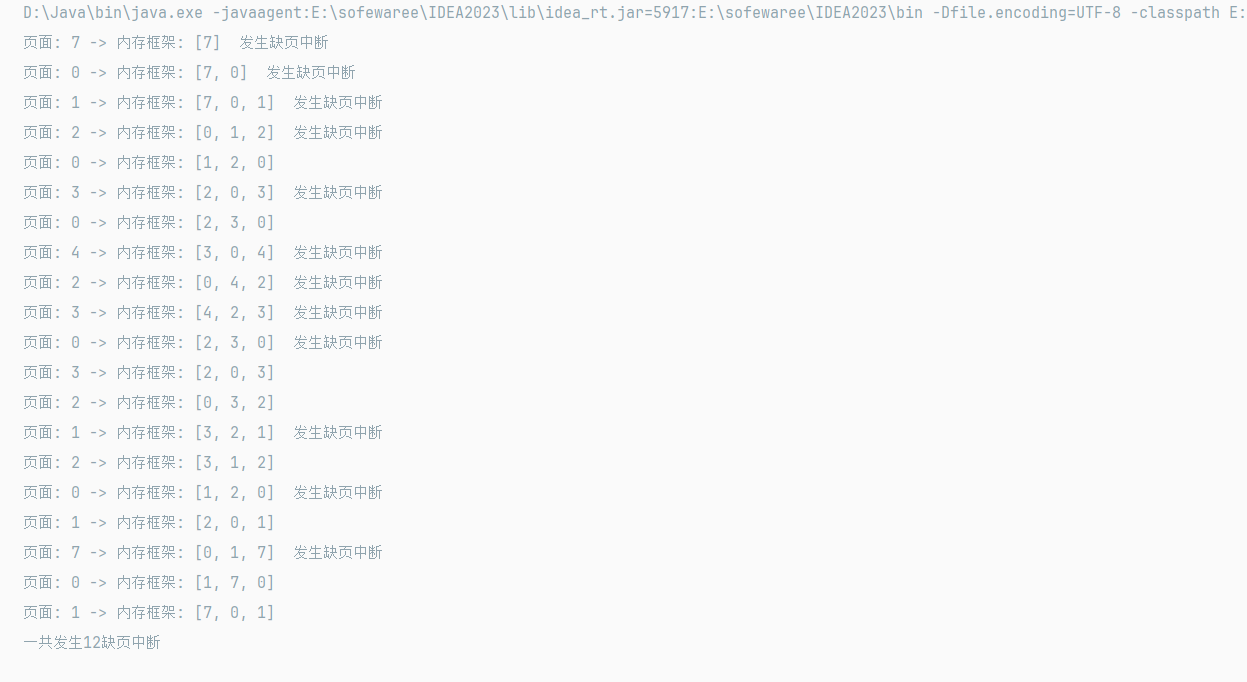
}public static void main(String[] args) {int[] a = {7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1};System.out.println("一共发生"+LRU(a, 3)+"缺页中断");
}
}
<h3 id="AZw5J">Clock时钟算法</h3>
<h3 id="e0704aae">**Clock算法的步骤**</h3>
1. **初始化**:- 为每个页面框架分配一个**使用位**,初始为0。- 设置一个指针(通常称为“手”)指向第一个页面框架。
2. **页面访问**:- 当一个页面被访问时:* **如果页面已经在内存中,设置其使用位为1。*** **如果页面不在内存中,发生页面缺失:**+ **如果有空闲的页面框架,直接将页面加载到空闲框架中,并设置使用位为1。**+ **如果没有空闲框架,启动页面置换过程。**
3. **页面置换**:- 检查指针指向的页面的使用位:* **使用位为0**:将该页面置换出去,加载新页面到该位置,并将使用位设置为1。然后将指针移动到下一个页面框架。* **使用位为1**:将使用位重置为0,指针移动到下一个页面框架,继续检查。- 重复上述过程,直到找到一个使用位为0的页面进行置换。```java
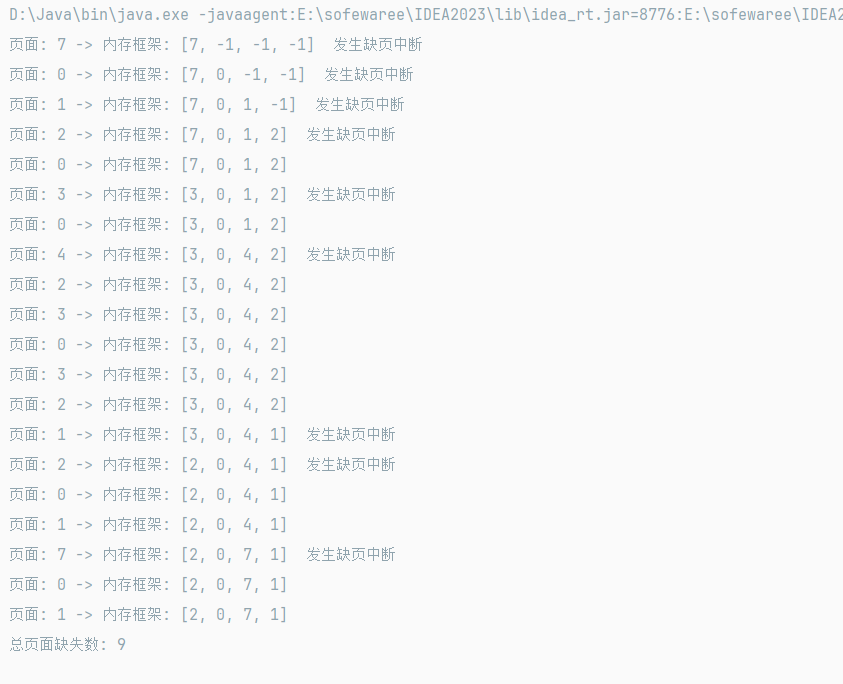
package 操作系统代码.页面置换算法.clock时钟算法;import java.util.Arrays;public class Main {//要构建成一个循环的 指针 通过取模来实现public static int CLOCK(int[] pages, int fragmeCount) {int[] pageFrames = new int[fragmeCount]; //创建一共循环块Arrays.fill(pageFrames, -1); //刚开始的框架boolean[] useBits = new boolean[fragmeCount]; //访问位int current = 0; //当前所在int pageFaults = 0;//页面确实for (int page : pages) {boolean flag=false;boolean isExist = false;int frameIndex = -1;//如果存在 访问为变为truefor (int i = 0; i < fragmeCount; i++) {if (pageFrames[i] == page) {frameIndex = i;isExist = true;break;}}if (isExist) {useBits[frameIndex] = true;} else {pageFaults++;flag=true;while (true) {if (!useBits[current]) { //当前访问位为0 也就是false1了 将当前的移除pageFrames[current] = page;useBits[current] = true;current = (current + 1) % fragmeCount;break;} else {useBits[current] = false;current = (current + 1) % fragmeCount;}}}System.out.print("页面: " + page + " -> 内存框架: " + Arrays.toString(pageFrames));if (flag==true){System.out.println(" 发生缺页中断");}else{System.out.println();}}return pageFaults;}public static void main(String[] args) {int[] a = {7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1};int frameCount = 4; // 页面框架数量int totalPageFaults = CLOCK(a, frameCount);System.out.println("总页面缺失数: " + totalPageFaults);}
}
LFU算法
LFU(**Least Frequently Used**,**最不经常使用**)算法是一种页面置换策略,旨在通过替换使用频率最低的页面来优化内存管理。这种算法基于一个假设:那些在过去较少被访问的页面,在未来也可能不常被访问,因此更适合被置换出去。### **LFU算法的基本思想**LFU算法选择那些在当前内存中被访问次数最少的页面进行置换。与其他算法(如FIFO、LRU)主要关注页面的时间特性不同,LFU关注的是页面的频率特性。具体来说,当需要置换页面时,LFU会:1. **统计每个页面的访问频率**:记录每个页面在内存中被访问的次数。
2. **选择访问频率最低的页面**:当内存已满且需要置换页面时,选择访问频率最少的页面进行置换。
3. **处理频率相同的页面**:如果有多个页面具有相同的最低访问频率,可以采用其他策略(如FIFO)来决定具体置换哪个页面。### **LFU算法的工作步骤**1. **初始化**:- 创建一个数据结构(通常是哈希表)来存储当前内存中的页面及其对应的访问频率。- 设置页面框架的数量(即内存中可以同时容纳的页面数量)。2. **页面访问**:- **页面命中**(Page Hit):如果访问的页面已经在内存中,增加该页面的访问频率。- **页面缺失**(Page Fault):如果访问的页面不在内存中,发生页面缺失。- 如果内存中还有空闲页面框架,直接将新页面加载到空闲框架中,并将其访问频率设置为1。- 如果内存已满,选择访问频率最低的页面进行置换,将新页面加载到该位置,并将新页面的访问频率设置为1。3. **频率更新**:- 每次页面被访问时,更新其访问频率。- 在某些实现中,可能需要周期性地调整频率计数器以防止频率数值无限增大。### **LFU算法的优缺点**#### **优点**1. **高效的频率管理**:LFU算法能够有效地管理页面的访问频率,减少那些经常被访问的页面被置换的可能性。
2. **适用于频繁访问模式**:在某些应用场景中,如缓存系统,LFU算法能够保持热点数据在内存中,提高系统性能。#### **缺点**1. **实现复杂**:相比FIFO和LRU,LFU需要维护额外的频率计数器,增加了实现的复杂性。
2. **不适应动态访问模式**:如果某些页面的访问频率在一段时间后突然下降,LFU可能仍然保留这些页面,导致新热点页面被频繁置换。
3. **频率数值膨胀**:频率计数器可能随着时间的推移而变得非常大,需要定期重置或使用其他技术来管理频率数值。### **LFU算法的示例**假设有3个页面框架,页面访问序列为:`[1, 2, 3, 2, 4, 1, 5, 2, 1, 2, 3, 4, 5]`#### **步骤解析**| 步骤 | 访问页面 | 页面框架状态 | 访问频率(页面:频率) | 页面缺失 |
|------|----------|-----------------------|-----------------------|----------|
| 1 | 1 | [1, -, -] | {1:1} | 是 |
| 2 | 2 | [1, 2, -] | {1:1, 2:1} | 是 |
| 3 | 3 | [1, 2, 3] | {1:1, 2:1, 3:1} | 是 |
| 4 | 2 | [1, 2, 3] | {1:1, 2:2, 3:1} | 否 |
| 5 | 4 | [1, 2, 4] | {1:1, 2:2, 4:1} | 是(置换页面3)|
| 6 | 1 | [1, 2, 4] | {1:2, 2:2, 4:1} | 否 |
| 7 | 5 | [5, 2, 4] | {5:1, 2:2, 4:1} | 是(置换页面1)|
| 8 | 2 | [5, 2, 4] | {5:1, 2:3, 4:1} | 否 |
| 9 | 1 | [5, 2, 1] | {5:1, 2:3, 1:1} | 是(置换页面4)|
| 10 | 2 | [5, 2, 1] | {5:1, 2:4, 1:1} | 否 |
| 11 | 3 | [5, 2, 3] | {5:1, 2:4, 3:1} | 是(置换页面1)|
| 12 | 4 | [5, 2, 4] | {5:1, 2:4, 4:2} | 是(置换页面3)|
| 13 | 5 | [5, 2, 4] | {5:2, 2:4, 4:2} | 否 |**总页面缺失数:8**#### **解释**1. **步骤1-3**:加载页面1、2、3到内存,均发生页面缺失。
2. **步骤4**:页面2已在内存中,更新其频率。
3. **步骤5**:页面4缺失,选择频率最低的页面3进行置换(页面1和3的频率均为1,但假设选择了页面3)。
4. **步骤6**:页面1已在内存中,更新其频率。
5. **步骤7**:页面5缺失,选择频率最低的页面1进行置换。
6. **步骤8**:页面2已在内存中,更新其频率。
7. **步骤9**:页面1缺失,选择频率最低的页面4进行置换。
8. **步骤10**:页面2已在内存中,更新其频率。
9. **步骤11**:页面3缺失,选择频率最低的页面1进行置换。
10. **步骤12**:页面4缺失,选择频率最低的页面3进行置换。
11. **步骤13**:页面5已在内存中,更新其频率。### **LFU算法的实现示例(Java)**以下是一个简单的Java实现示例,展示如何使用LFU算法进行页面置换:```java
import java.util.*;public class LFUPageReplacement {public static int LFU(int[] pages, int frameCount) {// 用于存储当前内存中的页面及其频率Map<Integer, Integer> pageFrequency = new HashMap<>();// 用于存储页面的插入顺序(用于处理频率相同的页面,FIFO)Map<Integer, Integer> pageTime = new HashMap<>();int pageFaults = 0;int currentTime = 0;for (int page : pages) {currentTime++;if (!pageFrequency.containsKey(page)) {// 页面缺失pageFaults++;if (pageFrequency.size() == frameCount) {// 找到最不常使用的页面int lfuPage = -1;int minFreq = Integer.MAX_VALUE;int oldestTime = Integer.MAX_VALUE;for (Map.Entry<Integer, Integer> entry : pageFrequency.entrySet()) {int p = entry.getKey();int freq = entry.getValue();if (freq < minFreq) {minFreq = freq;lfuPage = p;oldestTime = pageTime.get(p);} else if (freq == minFreq) {// 频率相同,选择最早插入的页面if (pageTime.get(p) < oldestTime) {lfuPage = p;oldestTime = pageTime.get(p);}}}// 移除LFU页面pageFrequency.remove(lfuPage);pageTime.remove(lfuPage);}// 添加新页面pageFrequency.put(page, 1);pageTime.put(page, currentTime);} else {// 页面命中,增加频率pageFrequency.put(page, pageFrequency.get(page) + 1);}System.out.println("页面: " + page + " -> 当前内存: " + pageFrequency);}return pageFaults;}public static void main(String[] args) {int[] pages = {1, 2, 3, 2, 4, 1, 5, 2, 1, 2, 3, 4, 5};int frameCount = 3;int faults = LFU(pages, frameCount);System.out.println("总页面缺失数: " + faults);}
}
代码解释
-
数据结构:
pageFrequency:存储每个页面的访问频率。pageTime:记录每个页面第一次被加载到内存中的时间,用于处理频率相同的页面置换(FIFO)。
-
页面访问处理:
- 页面缺失:
- 增加页面缺失计数。
- 如果内存已满,找到频率最低且最早加载的页面进行置换。
- 将新页面添加到内存中,初始化其频率为1,并记录加载时间。
- 页面命中:
- 增加该页面的访问频率。
- 页面缺失:
-
输出:
- 每次页面访问后,打印当前内存中所有页面及其访问频率。
- 最终输出总的页面缺失次数。
LFU算法的优缺点总结
优点:
- 有效的频率管理:能够保留那些被频繁访问的页面,减少页面缺失次数。
- 适用于特定场景:在一些访问模式中(如热点数据频繁访问),LFU表现优异。
缺点:
- 实现复杂:需要维护额外的数据结构(频率计数器和时间戳),增加了实现的复杂性。
- 频率衰减问题:某些实现中,频率计数器可能会无限增大,需定期重置或采用其他衰减策略。
- 不适应动态访问模式:如果某些页面的访问频率突然下降,LFU可能仍然保留这些页面,导致新热点页面被频繁置换。
- 缓存污染:对于一次性访问的页面,频率会被计入,可能导致其他需要长期缓存的页面被置换。
总结
LFU(最不经常使用)算法通过跟踪每个页面的访问频率,选择访问次数最少的页面进行置换,从而优化内存管理。尽管LFU在某些场景下表现出色,但其实现复杂性和对动态访问模式的不适应性使其在实际操作系统中的应用受到一定限制。为了解决这些问题,研究人员提出了多种改进版的LFU算法,如LFU-K、LFU with Dynamic Aging等,以提升算法的性能和适应性。
LFU(Least Frequently Used,最不经常使用)是一种缓存替换算法。该算法根据数据的使用频率决定其被替换的优先级,优先淘汰使用频率最低的数据,保留那些被频繁访问的数据。LFU 算法适用于频繁访问的缓存项有较大概率被再次访问的场景。<h3 id="216c1668">LFU算法原理</h3>
LFU算法会为每个缓存项维护一个计数器,记录其被访问的次数。当缓存空间满了需要替换数据时,算法会选择访问频率最少的项进行淘汰。+ **频率计数**:每次缓存项被访问时,计数器会增加。
+ **淘汰策略**:当缓存满了,需要替换数据时,优先选择那些计数器值最小的项。如果有多个频率相同的项,通常会使用FIFO(先进先出)策略来选择最早进入缓存的项进行替换。<h3 id="eb40924e">实现要点</h3>
1. **哈希表+最小堆**:可以使用一个哈希表存储每个缓存项的访问频率,以及一个最小堆来管理频率最小的项。
2. **哈希表+双向链表**:用一个哈希表存储缓存项,另一个哈希表存储不同频率的双向链表,以实现按频率访问的组织结构,便于在相同频率时使用先进先出原则。
3. **计数器更新**:每次访问缓存项时,更新计数器,并将该项移动到相应频率的链表中。<h3 id="1a63ac23">示例</h3>
假设缓存容量为3:1. 缓存初始为空。
2. 访问数据`A`,缓存变为`[A:1]`。
3. 访问数据`B`,缓存变为`[A:1, B:1]`。
4. 访问数据`C`,缓存变为`[A:1, B:1, C:1]`。
5. 再次访问数据`A`,缓存变为`[A:2, B:1, C:1]`。
6. 访问数据`D`,缓存已满,需要淘汰一个数据。`B`和`C`频率相同,按照FIFO策略淘汰`B`,缓存变为`[A:2, C:1, D:1]`。<h3 id="78102351">优缺点</h3>
+ **优点**:适合访问频率较高的数据项。
+ **缺点**:对于某些在一段时间内频繁访问但后续不再访问的数据,可能会造成缓存命中率下降(“缓存污染”现象)。相关文章:
操作系统页面置换算法Java实现(LFU,OPT,LRU,LFU,CLOCK)
FIFO先进先出算法 java import java.util.LinkedList; import java.util.Queue; public class Main { //先进先出的思想 是 用一个队列去模拟数据 如果当前不存在就是发生缺页中断了 就需要添加 如果已经满了 将队头的元素出队 即可 //先进先出 就是一个数组 frameCount publi…...

Request和Response
前言 这一节主要讲的是Request和Response还有一些实例 1. 介绍 就是这两个参数 WebServlet("/demo7") public class ServletDemo7 extends HttpServlet {Overrideprotected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletExcepti…...

【青牛科技】GC8549替代LV8549/ONSEMI在摇头机、舞台灯、打印机和白色家电等产品上的应用分析
引言 在现代电子产品中,控制芯片的性能直接影响到设备的功能和用户体验。摇头机、舞台灯、打印机和白色家电等领域对控制精度、功耗和成本等方面的要求日益提高。LV8549/ONSEMI等国际品牌的芯片曾是这些产品的主要选择,但随着国内半导体技术的进步&…...
(十二)JavaWeb后端开发——MySQL数据库
目录 1.数据库概述 2.MyQSL 3.数据库设计 DDL 4.MySQL常见数据类型 5.DML 1.数据库概述 数据库:DataBase(DB),是存储和管理数据的仓库 数据库管理系统:DataBase ManagementSystem(DBMS),操纵和管理数据库的大型软件 SQL&a…...

pnpm管理多工作区依赖
pnpm是一个支持多包仓库的一个包管理工具,那么怎么可以在项目根目录下执行pnpm install的时候,也能同步让所有的工作区都能够通安装依赖呢? 方式一,在执行pnpm install指令的时候,添加recursive参数: pnpm install --recursive 方式二,在项目的根目录下通过pnpm的配置文件p…...
如何在本地Linux服务器搭建WordPress网站结合内网穿透随时随地可访问
文章目录 前言1. 安装WordPress2. 创建WordPress数据库3. 安装相对URL插件4. 安装内网穿透发布网站4.1 命令行方式:4.2. 配置wordpress公网地址 5. 配置WordPress固定公网地址 前言 本文主要介绍如何在Linux Ubuntu系统上使用WordPress搭建一个本地网站,…...

二、应用层,《计算机网络(自顶向下方法 第7版,James F.Kurose,Keith W.Ross)》
文章目录 零、前言一、应用层协议原理1.1 网络应用的体系结构1.1.1 客户-服务器(C/S)体系结构1.1.2 对等体(P2P)体系结构1.1.3 C/S 和 P2P体系结构的混合体 1.2 进程通信1.2.1 问题1:对进程进行编址(addressing)&#…...

面粉直供系统|基于java和小程序的食品面粉直供系统设计与实现(源码+数据库+文档)
面粉直供系统 目录 基于java和小程序的食品面粉直供系统设计与实现 一、前言 二、系统设计 三、系统功能设计 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍:✌️大厂码农|毕设布道师&#x…...
-- Spring Spring MVC)
十四:java web(6)-- Spring Spring MVC
目录 Spring MVC 1.1 Spring MVC 概述 1.1.1 什么是 MVC 模式 1.1.2 Spring MVC 工作原理 1.2 Spring MVC 核心组件 1.2.1 DispatcherServlet 1.2.2 控制器(Controller) 1.2.3 请求映射(RequestMapping) 1.2.4 视图解析器…...
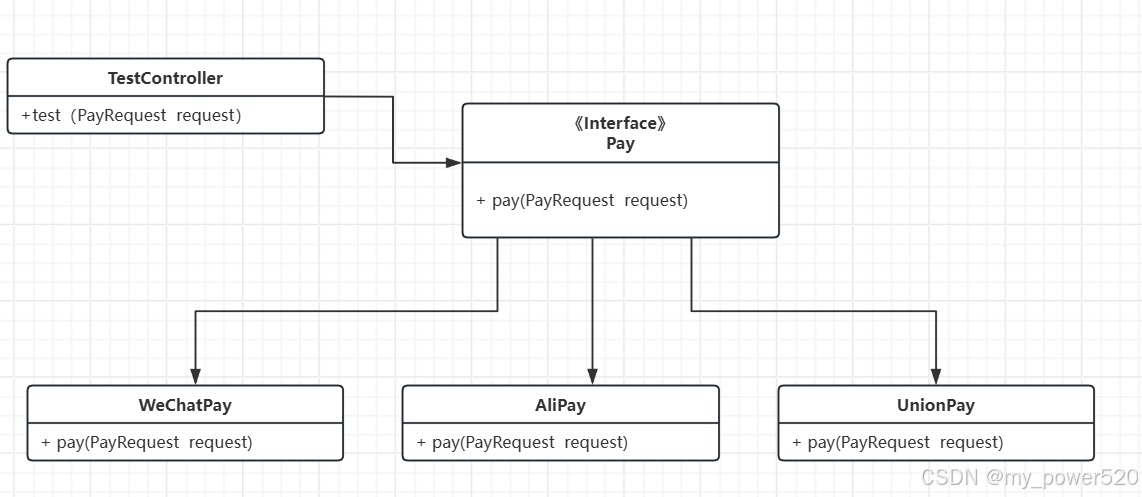
Java代码实现策略模式处理支付付款业务
1.需求:因为付款功能集成的第三方支付SDK越来越来多不好维护,改用策略模式实现,来代替代码中多余的if else 判断。 2.什么是策略模式? 策略模式(Strategy Pattern)是一种行为型设计模式,它允许在运行时选择算法的行为。该模式将不同的算法封装成独立的策略类,并使这些…...

unity3d————四元数概念
一、定义与表示 四元数是由一个实数部分和三个虚数部分组成,通常表示为q w xi yj zk,其中w是实数,x、y、z是实数系数,i、j、k是虚数单位,满足以下关系: i j k -1ij k,ji -kjk i&…...

spring相关的面试题
Spring 框架是 Java 开发中最常用的框架之一,因此在面试中经常会被问到与 Spring 相关的问题。以下是一些常见的 Spring 面试题及其答案。 基础概念 什么是 Spring 框架? Spring 框架是一个开源的 Java 平台,用于构建企业级应用程序。它提供…...

STM32外设之SPI的介绍
### STM32外设之SPI的介绍 SPI(Serial Peripheral Interface)是一种高速的,全双工,同步的通信总线,主要用于EEPROM、FLASH、实时时钟、AD转换器等外设的通信。SPI通信只需要四根线,节约了芯片的管脚&#x…...

二十三、Mysql8.0高可用集群架构实战
文章目录 一、MySQL InnoDB Cluster1、基本概述2、集群架构3、搭建一主两从InnoDB集群3.1、 安装3个数据库实例3.2、安装mysqlrouter和安装mysqlshell3.2.1、安装mysql-router3.2.2、安装mysql-shell 3.3、InnoDB Cluster 初始化3.3.1、参数及权限配置预需求检测3.3.2、初始化I…...

docker file 精简规则
在编写 Dockerfile 时,精简规则不仅有助于减小镜像大小,还能提高构建速度和可维护性。以下是一些常见的精简 Dockerfile 规则: 1. 尽量合并 RUN 指令 每个 RUN 指令会产生一个新的镜像层,因此多个命令可以合并为一个 RUN 指令&a…...

前端加密方式详解与选择指南
在当今数字化时代,前端数据安全的重要性日益凸显。本文将深入探讨前端加密的多种方式,为你提供选择适合项目加密方式的实用策略,并分享一些实际案例及相应代码。 一、前端加密方式汇总 (一)HTTPS 加密 HTTPS 是在 H…...

【React】条件渲染——逻辑与运算符
条件渲染——逻辑与&&运算符 你会遇到的另一个常见的快捷表达式是 JavaScript 逻辑与(&&)运算符。在 React 组件里,通常用在当条件成立时,你想渲染一些 JSX,或者不做任何渲染。 function Item({ nam…...

MATLAB中eig函数用法
目录 语法 说明 示例 矩阵特征值 矩阵的特征值和特征向量 排序的特征值和特征向量 左特征向量 不可对角化(亏损)矩阵的特征值 广义特征值 病态矩阵使用 QZ 算法得出广义特征值 一个矩阵为奇异矩阵的广义特征值 eig函数的功能是求取矩阵特征值…...

Chrome(谷歌浏览器中文版)下载安装(Windows 11)
目录 Chrome_10_30工具下载安装 Chrome_10_30 工具 系统:Windows 11 下载 官网:https://chrome.google-zh.com/,点击立即下载 下载完成(已经下过一遍所以点了取消) 安装 解压,打开安装包 点击下一步…...

Linux 配置JDK
文章目录 一、下载Oracle-JDK1.1、如何正确的下载JDK 二、配置JDK环境变量2.1 环境变量配置2.1.1、修改vim /etc/profile 添加jdk的路径 一、下载Oracle-JDK 1.1、如何正确的下载JDK 首先我要安装的是oracle-jdk,这个时候什么地方都不要去,就去oracle的…...

基于SUMO与PPO的智能换道决策实战:从环境构建到模型部署
1. 环境准备与基础配置 在开始构建智能换道决策系统之前,我们需要先搭建好开发环境。这里我推荐使用Anaconda来管理Python环境,它能很好地解决不同项目之间的依赖冲突问题。我习惯为每个项目创建独立的环境,比如这次我们可以命名为"sumo…...
)
【新手专属】OpenClaw 一键安装包:Windows 完整部署流程(含安装包)
OpenClaw 一键安装包|一键部署,告别复杂环境配置 适配系统:Windows 10/11 64 位当前版本:v2.7.5(虾壳云版)核心优势:全程可视化操作,无需命令行、无需手动配置 Python/Node.js&…...

研究助理/项目经理/内容编辑:Hermes Agent 3 类人格模板的 SOUL.md 配置要点
1. 三类人格不是“角色扮演”,而是上下文锚点的工程化切片 大多数人第一次看到 Hermes Agent 的 SOUL.md 配置时,会下意识把它当成一个“AI人设说明书”:研究助理要严谨、项目经理要干练、内容编辑要文雅。这种理解在小规模单次交互中勉强能用,但一旦进入真实研发流程——…...

前沿:小目标检测,YOLOv11n 再进化!
点击蓝字 关注我们 关注并星标 从此不迷路 计算机视觉研究院 公众号ID|计算机视觉研究院 学习群|扫码在主页获取加入方式 https://sensors.myu-group.co.jp/sm_pdf/SM4311.pdf 计算机视觉研究院专栏 Column of Computer Vision Institute 基于最新 YOLOv…...

从标签页混乱到高效工作流:Tabee如何彻底改变我的浏览器体验
从标签页混乱到高效工作流:Tabee如何彻底改变我的浏览器体验 【免费下载链接】chrome-tab-modifier Take control of your tabs 项目地址: https://gitcode.com/gh_mirrors/ch/chrome-tab-modifier 你是否曾经在几十个标签页中迷失方向?每个标签页…...

别再瞎猜了!LaTeX排版时em、ex、pt、px到底该用哪个?一篇讲透所有单位
LaTeX排版单位全指南:从em到px的精准选择策略 在学术写作和科技文档排版领域,LaTeX以其专业精美的输出质量著称。然而,对于初学者而言,面对em、ex、pt、px等多种长度单位时,常常陷入选择困难——图片宽度该用pt还是cm&…...

2026年照片去水印免费软件App推荐|主流工具优缺点对比与实测评价
处理照片时遇到水印,通常有两条路:要么花钱买专业软件,要么找个免费方案凑合着用。但2026年的现在,免费去水印工具已经相当能打了。无论是手机App、桌面软件还是在线网站,都能找到效果不错的免费选项。本文将详细介绍目…...

减肥成功的人,都有这 4 个共同点
减肥成功的人,都有这 4 个共同点 为什么你总是减肥失败,而有的人却轻松瘦下来不反弹? 今天告诉你真相 👇 01| 吃够基础代谢值 ❌ 极端节食 → 代谢下降 → 越减越肥 ✅ 男生 ≥1400 大卡,女生 ≥1100 大卡 …...

ARM架构LDRSB/LDRSH有符号加载指令详解
1. ARM架构中的有符号加载指令概述在嵌入式系统和低功耗应用领域,ARM处理器凭借其精简高效的指令集架构占据主导地位。内存加载指令作为处理器与外部存储交互的核心操作,其设计直接影响系统性能和数据处理的准确性。LDRSB(Load Register Sign…...
保姆级接线图解,附万用表检测电池坏点技巧)
别再乱接线了!12V手电钻保护板(B+/B-/B1/B2)保姆级接线图解,附万用表检测电池坏点技巧
12V手电钻保护板接线全攻略:从原理到实战的安全操作指南 面对手电钻保护板上密密麻麻的接线端子,即使是经验丰富的DIY爱好者也难免感到困惑。B、B-、B1、B2这些看似简单的标记背后,实际上隐藏着锂电池组安全工作的关键机制。本文将带您深入理…...