大语言模型(LLM)入门级选手初学教程 III
指令微调
一、指令数据的构建
包括任务描述(也称为指令)、任务输入-任务输出以及可选的示例。

- Self-Instruct
- 指令数据生成:从任务池中随机选取少量指令数据作为示例,并针对Chat-GPT 设计精细指令来提示模型生成新的微调数据

- 过滤与后处理:剔除低质量或者重复的生成实例:去除与任务池中指令相似度过高的指令、语言模型难以生成回复的指令、过长或过短的指令以及输入或输出存在重复的实例。
- Evol-Instruct
基于大语言模型的指令数据复杂化技术,基于初始指令数据集进行扩展
- 指令演化(深度和广度):深度演化通过五种特定类型的提示(添加约束、深化、具体化、增加推理步骤以及使输入复杂化)使得指令变得更加复杂与困难;而广度演化旨在扩充指令主题范围、指令涉及的能力范围以及整体数据集的多样性。


- 数据后处理:去除部分实例数据以保证数据集合的整体质量和多样性。
-
指令数据构建的提升方法
1)指令格式设计:指令+示例
训练过程中同时使用了带示例的指令数据(即少样本)和不带示例的指令数据(即零样本),混合提示的训练方式有助于同时改善下游任务中少样本和零样本的测试效果。引入思维链数据,例如算术推理的逐步解答过程。指令数据并不是包含信息越多越好。
2)扩展指令数量
指令数量扩展至0.18M、5.55M、7.2M 以及17.26M,研究人员发现模型性能呈持续上升的趋势,到7.2M变缓
3)指令重写与筛选
提高指令数据的质量或者多样性。“平衡指令难度”策略,其用大模型的困惑度分数来估算指令数据的难度水平,删除过于简单或过于困难的指令数据,从而缓解大模型训练不稳定或者过拟合的现象。
指令的质量比数量更为重要,如何大规模标注符合人类需求的指令数据目前仍然缺乏规范性的指导标准(比如什么类型的数据更容易激发大模型的能力。 -
指令微调的作用
1)整体任务性能改进
使用人工构建的指令数据对于大语言模型进一步训练,从而增强或解锁大语言模型的能力。提升的性能随着参数规模的增加而提升,经过指令微调的小模型甚至可以比没有经过微调的大模型表现得更出色。成本低,数据量仅需预训练万分之一甚至更少
2)任务求解能力增强
大模型能够获得较好的指令遵循与任务求解能力,无需下游任务的训练样本或者示例就可以解决训练中未见过的任务。
3)领域专业化适配
面向特定领域的指令微调,从而使之能够适配下游的任务
二、指令微调的训练策略
- 优化设置
指令微调中的优化器设置(AdamW 或Adafactor)、稳定训练技巧(权重衰减和梯度裁剪)和训练技术(3D 并行、ZeRO 和混合精度训练)都与预训练保持阶段一致,可以完全沿用。
- 目标函数:预训练阶段通常采用语言建模损失,优化每一个token,指令微调可以被视为一个有监督的训练过程,序列到序列损失,计算输出不计算输入部分损失
- 批次大小和学习率:小batch size和learning rate小幅度调整模型。例如InstructGPT (175B) 微调的批次大小为8,学习率恒定5.03×10−6;Alpaca (7B) 微调的批次大小为128,学习率预热到2 × 10−5
- 多轮对话数据的高效训练:拆分成多个不同的对话数据进行单独训练
- 数据组织策略
1) 平衡数据分布
- 样本比例混合:把所有数据集进行合并,然后从混合数据集中等概率采样每个实例
- 提高高质量数据集合的采样比例,会设置一个最大容量,用来限制每个数据集中可以采样的最大实例数
2)多阶段指令数据微调
首先使用大规模NLP 任务指令数据对模型进行微调,然后再使用相对多样的日常对话指令和合成指令进一步微调,在第二阶段中添加一些NLP 指令数据避免能力遗忘问题。逐渐增加指令的难度和复杂性
3)结合预训练数据与指令微调数据
为了使得微调过程更加有效和稳定,可以在指令微调期间引入了预训练数据和任务,这可以看作是对于指令微调的正则化,如5%。相同地,也可以在预训练引入少量指令微调数据,提前感知下游任务。
也可以在预训练和微调之间间添加一个“退火阶段”,是呀高质量预训练和指令微调数据。
三、参数高效的模型微调
全参数微调资源开销大,可以进行高效微调(Parameter-efficient Fine-tuning),也称为轻量化微调(Lightweight Fine-tuning)。旨在减少需要训练的模型参数量,同时保证微调后的模型性能
- 低秩适配微调方法
- LoRA 基础
针对特定任务进行适配时,参数矩阵往往过参数化(Over-parametrized),存在一个较低的内在秩。在预训练模型的参数矩阵上添加低秩分解矩阵来近似每层的参数更新,从而减少适配下游任务所需要训练的参数。

转变为

W 0 ∈ R H ∗ H W_0 \in R^{H*H} W0∈RH∗H是原始参数矩阵, Δ W \Delta W ΔW是更新的梯度矩阵。冻结原始矩阵, Δ W = A ∗ B T \Delta W = A*B^T ΔW=A∗BT低秩分解更新矩阵为 A ∈ R H ∗ R A \in R^{H*R} A∈RH∗R和 B ∈ R H ∗ R B \in R^{H*R} B∈RH∗R,R是减小后的秩远小于H。低秩分解矩阵𝑨 和𝑩 则是可训练参数用于适配下游任务
原始前向计算中间状态:

修改为

- LoRA 所需的显存估计
设LoRA 需要训练的参数量为 𝑃 L o R A 𝑃_{LoRA} PLoRA,模型原始参数为𝑃,可以近似地认为轻量化微调需要的显存从16𝑃 降至2𝑃。108G-14G - LoRA 变种
AdaLoRA引入动态低秩适应技术,在训练过程中动态调整每个参数矩阵需要训练的秩同时控制训练的参数总量。
模型在微调过程中通过损失来衡量每个参数矩阵对训练结果的重要性,重要性较高的参数矩阵被赋予比较高的秩
QLoRA将原始的参数矩阵量化为4 比特,而低秩参数部分仍使用16 比特进行训练,在保持微调效果的同时进一步节省了显存开销,2𝑃 进一步下降为0.5𝑃。 - LoRA 在大语言模型中的应用

- 其他高效微调方法
1) 适配器微调(Adapter Tuning)
引入了小型神经网络模块(适配器),瓶颈网络架构,将原始的特征向量压缩到较低维度,然后使用激活函数进行非线性变换,最后再将其恢复到原始维度。


会被集成到Transformer 架构的每一层中,使用串行的方式分别插入在多头注意力层和前馈网络层之后、层归一化之前,只优化适配器参数

2)前缀微调(Prefix Tuning)
每个多头注意力层中都添加了一组前缀参数,组成了一个可训练的连续矩阵,可以视为若干虚拟词元的嵌入向量,长度一般在10 到100 之间,还可以引入重参数化


3)提示微调
仅在输入嵌入层中加入可训练的提示向量,P-tuning提出了使用自由形式来组合输入文本和提示向量,通过双向LSTM来学习软提示词元的表示,它可以同时适用于自然语言理解和生成任务。Prompt Tuning,它以前缀形式添加提示,直接在输入前拼接连续型向量。

四、代码实践与分析
- 指令微调的代码实践
与预训练代码,区别主要在于指令微调数据集的构建(SFTDataset)和序列到序列损失的计算(DataCollatorForSupervisedDataset)。 - LoRA代码

人类对齐
一、人类对齐的背景与标准
大语言模型经过大规模的预训练和有监督指令微调,具备了解决各种任务的通用能力和指令遵循能力,但是同时也可能生成有偏见的、冒犯的以及事实错误的文本内容。如何确保大语言模型的行为与人类价值观、人类真实意图和社会伦理相一致成为了一个关键研究问题,通常称这一研究问题为人类对齐(Human Alignment)。引入全新的评估标准,如有用性、诚实性和无害性。
-
背景

-
对齐标准
1)有用性:大语言模型需要提供有用的信息,能够准确完成任务,正确理解上下文,并展现出一定的创造性与多样性
2)诚实性:输出应具备真实性和客观性,不应夸大或歪曲事实,避免产生误导性陈述,并能够应对输入的多样性和复杂性
3)无害性:避免生成可能引发潜在负面影响或危害的内容
二、基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)
- RLHF 概述
利用收集到的人类反馈数据指导大语言模型进行微调,从而使得大语言模型在多个标准(例如有用性、诚实性和无害性)上实现与人类的对齐
- 收集人类对于不同模型输出的偏好
- 使用收集到的人类反馈数据训练奖励模型
- 基于奖励模型使用强化学习算法微调大语言模型,如PPO算法
- RLHF 的关键步骤
1)监督微调
为了让待对齐语言模型具有较好的指令遵循能力,通常需要收集高质量的指令数据进行监督微调。(经过预训练、具备一定通用能力的大语言模型,但是并没有与人类价值观对齐)
2)奖励模型训练
为强化学习过程提供指导信号,反映了人类对于语言模型生成文本的偏好,通常以标量值的形式呈现。采用人类偏好数据对已有的语言模型继续微调,也可以基于人类偏好数据重新训练一个新的语言模型。
语言模型针对任务指令生成一定数量的候选输出,标注员对于输出文本进行偏好标注,通常是排序
3)强化学习训练
为了避免当前训练轮次的语言模型明显偏离初始的语言模型,通常会在原始优化目标中加入一个惩罚项(如KL散度)

- 人类反馈数据的收集
1)标注人员选择
研究人员首先标注一小部分数据,然后邀请候选标注员进行标注,并计算候选标注员与研究人员标注结果之间的一致性分数,只留下一致性分数高的
2)人类反馈形式
- 基于评分的人类反馈:标注者对模型输出进行打分,或者利用大模型给出打分(prompt输入设定好对齐规则)
- 基于排序的人类反馈:通过对模型输出进行两两比较,进而计算每个输出的综合得分并获得最终的输出排序
- 奖励模型的训练
需要训练一个模型来替代人类在RLHF 训练过程中实时提供反馈,这个模型被称为奖励模型。要预先构造一系列相关问题作为输入,人类标注者将针对这些问题标注出符合人类偏好的输出以及不符合人类偏好的输出。收集到这些人类偏好数据后,就可以用来训练奖励模型。
1)训练方法
- 打分式:人类标注者需针对给定的输入问题,为相应的输出赋予反馈分数,是离散的数值,用于表示输出与人类偏好的契合程度。MSE为训练目标,x,y为问题的输入和输出, r θ r_\theta rθ表示奖励模型,r^~表示人类标注者对输出的打分。

- 对比式:不同标注人员可能会存在不一致的理解,最终导致对于模型输出进行评分时可能会存在偏差,所以对比式能够克服打分式训练方法的不足,人类标注者仅需对两条相应输出进行排序,不仅降低了标注难度,还提高了不同标注者之间的一致性

- 排序式:对于一个给定输入,人类标注者根据偏好对于多个模型生成的回复进行排序,考虑了所有𝐾 个输出之间的两两偏序关系。比对比式学到更为全局的排序关系,进而更好地学习和拟合人类的价值观和偏好

2)训练策略 - 目标函数优化:将最佳的模型输出所对应的语言模型损失作为正则项,缓解奖励模型在二元分类任务上的过拟合问题

- 基座模型选取:使用更大的奖励模型(例如与原始模型尺寸相等或更大的模型)通常能够更好地判断模型输出质量,提供更准确的反馈信号,LLaMA-2使用相同的检查点来初始化待对齐语言模型和奖励模型
- 奖励计算形式:多个标准(例如有用性和诚实性),训练多个特定奖励模型,组合计算得到最终奖励,直接加和或者加权平均

- 代码实践


四、强化学习训练
强化学习旨在训练一个智能体,该智能体与外部环境进行多轮交互,通过学习合适的策略进而最大化从外部环境获得的奖励。
- 策略模型:在强化学习的过程中,智能体是根据外部环境决定下一步行动的决策者,因此其被称为策略模型
- 环境状态:智能体和外部环境第𝑡 次交互的过程中,当前外部环境的状态为 s t s_t st
- 行动:智能体需要根据 s t s_t st选择合适的策略,决定下一步该做出的行动 𝑎 𝑡 𝑎_𝑡 at
- 状态更新:当智能体采取了某个行动之后,外部环境会从原来的状态 s t s_t st变化为新的状态 s t + 1 s_{t+1} st+1
- 奖励分数:外部环境会给予智能体一个奖励分数 r t r_t rt
- 目标:智能体的目标是最大化所有决策能获得的奖励的总和
P表示决策轨迹的概率,R为对应奖励

大语言模型(即策略模型)需要根据用户输入的问题和已经生成的内容(即当前状态),生成下一个词元(即对下一步行动做出决策)。当大语言模型完整生成整个回复之后(即决策轨迹),标注人员(或奖励模型)会针对大语言模型生成的回复进行偏好打分(即奖励分数)。
1)策略梯度(Policy Gradient)是一种基础的强化学习算法,计算目标函数梯度如下(R与模型无关,视为常数):

使用梯度上升的方式对于策略模型的参数进行优化:

生成候选词元的决策空间非常大,难精确计算所有决策轨迹能获得的奖励期望,一般情况下使用采样算法选取多条决策轨迹

在线策略的训练方式(On-policy),为了保证采样得到的策略轨迹能够近似策略模型做出的决策的期望,需要在每次调整策略模型参数之后重新进行采样(每生成一个词进行参数更新,每次需要重新计算生成过程),较低的数据利用率和鲁棒性。近端策略优化使用了离线策略(Off-policy)的训练方式,即训练过程中负责交互与负责学习的策略模型不同。负责学习的策略模型通过另一个模型与环境交互产生的轨迹进行优化。采样的模型是固定的,同一批数据可以对负责学习的策略模型进行多次优化,以提升数据的使用效率,使训练过程更为稳定。
- PPO介绍


近端策略优化(Proximal Policy Optimization, PPO)算法主要用于训练能够根据外部环境状态做出行为决策的策略模型。主要使用优势估计来更加准确的评估决策轨迹能获得的奖励,使用了重要性采样来进行离线策略训练。为了稳定性,在目标函数中加入了梯度裁剪以及相关的惩罚项来减小采样误差。
-
优势估计:为了能够更好地计算在状态 s t s_t st做出决策 a t a_t at 时的奖励分数,PPO引入了优势函数 A t A_t At 来估算奖励分数。

前者表示表示在当前状态 s t s_t st选取特定决策 a t a_t at能获得的奖励分数, V ( s t ) V(s_t) V(st)表示从当前状态开始所有决策能得到的奖励的期望值(即对未来的预测)。前者需要奖励模型计算,后者需要训练一个评价模型(critic model,可以由奖励模型初始化,随着策略模型训练调整参数,奖励模型参数不变)。
优势函数的作用是引导模型从当前能做出的所有决策中挑选最佳的决策。

上图展示了传统策略梯度算法采样的随机性使得模型优化非最优决策。
而优势函数通过将决策的奖励与期望奖励做差,产生较低奖励的决策将会得到一个负的优势值,相对较差的决策就会被抑制,同时鼓励策略模型产生收益更高的决策。 -
重要性采样
使用在一个分布𝑝 上采样得到的样本,来近似另一个分布𝑞 上样本的分布。用于分布𝑞 难于计算或者采样的情况。求解变量𝑥 在分布𝑞 上函数𝑓 (𝑥)的期望,到分布𝑞 上的函数期望,可以通过在分布𝑝 上进行采样并且乘以系数𝑞(𝑥)/𝑝(𝑥) 计算进行估计

由以上推导可以得到:

使用策略模型Font metrics not found for font: . 与环境进行交互并采样决策轨迹(参数不变,reference),使用采样得到的决策轨迹近似估算策略模型𝜋𝜃 (参数更新)与环境交互时能获得的奖励的期望。可以针对PPO 算法的目标函数进行如下修改:

保证了在分布𝑝 和分布𝑞 上期望是一致的,但是无法保证二者方差一致或相近,为了保证重要性采样算法的稳定性,需要让两个分布𝑝 和𝑞 尽可能相似,二者的方差尽可能接近。 -
基于梯度裁剪的目标函数:通过裁剪策略比率的变化范围,防止策略更新过于激进,保证了新的策略模型产生的决策的分布和旧的策略模型产生的决策的分布不会相差太大(即𝜋𝜃 (𝑎𝑡 |𝑠𝑡 ) 和𝜋𝜃old(𝑎𝑡 |𝑠𝑡 ) 不会相差过大),保证稳定性。

当A大于0时,说明当前采样策略较优,需要提高该决策概率,增大𝜋𝜃 (𝑎𝑡 |𝑠𝑡 )。如果r小于1+e,min函数前者发挥作用,增大策略模型产生该决策的概率(即增大𝜋𝜃 (𝑎𝑡 |𝑠𝑡 ));如果r大于1+e,梯度裁剪,防止新旧两个决策分布差异过大造成的训练过程不稳定。 -
基于KL 散度的目标函数:PPO 可以使用KL 散度作为惩罚项来限制策略模型的更新幅度

当KL 散度的值较小时,适当调小𝛽 的取值,策略模型可以针对性的更新参数以产生更好的策略;当KL 散度的值较大的时候,适当调大𝛽 的取值,从而减少策略模型的更新程度。 -
PPO算法训练流程
(1)使用经过监督微调的大语言模型作为初始化策略模型𝜋𝜃 和𝜋𝜃old。
(2)将策略模型𝜋𝜃old 与环境进行交互,生成决策轨迹
(3)进行优势估计,衡量实际奖励与预期奖励之间的差异
(4)更新策略模型的参数,使用梯度裁剪或者引入KL散度惩罚,防止策略更新过于激进
(5)经过一定次数的迭代,PPO 算法会重新评估新策略性能,如果新策略相比旧策略有提升,新策略会被接受用作下一轮学习的基础。

-
训练策略
(1)模型初始化:强化学习的训练过程通常具有较高的不稳定性,对超参数敏感。“拒绝采样”(Rejection Sampling)或“最佳-𝑁 样本采样”(Best-of-𝑁)等方法进一步优化语言模型。首先使用大语言模型按照特定算法采样𝑁 个输出,由奖励模型选择最优的输出。然后,使用这些质量较高的输出对策略模型进行监督微调,直至收敛。最后,再执行强化学习算法的优化。
(2)效率提升:大语言模型和奖励模型的迭代解码过程将显著增加内存开销和计算成本,将两个模型部署在不同的服务器上,并通过调用相应的网络API 实现两个模型之间的协同训练。束搜索解码算法,一次解码生成多个候选输出,同时增强生成候选输出的多样性。
五、代表性RLHF 工作介绍
- InstructGPT 模型
三个步骤:(1)针对给定任务提示编写对应的输出示例,用于经过预训练后的GPT-3 模型的监督微调;(2)收集人类反馈数据训练奖励模型,排序,训练奖励模型来拟合标注人员的偏好;(3)使用PPO 算法和奖励模型进行大语言模型的强化学习训练。23不断迭代,基于当前最佳的语言模型持续收集数据,进一步训练奖励模型和优化模型的生成策略。1.3B可超过175B的GPT-3 - LLaMA-2 模型
- 人类反馈数据收集:收集7个开源数据集包含约1.50M 条人类偏好的数据,涉及安全和有用性;闭源数据,安全性和有用性的两类标注,标注者首先编写一段输入文本,然后基于相应的标准选取两个模型的输出,分别作为正例和负例。标注者编写的输入以及选取的正/负例,共同组成一条完整的人类反馈数据。
- 奖励函数训练:收集到人类反馈数据之后,将会根据收集到的数据训练奖励模型,安全性任务和有用性任务的相关数据被单独使用,训练两个不同目标的奖励模型。能够防止不同目标之间的互相干扰。引入m来衡量正例与负例之间的人类偏好差距。

- 强化学习算法:拒绝采样微调(Rejection Sampling Fine-tuning)和PPO 算法相结合的方法对于模型进行迭代训练。一共迭代5 轮,前四轮使用拒绝采样,不同于PPO 算法对同一输入仅采样一条回复,拒绝采样微调采样了𝐾 条不同的回复,选最好的回复对模型进行监督微调。
六、进阶RLHF 工作介绍
- 基于过程监督的RLHF
结果监督信号和过程监督信号,在结果监督的RLHF 算法中,使用一个单独的分数来评估模型生成的整个文本的质量,并引导大语言模型生成高得分的文本。而在过程监督的RLHF 算法中,针对模型输出内容的每个组成部分(如句子、单词或推理步骤)分别进行评估,从而提供细粒度的监督信号来加强大语言模型的训练,引导模型尽可能高质量地生成每个组成部分,帮助模型改进不理想的生成内容。
(1)数据集:OpenAI 发布了一个带有细粒度标注信息的数据集合PRM800K,例如模型解答的每个解题步骤会被标记为正确、错误或中立,更细粒度
(2)RLHF 训练方法:为了有效利用奖励模型产生的过程监督信号,可以使用专家迭代的方法来训练大语言模型;专家迭代方法包含两个主要阶段:策略改进和蒸馏;在策略改进阶段,专家策略进行广泛的搜索并生成样本,过程监督奖励模型基于当前的状态和决策轨迹,对专家策略的下一步决策进行打分。在蒸馏阶段,进一步使用第一阶段由专家策略生成的样本对基础策略(即待对齐的语言模型)进行监督微调。
(3)过程监督奖励模型的扩展功能:可以对大语言模型生成的候选答案进行重排序 - 基于AI 反馈的强化学习
(1)已对齐大语言模型的反馈:采用评价和修正的方法对初步回复进行调整和修改
(2)待对齐大语言模型的自我反馈:通过自我反馈进行对齐训练
七、非强化学习的对齐方法
在RLHF 的训练过程中,需要同时维护和更新多个模型,包括策略模型、奖励模型、参考模型以及评价模型,内存资源消耗大且执行复杂。非强化学习的对齐方法旨在利用高质量的对齐数据集,通过特定的监督学习算法对于大语言模型进行微调。
- 对齐数据的收集
(1)基于奖励模型的方法
由于奖励模型已经在包含人类偏好的反馈数据集上进行了训练,因此可以将训练好的奖励模型用于评估大语言模型输出的对齐程度。
- 大语言模型基于输入生成相应的输出
- 奖励模型对其输出进行打分
- 按照分数可以将这些输入与输出划分到不同的组,得到与人类偏好具有不同对齐水平的数据,可用于后续的监督微调
此外,基于排序式反馈数据训练的奖励模型利用奖励模型对大语言模型的多个输出进行质量高低排序,可用于训练模型生成排名较高的输出,避免生成排名较低的输出。
(2)基于大语言模型的方法
奖励模型以来训练过程中使用大规模高质量的人工标注数据,难以获取,且可能采用了不同的模型架构或者在分布完全不同的数据上进行训练,可能无法精确地识别并纠正其他独立训练的大语言模型中的不当行为。如何利用大语言模型自身能力?
既然自然语言指令可以指导人类进行反馈数据标注,那么也可以用来提示和引导大语言模型做出与人类相似的标注行为。
编写符合人类对齐标准的自然语言指令与相关示例,进而让大语言模型对其输出进行自我评价与检查,并针对有害内容进行迭代式修正,最终生成与人类价值观对齐的数据集。

- 代表性监督对齐算法DPO
直接偏好优化(Direct Preference Optimization, DPO)是一种不需要强化学习的对齐算法。通过与有监督微调相似的复杂度实现模型对齐,不再需要在训练过程中针对大语言模型进行采样。
(1)算法介绍
在强化学习的目标函数中建立决策函数与奖励函数之间的关系,以规避奖励建模过程。𝜋𝜃 (𝑦|𝑥) 来表示𝑟 (𝑥, 𝑦),PPO公式如下:

推导该目标函数最优解,先拆解原式中的KL 函数,对式子进行化简:

Z(x)为一个配分函数,只与状态𝑥 和旧的决策函数𝜋𝜃old (𝑦| 𝑥) 有关,并且不依赖于正在训练的决策函数𝜋𝜃 (𝑦|𝑥)。

简化式子8.26,𝜋∗ (·|𝑥) 也是一个概率分布,并且与当前的决策函数𝜋𝜃 (𝑦|𝑥) 无关。

代入上面式子:


们尝试使用𝜋𝑟 (𝑦|𝑥)、𝜋𝜃old(𝑦|𝑥) 和𝑍(𝑥) 来表示奖励函数𝑟 (𝑥, 𝑦),从而建立决策函数和奖励函数之间的关系




推导太长了,直接看最终目标函数还是比较好理解的,希望模型正例概率高于负例
-
DPO 算法分析
(1)对目标函数求导,深入理解DPO 算法如何针对大语言模型的参数进行优化。



DPO 采用梯度下降的方式来优化策略模型的参数𝜃。可以发现优化过程中会增大log 𝜋𝜃 (𝑦+|𝑥) 与log 𝜋𝜃 (𝑦−|𝑥)之间的差异。前半部分𝜎( ˆ 𝑟 𝜃 (𝑥, 𝑦−)−ˆ 𝑟 𝜃 (𝑥, 𝑦+)) 可以看作是梯度的系数,动态地控制梯度下降的步长。当策略模型更倾向于生成不符合人类偏好的内容𝑦− 时,ˆ 𝑟 𝜃 (𝑥, 𝑦−) 和ˆ 𝑟 𝜃 (𝑥, 𝑦+) 之间的差值变大,导致梯度下降的步长变大,从而进行更为激进的参数更新以避免生成𝑦− -
DPO 代码实践
DPOTrainer 训练器集成了对训练数据进行分词、计算DPO 损失函数和模型参数优化等功能,用户只需要正确加载模型并按照格式构造数据集即可进行训练。数据集需要包含三个关键字:“prompt”、“chosen”和“rejected”,分别表示输入数据、符合人类偏好的输出和不符合人类偏好的输出。在实现过程中,需要加载策略模型𝜋𝜃和参考模型𝜋𝜃old。在初始状态下,策略模型和参考模型为同一个模型,可以从相同的模型检查点进行加载。



DPO 在训练过程中只需要加载策略模型和参考模型,并不用加载奖励模型和评价模型,占用的资源更少、运行效率更高,并且具有较好的对齐性能,在实践中得到了广泛应用。
为什么不需要加载奖励模型?r哪里来的?~~~~~~提前计算?
- 其他有监督对齐算法
这些算法大多基于对齐数据,使用传统的序列到序列生成目标(交叉熵损失)来优化大语言模型;同时,搭配一些辅助优化目标,以增强对齐数据的学习利用效果。

这里的正负例既可以根据奖励模型的排序获得,也可以通过人类标注得到。
- 基于质量提示的训练目标
可以为正负例添加相应的前缀进行区别,比如在正例输出𝑦+ 和负例输出𝑦− 前面分别加入前缀“好的回复:”和“差的回复:”,然后采用序列到序列生成作为最终的训练目标。为了区分不同质量的模型输出,还可以在每个模型输出之前附加一个特殊的奖励标记,用以指示该模型输出的对齐水平,例如“5 分奖励的回复:”或者“排名第二的回复:”。 - 基于质量对比的训练目标
旨在让模型有更高的概率生成高质量的回答,更低的概率生成低质量的回答,更好地利用质量得分的偏序关系。
首先从每个输入𝑥 的多个输出中采样得到多组正负例组合{𝑦+, 𝑦−, 𝑥},然后采用RLHF 中奖励模型的对比式训练方法或者排序式训练方法,对比学习的优化目标为最大化基于当前输入𝑥 生成正例输出𝑦+(得分或排序最高的输出)的概率,同时降低基于其他输入˜ 𝑥 (𝑥 ≠ ˜ 𝑥) 生成输出𝑦+ 的概率。这一方法可以避免大语言模型由于自身能力的限制或者安全性要求,对于不同的输入均产生相似的输出。
八、关于SFT 和RLHF 的进一步讨论
指令微调利用配对文本进行训练的方法也被广泛地称为监督微调(SupervisedFine-Tuning, SFT),深入探讨SFT 和RLHF 视为两种独立的大模型训练方法之间的差异

- 基于学习方式的总体比较
文本生成问题可看作基于强化学习的决策过程,当给定一个提示作为输入时,大语言模型的任务是生成与任务指令相匹配的输出文本。
优化的目标是让大语言模型能够不断优化其生成策略,生成更高质量的输出文本,获得更高的奖励分数。
在RLHF 中,首先学习一个奖励模型,然后利用该奖励模型通过强化学习算法(如PPO)来改进大语言模型。而在SFT 中,我们则采用了Teacher-Forcing 的方法,直接优化模型对实例输出的预测概率。采用了基于示例数据的“局部”优化方式,即词元级别的损失函数。
SFT 主要依赖于序列到序列的监督损失来优化模型,而RLHF 则主要通过强化学习方法来实现大模型与人类价值观的对齐。采用了涉及人类偏好的“全局”优化方式,即文本级别的损失函数。 - SFT 的优缺点
- 优点:成为一种主要的大语言模型微调方法,能够显著提升大语言模型在各种基准测试中的性能,增强在不同任务上的泛化能力。它在实现上简单、灵活、可拓展性较强,还可以用于构建很多特定功能,例如帮助大语言模型建立聊天机器人的身份。“解锁”大语言模型能力,而非“注入”新能力。
- 缺点:当待学习的标注指令数据超出了大语言模型的知识或能力范围,例如训练大语言模型回答关于模型未知事实的问题时,可能会加重模型的幻象(Hallucination)行为;基于行为克隆的学习方法,SFT 旨在模仿构建标注数据的教师的行为,而无法在这一过程中进行有效的行为探索,因此高质量的指令数据(而非数量)是影响大语言模型训练的主要因素。
- RLHF 的优缺点
- 优点:使用RLHF 加强模型对于人类价值观的遵循,减少模型输出的有害性,也能够有效增强模型的综合能力;主要为训练过程提供偏好标注数据,而不是直接生成示例数据,因此它可以减少标注员之间的不一致且偏好标注更为简单易行;在模型学习阶段,RLHF 通过对比模型的输出数据(区分“好”输出与“坏”输出)来指导大语言模型学习正确的生成策略,它不再强迫大语言模型模仿教师的示例数据,因此可以缓解上述提到的SFT 所导致的幻象问题;奖励模型很重要,一般来说,奖励模型应该能够了解待对齐的大语言模型的知识或能力范畴。
- 缺点:样本学习效率低和训练过程不稳定等问题;持续多轮,迭代优化过程复杂,涉及了很多重要细节的设定(例如提示选择、奖励模型训练、PPO的超参数设置以及训练过程中对超参数的调整),都会影响整个模型的性能,难以精确复现。
- 总结
SFT 特别适合预训练后增强模型的性能,具有实现简单、快速高效等优点;而RLHF 可在此基础上规避可能的有害行为并进一步提高模型性能,但是实现较为困难,不易进行高效优化。
相关文章:
大语言模型(LLM)入门级选手初学教程 III
指令微调 一、指令数据的构建 包括任务描述(也称为指令)、任务输入-任务输出以及可选的示例。 Self-Instruct 指令数据生成:从任务池中随机选取少量指令数据作为示例,并针对Chat-GPT 设计精细指令来提示模型生成新的微调数据…...

STM32G0xx使用LL库将Flash页分块方式存储数据实现一次擦除可多次写入
STM32G0xx使用LL库将Flash页分块方式存储数据实现一次擦除可多次写入 参考例程例程说明一、存储到Flash中的数据二、Flash最底层操作(解锁,加锁,擦除,读写)三、从Flash块中读取数据五、测试验证 参考例程 STM32G0xx HAL和LL库Flash读写擦除操…...

SAP B1 认证考试习题 - 解析版(三)
前一篇:《SAP B1 认证考试习题 - 解析版(二)》 题目纯享版合集:《SAP B1 认证考试习题 - 纯享版》 五、运费(附加费用) 57. 以下哪个选项能够影响库存商品的价格 A. 仅为总量级别的附加费用 B. 只为行级…...

数据库开发规范
一、概述 本规范规定了,软件项目团队开发数据库的全流程规范。规范覆盖了数据库设计、管理及配套文件等。 二、项目阶段 项目阶段包括需求评审(需求分析阶段)、技术评审(方案阶段)、数据库开发…...

使用python向钉钉群聊发送消息
使用python向钉钉群聊发送消息 一、在钉钉群中新建机器人二、使用代码发送消息 一、在钉钉群中新建机器人 在群设置中添加机器人 选择自定义 勾选对应的安全设置 完成后会展示webhook,将地址复制出来,并记录,后面会用到 二、使用代码发送消…...

YOLOv11改进:SE注意力机制【注意力系列篇】(附详细的修改步骤,以及代码,与其他一些注意力机制相比,不仅准确度更高,而且模型更加轻量化。)
如果实验环境尚未搭建成功,可以参考这篇文章 ->【YOLOv11超详细环境搭建以及模型训练(GPU版本)】 文章链接为:YOLOv11超详细环境搭建以及模型训练(GPU版本)-CSDN博客 -------------------------------…...
--GPIO的使用)
STM32 基于HAL库和STM32cubeIDE的应用教程 (二)--GPIO的使用
如果有什么不懂的地方欢迎私聊博主,欢迎小白,博主必一一解答。 在 STM32 中,GPIO(通用输入输出)是与外部硬件接口进行交互的主要方式之一。STM32 HAL 库提供了简洁的接口来配置和控制 GPIO 引脚。下面是使用 STM32 HA…...

【毫米波雷达(七)】自动驾驶汽车中的精准定位——RTK定位技术
一、什么是RTK? RTK,英文全名叫做Real-time kinematic,也就是实时动态。这是一个简称,全称其实应该是RTK(Real-time kinematic,实时动态)载波相位差分技术。 二、RTK的组装 如上图所示&#x…...

Transformer和BERT的区别
Transformer和BERT的区别比较表: 两者的位置编码: 为什么要对位置进行编码? Attention提取特征的时候,可以获取全局每个词对之间的关系,但是并没有显式保留时序信息,或者说位置信息。就算打乱序列中token…...

linux 加载uPD720201固件
硬件 jetson orin nano jetpack 35.5.0 uPD720201是瑞萨推出的怕pcie扩展usb3.0芯片,支持flash主动加载与在系统被动加载 本文介绍如何做到没接flash情况下由系统加载固件 在uPD720201没接spi flash时候nano启动会报XhciDxe错误而自动重启,首先需要在ue…...

C语言中的信号量semaphore详解
在C语言中,**信号量(Semaphore)**是一种常用的同步机制,用于控制多个线程或进程对共享资源的访问。信号量可以实现类似于锁的效果,但更为灵活,适用于并发编程场景。 1. 什么是信号量 信号量可以看作是一个…...

0087__DirectX11 With Windows SDK--02 顶点/像素着色器的创建、顶点缓冲区
DirectX11 With Windows SDK--02 顶点/像素着色器的创建、顶点缓冲区-CSDN博客...
后,使用selenium的程序怎么办(20241030))
Windows换机华为擎云(银河麒麟V10+麒麟9000C CPU)后,使用selenium的程序怎么办(20241030)
原本的 seleniumChrome 已无法正常工作。chromedriver 报错:不支持 Linux/aarch64。 1、尝试Firefox、edge驱动。Firefox有一个geckodriver版本与Firefox版本的对照表,我看了一下,感觉他们是始终跟进新技术的。银河麒麟的很多库都是几年前的…...
 函数的用法,信号类型在哪里定义的?)
linux 下 signal() 函数的用法,信号类型在哪里定义的?
--------------------------------------------------- author: hjjdebug date: 2024年 11月 07日 星期四 14:47:33 CST description: linux 下 signal() 函数的用法 --------------------------------------------------- signal 是linux 下最基础的进程通讯机制…...

享元模式及其运用场景:结合工厂模式和单例模式优化内存使用
介绍 享元模式(Flyweight Pattern)是一种结构型设计模式,它通过共享对象来减少内存使用,尤其是对于大量相似对象的场景。享元模式通常与工厂模式和单例模式结合使用,从而有效地控制和复用对象的创建。在享元模式中&am…...

【物联网技术】ESP8266 WIFI模块在STA模式下实现UDP与电脑/手机网络助手通信——UDP数据透传
前言:完成ESP8266 WIFI模块在STA模式下实现UDP与电脑/手机网络助手通信——实现UDP数据透传 STA模式,通俗来说就是模块/单片机去连接路由器/热点来通信。 UDP协议,是传输层协议,UDP没有服务器和客户端的说法。 本实验需要注意,wifi模块/单片机与电脑/手机需要连接在同一个…...

【SQL Server】华中农业大学空间数据库实验报告 实验一 数据库
实验目的 熟悉了解掌握SQL Server软件的基本操作与使用方法,认识界面,了解其两个基本操作系统文件,并能熟练区分与应用交互式与T-SQL式两种方法在SQL Server中如何进行操作;学习有关数据库的基本操作,包括:…...
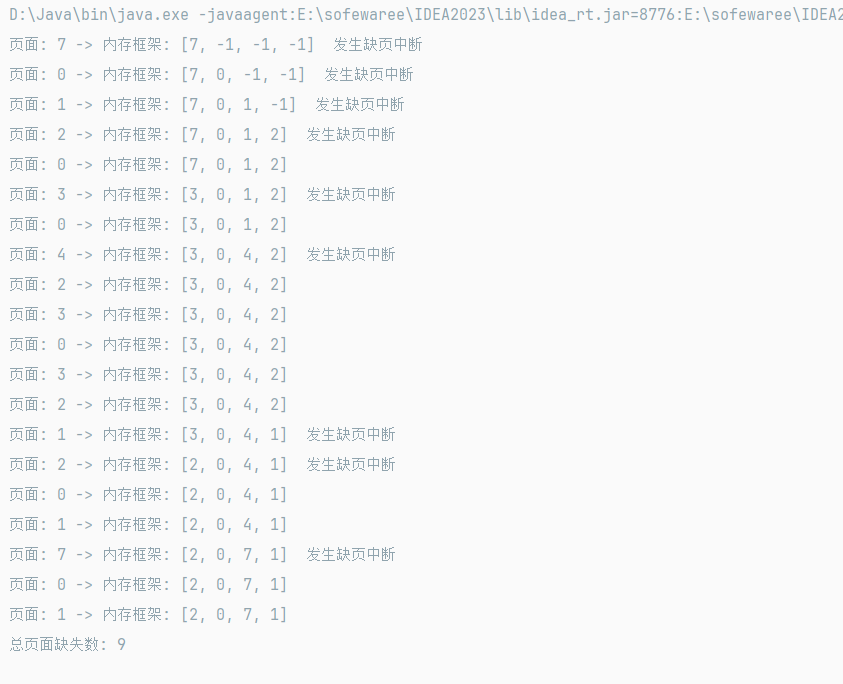
操作系统页面置换算法Java实现(LFU,OPT,LRU,LFU,CLOCK)
FIFO先进先出算法 java import java.util.LinkedList; import java.util.Queue; public class Main { //先进先出的思想 是 用一个队列去模拟数据 如果当前不存在就是发生缺页中断了 就需要添加 如果已经满了 将队头的元素出队 即可 //先进先出 就是一个数组 frameCount publi…...

Request和Response
前言 这一节主要讲的是Request和Response还有一些实例 1. 介绍 就是这两个参数 WebServlet("/demo7") public class ServletDemo7 extends HttpServlet {Overrideprotected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletExcepti…...

【青牛科技】GC8549替代LV8549/ONSEMI在摇头机、舞台灯、打印机和白色家电等产品上的应用分析
引言 在现代电子产品中,控制芯片的性能直接影响到设备的功能和用户体验。摇头机、舞台灯、打印机和白色家电等领域对控制精度、功耗和成本等方面的要求日益提高。LV8549/ONSEMI等国际品牌的芯片曾是这些产品的主要选择,但随着国内半导体技术的进步&…...
)
【微信取证篇】从微信收藏文件看微信存储加密逻辑(附解密工具思路)
1. 微信收藏文件的存储结构解析 第一次打开微信收藏夹时,你可能不会想到那些随手保存的图片、视频和文档,在手机存储里竟会以三种完全不同的形态存在。作为一名长期研究移动应用数据存储的开发者,我发现微信对收藏文件的处理方式堪称"精…...
)
别再傻傻分不清了!给硬件工程师的SI、PI、EMI关系速查手册(附高频PCB设计实例)
硬件工程师实战指南:SI、PI、EMI的三角关系与高频PCB设计避坑 当你第一次面对DDR4布线导致的EMI测试失败时,可能会陷入这样的困惑:明明是信号完整性问题,为什么整改方案却是调整电源层的去耦电容?这种看似跨领域的因果…...

避坑指南:CubeMX配置STM32F429三重ADC时,ADC2/3的DMA请求为啥点不了?附手动开启代码
STM32F429三重ADC配置疑难解析:当CubeMX无法启用ADC2/3的DMA请求时如何手动突破限制 在嵌入式开发中,STM32系列微控制器因其丰富的外设资源而备受青睐,其中ADC(模数转换器)模块的性能直接影响信号采集系统的精度与速度…...

Seraphine:你的英雄联盟智能助手,3步实现高效战绩查询与游戏辅助
Seraphine:你的英雄联盟智能助手,3步实现高效战绩查询与游戏辅助 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 还在为英雄联盟对局中信息不足而困扰吗?想要在BP阶段就占据…...
)
别再被Windows权限卡脖子!用`--user`参数搞定pip安装报错(附详细排查步骤)
彻底解决Windows下Python包安装权限问题:从--user参数到环境配置全攻略 在Windows系统上进行Python开发时,许多开发者都曾遭遇过这样的尴尬时刻:当你满怀期待地输入pip install package_name准备安装一个新工具时,屏幕上却突然跳出…...

终极指南:用DDrawCompat在现代Windows上完美复活经典游戏
终极指南:用DDrawCompat在现代Windows上完美复活经典游戏 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirrors/dd/DDr…...

2026 OpenTiny NEXT 产品调研启动!
各位开发者朋友们! OpenTiny NEXT 系列产品(NEXT SDK / TinyRobot / GenUI SDK / AI Extension / WebAgent 等)已陪伴大家走过一段时间。为了更精准地解决实际开发中的痛点,我们正式启动 2026 年度用户体验调研。 ⏰ 调研时间&…...

B站视频转文字终极指南:如何用AI工具3步搞定视频内容整理
B站视频转文字终极指南:如何用AI工具3步搞定视频内容整理 【免费下载链接】bili2text Bilibili视频转文字,一步到位,输入链接即可使用 项目地址: https://gitcode.com/gh_mirrors/bi/bili2text 你是否曾为了一段精彩的B站课程内容反复…...

RISC-V开发板结合Python实现B站消息监测:硬件极客的IoT实践
1. 项目概述:当硬件极客遇上日常痛点前几天在极客社区里看到一个挺有意思的分享,一位开发者朋友用一块高性能的RISC-V开发板,结合自己写的Python脚本,做了一个B站未读消息的实时监测器。这项目乍一听有点“杀鸡用牛刀”的感觉——…...

Claude Code用户如何通过Taotoken解决封号与Token不足的困扰
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code用户如何通过Taotoken解决封号与Token不足的困扰 1. 理解Claude Code的接入限制与Taotoken的解决方案 Claude Code作为…...