【Python】轻松实现机器翻译:Transformers库使用教程
轻松实现机器翻译:Transformers库使用教程
近年来,机器翻译技术飞速发展,从传统的基于规则的翻译到统计机器翻译,再到如今流行的神经网络翻译模型,尤其是基于Transformer架构的模型,翻译效果已经有了质的飞跃。Transformers库由Hugging Face推出,是目前最流行的自然语言处理库之一,它提供了多种预训练的语言模型,可以用于文本分类、文本生成、机器翻译等任务。本文将详细介绍如何使用Transformers库来实现一个机器翻译模型。

一、准备工作
在开始之前,请确保安装了Transformers库和PyTorch或TensorFlow框架。以下是安装命令:
pip install transformers torch
本文将使用PyTorch作为深度学习框架,TensorFlow用户可以相应调整代码。

二、选择模型与数据集
Transformers库提供了多种用于机器翻译的预训练模型,例如:
Helsinki-NLP/opus-mt-*系列:覆盖多种语言对。facebook/wmt19-*系列:基于WMT19数据集的模型。
可以通过访问Hugging Face的模型库来选择适合的模型。例如,如果要实现英文到法文的翻译,可以使用Helsinki-NLP/opus-mt-en-fr模型。

三、实现机器翻译步骤
1. 加载预训练模型和分词器
首先,从Transformers库中加载翻译模型和分词器。分词器用于将文本转化为模型可以理解的输入格式。
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM# 选择模型
model_name = "Helsinki-NLP/opus-mt-en-fr" # 英文到法文翻译模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
在这里,我们选择了Helsinki-NLP/opus-mt-en-fr模型,用于将英文翻译成法文。对于不同语言对,选择不同的模型即可。
2. 编写翻译函数
在此基础上,我们可以编写一个简单的翻译函数,将输入文本翻译成目标语言。此函数将使用分词器对输入文本进行编码,将编码后的文本传递给模型,然后解码模型的输出生成翻译文本。
def translate(text, tokenizer, model):# 将输入文本编码为模型输入格式inputs = tokenizer.encode(text, return_tensors="pt", truncation=True)# 使用模型生成翻译outputs = model.generate(inputs, max_length=40, num_beams=4, early_stopping=True)# 解码生成的张量为文本translated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)return translated_text
3. 进行测试
编写好翻译函数后,我们可以测试一些英文句子,看看模型的翻译效果。
english_text = "Hello, how are you?"
translated_text = translate(english_text, tokenizer, model)
print("Translated text:", translated_text)
运行该代码后,您会得到一段翻译后的法文文本。

四、调整翻译效果
在机器翻译中,生成的翻译文本质量可能会受到生成参数的影响。在model.generate方法中,可以通过调整以下参数来优化效果:
max_length: 控制生成的翻译文本的最大长度,防止文本过长。num_beams: 设置beam search的大小。较大的值可以提高翻译质量,但会增加计算量。early_stopping: 设置为True可以让生成过程在合适的时间停止。
例如,您可以将num_beams设置为8来提高翻译效果,或减少max_length以加快生成速度。
outputs = model.generate(inputs, max_length=50, num_beams=8, early_stopping=True)

五、批量翻译与后处理
如果有多条文本需要翻译,可以使用批量翻译方式,这样可以提高效率。同时,有时模型的输出可能包含冗余标点符号或空格,可以在输出后进行后处理。
批量翻译
def batch_translate(texts, tokenizer, model):inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True)outputs = model.generate(**inputs, max_length=40, num_beams=4, early_stopping=True)return [tokenizer.decode(output, skip_special_tokens=True) for output in outputs]
后处理
有时模型的输出可能包含多余的空格或标点符号,可以在生成后进行简单的清理:
import redef clean_translation(text):# 去除多余的空格text = re.sub(r"\s+", " ", text)# 去除句末多余的标点符号text = re.sub(r"\s([?.!"](?:\s|$))", r"\1", text)return text

六、其他进阶操作
1. 使用自定义词汇表
在某些专业领域(例如法律、医学等),需要使用特定的词汇。Transformers支持加载自定义的词汇表来增强翻译的专业性。
2. 微调模型
如果现有的预训练模型无法满足特定任务的需求,可以通过少量特定领域的数据对模型进行微调,以提升翻译效果。Hugging Face提供了Trainer类,可以方便地进行微调操作。

七、建议
上面介绍了如何使用Transformers库快速搭建机器翻译系统,并使用预训练的翻译模型实现了英文到法文的翻译功能。对于需要翻译其他语言的情况,只需替换适合的模型即可。通过适当调整参数、进行后处理等操作,可以进一步提升翻译效果。如果有更高的要求,还可以对模型进行微调和训练,以适应特定的领域。

八、完整代码示例
为了方便理解和应用,以下是一个完整的代码示例,从模型加载到翻译文本的处理都包含在内。代码还包括了批量翻译和简单的后处理,方便您在实际项目中使用。
import re
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM# 1. 加载模型和分词器
model_name = "Helsinki-NLP/opus-mt-en-fr"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)# 2. 定义翻译函数
def translate(text, tokenizer, model):inputs = tokenizer.encode(text, return_tensors="pt", truncation=True)outputs = model.generate(inputs, max_length=50, num_beams=8, early_stopping=True)translated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)return clean_translation(translated_text)# 3. 定义批量翻译函数
def batch_translate(texts, tokenizer, model):inputs = tokenizer(texts, return_tensors="pt", padding=True, truncation=True)outputs = model.generate(**inputs, max_length=50, num_beams=8, early_stopping=True)return [clean_translation(tokenizer.decode(output, skip_special_tokens=True)) for output in outputs]# 4. 定义翻译后的后处理函数
def clean_translation(text):text = re.sub(r"\s+", " ", text) # 去除多余的空格text = re.sub(r"\s([?.!"](?:\s|$))", r"\1", text) # 去除句末的多余空格return text# 测试单个翻译
english_text = "Hello, how are you?"
translated_text = translate(english_text, tokenizer, model)
print("单条翻译结果:", translated_text)# 测试批量翻译
texts = ["Hello, how are you?", "I am learning machine translation.", "Transformers library is amazing!"]
translated_texts = batch_translate(texts, tokenizer, model)
print("批量翻译结果:", translated_texts)

九、机器翻译的挑战和未来发展
尽管使用Transformers库可以快速搭建翻译系统,但机器翻译的效果受限于许多因素:
- 模型限制:预训练的通用模型对复杂的句法结构或特定领域的词汇可能翻译得不够准确。
- 数据质量:模型的翻译效果与训练数据的质量息息相关。多语言模型在翻译某些低资源语言时效果有限。
- 长文本处理:现有模型在翻译长文本时可能会出现文本不连贯、遗漏信息等问题。
未来发展方向
随着研究的深入,机器翻译还在不断演进,未来有几个关键方向可能带来更优质的翻译效果:
- 大规模预训练多任务模型:如多语言和多任务预训练,可以让模型更好地泛化,提高低资源语言的翻译效果。
- 小样本微调:通过少量特定领域数据微调模型,可以增强其在特定领域的表现。
- 增强语言语境理解:结合深度学习中的最新发展(如上下文感知、图神经网络等),可能让机器更好地理解语境。

十、总结
使用Transformers库进行机器翻译相对简单且有效,特别适合在项目中快速搭建和测试翻译功能。通过本文的教程,您可以轻松上手机器翻译的基本实现,并理解如何对生成的翻译进行优化。未来,随着自然语言处理技术的不断发展,机器翻译的应用前景会更为广阔。希望本文能帮助您在项目中实现更流畅的翻译体验!

相关文章:
【Python】轻松实现机器翻译:Transformers库使用教程
轻松实现机器翻译:Transformers库使用教程 近年来,机器翻译技术飞速发展,从传统的基于规则的翻译到统计机器翻译,再到如今流行的神经网络翻译模型,尤其是基于Transformer架构的模型,翻译效果已经有了质的飞…...

【数据集】【YOLO】【目标检测】道路结冰数据集 1527 张,YOLO目标检测实战训练教程!
数据集介绍 【数据集】道路结冰数据集 1527 张,目标检测,包含YOLO/VOC格式标注。数据集中包含2种分类:“clear_road, ice_road”。数据集来自国内外图片网站和视频截图,部分数据经过数据增强处理。检测范围监控视角检测、无人机视…...

Java链表及源码解析
文章目录 创建一个ILindkedList接口创建方法(模拟实现链表方法)创建MyLinkedList来实现接口的方法创建链表节点addFirst方法(新增头部属性)addLast方法(新增到末尾一个属性)remove方法(删除指定属性)addInd…...

十、快速入门go语言之方法
文章目录 方法:one: 方法的概念:star2: 内嵌类型的方法和继承:star2: 多重继承 📅 2024年5月9日 📦 使用版本为1.21.5 方法 1️⃣ 方法的概念 ⭐️ 在Go语言中没有类这个概念,可以使用结构体来实现,那类方法呢?Go也…...

JVM 处理多线程并发执行
JVM(Java Virtual Machine)在处理多线程并发执行方面具有强大的支持,主要依赖于其内置的线程模型、内存模型以及同步机制。 JVM 通过以下关键机制和组件来管理多线程并发执行: 1. 线程模型 Java 线程与操作系统线程:…...

【D3.js in Action 3 精译_039】4.3 D3 面积图的绘制方法及其边界标签的添加
当前内容所在位置: 第四章 直线、曲线与弧线的绘制 ✔️ 4.1 坐标轴的创建(上篇) 4.1.1 D3 中的边距约定(中篇)4.1.2 坐标轴的生成(中篇) 4.1.2.1 比例尺的声明(中篇)4.1…...

布谷直播源码部署服务器关于数据库配置的详细说明
布谷直播源码搭建部署配置接口数据库 /public/db.php(2019年8月后的系统在该路径下配置数据库,老版本继续走下面的操作) 在项目代码中执行命令安装依赖库(⚠️注意:如果已经有了vendor内的依赖文件的就不用执行了&am…...
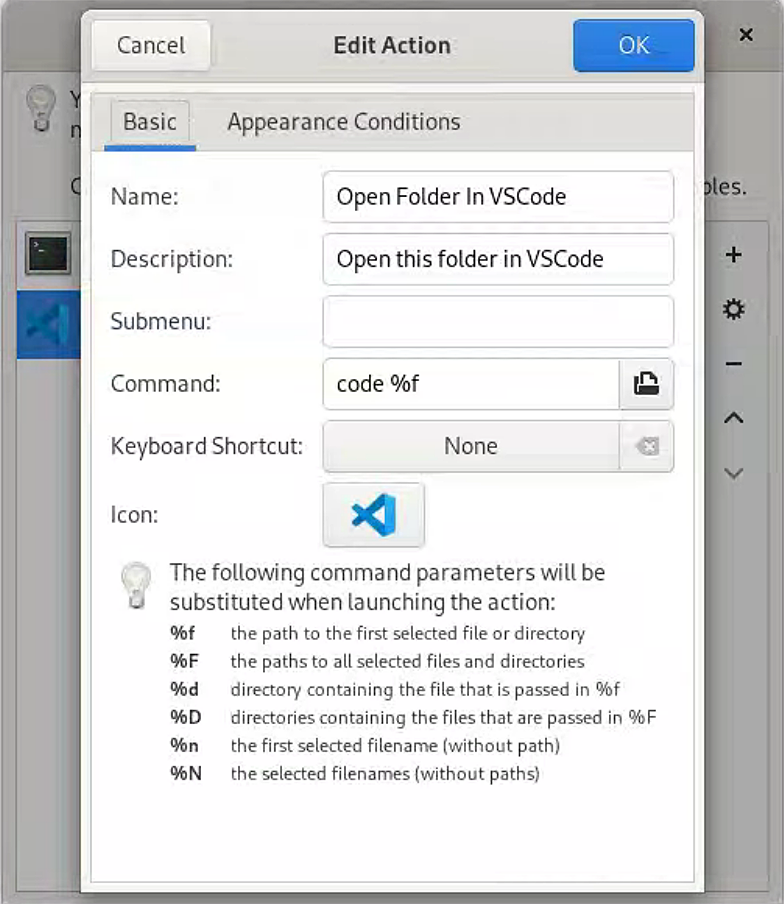
Xfce桌面设置右键菜单:用右键打开VSCode
前言 AlmaLinux安装VSCode之后始终没有找到如何用右键菜单打开VSCode,比Windows麻烦多了。每次都需要先找到文件夹,然后用系统自带的Open In Terminal打开终端,再输入code .,才能够在当前文件夹中快速打开VSCode。那么࿰…...

【NLP自然语言处理】深入探索Self-Attention:自注意力机制详解
目录 🍔 Self-attention的特点 🍔 Self-attention中的归一化概述 🍔 softmax的梯度变化 3.1 softmax函数的输入分布是如何影响输出的 3.2 softmax函数在反向传播的过程中是如何梯度求导的 3.3 softmax函数出现梯度消失现象的原因 &…...

Pytorch训练时报nan
0. 引言 Pytorch训练时在batchN时loss为nan。经过断点检查发现在batchN-1时,网络参数非nan,输出非nan,但梯度为nan,导致网络参数已经全部被更新为nan,遇到这种情况应该如何排查,如何避免?由于导…...

JavaScript定时器详解:setTimeout与setInterval的使用与注意事项
在JavaScript中,定时器用于在指定的时间间隔后或周期性地执行代码。JavaScript 提供了两种主要的定时器函数:setTimeout 和 setInterval。以下是它们的详细解释和实现方式: 1. setTimeout setTimeout 函数用于在指定的毫秒数后执行一次函数…...

CSS——选择器、PxCook软件、盒子模型
选择器 结构伪类选择器 作用:根据元素的结构关系查找元素。 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0&quo…...

Mysql 大表limit查询优化原理实战
文章目录 1 大表查询无条件优化&原理(入门)2 大表查询带 条件 优化&原理(进阶)2.1 where 后面的查询字段只有一个时,要求该字段是索引字段2.2 where 后面的查询字段有多个时,尽量让查询字段为索引字段且字段值基数大 3 大表查询带 排序 优化&…...

在vscode中开发运行uni-app项目
确保电脑已经安装配置好了node、vue等相关环境依赖 进行项目的创建 vue create -p dcloudio/uni-preset-vue 项目名 vue create -p dcloudio/uni-preset-vue uni-app 选择模版 这里选择【默认模版】 项目创建成功后在vscode中打开 第一次打开项目 pages.json 文件会报错&a…...

【JavaEE初阶 — 多线程】Thread的常见构造方法&属性
目录 Thread类的属性 1.Thread 的常见构造方法 2.Thread 的几个常见属性 2.1 前台线程与后台线程 2.2 setDaemon() 2.3 isAlive() Thread类的属性 Thread 类是JVM 用来管理线程的一个类,换句话说,每个线程都有一个唯一的Thread 对象与之关联&am…...

ctfshow(316)--XSS漏洞--反射性XSS
Web316 进入界面: 审计 显示是关于反射性XSS的题目。 思路 首先想到利用XSS平台解题,看其他师傅的wp提示flag是在cookie中。 当前页面的cookie是flagyou%20are%20not%20admin%20no%20flag。 但是这里我使用XSS平台,显示的cookie还是这样…...

ubuntu22.04安装conda
在 Ubuntu 22.04 上安装 Conda 可以通过以下步骤进行: 下载 Miniconda(轻量级版本的 Conda): 打开终端并运行以下命令以下载 Miniconda 安装脚本: wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-…...
D58【python 接口自动化学习】- python基础之异常
day58 异常捕获 学习日期:20241104 学习目标:异常 -- 74 自定义异常捕获:如何定义业务异常? 学习笔记: 自定义异常的用途 自定义异常的方法 # 抛出一个异常 # raise ValueError(value is error) # ValueError: val…...

Java项目实战II基于Spring Boot的便利店信息管理系统(开发文档+数据库+源码)
目录 一、前言 二、技术介绍 三、系统实现 四、文档参考 五、核心代码 六、源码获取 全栈码农以及毕业设计实战开发,CSDN平台Java领域新星创作者,专注于大学生项目实战开发、讲解和毕业答疑辅导。获取源码联系方式请查看文末 一、前言 在快节奏的…...

Java-日期计算工具类DateCalculator
DateCalculator是用于日期计算的工具类。这个工具类将包括日期的加减、比较、周期计算、日期 范围生成等功能。 import java.time.LocalDate; import java.time.LocalDateTime; import java.time.LocalTime; import java.time.Period; import java.time.temporal.ChronoUnit;…...

探索中医数字化:基于深度学习的舌苔检测项目推荐
探索中医数字化:基于深度学习的舌苔检测项目推荐 【下载地址】基于深度学习的舌苔检测毕设留档 本项目是针对中医领域中舌象分析的一项研究,通过应用深度学习技术来实现自动的舌苔检测。随着人工智能在医疗健康领域的深入发展,利用计算机视觉…...

HiC-Pro跑完数据后,你的结果文件都看懂了吗?从out文件夹到可视化图谱的完整解读指南
HiC-Pro结果文件全解析:从原始数据到发表级图谱的实战指南 当HiC-Pro顺利完成运行后,面对out文件夹中密密麻麻的文件,很多研究者会陷入"数据沼泽"——明明流程跑通了,却不知道如何从这些中间文件中提取有价值的信息。本…...

MAA明日方舟自动化工具技术解析:图像识别算法如何解放你的游戏时间
MAA明日方舟自动化工具技术解析:图像识别算法如何解放你的游戏时间 【免费下载链接】MaaAssistantArknights 《明日方舟》小助手,全日常一键长草!| A one-click tool for the daily tasks of Arknights, supporting all clients. 项目地址:…...
)
GD32 vs STM32:除了参数表,新手选型还得看这几点(附快速上手指南)
GD32与STM32实战选型指南:新手避坑与快速上手指南 当你在电子市场拿起一片GD32开发板和一片STM32开发板时,它们看起来几乎一模一样——同样的引脚排列,同样的封装尺寸,甚至连丝印字体都相似。但当你真正开始项目开发时,…...

[笔记] 系统分析师 目录
文章目录系统分析师 第一章 绪论系统分析师 第二章 经济管理与应用数学系统分析师 第三章 操作系统基本原理系统分析师 第四章 数据通信与计算机网络系统分析师 第五章 数据库系统系统分析师 第六章 系统配置与性能评价系统分析师 第七章 企业信息化系统分析师 第八章 软件工程…...

别再只跑仿真了!用Vivado 2023.1给你的FPGA图像处理项目做个“硬件体检”
从仿真到硬件的跨越:FPGA图像处理项目实战验证指南 在实验室里看着仿真波形完美无缺,却在开发板上遭遇各种"灵异事件"——这可能是每个FPGA开发者都经历过的成长仪式。仿真环境就像飞行模拟器,能教会你基本操作,但真正的…...

Ubuntu下编译与测试libwebsockets:从x86环境验证到嵌入式移植
1. 项目概述与背景 在嵌入式开发中,尤其是涉及到网络通信模块时,我们常常会遇到一个典型的困境:直接在资源受限的目标板(比如ARM架构的开发板)上进行代码的编译、调试和功能验证,过程往往非常痛苦。编译速…...

AMBA系统监视器:从端口验证到SoC系统级验证的关键跃迁
1. 项目概述:从端口到系统的验证跃迁在SoC验证的战场上,我们常常陷入一种“只见树木,不见森林”的困境。作为一名验证工程师,你可能已经熟练地为每个AXI、AHB或APB接口挂上VIP(验证IP),看着端口…...

如何用LyricsX在Mac桌面显示歌词:免费开源工具终极指南
如何用LyricsX在Mac桌面显示歌词:免费开源工具终极指南 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics 你是否曾在听歌时想要跟着歌词一起唱,却不…...

手把手教你用SWM34SRET6驱动4.3寸TFT屏:从LVGL图片加载到SDRAM缓存的完整流程
手把手教你用SWM34SRET6驱动4.3寸TFT屏:从LVGL图片加载到SDRAM缓存的完整流程 在嵌入式开发中,实现高性能的图形界面显示往往需要处理复杂的硬件资源分配和软件架构设计。SWM34SRET6作为一款内置8MB SDRAM的Cortex-M33微控制器,为TFT-LCD驱动…...