使用 HuggingFace 提供的 Elasticsearch 托管交叉编码器进行重新排名
作者:来自 Elastic Jeff Vestal

了解如何使用 Hugging Face 的模型在 Elasticsearch 中托管和执行语义重新排序。
在这篇简短的博文中,我将向你展示如何使用 Hugging Face 中的模型在搜索时在你自己的 Elasticsearch 集群中执行语义重新排序。我们将使用 Eland 下载模型,从 Hugging Face 加载数据集,并使用检索器执行示例查询,所有这些都在 Jupyter 笔记本中完成。
概述
如果你不熟悉语义文本,请查看以下资源:
- 它是什么
- 为什么要使用它
- 如何创建推理 API 并将其连接到外部服务
- 如何使用检索器查询进行重新排名
请查看以下链接:
- 什么是语义重新排名以及如何使用它?
- 了解在搜索和 RAG 管道中使用语义重新排名的权衡
- 使用检索器在 Elasticsearch 中进行语义重新排名
- 本博客包含视频演示和入门所需的所有内容的概述。
- Elastic 文档 - 语义重新排名
- 这个优秀的文档指南讨论了用例、编码器模型类型和 Elasticsearch 中的重新排名
本博客和随附笔记本中的代码也将帮助你入门,但我们不会深入讨论是什么和为什么。
另外,请注意,我将在下面展示代码片段,但自己做这件事的最佳方法是按照随附的笔记本进行操作。
步骤零
我还假设你有一个 Elasticsearch 集群或 serverless 项目,你将在本指南中使用它们。如果没有,请前往 cloud.elastic.co 并注册免费试用!你需要一个 Cloud ID 和 Elasticsearch API 密钥。
模型选择
第一步(真正的)是选择用于重新排名的模型。深入讨论选择模型和评估结果超出了本博客的范围。请注意,目前 Elasticsearch 仅支持跨编码(cross-encoder)器模型。
虽然没有直接涵盖模型选择,但以下博客很好地概述了评估搜索相关性。
- 评估搜索相关性(三部分系列)
- 搜索相关性调整:平衡关键字和语义搜索
对于本指南,我们将使用 cross-encoder/ms-marco-MiniLM-L-6-v2。该模型使用 MS Marco 数据集进行检索和重新排名。
模型加载
要将 Hugging Face 中的 NLP 模型加载到 Elasticsearch,你需要使用 Eland Python 库。
Eland 是 Elastic 的 Python 库,用于数据帧分析以及将监督和 NLP 模型加载到 Elasticsearch。它提供了一个熟悉的 Pandas 兼容 API。你可以参考文章来安装 Eland。
以下代码来自笔记本部分 “Hugging Face Reranking Model.”。
model_id = "cross-encoder/ms-marco-MiniLM-L-6-v2"cloud_id = "my_super_cloud_id"
api_key = "my_super_secred_api_key!"!eland_import_hub_model \
--cloud-id $cloud_id \
--es-api-key $api_key \
--hub-model-id $model_id \
--task-type text_similarityEland 没有特定的 “rerank” 任务类型;我们使用 text_similarity 类型来加载模型。
此步骤将在运行代码的本地下载模型,将其拆分,然后加载到你的 Elasticsearch 集群中。
切到
在笔记本中,你可以按照步骤设置集群以在下一节中运行重新排名查询。下载笔记本中显示的模型后的设置步骤如下:
- 使用重新排名任务创建推理端点
- 这还将在 Elasticsearch 机器学习节点上部署我们的重新排名模型
- 创建索引映射
- 从 Hugging Face - CShorten/ML-ArXiv-Papers 下载数据集
- 将数据索引到 Elasticsearch
重新排序时间!
一切设置完毕后,我们可以使用 text_similarity_reranker 检索器进行查询。文本相似性重新排序器是一个两阶段重新排序器。这意味着首先运行指定的检索器,然后将这些结果传递到第二个重新排序阶段。
笔记本中的示例:
query = "sparse vector embedding"# Query with Semantic Reranker
response_reranked = es.search(index="arxiv-papers-lexical",body={"size": 10,"retriever": {"text_similarity_reranker": {"retriever": {"standard": {"query": {"match": {"title": query}}}},"field": "abstract","inference_id": "semantic-reranking","inference_text": query,"rank_window_size": 100}},"fields": ["title", "abstract"], "_source": False}
)上述 text_similarity_reranker 的参数为:
- retriever - 在这里,我们使用标准检索器进行词汇第一阶段检索的简单匹配查询。你也可以在此处使用 knn 检索器或 rrf 检索器。
- field - 重新排名模型将用于相似性比较的第一阶段结果中的字段。
- inference_id - 用于重新排名的推理服务的 ID。在这里,我们使用我们之前加载的模型。
- inference_text - 用于相似性排名的字符串
- rank_window_size - 模型将考虑的第一阶段的顶级文档数量。
你可能想知道为什么 `rank_window_size` 设置为 100,即使你最终可能只想要前 10 个结果。
在两阶段搜索设置中,初始词汇搜索为语义重新排序器提供了广泛的文档集以供评估。返回 100 个结果的较大集合增加了相关文档可供语义重新排序器识别并根据语义内容(而不仅仅是词汇匹配)重新排序的机会。这种方法弥补了词汇搜索在捕捉细微含义方面的局限性,使语义模型能够筛选出更广泛的可能性。
但是,找到正确的 `rank_window_size` 是一种平衡。虽然更大的候选集可以提高准确性,但也可能会增加资源需求,因此需要进行一些调整以在召回率和资源之间实现最佳权衡。
比较
虽然我不会在本简短指南中对结果进行深入分析,但可能引起普遍兴趣的是查看标准词汇匹配查询的前 5 个结果和上述重新排序查询的结果。
此数据集包含有关机器学习的 ArXiv 论文子集。列出的结果是论文的标题。
“评分结果” 是使用标准检索器的前 10 个结果
“重新排序结果” 是重新排序后的前 10 个结果
| 评分结果 | 重新排序结果 | |
|---|---|---|
| 0 | Compact Speaker Embedding: lrx-vector | Scaling Up Sparse Support Vector Machines by Simultaneous Feature and Sample Reduction |
| 1 | Quantum Sparse Support Vector Machines | Spaceland Embedding of Sparse Stochastic Graphs |
| 2 | Sparse Support Vector Infinite Push | Elliptical Ordinal Embedding |
| 3 | The Sparse Vector Technique, Revisited | Minimum-Distortion Embedding |
| 4 | L-Vector: Neural Label Embedding for Domain Adaptation | Free Gap Information from the Differentially Private Sparse Vector and Noisy Max Mechanisms |
| 5 | Spaceland Embedding of Sparse Stochastic Graphs | Interpolated Discretized Embedding of Single Vectors and Vector Pairs for Classification, Metric Learning and Distance Approximation |
| 6 | Sparse Signal Recovery in the Presence of Intra-Vector and Inter-Vector Correlation | Attention Word Embedding |
| 7 | Stable Sparse Subspace Embedding for Dimensionality Reduction | Binary Speaker Embedding |
| 8 | Auto-weighted Mutli-view Sparse Reconstructive Embedding | NetSMF: Large-Scale Network Embedding as Sparse Matrix Factorization |
| 9 | Embedding Words in Non-Vector Space with Unsupervised Graph Learning | Estimating Vector Fields on Manifolds and the Embedding of Directed Graphs |
轮到你了
希望你明白将 Hugging Face 的重新排名模型整合到 Elasticsearch 中是多么容易,这样你就可以开始重新排名了。虽然这不是唯一的重新排名选项,但当你在隔离环境中运行、无法访问外部重新排名服务、想要控制成本或拥有一个特别适合你的数据集的模型时,它会很有帮助。
如果你还没有点击随附笔记本的众多链接之一,现在是时候了!
准备好自己尝试一下了吗?开始免费试用。
想要获得 Elastic 认证吗?了解下一次 Elasticsearch 工程师培训何时举行!
原文:Reranking with an Elasticsearch-hosted cross-encoder from HuggingFace - Search Labs
相关文章:
使用 HuggingFace 提供的 Elasticsearch 托管交叉编码器进行重新排名
作者:来自 Elastic Jeff Vestal 了解如何使用 Hugging Face 的模型在 Elasticsearch 中托管和执行语义重新排序。 在这篇简短的博文中,我将向你展示如何使用 Hugging Face 中的模型在搜索时在你自己的 Elasticsearch 集群中执行语义重新排序。我们将使用…...

CKA认证 | Day1 k8s核心概念与集群搭建
第一章 Kubernetes 核心概念 1、主流的容器集群管理系统 容器编排系统: KubernetesSwarmMesos Marathon 2、Kubernetes介绍 Kubernetes是Google在2014年开源的一个容器集群管理系统,Kubernetes简称K8s。 Kubernetes用于容器化应用程序的部署&#x…...
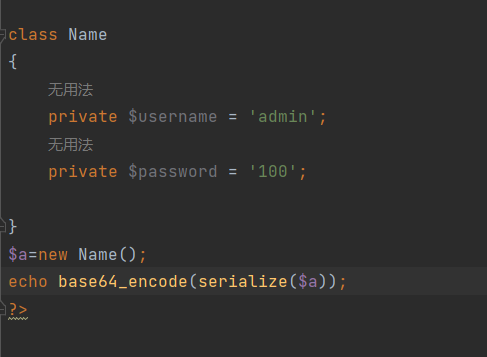
[极客大挑战 2019]PHP 1
[极客大挑战 2019]PHP 1 审题 猜测备份在www.zip中,输入下载文件。 知识点 反序列化 解题 查看代码 看到index.php中包含了class.php,直接看class.php中的代码 查看条件 当usernameadmin,password100时输出flag 构造反序列化 输入select中&#…...

【c++丨STL】vector模拟实现
🌟🌟作者主页:ephemerals__ 🌟🌟所属专栏:C、STL 目录 前言 一、vector底层刨析 二、模拟实现 1. 属性、迭代器以及函数声明 2. 功能实现 交换两个容器的内容 构造函数 拷贝构造 赋值重载 析构…...

SQLAlchemy 介绍与实践
postgresql 实践 pydantic 实践 1. SQLAlchemy 介绍 SQLAlchemy 是一个 ORM 框架。SQLAlchemy 是一个用于 Python 的 SQL 工具和对象关系映射(ORM)库。它允许你通过 Python 代码来与关系型数据库交互,而不必直接编写SQL语句。 简单介绍一下…...

docker进行SRS直播服务器搭建
docker进行SRS直播服务器搭建 docker构建参考地址: 地址: https://github.com/ossrs/srs https://ossrs.net/lts/zh-cn/docs/v5/doc/getting-started docker run --rm -it -p 1935:1935 -p 1985:1985 -p 8080:8080 \-p 8000:8000/udp -p 10080:10080/udp ossrs/sr…...

windows server2019下载docker拉取redis等镜像并运行项目
一、基本概念 1、windows server 指由微软公司开发的“Windows”系列中的“服务器”版本。这意味着它是基于Windows操作系统的,但专门设计用于服务器环境,而不是普通的桌面或个人用户使用。主要用途包括服务器功能、用户和资源管理、虚拟化等 2、dock…...

数据结构(8.7_2)——败者树
多路平衡归并带来的问题 什么是败者树 败者树的构造 败者树的使用 败者树在多路平衡归并中的应用 败者树的实现思路 总结...

设计模式-七个基本原则之一-里氏替换原则
里氏替换原则(LSP)面向对象六个基本原则之一 子类与父类的替代性:子类应当能够替代父类出现的任何地方,且表现出相同的行为。行为的一致性:子类的行为必须与父类保持一致,包括输入和输出、异常处理等。接口…...

k8s中基于overlay网络和underlay网络的网络插件分别有哪些
在 Kubernetes 中,不同的网络插件会使用 overlay 或 underlay 网络来连接 Pod 和节点。以下是基于 overlay 网络和 underlay 网络的常见 Kubernetes 网络插件: 1. 基于 Overlay 网络的插件 这些插件通过隧道封装技术(如 VXLAN、GRE 等&#…...

一文详解java的数据类型
1. 题记 Java是一门对数据类型敏感的语言,本博文主要总结介绍java语言的数据类型。 2. java的数据类型 Java 的数据类型分为基本数据类型(Primitive Data Types)和引用数据类型(Reference Data Types)。 2.1 基本数…...

Flink API 的层次结构
Apache Flink 提供了多层 API,每层 API 针对不同的抽象层次和用途,使得开发者可以根据具体需求选择合适的 API 层次。以下是 Flink API 的层次结构及其简要说明:...

lua入门教程:math
在Lua中,math库是一个非常重要的内置库,它提供了许多用于数学计算的函数。这些函数可以处理各种数学运算,包括基本的算术运算、三角函数、对数函数、随机数生成等。结合你之前提到的Lua中的数字遵循IEEE 754双精度浮点标准,我们可…...

ROS2简介与Ubuntu24.04中安装指南
之前安装了一个版本,但是不愿意写blog,现在想想自己就是个沙子立个flag,每次配置项目,写流程blog ROS简介 ROS(Robot Operating System)是一个开源的机器人软件平台,提供了许多工具和库来帮助…...
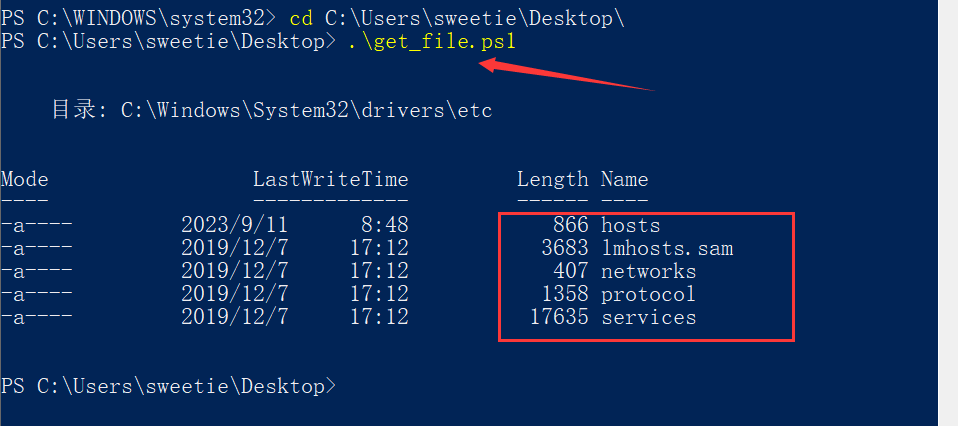
命令行工具PowerShell使用体验
命令行工具PowerShell使用 PowerShell是微软开发的一种面向对象的命令行Shell和脚本语言环境,它允许用户通过命令行的方式管理操作系统。相较于传统CMD,PowerShell增加了面向对象的程序设计框架,拥有更强大的功能和扩展性。使用PowerShell可…...

MongoDB 详解:深入理解与探索
在当今的数据库领域,MongoDB 以其独特的特性和强大的功能,成为了众多开发者和企业的首选。本文将对 MongoDB 进行详细的介绍,包括其特点、应用场景、流程图以及源码分析。 一、MongoDB 概述 MongoDB 是一个基于分布式文件存储的开源数据库系…...

使用 Elasticsearch 构建食谱搜索(一)
作者:来自 Elastic Andre Luiz 了解如何使用 Elasticsearch 构建基于语义搜索的食谱搜索。 简介 许多电子商务网站都希望增强其食谱搜索体验。正确使用语义搜索可以让客户根据更自然的查询(例如 “something for Valentines Day - 情人节的礼物” 或 “…...

sealos部署K8s,安装docker时master节点突然NotReady
1、集群正常运行中,在集群master-1上安装了dockerharbor,却发现master-1节点NotReady,使用的网络插件为 Cilium #安装docker和harbor(docker运行正常) rootmaster-1:/etc/apt# apt install docker-ce5:19.03.15~3-0~u…...

使用vite+react+ts+Ant Design开发后台管理项目(五)
前言 本文将引导开发者从零基础开始,运用vite、react、react-router、react-redux、Ant Design、less、tailwindcss、axios等前沿技术栈,构建一个高效、响应式的后台管理系统。通过详细的步骤和实践指导,文章旨在为开发者揭示如何利用这些技术…...

Spring Boot实现多数据源连接和切换
文章目录 前言一、多数据源配置与切换方案二、实现步骤1. 创建多个 DataSource 配置类2. 创建 DataSource 配置类3. 创建动态数据源路由类4. 实现 DynamicDataSource 类5. 创建 DataSourceContextHolder 来存储当前的数据源标识6. AOP 方式切换数据源7. 自定义注解来指定数据源…...

打破平台壁垒:Windows上安装APK文件的完整解决方案
打破平台壁垒:Windows上安装APK文件的完整解决方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过在Windows电脑上直接运行安卓应用ÿ…...

CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战
CCPD车牌数据集预处理避坑指南:透视变换原理详解与OpenCV实战 车牌识别系统中,数据预处理的质量直接影响模型性能。CCPD作为目前最全面的中文车牌数据集,其四点标注特性为透视变换提供了基础,但也暗藏诸多陷阱。本文将手把手带您穿…...
)
保姆级教程:在CentOS 7/8服务器上部署DrissionPage爬虫(含Chrome无头模式配置)
CentOS服务器上DrissionPage爬虫的工业级部署指南 1. 环境准备与Chrome浏览器安装 在CentOS服务器上部署基于DrissionPage的爬虫系统,首要任务是构建稳定可靠的浏览器运行环境。与个人开发环境不同,生产服务器通常需要面对无图形界面、资源受限等特殊场景…...

3步实现专业级AI换脸:roop-unleashed创新方案指南
3步实现专业级AI换脸:roop-unleashed创新方案指南 【免费下载链接】roop-unleashed Evolved Fork of roop with Web Server and lots of additions 项目地址: https://gitcode.com/gh_mirrors/ro/roop-unleashed 在数字创意飞速发展的今天,AI换脸…...

ARM Neoverse-V3架构解析与性能优化实战
1. ARM Neoverse-V3架构概览作为Arm公司面向基础设施领域的最新处理器IP,Neoverse-V3代表了当前服务器级处理器的顶尖设计水平。我在实际芯片开发中多次接触该架构,其设计哲学可概括为:通过精细化微架构控制实现性能与能效的完美平衡。1.1 指…...

数据中心碳足迹与可靠性优化框架解析
1. 数据中心碳足迹与可靠性优化的挑战 现代数据中心已成为数字经济的动力引擎,但伴随算力需求的爆炸式增长,其能源消耗与碳排放问题日益凸显。根据最新统计,全球数据中心年耗电量已达4600亿度,占全球总用电量的2%。随着大语言模型…...
Pixel Framebuf库:图形化编程驱动LED矩阵,告别底层坐标换算
1. 项目概述:告别点灯,拥抱图形化LED矩阵编程如果你玩过Arduino或者树莓派,大概率接触过WS2812B这类可寻址LED,也就是大家常说的NeoPixel。单个灯珠的控制很简单,setPixelColor一下就能亮。但当你面对一个8x8、16x16甚…...

Agent Framework 中的 Workflow Composition
在前面的文章中,我们已经介绍了 Agent Framework 中如何定义流程节点,以及 Workflow 的流式执行事件。 如果你对这些概念还不太熟悉,可以先回顾上一篇文章: Agent Framework 定义流程节点以及节点的流式输出 这一节我们来介绍 Wor…...

Verilog时钟分频实战:从偶数、奇数到小数分频的设计与实现
1. 项目概述:从零开始掌握Verilog时钟分频 在数字电路和FPGA设计中,时钟信号是驱动整个系统同步运行的“心跳”。然而,一个系统往往需要多种不同频率的时钟来驱动不同的模块,比如高速的处理器核心和低速的外设接口。直接使用多个外…...
)
告别复杂推导!用PyTorch 2.0手把手实现Reptile算法(附完整代码与对比实验)
告别复杂推导!用PyTorch 2.0手把手实现Reptile算法(附完整代码与对比实验) 元学习(Meta-Learning)作为机器学习领域的前沿方向,近年来在少样本学习、快速适应新任务等场景展现出巨大潜力。然而,…...