一文熟悉新版llama.cpp使用并本地部署LLAMA
0. 简介
最近是快到双十一了再给大家上点干货。去年我们写了一个大模型的系列,经过一年,大模型的发展已经日新月异。这一次我们来看一下使用llama.cpp这个项目,其主要解决的是推理过程中的性能问题。主要有两点优化:
- llama.cpp 使用的是 C 语言写的机器学习张量库 ggml
- llama.cpp 提供了模型量化的工具

此项目的牛逼之处就是没有GPU也能跑LLaMA模型。llama.cpp是一个不同的生态系统,具有不同的设计理念,旨在实现轻量级、最小外部依赖、多平台以及广泛灵活的硬件支持:
-
纯粹的C/C++实现,没有外部依赖
-
支持广泛的硬件:
- x86_64 CPU的AVX、AVX2和AVX512支持
- 通过Metal和Accelerate支持Apple Silicon(CPU和GPU)
- NVIDIA GPU(通过CUDA)、AMD GPU(通过hipBLAS)、Intel GPU(通过SYCL)、昇腾NPU(通过CANN)和摩尔线程GPU(通过MUSA)
- GPU的Vulkan后端
-
多种量化方案以加快推理速度并减少内存占用
-
CPU+GPU混合推理,以加速超过总VRAM容量的模型
llama.cpp 提供了大模型量化的工具,可以将模型参数从 32 位浮点数转换为 16 位浮点数,甚至是 8、4 位整数。除此之外,llama.cpp 还提供了服务化组件,可以直接对外提供模型的 API 。
这里最近受到优刻得的使用邀请,正好解决了我在大模型和自动驾驶行业对GPU的使用需求。UCloud云计算旗下的Compshare的GPU算力云平台。他们提供高性价比的4090 GPU,按时收费每卡1.88元,并附带200G的免费磁盘空间。暂时已经满足我的使用需求了,同时支持访问加速,独立IP等功能,能够更快的完成项目搭建。此外对于低性能的还有3080TI使用只需要0.88元,已经吊打市面上主流的云服务器了
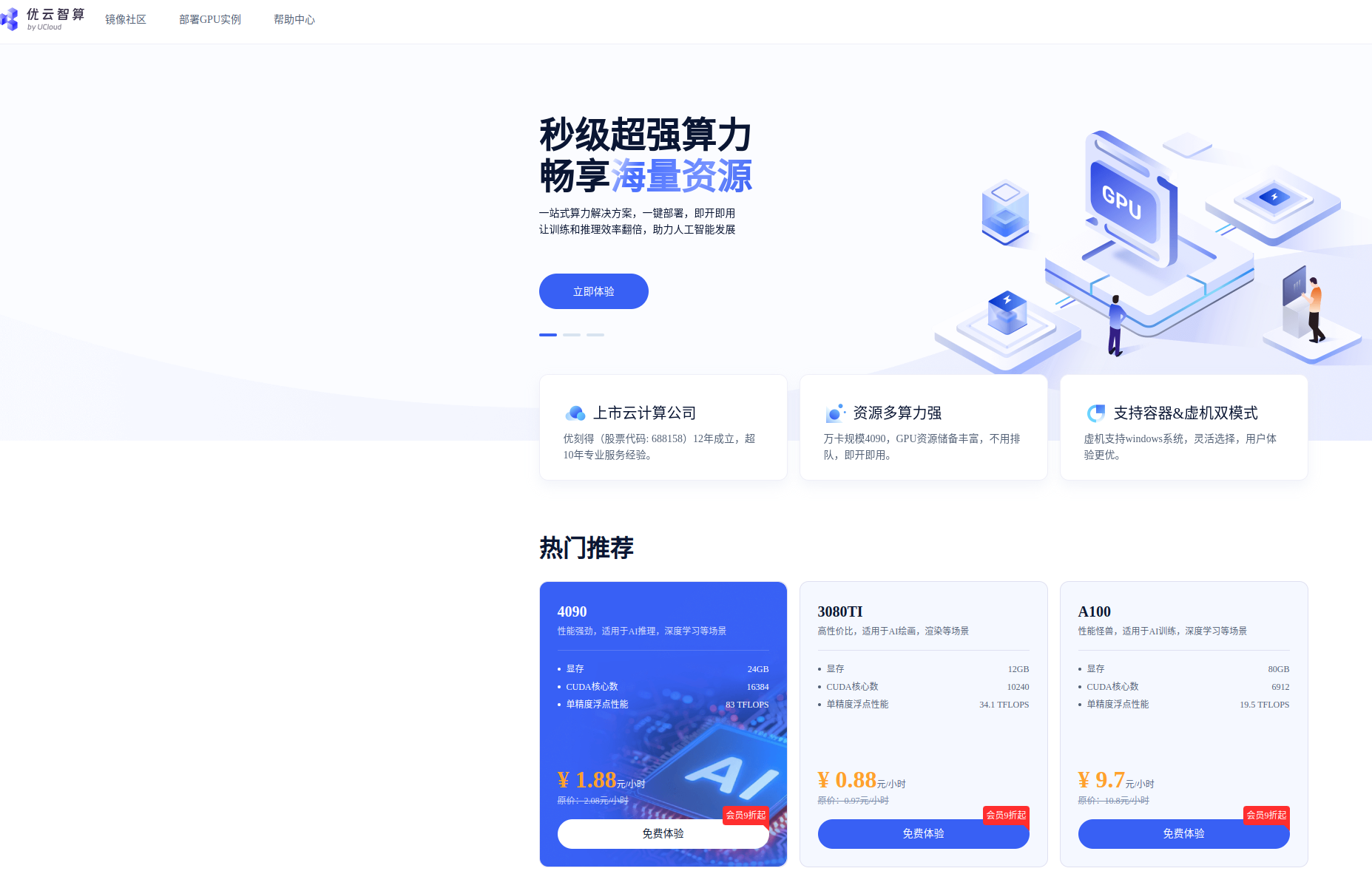
这里已经提供了我们本项目使用镜像,方便读者快速复现

1. llama.cpp环境安装
克隆仓库并进入该目录:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
构建GPU执行环境,确保安装CUDA工具包,适用于有GPU的操作系统
如果CUDA设置正确,那么执行nvidia-smi、nvcc --version没有错误提示,则表示一切设置正确。
mkdir build
sudo apt-get install make cmake gcc g++ locate
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release -j4
cd build
make install

在当前版本(截至2024年11月10日)这些指令分别被重命名为llama-quantize、llama-cli、llama-server。
ln -s your/path/to/llama.cpp/build/bin/llama-quantize llama-quantize
ln -s your/path/to/llama.cpp/build/bin/llama-server llama-server
ln -s your/path/to/llama.cpp/build/bin/llama-cli llama-cli
2. LLAMA模型转换
这里我们会从pth开始,一步步给出我们怎么将模型应用到llama.cpp中的。
2.1 pth原始模型处理
首先安装高版本python 3.10
pip install protobuf==3.20.0
pip install transformers #最新版
pip installsentencepiece #(0.1.97测试通过)
pip install peft #(0.2.0测试通过)
pip install git+https://github.com/huggingface/transformers
pip install sentencepiece
pip install peft
2.1.1 磁链下载
然后下载原版LLaMA模型的权重和tokenizer.model文件。如果嫌从官方下载太麻烦,网上也有一些泄露的模型版本可以直接下载。
这里应该是最早泄漏的版本,可以使用 IPFS 客户端 进行下载。
社区里也有人制作了种子,可以使用 BitTorrent 下载,磁链地址为 magnet:?xt=urn:btih:ZXXDAUWYLRUXXBHUYEMS6Q5CE5WA3LVA&dn=LLaMA
sudo apt update
sudo apt install transmission-cli
transmission-cli "magnet:?xt=urn:btih:ZXXDAUWYLRUXXBHUYEMS6Q5CE5WA3LVA&dn=LLaMA"
压缩包内文件目录如下(LLaMA-7B为例)
├── llama-7b
│ ├── consolidated.00.pth
│ ├── params.json
│ └── checklist.chk
└── tokenizer.model
2.1.2 使用 pyllama 下载
另一种下载 Llama 模型的方法是使用 pyllama 库。首先,通过 pip 安装它(非M2芯片):
pip3 install transformers pyllama -U
然后通过下面的命令下载 Llama 7B 模型(根据需要你也可以下载 13B、30B 和 65B,如果不指定 --model_size 则下载所有):
python3 -m llama.download --model_size 7B
在 Mac M2 下可能会遇到下面这样的报错:
ImportError: dlopen(/Library/Python/3.9/site-packages/_itree.cpython-39-darwin.so, 0x0002): tried: '/Library/Python/3.9/site-packages/_itree.cpython-39-darwin.so' (mach-o file, but is an incompatible architecture (have 'x86_64', need 'arm64')), '/System/Volumes/Preboot/Cryptexes/OS/Library/Python/3.9/site-packages/_itree.cpython-39-darwin.so' (no such file), '/Library/Python/3.9/site-packages/_itree.cpython-39-darwin.so' (mach-o file, but is an incompatible architecture (have 'x86_64', need 'arm64'))
根据 itree 的官方文档,这个库我们需要自己手动构建:
brew install cmake
pip3 install https://github.com/juncongmoo/itree/archive/refs/tags/v0.0.18.tar.gz
安装完成后,再次下载,这次虽然没有报错,但是模型的下载目录 pyllama_data 却是空的,根据 这里 的解决方案,我们使用源码重新安装 pyllama:
pip3 uninstall pyllama
git clone https://github.com/juncongmoo/pyllama
pip3 install -e pyllama
然后再次下载即可,7B 模型文件大约 13G,下载速度取决于你的网速,成功后输出如下:
python3 -m llama.download --model_size 7B
❤️ Resume download is supported. You can ctrl-c and rerun the program to resume the downloadingDownloading tokenizer...
✅ pyllama_data/tokenizer.model
✅ pyllama_data/tokenizer_checklist.chk
tokenizer.model: OKDownloading 7Bdownloading file to pyllama_data/7B/consolidated.00.pth ...please wait for a few minutes ...
✅ pyllama_data/7B/consolidated.00.pth
✅ pyllama_data/7B/params.json
✅ pyllama_data/7B/checklist.chkChecking checksums for the 7B model
consolidated.00.pth: OK
params.json: OK
2.1.3 脚本下载(作者使用的这个方法)
#!/bin/bash
# Function to handle stopping the script
function stop_script() {echo "Stopping the script."exit 0
}
# Register the signal handler
trap stop_script SIGINT
while true; do# Run the command with a timeout of 200 secondstimeout 2000 python -m llama.download --model_size $1 --folder modelecho "restart download"sleep 1 # Wait for 1 second before starting the next iteration
# Wait for any key to be pressed within a 1-second timeoutread -t 1 -n 1 -s keyif [[ $key ]]; thenstop_scriptfi
done
之后运行该文件即可自动执行(漫长等待ing)
bash llama_download.sh 7B

下载后一共有 5 个文件:
pyllama_data
|-- 7B
| |-- checklist.chk
| |-- consolidated.00.pth
| `-- params.json
|-- tokenizer.model
`-- tokenizer_checklist.chk
2.2 原版转为hf格式文件
2.2.1 hf格式转换
这里使用transformers提供的脚本convert_llama_weights_to_hf.py将原版LLaMA模型转换为HuggingFace格式。或者直接在抱抱脸上下载
git clone https://huggingface.co/luodian/llama-7b-hf ./models/Llama-7b-chat-hf
将原版LLaMA的tokenizer.model放在--input_dir指定的目录,其余文件放在${input_dir}/${model_size}下。 执行以下命令后,--output_dir中将存放转换好的HF版权重。
git clone https://github.com/huggingface/transformers.git
cd transformers
python src/transformers/models/llama/convert_llama_weights_to_hf.py \--input_dir /workspace/pth_model/7B \--model_size 7B \--output_dir /workspace/hf_data
--output_dir目录下会生成HF格式的模型文件,诸如:
config.json
generation_config.json
pytorch_model-00001-of-00002.bin
pytorch_model-00002-of-00002.bin
pytorch_model.bin.index.json
special_tokens_map.json
tokenizer_config.json
tokenizer.json
tokenizer.model

2.2.2 合并lora
这里我们选择了Chinese-LLaMA-Alpaca作为lora合并的操作。然后我们需要合并LoRA权重,生成全量模型权重。这里我们使用ymcui/Chinese-LLaMA-Alpaca at v2.0 (github.com)里面的scripts/merge_llama_with_chinese_lora.py脚本
git clone https://github.com/ymcui/Chinese-LLaMA-Alpaca.git
对原版LLaMA模型(HF格式)扩充中文词表,并与LoRA权重进行合并,生成全量模型权重consolidated.*.pth(建议检查生成模型的SHA256值)和配置文件params.json。请执行以下命令:

此处输入使用scripts/merge_llama_with_chinese_lora.py脚本,对原版LLaMA模型(HF格式)扩充中文词表,并与LoRA权重进行合并,生成全量模型权重consolidated.*.pth(建议检查生成模型的SHA256值)和配置文件params.json。需要保证以上两个脚本所需参数一致,仅输出文件格式不同。下面以生成PyTorch版本权重为例,介绍相应的参数设置。
python scripts/merge_llama_with_chinese_lora.py \--base_model /workspace/hf_data \--lora_model /workspace/chinese_llama_lora_7b \--output_dir /workspace/lora_pth_data
--base_model:存放HF格式的LLaMA模型权重和配置文件的目录(Step 1生成)
--lora_model:中文LLaMA/Alpaca LoRA解压后文件所在目录,也可使用Model Hub模型调用名称:ziqingyang/chinese-alpaca-lora-7b或ziqingyang/chinese-llama-lora-7b
--output_type: 指定输出格式,可为pth或huggingface。若不指定,默认为pth
--output_dir:指定保存全量模型权重的目录,默认为./(可选)
--offload_dir(仅对旧脚本scripts/merge_llama_with_chinese_lora.py有效): 对于低内存用户需要指定一个offload缓存路径(可选)
如果出现下面的错误

则将/workspace/chinese_llama_lora_7b下的adapter_config.json删除lora内容

转换结果:

在转换完毕后,如有需要,可自行按照2.2.1节中的脚本将本步骤生成的.pth文件转换为HuggingFace格式。
2.3 hf转guff模型
之前的convert.py 已被移至 examples/convert_legacy_llama.py,并且不应用于 Llama/Llama2/Mistral 模型及其衍生品以外的任何用途。它不支持 LLaMA 3,您可以使用 convert_hf_to_gguf.py 来处理从 Hugging Face 下载的 LLaMA 3。这里我们对模型进行转化,将其转化为gguf格式并进行量化,在llama.cpp路径下:
# 请参考并替换为自己的对应路径,记得创建/workspace/chinese_gguf/llama-7b.gguf这个文件。其中outtype 是指下面的量化精度,其实不需要转,可以使用下面的指令转
python convert_hf_to_gguf.py ../hf_data --outfile /workspace/chinese_gguf/llama-7b.gguf --outtype q8_0#如果是pth则是
python3 examples/convert_legacy_llama.py /workspace/lora_pth_data/ --outfile /workspace/chinese_gguf/chinese.gguf

pth 版本
hf版本

# llama-quantize 提供各种精度的量化
#./llama-quantize
#usage: ./quantize [--help] [--allow-requantize] [--leave-output-tensor] model-f32.gguf [model-quant.gguf] type [nthreads]
# --allow-requantize: Allows requantizing tensors that have already been quantized. Warning: This can severely reduce quality compared to quantizing from 16bit or 32bit
# --leave-output-tensor: Will leave output.weight un(re)quantized. Increases model size but may also increase quality, especially when requantizing# Allowed quantization types:
# 2 or Q4_0 : 3.56G, +0.2166 ppl @ LLaMA-v1-7B
# 3 or Q4_1 : 3.90G, +0.1585 ppl @ LLaMA-v1-7B
# 8 or Q5_0 : 4.33G, +0.0683 ppl @ LLaMA-v1-7B
# 9 or Q5_1 : 4.70G, +0.0349 ppl @ LLaMA-v1-7B
# 10 or Q2_K : 2.63G, +0.6717 ppl @ LLaMA-v1-7B
# 12 or Q3_K : alias for Q3_K_M
# 11 or Q3_K_S : 2.75G, +0.5551 ppl @ LLaMA-v1-7B
# 12 or Q3_K_M : 3.07G, +0.2496 ppl @ LLaMA-v1-7B
# 13 or Q3_K_L : 3.35G, +0.1764 ppl @ LLaMA-v1-7B
# 15 or Q4_K : alias for Q4_K_M
# 14 or Q4_K_S : 3.59G, +0.0992 ppl @ LLaMA-v1-7B
# 15 or Q4_K_M : 3.80G, +0.0532 ppl @ LLaMA-v1-7B
# 17 or Q5_K : alias for Q5_K_M
# 16 or Q5_K_S : 4.33G, +0.0400 ppl @ LLaMA-v1-7B
# 17 or Q5_K_M : 4.45G, +0.0122 ppl @ LLaMA-v1-7B
# 18 or Q6_K : 5.15G, -0.0008 ppl @ LLaMA-v1-7B
# 7 or Q8_0 : 6.70G, +0.0004 ppl @ LLaMA-v1-7B
# 1 or F16 : 13.00G @ 7B
# 0 or F32 : 26.00G @ 7B
# 2. 使用llama-quantize 转换精度
# llama-quantize支持的精度以及更多的使用方法可通过llama-quantize --help查看
llama-quantize /workspace/chinese_gguf/chinese.gguf /workspace/chinese_gguf/chinese_q4_0.gguf Q4_0

转换完成后,模型目录下会多一个 chinese_q4_0.gguf 文件:
ls -lh /workspace/chinese_gguf

3. 使用 llama.cpp 运行 GGUF 模型
这里我们可以通过上面的操作,或者去 https://huggingface.co/models 找 GGUF 格式的大模型版本,下载模型文件放在 llama.cpp 项目 models 目录下。
git clone https://huggingface.co/rozek/LLaMA-2-7B-32K-Instruct_GGUF ./models/LLaMA-2-7B-32K-Instruct_GGUF
仓库中包含各种量化位数的模型,Q2、Q3、Q4、Q5、Q6、Q8、F16。量化模型的命名方法遵循: “Q” + 量化比特位 + 变种。量化位数越少,对硬件资源的要求越低,但是模型的精度也越低。
3.1 交互模式
可通过llama-cli或llama-server运行模型。
llama-cli -m chinese_q4_0.gguf -p "you are a helpful assistant" -cnv -ngl 24

其中:
-m参数后跟要运行的模型-cnv表示以对话模式运行模型-ngl:当编译支持 GPU 时,该选项允许将某些层卸载到 GPU 上进行计算。一般情况下,性能会有所提高。
其他参数详见官方文档llama.cpp/examples/main/README.md at master · ggerganov/llama.cpp (github.com)
3.2 模型API服务
llama.cpp提供了完全与OpenAI API兼容的API接口,使用经过编译生成的llama-server可执行文件启动API服务。如果编译构建了GPU执行环境,可以使用-ngl N或 --n-gpu-layers N参数,指定offload层数,让模型在GPU上运行推理。未使用-ngl N或 --n-gpu-layers N参数,程序默认在CPU上运行
./llama-server -m /mnt/workspace/my-llama-13b-q4_0.gguf -ngl 28
可从以下关键启动日志看出,模型在GPU上执行
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: CUDA_USE_TENSOR_CORES: yes
ggml_cuda_init: found 1 CUDA devices:Device 0: Tesla V100S-PCIE-32GB, compute capability 7.0, VMM: yes
llm_load_tensors: ggml ctx size = 0.30 MiB
llm_load_tensors: offloading 32 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 33/33 layers to GPU
llm_load_tensors: CPU buffer size = 1002.00 MiB
llm_load_tensors: CUDA0 buffer size = 14315.02 MiB
.........................................................................................
llama_new_context_with_model: n_ctx = 512
llama_new_context_with_model: n_batch = 512
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 0
会启动一个类似web服务器的进程,默认端口号为8080,这样就启动了一个 API 服务,可以使用 curl 命令进行测试。
curl --request POST \--url http://localhost:8080/completion \--header "Content-Type: application/json" \--data '{"prompt": "What color is the sun?","n_predict": 512}'{"content":".....","generation_settings":{"frequency_penalty":0.0,"grammar":"","ignore_eos":false,"logit_bias":[],"mirostat":0,"mirostat_eta":0.10000000149011612,"mirostat_tau":5.0,......}}
此外可通过web页面或者OpenAI api等进行访问。安装openai依赖
pip install openai
使用OpenAI api访问:
import openaiclient = openai.OpenAI(base_url="http://127.0.0.1:8080/v1",api_key = "sk-no-key-required"
)completion = client.chat.completions.create(model="qwen", # model name can be chosen arbitrarilymessages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "tell me something about michael jordan"}]
)
print(completion.choices[0].message.content)
3.3模型API服务(第三方,自己安装不需要)
在llamm.cpp项目中有提到各种语言编写的第三方工具包,可以使用这些工具包提供API服务,这里以Python为例,使用llama-cpp-python提供API服务。
安装依赖
pip install llama-cpp-python
pip install llama-cpp-python -i https://mirrors.aliyun.com/pypi/simple/
注意:可能还需要安装以下缺失依赖,可根据启动时的异常提示分别安装。
pip install sse_starlette starlette_context pydantic_settings
启动API服务,默认运行在http://localhost:8000
python -m llama_cpp.server --model models/Llama3-q8.gguf
然后操作和上面一致,运行openai的脚本
4. 实现类似 ChatGPT 的聊天应用
至此,我们已经可以熟练地在本地部署和运行 Llama 模型了,为了让我们和语言模型之间的交互更加友好,我们还可以借助一些开源项目打造一款类似 ChatGPT 的聊天应用。无论是 llama.cpp 还是 Ollama,周边生态都非常丰富,社区开源了大量的网页、桌面、终端等交互界面以及诸多的插件和拓展,参考 Ollama 的 Community Integrations。
下面列举一些比较有名的 Web UI:
- Open WebUI
- Text generation web UI
- Jan
- GPT4All
- LibreChat
接下来我们就基于 Open WebUI 来实现一个本地聊天应用。Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 WebUI,旨在完全离线运行。它的原名叫 Ollama WebUI,原本只是对 Ollama 的,后来在社区的推动下,发展成了一款通用的聊天应用 WebUI,支持各种 LLM 运行器,包括 Ollama 以及与 OpenAI 兼容的接口。
Open WebUI 具备大量的功能特性,包括:
- 直观的界面:接近 ChatGPT 的界面,提供用户友好的体验;
- 响应式的设计:同时兼容桌面和移动端设备;
- 快速的响应:让用户享受快速且响应迅速的性能;
- 轻松的安装:支持使用 Docker 或 Kubernetes 进行安装;
- 代码语法高亮:增强代码的可读性;
- 全面支持 Markdown 和 LaTeX:实现更丰富的交互,提升用户的体验;
- 本地 RAG 集成:支持在聊天中对文档进行问答;
- 网页浏览功能:支持在聊天中对网页进行问答;
- 预设的提示词:聊天时输入
/命令即可立即访问预设的提示词; - RLHF 注释:通过给消息点赞或点踩,为 RLHF 创建数据集,便于使用您的消息来训练或微调模型;
- 对话标记:轻松分类和定位特定的聊天,以便快速参考和高效数据收集;
- 模型管理:支持在页面上下载或删除模型;支持导入 GGUF 文件,轻松创建 Ollama 模型或 Modelfile 文件;
- 多模型切换:支持多个模型之间的切换;
- 多模型对话:同时与多个模型进行交流,通过比较获得最佳回应;
- 多模态:支持多模态大模型,可以在聊天中使用图片;
- 聊天记录:轻松访问和管理对话历史,支持导入和导出聊天数据;
- 语音输入支持:通过语音互动与模型进行交流,享受直接与模型对话的便利;
- 图像生成集成:无缝地使用 AUTOMATIC1111 API 和 DALL-E 集成图像生成功能,为聊天体验增添动态视觉内容;
- OpenAI API 集成:轻松地将与 Ollama 模型兼容的 OpenAI API 集成到对话中;
- 国际化(i18n):支持多种不同的语言;
运行如下的 Docker 命令即可安装 Open WebUI:
$ docker run -d -p 3000:8080 \--add-host=host.docker.internal:host-gateway \-v open-webui:/app/backend/data \--name open-webui \--restart always \ghcr.io/open-webui/open-webui:main
安装成功后,浏览器访问 http://localhost:3000/ 即可,首次访问需要注册一个账号:

注册账号并登录后,就可以看到我们熟悉的聊天界面了:

5. 参考链接
https://blog.csdn.net/god_zzZ/article/details/130328307
https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/llama.cpp%E9%87%8F%E5%8C%96%E9%83%A8%E7%BD%B2
https://www.chenshaowen.com/blog/llama-cpp-that-is-a-llm-deployment-tool.html
https://blog.csdn.net/m0_61797126/article/details/140583788
https://www.bilibili.com/read/cv34175051/
https://qwen.readthedocs.io/zh-cn/latest/run_locally/llama.cpp.html
https://blog.csdn.net/qq_38628046/article/details/139006498
https://www.aneasystone.com/archives/2024/04/llama-in-action.html
相关文章:
一文熟悉新版llama.cpp使用并本地部署LLAMA
0. 简介 最近是快到双十一了再给大家上点干货。去年我们写了一个大模型的系列,经过一年,大模型的发展已经日新月异。这一次我们来看一下使用llama.cpp这个项目,其主要解决的是推理过程中的性能问题。主要有两点优化: llama.cpp …...

vue/react做多语言国际化的时候,在语言配置中不同的语言配置不同的字体,动态引入scss里面
如果想直接在vue文件的css里面使用,就可以使用i18n的t函数,注意t外层也有引号: font-size: v-bind("t(style.teamCurModelFontSize)"); 前提是要引入t函数:...

Unity——鼠标点击信息和当前位置获取
文章目录 前言一、应用场景二、实现方法1.获取鼠标在屏幕上的位置2.获取鼠标点击位置的世界坐标3.获取鼠标点击位置的UI元素总结前言 在Unity开发中,有时会需要我们获取一些鼠标的信息用于数据交互或者角色控制。 一、应用场景 交互式UI 按钮点击:检测用户是否点击了UI按钮,…...

vue 2的v-***关键字作用及使用场景
作为一个Vue 2的高级前端程序员,你需要熟悉Vue 2的所有指令(Directives)。以下是Vue 2中的指令及其详细说明: v-text 作用:更新元素的textContent。使用场景:当你需要将数据直接显示在页面上,且…...

Matlab实现鲸鱼优化算法优化随机森林算法模型 (WOA-RF)(附源码)
目录 1.内容介绍 2.部分代码 3.实验结果 4.内容获取 1内容介绍 鲸鱼优化算法(Whale Optimization Algorithm, WOA)是受座头鲸捕食行为启发而提出的一种新型元启发式优化算法。该算法通过模拟座头鲸围绕猎物的螺旋游动和缩小包围圈的方式,在…...

【Android】ubutun 创建Androidstudio桌面快捷方式
此方法不仅适合Androidstudio,其他应用的快捷方式创建同理。 创建桌面快捷方式 进入桌面 cd ~/Desktop创建.desktop文件 touch androidStudio.desktop编辑.desktop文件 [Desktop Entry] TypeApplication Terminalfalse NameAndroid Studio Comment android stu…...

javascript 流程控制,数组【知识点整理】
javascript JS 流程控制条件控制语句循环语句跳转语句:异常处理: JS 数组数组的方法 JS 流程控制 条件控制语句 if 语句:用于在满足特定条件时执行代码块。 if (condition) {// 如果条件为真,则执行代码块 }if…else 语句&#x…...

2.索引:SQL 性能分析详解
SQL性能分析是数据库优化中重要的一环。通过分析SQL的执行频率、慢查询日志、PROFILE工具以及EXPLAIN命令,能够帮助我们识别出数据库性能的瓶颈,并做出有效的优化措施。以下将详细讲解这几种常见的SQL性能分析工具和方法。 一、SQL 执行频率 SQL执行频率…...

Flink SQL
进入 JobManager 容器: docker exec -it 21442d9ca797 /bin/bash 启动 Flink 的 SQL 客户端: /opt/flink/bin/sql-client.sh embedded 尝试创建 Kafka 表: 在启动的 SQL 客户端中,尝试创建一个 Kafka 表,看看是否能…...

鸿蒙UI开发——实现环形文字
1、背 景 有朋友提问:您好关于鸿蒙UI想咨询一个问题 如果我想实现展示环形文字是需要通过在Text组件中设置transition来实现么,还是需要通过其他方式来实现。 针对这位粉丝朋友的提问,我们做一下解答。 2、实现环形文字效果 ❓ 什么是环形…...

QT版发送邮件程序
简单的TCP邮箱程序 **教学与实践目的:**学会网络邮件发送的程序设计技术。 1.SMTP协议 邮件传输协议包括 SMTP(简单邮件传输协议,RFC821)及其扩充协议 MIME; 邮件接收协议包括 POP3 和功能更强大的 IMAP 协议。 服务…...

JavaSE:初识Java(学习笔记)
java是高级语言的面向对象语言 .[最贴近生活.最快速分析和设计程序] 一,计算机语言发展历史 二,Java体系结构 1,JavaSE(Java Standard Edition) 标准版,定位在个人计算机上的应用 这个版本是Jav…...

ClickHouse创建分布式表
ClickHouse创建分布式表 当数据量剧增的时候,clickhouse是采用分片的方式进行数据的存储的,类似于redis集群的实现方式。然后想进行统一的查询的时候,因为涉及到多个本地表,可以通过分布式表的方式来提供统一的入口。由于是涉及到…...

Flink转换算子
Apache Flink 是一个用于处理无界和有界数据的开源流处理框架。在 Flink 中,转换(Transformation)是数据流处理的核心组件之一,它们定义了如何从输入数据集生成输出数据集。以下是 Flink 中一些常见的转换算子: Map: 将…...

ThinkBook 14+ 2024 Ubuntu 触控板失效 驱动缺失问题解决
首先我的电脑是thinkbook14 2024,从ubuntu18到ubuntu24,笔者整个都试了一遍,触摸板都没反应,确认不是linux系统内核问题,原因为驱动缺失。 解决步骤: (1)下载驱动,网址如…...
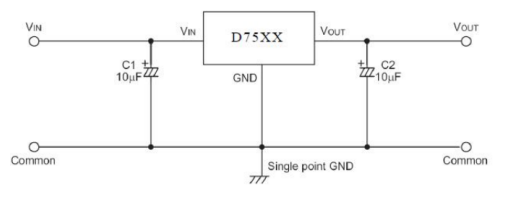
【青牛科技】应用方案 | D75xx-150mA三端稳压器
概 述 D75XX系列是一套三端高电流低压稳压器。它们可以提供 150mA 的输出电流和允许输入电压高达30V。它们有几个固定的输出电压范围为3.0 V至5.0 V。CMOS 技术确保低电压降和低静态电流。 虽然这些设备主要设计为固定电压调节器,但它们可以与外部元件一起使用&…...

WPF之iconfont(字体图标)使用
1,前文: WPF的Xaml是与前端的Html有着高度相似性的标记语言,所以Xaml也可同Html一般轻松使用阿里提供的海量字体图标,从而有效的减少开发工作度。 2,下载字体图标: 登录阿里图标库网iconfont-阿里巴巴矢量…...

08、Java学习-面向对象中级:
Java学习第十二天——面向对象中级: IDEA: 创建完新项目后,再src里面创建.java文件进行编写。 src——存放源码文件(.java文件);out——存放编译后的字节码文件(.class文件) 在I…...
)
springboot集成onlyoffice(部署+开发)
前言 最近有个项目需求是实现前端页面可以对word文档进行编辑,并且可以进行保存,于是一顿搜索,找到开源第三方onlyoffice,实际上onlyOffice有很多功能,例如文档转化、多人协同编辑文档、文档打印等,我们只用…...
--数据类型)
LabVIEW编程基础教学(二)--数据类型
在LabVIEW中,数据类型是非常重要的基本概念,因为它们决定了如何存储和操作数据。掌握这些基础数据类型对于编写有效的程序非常关键。以下是LabVIEW中的基础数据类型介绍: 1. 数值类型(Numeric) 整型(Inte…...

MiniCPM-o-4.5-nvidia-FlagOS部署运维:使用Docker Compose管理多服务依赖
MiniCPM-o-4.5-nvidia-FlagOS部署运维:使用Docker Compose管理多服务依赖 你是不是也遇到过这种情况?想部署一个AI模型,发现它依赖一堆东西:模型服务本身、数据库、缓存、可能还有别的辅助工具。一个个手动去装、去配置、去启动&…...

OpenRouter最新免费额度调整:如何用微信支付宝充值解锁1000次/天API调用
OpenRouter API调用新规解析:微信支付宝充值实战指南 最近OpenRouter平台对免费API调用额度进行了重要调整,这一变化直接影响着国内开发者和AI爱好者的日常使用体验。作为聚合了300多个主流AI模型的统一接口平台,OpenRouter一直以友好的免费政…...

Phi-3-mini-4k-instruct-gguf实操手册:短问答/改写/摘要三大高频场景落地
Phi-3-mini-4k-instruct-gguf实操手册:短问答/改写/摘要三大高频场景落地 1. 模型简介与核心能力 Phi-3-mini-4k-instruct-gguf是微软推出的轻量级文本生成模型,基于Phi-3系列优化而来。这个GGUF版本特别适合处理短文本任务,具有以下特点&a…...

如何用baidupankey解决百度网盘提取码获取难题
如何用baidupankey解决百度网盘提取码获取难题 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 引言:被提取码困住的日常 "又要找提取码?"小张盯着电脑屏幕上的百度网盘分享链接,…...

霜儿-汉服-造相Z-Turbo模型推理优化:理解与避免神经网络中的耦合过度
霜儿-汉服-造相Z-Turbo模型推理优化:理解与避免神经网络中的耦合过度 不知道你有没有遇到过这种情况:想让AI画一个穿汉服的女孩,结果出来的图,发型和衣服总是一起“跑偏”。比如,你想生成一个“唐代齐胸襦裙”的造型&…...

Magisk完整实践指南:从Root权限获取到系统级定制
Magisk完整实践指南:从Root权限获取到系统级定制 【免费下载链接】Magisk The Magic Mask for Android 项目地址: https://gitcode.com/GitHub_Trending/ma/Magisk Magisk作为Android系统Root权限管理的主流解决方案,提供了系统级定制能力而无需修…...

突破限速:8大网盘直链解析方案全解析
突破限速:8大网盘直链解析方案全解析 【免费下载链接】Online-disk-direct-link-download-assistant 可以获取网盘文件真实下载地址。基于【网盘直链下载助手】修改(改自6.1.4版本) ,自用,去推广,无需输入“…...

代码生成神器实测:Yi-Coder-1.5B在Ollama上的真实体验与效果
代码生成神器实测:Yi-Coder-1.5B在Ollama上的真实体验与效果 1. 开箱体验:Yi-Coder-1.5B初印象 1.1 为什么选择Yi-Coder-1.5B 作为一名经常需要编写各种编程语言的开发者,我一直在寻找一个既轻量又强大的代码生成工具。Yi-Coder-1.5B以其1…...
)
收藏!程序员转型AI大模型应用开发,必学四大核心技能(小白友好版)
当下AI大模型风口持续爆发,越来越多程序员想抓住机遇转型入局,但大多陷入“盲目跟风、无从下手、学了没用”的困境——其实,转型AI大模型应用开发无需急于求成,不用追求“面面俱到”,先吃透核心技能,搭建完…...

嵌入式开发五大常见Bug解析与解决方案
1. 嵌入式开发中的五大常见Bug根源解析在嵌入式系统开发领域,代码质量直接关系到产品的可靠性和稳定性。作为一名经历过多个嵌入式项目的开发者,我深刻体会到某些类型的bug特别顽固且难以排查。这些bug往往在实验室测试中难以复现,却在现场运…...