Spark中的shuffle
Shuffle的本质基于磁盘划分来解决分布式大数据量的全局分组、全局排序、重新分区【增大】的问题。
1、Spark的Shuffle设计
Spark Shuffle过程也叫作宽依赖过程,Spark不完全依赖于内存计算,面临以上问题时,也需要Shuffle过程。
2、Spark中哪些算子会产生Shuffle?
只要这个算子包含以下四个功能之一:必须经过Shuffle
进行join:join、fullOuterJoin、 leftOuterJoin 、rightOuterJoin
大数据量全局分组:reduceByKey、groupByKey
大数据量全局排序:sortBy、sortByKey
大数据量增大分区:repartition、coalesce
3、Spark中有哪些shuffle【分类的】?
Spark 0.8及以前 Hash Based Shuffle
Spark 0.8.1 为 Hash Based Shuffle 引入 File Consolidation 机制
Spark 1.1 引入 Sort Based Shuffle ,但默认仍为 Hash Based Shuffle
Spark 1.2 默认的 Shuffle 方式改为 Sort Based Shuffle
Spark 1.4 引入 Tungsten-Sort Based Shuffle 直接使用堆外内存和新的内存管理模型,节省了内存空间和大量的gc,提升了性能
Spark 1.6 Tungsten-sort 并入 Sort Based Shuffle
Spark 2.0 Hash Based Shuffle 退出历史舞台
1)Hash Based Shuffle
特点:没有排序,只分区,每个Task按照ReduceTask个数生成多个文件【M * R】
优点:简单,数据量比较小,性能就比较高
缺点:小文件非常多,数据量比较大性能非常差

2) Hash Based Shuffle 【优化后的,File Consolidation机制

3) Sort Based Shuffle [目前最新的]
Shuffle Write + Shuffle Read
Shuffle Write:类似于MR中的Map端Shuffle,但是Spark的 Shuffle Write 有3种,会根据情况自动判断选择哪种Shuffle Write
Shuffle Read:类似于MR中的Reduce端Shuffle,但是 Spark的 Shuffle Read 功能由算子来决定,不同算子经过的过程不一样的。
MR Shuffle可以参考MapReduce 的 Shuffle 过程-CSDN博客
4、Spark 2以后的Shuffle Write判断机制:
第一种:SortShuffleWriter:普通Sort Shuffle Write机制
排序,生成一个整体基于分区和分区内部有序的文件和一个索引文件
大多数场景:数据量比较大场景 与MR的Map端Shuffle基本一致
特点:有排序,先生成多个有序小文件,再生成整体有序大文件,每个Task生成2个文件,数据文件和索引文件
Sort Shuffle Write过程与MapReduce的Map端shuffle基本一致

第二种:BypassMergeSortShuffleWriter
类似于优化后的Hash Based Shuffle,先为每个分区生成一个文件,最后合并为一个大文件,分区内部不排序
条件:分区数小于200,并且Map端没有聚合操作
场景:数据量小
跟第一个相比,处理的数据量小,处理的分区数小于200 ,不在内存中排序。
第三种:UnsafeShuffleWriter
钨丝计划方案,使用UnSafe API操作序列化数据,使用压缩指针存储元数据,溢写合并使用fastMerge提升效率
条件:Map端没有聚合操作、序列化方式需要支持重定位,Partition个数不能超过2^24-1个
在什么情况下使用什么ShuffleWriter 呢?

ShuffleWriter的实现方式有三种:
BypassMergeSortShuffleWriter
使用这种shuffle writer的条件是:
(1) 没有map端的聚合操作
(2) 分区数小于参数:spark.shuffle.sort.bypassMergeThreshold,默认是200
UnsafeShuffleWriter
使用这种shuffle writer的条件是:
(1) 序列化工具类支持对象的重定位
(2) 不需要在map端进行聚合操作
(3) 分区数不能大于:PackedRecordPointer.MAXIMUM_PARTITION_ID + 1
SortShuffleWriter
若以上两种shuffle writer都不能选择,则使用该shuffle writer类。
这也是相对比较常用的一种shuffle writer。
5、 Shuffle Read:类似于MapReduce中的Reduce端shuffle
MR:Reduce端的shuffle过程一定会经过合并排序、分组
需求:统计每个单词出现的次数,不需要排序,依旧会给结果进行排序
Spark:Shuffle Read具体的功能由算子来决定,不同的算子在经过shuffle时功能不一样
reduceByKey:Shuffle Read:只分组聚合,不排序
sortByKey:Shuffle Read:只排序,不分组
repartition:Shuffle Read:不排序,不分组
相关文章:
Spark中的shuffle
Shuffle的本质基于磁盘划分来解决分布式大数据量的全局分组、全局排序、重新分区【增大】的问题。 1、Spark的Shuffle设计 Spark Shuffle过程也叫作宽依赖过程,Spark不完全依赖于内存计算,面临以上问题时,也需要Shuffle过程。 2、Spark中哪…...
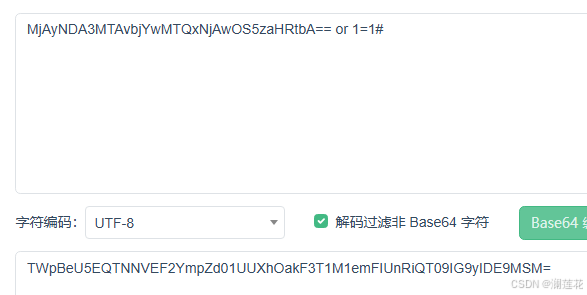
网络安全SQL初步注入2
六.报错注入 mysql函数 updatexml(1,xpath语法,0) xpath语法常用concat拼接 例如: concat(07e,(查询语句),07e) select table_name from information_schema.tables limit 0,1 七.宽字节注入(如果后台数据库的编码为GBK) url编码:为了防止提交的数据和url中的一些有特殊意…...
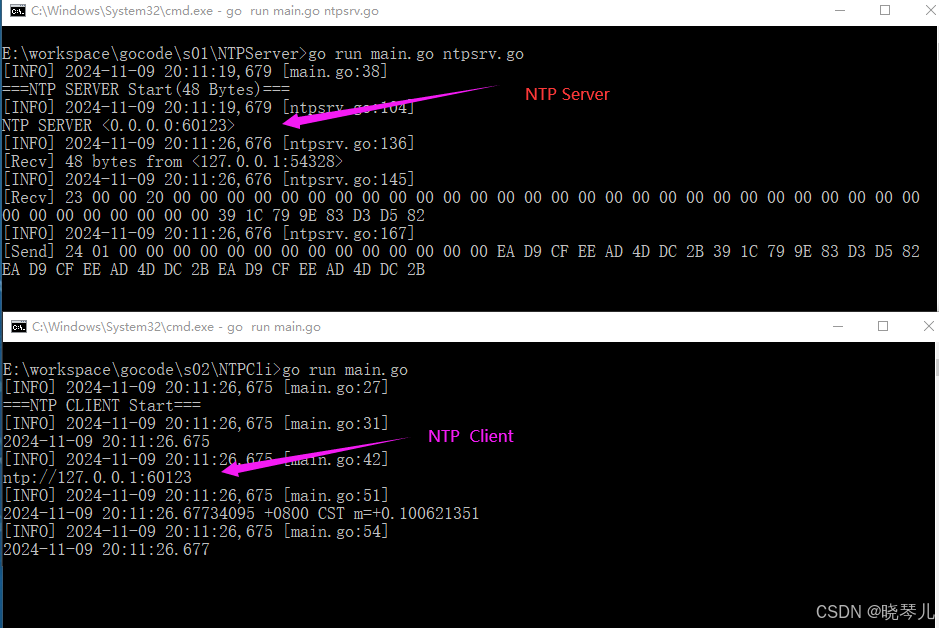
使用Go语言编写一个简单的NTP服务器
NTP服务介绍 NTP服务器【Network Time Protocol(NTP)】是用来使计算机时间同步化的一种协议。 应用场景说明 为了确保封闭局域网内多个服务器的时间同步,我们计划部署一个网络时间同步服务器(NTP服务器)。这一角色将…...

注意力机制篇 | YOLO11改进 | 即插即用的高效多尺度注意力模块EMA
前言:Hello大家好,我是小哥谈。与传统的注意力机制相比,多尺度注意力机制引入了多个尺度的注意力权重,让模型能够更好地理解和处理复杂数据。这种机制通过在不同尺度上捕捉输入数据的特征,让模型同时关注局部细节和全局…...
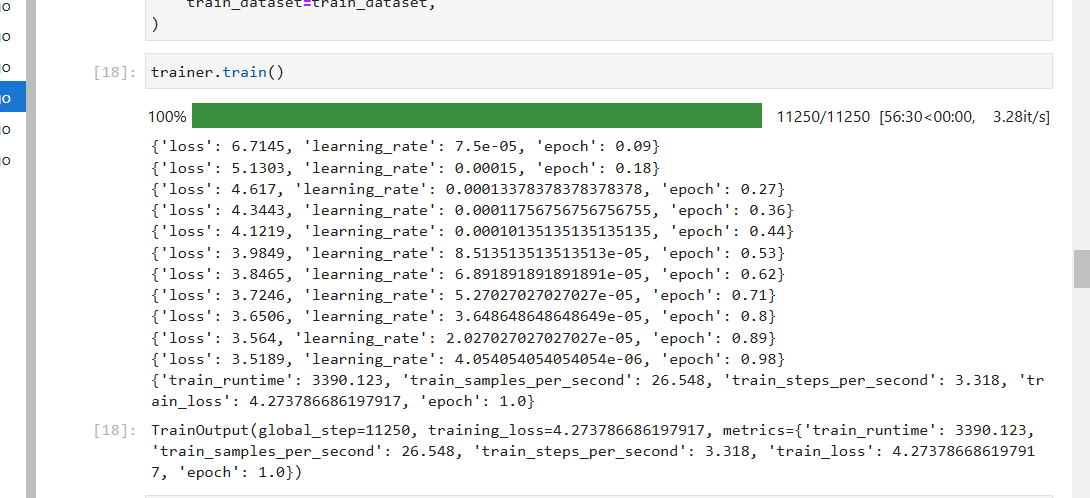
昇思大模型平台打卡体验活动:项目3基于MindSpore的GPT2文本摘要
昇思大模型平台打卡体验活动:项目3基于MindSpore的GPT2文本摘要 1. 环境设置 本项目可以沿用前两个项目的相关环境设置。首先,登陆昇思大模型平台,并进入对应的开发环境: https://xihe.mindspore.cn/my/clouddev 接着࿰…...
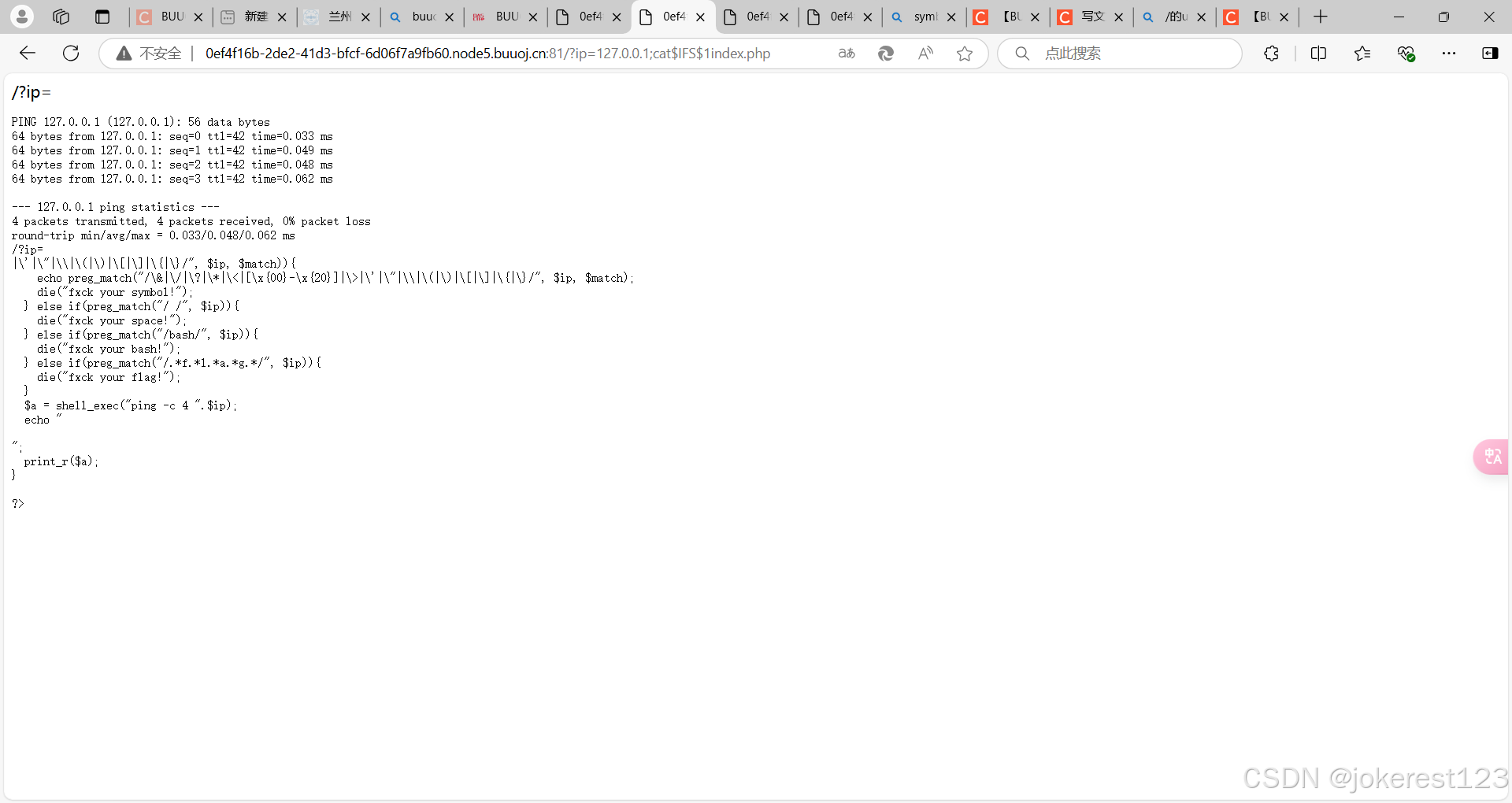
web——[GXYCTF2019]Ping Ping Ping1——过滤和绕过
0x00 考点 0、命令联合执行 ; 前面的执行完执行后面的 | 管道符,上一条命令的输出,作为下一条命令的参数(显示后面的执行结果) || 当前面的执行出错时(为假)执行后面的 & 将任…...

婚礼纪 9.5.57 | 解锁plus权益的全能结婚助手,一键生成结婚请柬
婚礼纪是一款结婚服务全能助手,深受9000万新人信赖的一站式结婚服务平台。解锁plus权益后,用户可以享受部分VIP会员功能。应用提供了丰富的结婚筹备工具和服务,包括一键生成结婚请柬、婚礼策划、婚纱摄影、婚宴预订等。婚礼纪旨在为新人提供全…...

M1M2 MAC安装windows11 虚拟机的全过程
M1/M2 MAC安装windows11 虚拟机的全过程 这两天折腾了一下windows11 arm架构的虚拟机,将途中遇到的坑总结一下。 1、虚拟机软件:vmware fusion 13.6 或者 parallel 19 ? 结论是:用parellel 19。 这两个软件都安装过࿰…...

监控架构-Prometheus-普罗米修斯
目录 1. Prometheus概述 2. Prometheus vs Zabbix 3. Prometheus极速上手指南 3.1 时间同步 3.2 部署Prometheus 3.3 启动Prometheus 3.4 Prometheus监控架构 3.5 补充 配置页面 简单过滤 查看数据 查看图形 http://prometheus.oldboylinux.cn:9090/metrics显示…...

Kylin Server V10 下自动安装并配置Kafka
Kafka是一个分布式的、分区的、多副本的消息发布-订阅系统,它提供了类似于JMS的特性,但在设计上完全不同,它具有消息持久化、高吞吐、分布式、多客户端支持、实时等特性,适用于离线和在线的消息消费,如常规的消息收集、…...

windows环境下cmd窗口打开就进入到对应目录,一般人都不知道~
前言 很久以前,我还在上一家公司的时候,有一次我看到我同事打开cmd窗口的方式,瞬间把我惊呆了。原来他打开cmd窗口的方式,不是一般的在开始里面输入cmd,然后打开cmd窗口。而是另外一种方式。 我这个同事是个技术控&a…...

企微SCRM价格解析及其性价比分析
内容概要 在如今的数字化时代,企业对于客户关系管理的需求日益增长,而企微SCRM(Social Customer Relationship Management)作为一款新兴的客户管理工具,正好满足了这一需求。本文旨在为大家深入解析企微SCRM的价格体系…...

【SpringMVC】记录一次Bug——mvc:resources设置静态资源不过滤导致WEB-INF下的资源无法访问
SpringMVC 记录一次bug 其实都是小毛病,但是为了以后再出毛病,记录一下: mvc:resources设置静态资源不过滤问题 SpringMVC中配置的核心Servlet——DispatcherServlet,为了可以拦截到所有的请求(JSP页面除外…...

【React】React 生命周期完全指南
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 React 生命周期完全指南一、生命周期概述二、生命周期的三个阶段2.1 挂载阶段&a…...

【NLP】使用 SpaCy、ollama 创建用于命名实体识别的合成数据集
命名实体识别 (NER) 是自然语言处理 (NLP) 中的一项重要任务,用于自动识别和分类文本中的实体,例如人物、位置、组织等。尽管它很重要,但手动注释大型数据集以进行 NER 既耗时又费钱。受本文 ( https://huggingface.co/blog/synthetic-data-s…...

【C++练习】二进制到十进制的转换器
题目:二进制到十进制的转换器 描述 编写一个程序,将用户输入的8位二进制数转换成对应的十进制数并输出。如果用户输入的二进制数不是8位,则程序应提示用户输入无效,并终止运行。 要求 程序应首先提示用户输入一个8位二进制数。…...

Vue功能菜单的异步加载、动态渲染
实际的Vue应用中,常常需要提供功能菜单,例如:文件下载、用户注册、数据采集、信息查询等等。每个功能菜单项,对应某个.vue组件。下面的代码,提供了一种独特的异步加载、动态渲染功能菜单的构建方法: <s…...
)
云技术基础学习(一)
内容预览 ≧∀≦ゞ 声明导语云技术历史 云服务概述云服务商与部署模式1. 公有云服务商2. 私有云部署3. 混合云模式 云服务分类1. 基础设施即服务(IaaS)2. 平台即服务(PaaS)3. 软件即服务(SaaS) 云架构云架构…...

【优选算法篇】微位至简,数之恢宏——解构 C++ 位运算中的理与美
文章目录 C 位运算详解:基础题解与思维分析前言第一章:位运算基础应用1.1 判断字符是否唯一(easy)解法(位图的思想)C 代码实现易错点提示时间复杂度和空间复杂度 1.2 丢失的数字(easy࿰…...

MFC工控项目实例二十九主对话框调用子对话框设定参数值
在主对话框调用子对话框设定参数值,使用theApp变量实现。 子对话框各参数变量 CString m_strTypeName; CString m_strBrand; CString m_strRemark; double m_edit_min; double m_edit_max; double m_edit_time2; double …...

STL到STEP格式转换:技术选型与实施指南
STL到STEP格式转换:技术选型与实施指南 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在制造业数字化转型的背景下,3D数据格式互操作性已成为工程团队面临的核心挑战。…...

用Python复现数学建模国赛B题‘穿越沙漠’:手把手教你写最优路径规划算法
用Python复现数学建模国赛B题‘穿越沙漠’:手把手教你写最优路径规划算法 当数学建模问题遇上Python编程,会产生怎样的化学反应?本文将以2020年高教杯数学建模国赛B题"穿越沙漠"为例,带你从零开始构建一个完整的路径规划…...
)
告别手动填坑:用SSC工具+Excel快速搞定LAN9252 EtherCAT从站XML配置(附64点IO实例)
高效配置LAN9252 EtherCAT从站的自动化工具链实践 在嵌入式工业通信领域,EtherCAT因其卓越的实时性能被广泛采用,而LAN9252作为高性价比的从站控制器芯片,配合SPI接口成为许多开发者的首选方案。然而传统XML配置流程的复杂性往往成为项目瓶颈…...

HLS.js技术深度解析:解决浏览器端HLS流媒体播放的工程挑战
HLS.js技术深度解析:解决浏览器端HLS流媒体播放的工程挑战 【免费下载链接】hls.js HLS.js is a JavaScript library that plays HLS in browsers with support for MSE. 项目地址: https://gitcode.com/gh_mirrors/hl/hls.js 在现代Web视频应用中࿰…...

第14章:C++ 代码规范评审
第14章:C++ 代码规范评审 本章定位:第四卷《实战卷》第四篇"工程化与编译链接"第 14 章。 与第 13 章《静态分析工具》构成"机器查 + 人查"互补:能机器查的让 lint 拦,必须人脑判断的进 review。 目录 01.规范与评审定位 1.1 规范的三个层级 1.2 评审解…...
增强代码的层级结构注意事项)
不使用void HAL_TIM_Encoder_MspInit(TIM_HandleTypeDef* tim_encoderHandle)增强代码的层级结构注意事项
这是正常用cube Max生成的代码,这里以设置编码器为例。 GPIO初始化函数放在HAL_TIM_Encoder_MspInit这个回调函数中。代码正常运行/* TIM3 init function */ void MX_TIM3_Init(void) {TIM_Encoder_InitTypeDef sConfig {0};TIM_MasterConfigTypeDef sMasterConfig…...

PromethAI-Backend:构建标准化AI智能体后端框架的工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想搞一个能处理复杂工作流的智能体系统,发现了一个挺有意思的开源项目——PromethAI-Backend。这名字听着就有点“普罗米修斯”盗火种给人类的意思,挺形象的,它本质上就是一个为…...
)
别再死记硬背了!用Python模拟LDPC和Polar码的编码过程(附代码)
Python实战:用可视化方法理解LDPC与Polar码的核心原理 在无线通信系统的物理层设计中,信道编码技术如同数据的"防弹衣",保护信息在充满噪声的传输环境中安全抵达。本文将带你用Python构建两种5G核心编码方案——LDPC码和Polar码的简…...

为什么92%的团队把DeepSeek CQRS配错了?资深SRE曝光3个被文档刻意弱化的配置陷阱
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队把DeepSeek CQRS配错了?资深SRE曝光3个被文档刻意弱化的配置陷阱 陷阱一:事件序列号(Sequence ID)与数据库事务隔离级别的隐式冲突 Deep…...

别再手动对比了!用Beyond Compare 4在Ubuntu上5分钟搞定文件同步与合并
高效文件管理利器:Beyond Compare 4在Ubuntu中的深度应用指南 在当今快节奏的开发与运维工作中,文件比较与同步已成为日常工作中不可或缺的环节。无论是代码合并、配置同步还是日志分析,传统的手动对比方式不仅效率低下,还容易出错…...