dolphin 配置data 从文件导入hive 实践(一)
datax 支持多种数据源的相互读写,作为开源软件,提供了离线采集功能,方便系统开发,过程中遇到诸多配置,需要开发者自己探索,免费同样有成本
配置模板
{"setting": {},"job": {"setting": {"speed": {"channel": 2}},"content": [{"reader": {"name": "txtfilereader","parameter": {"path": ["/data/test/test.txt"],"encoding": "UTF-8","column": [{"index": 0,"type": "string"},{"index": 1,"type": "string"}],"fieldDelimiter": "\t"}},"writer": {"name": "hdfswriter","parameter": {"defaultFS": "hdfs://****:9000","fileType": "TEXT","path": "/user/hive/warehouse/sz_center_devdb.db/cat","fileName": "catfile","column": [{"name": "cat_id","type": "STRING"},{"name": "cat_name","type": "STRING"}],"writeMode": "append","fieldDelimiter": "\t","compress":"NONE"}}}]}
}注意:文本文件需要上传到datax 所在服务器
执行报错一:
Hadoop 权限异常
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=default, access=WRITE, inode="/user/hive/warehouse/sz_center_devdb.db":anonymous:supergroup:drwxr-xr-xat org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:496)at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:336)at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:241)at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1909)at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:1893)at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:1852)at org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp.resolvePathForStartFile(FSDirWriteFileOp.java:323)at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFileInt(FSNamesystem.java:2635)at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startFile(FSNamesystem.java:2577)at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.create(NameNodeRpcServer.java:807)at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.create(ClientNamenodeProtocolServerSideTranslatorPB.java:494)at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)at org.apache.hadoop.ipc.ProtobufRpcEngine2$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine2.java:532)at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1070)at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:1020)at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:948)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:422)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1845)at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2952)at org.apache.hadoop.ipc.Client.call(Client.java:1476)at org.apache.hadoop.ipc.Client.call(Client.java:1407)at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)at com.sun.proxy.$Proxy9.create(Unknown Source)at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.create(ClientNamenodeProtocolTranslatorPB.java:296)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:187)at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)at com.sun.proxy.$Proxy10.create(Unknown Source)at org.apache.hadoop.hdfs.DFSOutputStream.newStreamForCreate(DFSOutputStream.java:1623)... 18 more
这里是因为Hadoop 目录没有权限。
这里执行的用户是default
dataX 模板中没有配置用户的地方,这里先去Hadoop 配置目录权限
Hadoop 目录权限配置
hdfs dfs -ls /
hdfs dfs -mkdir /user
hdfs dfs -mkdir /hbase
hdfs dfs -ls /
hadoop fs -chmod 777 /user
hadoop fs -chmod 777 /hbase
# 循环所有子目录配置权限
hadoop fs -chmod -R 777 /hbase
然后运行dataX 任务成功。
但从hive 链接中发现数据乱码,这里就是 hive的文件类型和分隔符不一致导致

这里回顾日志发现读取文本异常
[WI-0][TI-0] - [INFO] 2024-11-06 16:16:36.229 +0800 o.a.d.p.t.a.AbstractTask:[169] - -> 2024-11-06 16:16:35.230 [0-0-0-reader] INFO TxtFileReader$Task - reading file : [/data/test/test.txt]2024-11-06 16:16:35.231 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started2024-11-06 16:16:35.268 [0-0-0-writer] INFO HdfsWriter$Task - begin do write...2024-11-06 16:16:35.268 [0-0-0-writer] INFO HdfsWriter$Task - write to file : [hdfs://10.80.18.165:9000/user/hive/warehouse/sz_center_devdb.db/cat__f395492b_e42a_47e5_a52b_214ab8bf833a/catfile__d369974c_fdeb_4601_b118_67ae6e97e197]2024-11-06 16:16:35.341 [0-0-0-reader] INFO UnstructuredStorageReaderUtil - CsvReader使用默认值[{"captureRawRecord":true,"columnCount":0,"comment":"#","currentRecord":-1,"delimiter":"\t","escapeMode":1,"headerCount":0,"rawRecord":"","recordDelimiter":"\u0000","safetySwitch":false,"skipEmptyRecords":true,"textQualifier":"\"","trimWhitespace":true,"useComments":false,"useTextQualifier":true,"values":[]}],csvReaderConfig值为[null]2024-11-06 16:16:35.351 [0-0-0-reader] WARN UnstructuredStorageReaderUtil - 您尝试读取的列越界,源文件该行有 [1] 列,您尝试读取第 [2] 列, 数据详情[1 hello]2024-11-06 16:16:35.356 [0-0-0-reader] ERROR StdoutPluginCollector - 脏数据: {"message":"您尝试读取的列越界,源文件该行有 [1] 列,您尝试读取第 [2] 列, 数据详情[1 hello]","record":[{"byteSize":7,"index":0,"rawData":"1 hello","type":"STRING"}],"type":"reader"}2024-11-06 16:16:35.357 [0-0-0-reader] WARN UnstructuredStorageReaderUtil - 您尝试读取的列越界,源文件该行有 [1] 列,您尝试读取第 [2] 列, 数据详情[2 cat]2024-11-06 16:16:35.357 [0-0-0-reader] ERROR StdoutPluginCollector - 脏数据: {"message":"您尝试读取的列越界,源文件该行有 [1] 列,您尝试读取第 [2] 列, 数据详情[2 cat]","record":[{"byteSize":5,"index":0,"rawData":"2 cat","type":"STRING"}],"type":"reader"}2024-11-06 16:16:35.793 [0-0-0-writer] INFO HdfsWriter$Task - end do write2024-11-06 16:16:35.841 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[623]ms2024-11-06 16:16:35.841 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
[WI-0][TI-0] - [INFO] 2024-11-06 16:16:45.231 +0800 o.a.d.p.t.a.AbstractTask:[169] - -> 2024-11-06 16:16:45.222 [job-0] INFO StandAloneJobContainerCommunicator - Total 2 records, 12 bytes | Speed 1B/s, 0 records/s | Error 2 records, 12 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%2024-11-06 16:16:45.222 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.2024-11-06 16:16:45.223 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do post work.2024-11-06 16:16:45.224 [job-0] INFO HdfsWriter$Job - start rename file [hdfs://10.80.18.165:9000/user/hive/warehouse/sz_center_devdb.db/cat__f395492b_e42a_47e5_a52b_214ab8bf833a/catfile__d369974c_fdeb_4601_b118_67ae6e97e197] to file [hdfs://10.80.18.165:9000/user/hive/warehouse/sz_center_devdb.db/cat/catfile__d369974c_fdeb_4601_b118_67ae6e97e197].
[WI-0][TI-0] - [INFO] 2024-11-06 16:16:46.231 +0800 o.a.d.p.t.a.AbstractTask:[169] - ->
暂时不确定是源文件格式问题 还是编码问题
或者是任务配置问题。
后续出结果后更新。
执行异常二

数据为空,或者数据列不对应。
这种情况执行日志没有任何异常,执行结果也是成功,但是目标的hive 表里没有数据。
这时候就看hive的分隔符配置了。
如何查看hive表的分隔符
执行命令
show create table hello
查看

‘org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe’ # 默认分隔符,行分割符:“\n”,列分割符:“^A”
这个在data JSON 中还不能直接配置,必须使用转义字符
默认存储格式textfile
JSON 里配置 TEXT
参考资料:https://blog.csdn.net/mn525520/article/details/106876384
https://blog.csdn.net/u010520724/article/details/121999575
https://blog.csdn.net/qq_36039236/article/details/108101345
生效hive 建表语句、dataX json 任务配置参见
配置示例:www.fancv.com
相关文章:
dolphin 配置data 从文件导入hive 实践(一)
datax 支持多种数据源的相互读写,作为开源软件,提供了离线采集功能,方便系统开发,过程中遇到诸多配置,需要开发者自己探索,免费同样有成本 配置模板 {"setting": {},"job": {"s…...
)
Docker Compose部署Rabbitmq(脚本下载延迟插件)
整个工具的代码都在Gitee或者Github地址内 gitee:solomon-parent: 这个项目主要是总结了工作上遇到的问题以及学习一些框架用于整合例如:rabbitMq、reids、Mqtt、S3协议的文件服务器、mongodb github:GitHub - ZeroNing/solomon-parent: 这个项目主要是…...

麦当劳自助点餐机——实现
餐厅自助点餐优点 1. 降低服务成本: - 减少了对服务员数量的需求,降低了人力成本。 - 减轻了服务员的工作负担,使其能够更专注于提供优质的服务,如解决顾客的特殊需求和处理复杂问题。 2. 提升点餐效率和准确性…...

C++ STL CookBook 6:STL Containers (I)
目录 顺序容器 关联容器 容器适配器 使用统一擦除函数从容器中删除指定项 在恒定时间内对一个对排序不敏感的vector中删除项目 如果不确定自己访问容器会不会越界,那就使用.at方法而不是[] 在我们开始之前,先来回顾一下传统的经典的几个容器&#…...

行转列实现方式总结
前言 在日常开发中遇到了,需要对表中数据某个字段行数据转成列,个人觉得这中做目前想到两种, 一种是sql 操作, 另一种代码中做逻辑处理。 方式一 Java 操作 import lombok.Data;import java.util.ArrayList; import java.util.H…...

【go从零单排】初探goroutine
🌈Don’t worry , just coding! 内耗与overthinking只会削弱你的精力,虚度你的光阴,每天迈出一小步,回头时发现已经走了很远。 📗概念 Goroutines 是 Go 语言中的一种轻量级线程,用于并发编程。它们允许程…...

HarmonyOS NEXT应用元服务开发Intents Kit(意图框架服务)本地搜索接入方案
一、方案概述 当用户使用应用/元服务时,开发者可以按照标准意图Schema向系统共享数据,并支持意图调用(空调用与传参调用),以实现用户点击卡片后,可后台执行功能(例如播放指定歌曲)或…...

C语言可变参数列表编程实战指南:从基础概念到高级应用的全面解析
引言 在C语言中,可变参数列表的功能使得函数能够灵活地处理不确定数量的输入参数。本文将深入探讨可变参数列表的基础概念、技术原理及其在实际编程中的应用,帮助开发者更好地理解和使用这一特性。 一、可变参数列表的基本概念 1.1 什么是可变参数列表…...

AndroidStudio-文本显示
一、设置文本的内容 1.方式: (1)在XML文件中通过属性:android:text设置文本 例如: <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas.andr…...
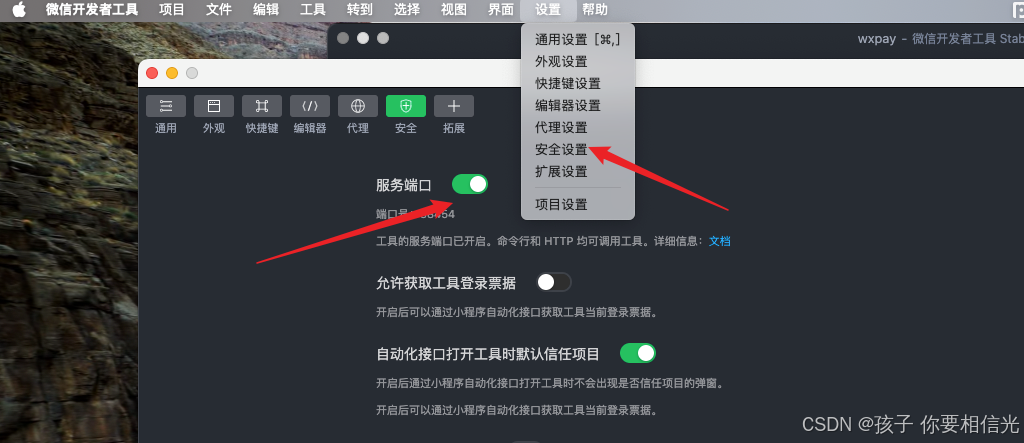
HBuilderX运行微信小程序,编译的文件在哪,怎么运行
1. 点击HBuilderX顶部的运行-运行到小程序模拟器-微信开发者工具,就会开始编译 2. 编译完成后的文件在根目录找到 unpackage -- dist -- dev -- mp-weixin, 这里面就是编译后的文件,如果未跳转到开发者工具,那可能是没设置启动路径࿰…...

百亿AI数字人社会初现:Project Sid展示智能代理文明进化路径
项目背景 Project Sid 是一项开创性的AI代理人文明实验,旨在通过新开发的认知架构 PIANO 探讨AI代理人是否能够在大规模数字社会中实现文明的演进。这项实验不仅展示了社会进步、角色分化、治理体系及文化传播等特征,还揭示了一个包含百亿“数字人类”的社会可能性。 PIANO…...

代码随想录训练营Day21 | 491.递增子序列 - 46.全排列 - 47.全排列 II - 332.重新安排行程 - 51.N皇后 - 37.解数独
491.递增子序列 题目链接:491.递增子序列思路:和子集那道题思路很像,每次在数组中选择一个数,选过的数不能选择,这里要求集合数量必须大于2个才能符合,仍然需要去重,但这里选额的是子序列&…...

多用户商城系统的功能及设计和开发
多用户商城系统的功能及设计与开发(基于 PHP MySQL) 在现代电子商务平台的开发中,PHP MySQL 是一对非常流行且高效的技术栈。PHP作为服务器端脚本语言,结合MySQL数据库,可以高效地处理多用户商城系统的各种需求。本…...

2024年11月8日day8
半加器和全加器的区别 半加器:只能处理两个二进制位的相加,无法处理进位。全加器:不仅能处理两个二进制位的相加,还能处理来自低位的进位。 ⑴ 完成满足754标准存储格式的浮点数((43940000)16的十进制数值)…...

Debezium系列之:Debezium3版本增量快照和只读增量快照应用的变化
Debezium系列之:Debezium3版本增量快照和只读增量快照应用的变化 一、需求背景二、基于数据库信号表使用增量快照案例三、基于Kafka信号Topic使用增量快照案例四、只读增量快照案例五、增量快照技术总结增量快照相关知识请阅读博主下面系列文章: Debezium系列之:实现增量快照…...

Python正则表达式1 re.match惰性匹配详解案例
点个关注 re.match() re.match() 函数尝试从字符串的开头开始匹配一个模式,如果匹配成功,返回一个匹配成功的对象,否则返回None。大小写区分,内容匹配不到后面的,只能匹配一个,不能有空格(开头匹配&#…...
学习日志10:Prism框架下按键绑定)
WPF(C#)学习日志10:Prism框架下按键绑定
在Prism框架下,提供了DelegateCommand类用于处理了UI的按键请求,XAML中可以直接采用 Command"{Binding **}" 来绑定这些方法。这个类是一个泛型的类生命时仅需要DelegateCommand<T>即可,同时在XAML中绑定CommandParameter&qu…...

WPF中的ResizeMode
在 WPF (Windows Presentation Foundation) 中,ResizeMode 属性用于指定窗口是否可以被用户调整大小,以及如何调整大小。ResizeMode 属性可以设置为以下几个值之一: NoResize:窗口不能被用户调整大小,但可以被程序代码…...

Unity3D UI 双击和长按
Unity3D 实现 UI 元素双击和长按功能。 UI 双击和长按 上一篇文章实现了拖拽接口,这篇文章来实现 UI 的双击和长按。 双击 创建脚本 UIDoubleClick.cs,创建一个 Image,并把脚本挂载到它身上。 在脚本中,继承 IPointerClickHa…...
LabVIEW扫描探针显微镜系统
开发了一套基于LabVIEW软件开发的扫描探针显微镜系统。该系统专为微观尺度材料的热性能测量而设计,特别适用于纳米材料如石墨烯、碳纳米管等的研究。系统通过LabVIEW编程实现高精度的表面形貌和热性能测量,广泛应用于科研和工业领域。 项目背景 随着纳…...
)
【限时解禁】Google I/O 2024未发布的Gemini Android Enterprise Integration白皮书核心章节(仅剩37份授权访问码)
更多请点击: https://intelliparadigm.com 第一章:Gemini Android深度整合的战略定位与演进脉络 Google 将 Gemini 模型深度嵌入 Android 生态,并非单纯叠加 AI 功能,而是重构操作系统级智能代理的交互范式。其战略内核在于将大模…...
)
科研绘图升级:用CMplot为你的基因组文章制作高颜值SNP密度图(R实战)
科研绘图升级:用CMplot为你的基因组文章制作高颜值SNP密度图(R实战) 在基因组学研究中,数据可视化不仅是结果展示的手段,更是科学叙事的重要语言。一张精心设计的SNP密度图,能够直观呈现全基因组范围内单核…...
 微服务测试策略-单元到集成到契约到端到端分层实战)
自动化测试(十) 微服务测试策略-单元到集成到契约到端到端分层实战
微服务测试策略:单元→集成→契约→端到端分层实战前面咱们分别聊了单元测试、接口测试、契约测试。今天把它们串起来,聊聊微服务架构下怎么设计完整的测试策略——每一层测什么、怎么测、用什么工具。一、微服务测试的"金字塔"变体 单体应用的…...

Axure中文汉化终极指南:3分钟搞定英文界面,让原型设计更顺手
Axure中文汉化终极指南:3分钟搞定英文界面,让原型设计更顺手 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn …...

多视角时空对齐 + 跨镜轨迹融合:镜像视界打造无断点跟踪闭环
多视角时空对齐 跨镜轨迹融合:镜像视界打造无断点跟踪闭环在工业安防、智慧仓储、园区管控等全域场景智能化升级进程中,目标跟踪的连续性、精准性、全域性,始终是衡量管控体系效能的核心指标,也是传统视频监控技术难以逾越的行业…...

终极网盘直链下载助手完整指南:快速免费获取8大网盘真实下载地址
终极网盘直链下载助手完整指南:快速免费获取8大网盘真实下载地址 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云…...

[HFSS] 从零到一:Floquet Port与主从边界在波导阵列建模中的实战解析
1. 初识Floquet Port与主从边界 第一次接触HFSS的周期性结构仿真时,我被Floquet Port和主从边界这两个概念搞得一头雾水。直到实际建模了一个波导阵列天线,才真正理解它们的妙用。简单来说,Floquet Port是专门为周期性结构设计的特殊端口&…...

让你的自定义结构体也能被qDebug优雅打印:Qt运算符重载的妙用与避坑指南
让自定义结构体与qDebug完美融合:Qt运算符重载实战解析 在Qt开发中,调试信息输出是日常开发不可或缺的环节。当项目规模扩大,自定义数据结构变得复杂时,如何优雅地输出这些结构体的调试信息就成了开发者面临的现实挑战。本文将深入…...

03-从Chat到Act-Agent行动闭环的产品心理学拆解
从Chat到Act:Agent行动闭环的产品心理学拆解系列一:AI Agent GAP模型 | 第3篇(深度型) 从"一问一答"到"自主行动",拆解Agent行动闭环背后的行为设计逻辑。本文你将获得 🔄 Agent行动闭…...

如何做变量操作化:从抽象概念到测量指标
一、理解变量:科研的基石在深入操作化之前,我们首先要明确“变量”在定量研究中的定义。变量(Variable)指的是个体或组织的特征或属性,这些特征可以被研究者测量或观察,并且在不同个体或组织之间存在差异。…...