pytorch实现深度神经网络DNN与卷积神经网络CNN
DNN概述
深度神经网络DNN来自人脑神经元工作的原理,通过在计算机中逻辑抽象出多个节点,接收处理并向后传递信息,实现计算机的自我学习,类比结构见下图:

该方法通过预测输出与实际值的差异不断调整节点参数,从而一步步调整整体预测效果,节点预测输出的过程称为前向传播,根据差异调整参数的过程称为反向传播,而又因为节点计算公式y=wx+b为线性的,如果每个节点都向后传递该值,那最终的输出也可以表示为wx+b,故要体现每个节点的特殊性,需要引入非线性处理,即激活函数,根据在该过程中对学习率步长的设置调整、更新参数依靠样本的选择等区别,产生了多种不同的优化算法。
一般的机器学习流程如下图:

DNN网络训练
首先导入一般需要的包
import torch.nn as nn
import torch
import pandas as pd
import numpy as np
所有参数和模型的文档都可以在官网查看,查找前记得在选项中选择自己使用pytorch的版本:

数据集导入
大致流程为:
1,使用pandas从文件中读取数据
2,将带标签的数据退化为数组,并转换类型
3,将数组转换为张量
4,数据搬到显卡上进行加速
代码分别如下:
df=pd.read_csv("文件路径")
arr=df.values.astype(np.float32)
ts=torch.tensor(arr)
ts=ts.to('cuda')
划分训练集与测试集
首先根据比例划分训练集与测试集大小,为了避免数据前后关联,最好打乱样本的顺序,然后分别按行读取样本到数据集集合中,代码如下:
tran_size=int(len(ts)*0.8) # 训练集大小,0.8为比例系数
test_size=len(ts)-tran_size # 测试集大小
ts=ts[torch.randperm(ts.size(0)),:] # 打乱数据
train_data=ts[:tran_size] # 训练集数据
test_data=ts[tran_size:] # 测试集数据
搭建网络
根据输入和输出特征搭建网络,需注意相邻网络的输入输出需对应,网络需继承nn.Module模块,继承后重写网络模型到初始化函数中,定义向前传播forward调用网络并返回预测,示例代码如下:
class DNN(nn.Module):def __init__(self):super(DNN, self).__init__() # 初始化父类self.network = nn.Sequential(nn.Linear(28*28, 512), # 第一层线性层nn.ReLU(), # 第一层激活函数nn.Linear(512, 1024), # 第二层线性层nn.Sigmoid(), # 第二层激活函数)def forward(self, x):x = self.network(x) # 第三层无激活函数return xDNN=DNN() # 创建网络对象实例
优化器算法
首先定义损失函数loss_fn,具体的选项见官方文档,然后设置学习速率learning_rate和optimizer优化器,通过torch.optim设置优化算法,示例代码如下:
loss_fn=nn.MSELoss()
learning_rate=0.001
optimizer=torch.optim.Adam(DNN.parameters(), lr=learning_rate)
训练网络
网络的训练往往要经过多次循环,所以通常先设置一个epochs循环次数,为了将学习成果可视化,一般也设置一个列表用于存储损失函数的变化过程,然后对数据的输入输出特征进行划分,将数据除最后一列的值作为输入,最后一列的值升级为二维作为输出,代码如下:
epochs=100
loss_list=[]x=train_data[: , : -1] # 取出所有行,除最后一列的所有列
y=train_data[: , -1].reshape((-1,1)) # 取出所有行,最后一列,升级为二维
最后在循环中计算前向传播预测值,使用损失函数计算损失,反向传播计算梯度,优化模型参数,最后清空梯度,示例代码如下:
for epoch in range(epochs):y_pred=DNN(x)loss=loss_fn(y_pred, y)loss.backward() # 反向传播optimizer.step() # 更新参数optimizer.zero_grad() # 清空梯度缓存print(f"Epoch: {epoch}, Loss:{loss}") # 打印当前epoch和损失值loss_list.append(loss.item()) # 将损失值添加到列表中
测试方法为:首先声明关闭梯度计算功能,将预测值与真实值进行比较,统计正确信息,示例代码如下:
with torch.no_grad(): # 关闭自动求导功能test_x=test_data[: , : -1]test_y=test_data[: , -1].reshape((-1,1))pred_y=DNN(test_x)
制作数据集DataSet
前面我们使用的是批量梯度下降,每次参数更新使用所有样本,为了提高训练效率,我们在实践中多使用小批量梯度下降,这要求我们分批加载数据,加上我们为了复用代码和更好地管理数据,数据集应该也使用框架管理起来,该功能可以借助DataSet实现。
我们的数据集必须继承DataSet类,同时要重写__init__加载数据集、__getitem__获取数据索引和__len__获取数总量方法,示例代码如下:
from torch.utils.data import Dataset, DataLoaderclass Data(Dataset):def __init__(self,filename): # 根据文件路径加载数据集super(Data, self).__init__()df = pd.read_csv(filename)arr = df.values.astype(np.float32)ts = torch.tensor(arr)ts = ts.to('cuda')tran_size=int(len(ts)*0.8)ts=ts[torch.randperm(ts.size(0)),:]self.x=ts[:tran_size,:-1]self.y=ts[:tran_size,-1].reshape((-1,1))self.xlength=len(self.x)self.ylength=len(self.y)def __getitem__(self, index):return self.x[index], self.y[index]def __len__(self):return self.xlength,self.ylength
加载数据集时使用Data=Data("路径")创建数据集对象,train_size,test_size= len(dataset)读取文件长度,使用train_loader=DataLoader(dataset,batch_size=100,shuffle=True)和test_loader=DataLoader(dataset,batch_size=100,shuffle=False)分别读取训练集和测试集,shuffle表示是否洗牌,训练集可用,测试集无需洗牌。
使用该方法加载数据集,训练测试时直接可用for (x,y) in train_loader循环,因为其中已经包含了两个元素,代码更简洁。
CNN卷积神经网络
该网络顺应机器学习的图像处理潮流而生,传统神经网络需要将图像展为一列,该方式会忽略图像原本二维排布时的关系,更不必说如今的彩色图像可能有多个通道,传统方法更无法处理,基于保留临近位置像素点关系的想法,产生了卷积神经网络。
卷积核
该方法本质上是神经网络的变形,只是其表现形式有所区别,原本的权重w变成了卷积核,图像像素与卷积核逐位相乘求和,再进行偏置计算,原本的激活函数此时变成了池化层pool,直观展示如下:

构建网络时使用nn.Conv2d(输入通道数,输出通道,卷积核大小,填充,步长)来添加卷积层,由于卷积核的数值也是训练的一部分,故无需手动设置,由随机初始化完成,使用示例如下:
model = nn.Sequential(nn.Conv2d(1,20,5),nn.ReLU(),nn.Conv2d(20,64,5),nn.ReLU())
其他卷积层见官方文档。
池化层
该层功能与激活函数类似,用于获取特征,比如选出最大值,求平均等操作,如nn.MaxPool1d(),详见官方文档,可惜是英文的,而且信息量太大,每个函数都值得学一会。
输出尺寸计算
此外为了使图像与卷积核大小相符,增加了填充padding,和卷积核的移动步长stride,现在整合所有参数,输入图像尺寸(H,W),卷积核大小(FH,FW),填充p,步幅s,输出图像大小(OH,OW)的计算方法如下:


滤波器
彩色图像等多通道时使用相应通道数的卷积核即可,但此时卷积核又有了新的名字——滤波器Filter,即输入数据与滤波器通道设置为相同的值时,输出仍为一维,输出时再使用滤波器,即可实现升维。
经典网络
LeNet-5
AlexNet
GoogLeNet
ResNet
答疑—清空梯度
上次模型构建我们讨论了反向传播的具体作用,这次我又对清空梯度这步有了疑问,每个epoch梯度清空,那是否i多次实验彼此独立,又如何收敛呢?经过查询得出如下结论。
首先重申,清空的是梯度,而非模型参数,pytorch默认使用的是梯度累加的方法,即多次训练的梯度累加计算,并允许手动清零,该方式允许硬件条件不允许的项目使用小的batch_size,多次循环累加梯度可以实现较好的效果,而我们手动清零后可以避免多个数据集对模型参数优化的影响,实现全新的二次训练。
总结
本次算是初学pytorch的第二次实践,对于一些方法和原理有了更进一步的理解:
清空梯度避免干扰,小批量时可不清空;
继承方法建立模型和数据集;
卷积核用于保存图像空间上的相邻关系,池化层选特征;
多通道用滤波器降维,学习后再升维。
至此觉得可以算是入门了,但仍然路漫漫,学习网络模型结构的搭建,各种优化算法和损失函数,池化操作,步长卷积核大小的设置,这些的工作才是大头,此外将深度学习与什么相结合,这更是关键。
相关文章:
pytorch实现深度神经网络DNN与卷积神经网络CNN
DNN概述 深度神经网络DNN来自人脑神经元工作的原理,通过在计算机中逻辑抽象出多个节点,接收处理并向后传递信息,实现计算机的自我学习,类比结构见下图: 该方法通过预测输出与实际值的差异不断调整节点参数࿰…...

芯片测试-LDO测试
LDO测试 💢LDO的简介💢💢压降💢💢决定压降的主要因素💢 💢LDO的分类及原理💢💢PMOS LDO💢💢PMOS LDO工作过程💢💢PMOS LDO…...

期权懂|期权新手看过来:看跌期权该如何交易?
期权小懂每日分享期权知识,帮助期权新手及时有效地掌握即市趋势与新资讯! 期权新手看过来:看跌期权该如何交易? 一、可以直接购买看跌期权: (1)选择预期下跌的标的资产。 (2&#…...
:密码学Hash算法的分类)
《深入浅出HTTPS》读书笔记(8):密码学Hash算法的分类
密码学Hash算法有很多,比如MD5算法、SHA族类算法,MD5早已被证明是不安全的Hash算法了,目前使用最广泛的Hash算法是SHA族类算法。 1)MD5 MD5是一种比较常用的Hash算法,摘要值长度固定是128比特。 MD5算法目前被证明已…...

大语言模型安全,到底是什么的安全
什么是AI安全 自ChatGPT问世以来,市场上涌现出了众多大型语言模型和多样化的AI应用。这些应用和模型在为我们的生活带来便利的同时,也不可避免地面临着安全挑战。AI安全,即人工智能安全,涉及在人工智能系统的开发、部署和使用全过…...

论文2—《基于柔顺控制的智能神经导航手术机器人系统设计》文献阅读分析报告
论文报告:基于卷积神经网络的手术机器人控制系统设计 摘要 本研究针对机器人辅助微创手术中定向障碍和缺乏导航信息的问题,设计了一种智能控制导航手术机器人系统。该系统采用可靠和安全的定位技术、7自由度机械臂以及避免关节角度限制的逆运动学控制策…...
)
试编写算法将单链表就地逆置(默认是带头节 点,如果是不带头节点地逆置呢?)
编写一个算法来就地逆置一个单链表。默认情况下,链表是带头节点的,但如果链表不带头节点,逆置的过程会有所不同。 第一步:定义逆置函数 根据题目中的“试编写算法将单链表就地逆置”,我们需要: 定义一个…...

FPGA学习笔记#3 Vitis HLS编程规范、数据类型、基本运算
本笔记根据笔者目前的项目确定学习目标,目前主要集中在Vitis HLS上,使用的Vitis HLS版本为2022.2,在windows11下运行,仿真part为xcku15p_CIV-ffva1156-2LV-e,从这一篇开始是HLS的学习进度,主要根据教程&…...

爬虫 - 二手交易电商平台数据采集 (一)
背景: 近期有一个需求需要采集某电商网站平台的商品数据进行分析。因此,我计划先用Python实现一个简单的版本,以快速测试技术的实现可能性,再用PHP实现一个更完整的版本。文章中涉及的技术仅为学习和测试用途,请勿用于商业或非法用…...

“成交量分布指标“,通过筹码精准锁定价格方向+简单找市场支撑压力位 MT4免费公式!
指标名称:成交量分布指标 版本:MT4 ver. 1.32 之前发布的市场分布图不少朋友反馈不错,希望获得其它版本。 这个版本只有MT4的,MT5可以看之前版本,链接: “市场分布图”,精准把握价格动向 更直…...

简记Vue3(四)—— 路由
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…...

Python批量合并多个PDF
在日常工作中,处理和合并多个 PDF 文件是一个常见需求,尤其是在需要将大量文件整理成一个完整文档时。本文将详细介绍如何使用 Python 的 PyMuPDF 库来实现批量 PDF 文件合并,并提供针对大文件优化的解决方案。 安装 PyMuPDF 要使用 PyMuPD…...

Linux:vim命令总结及环境配置
文章目录 前言一、vim的基本概念二、vim模式命令解析1. 命令模式1)命令模式到其他模式的转换:2)光标定位:3)其他命令: 2. 插入模式3. 底行模式4. 替换模式5. 视图模式6. 外部命令 三、vim环境的配置1. 环境…...

贪心算法day05(k次取反后最大数组和 田径赛马)
目录 1.k次取反后最大化的数组和 2.按身高排序 3.优势洗牌 1.k次取反后最大化的数组和 题目链接:. - 力扣(LeetCode) 思路: 代码: class Solution {public int largestSumAfterKNegations(int[] nums, int k) {//如…...
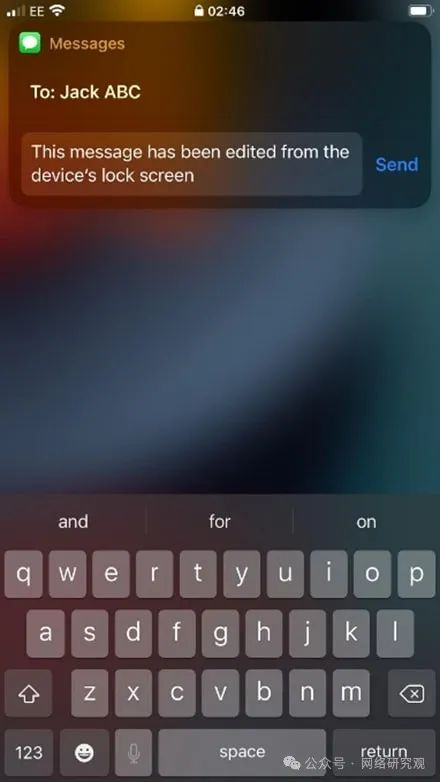
默认 iOS 设置使已锁定的 iPhone 容易受到攻击
苹果威胁研究的八个要点 苹果手机间谍软件问题日益严重 了解 Apple 苹果的设备和服务器基础模型发布 尽管人们普遍认为锁定的 iPhone 是安全的,但 iOS 中的默认设置可能会让用户面临严重的隐私和安全风险。 安全研究员 Lambros 通过Pen Test Partners透露&#…...

上海市计算机学会竞赛平台2024年11月月赛丙组
题目描述 在一个棋盘上,有两颗棋子,一颗棋子在第 aa 行第 bb 列,另一个颗棋子在第 xx 行第 yy 列。 每一步,可以选择一个棋子沿行方向移动一个单位,或沿列方向移动一个单位,或同时沿行方向及列方向各移动…...

Python批量设置图片背景为透明
我们日常生活中制作PPT等教学资源时,需要批量去除图片背景,就可以使用 Python 的 rembg 库。 这个库基于神经网络模型,去背景效果较好,可以批量处理png, jpg, jpeg等图片。采用以下代码可以批量处理当前目录下的所有图片…...

Vue CLI 脚手架
cli脚手架创建项目步骤 全局安装(一次):yarn global add vue/cli 无法识别yarn的要先安装yarn;终端执行npm install -g yarn 查看Vue版本:vue --version 这里有问题(success上方有warning) 报错:‘vue’不是内部或外部…...

Linux【基础篇】
-- 原生罪 linux的入门安装学习 什么是操作系统? 用户通过操作系统和计算机硬件联系使用。桥梁~ 什么是Linux? 他是一套开放源代码(在互联网上找到Linux系统的源代码,C语言写出的软件),可以自由 传播&…...

多线程环境下安全地使用 SimpleDateFormat的常见方法
文章目录 1. 使用局部变量(每个线程独立一个实例)2. 使用 ThreadLocal<SimpleDateFormat>3. 使用 DateTimeFormatter(Java 8 及以上)4. 使用 DateFormat 子类(如 FastDateFormat)5. 使用 synchronize…...

解密智能工具:3步实现Windows高效安装Android应用
解密智能工具:3步实现Windows高效安装Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在数字生活日益融合的今天,你是否曾为Windows…...
:从token消耗策略、种子可控性、多主体一致性到商用合规链路的断代式升级)
Midjourney版本战争白皮书(V7终结篇 vs V8统治纪元):从token消耗策略、种子可控性、多主体一致性到商用合规链路的断代式升级
更多请点击: https://intelliparadigm.com 第一章:V7终结篇与V8统治纪元的战略分水岭 V7 版本的正式 EOL(End-of-Life)标志着一个技术周期的谢幕,而 V8 的全面 GA(General Availability)则开启…...

通过Taotoken模型广场为不同视频类型选择合适的生成模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken模型广场为不同视频类型选择合适的生成模型 为视频内容生成高质量的文本描述、脚本或字幕,是许多创作者和…...

BBDown终极指南:5分钟掌握B站视频本地化完整解决方案
BBDown终极指南:5分钟掌握B站视频本地化完整解决方案 【免费下载链接】BBDown Bilibili Downloader. 一个命令行式哔哩哔哩下载器. 项目地址: https://gitcode.com/gh_mirrors/bb/BBDown 在数字内容爆炸的时代,你是否曾为无法离线观看B站优质视频…...
)
Codex入门10-Goal自主任务(进阶必学:设定目标就不管了,AI自己干活到完成)
🎯 本文目标 掌握 /goal 持久化任务系统,让 Codex 自主完成复杂的大型工作。 🤔 /goal 和普通对话有什么区别? 对比 普通对话 /goal 任务 交互方式 一问一答 设定目标后AI自主工作 持久性 关终端就中断 关终端也能继续 适合任务 小任务、即时反馈 大任务、长期执行 计划…...

Apollo Save Tool:3步解决PlayStation存档管理难题的终极方案
Apollo Save Tool:3步解决PlayStation存档管理难题的终极方案 【免费下载链接】apollo-ps4 Apollo Save Tool (PS4) 项目地址: https://gitcode.com/gh_mirrors/ap/apollo-ps4 你是否曾为丢失珍贵的游戏进度而懊恼?是否在主机升级时面临数百个存档…...
)
告别按钮!用Qt实现STM32小车的键盘与手柄控制方案(附串口通信源码)
超越按钮控制:Qt框架下STM32小车的键盘与手柄交互方案 在嵌入式开发领域,人机交互体验往往被忽视,而实际上它直接影响着用户的操作效率和舒适度。对于STM32遥控小车这类需要实时操控的项目,传统的按钮点击方式存在明显局限——操作…...

从零到一:OWASP ZAP实战渗透测试全流程解析
1. OWASP ZAP入门:渗透测试的瑞士军刀 第一次接触OWASP ZAP时,我完全被它复杂的界面吓到了。但用了三个月后,我发现这简直是Web安全测试的"瑞士军刀"——功能强大但需要正确打开方式。简单来说,ZAP就是个会自动帮你找网…...

多目标粒子群混合储能优化配置【附算法】
✨ 长期致力于混合储能、优化配置、风光互补微电网、多目标粒子群算法、CRITIC-TOPSIS研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)风光-负荷多场景…...

osModa:基于NixOS与AI智能体的下一代服务器操作系统
1. 项目概述:为AI智能体而生的操作系统如果你和我一样,长期在服务器运维和AI应用部署的一线摸爬滚打,那你一定对这样的场景深有体会:凌晨三点,手机突然响起刺耳的告警,你睡眼惺忪地爬起来,SSH连…...