GoogLeNet-水果分类
GoogLeNet-水果分类
1.数据集
官方下载地址:https://www.kaggle.com/datasets/karimabdulnabi/fruit-classification10-class?resource=download
备用下载地址:https://www.123684.com/s/xhlWjv-pRAPh
介绍:
十个类别:苹果、橙色、鳄梨、猕猴桃、芒果、凤梨、草莓、香蕉、樱桃、西瓜
2.训练
import copy
import time
import torch
from torch import nn
import torchvision
from torchvision import transforms
import torch.utils.data as Data
import matplotlib.pyplot as plt
import numpy as np
from model import GoogLeNet, Inception
import pandas as pddef train_val_data_process():ROOT_TARIN = './02框架学习/04经典卷积神经网络与实战-pao哥/06_GoogLeNet_fruit/dataset/train'# 定义处理训练集的数据 Tensor会将数据转换为0-1之间的数据train_transform = transforms.Compose([transforms.Resize((224,224)), transforms.ToTensor()])# 加载数据集train_data = torchvision.datasets.ImageFolder(root=ROOT_TARIN, transform=train_transform)# 划分训练集验证集train_data, val_data = Data.random_split(dataset=train_data, lengths=[round(0.8*len(train_data)), round(0.2*len(train_data))])train_dataloader = Data.DataLoader(dataset=train_data, batch_size=64,shuffle=True,num_workers=3)val_dataloader = Data.DataLoader(dataset=val_data,batch_size=64,shuffle=True,num_workers=3)return train_dataloader, val_dataloaderdef train_model_process(model, train_dataloader, val_dataloader, epochs):device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')optimizer = torch.optim.Adam(model.parameters(), lr=0.001)loss_fn = nn.CrossEntropyLoss()# 将模型放入到训练设备model = model.to(device)# 最佳权重best_model_wts = copy.deepcopy(model.state_dict)# 参数best_acc = 0.0train_loss_all = []val_loss_all = []train_acc_all = []val_acc_all = []since = time.time()for epoch in range(epochs):print(f'epoch:{epoch} / {epochs-1}')print('-'*10)# 初始化参数train_loss = 0.0train_corrects = 0.0val_loss = 0.0val_corrects = 0.0train_num = 0val_num = 0# 对每个batch进行训练for step, (x, y) in enumerate(train_dataloader):x = x.to(device)y = y.to(device)model.train()# 前向传播output = model(x)# 查找每一行中最大的行标pre_lab = torch.argmax(output, dim=1)loss = loss_fn(output, y)optimizer.zero_grad()loss.backward()optimizer.step()# 对损失函数进行累加train_loss += loss.item() * x.size(0)# 如果预测正确,则准确度加1train_corrects += torch.sum(pre_lab == y.data)# 当前用于训练的样本数量train_num += x.size(0)# 对验证集进行验证for step, (x, y) in enumerate(val_dataloader):x = x.to(device)y = y.to(device)model.eval()output = model(x)# 查找每一行对应的最大的行标pre_lab = torch.argmax(output, dim=1)# 计算每一个batch对应的损失loss = loss_fn(output, y)# 对损失值进行累加val_loss += loss.item() * x.size(0)# 如果预测正确,则准确度加1val_corrects += torch.sum(pre_lab == y.data)# 当前用于训练的样本数量val_num += x.size(0)train_loss_all.append(train_loss / train_num)train_acc_all.append(train_corrects.item() / train_num)val_loss_all.append(val_loss / val_num)val_acc_all.append(val_corrects.item() / val_num)print(f'epoch:{epoch} train loss:{train_loss_all[-1]:.4f} train acc:{train_acc_all[-1]:.4f}')print(f'epoch:{epoch} val loss:{val_loss_all[-1]:.4f} val acc:{val_acc_all[-1]:.4f}')# 寻找最高准确度if val_acc_all[-1] > best_acc:# 保存当前最高的准确度和对应的权重best_acc = val_acc_all[-1]best_model_wts = copy.deepcopy(model.state_dict())# 训练耗时time_use = time.time() - sinceprint(f'训练和验证耗费的时间{time_use / 60:.0f}m:{time_use % 60:.0f}s')# 选择最优的模型torch.save(best_model_wts, 'best_model.pth')train_process = pd.DataFrame(data = {'epoch':range(epochs),'train_loss_all':train_loss_all,'train_acc_all':train_acc_all,'val_loss_all':val_loss_all,'val_acc_all':val_acc_all})return train_process# 绘制
def matplot(train_process):plt.figure(figsize=(12, 4))plt.subplot(1,2,1)plt.plot(train_process['epoch'], train_process.train_loss_all, 'ro-', label='train loss')plt.plot(train_process['epoch'], train_process.val_loss_all, 'bo-', label='val loss')plt.legend()plt.xlabel('epoch')plt.ylabel('loss')plt.subplot(1,2,2)plt.plot(train_process['epoch'], train_process.train_acc_all, 'ro-', label='train acc')plt.plot(train_process['epoch'], train_process.val_acc_all, 'bo-', label='val acc')plt.legend()plt.xlabel('epoch')plt.ylabel('acc') plt.show() if __name__ == '__main__':# 模型实例化model = GoogLeNet(Inception)train_dataloader, val_dataloader = train_val_data_process()train_process = train_model_process(model, train_dataloader, val_dataloader, 51)matplot(train_process)训练了50轮,但是最终的效果不是很好


3.测试
"""
@author:Lunau
@file:model_test.py
@time:2024/09/19
"""
import torch
from torch import nn
from torchvision import transforms
import torchvision
import torch.utils.data as Data
import matplotlib.pyplot as plt
import numpy as np
from model import GoogLeNet, Inceptiondef test_data_process():ROOT_TEST = './02框架学习/04经典卷积神经网络与实战-pao哥/05_GoogLeNet_catAndDog/dataset/test'# 处理测试集的数据test_transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])# 加载数据集test_data = torchvision.datasets.ImageFolder(root=ROOT_TEST, transform=test_transform)test_dataloader = Data.DataLoader(dataset=test_data,batch_size=32, shuffle=True,num_workers=3,)return test_dataloaderdef test_model_process(model, test_dataloader):device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')model = model.to(device)# 初始化参数test_corrects = 0.0test_num = 0# 只进行前向传播with torch.no_grad():try:for x, y in test_dataloader:x = x.to(device)y = y.to(device)model.eval()# 输出结果,是概率值output = model(x)# 查找每一行中最大的行标prd_lab = torch.argmax(output, dim=1)# 预测正确的数量test_corrects += torch.sum(prd_lab == y.data)# 将所有测试的样本数进行累加test_num += x.size(0)except Exception:print('error and skip')# 计算测试的准确率test_acc = test_corrects.item() / test_numprint(f'测试的准确率为:{test_acc}')def imshow(img):img = img / 2 + 0.5 # 将图像归一化还原npimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0)))plt.show()if __name__ == '__main__':# 加载模型结构device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = GoogLeNet(Inception).to(device)# 加载模型权重model.load_state_dict(torch.load('02框架学习\\04经典卷积神经网络与实战-pao哥\\05_GoogLeNet_catAndDog\\best_model.pth', weights_only=True))test_loader = test_data_process()test_model_process(model, test_loader)
测试的准确率确实有些低,训练轮次多一些可能会好一点

4.预测
对这张图片进行预测


"""
@author:Lunau
@file:model_test.py
@time:2024/09/19
"""
import torch
from torch import nn
from torchvision import transforms
import torch.utils.data as Data
import matplotlib.pyplot as plt
import numpy as np
from model import GoogLeNet, Inception
from PIL import Image# 推理单张图片
if __name__ == '__main__':# 加载模型结构device = torch.device("cuda" if torch.cuda.is_available() else "cpu")model = GoogLeNet(Inception).to(device)# 加载模型权重model.load_state_dict(torch.load('02框架学习\\04经典卷积神经网络与实战-pao哥\\06_GoogLeNet_fruit\\best_model.pth', weights_only=True))image = Image.open('02框架学习\\04经典卷积神经网络与实战-pao哥\\06_GoogLeNet_fruit\\dataset/predict/0.jpeg')# 将图像转为tensortransform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])image = transform(image)# 增加一批次维度image = image.unsqueeze(0)print(image.shape)# 推理 model.eval()with torch.no_grad():image = image.to(device)output = model(image)output = torch.argmax(output, dim=1) # 输出最大值的索引 dim=1表示按行取最大值classes = ['Apple','Orange','Avocado','Kiwi','Mango','Pineapple','Strawberries','Banana','Cherry','Watermelon']print(f'预测结果为:{classes[output.item()]}')
相关文章:
GoogLeNet-水果分类
GoogLeNet-水果分类 1.数据集 官方下载地址:https://www.kaggle.com/datasets/karimabdulnabi/fruit-classification10-class?resourcedownload 备用下载地址:https://www.123684.com/s/xhlWjv-pRAPh 介绍: 十个类别:苹果、…...

深度学习入门指南:一篇文章全解
目录 0.前言 1.深度学习的背景历史 2.深度学习主要研究的内容 3.深度学习的分支 3.1.卷积神经网络(CNN) 3.2 递归神经网络(RNN) 3. 3长短期记忆网络(LSTM) 4.深度学习的主要应用 4.1计算机视觉 4…...

java ssm 医院病房管理系统 医院管理 医疗病房信息管理 源码 jsp
一、项目简介 本项目是一套基于SSM的医院病房管理系统,主要针对计算机相关专业的和需要项目实战练习的Java学习者。 包含:项目源码、数据库脚本、软件工具等。 项目都经过严格调试,确保可以运行! 二、技术实现 后端技术&#x…...

钩子函数的使用
钩子函数在计算机科学和软件工程中,特别是在编程框架和库中,是一种特殊的函数或方法,它们允许用户在框架或库的特定点插入自定义代码。这些钩子提供了一种扩展框架功能而无需修改其源代码的方式。 在前后端分离的项目中,如使用Dj…...

【Docker】自定义网络:实现容器之间通过域名相互通讯
文章目录 一. 默认网络:docker0网络的问题二. 自定义网络三. nginx容器指之间通过主机名进行内部通讯四. redis集群容器(跳过宿主机)内部网络通讯1. 集群描述2. 基于bitnami镜像的环境变量快速构建redis集群 一. 默认网络:docker0…...

护理陪护系统|护理陪护软件|陪护软件
在当今社会,随着人口老龄化的加剧和生活节奏的加快,护理陪护服务的需求日益增长。为了满足这一需求,开发定制一套高效、专业的护理陪护系统显得尤为重要。在开发过程中,有几个关键方面不能忽视。 一、用户需求分析 护理陪护系统的…...

苍穹外卖-账号被锁定怎么办?
刚刚解决的小问题, 最近在搞黑马程序员的苍穹外卖项目, 在完善开发编辑员工功能的时候, 不知道怎么搞的, 无论是swagger接口测试, 还是前后端联调, 都显示"账号被锁定", 原本想在网上找找解释, 结果我太笨, 搜不到, 那就只能在代码里面排查咯, 既然是登录接口出…...

webpack loader全解析,从入门到精通(10)
webpack 的核心功能是分析出各种模块的依赖关系,然后形成资源列表,最终打包生成到指定的文件中。更多复杂的功能需要借助 webpack loaders 和 plugins 来完成。 1. 什么是 Loader Loader 本质上是一个函数,它的作用是将某个源码字符串转换成…...

python机器人Agent编程——实现一个本地大模型和爬虫结合的手机号归属地天气查询Agent
目录 一、前言二、准备工作三、Agent结构四、python模块实现4.1 实现手机号归属地查询工具4.2实现天气查询工具4.3定义创建Agent主体4.4创建聊天界面 五、小结PS.扩展阅读ps1.六自由度机器人相关文章资源ps2.四轴机器相关文章资源ps3.移动小车相关文章资源ps3.wifi小车控制相关…...

【动态规划】斐波那契数列模型总结
一、第 N 个泰波那契数 题目链接: 第 N 个泰波那契数 题目描述: 题目分析: 1、状态表示: dp[i] 表示:第 i 个斐波那契数的值 2、状态转移方程: 由题意可知第 i 个数等于其前三个数之和 dp[i] dp[i-…...

EasyUI弹出框行编辑,通过下拉框实现内容联动
EasyUI弹出框行编辑,通过下拉框实现内容联动 需求 实现用户支付方式配置,当弹出框加载出来的时候,显示用户现有的支付方式,datagrid的第一列为conbobox,下来选择之后实现后面的数据直接填充; 点击新增:新…...
使用 PageOffice 实现word文件在线留痕)
国产linux系统(银河麒麟,统信uos)使用 PageOffice 实现word文件在线留痕
PageOffice 国产版 :支持信创系统,支持银河麒麟V10和统信UOS,支持X86(intel、兆芯、海光等)、ARM(飞腾、鲲鹏、麒麟等)、龙芯(LoogArch)芯片架构。 查看本示例演示效果 …...
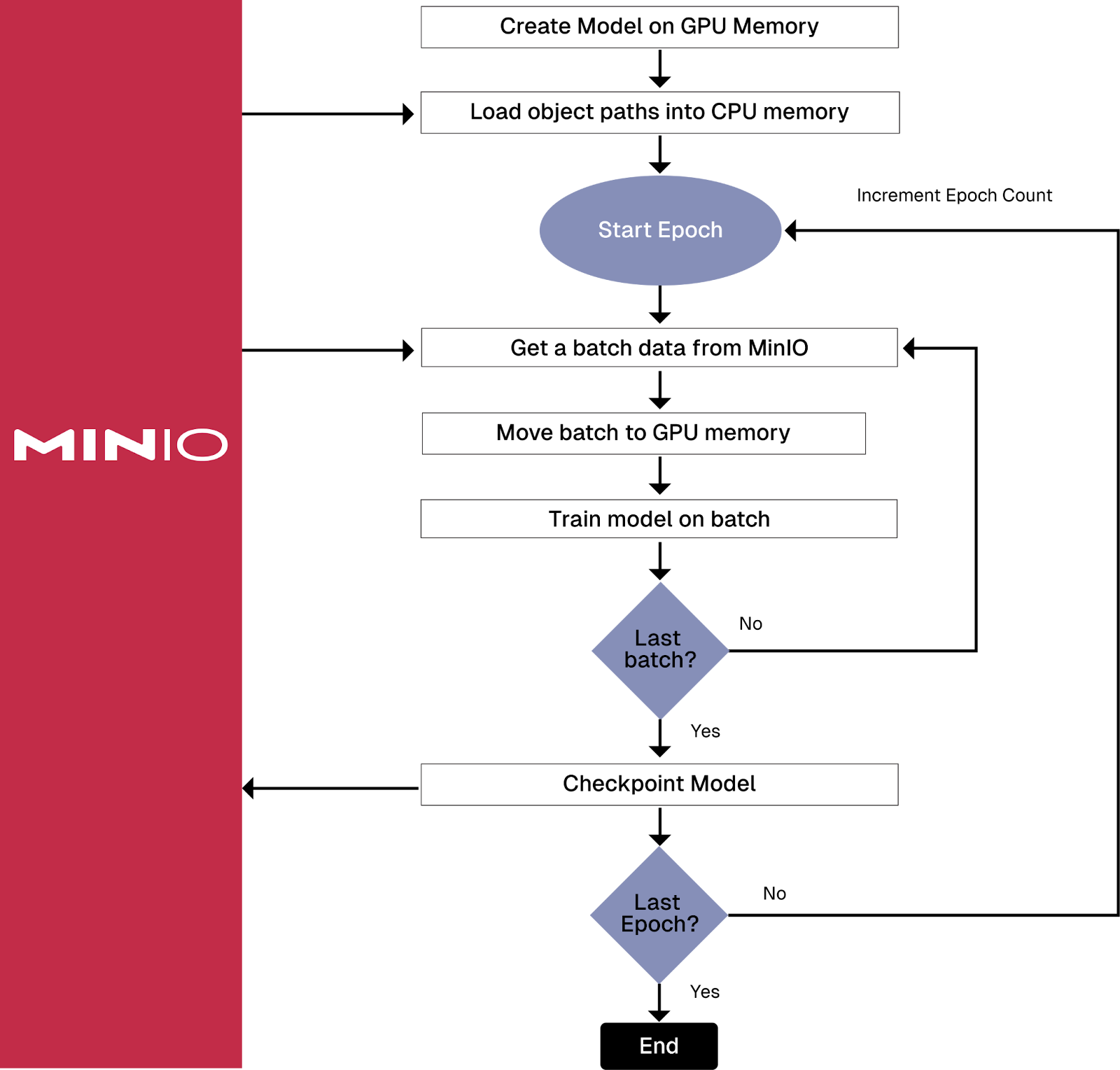
使用亚马逊 S3 连接器为 PyTorch 和 MinIO 创建地图式数据集
在深入研究 Amazon 的 PyTorch S3 连接器之前,有必要介绍一下它要解决的问题。许多 AI 模型需要使用无法放入内存的数据进行训练。此外,许多为计算机视觉和生成式 AI 构建的真正有趣的模型使用的数据甚至无法容纳在单个服务器附带的磁盘驱动器上。解决存…...

自动化运维:提升效率与稳定性的关键技术实践
自动化运维:提升效率与稳定性的关键技术实践 在数字化转型的浪潮中,企业对于IT系统的依赖日益加深,系统的复杂性和规模也随之膨胀。面对这一挑战,传统的运维模式——依靠人工进行服务器的监控、配置变更、故障排查等任务…...

Google Go编程风格指南-介绍
关于 首先应该明确的是:Go语言是Google搞出来的,这个编程风格指南也是它提出来的,详见:https://google.github.io/styleguide/go/。 然后国内翻译组跟上,于是有了中文版:https://gocn.github.io/stylegui…...

思科模拟器路由器配置实验
一、实验目的 了解路由器的作用。掌握路由器的基本配置方法。掌握路由器模块的使用和互连方式。 二、实验环境 设备: 2811 路由器 1 台计算机 2 台Console 配置线 1 根网线若干根 拓扑图:实验拓扑图如图 8-1 所示。计算机 IP 地址规划:如表…...

机器学习—选择激活函数
可以为神经网络中的不同神经元选择激活函数,我们将从如何为输出层选择它的一些指导开始,事实证明,取决于目标标签或地面真相标签y是什么,对于输出层的激活函数,将有一个相当自然的选择,然后看看激活函数的选…...

[ Linux 命令基础 4 ] Linux 命令详解-文本处理命令
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...

Odoo:免费开源的钢铁冶金行业ERP管理系统
文 / 开源智造 Odoo亚太金牌服务 简介 Odoo免费开源ERP集成计质量设备大宗原料采购,备件设材全生命周期,多业务模式货控销售,全要素追溯单品,无人值守计量物流,大宗贸易交易和精细化成本管理等方案;覆盖…...

33.Redis多线程
1.Redis队列与Stream Redis5.0 最大的新特性就是多出了一个数据结构 Stream,它是一个新的强大的支持多播的可持久化的消息队列。 Redis Stream 的结构如上图所示,每一个Stream都有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯…...

别再只会拖模块了!手把手教你用Simulink封装打造自己的‘智能积木’
从零构建你的Simulink智能积木库:封装技术实战指南 在工程建模领域,Simulink就像数字世界的乐高积木箱,但大多数用户只停留在拖拽现成模块的初级阶段。真正的高手都掌握了一项核心技能——模块封装。这就像把一堆散乱的乐高零件组装成功能完整…...

基于Refine框架的企业级后台管理系统实战开发指南
1. 项目概述与核心价值最近在梳理企业内部后台管理系统的技术栈时,我又一次把目光投向了refine这个框架。如果你也和我一样,长期被各种业务后台的重复性开发工作所困扰——比如没完没了的增删改查(CRUD)界面、复杂的权限控制、数据…...

收藏必看!2026 网安行业深度解析,人才缺口巨大,五大高薪技术方向详解
2026年网络安全行业迎来黄金发展期,全球人才缺口达480万,岗位年增37%,薪资普遍高于IT行业20%以上。热门方向包括AI安全、零信任架构、数据安全合规、云安全和工业互联网安全。入行可通过四大阶段系统学习:基础入门、技术进阶、高阶…...

Butlerclaw:OpenClaw AI Agent的图形化桌面管理工具
1. 项目概述如果你和我一样,对AI Agent的潜力感到兴奋,但又对OpenClaw这类框架复杂的安装、配置和日常管理感到头疼,那么Butlerclaw的出现,绝对是一个值得庆祝的消息。简单来说,Butlerclaw是一个为OpenClaw量身打造的“…...

如何使用pretty-ts-errors:TypeScript错误追踪与性能优化终极指南
如何使用pretty-ts-errors:TypeScript错误追踪与性能优化终极指南 【免费下载链接】pretty-ts-errors 🔵 Make TypeScript errors prettier and human-readable in VSCode 🎀 项目地址: https://gitcode.com/gh_mirrors/pr/pretty-ts-error…...

从零学会基础算法前缀和差分:数组区间求和离散化基础
首先祝大家劳动节快乐!开学两个月来学的东西不多,主要掌握了两块内容:前缀和/差分/离散化 和 数学基础。本文是第一篇,重点整理前缀和相关内容。 编程语言:C 排版助手:AI一、数组的三个简化技巧 1. 前缀和 …...

量子噪声对机器学习模型的影响与优化策略
1. 量子噪声与机器学习模型的复杂博弈在量子计算领域,噪声问题就像一位不请自来的客人,总是干扰着我们的计算过程。特别是在量子机器学习(QML)中,噪声的影响更为微妙且复杂。我最近使用Qiskit平台进行了一系列实验,试图揭示不同类…...

VCSA 7.0 报 vAPI Endpoint 黄灯告警?别慌,这份保姆级排查与修复指南帮你搞定
VCSA 7.0 vAPI Endpoint黄灯告警全流程诊断手册 凌晨三点,监控系统突然弹出一条告警——vCenter Server的vAPI Endpoint服务状态由绿转黄。作为运维负责人,你需要在最短时间内判断这是需要立即处理的严重故障,还是可以暂缓的偶发异常。本文将…...
)
Google Calendar智能安排深度拆解(Gemini原生集成技术白皮书级解析)
更多请点击: https://intelliparadigm.com 第一章:Gemini Google Calendar智能安排技术全景概览 Gemini 与 Google Calendar 的深度集成标志着日程管理进入语义理解驱动的新阶段。该能力并非简单调用 API,而是依托 Gemini 模型对自然语言指…...

MCP协议专用Linter:mcp-lint工具的设计、规则与集成实践
1. 项目概述:一个为MCP协议量身定制的代码质量守护者 最近在折腾MCP(Model Context Protocol)相关的开发,发现一个挺有意思的项目: robert19001-cmyk/mcp-lint 。光看名字,你大概能猜到它是个代码检查工具…...