【贪心算法】贪心算法三
贪心算法三
- 1.买卖股票的最佳时机
- 2.买卖股票的最佳时机 II
- 3.K 次取反后最大化的数组和
- 4.按身高排序
- 5.优势洗牌(田忌赛马)

点赞👍👍收藏🌟🌟关注💖💖
你的支持是对我最大的鼓励,我们一起努力吧!😃😃
1.买卖股票的最佳时机
题目链接: 121. 买卖股票的最佳时机
题目分析:

买卖股票的最佳时机既可以用贪心也可以用动规,其中所有的股票问题都可以只用动规来解,但是有些题用贪心来解思路和写法是更优的。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。这句话的意思是买卖股票只能执行一次。返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
算法原理:
我们用圆圈代表数组中一个个元素。
如果我们把题意搞清楚,我们很容易想到一个暴力策略,我们要最大利润的话,无非就是在数组中挑出两个位置,一个位置是买入,一个位置是卖出,使这两个位置的值的差是最大的。此时我们有一个暴力解法可以把所有的二元组枚举出来,也就是两次for循环,第一层for依次从左往右固定一个卖出位置,第二层for依次枚举买入位置,每到一个位置就用卖出位置 - 买入位置,把所有情况的差求一个最大值。当固定完一个卖出位置之后,卖入位置往后走一步,然后买入位置继续从头开始枚举。
解法一:暴力解法,两层 for 循环的暴力枚举
但是时间复杂度是O(N^2)

有了这两层 for 循环的暴力枚举,我们可以想到一个优化方式,固定卖出位置的时候,我们想找到这一段的最大利润,我们之前是从头开始枚举。我们买入点其实就是在找以该卖出点位置的最大利润,此时贪心就来了,我们其实进行找到卖入位置之前买入的最小值就行了,然后拿卖出减去前面买入的最小值,就是这个点卖出的最大利润。所以我们仅需知道卖出之前所有买入位置的最小值就可以了。
我们求最小值如果从前往后遍历,时间复杂度是O(N),如果固定完一个卖出位置就已经知道前面买入位置的最小值,时间复杂度就是O(1),那整体时间复杂度就是O(N)

当我们把这个卖出位置的最大利润知道之后,接下来要求下一个卖出位置的最大利润,我们可以在去下一个卖出位置之前,拿之前的 prevMin 和 该卖出位置 做比较 求一个最小值,就知道 下一个卖出位置之前所有买入位置的最小值。

解法二: 贪心 + 一个变量标记 “前缀最小值”
时间复杂度O(N)
我们这个贪心策略其实适合暴力解法结果是一样的依旧把所有情况都枚举到,所以暴力是对的,贪心也是对的。
class Solution {
public:int maxProfit(vector<int>& prices) {int n = prices.size();int ret = 0, prevmin = INT_MAX;for(int i = 0; i < n; ++i){ret = max(ret, prices[i] - prevmin);// 先更新结果prevmin = min(prevmin, prices[i]); // 在更新最⼩值}return ret;}
};
动态规划:
因为这个动态规划思想其实就和上面贪心几乎是一模一样的,都是找前 i 天 的最低价格,所以我们直接给代码。
class Solution {
public:int maxProfit(vector<int>& prices) {// int n = prices.size();// int ret = 0, prevmin = INT_MAX;// for(int i = 0; i < n; ++i)// {// ret = max(ret, prices[i] - prevmin);// 先更新结果// prevmin = min(prevmin, prices[i]); // 在更新最⼩值// }// return ret;// 动态规划//dp[i] 表示: 前 i 天 价格最低点int n = prices.size(), ret = 0;vector<int> dp(n + 1);dp[0] = INT_MAX;for(int i = 1; i <= n; ++i){ret = max(ret, prices[i - 1] - dp[i - 1]);dp[i] = min(dp[i - 1], prices[i - 1]);}return ret;}
};
2.买卖股票的最佳时机 II
题目链接: 122. 买卖股票的最佳时机 II
题目分析:

在每一天,你可以决定是否购买和/或出售股票,这句话的意思就决定了买卖股票是没有限制的。你在任何时候 最多 只能持有 一股 股票。这句话的意思是这一天你手里有股票是不能够在买的。要想这一天把股票买走,你必须把手里股票卖出之后才能在买。你也可以先购买,然后在 同一天 出售,这句话的意思是你可以今天买今天就卖,我们是可以进行这样操作的。
返回 你能获得的 最大 利润 。
算法原理:
我们把数组中的数放在一个二维平面,能够很清楚看见股票的增减关系,还能得到我们的策略。

这道题我们是可以执行任意多笔交易,也就是可以选任意点买入股票,任意点卖出股票。此时我们要获得最大利润,看这个图是否有这样的想法,你会选择在下降趋势买卖股票吗?肯定不会的。只要是下降趋势我们都不会买卖股票。

所以说我们的贪心策略非常简单,在这个图像中只要是股票价格是上升趋势的我就买和卖,在上升最低点买入,在上升最高点卖出。那么我就可以获得最大利润。

水平和下降我们都不会买卖股票。
贪心策略:只要能获得正收益,我就交易。
如何实现?实现方式有两种:
- 双指针
我们要在数组中找增加的区域,所以我们可以先定义一个指针 i 指向初始位置,同时定义一个指针 j ,从指针 i 位置开始往后遍历,只要当前位置的值小于后面位置的值,j 就往后走。如果发现后面的值小于或者等于 j 位置的值,说明 i 到 j 增长的区域已经被找到,此时搞一个全局的ret,ret += p[j] - p[i],当计算完这一段的时候,更新 i 到 j 位置 或者 j + 1位置,然后 j 进行从 i 位置开始。如果发现后面的值比 j 小,没关系,j 是不移动的,此时ret += p[j] - p[i] 是等于 0 的。

2. 拆分交易,把一段交易拆分成一天一天
我们求前面这段上升区域在双指针哪里其实是 p[3] - p[1],此时我们发现求这一整段的利润时,可以拆分成两段利润。我们会发现 p[3] - p[1] 正好等于 p[3] - p[2] + p[2] - p[1] 然后p[2]一抵消,两边就是相等的。左边是整体计算,右边是分开计算,它们的利润是一样的。所以只要是一段上升区域我们都可以拆分成一天一天。

class Solution {
public:int maxProfit(vector<int>& prices) {// 实现方式一: 双指针// int ret = 0, n = prices.size();// for(int i = 0; i < n; )// {// int j = i;// while(j + 1 < n && prices[j] < prices[j + 1]) ++j;//找上升的末端// ret += prices[j] - prices[i];// i = j + 1;// }// return ret;// 实现⽅式⼆: 拆分成⼀天⼀天int ret = 0, n = prices.size();for(int i = 0; i < n - 1; ++i){if(prices[i] < prices[i + 1])ret += prices[i + 1] - prices[i];}return ret;}
};
3.K 次取反后最大化的数组和
题目链接: 1005. K 次取反后最大化的数组和
题目分析:

对数组中的数取k次取反操作,注意可以多次选择同一个数进行进行取反操作。以这种方式修改数组后,返回数组 可能的最大和。
算法原理:
如果想对数组执行取反操作让数组和是最大的,我们下意识就会先挑选负数变成正数,而且是挑选最小的那个负数。
然后根据 k 和 数组中负数的个数的关系,我们进行分类讨论:
设整个数组中负数的个数是 m 个。
- m > k
负数的个数比取反k次要多

2. m == k
负数个数和k的个数一样,其实可以归类到第一类情况,直接把所有负数转化为整数。

- m < k
负数个数小于k的个数

此时在对 k - m 的奇偶性分析。如果整个数组是正数的话,我们非常不希望把里面的数变成负数。
当 k - m 是偶数的时候,那我们就疯狂的对一个数进行取反操作,对一个数进行偶数次取反操作这个数是不变的。
当 k - m 是奇数的时候,我们必须会让一个数变成负数,此时我们会让数组中最小的数变成负数。损失是最小的。

class Solution {
public:int largestSumAfterKNegations(vector<int>& nums, int k) {int m = 0, minElem = INT_MAX, n = nums.size();for(auto x : nums){if(x < 0) ++m;minElem = min(minElem, abs(x));// 求绝对值最⼩的那个数}// 分类讨论int ret = 0;if(m > k){sort(nums.begin(), nums.end());for(int i = 0; i < k; ++i)// 前 k ⼩个负数,变成正数ret += abs(nums[i]);for(int i = k; i < n; ++i)// 后⾯的数不变ret += nums[i];}else{// 把所有的负数变成正数for(auto x : nums) ret += abs(x);if((k - m) % 2)// 判断是否处理最⼩的正数{ret -= minElem * 2;}}return ret;}
};
4.按身高排序
题目链接: 2418. 按身高排序
题目分析:

这道题并不是一道贪心题,它只是一道排序题。但是这道题里面的排序思想会用到下到题里面。
给你一个字符串数组 names ,和一个由 互不相同 的正整数组成的数组 heights 。两个数组的长度均为 n 。对于每个下标 i,names[i] 和 heights[i] 表示第 i 个人的名字和身高,也就是说这两个数组是绑定的。按身高 降序 顺序返回对应的名字数组 names。
算法原理:
这道题主要就是排序,接下来我们就想如何排序就可以了。
我们要对身高进行降序排序,但是不能直接排,如果不管名字直接拿升高排序,排完序之后身高和姓名就可能不是对应的了。 我们必须要保证排完序后姓名和升高映射关系要能对应上。
此时我们有三种解决方式:
解法一:创建二元组
- 创建一个新的数组pair<int,string>,把原始身高和姓名绑定重新放在pair数组里面
- 对新的数组按照第一个元素排序
- 按照顺序把名字提取出来即可

解法二: 利用哈希表存下映射关系
- 先用哈希表存下映射关系 <身高,名字>
- 对身高数组排序
- 根据排序后的结果,往哈希表里找名字即可

虽然这两种方法都能解决问题,但是都是有缺陷的。统一的缺陷就是既要存身高也要存名字,第二个缺陷就是解法二的缺陷,有可能身高时重复的,但是我们的hash里key是不能相同的,此时解决方法就是把string改成string数组。
解法三:对下标排序(非常常用的一个技巧)
在排序的时候,虽然想排序但是并不想改变元素原始的位置。也就是说排序之前元素在那个位置排序后该元素还在那个位置。刚好我们这道题就符合这样排序,排序后身高和姓名还是和之前一一对应。
- 创建一个下标数组
- 仅需对下标数组排序
- 根据下标数组排序后的结果,找到原数组的信息
假如有下面的姓名数组和身高数组,我们的策略就是创建一个下标数组,下标数组保存对应的信息的下标。然后仅需对下标数组排序,排序的时候就按照要求来排,这里下标数组排序按照身高的降序来排,所以我们要重写一个排序比较方法。排序我们也是也是对下标数组排序,原始的数组我们可没动,接下来通过下标就可以找到对应的身高和姓名。

class Solution {
public:vector<string> sortPeople(vector<string>& names, vector<int>& heights) {// 解法一 // // 1. 创建一个pair<int,string>数组// int n = heights.size();// vector<pair<int,string>> x(n);// for(int i = 0; i < n; ++i)// x[i] = make_pair(heights[i],names[i]);// // 2. 对数组元素进行排序// sort(x.begin(), x.end(), [](const pair<int,string>& p1, const pair<int,string>& p2)// {// return p1.first > p2.first;// });// // 3. 提取结果// vector<string> ret;// for(auto p : x)// {// ret.push_back(p.second);// }// return ret;// 解法二// // 1.创建一个hash表// unordered_map<int,string> hash;// int n = heights.size();// for(int i = 0; i < n; ++i)// hash[heights[i]] = names[i];// // 2. 对身高数组进行排序// sort(heights.begin(), heights.end(), greater<int>());// // 3.提取结果// vector<string> ret;// for(auto x: heights)// {// ret.push_back(hash[x]);// }// return ret;// 解法三// 1. 创建一个下标数组int n = heights.size();vector<int> index(n);for(int i = 0; i < n; ++i) index[i] = i;// 2. 对下标进行排序sort(index.begin(), index.end(), [heights](const int& i, const int& j){return heights[i] > heights[j];});// 3. 提取结果vector<string> ret;for(auto i : index){ret.push_back(names[i]);}return ret;}
};
5.优势洗牌(田忌赛马)
题目链接: 870. 优势洗牌
题目分析:

给定两个长度相等的数组 nums1 和 nums2,nums1 相对于 nums2 的优势可以用满足 nums1[i] > nums2[i] 的数目来描述。也就是说相同位置只要nums1数组的数比nums2数组的数大就存在一个优势。
返回 nums1 的任意排列,使其相对于 nums2 的优势最大化。也就是想办法对第一个数组进行排序,使排序后的优势使最大的。

算法原理:
我们先回忆田忌赛马的故事,当把这道题题意搞清楚后你会发现它和田忌赛马的故事是一模一样的。田忌赛马无非就三匹马在比,我们这里是有很多马在比。但是它的策略和田忌赛马的策略是一样的。我们从田忌赛马的故事提取最优策略。
田忌赛马故事很简单,齐威王和田忌在赛马,按照等级把马划分为上、中、下三匹马,它们每次都按照上、中、下的顺序比较,但是同级别下齐威王的马比田忌的好,所以结果都每次都是齐威王赢。这个时候来了一个孙膑,它给田忌出了一个策略,让田忌更改一下马的出场顺序,改成 下、上、中。此时田忌在和齐威王比较,虽然他的下等马对齐威王的上等马是惨败的,但是他的上等马是胜于齐威王的中等马,中等马胜于齐威王的下等马。此时田忌获得胜利。

接下来我们从这个故事中提取孙膑的最优策略,为了方便叙述我们将他俩的马从小到大排序。刚开始拿着田忌的下等马去比齐威王的下等马你会发现是干不过的,如果比不过就相当于齐威王所有的马,田忌的下等马都比不过。因为我们已经按照从小到大排序了,如果田忌的下等马连齐威王最差的那匹马都比不过,那它所有的马都比不过。这里我们的第一个贪心策略,如果连最差的比不过,那就去拖累掉最强的那匹马(废物利用最大化)。接下来考虑田忌的中等马,发现中等马能打过齐威王的下等马,上等马也能打过齐威王的下等马,此时第二个贪心策略,当前最差的马就已经能比掉齐威王最差的马,绝对不会浪费更优秀的马。

总结一下最优策略:
- 排序
- 如果比不过,就去拖累掉对面最强的那一个
- 如果能比过,那就直接比
接下来我们模拟一下:
先对数组进行排序,(我们是要把nums1数组修改成ret)

8比不过11,我们的策略是废物利用最大化,直接去匹配最强的32

12比的过11,直接放

24比的过13,直接放

32比的过25,直接放

这个ret就是我们最优的策略,但是这个结果和答案给的不一样!

原因是答案是按照未排序之前的num2的顺序来匹配最终结果的。意思就是如果是11对12,应该是原始的nums2数组的11的位置放12,而不是在排完序后的第一个位置放12.

同理其他都是如此,然后这个数组才是我们要的最终结果

原因就在于我们排完序之后是要按照之前排序之前的数组来还原的,所以就出现了,虽然想排序,但是原来的顺序我还要知道。那如何实现这一点呢?《身高排序》 这到题我们正好用了这个技巧,又想让数组排序,又想找到之前的相对位置,我们的策略是直接排序下标数组。不排原始数组,对下标数组进行排序,然后通过下标数组找到原始的数,最终就能把ret对应到原始的位置。
接下来我们在模拟一下这个过程。
先对下标数组排序,如何排序之前已经说过改变排序规则,这里我们还需要两个指针,left指向num2下标数组排序后的第一个元素的下标,right指向nums2下标数组排序后的最后一个元素的下标。

依次遍历nums1,每次和left所指向的下标对应nums2中的元素做比较nums2[index2[left]],
8比不过11,把8放在最后一个位置,此时并不是把8放在ret最后一个位置,而是把8放在nums2排完序之后的最后一个位置所对应的下标的位置。也ret下标为2的位置。然后right–,代表之前的数已经匹配过了,此时最后一个位置的就是下标1。

12比的过left所指向下标对应的数11,就放在第一个位置,第一个位置下标是3,然后left++

24比的过left所指向下标对应的数13,就放在0位置,然后left++

32比的过left所指向下标对应的数25,放在下标1的位置,此时nums1遍历完就结束了。

class Solution {
public:vector<int> advantageCount(vector<int>& nums1, vector<int>& nums2) {int n = nums1.size();// 1. 排序sort(nums1.begin(), nums1.end());vector<int> index2(n);for(int i = 0; i < n; ++i) index2[i] = i;sort(index2.begin(), index2.end(), [&](const int& i, const int& j){//所有下标按照nums2里面升序形式排序return nums2[i] < nums2[j];});// 2. 田忌赛马vector<int> ret(n);int left = 0, right = n - 1;for(int i = 0; i < n; ++i){if(nums1[i] > nums2[index2[left]]){ret[index2[left]] = nums1[i];++left;}else{ret[index2[right]] = nums1[i];--right;}}return ret;}
};
证明:
证明方法:交换论证法
nums1表示排序后升序的样子,nums2也表示排序后的样子,并且nums1表示的贪心解

在来一个nums1表示最优解的情况

交换论证法就是在最优解不失去最优性的情况下调整成贪心解的话,那我们就说贪心解就是最优解。
从左往右扫描贪心解和最优解的匹配情况,当遇到第一个它们俩匹配不同的情况,就考虑这个点。
我们要分两种情况讨论:
- 贪心解比的过
贪心解比得过,那就去匹配第一个,最优解和贪心解不一样,最优解就去匹配后面的。然后最优解后面的在和第一个匹配

接下来就看最优解调整成贪心解会不会变差。
如何调整就是调的和贪心解一样就可以了,这里我们设一些变量,然后在贪心解比得过我们有一个不等式 b > a > x1

a > x1,b > x1,这两条线可以抵消

剩下两条线我们不容易得出胜负情况, 我们仅知道 b > a > x1,我们并不知道a是否大于x2,也并不知道b是否大于x2。但是我们可以粗略估计一下用b来比较x2是更优的,原因是最优解之前拿的是较小的a都能和x2匹配,调整完之后拿较大的b和x2匹配,所以绝对是更优的。a能胜过x2,b一定能胜过,a打不过x2,但是b比a大是有可能打得过x2的。 所以我们第一种情况是可以的。
- 贪心解比不过
如果比不过,贪心选择的策略就是和最后一个抵消,最优解肯定不是最后一个,接下来我们继续调整。依旧是调整后的别比之前的差就可以。

我们的谈贪心解是比不过第一个才会抵消最后一个,也就是比nums2最小的还要小。调整之前拿最优解的a和nums2前面的匹配,调整后和nums2最后一个匹配,反正都不会得分所以可以抵消。

剩下还有两条线,你会发现调整最优解b之后是更优的,b是固定的,之前b是去匹配较大的的x2,现在是匹配较小的x1,b能打过x1一定能打过x2,b打不过x2可能会打过x1。

因为我们最优解调整后是更优的,所以最优解肯定能在不失去最优性的前提下调整到贪心解。
相关文章:
【贪心算法】贪心算法三
贪心算法三 1.买卖股票的最佳时机2.买卖股票的最佳时机 II3.K 次取反后最大化的数组和4.按身高排序5.优势洗牌(田忌赛马) 点赞👍👍收藏🌟🌟关注💖💖 你的支持是对我最大的鼓励&#…...

LeetCode 40-组合总数Ⅱ
题目链接:LeetCode40 欢迎留言交流,每天都会回消息。 class Solution {List<List<Integer>> rs new ArrayList<>();LinkedList<Integer> path new LinkedList<>();public List<List<Integer>> combinatio…...

STM32WB55RG开发(1)----开发板测试
STM32WB55RG开发----1.开发板测试 概述硬件准备视频教学样品申请源码下载产品特性参考程序生成STM32CUBEMX串口配置LED配置堆栈设置串口重定向主循环演示 概述 STM32WB55 & SENSOR是一款基于STM32WB55系列微控制器的评估套件。该套件采用先进的无线通信技术,支…...

误删分区数据恢复全攻略
一、误删分区现象描述 在日常使用电脑的过程中,我们可能会遇到一种令人头疼的情况——误删分区。这通常发生在用户对磁盘管理操作不当,或者在进行系统重装、分区调整时不慎删除了重要分区。误删分区后,原本存储在该分区的数据将无法直接访问…...

《XGBoost算法的原理推导》12-14决策树复杂度的正则化项 公式解析
本文是将文章《XGBoost算法的原理推导》中的公式单独拿出来做一个详细的解析,便于初学者更好的理解。 我们定义一颗树的复杂度 Ω Ω Ω,它由两部分组成: 叶子结点的数量;叶子结点权重向量的 L 2 L2 L2范数; 公式(…...
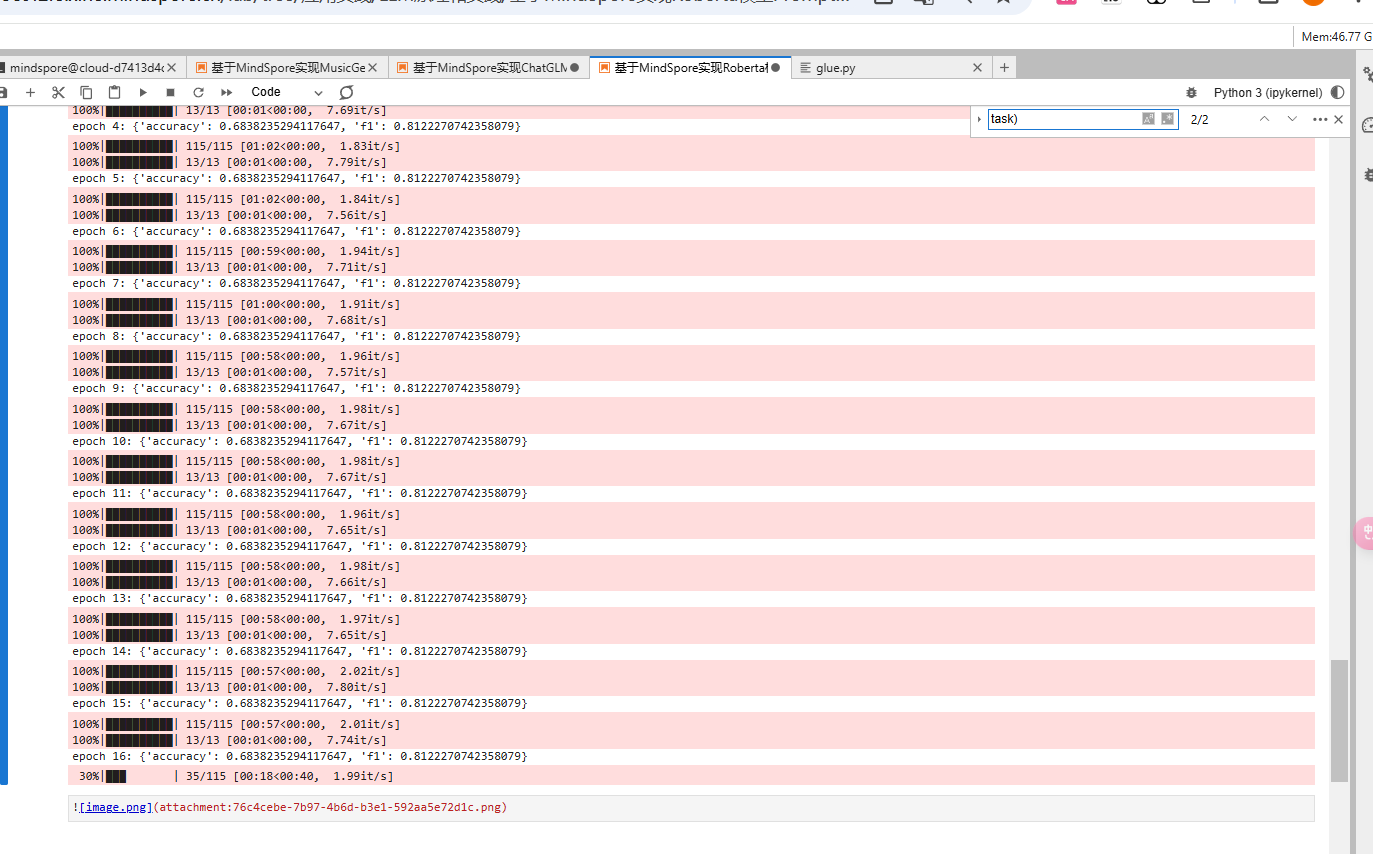
昇思大模型平台打卡体验活动:项目4基于MindSpore实现Roberta模型Prompt Tuning
基于MindNLP的Roberta模型Prompt Tuning 本文档介绍了如何基于MindNLP进行Roberta模型的Prompt Tuning,主要用于GLUE基准数据集的微调。本文提供了完整的代码示例以及详细的步骤说明,便于理解和复现实验。 环境配置 在运行此代码前,请确保…...

hadoop 3.x 伪分布式搭建
hadoop 伪分布式搭建 环境 CentOS 7jdk 1.8hadoop 3.3.6 1. 准备 准备环境所需包上传所有压缩包到服务器 2. 安装jdk # 解压jdk到/usr/local目录下 tar -xvf jdk-8u431-linux-x64.tar.gz -C /usr/local先不着急配置java环境变量,后面和hadoop一起配置 3. 安装had…...

springboot 整合mybatis
一,引入MyBatis起步依赖 <!--mybatis依赖--><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>3.0.0</version></dependency> 二&a…...

餐饮门店收银系统源码、php收银系统源码
1. 系统开发语言 核心开发语言: PHP、HTML5、Dart后台接口: PHP7.3后台管理网站: HTML5vue2.0element-uicssjs线下收银台(安卓/PC收银、安卓自助收银): Dart3框架:Flutter 3.19.6移动店务助手: uniapp线上商城: uniapp 2.系统概况及适用行业…...

canal1.1.7使用canal-adapter进行mysql同步数据
重要的事情说前面,canal1.1.8需要jdk11以上,大家自行选择,我这由于项目原因只能使用1.1.7兼容版的 文章参考地址: canal 使用详解_canal使用-CSDN博客 使用canal.deployer-1.1.7和canal.adapter-1.1.7实现mysql数据同步_mysql更…...

揭秘文心一言,智能助手新体验
一、产品描述 文心一言是一款集先进人工智能技术与自然语言处理能力于一体的智能助手软件。它采用了深度学习算法和大规模语料库训练,具备强大的语义理解和生成能力。通过简洁直观的用户界面,文心一言能够与用户进行流畅的对话交流,理解用户…...

良心无广,这5款才是你电脑上该装的神仙软件,很多人都不知道
图吧工具箱 这是一款完全纯净的硬件检测工具包,体积小巧不足0.5MB,却全面整合了CPU、硬盘、内存、显卡等电脑大神常用的检测工具与压力测试软件。 还特别为游戏爱好者们准备了直达平台官网的链接以及Directx修复工具,而且全部免费哦…...

Scala图书馆创建图书信息
图书馆书籍管理系统相关的练习。内容要求: 1.创建一个可变 Set,用于存储图书馆中的书籍信息(假设书籍信息用字符串表示,如 “Java 编程思想”“Scala 实战” 等),初始化为包含几本你喜欢的书籍。 2.添加两本…...

【Python】深入理解Python中的单例模式:用元类、装饰器和模块实现高效的单例设计
解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 《Python OpenCV从菜鸟到高手》带你进入图像处理与计算机视觉的大门! 单例模式是一种重要的设计模式,旨在确保一个类的实例在整个应用程序中仅存在一个。Python作为一种动态语言,为实现单例模式提供了多种方式…...

Flutter 小技巧之 Shader 实现酷炫的粒子动画
在之前的《不一样的思路实现炫酷 3D 翻页折叠动画》我们其实介绍过:如何使用 Shader 去实现一个 3D 的翻页效果,具体就是使用 Flutter 在 3.7 开始提供 Fragment Shader API ,因为每个像素都会过 Fragment Shader ,所以我们可以通…...

【LeetCode】【算法】42. 接雨水
LeetCode 42. 接雨水 题目描述 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数…...

深⼊理解指针(5)[回调函数、qsort相关知识(qsort可用于各种类型变量的排序)】
目录 1. 回调函数 2. qsort相关知识(qsort可用于各种类型变量的排序) 一 回调函数 1定义/作用:把函数的指针(地址)作为参数传递给另⼀个函数,当这个指针被⽤来调⽤其所指向的函数 时,被调⽤的函数就…...

qt QRunnable 与 QThreadPool详解
1. 概述 QRunnable是所有runnable对象的基类,它表示一个任务或要执行的代码。开发者需要子类化QRunnable并重写其run()函数来实现具体的任务逻辑。而QThreadPool则是一个管理QThread集合的类,它帮助减少创建线程的成本,通过管理和循环使用单…...

博客摘录「 java三年工作经验面试题整理《精华》」2023年6月12日
JDK 和 JRE 有什么区别?JDK:java 开发工具包,提供了 java 的开发环境和运行环境。JRE:java 运行环境,为 java 的运行提供了所需环境。JDK 其实包含了 JRE,同时还包含了编译 java 源码的编译器 javac&#x…...

福禄克FLUKE5500A与fluke5520a校准仪的区别功能
FLUKE5500A是美国福禄克公司的一款高性能的多功能校准仪,能够对手持式和台式多用表、示波器、示波表、功率计、电子温度表、数据采集器、功率谐波分析仪、进程校准器等多种仪器进行校准。 FLUKE5500A多功能校准仪供给了GPIB(IEEE-488)、RS-2…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

多模态大语言模型arxiv论文略读(108)
CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文标题:CROME: Cross-Modal Adapters for Efficient Multimodal LLM ➡️ 论文作者:Sayna Ebrahimi, Sercan O. Arik, Tejas Nama, Tomas Pfister ➡️ 研究机构: Google Cloud AI Re…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

【笔记】WSL 中 Rust 安装与测试完整记录
#工作记录 WSL 中 Rust 安装与测试完整记录 1. 运行环境 系统:Ubuntu 24.04 LTS (WSL2)架构:x86_64 (GNU/Linux)Rust 版本:rustc 1.87.0 (2025-05-09)Cargo 版本:cargo 1.87.0 (2025-05-06) 2. 安装 Rust 2.1 使用 Rust 官方安…...

4. TypeScript 类型推断与类型组合
一、类型推断 (一) 什么是类型推断 TypeScript 的类型推断会根据变量、函数返回值、对象和数组的赋值和使用方式,自动确定它们的类型。 这一特性减少了显式类型注解的需要,在保持类型安全的同时简化了代码。通过分析上下文和初始值,TypeSc…...

PHP 8.5 即将发布:管道操作符、强力调试
前不久,PHP宣布了即将在 2025 年 11 月 20 日 正式发布的 PHP 8.5!作为 PHP 语言的又一次重要迭代,PHP 8.5 承诺带来一系列旨在提升代码可读性、健壮性以及开发者效率的改进。而更令人兴奋的是,借助强大的本地开发环境 ServBay&am…...

破解路内监管盲区:免布线低位视频桩重塑停车管理新标准
城市路内停车管理常因行道树遮挡、高位设备盲区等问题,导致车牌识别率低、逃费率高,传统模式在复杂路段束手无策。免布线低位视频桩凭借超低视角部署与智能算法,正成为破局关键。该设备安装于车位侧方0.5-0.7米高度,直接规避树枝遮…...
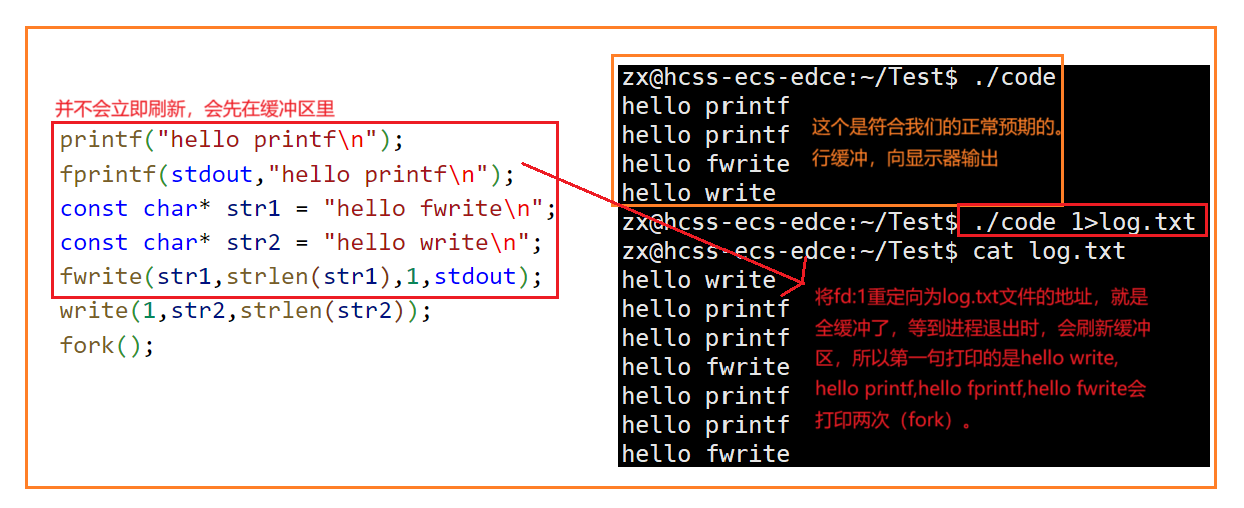
Linux中《基础IO》详细介绍
目录 理解"文件"狭义理解广义理解文件操作的归类认知系统角度文件类别 回顾C文件接口打开文件写文件读文件稍作修改,实现简单cat命令 输出信息到显示器,你有哪些方法stdin & stdout & stderr打开文件的方式 系统⽂件I/O⼀种传递标志位…...
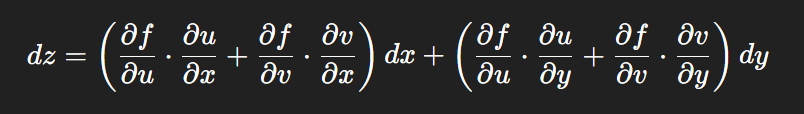
链式法则中 复合函数的推导路径 多变量“信息传递路径”
非常好,我们将之前关于偏导数链式法则中不能“约掉”偏导符号的问题,统一使用 二重复合函数: z f ( u ( x , y ) , v ( x , y ) ) \boxed{z f(u(x,y),\ v(x,y))} zf(u(x,y), v(x,y)) 来全面说明。我们会展示其全微分形式(偏导…...