Python学习从0到1 day26 第三阶段 Spark ② 数据计算Ⅰ
人总是会执着于失去的,而又不珍惜现在所拥有的
—— 24.11.9
一、map方法
PySpark的数据计算,都是基于RDD对象来进行的,采用依赖进行,RDD对象内置丰富的成员方法(算子)
map算子
功能:map算子,是将RDD的数据一条条处理(处理的逻辑:基于map算子中接收的处理函数),返回新的RDD
语法:
from pyspark import SparkConf,SparkContext# 设置spark中的python解释器对象
import os
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备一个RDD对象
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9])
# 通过map方法将全部的数据乘以10
# 能够接受一个函数,并且将函数作为参数传递进去
# 方法1:接受一个匿名函数lambda
rdd1 = rdd.map(lambda x:x*10)
print("rdd1:",rdd1.collect())# 方法2:接受一个函数
def multi(x):return x * 10rdd2 = rdd.map(multi)
print("rdd2:",rdd2.collect())# 匿名函数链式调用
# 将每一个数乘以100再加上7再减去114
rdd3 = rdd.map(lambda x:x*100).map(lambda x:x+7).map(lambda x:x-114)
print("rdd3:",rdd3.collect())
注:
map算子可以通过lambda匿名函数进行链式调用,处理复杂的功能
二、flatMap方法
flatMap算子
计算逻辑和map一样
比map多出:解除一层嵌套的功能
功能:
对rdd执行map操作,然后进行 解除嵌套 操作
用法
from pyspark import SparkConf,SparkContext# 设置spark中的python解释器对象
import os
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)rdd = sc.parallelize(["一切都会解决 回头看","轻舟已过万重山 一切都会好的","我一直相信"])# 需求:将RDD数据里面的一个个单词提取出来
rdd1 = rdd.map(lambda x:x.split(" "))
print("rdd1:", rdd2.collect())rdd2 = rdd.flatMap(lambda x:x.split(" "))
print("rdd2:", rdd3.collect())
注:
计算逻辑和map一样,比map多出解除一层嵌套的功能
三、reduceByKey方法
reduceByKey算子
功能:
① 自动分组:针对KV型(二元元组)RDD,自动按照 key 分组
② 分组聚合:接受一个处理函数,根据你提供的聚合逻辑,完成组内数据 (valve) 的聚合操作.
用法:
rdd.reduceByKey(func)
# func:(V,V)→V
# 接受2个传入参数(类型要一致),返回一个返回值,类型和传入要求一致reduceByKey的聚合逻辑是:
比如,有[1,2,3,4,5],然后聚合函数是:lambda a,b:a + b
将容器中的所有元素进行聚合

语法:
from pyspark import SparkConf,SparkContext# 设置spark中的python解释器对象
import os
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备一个二元元组rdd对象
rdd = sc.parallelize([("男",99),("男",88),("女",99),("男",77),("女",88)])# 求男生和女生两个组的成绩之和
rdd2 = rdd.reduceByKey(lambda x , y : x + y)
print(rdd2.collect())
注:
1.reduceByKey算子:接受一个处理函数,对数据进行两两计算
四、WordCount案例
使用PySpark进行单词计数的案例
读取文件,统计文件内,单词的出现数量
WordCount文件:
So long as men can breathe or eyes can see,
So long lives this,and this gives life to thee.
代码
将所有单词都转换成二元元组,单词为key,value设置为1,value表示每个单词出现的次数,作为value,初始化为1,若单词相等,则表示key相同,value值进行累加
from pyspark import SparkConf,SparkContext# 设置spark中的python解释器对象
import os
os.environ['PYSPARK_PYTHON'] = "E:/python.learning/pyt/scripts/python.exe"conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 读取数据文件
rdd = sc.textFile("D:/2LFE\Desktop\WordCount.txt")
# 取出全部单词
word_rdd = rdd.flatMap(lambda x:x.split(" "))
print(word_rdd.collect())
# 将所有单词都转换成二元元组,单词为key,value设置为1,value表示每个单词出现的次数,作为value,
# 若单词相等,则表示value相同,key值进行累加
word_with_one_rdd = word_rdd.map(lambda word:(word,1))
# 分组并求和
result_rdd = word_with_one_rdd.reduceByKey(lambda a,b:a+b)
# 打印并输出结果
print(result_rdd.collect())
相关文章:
Python学习从0到1 day26 第三阶段 Spark ② 数据计算Ⅰ
人总是会执着于失去的,而又不珍惜现在所拥有的 —— 24.11.9 一、map方法 PySpark的数据计算,都是基于RDD对象来进行的,采用依赖进行,RDD对象内置丰富的成员方法(算子) map算子 功能:map算子…...

【详细】如何优雅地删除 Docker 容器与镜像
内容预览 ≧∀≦ゞ 镜像与容器的区别删除容器和镜像的具体步骤1. 删除容器步骤 1:查看当前运行的容器步骤 2:停止容器步骤 3:删除容器 2. 删除镜像步骤 1:查看镜像列表步骤 2:删除镜像 3. 删除所有容器和镜像 使用 1Pa…...

Spring Spring Boot 常用注解总结
在 Java 开发中,Spring 和 Spring Boot 框架广泛应用于企业级应用开发。这两个框架提供了丰富的注解,使得开发更加高效和便捷。本文将对 Spring 和 Spring Boot 中常用的注解进行总结。 一、Spring 常用注解 1. Component 作用:用于将普通的…...

Flink独立集群+Flink整合yarn
Flink独立集群的搭建: 1、上传解压配置环境变量 # 1、解压 tar -xvf flink-1.15.4-bin-scala_2.12.tgz # 2、修改环境变量 export FLINK_HOME/usr/local/soft/flink-1.15.4 export PATH$PATH:$FLINK_HOME/bin 2、修改配置文件 cd /usr/local/soft/flink-1.15.4/…...

动态规划 之 简单多状态 dp 问题 算法专题
一. 按摩师 按摩师 状态表示 根据经验 题目要求 dp[i] 表示: 选择到i位置时, 此时的最长预约时长 但是根据题目又分成两种情况: f[i] : 选择到 i 位置的时候, nums[i] 必选, 此时的最长预约时长 g[i] : 选择到 i 位置的时候, nums[i] 不选, 此时的最长预约时长状态转移方程 …...

qt QPixmapCache详解
1、概述 QPixmapCache是Qt框架中提供的一个功能强大的图像缓存管理工具类。它允许开发者在全局范围内缓存QPixmap对象,从而有效减少图像的重复加载,提高图像加载和显示的效率。这对于需要频繁加载和显示图像的用户界面应用来说尤为重要,能够…...

Redis中的持久化
什么是 Redis 持久化? Redis 是一个内存数据库,也就是说它主要把数据存储在内存中,这样可以实现非常高的读写速度。通常,内存数据库是非常快速且高效的,但它也有一个很大的问题:数据丢失的风险。因为当 Red…...

Unity 如何优雅的限定文本长度, 包含对特殊字符,汉字,数字的处理。实际的案例包括 用户昵称
常规限定文本长度 ( 通过 UntiyEngine.UI.Inputfiled 附带的长度限定 ) 痛点1 无法对中文,数字,英文进行识别,同样数量的汉字和同样数量的英文像素长度是不一样的,当我们限定固定长度后,在界面上的排版不够美观 痛点2…...
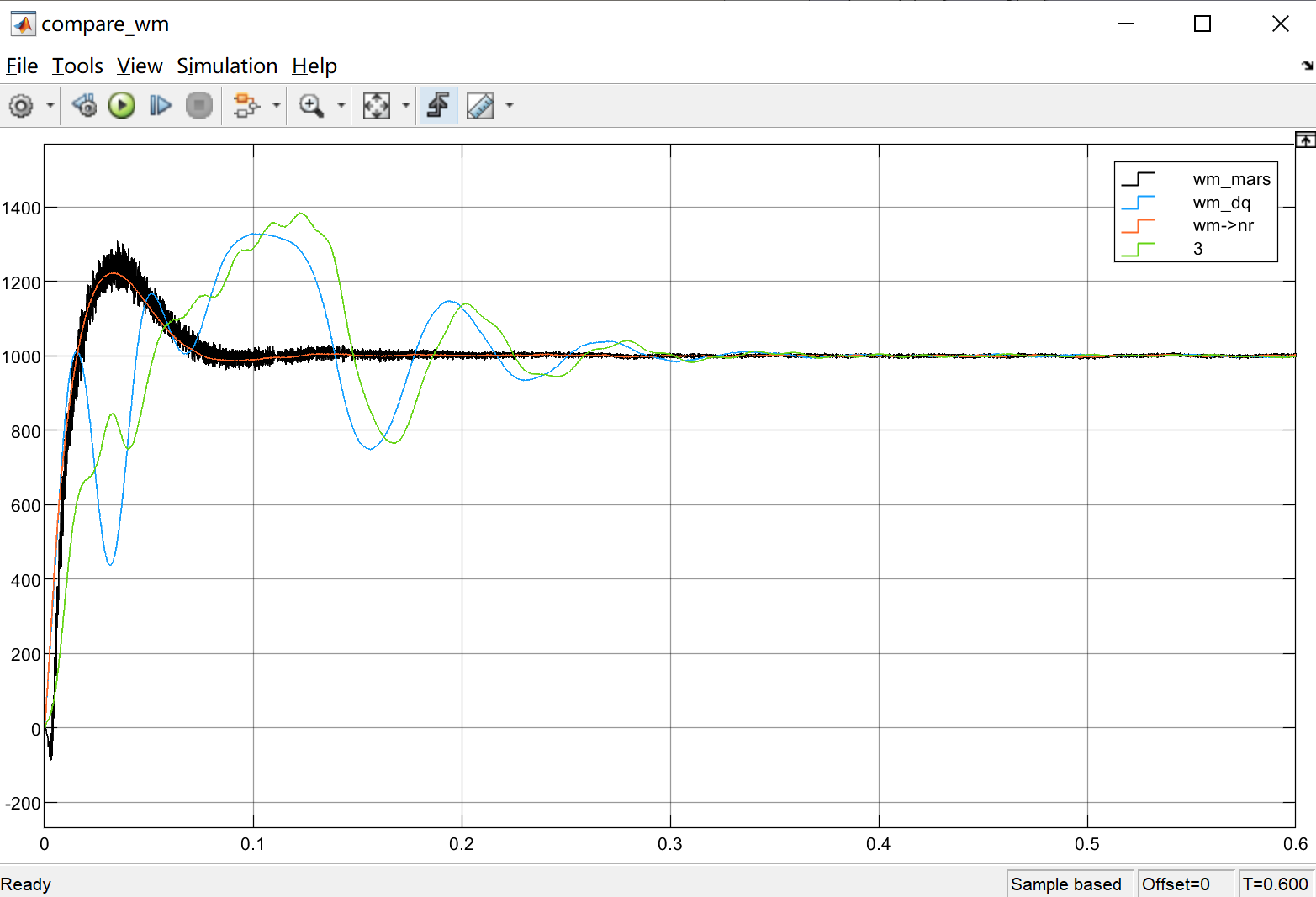
SMO+PLL滑膜观测器、MARS模型参考自适应观测器simulink仿真
模型内容介绍: (1)SMOPLL滑膜观测器通过SMO估计电机的转速和位置信息,并利用PLL技术对这些信息进行跟踪和校正,以实现高精度的电机控制; (2)MARS是一种基于模型参考自适应控制理论…...
找出单独的数)
例题解析:利用异或运算(XOR)找出单独的数
异或运算(XOR) 异或运算是一种位运算,通常用符号 ^ 表示。它的运算规则如下: 如果两个二进制位相同,结果为 0。如果两个二进制位不同,结果为 1。 具体来说,对于两个二进制位 a 和 bÿ…...
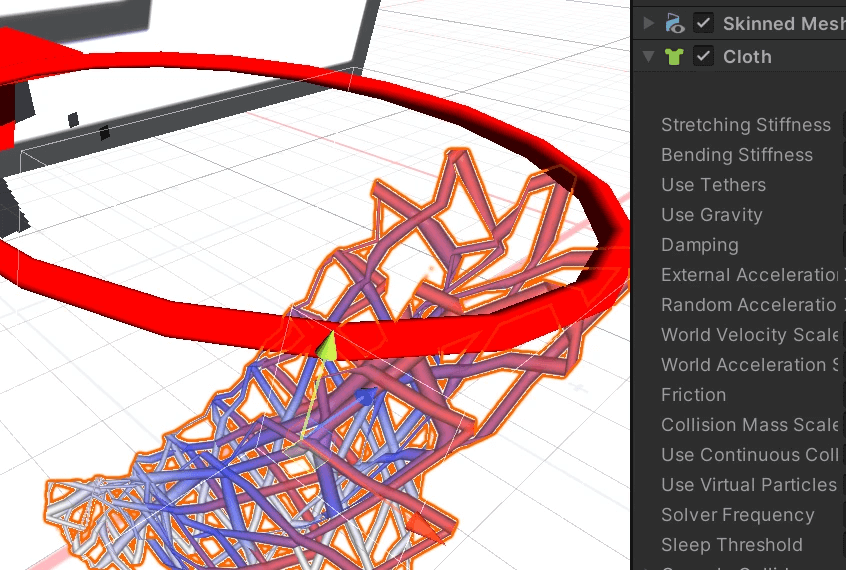
如何处理微信小程序大量未捕获的异常
1)如何处理微信小程序大量未捕获的异常 2)如何关闭代码创建的纹理的读写,或者创建不带读写的图片 3)回收带有贴图和Collider的Mesh,如何正确用对象池维护 4)Cloth组件使用在一个篮筐上,运行后篮…...

C#-StringBuilder
string:特殊的引用 每次重新赋值或者拼接时会分配新的内存空间,如果一个字符串经常改变会非常浪费空间。 StringBuilder:C#提供的一个用于处理字符串的公共类 修改字符串而不创建新的对象,需要频繁修改和拼接的字符串可以使用它…...

SQLI LABS | Less-39 GET-Stacked Query Injection-Intiger Based
关注这个靶场的其它相关笔记:SQLI LABS —— 靶场笔记合集-CSDN博客 0x01:过关流程 输入下面的链接进入靶场(如果你的地址和我不一样,按照你本地的环境来): http://localhost/sqli-labs/Less-39/ 本关是堆…...

linux安装zookeeper和kafka集群
linux安装zookeeper和kafka集群 一、Zookeeper集群部署安装zookeeper1. 下载2. 上传, 解压3. 配置 Zookeeper 节点4. 创建 myid 文件5. 启动参数更改6. sh文件授权7. 启动集群8. 防火墙开启端口 验证集群 二、kafka集群安装安装Kafka1. 下载Kafka安装包2. 上传到服务器…...

洞悉 Linux 系统运行细节,使用 atop 监测和回看系统负载状态
Linux系统的资源使用情况,你可以通过使用命令如free、top和netstat来实时监控内存、CPU及端口的使用状态。对于需要追踪历史资源消耗动态的场景,atop命令则能有效帮助用户查看过去的系统负载情况。 本篇教程的灵感源自一位小伙伴的真实经历:…...
“双十一”电商狂欢进行时,在AI的加持下看网易云信IM、RTC如何助力商家!
作为一年一度的消费盛会,2024年“双十一”购物狂欢节早已拉开帷幕。蹲守直播间、在主播热情介绍中点开链接并加购,也已成为大多数人打开“双11”的重要方式。然而,在这火热的购物氛围背后,主播频频“翻车”、优质主播稀缺、客服响…...

Python调用企业微信的扫一扫
在企业微信里面新建了一个应用,指向了搭建服务器上Django写的web应用。 web应用需要使用扫描二维码的功能,就使用了大家都评价效果好的微信的扫一扫,事实也证明微信的扫一扫很好,但实现这个功能还是花了自己不少时间,很…...

速盾:CDN和OBS能共用流量包吗?
CDN和OBS是两种不同的云服务,它们在内容分发和存储方面有着不同的功能和优势。虽然它们都可以用于提供高效的内容分发和存储服务,但是它们的流量包是不能共用的。 CDN,即内容分发网络,是一种通过将内容存储在全球分布的服务器上&…...

第8章 利用CSS制作导航菜单
8.1 水平顶部导航栏 水平莱单导航栏是网站设计中应用范围最广的导航设计,一般放置在页面的顶部。水平 导航适用性强,几乎所有类型的网站都可以使用,设计难度较低。 如果导航过于普通,无法容纳复杂的信息结构,就需要在…...

C# 集合与泛型
文章目录 前言1.什么是集合?2.非泛型集合(了解即可)2.1常见的非泛型集合 3.泛型的概念4.常用的泛型集合4.1 List < T > <T> <T>4.2 Dictionary<TKey, TValue>4.3 Queue < T > <T> <T>4.4 S t a c…...

FPGA加速SVM量子态判别:5.74纳秒低延迟与8位量化硬件实现
1. 项目概述与核心挑战 在量子计算这个前沿领域,我们每天都在和微观世界的基本单元——量子比特打交道。对于超导量子比特这类物理实现,一个核心且基础的操作就是“状态读取”:在量子算法执行或纠错循环中,我们必须快速、准确地判…...

深入解析中兴光猫工厂模式:解锁隐藏网络管理权限的技术探索
深入解析中兴光猫工厂模式:解锁隐藏网络管理权限的技术探索 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 在当今的网络设备管理中,中兴光猫作为广泛部署的终端…...

【Redis基础篇】Redis的Java客户端
温馨提示:建议在PC端浏览~ Redis的Java客户端在Redis官网中提供了各种语言的客户端,地址:https://redis.io/clientsJedis客户端Jedis的官网地址:https://github.com/redis/jedis,我们先来个快速入门:1、引入…...

AutoCut终极教程:如何用文本编辑器3分钟剪出专业视频
AutoCut终极教程:如何用文本编辑器3分钟剪出专业视频 【免费下载链接】autocut 用文本编辑器剪视频 项目地址: https://gitcode.com/GitHub_Trending/au/autocut 还在为视频剪辑软件复杂的界面而头疼吗?AutoCut让你告别繁琐的视频编辑,…...
)
DeepSeek-R1量化部署实战指南(含TensorRT+AWQ+GGUF三引擎对比评测)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1量化部署方案概览 DeepSeek-R1 是一款高性能开源大语言模型,其量化部署旨在平衡推理精度、显存占用与吞吐效率。本章聚焦于面向生产环境的轻量化落地路径,涵盖权重量…...
)
DeepSeek企业版访问控制配置白皮书(内部泄露版·含审计日志埋点规范与SOC2合规映射表)
更多请点击: https://codechina.net 第一章:DeepSeek企业版访问控制配置概述 DeepSeek企业版提供细粒度、可审计、可扩展的访问控制能力,支持基于角色(RBAC)、属性(ABAC)及策略即代码ÿ…...

Legacy iOS Kit:让旧款iPhone/iPad重获新生的终极指南
Legacy iOS Kit:让旧款iPhone/iPad重获新生的终极指南 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit …...

在个人项目中集成多模型API以应对不同任务需求
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在个人项目中集成多模型API以应对不同任务需求 对于独立开发者或小型团队而言,构建一个具备智能能力的应用,…...

2026年度最新主流AI写作辅助平台综合排行
本次测评围绕综合运行性能、学术场景适配性、用户口碑反馈与功能完整性四大核心维度,对2026年市面上主流的AI论文辅助工具展开专业综合排序,依照各工具综合推荐分值由高至低进行排列,同时逐一解析每款工具的核心优势、特色亮点及适用场景。第…...

联想刃7000K BIOS高级配置优化指南:解锁隐藏参数设置与性能调优
联想刃7000K BIOS高级配置优化指南:解锁隐藏参数设置与性能调优 【免费下载链接】Lenovo-7000k-Unlock-BIOS Lenovo联想刃7000k2021-3060版解锁BIOS隐藏选项并提升为Admin权限 项目地址: https://gitcode.com/gh_mirrors/le/Lenovo-7000k-Unlock-BIOS 本文详…...