索引【MySQL】
文章目录
- 聚簇索引 VS 非聚簇索引
- 索引
- MySQL与磁盘交互的基本单位
- 主键索引
- 索引操作
- 唯一索引的创建
- 普通索引的创建
- 复合索引
- 索引创建原则
聚簇索引 VS 非聚簇索引
MyISAM存储引擎 - 主键索引结构
-
MyISAM存储引擎同样采用B+树作为索引的基本数据结构
-
与InnoDB存储引擎的B+树不同的是,MyISAM存储引擎的B+树的叶子结点存放的不是数据记录,而是数据记录对应的地址
下图为MyISAM存储引擎的主键索引结构,其中Col1为主键

MyISAM存储引擎 - 普通索引结构
- MyISAM存储引擎的普通索引采用的也是B+树结构,与主键索引唯一不同的地方就是普通索引的B+树中的键值可以重复。
- 因此一张表可能会同时存在多个B+树结构,但由于MyISAM存储引擎的B+树叶子结点中,存储的是对应的数据记录的地址,因此有效数据只会存储一份
下图为MyISAM存储引擎的普通索引结构,其中Col2为索引列

InnoDB存储引擎 - 普通索引结构
- InnoDB存储引擎的普通索引采用的也是B+树结构,但普通索引的B+树中的键值可以重复,并且B+树的叶子结点中存储的不是数据记录,而是对应数据记录的主键值。
- 当根据普通索引查询数据时,会先查找普通索引对应的B+树找到目标记录的主键值,然后再查找主键索引对应的B+树找到目标记录,这个过程就叫做回表查询
下图为InnoDB存储引擎的普通索引结构,其中Col3为索引列

InnoDB存储引擎的普通索引的B+树叶子结点中没有保存整条数据记录,是为了节省空间,因为同一张表可能会创建多个普通索引,每个普通索引的B+树中都保存一份数据会造成数据冗余,所以通过回表查询主键索引对应的B+来获取整个数据记录,该做法本质一种以时间换取空间的做法。
当根据普通索引查询数据时,其实也不一定需要进行回表查询,因为有可能我们要查询的就是这条记录对应的主键值,因此查询完普通索引对应B+树后即可完成查询。
采用InnoDB存储引擎建立的每张表都会有一个主键,就算用户没有设置,InnoDB也会自动帮你创建一个不可见的主键,因为完整数据记录只会存储在主键索引对应的B+树中的,因此采用InnoDB存储引擎建立的表必须有主键。
- 聚簇索引: 像InnoDB存储引擎这种,将数据记录与索引结构放在一起的索引方案,叫做聚簇索引。
- 非聚簇索引: 像MyISAM存储引擎这种,将数据记录与索引结构分离的索引方案,叫做非聚簇索引
采用InnoDB存储引擎创建表时,在数据库对应的目录下会新增两个文件

采用MyISAM存储引擎创建表时,在数据库对应的目录下会新增三个文件

采用InnoDB和MyISAM存储引擎创建表时都会生成xxx.frm文件,该文件中存储的是表结构相关的信息。
采用InnoDB存储引擎创建表时会生成一个xxx.ibd文件,该文件中存储的是索引和数据相关的信息,这就是聚簇索引,索引和数据是存储在同一个文件中的。
采用MyISAM存储引擎创建表时会生成一个xxx.MYD文件和一个xxx.MYI文件,其中xxx.MYD文件中存储的是数据相关的信息,而xxx.MYI文件中存储的是索引相关的信息,这就是非聚簇索引,索引和数据是分开存储的。
索引
MySQL与磁盘交互的基本单位
MySQL与磁盘交互的基本单位是16KB,这个基本数据单元在MySQL这里也叫做Page
show命令查看系统中的全局变量,可以看到InnoDB存储引擎交互的基本单位是16KB
mysql> show global status like 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| Innodb_page_size | 16384 |
+------------------+-------+
1 row in set (0.02 sec)16384 = 1024* 16
Buffer Pool
在MySQL中进行的各种CRUD时,需要先通过计算找到对应的操作位置,只要涉及计算就需要CPU参与,而冯诺依曼体系结构决定了CPU只能和内存打交道,为了便于CPU参与,就需要先将数据加载到内存当中
所以在特定的时间内,MySQL中的数据一定是同时存在于磁盘和内存中的,当操作完内存数据后,再以特定的刷新策略将内存中的数据刷新到磁盘当中,这时MySQL和磁盘进行数据交互的基本单位就是Page。
为了更好的支持上述操作,MySQL服务器在启动的时候会预先申请一块内存空间来进行各种缓存,这块内存空间叫做Buffer Pool,后续磁盘中加载的数据就会保存在Buffer Pool中,刷新数据时也就是将Buffer Pool中的数据刷新到磁盘。
由于内核中是有内核文件缓冲区的,因此MySQL从磁盘读取数据时,需要先将数据从磁盘读取到内核文件缓冲区,再将数据从内核缓冲区读取到Buffer Pool,MySQL将数据刷新到磁盘时,同样需要先将数据从Buffer Pool刷新到内核文件缓冲区,再将数据从内核文件缓冲区刷新到磁盘
操作系统和磁盘交互的基本单位是4KB,是指内核文件缓冲区与磁盘之间是以4KB为单位进行交互的。而MySQL的Buffer Pool和磁盘实际并不是直接交互的
MySQL与磁盘交互的基本单位是16KB,指的是MySQL的Buffer Pool与内核文件缓冲区之间是以16KB为单位进行交互的。只不过更关注的是MySQL和磁盘之间的关系,所以直接说的是MySQL与磁盘交互的基本单位是16KB,忽略了中间的内核缓冲区

主键索引
创建索引
mysql> select * from EMP limit 5 ;
+--------+--------+----------+------+---------------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+----------+------+---------------------+---------+--------+--------+
| 100002 | pfDDeM | SALESMAN | 0001 | 2024-11-07 00:00:00 | 2000.00 | 400.00 | 251 |
| 100003 | jvDEkm | SALESMAN | 0001 | 2024-11-07 00:00:00 | 2000.00 | 400.00 | 325 |
| 100004 | vlRzWk | SALESMAN | 0001 | 2024-11-07 00:00:00 | 2000.00 | 400.00 | 130 |
| 100005 | EjioUI | SALESMAN | 0001 | 2024-11-07 00:00:00 | 2000.00 | 400.00 | 332 |
| 100006 | lhdXzF | SALESMAN | 0001 | 2024-11-07 00:00:00 | 2000.00 | 400.00 | 293 |
+--------+--------+----------+------+---------------------+---------+--------+--------+
5 rows in set (0.00 sec)mysql> alter table EMP add index(empno) ;
Query OK, 0 rows affected (22.83 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> create table if not exists user ( id int primary key, age int not null, name varchar(16) not null );
Query OK, 0 rows affected (0.01 sec)mysql> desc user ;
+--------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| age | int(11) | NO | | NULL | |
| name | varchar(16) | NO | | NULL | |
+--------+-------------+------+-----+---------+-------+
3 rows in set (0.00 sec)
mysql> show create table user \G
*************************** 1. row ***************************Table: user
Create Table: CREATE TABLE `user` (` id` int(11) NOT NULL,`age` int(11) NOT NULL,` name` varchar(16) NOT NULL,PRIMARY KEY (` id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)mysql> insert into user( id, age, name) values(3, 18, '杨过');
Query OK, 1 row affected (0.00 sec)mysql> insert into user (id, age, name) values(4, 16, '小龙女');
Query OK, 1 row affected (0.00 sec)mysql> insert into user (id, age, name) values(2, 26, '黄蓉');
Query OK, 1 row affected (0.00 sec)mysql> insert into user (id, age, name) values(5, 36, '郭靖');
Query OK, 1 row affected (0.00 sec)mysql> insert into user (id, age, name) values(1, 56, '欧阳锋');
Query OK, 1 row affected (0.00 sec)mysql> select * from user;
+----+-----+-----------+
| id | age | name |
+----+-----+-----------+
| 1 | 56 | 欧阳锋 |
| 2 | 26 | 黄蓉 |
| 3 | 18 | 杨过 |
| 4 | 16 | 小龙女 |
| 5 | 36 | 郭靖 |
+----+-----+-----------+
5 rows in set (0.00 sec)查看表中的数据时,却发现显示出来的数据是按照主键进行有序排列的
之所以出现按照主键进行有序排列的现象,因为我们创建表时设置了主键,即便向表中插入数据时是乱序插入的,MySQL底层也会自动按照主键对插入的数据进行排序
如何理解MySQL与磁盘交互的基本单位是Page
查询表中的某一条记录时,如果MySQL只从磁盘中将这一条记录加载到内存当中,那么当继续查询表中的其他记录时,MySQL就一定需要再次与磁盘进行IO交互。
如果查询表中的某一条记录时,MySQL直接将这条记录所在的整个Page都加载到内存当中,那么继续查询表中的其他记录时,MySQL很可能就不再需要与磁盘进行IO交互了,因为这条记录很可能也在被加载进来的Page当中,这时直接在内存中进行查询即可,大大减少了IO的次数。
当然,不能保证用户下一次要访问的数据一定就在本次加载进来的Page当中,但是根据统计学原理,当一个数据正在被访问时,那么下一次有很大可能会访问其周围的数据(局部性原理),因此有较大概率保证用户下一次要访问的数据和本次访问的数据在同一个Page当中,如果局部性原理没有起作用,那就再把对应的Page加载到内存当中即可。
也就是说,MySQL与磁盘进行交互时以Page为基本单位,可以减少与磁盘IO交互的次数,进而提高IO的效率
索引操作
创建两个表test1,test2
mysql> create table test1 ( id int primary key , name varchar(20) not null )engine=innodb ;
Query OK, 0 rows affected (0.01 sec)mysql> desc test1 ;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | NO | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)mysql> show create table test1 \G
*************************** 1. row ***************************Table: test1
Create Table: CREATE TABLE `test1` (`id` int(11) NOT NULL,`name` varchar(20) NOT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)mysql> create table test2 ( id int primary key , name varchar(20) not null )engine=myisam ;
Query OK, 0 rows affected (0.00 sec)mysql> show create table test2 \G
*************************** 1. row ***************************Table: test2
Create Table: CREATE TABLE `test2` (`id` int(11) NOT NULL,`name` varchar(20) NOT NULL,PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1
1 row in set (0.01 sec)mysql> show tables;
+--------------------+
| Tables_in_index_db |
+--------------------+
| test1 |
| test2 |
+--------------------+
2 rows in set (0.00 sec)mysql> show index from test1\G
*************************** 1. row ***************************Table: test1Non_unique: 0Key_name: PRIMARYSeq_in_index: 1Column_name: idCollation: ACardinality: 0Sub_part: NULLPacked: NULLNull: Index_type: BTREEComment:
Index_comment: 删除索引
mysql> show tables;
+--------------------+
| Tables_in_index_db |
+--------------------+
| test1 |
| test2 |
+--------------------+
2 rows in set (0.00 sec)mysql> alter table test1 drop primary key ;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> show index from test1\G
Empty set (0.00 sec)mysql> desc test1;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | | NULL | |
| name | varchar(20) | NO | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)添加索引
mysql> alter table test1 add primary key(id) ;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> show index from test1\G
*************************** 1. row ***************************Table: test1Non_unique: 0Key_name: PRIMARYSeq_in_index: 1Column_name: idCollation: ACardinality: 0Sub_part: NULLPacked: NULLNull: Index_type: BTREEComment:
Index_comment:
1 row in set (0.00 sec)

主键索引的特点:
- 一个表中,最多有一个主键索引,可以使用复合主键
- 主键索引的效率高(主键不可重复)
- 创建主键索引的列,它的值不能为null,且不能重复
- 主键索引的列基本上是int
唯一索引的创建
mysql> alter table test1 add unique (name) ;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> desc test1 ;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | NO | UNI | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
唯一索引的删除
mysql> alter table test1 drop index name ;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
删除之后 ,只剩下一个主键索引了

普通索引的创建
普通索引的特点如下:
- 一个表中,可以有多个普通索引,一个普通索引可以由多个列同时承担。
- 创建普通索引的列,其列值可以为NULL,也可以重复。
第一种方式:
mysql> alter table test1 add index(name) ;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> desc test1;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | NO | MUL | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
普通索引的删除
mysql> alter table test1 drop index name ;
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0第二种方式:
mysql> create index myindex on test1(name) ;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> show index from test1\G
*************************** 1. row ***************************Table: test1Non_unique: 0Key_name: PRIMARYSeq_in_index: 1Column_name: idCollation: ACardinality: 0Sub_part: NULLPacked: NULLNull: Index_type: BTREEComment:
Index_comment:
*************************** 2. row ***************************Table: test1Non_unique: 1Key_name: myindexSeq_in_index: 1Column_name: nameCollation: ACardinality: 0Sub_part: NULLPacked: NULLNull: Index_type: BTREEComment:
Index_comment:
2 rows in set (0.00 sec)
普通索引的删除
mysql> alter table test1 drop index myindex ;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> show index from test1\G
*************************** 1. row ***************************Table: test1Non_unique: 0Key_name: PRIMARYSeq_in_index: 1Column_name: idCollation: ACardinality: 0Sub_part: NULLPacked: NULLNull: Index_type: BTREEComment:
Index_comment:
1 row in set (0.00 sec)复合索引
新增一列email, 再添加name和email为索引
mysql> alter table test1 add email varchar(30) not null after name ;
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0mysql> desc test1 ;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(20) | NO | | NULL | |
| email | varchar(30) | NO | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.01 sec)mysql> alter table test1 add index(name,email) ;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
name和emali这两列充当索引列 ,用这两列构建B+树, name和email使用的是同一颗B+树
删除name索引
mysql> alter table test1 drop index name ;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
第二种普通索引的创建
mysql> show index from test1\G
*************************** 1. row ***************************Table: test1Non_unique: 0Key_name: PRIMARYSeq_in_index: 1Column_name: idCollation: ACardinality: 0Sub_part: NULLPacked: NULLNull: Index_type: BTREEComment:
Index_comment:
1 row in set (0.00 sec)mysql> create index myindex on test1(name, email);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
索引的删除
mysql> alter table test1 drop index myindex;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0索引创建原则
比较频繁作为查询条件的字段应该创建索引
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
更新非常频繁的字段不适合作创建索引
不会出现在where子句中的字段不该创建索引
相关文章:
索引【MySQL】
文章目录 聚簇索引 VS 非聚簇索引索引MySQL与磁盘交互的基本单位主键索引索引操作唯一索引的创建普通索引的创建复合索引 索引创建原则 聚簇索引 VS 非聚簇索引 MyISAM存储引擎 - 主键索引结构 MyISAM存储引擎同样采用B树作为索引的基本数据结构 与InnoDB存储引擎的B树不同的…...

【Allure】mac下环境配置
安装 1.Mac 可以使用 brew 安装 allure,安装命令如下 brew install allure 2.与 pytest 结合需要安装 allure-pytest 插件: pip install allure-pytest3.查看allure版本 allure --version...

Android 开启混淆R8编译问题处理
Android R8是一个代码混淆和压缩工具,可以将应用程序的大小和安全性优化。它引入了一些新功能,如成员内省、混淆指针、类内省等。 但R8使用起来一直不友好,因为自从使用R8之后编译问题不断。主要还是和混淆相关,经常报错ÿ…...

Rust:GUI 开源框架
Rust的GUI代码包有多个选择,每个都有其独特的特点和优势。以下是一些比较受欢迎的Rust GUI库,以及它们的主要特点和适用场景: KAS GUI: 特点:基于Rust语言开发的状态化图形用户界面(GUI)框架&am…...

移远通信亮相骁龙AI PC生态科技日,以领先的5G及Wi-Fi产品革新PC用户体验
PC作为人们学习、办公、娱乐的重要工具,已经深度融入我们的工作和生活。随着物联网技术的快速发展,以及人们对PC性能要求的逐步提高,AI PC成为了行业发展的重要趋势。 11月7-8日,骁龙AI PC生态科技日在深圳举办。作为高通骁龙的重…...

力扣每日一题 3258. 统计满足 K 约束的子字符串数量 I
给你一个 二进制 字符串 s 和一个整数 k。 如果一个 二进制字符串 满足以下任一条件,则认为该字符串满足 k 约束: 字符串中 0 的数量最多为 k。字符串中 1 的数量最多为 k。 返回一个整数,表示 s 的所有满足 k 约束 的子字符串的数量。 如…...

SQL面试题——奔驰面试题
SQL面试题——奔驰SQL面试题 我们的表大致如下 CREATE TABLE signal_log( vin STRING COMMENTvehicle frame id, signal_name STRING COMMENTfunction name, signal_value STRING COMMENT signal value , ts BIGINT COMMENTevent timestamp, dt STRING COMMENTformat yyyy-mm…...
24.11.10 css
2.css语法结构 选择器{ 样式:样式值; 样式:样式值; } 3.css引入方式 如何在html页面中写css代码 1.页面中直接使用style标签 编写css 调试样式代码时使用<style> h1{color:red}</style>2.通过link标签 引入css文件 …...

git新手使用教程
git新手使用教程 一、安装和初始化配置2、新建仓库3.工作区域和文件状态4.添加和提交文件5 git reset回退版本6 使用git diff查看差异7 使用git rm删除文件8 .gitignore忽略文件9 注册GitHub账号10 SSH配置和克隆仓库11 关联本地仓库和远程仓库12 Gitee的使用 由B站视频教程整理…...

运维发展方向
作为一名运维工程师,我建议可以从以下几个方面规划职业发展: 1. 夯实基础知识 - Linux 系统管理与优化 - 网络协议和架构 - 数据库运维(MySQL、PostgreSQL等) - Shell 脚本编程 - Python/Go 等自动化语言 2. 掌握现代化工具 - 容器技术(Docker、Kubern…...

jmeter常用配置元件介绍总结之函数助手
系列文章目录 1.windows、linux安装jmeter及设置中文显示 2.jmeter常用配置元件介绍总结之安装插件 3.jmeter常用配置元件介绍总结之取样器 jmeter常用配置元件介绍总结之函数助手 1.进入函数助手对话框2.常用函数的使用介绍2.1.RandomFromMultipleVars函数2.2.Random函数2.3.R…...
Pytorch从0复现worc2vec skipgram模型及fasttext训练维基百科语料词向量演示
目录 Skipgram架构 代码开源声明 Pytorch复现Skip-gram 导包及随机种子设置 维基百科数据读取 建立词频元组列表并根据词频排序 建立词频字典,word_id字典,id_word字典 二次采样 正采样与负采样 Skipgram模型类 模型训练 词向量输出 近义词寻找 fasttext训练Skip-…...

fastapi 查询参数支持 Pydantic Model:参数校验与配置技巧
fastapi 查询参数支持 Pydantic Model:参数校验与配置技巧 本文介绍了 FastAPI 中通过 Pydantic model 声明查询参数的使用方法,提供了更加灵活和强大的参数校验方式。通过将查询参数定义在 Pydantic model 中,开发者可以对参数设置默认值、…...

mysql 大数据查询
基于 mysql 8.0 基础介绍 com.mysql.cj.protocol.ResultsetRows该接口表示的是应用层如何访问 db 返回回来的结果集 它有三个实现类 ResultsetRowsStatic 默认实现。连接 db 的 url 没有增加额外的参数、单纯就是 ip port schema 。 @Test public void generalQuery() t…...

如何在 Spring Boot 中利用 RocketMQ 实现批量消息消费
文章目录 准备工作项目依赖配置 RocketMQ生产批量消息消费批量消息测试批量消息发送和消费总结推荐阅读文章 RocketMQ 是一款分布式消息队列,支持高吞吐、低延迟的消息传递。对于需要一次处理多条消息的场景,RocketMQ 提供了批量消费的机制,这…...
推荐一个Star超过2K的.Net轻量级的CMS开源项目
推荐一个具有模块化和可扩展的架构的CMS开源项目。 01 项目简介 Piranha CMS是一个轻量级且跨平台的CMS库,专为.NET 8设计。 该项目提供多种模板,具备CMS基本功能,也有空模板方便从头开始构建新网站,甚至可以作为移动应用的后端…...
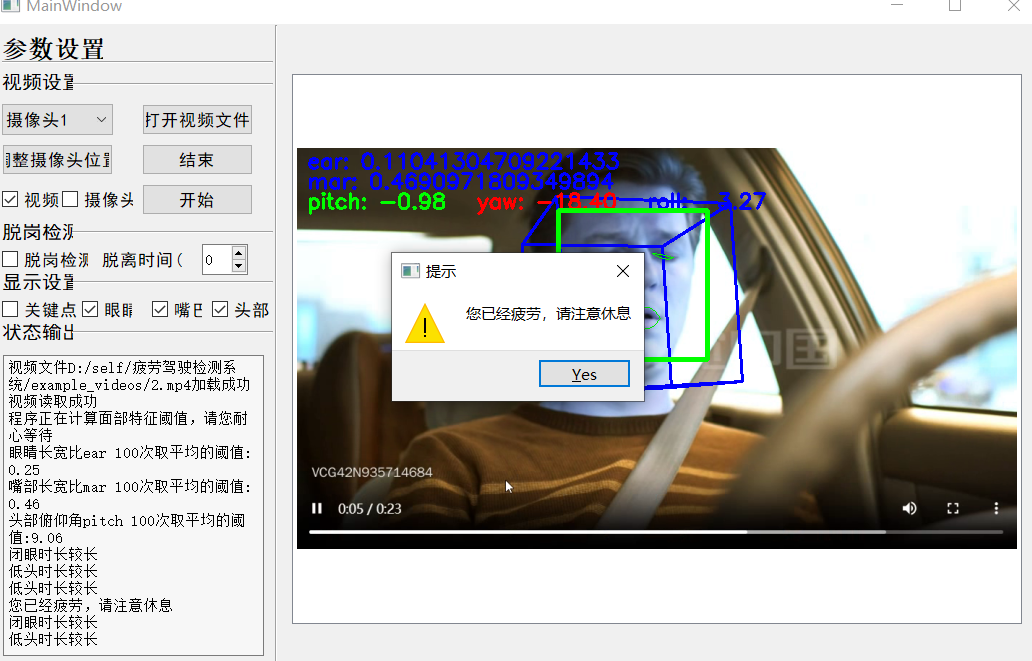
基于驾驶员面部特征的疲劳检测系统
大家好,本文是对基于驾驶员面部特征的疲劳检测系统源码的介绍与说明。 项目下载:基于驾驶员面部特征的疲劳检测系统 1.关于项目 疲劳驾驶检测系统通过监测驾驶人的眼睛状态,头部状态,嘴部状态等指标,识别出疲劳迹象…...
)
前端知识点---字符串的8种拼接方法(Javascript)
文章目录 01使用 运算符(改变了原始字符串)02使用 运算符(改变了原本的字符串)03 使用 concat() 方法(不改变原本的字符串)04使用模板字面量(不改变原本的字符串)05使用 join() 方法(不改变原本的字符串)①指定分隔符 ②没有指定…...

用 Python 从零开始创建神经网络(一):编码我们的第一个神经元
编码我们的第一个神经元 引言1. A Single Neuron:Example 1Example 2 2. A Layer of Neurons:Example 1 引言 本教程专为那些对神经网络已有基础了解、但尚未动手实践过的读者而设计。尽管网上充斥着各种教程,但很多内容要么过于简略&#x…...

低代码开发
低代码(Low Code)是一种软件开发方法,它通过可视化界面和少量的编码来快速构建应用程序。低代码平台的核心理念是通过抽象和最小化手工编码的方式,加速软件开发和部署的过程。 定义 低代码是一种软件开发方法,它允许…...

【DeepSeek推理加速实战指南】:20年AI系统优化专家亲授7大低开销部署技巧
更多请点击: https://kaifayun.com 第一章:DeepSeek推理加速的核心挑战与优化全景 DeepSeek系列大模型在实际部署中面临显著的推理延迟与显存压力,尤其在长上下文(如32K tokens)和高并发场景下,GPU利用率常…...

独立开发者如何借助 Taotoken 一站式管理多个项目的 AI 调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助 Taotoken 一站式管理多个项目的 AI 调用 对于独立开发者而言,同时维护多个项目是常态。每个项目可…...
:谷歌内部技术白皮书级拆解)
Gemini深度研究模式全解析(2024最新版API+多模态检索内参):谷歌内部技术白皮书级拆解
更多请点击: https://codechina.net 第一章:Gemini深度研究模式的核心定位与演进脉络 Gemini深度研究模式并非单纯的功能叠加,而是Google面向复杂知识工作场景构建的推理范式跃迁。它将多跳检索、跨模态证据聚合与可验证推理链生成深度融合&…...

FanControl终极指南:3步掌握Windows风扇控制,打造静音高效散热系统
FanControl终极指南:3步掌握Windows风扇控制,打造静音高效散热系统 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode…...

学术 PPT 创作提速方案:九款 AI 工具,轻松攻克毕业答辩制作难题
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPTAI PPT制作 - Okbiye智能写作https://www.okbiye.com/ppt 毕业答辩阶段,演示文稿制作成为多数学子耗时耗力的一大关卡。梳理论文脉络、匹配专业模板、规整内容排版、优化数据展示࿰…...

DeepXDE终极指南:如何用科学机器学习轻松求解物理方程
DeepXDE终极指南:如何用科学机器学习轻松求解物理方程 【免费下载链接】deepxde A library for scientific machine learning and physics-informed learning 项目地址: https://gitcode.com/gh_mirrors/de/deepxde DeepXDE是一款革命性的开源科学机器学习库…...

在个人项目中集成多模型API以应对不同任务需求
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在个人项目中集成多模型API以应对不同任务需求 对于独立开发者或小型团队而言,构建一个具备智能能力的应用,…...

CompressO:免费开源的终极视频压缩工具,一键将大文件变小90%
CompressO:免费开源的终极视频压缩工具,一键将大文件变小90% 【免费下载链接】compressO Convert any video/image into a tiny size. 100% free & open-source. Available for Mac, Windows & Linux. 项目地址: https://gitcode.com/gh_mirro…...

SLUSCHI+LAMMPS+LASP:机器学习势函数加速材料熔点高通量计算
1. 项目概述:当SLUSCHI遇见机器学习势函数在计算材料学的日常工作中,预测材料的熔点一直是个既关键又让人头疼的活。说它关键,是因为熔点直接关联着材料的加工性、热稳定性和服役性能,无论是设计下一代高温合金还是开发新型陶瓷&a…...

终极解决方案:如何用qmc-decoder快速解锁QQ音乐加密格式
终极解决方案:如何用qmc-decoder快速解锁QQ音乐加密格式 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经下载了QQ音乐,却发现那些.qmc3、…...