Jmeter中的监听器(一)
监听器
1--查看结果树
用途
- 调试测试计划:查看每个请求的详细信息,帮助调试和修正测试计划。
- 分析响应数据:查看服务器返回的响应数据,验证请求是否成功。
- 检查错误:识别和分析请求失败的原因。
配置步骤
-
添加查看结果树监听器
- 右键点击线程组(Thread Group)。
- 选择“添加” -> “监听器” -> “查看结果树”(View Results Tree)。
-
配置查看结果树监听器
- 名称:给查看结果树监听器一个有意义的名称。
- 保存响应数据:选择是否保存响应数据到文件。
- 响应数据文件:指定保存响应数据的文件路径(可选)。
- 高级选项:可以启用一些高级选项,如显示响应头、响应体等。
示例配置
假设我们需要测试一个Web应用,并使用“查看结果树”监听器来查看每个请求的详细信息。
-
创建测试计划:
- 右键点击“测试计划” -> 新建 -> 输入测试计划名称(例如“Web应用性能测试”)。
-
添加线程组:
- 右键点击测试计划 -> 添加 -> 线程组 -> 输入线程组名称(例如“用户模拟”)。
-
添加HTTP请求:
- 右键点击线程组 -> 添加 -> 取样器 -> HTTP请求。
- 配置HTTP请求:
- 名称:请求名称(例如“获取用户列表”)。
- 服务器名称或IP:目标服务器的地址(例如
example.com)。 - 端口号:目标服务器的端口(例如
80)。 - 协议:HTTP或HTTPS(例如
HTTP)。 - 方法:请求的方法(例如
GET)。 - 路径:请求的路径(例如
/api/users)。
-
添加查看结果树监听器:
- 右键点击线程组 -> 添加 -> 监听器 -> 查看结果树。
- 配置查看结果树监听器:
- 名称:查看结果树
- 保存响应数据:选择“否”(除非需要保存响应数据到文件)。
- 响应数据文件:(可选,留空)
-
运行测试:
- 点击工具栏上的“启动”按钮,运行测试。
-
查看结果:
- 在“查看结果树”监听器中,可以看到每个请求的详细信息,包括请求和响应的数据、响应代码、响应时间等。
- 请求标签:显示请求的基本信息,如请求名称、服务器地址、请求方法等。
- 请求数据:显示发送的请求数据。
- 响应数据:显示服务器返回的响应数据。
- 响应码:显示服务器返回的HTTP响应码。
- 响应时间:显示请求的响应时间。
- 响应头:显示服务器返回的响应头信息。
- 响应体:显示服务器返回的响应体内容。
优化建议
-
名称:
- 给监听器一个有意义的名称,以便在测试计划中容易识别。
-
保存响应数据:
- 如果不需要保存响应数据到文件,可以选择不保存,以减少磁盘空间占用。
-
高级选项:
- 启用“显示响应头”和“显示响应体”选项,可以查看更多的响应信息,有助于调试和分析。
-
性能影响:
- 注意“查看结果树”监听器会记录大量的详细信息,可能会对测试性能产生一定影响。在大规模性能测试中,建议使用其他轻量级的监听器,如“聚合报告”或“汇总报告”。
-
过滤请求:
- 如果测试计划中有大量请求,可以使用过滤功能,只查看特定的请求。
2--汇总报告
用途
- 性能评估:评估测试的整体性能,包括平均响应时间、吞吐量、错误率等。
- 数据分析:生成详细的统计数据,帮助分析测试结果。
- 报告生成:生成易于理解和分享的测试报告。
配置步骤
-
添加汇总报告监听器
- 右键点击线程组(Thread Group)。
- 选择“添加” -> “监听器” -> “汇总报告”(Summary Report)。
-
配置汇总报告监听器
- 名称:给汇总报告监听器一个有意义的名称。
- 文件:指定保存报告的文件路径(可选)。
- 其他选项:可以启用一些高级选项,如保存响应数据等。
示例配置
假设我们需要测试一个Web应用,并使用汇总报告监听器来生成测试结果的汇总统计信息。
-
创建测试计划:
- 右键点击“测试计划” -> 新建 -> 输入测试计划名称(例如“Web应用性能测试”)。
-
添加线程组:
- 右键点击测试计划 -> 添加 -> 线程组 -> 输入线程组名称(例如“用户模拟”)。
-
添加HTTP请求:
- 右键点击线程组 -> 添加 -> 取样器 -> HTTP请求。
- 配置HTTP请求:
- 名称:请求名称(例如“获取用户列表”)。
- 服务器名称或IP:目标服务器的地址(例如
example.com)。 - 端口号:目标服务器的端口(例如
80)。 - 协议:HTTP或HTTPS(例如
HTTP)。 - 方法:请求的方法(例如
GET)。 - 路径:请求的路径(例如
/api/users)。
-
添加汇总报告监听器:
- 右键点击线程组 -> 添加 -> 监听器 -> 汇总报告。
- 配置汇总报告监听器:
- 名称:汇总报告
- 文件:(可选,指定保存报告的文件路径,例如
C:\reports\summary_report.csv)
-
运行测试:
- 点击工具栏上的“启动”按钮,运行测试。
-
查看报告:
- 在“汇总报告”监听器中,可以看到每个请求的汇总统计信息,包括以下列:
- Label:请求的标签名称。
- # Samples:请求的样本数量。
- Average:平均响应时间(毫秒)。
- Min:最小响应时间(毫秒)。
- Max:最大响应时间(毫秒)。
- Error %:错误率(百分比)。
- Throughput:吞吐量(每秒请求数)。
- KB/sec:每秒传输的数据量(千字节)。
- 在“汇总报告”监听器中,可以看到每个请求的汇总统计信息,包括以下列:
优化建议
-
名称:
- 给监听器一个有意义的名称,以便在测试计划中容易识别。
-
文件保存:
- 如果需要保存报告到文件,确保指定的文件路径有效。保存为CSV格式的文件便于后续分析和处理。
-
性能影响:
- 汇总报告监听器对性能的影响较小,适合在大规模性能测试中使用。
-
过滤请求:
- 如果测试计划中有大量请求,可以使用过滤功能,只查看特定的请求。
-
多线程组:
- 如果测试计划中包含多个线程组,可以在每个线程组中添加汇总报告监听器,分别生成各自的报告。
-
综合分析:
- 结合其他监听器(如“查看结果树”、“聚合报告”等)一起使用,可以更全面地分析测试结果。
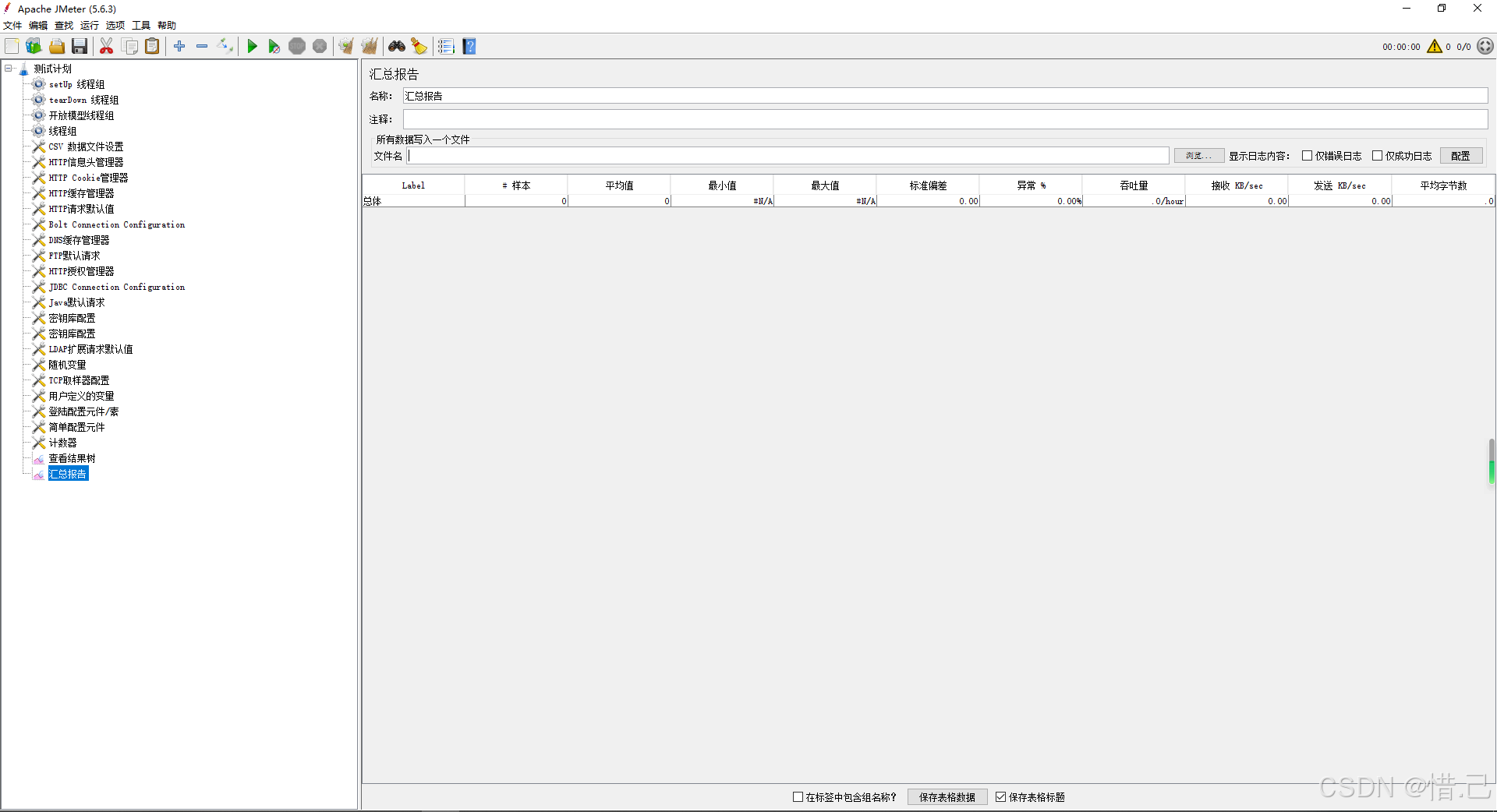
3--聚合报告
用途
- 性能评估:评估测试的整体性能,包括平均响应时间、中位数、标准差、错误率等。
- 数据分析:生成详细的统计数据,帮助分析测试结果。
- 报告生成:生成易于理解和分享的测试报告。
配置步骤
-
添加聚合报告监听器
- 右键点击线程组(Thread Group)。
- 选择“添加” -> “监听器” -> “聚合报告”(Aggregate Report)。
-
配置聚合报告监听器
- 名称:给聚合报告监听器一个有意义的名称。
- 文件:指定保存报告的文件路径(可选)。
- 其他选项:可以启用一些高级选项,如保存响应数据等。
示例配置
假设我们需要测试一个Web应用,并使用聚合报告监听器来生成测试结果的详细统计信息。
-
创建测试计划:
- 右键点击“测试计划” -> 新建 -> 输入测试计划名称(例如“Web应用性能测试”)。
-
添加线程组:
- 右键点击测试计划 -> 添加 -> 线程组 -> 输入线程组名称(例如“用户模拟”)。
-
添加HTTP请求:
- 右键点击线程组 -> 添加 -> 取样器 -> HTTP请求。
- 配置HTTP请求:
- 名称:请求名称(例如“获取用户列表”)。
- 服务器名称或IP:目标服务器的地址(例如
example.com)。 - 端口号:目标服务器的端口(例如
80)。 - 协议:HTTP或HTTPS(例如
HTTP)。 - 方法:请求的方法(例如
GET)。 - 路径:请求的路径(例如
/api/users)。
-
添加聚合报告监听器:
- 右键点击线程组 -> 添加 -> 监听器 -> 聚合报告。
- 配置聚合报告监听器:
- 名称:聚合报告
- 文件:(可选,指定保存报告的文件路径,例如
C:\reports\aggregate_report.csv)
-
运行测试:
- 点击工具栏上的“启动”按钮,运行测试。
-
查看报告:
- 在“聚合报告”监听器中,可以看到每个请求的详细统计信息,包括以下列:
- Label:请求的标签名称。
- # Samples:请求的样本数量。
- Average:平均响应时间(毫秒)。
- Median:中位数响应时间(毫秒)。
- 90% Line:90%的响应时间(毫秒)。
- Min:最小响应时间(毫秒)。
- Max:最大响应时间(毫秒)。
- Error %:错误率(百分比)。
- Throughput:吞吐量(每秒请求数)。
- KB/sec:每秒传输的数据量(千字节)。
- Std Dev:标准差(响应时间的标准差)。
- 在“聚合报告”监听器中,可以看到每个请求的详细统计信息,包括以下列:
优化建议
-
名称:
- 给监听器一个有意义的名称,以便在测试计划中容易识别。
-
文件保存:
- 如果需要保存报告到文件,确保指定的文件路径有效。保存为CSV格式的文件便于后续分析和处理。
-
性能影响:
- 聚合报告监听器对性能的影响较小,适合在大规模性能测试中使用。
-
过滤请求:
- 如果测试计划中有大量请求,可以使用过滤功能,只查看特定的请求。
-
多线程组:
- 如果测试计划中包含多个线程组,可以在每个线程组中添加聚合报告监听器,分别生成各自的报告。
-
综合分析:
- 结合其他监听器(如“查看结果树”、“汇总报告”等)一起使用,可以更全面地分析测试结果。
常见统计术语解释
- Label:请求的标签名称,用于标识不同的请求。
- # Samples:请求的样本数量,即该请求被发送的次数。
- Average:平均响应时间,所有样本的响应时间的平均值。
- Median:中位数响应时间,所有样本的响应时间的中间值。
- 90% Line:90%的响应时间,表示90%的请求的响应时间不超过这个值。
- Min:最小响应时间,所有样本中的最小值。
- Max:最大响应时间,所有样本中的最大值。
- Error %:错误率,表示请求失败的比例。
- Throughput:吞吐量,每秒处理的请求数。
- KB/sec:每秒传输的数据量,单位为千字节。
- Std Dev:标准差,表示响应时间的离散程度,标准差越大表示响应时间的波动越大。
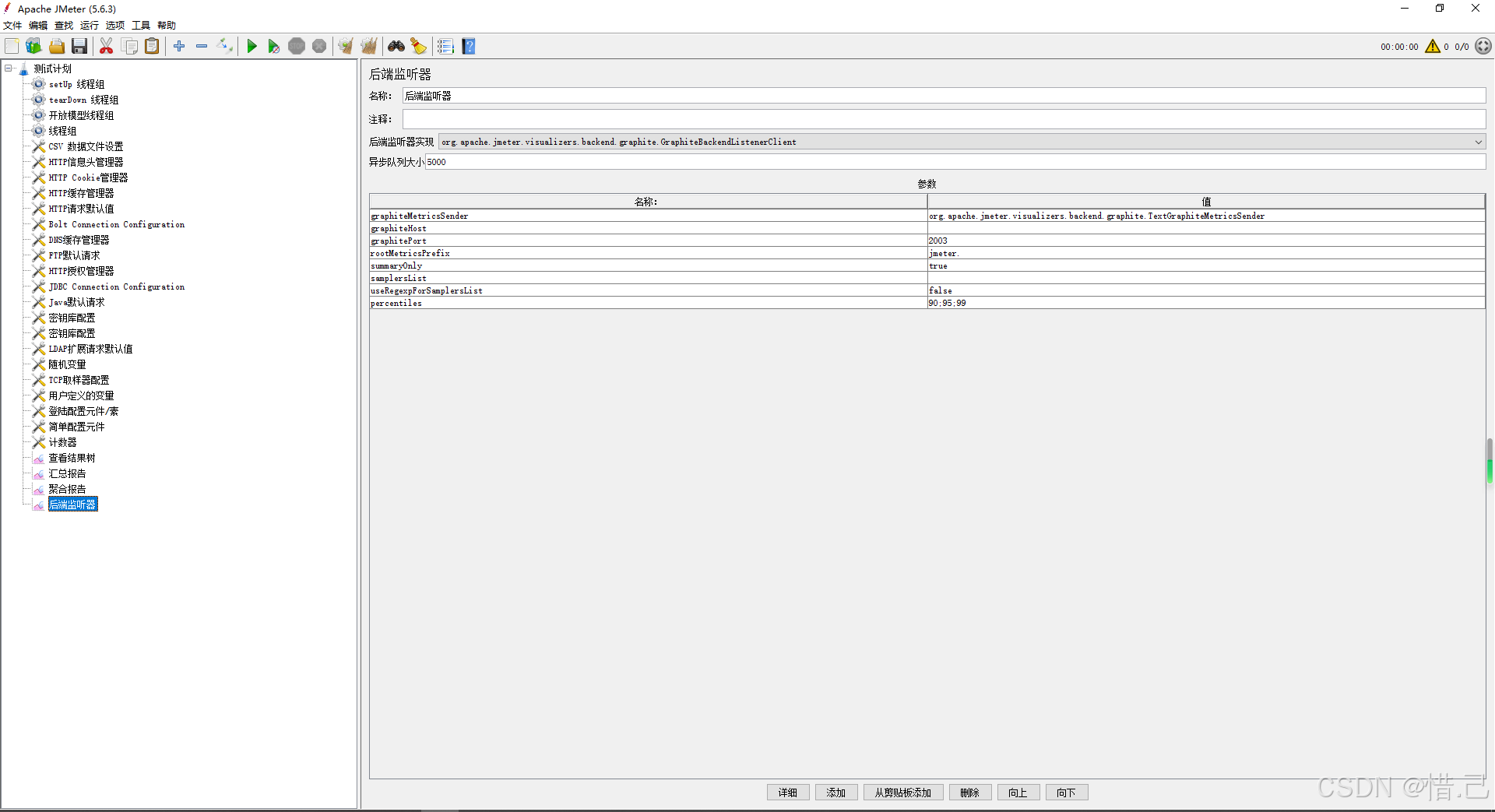
4--后端监听器
用途
- 实时监控:将测试结果实时发送到外部系统,实现实时监控。
- 数据存储:将测试结果存储到外部数据库,便于后续分析。
- 集成工具:与各种数据存储和分析工具集成,扩展JMeter的功能。
支持的后端系统
- InfluxDB:一个开源的时间序列数据库,适合存储和查询时间序列数据。
- Graphite:一个开源的度量数据存储和绘图工具。
- TSDB:Telegraf、InfluxDB、Chronograf、Kapacitor等组成的监控解决方案。
- 其他自定义后端:可以通过编写自定义脚本或插件支持其他后端系统。
配置步骤
-
添加后端监听器
- 右键点击线程组(Thread Group)。
- 选择“添加” -> “监听器” -> “后端监听器”(Backend Listener)。
-
配置后端监听器
- 名称:给后端监听器一个有意义的名称。
- 实现类:选择后端监听器的具体实现类(例如
org.apache.jmeter.visualizers.backend.influxdb.InfluxdbBackendListenerClient)。 - 数据库URL:后端系统的URL(例如
http://localhost:8086)。 - 数据库名称:后端数据库的名称(例如
jmeter)。 - 保留策略:后端数据库的保留策略(例如
autogen)。 - 测量名称:存储数据的测量名称(例如
response_times)。 - 用户名:后端系统的用户名(如果需要)。
- 密码:后端系统的密码(如果需要)。
- 采样间隔:发送数据的间隔时间(毫秒)。
- 批处理大小:每次发送的数据条数。
- 其他选项:根据需要配置其他选项,如标签、字段等。
示例配置
假设我们需要将测试结果实时发送到InfluxDB进行监控和分析。
-
创建测试计划:
- 右键点击“测试计划” -> 新建 -> 输入测试计划名称(例如“Web应用性能测试”)。
-
添加线程组:
- 右键点击测试计划 -> 添加 -> 线程组 -> 输入线程组名称(例如“用户模拟”)。
-
添加HTTP请求:
- 右键点击线程组 -> 添加 -> 取样器 -> HTTP请求。
- 配置HTTP请求:
- 名称:请求名称(例如“获取用户列表”)。
- 服务器名称或IP:目标服务器的地址(例如
example.com)。 - 端口号:目标服务器的端口(例如
80)。 - 协议:HTTP或HTTPS(例如
HTTP)。 - 方法:请求的方法(例如
GET)。 - 路径:请求的路径(例如
/api/users)。
-
添加后端监听器:
- 右键点击线程组 -> 添加 -> 监听器 -> 后端监听器。
- 配置后端监听器:
- 名称:后端监听器
- 实现类:
org.apache.jmeter.visualizers.backend.influxdb.InfluxdbBackendListenerClient - 数据库URL:
http://localhost:8086 - 数据库名称:
jmeter - 保留策略:
autogen - 测量名称:
response_times - 用户名:(如果需要,填写InfluxDB的用户名)
- 密码:(如果需要,填写InfluxDB的密码)
- 采样间隔:1000(每秒发送一次数据)
- 批处理大小:100(每次发送100条数据)
-
运行测试:
- 点击工具栏上的“启动”按钮,运行测试。
-
查看结果:
- 打开InfluxDB的Web界面或使用命令行工具,查看存储的数据。
- 使用Grafana等可视化工具,创建仪表板展示测试结果。
优化建议
-
名称:
- 给监听器一个有意义的名称,以便在测试计划中容易识别。
-
实现类:
- 根据使用的后端系统选择合适的实现类。
-
数据库URL和名称:
- 确保数据库URL和名称的正确性,避免因配置错误导致数据无法发送。
-
保留策略:
- 根据需要选择合适的保留策略,确保数据的持久性和性能。
-
测量名称:
- 选择合适的测量名称,以便在后端系统中容易识别和查询。
-
采样间隔和批处理大小:
- 根据测试需求和后端系统的性能,调整采样间隔和批处理大小,确保数据发送的频率和批量大小合适。
-
安全性:
- 如果后端系统需要认证,确保填写正确的用户名和密码。
-
性能影响:
- 注意后端监听器可能会对测试性能产生一定影响,特别是在大规模性能测试中。可以通过调整采样间隔和批处理大小来优化性能。
相关文章:
Jmeter中的监听器(一)
监听器 1--查看结果树 用途 调试测试计划:查看每个请求的详细信息,帮助调试和修正测试计划。分析响应数据:查看服务器返回的响应数据,验证请求是否成功。检查错误:识别和分析请求失败的原因。 配置步骤 添加查看结果…...

C++ 标准库 std::vector 的介绍
std::vector 是 C 标准库中的一个动态数组容器,它提供了多种成员函数来管理其内部存储的元素。以下是一些常用的 std::vector 成员函数的介绍: 构造函数和析构函数 vector(): 默认构造函数。vector(size_type n): 构造一个包含 n 个元素的向量…...

鸿蒙开发-装饰器@Link问题
正常示例 class Parent {public count: number;constructor( count: number) {this.count count;} } Entry Component struct TestPage {State parent: Parent new Parent( 11)build() {Column() {SubComponent({ parent: this.parent })}.height(100%)} } Component struct…...

CTFhub靶场RCE学习
靶场 eval执行 <?php if (isset($_REQUEST[cmd])) {eval($_REQUEST["cmd"]); } else {highlight_file(__FILE__); } ?> PHP代码显示,要求将命令赋值给cmd然后执行 先查看一下根目录文件 ?cmdsystem("ls");!切记最后的分…...

一文3000字从0到1带你进行Mock测试(建议收藏)
什么是mock? mock测试是以可控的方式模拟真实的对象行为。程序员通常创造模拟对象来测试对象本身该具备的行为,很类似汽车设计者使用碰撞测试假人来模拟车辆碰撞中人的动态行为 为什么要使用Mock? 之所以使用mock测试,是因…...

数据结构 ——— 链式二叉树的销毁(释放)
目录 链式二叉树示意图 手搓一个链式二叉树 代码实现 示意图 手搓一个链式二叉树 代码演示: // 数据类型 typedef int BTDataType;// 二叉树节点的结构 typedef struct BinaryTreeNode {BTDataType data; //每个节点的数据struct BinaryTreeNode* left; //指向…...

log4j异常堆栈文件输出
目的:log4j异常堆栈关联到traceId一句话中,方便搜索 1、获取堆栈后一起打印 private void logException(Throwable t, ProceedingJoinPoint joinPoint) {if (this.printErrorStackSys) {StringWriter sw new StringWriter();PrintWriter pw new Print…...

在配置环境变量之后使用Maven报错 : mvn : 无法将“mvn”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。
最近,我在 Windows 系统上安装和配置 Apache Maven 时遇到了一些问题,想在此记录下我的解决历程,希望对遇到类似问题的朋友有所帮助。 问题描述 我下载了 Maven 并按照常规步骤配置了相关的环境变量。然而,在 PowerShell 中输入…...

SpringSecurity源码中核心类
SpringSecurity源码 第一部分 核心类 SecurityBuilderHttpSecurityWebSecuritySecurityFilterChainFilterChainProxy SecurityBuilder是安全构架器,HttpSecurity和WebSecurity都是SecurityBuilder的实现类,HttpSecurity通过build()构建了一个Security…...

【JAVA】使用IDEA创建maven聚合项目
【JAVA】使用IDEA创建maven聚合项目 1.效果图 2.创建父模块项目 2.1删除父模块下面的src目录以及不需要的maven依赖 3创建子模块项目 3.1右击父模块项目选择Module… 3.2创建子模块 3.3删除子模块下不需要的maven依赖 4.子模块创建完成后引入SpringBoot依赖启动项目...

猿创征文|Inscode桌面IDE:打造高效开发新体验
猿创征文|Inscode桌面IDE:打造高效开发新体验 引言 在当今快速发展的软件开发领域,一个高效、易用的集成开发环境(IDE)是每个开发者必不可少的工具。Inscode 桌面 IDE 作为一款新兴的开发工具,凭借其强大…...

概率论中的PMF、PDF和CDF
在概率论中,PMF(概率质量函数)、PDF(概率密度函数)和CDF(累积分布函数)是描述随机变量分布的三个重要概念。它们分别用于不同类型的随机变量,并帮助我们理解随机事件的概率特性。本文…...

Vue 简单入手
前端工程化(Front-end Engineering)指的是在前端开发中,通过一系列工具、流程和规范的整合,以提高开发效率、代码质量和可维护性的一种技术和实践方法。其核心目的是使得前端开发变得更高效、可扩展和可维护。 文章目录 一、Vue 项…...

Github配置ssh key原理及操作步骤
文章目录 配置SSH第一步:检查本地主机是否已经存在ssh key第二步:生成ssh key第三步:获取ssh key公钥内容第四步:Github账号上添加公钥第五步:验证是否设置成功验证原理 往github上push项目的时候,如果走ht…...

大循环引起CPU负载过高
一、问题背景 环境:jdk1.8 tomcat7 在一次发布时,cpu出现负载过高,其负载突破200%,并且响应时间也大幅度超时。 二、问题分析 【1】发布前做过压测,并没有发现cpu异常升高的现象,所以其可能与生产环境的请…...
[Java]微服务治理
注册中心原理 注册中心可以统一管理项目中的所有服务 服务治理中的三个角色分别是什么? 服务提供者: 暴露服务接口,供其它服务调用服务消费者: 调用其它服务提供的接口注册中心: 记录并监控微服务各实例状态,推送服务变更信息 消费者如何知道提供者的…...

深入解析C语言中的extern关键字:语法、工作原理与高级应用技巧
引言 在C语言中,extern 关键字是一个强大的工具,用于声明外部变量和函数,使得这些变量和函数可以在多个源文件之间共享。理解 extern 的工作原理和最佳实践对于编写模块化、可维护的代码至关重要。本文将深入探讨 extern 关键字的各个方面&a…...

元器件封装
元器件封装类型 为什么越来越多用贴片元件,而不是插件元件 为什么越来越多用贴片元件,而不是插件元件 1.体积小、质量小、容易保存和运输; 2.容易焊接和拆卸。抗震效果好。 贴片元件不用过孔,用锡少。直插元件最麻烦的就是拆卸&a…...

状态空间方程离散化(Matlab符号函数)卡尔曼
// 卡尔曼滤波(4):扩展卡尔曼滤波 - 知乎 // // matlab 连续系统状态空间表达式的离散化&状态转移矩阵求解_matlab状态方程离散化-CSDN博客 // // // %https://blog.csdn.net/weixin_44051006/article/details/107007916 clear all; clc; syms R1 R2 C1 C…...

软件设计师-计算机网络
OSI网络模型 物理层,提供原始物理通路。数据交换的单位是二进制,bit,比特流,设备有中继器,集线器数据连输层,把原始不可靠的物理层链接变成无差错的数据通道,并解决多用户竞争问题。传送单位是帧ÿ…...

非参数贝叶斯聚类与核主成分分析:从原理到工程实践
1. 项目概述:从数据分组到降维的工程实践在数据科学和机器学习的日常工作中,我们常常面临两大核心挑战:一是如何从一堆看似杂乱无章的数据点中,发现其内在的、有意义的组别结构;二是当数据维度高到令人眼花缭乱时&…...

ml_edm:基于成本敏感的时间序列早期分类Python工具包详解
1. 项目概述在工业监控、医疗诊断和金融风控这些领域,我们常常面对一个共同的困境:数据是随着时间一点点“流”进来的,但决策却不能等到所有数据都齐备了再做。比如,一台设备传感器传回的振动信号刚开始出现异常,你是立…...

鸿蒙electron跨端框架PC墨案写作实战:把 Markdown 正文区做成桌面写作的中心
前言 欢迎加入鸿蒙PC开发者社区,共同打造开发者工具生态:鸿蒙PC开发者社区 :https://harmonypc.csdn.net/ 项目开源地址:https://AtomGit.com/lqjmac/ele-moanxiezuo 墨案写作这个小工具看起来轻,但真正落地时要先把…...

随机计算与ViT硬件加速:混合架构如何突破AI芯片能效墙
1. 项目概述:当ViT遇见随机计算最近在硬件加速领域,一个名为“ASCEND”的项目引起了我的注意。这本质上是一个专门为Vision Transformer(ViT)模型设计的硬件加速器,但其核心创新点在于采用了“随机计算”这种非常规的电…...

统计学习理论:从VC维到泛化误差,构建稳健CV系统的数学基石
1. 项目概述:从“炼丹”到“建楼”的范式转变在计算机视觉和机器学习这个圈子里混了十几年,我见过太多“炼丹”的场景了。大家热衷于调参、换模型、堆数据,一个模型效果好,大家就一拥而上,但很少有人能说清楚它为什么好…...

8051单片机PDATA与XDATA存储访问优化解析
1. PDATA与XDATA变量生成的指令解析在8051单片机开发中,外部数据存储器的访问方式直接影响程序效率和硬件设计。作为从业十余年的嵌入式工程师,我经常需要针对不同存储区域优化代码。PDATA和XDATA作为两种常见的外部数据存储模式,其指令生成机…...

【字节跳动】Robix系统的底层技术参数配置
Robix 绝密底层裸数据 无修饰纯技术续档一、地址总线时序剥离源码 void addr_bus_timing_restore(void) {setup_hold_time_clr();strobe_delay_cancel();bus_wait_state_disable();addr_valid_mask_null(); } 总线时序原生参数地址建立保持时间清零 读写选通脉冲延时全部取消 总…...

【2024最严合规落地清单】:金融/医疗/政务三大强监管行业AI Agent设计红线与审计通关模板
更多请点击: https://intelliparadigm.com 第一章:AI Agent设计行业应用 AI Agent正从实验室原型快速演进为可部署、可编排、可审计的企业级智能体系统,其核心价值在于将大语言模型能力封装为具备目标导向、工具调用、记忆管理与自主决策能力…...

Hermes Agent 总记不住你说的话?3 步治好 AI 助手的“健忘症“
你有没有这样的经历:你跟它说"每次写营销文章,记得先加载技能审核",它答应得好好的。结果下一篇写出来,你又得说一遍同样的话。它就像一个只点头不记事的实习生——每轮对话都重头来过。又或者,昨天刚刚聊完…...
)
别再手动跑Jupyter了!Lindy标准化流程强制接管你的分析工作流(仅剩最后23个企业未迁移)
更多请点击: https://codechina.net 第一章:Lindy数据分析自动化流程的演进逻辑与核心价值 Lindy效应指出,一个事物的预期剩余寿命与其当前已存在时间成正比——在数据分析领域,这一原理映射为:越经受住多轮业务迭代、…...