PostgreSQL中的COPY命令:高效数据导入与导出
在PostgreSQL数据库中,数据导入和导出是日常工作中常见的操作。传统的插入(INSERT)方法虽然可以实现数据的导入,但在处理大量数据时效率较低。而COPY命令则提供了一个快速、高效的方式来完成这一任务。COPY命令不仅可以用于将数据从文件导入到表中,还可以将表中的数据导出到文件中,支持多种文件格式,如TEXT、BINARY和CSV。通过使用COPY命令,可以大大提高数据导入和导出的效率,尤其是在处理大量数据时。
一、引言
数据的导入与导出在数据库操作中的重要性:
数据库作为存储和管理数据的核心组件,其数据的导入和导出操作对于维护数据完整性、实现数据迁移、备份和恢复等任务至关重要。无论是对于大型企业还是个人用户,数据的导入和导出都是日常数据库操作中不可或缺的一部分。
传统数据导入方法的局限性:
传统的插入(INSERT)方法虽然可以实现数据的导入,但在处理大量数据时效率较低,且容易出错。
导入大量数据时,需要编写大量的SQL语句,这不仅耗时,而且容易引发错误。
对于数据的格式和一致性检查,传统方法也缺乏足够的自动化和灵活性。
COPY命令的引入及其优势:
COPY命令为PostgreSQL数据库提供了一种快速、高效的数据导入和导出方法。
它支持多种格式,如TEXT、BINARY和CSV,可以根据实际需求选择合适的格式。
COPY命令可以直接从文件导入数据到表,或将表中的数据导出到文件,大大提高了数据导入和导出的效率。
与传统方法相比,COPY命令具有更高的自动化程度,能够减少人工错误,提高数据导入和导出的准确性。
二、COPY命令的基础
COPY命令概述:
COPY命令是PostgreSQL中用于高效导入和导出数据的命令。它支持从文件导入数据到表,或将表中的数据导出到文件。COPY命令可以处理文本、二进制和CSV格式的数据。支持的格式:TEXT、BINARY和CSV:
TEXT格式:适用于纯文本数据,每个字段由分隔符分隔。BINARY格式:适用于二进制数据,例如图像、音频和视频等。CSV格式:以逗号分隔值(Comma Separated Values)的形式存储数据,易于阅读和编辑。
数据的来源和去向:
- 数据来源可以是本地文件、远程文件或通过网络传输的数据流。
- 数据去向可以是本地文件、远程文件或通过网络发送的数据流。
通过COPY命令,我们可以将数据库中的数据导出到文件,或者从文件导入数据到数据库表中。
三、COPY命令的用法
将数据从表导出到文件
a. 语法示例:
COPY { table_name [ ( column_name [, ...] ) ] | ( query ) }
TO { 'filename' | PROGRAM 'command' | STDOUT }
[ [ WITH ] ( option [, ...] ) ]
b. 参数解释:
table_name:要导出数据的表名。column_name:可选,指定要导出的列名。filename:要导出的数据文件的路径。PROGRAM 'command':可选,指定执行命令以发送数据。STDOUT:将数据发送到标准输出流。option:可选,指定COPY命令的选项,如格式、分隔符、编码等。
c. 注意事项:
- 确保文件存在且可写。
- 根据需要选择正确的格式和分隔符。
- 注意文件路径的权限和所有权。
示例:
创建一个表并插入1000000条数据
postgres=# create table test_big(id int,name varchar(50));
CREATE TABLE
postgres=# insert into test_big select n,'test_name' from generate_series(1,1000000) as n;
INSERT 0 1000000
postgres=# select count(*) from test_big;count
---------1000000
(1 row)默认不带条件导出
postgres=# \copy test_big to '/home/postgres/test_big.sql'
COPY 1000000查看导出的数据文件
[postgres@pcp ~]$ cat test_big.sql |more
1 test_name
2 test_name
3 test_name
4 test_name
5 test_name
6 test_name
7 test_name
8 test_name
...
导出文件带字段名
如果需要把列名也打出来,可以加 with csv header;
postgres=# \copy test_big to '/home/postgres/test_big2.sql' with csv header;
COPY 1000000查看数据文件内容,可以看到第一行是表的字段名
[postgres@pcp ~]$ cat test_big2.sql |more
id,name
1,test_name
2,test_name
3,test_name
4,test_name
5,test_name
6,test_name
7,test_name
8,test_name
...
导出文件自定义数据分割符
如果想把这个逗号改成其他分隔符,可以使用delimiter关键字:
postgres=# \copy test_big to '/home/postgres/test_big3.sql' with csv header delimiter '|';
COPY 1000000查看数据文件内容:
[postgres@pcp ~]$ cat test_big3.sql |more
id|name
1|test_name
2|test_name
3|test_name
4|test_name
5|test_name
6|test_name
7|test_name
8|test_name
...
导出部分数据
如果只想导出表中的部分数据,可以这样操作:
postgres=# \copy (select * from test_big limit 10) to '/home/postgres/test_big4.sql' with csv header delimiter '|';
COPY 10查看文件内容:
[postgres@pcp ~]$ cat test_big4.sql
id|name
1|test_name
2|test_name
3|test_name
4|test_name
5|test_name
6|test_name
7|test_name
8|test_name
9|test_name
10|test_name可以看到只有10条数据,导出的条件可以根据sql自己定义。
更多语法可以通过\h copy查看
postgres=# \h copy
Command: COPY
Description: copy data between a file and a table
Syntax:
COPY table_name [ ( column_name [, ...] ) ]FROM { 'filename' | PROGRAM 'command' | STDIN }[ [ WITH ] ( option [, ...] ) ][ WHERE condition ]COPY { table_name [ ( column_name [, ...] ) ] | ( query ) }TO { 'filename' | PROGRAM 'command' | STDOUT }[ [ WITH ] ( option [, ...] ) ]where option can be one of:FORMAT format_nameFREEZE [ boolean ]DELIMITER 'delimiter_character'NULL 'null_string'HEADER [ boolean | MATCH ]QUOTE 'quote_character'ESCAPE 'escape_character'FORCE_QUOTE { ( column_name [, ...] ) | * }FORCE_NOT_NULL ( column_name [, ...] )FORCE_NULL ( column_name [, ...] )ENCODING 'encoding_name'URL: https://www.postgresql.org/docs/15/sql-copy.html将数据从文件导入到表
a. 语法示例:
COPY table_name [ ( column_name [, ...] ) ]
FROM { 'filename' | PROGRAM 'command' | STDIN }
[ [ WITH ] ( option [, ...] ) ]
b. 参数解释:
table_name:要导入数据的表名。column_name:可选,指定要导入的列名。filename:要导入的数据文件的路径。PROGRAM 'command':可选,指定执行命令以获取数据。STDIN:从标准输入流读取数据。option:可选,指定COPY命令的选项,如格式、分隔符、编码等。
c. 注意事项:
- 确保数据文件与数据库中的表结构匹配。
- 根据需要选择正确的格式和分隔符。
- 确保数据文件存在且可读。
示例
从刚才导出的文件中导入数据。先创建一个空表
postgres=# create table test_copy(id int,name varchar(50));
CREATE TABLE导入数据,按照刚才导出的顺序,先导入第一个文件test_big.sql,不带列名的
postgres=# \copy test_copy from '/home/postgres/test_big.sql';
COPY 1000000
postgres=# select count(*) from test_copy;count
---------1000000
(1 row)导入第二个文件test_big2.sql,文件里面数据带列名。
postgres=# \copy test_copy from '/home/postgres/test_big2.sql' with csv header;
COPY 1000000
postgres=# select count(*) from test_copy;count
---------2000000
(1 row)导入第三个文件test_big3.sql,文件数据带列名且分割符自定义类型。
postgres=# \copy test_copy from '/home/postgres/test_big3.sql' with csv header delimiter '|';
COPY 1000000
postgres=# select count(*) from test_copy;count
---------3000000
(1 row)全部成功导入,总结一下
怎样导出的,就可以怎样导入
注意点
使用COPY命令进行数据导入或导出时,如果操作被中断(例如通过按Ctrl+C),其行为会依赖于COPY命令的具体执行方式以及你的操作环境。
使用psql命令行工具:
如果你使用psql命令行工具并运行\COPY命令,那么当操作被中断时,通常psql会停止并可能显示错误消息。但是,已经成功传输到数据库的数据不会被回滚,而已经读取但尚未传输到数据库的数据可能会留在psql的缓冲区中。
如果你使用的是psql的\COPY命令,并且数据是通过管道(pipe)从另一个程序读取的,那么当操作被中断时,这个管道会被关闭,但已经读取的数据仍然可能留在psql的缓冲区中。
使用COPY SQL命令:
如果你在SQL脚本或命令行中使用COPY命令,并且该命令被中断,那么已经成功写入数据库的数据不会被回滚,但读取的数据可能仍然在COPY命令的缓冲区中。
如果COPY命令使用了事务,并且事务被回滚,那么已经写入数据库的数据会被回滚,但读取的数据可能仍然留在COPY命令的缓冲区中。
COPY命令在PostgreSQL中非常快的原因主要归因于以下几点:
直接文件访问
COPY命令直接访问文件,绕过了数据库内部的一些中间层,从而减少了数据在数据库和文件系统之间的额外传输。这使得COPY命令能够更快地传输数据。
避免事务开销
传统的SQL插入操作可能涉及多个事务和回滚,这会增加额外的开销。而COPY命令通常在一个事务中执行,从而减少了事务开销,提高了效率。
批量操作
COPY命令允许你一次性插入或导出大量数据,而不是一次插入或导出一条记录。这种批量操作减少了数据库与客户端之间的通信次数,从而提高了效率。
跳过索引和触发器
在执行COPY命令时,PostgreSQL可以跳过索引的更新和触发器的执行,这进一步提高了性能。
减少锁竞争
由于COPY命令通常在一个事务中执行,所以它可以减少锁竞争,从而避免阻塞其他操作。
利用磁盘缓存
PostgreSQL使用磁盘缓存来缓存数据,这有助于减少磁盘I/O操作,从而提高性能。
由于上述原因,COPY命令在PostgreSQL中通常比传统的插入或导出方法更快。
COPY命令在PostgreSQL数据库操作中扮演着重要角色,它提供了一种高效、自动化的数据导入和导出方法。通过正确的使用COPY命令,我们可以大大提高数据导入和导出的效率,减少人工错误,并确保数据的完整性和安全性。在实际应用中,我们需要根据数据量、格式和数据库配置等因素,选择合适的导入方法,并注意监控数据库的性能和资源使用情况,以确保系统的稳定和数据的安全。
随着数据库技术的不断发展,我们可以期待更多高效、自动化的数据操作方法的出现,以更好地满足实际应用的需求。
相关文章:

PostgreSQL中的COPY命令:高效数据导入与导出
在PostgreSQL数据库中,数据导入和导出是日常工作中常见的操作。传统的插入(INSERT)方法虽然可以实现数据的导入,但在处理大量数据时效率较低。而COPY命令则提供了一个快速、高效的方式来完成这一任务。COPY命令不仅可以用于将数据…...

【HAL库】STM32F105VCTx多通道ADC+DMA方式的【STM32CubeMX】配置及代码实现
相关代码编写 配置好后点击生成代码,在生成代码的adc.c文件中的初始化函数MX_ADC1_Init中添加如下代码: HAL_ADCEx_Calibration_Start(&hadc1); /* 校准ADC */HAL_ADC_Start_DMA(&hadc1,(uint32_t*)ADC_Value,ADC_DMA_…...

[SaaS] 数禾科技 AIGC生成营销素材
https://zhuanlan.zhihu.com/p/923637935https://zhuanlan.zhihu.com/p/923637935...

vue3中查找字典列表中某个元素的值对应的列表索引值
vue3中查找字典列表中某个元素的值对应的列表索引值 目录思路方法代码实现示例解释说明 目录 思路方法 要获取字典列表中某个元素的值对应的列表索引值,可以使用数组的 findIndex 方法。这个方法返回数组中满足提供的测试函数的第一个元素的索引。如果没有找到&am…...

爱普生机器人EPSON RC
爱普生机器人Epson RC系列,搭配其专用的Epson RC编程语言和软件环境,为用户提供了一个直观且功能强大的机器人控制和编程解决方案。以下是对Epson RC及爱普生机器人的一些详细介绍: Epson RC 定义:Epson RC 是爱普生机器人技术中…...

Linux探秘坊-------1.系统核心的低语:基础指令的奥秘解析(1)
1.Linux的背景介绍 Linux 操作系统的发展历程充满了激情与创新喵~🎀 萌芽期 (1983 - 1991):Linux 的历史可追溯到 1983 年,理查德斯托曼 (Richard Stallman) 发起 GNU 计划,目标是创建一个自由软件操作系统。1987 年发…...

❤React-JSX语法认识和使用
1、JSX基本使用 JSX是React的核心 JSX是ES的扩展 jsx语法 -> 普通的JavaScript代码 -> babel React可以使用JSX的前提和原因: React生态系统支持: 脚手架通常用于构建React应用程序,而JSX是React框架的核心语法之一。因此…...

51单片机应用开发(进阶)---定时器应用(电子时钟)
实现目标 1、巩固定时器的配置流程; 2、掌握按键、数码管与定时器配合使用; 3、功能1:(1)简单显示时间。显示格式:88-88-88(时-分-秒) 4、功能2:(1&#…...
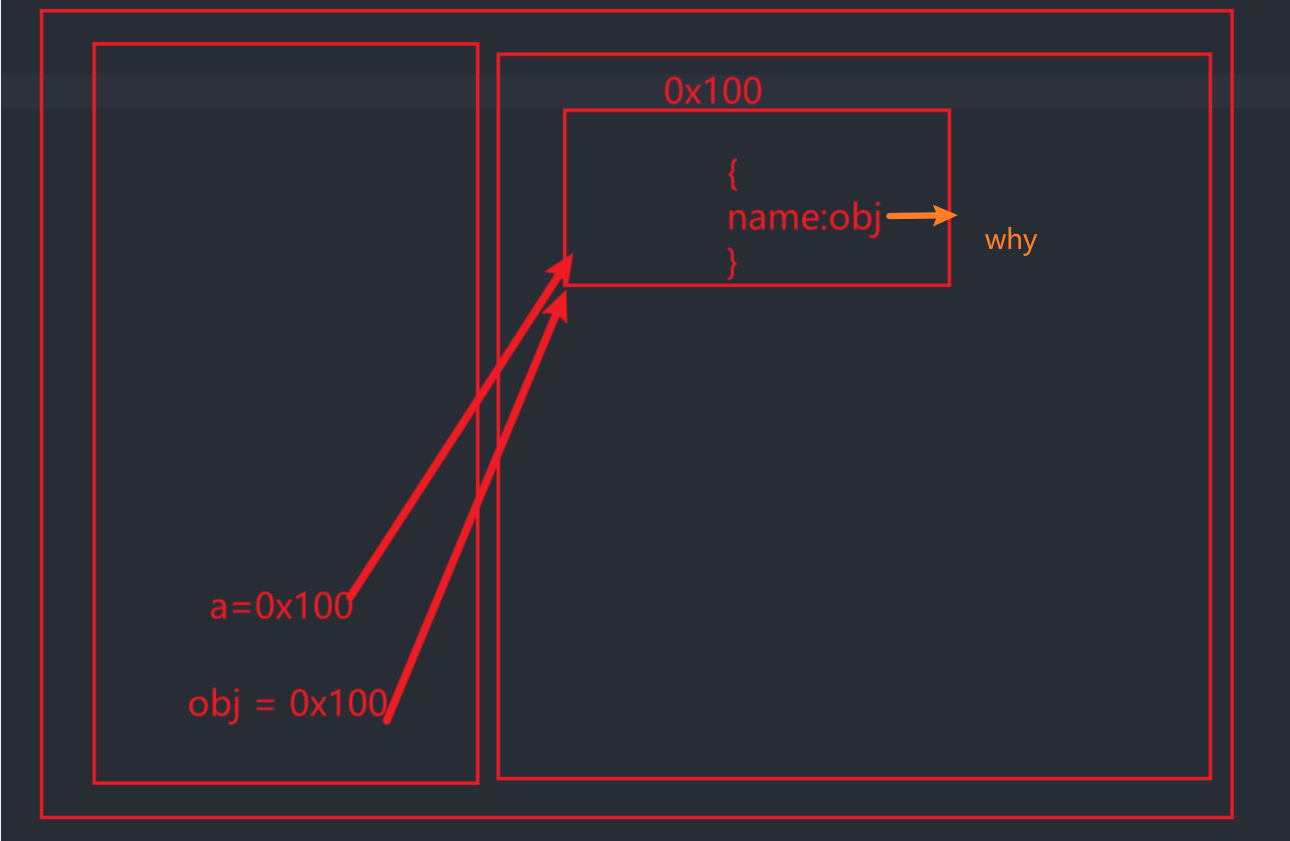
JavaScript中的对象-栈内存和堆内存以及this指向的两种情况(后续会出进阶)
1.1 栈内存和堆内存 我们知道程序是需要加载到内存中来执行的,我们可以将内存划分为两个区域:栈内存和堆内存 原始类型占据的空间是在栈内存中分配的对象类型占据的空间是在堆内存中分配的 1.1.1 值类型和引用类型 原始类型的保存方式:在变量中保存的是…...

shell脚本使用curl上传FTP
背景:要求使用curl通过shell脚本实现上传文件到FTP的功能,同时对远程目录不存在的时候,主动创建目录并上传文件,shell脚本如下: #!/bin/bash# FTP服务器的地址 FTP_SERVER"ftp://1.1.1.1:2121" # FTP用户名…...

【漏洞分析】Fastjson最新版本RCE漏洞
01漏洞编号 CVE-2022-25845CNVD-2022-40233CNNVD-202206-1037二、Fastjson知多少 万恶之源AutoType Fastjson的主要功能是将Java Bean序列化为JSON字符串,这样得到的字符串就可以通过数据库等方式进行持久化了。 但是,Fastjson在序列化及反序列化的过…...

【项目开发 | 跨域认证】JSON Web Token(JWT)
未经许可,不得转载。 文章目录 JWT设计背景:跨域认证JWT 原理JWT 结构JWT 使用方式注意JSON Web Token(缩写 JWT)是目前最流行的跨域认证解决方案,本文介绍它的原理、结构及用法。 JWT设计背景:跨域认证 互联网服务的用户认证流程是现代应用中的核心组成部分,通常的流程…...

杨中科 .Net Core 笔记 DI 依赖注入2
ServiceCollection services new ServiceCollection();//定义一个承放服务的集合 services.AddScoped<iGetRole, GetRole>();using (ServiceProvider serviceProvider services.BuildServiceProvider()) {var list serviceProvider.GetServices(typeof(iGetRole));//获…...
微信版产品目录如何制作?
微信作为我国最流行的社交媒体平台,拥有庞大的用户群体。许多企业都希望通过微信来推广自己的产品,提高品牌知名度。制作一份精美、实用的微信版产品目录,是企业微信营销的重要手段。微信版产品目录的制作方法,帮助您轻松入门。 …...

使用HTML、CSS和JavaScript创建动态圣诞树
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 ✨特色专栏:…...

机器学习-35-提取时间序列信号的特征
文章目录 1 特征提取方法1.1 特征提取过程1.2 两类特征提取方法2 基于数据驱动的方法2.1 领域特定特征提取2.2 基于频率的特征提取2.2.1 模拟信号2.2.2 傅里叶变换2.2.3 抽取最大幅值对应特征2.2.4 抽取峰值幅值对应特征2.3 基于统计的特征提取2.4 基于时间的特征提取3 参考附录…...
【软件测试】设计测试用例的万能公式
文章目录 概念设计测试用例的万能公式常规思考逆向思维发散性思维万能公式水杯测试弱网测试如何进行弱网测试 安装卸载测试 概念 什么是测试用例? 测试⽤例(Test Case)是为了实施测试⽽向被测试的系统提供的⼀组集合,这组集合包…...

【MySQL 保姆级教学】事务的自动提交和手动提交(重点)--上(13)
目录 1. 什么是事务?2. 事务的版本支持3. 事务提交的方式3.1 事务提交方式的分类3.2 演示的准备的工作3.2.1 创建表3.2.2 MySQL的服务端和客户端3.2.3 调低事务的隔离级别 4. 手动提交4.1 手动提交的命令说明4.2 示例一4.3 示例二4.4 示例三4.5 示例四 5. 自动提交5…...

CUDA 核心与科学计算 :NVIDIA 计算核心在计算服务器的价值
在现代科学计算领域,NVIDIA GPU 的计算能力是突破研究瓶颈的关键力量,而其中的 CUDA 核心与科学计算有着紧密的联系。 CUDA 核心于 2007 年开发,是一款基于单指令多线程 (SIMT) 模型的多功能通用核心。它在处理并行计算任务方面能力卓越&…...

架构师之路-学渣到学霸历程-58
Nginx的反向代理实验 今天分享的实验其实就是一个变形;变形uri看看nginx的配置有什么区别; 这个就更加绕,是比较不同的配置路径会有什么的区别? 来看看这个变形会得出什么的效果 1.首先配置后端服务器的资源 首页资源–>1…...
)
AI Agent驱动的管理咨询实战手册(麦肯锡/BCG未公开方法论首次披露)
更多请点击: https://intelliparadigm.com 第一章:AI Agent驱动的管理咨询范式革命 传统管理咨询依赖专家经验、手工访谈与静态模型,响应周期长、知识复用率低、规模化交付困难。AI Agent 的崛起正从根本上重构这一价值链——它不再是辅助工…...

企业从 Excel 管理转向系统化管理的关键步骤
企业从 Excel 管理转向系统化管理的关键步骤 几乎每家中小企业都经历过 Excel 管理阶段。客户表、合同表、项目表、库存表、资产表、员工表、回款表,一个个表格撑起了企业早期管理。Excel 的优势很明显:灵活、低成本、人人会用。 但企业规模一旦扩大&…...

Unity 2D基础:2D相机Orthographic的参数调节
Unity 2D基础:2D相机Orthographic的参数调节📚 本章学习目标:深入理解2D相机Orthographic的参数调节的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最佳实践。本文属于《Unity工程师成长之路教程》Unity 2…...

观测通过Taotoken调用大模型API的延迟与用量消耗体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观测通过Taotoken调用大模型API的延迟与用量消耗体验 在开发工作中引入大模型能力,例如自动生成代码注释,已…...

F3工具深度解析:开源存储设备容量检测与反欺诈技术
F3工具深度解析:开源存储设备容量检测与反欺诈技术 【免费下载链接】f3 F3 - Fight Flash Fraud 项目地址: https://gitcode.com/gh_mirrors/f3/f3 F3(Fight Flash Fraud)是一个专业的开源存储设备容量检测工具,通过伪随机…...

从分钟到秒级:我们用 Fluss + Paimon 替换掉 Kafka + Iceberg,实时宽表终于不用 Flink 死扛了
从分钟到秒级:我们用 Fluss Paimon 替换掉 Kafka Iceberg,实时宽表终于不用 Flink 死扛了 📅 更新于 2026-05-21 | 🏷️ Fluss Paimon 湖流一体 实时数仓 架构升级 摘要:上一代湖仓一体架构中,Kafka …...

nvm-desktop:图形化Node.js版本管理解决方案
nvm-desktop:图形化Node.js版本管理解决方案 【免费下载链接】nvm-desktop Node Version Manager Desktop - A desktop application to manage multiple active node.js versions. 项目地址: https://gitcode.com/gh_mirrors/nv/nvm-desktop 在Node.js多版本…...

EGO-Planner-v2:零配置开启无人机集群仿真新体验
EGO-Planner-v2:零配置开启无人机集群仿真新体验 【免费下载链接】EGO-Planner-v2 Swarm Playground, the codebase of the paper "Swarm of micro flying robots in the wild" 项目地址: https://gitcode.com/gh_mirrors/eg/EGO-Planner-v2 想要快…...

Unity 2D跑酷开发全链路实战:从物理帧到对象池的工程化落地
1. 这不是“又一个跑酷游戏”,而是Unity 2D开发能力的完整压力测试 很多人点开“Unity跑酷游戏教程”时,心里想的是:拖几个Sprite,加个Rigidbody2D,写个Input.GetKeyDown(KeyCode.Space)跳一下,再配个背景滚…...

Unity图表性能优化:从折线图到饼图的底层实现与避坑指南
1. 为什么Unity里做图表不是“加个UI控件”就完事了? 在Unity项目里,当策划甩来一句“这个数据面板加个折线图展示用户留存率”,或者美术提出“战斗结算页需要动态饼图显示伤害来源分布”,很多开发者第一反应是:去Asse…...