wafw00f源码详细解析
声明
本人菜鸟一枚,为了完成作业,发现网上所有的关于wafw00f的源码解析都是这抄那那抄这的,没有新东西,所以这里给出一个详细的源码解析,可能有错误,如果有大佬发现错误,可以在评论区平和的指出,如果觉得这篇文章对你有帮助,请点点赞和收藏^_^
这里不展示wafw00f的安装使用,这些可以去github上看wafw00f的readme,或者网上有挺多教程的,只解析其源码
前言
昨晚写了关于IdentYwaf的的源码解析:IdentYwaf源码详细解析
在这篇文章中我说到wafw00f在识别waf的能力上远远强于IdentYwaf,所以我就在写一篇wafw00f来证明为什么wafw00f比IdentYwaf要强的多
wafw00f工具可以去github下载:wafw00f
概述
至于什么是waf以及wafw00f是做什么的,这里大概总结一下:
waf就是网络程序防火墙,可以识别出一些非法语句,例如XSS和SQL注入语句,然后拦截这些语句
wafw00f以及IdentYwaf这些工具就是识别网站用了市面上哪些waf的,是渗透测试前期收集信息必不可少的一部分
wafw00f源码分析
wafw00f工作流程
和网上当然是不一样的啦

这里可以看出wafw00f的工作流程是比较简单的,它的核心就一个,identwaf函数
wafw00f文件目录
└─wafw00f│ .gitignore│ CODE_OF_CONDUCT.md│ CREDITS.txt│ Dockerfile│ LICENSE│ Makefile│ MANIFEST.in│ README.md│ setup.py ├─docs│ conf.py│ index.rst│ Makefile│ wafw00f.8│ └─wafw00f│ main.py★★★│ manager.py│ wafprio.py│ __init__.py│ ├─bin│ wafw00f│ ├─lib│ asciiarts.py│ evillib.py★★★│ __init__.py│ └─plugins★★★★aesecure.pyairee.pyairlock.pyalertlogic.pyaliyundun.py...__init__.pywafw00f核心流程分析
我分析wafw00f的过程主要分成两个部分,因为这个工具最重要的就两个文件main.py和evillib.py,我就分成两个文件来解析,这里先解析evillib.py再解析main.py,至于用到的其它文件我就把里面的函数当成集成在main.py和evillib.py文件里面了
最后我们还会详细解析plugins目录里面的一些东西,这个插件目录是wafw00f的超级核心
evillib.py
整个文件内容:
#!/usr/bin/env python
'''
Copyright (C) 2022, WAFW00F Developers.
See the LICENSE file for copying permission.
'''import time
import logging
from copy import copyimport requests
import urllib3
try:from urlparse import urlparse, urlunparse
except ImportError:from urllib.parse import urlparse, urlunparse# For requests < 2.16, this should be used.
# requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
# For requests >= 2.16, this is the convention
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)def_headers = {'Accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3','Accept-Encoding': 'gzip, deflate','Accept-Language': 'en-US,en;q=0.9','DNT' : '1', # Do Not Track request header'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3770.100 Safari/537.36','Upgrade-Insecure-Requests': '1' #}
proxies = {}def urlParser(target):log = logging.getLogger('urlparser')ssl = Falseo = urlparse(target)if o[0] not in ['http', 'https', '']:log.error('scheme %s not supported' % o[0])returnif o[0] == 'https':ssl = Trueif len(o[2]) > 0:path = o[2]else:path = '/'tmp = o[1].split(':')if len(tmp) > 1:port = tmp[1]else:port = Nonehostname = tmp[0]query = o[4]return (hostname, port, path, query, ssl)class waftoolsengine:def __init__(self, target='https://example.com', debuglevel=0, path='/', proxies=None,redir=True, head=None):self.target = targetself.debuglevel = debuglevelself.requestnumber = 0self.path = pathself.redirectno = 0self.allowredir = redirself.proxies = proxiesself.log = logging.getLogger('wafw00f')if head:self.headers = headelse:self.headers = copy(def_headers) #copy object by value not reference. Fix issue #90def Request(self, headers=None, path=None, params={}, delay=0, timeout=7):try:time.sleep(delay)if not headers:h = self.headerselse: h = headersreq = requests.get(self.target, proxies=self.proxies, headers=h, timeout=timeout,allow_redirects=self.allowredir, params=params, verify=False)self.log.info('Request Succeeded')self.log.debug('Headers: %s\n' % req.headers)self.log.debug('Content: %s\n' % req.content)self.requestnumber += 1return reqexcept requests.exceptions.RequestException as e:self.log.error('Something went wrong %s' % (e.__str__()))主要有三个东西:urlParser()函数、waftoolsengine类、默认的Headers
默认Headers
def_headers = {'Accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3','Accept-Encoding': 'gzip, deflate','Accept-Language': 'en-US,en;q=0.9','DNT' : '1', # Do Not Track request header'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3770.100 Safari/537.36','Upgrade-Insecure-Requests': '1' #}
没什么好讲的,跳
urlParser(target)函数
def urlParser(target):log = logging.getLogger('urlparser')ssl = Falseo = urlparse(target)if o[0] not in ['http', 'https', '']:log.error('scheme %s not supported' % o[0])returnif o[0] == 'https':ssl = Trueif len(o[2]) > 0:path = o[2]else:path = '/'tmp = o[1].split(':')if len(tmp) > 1:port = tmp[1]else:port = Nonehostname = tmp[0]query = o[4]return (hostname, port, path, query, ssl)
wafw00f如果不提供完整的url和端口号,会出现如下错误:
ERROR:wafw00f:Something went wrong
HTTPSConnectionPool(host=‘117.39.30.114’, port=443): Max retries
exceeded with url: / (Caused by SSLError(SSLError(1, ‘[SSL:
UNSUPPORTED_PROTOCOL] unsupported protocol (_ssl.c:1129)’)))
ERROR:wafw00f:Site 117.39.30.114 appears to be down
其中错误是在urlparse(target)发出来的
https:// 默认端口号为443,http://默认端口号为80,若遇到仅开放8080等其他情况的网站,需要指定网站端口号才能顺利扫描识别waf,且务必告知是https访问还是http访问。否则urlparse均会抛出错误。
如果urlparse顺利过关,则会返回如下内容:
<scheme>://<netloc>/<path>;<params>?<query>#<fragment>
urlParser则返回:
hostname = netloc.split(“:”)[0]
prot = netloc.split(“:”)[1]
path = path
query = query
ssl = True if scheme == “https” else False
这个函数就是关于url解析的一个函数
waftoolsengine类
class waftoolsengine:def __init__(self, target='https://example.com', debuglevel=0, path='/', proxies=None,redir=True, head=None):self.target = targetself.debuglevel = debuglevelself.requestnumber = 0self.path = pathself.redirectno = 0self.allowredir = redirself.proxies = proxiesself.log = logging.getLogger('wafw00f')if head:self.headers = headelse:self.headers = copy(def_headers) #copy object by value not reference. Fix issue #90def Request(self, headers=None, path=None, params={}, delay=0, timeout=7):try:time.sleep(delay)if not headers:h = self.headerselse: h = headersreq = requests.get(self.target, proxies=self.proxies, headers=h, timeout=timeout,allow_redirects=self.allowredir, params=params, verify=False)self.log.info('Request Succeeded')self.log.debug('Headers: %s\n' % req.headers)self.log.debug('Content: %s\n' % req.content)self.requestnumber += 1return reqexcept requests.exceptions.RequestException as e:self.log.error('Something went wrong %s' % (e.__str__()))
这个类主要有两个部分,初始化和请求,不难看懂,后面的main.py会实例化一个这个类,并不断用实例化对象进行操作,所以我们后面再来详细解析这里面都做了什么操作
main.py
先来看看WAFW00F类(继承自waftoolsengine类)
class WAFW00F(waftoolsengine):xsstring = '<script>alert("XSS");</script>'sqlistring = "UNION SELECT ALL FROM information_schema AND ' or SLEEP(5) or '"lfistring = '../../../../etc/passwd'rcestring = '/bin/cat /etc/passwd; ping 127.0.0.1; curl google.com'xxestring = '<!ENTITY xxe SYSTEM "file:///etc/shadow">]><pwn>&hack;</pwn>'def __init__(self, target='www.example.com', debuglevel=0, path='/',followredirect=True, extraheaders={}, proxies=None):self.log = logging.getLogger('wafw00f')self.attackres = Nonewaftoolsengine.__init__(self, target, debuglevel, path, proxies, followredirect, extraheaders)self.knowledge = dict(generic=dict(found=False, reason=''), wafname=list())self.rq = self.normalRequest()def normalRequest(self):return self.Request()def customRequest(self, headers=None):return self.Request(headers=headers)def nonExistent(self):return self.Request(path=self.path + str(random.randrange(100, 999)) + '.html')def xssAttack(self):return self.Request(path=self.path, params= {'s': self.xsstring})def xxeAttack(self):return self.Request(path=self.path, params= {'s': self.xxestring})def lfiAttack(self):return self.Request(path=self.path + self.lfistring)def centralAttack(self):return self.Request(path=self.path, params={'a': self.xsstring, 'b': self.sqlistring, 'c': self.lfistring})def sqliAttack(self):return self.Request(path=self.path, params= {'s': self.sqlistring})def oscAttack(self):return self.Request(path=self.path, params= {'s': self.rcestring})def performCheck(self, request_method):r = request_method()if r is None:raise RequestBlocked()return r# Most common attacks used to detect WAFsattcom = [xssAttack, sqliAttack, lfiAttack]attacks = [xssAttack, xxeAttack, lfiAttack, sqliAttack, oscAttack]def genericdetect(self):reason = ''reasons = ['Blocking is being done at connection/packet level.','The server header is different when an attack is detected.','The server returns a different response code when an attack string is used.','It closed the connection for a normal request.','The response was different when the request wasn\'t made from a browser.']try:# Testing for no user-agent response. Detects almost all WAFs out there.resp1 = self.performCheck(self.normalRequest)if 'User-Agent' in self.headers:self.headers.pop('User-Agent') # Deleting the user-agent key from object not dict.resp3 = self.customRequest(headers=self.headers)if resp3 is not None and resp1 is not None:if resp1.status_code != resp3.status_code:self.log.info('Server returned a different response when request didn\'t contain the User-Agent header.')reason = reasons[4]reason += '\r\n'reason += 'Normal response code is "%s",' % resp1.status_codereason += ' while the response code to a modified request is "%s"' % resp3.status_codeself.knowledge['generic']['reason'] = reasonself.knowledge['generic']['found'] = Truereturn True# Testing the status code upon sending a xss attackresp2 = self.performCheck(self.xssAttack)if resp1.status_code != resp2.status_code:self.log.info('Server returned a different response when a XSS attack vector was tried.')reason = reasons[2]reason += '\r\n'reason += 'Normal response code is "%s",' % resp1.status_codereason += ' while the response code to cross-site scripting attack is "%s"' % resp2.status_codeself.knowledge['generic']['reason'] = reasonself.knowledge['generic']['found'] = Truereturn True# Testing the status code upon sending a lfi attackresp2 = self.performCheck(self.lfiAttack)if resp1.status_code != resp2.status_code:self.log.info('Server returned a different response when a directory traversal was attempted.')reason = reasons[2]reason += '\r\n'reason += 'Normal response code is "%s",' % resp1.status_codereason += ' while the response code to a file inclusion attack is "%s"' % resp2.status_codeself.knowledge['generic']['reason'] = reasonself.knowledge['generic']['found'] = Truereturn True# Testing the status code upon sending a sqli attackresp2 = self.performCheck(self.sqliAttack)if resp1.status_code != resp2.status_code:self.log.info('Server returned a different response when a SQLi was attempted.')reason = reasons[2]reason += '\r\n'reason += 'Normal response code is "%s",' % resp1.status_codereason += ' while the response code to a SQL injection attack is "%s"' % resp2.status_codeself.knowledge['generic']['reason'] = reasonself.knowledge['generic']['found'] = Truereturn True# Checking for the Server header after sending malicious requestsnormalserver, attackresponse_server = '', ''response = self.attackresif 'server' in resp1.headers:normalserver = resp1.headers.get('Server')if response is not None and 'server' in response.headers:attackresponse_server = response.headers.get('Server')if attackresponse_server != normalserver:self.log.info('Server header changed, WAF possibly detected')self.log.debug('Attack response: %s' % attackresponse_server)self.log.debug('Normal response: %s' % normalserver)reason = reasons[1]reason += '\r\nThe server header for a normal response is "%s",' % normalserverreason += ' while the server header a response to an attack is "%s",' % attackresponse_serverself.knowledge['generic']['reason'] = reasonself.knowledge['generic']['found'] = Truereturn True# If at all request doesn't go, press Fexcept RequestBlocked:self.knowledge['generic']['reason'] = reasons[0]self.knowledge['generic']['found'] = Truereturn Truereturn Falsedef matchHeader(self, headermatch, attack=False):if attack:r = self.attackreselse:r = self.rqif r is None:returnheader, match = headermatchheaderval = r.headers.get(header)if headerval:# set-cookie can have multiple headers, python gives it to us# concatinated with a commaif header == 'Set-Cookie':headervals = headerval.split(', ')else:headervals = [headerval]for headerval in headervals:if re.search(match, headerval, re.I):return Truereturn Falsedef matchStatus(self, statuscode, attack=True):if attack:r = self.attackreselse:r = self.rqif r is None:returnif r.status_code == statuscode:return Truereturn Falsedef matchCookie(self, match, attack=False):return self.matchHeader(('Set-Cookie', match), attack=attack)def matchReason(self, reasoncode, attack=True):if attack:r = self.attackreselse:r = self.rqif r is None:return# We may need to match multiline context in response bodyif str(r.reason) == reasoncode:return Truereturn Falsedef matchContent(self, regex, attack=True):if attack:r = self.attackreselse:r = self.rqif r is None:return# We may need to match multiline context in response bodyif re.search(regex, r.text, re.I):return Truereturn Falsewafdetections = dict()plugin_dict = load_plugins()result_dict = {}for plugin_module in plugin_dict.values():wafdetections[plugin_module.NAME] = plugin_module.is_waf# Check for prioritized ones first, then check those added externallychecklist = wafdetectionspriochecklist += list(set(wafdetections.keys()) - set(checklist))def identwaf(self, findall=False):detected = list()try:self.attackres = self.performCheck(self.centralAttack)except RequestBlocked:return detectedfor wafvendor in self.checklist:self.log.info('Checking for %s' % wafvendor)if self.wafdetections[wafvendor](self):detected.append(wafvendor)if not findall:breakself.knowledge['wafname'] = detectedreturn detected
我们在后续分析中再来一点一点拆解这个类,直接分析没啥大用
主流程
def main():parser = OptionParser(usage='%prog url1 [url2 [url3 ... ]]\r\nexample: %prog http://www.victim.org/')parser.add_option('-v', '--verbose', action='count', dest='verbose', default=0,help='Enable verbosity, multiple -v options increase verbosity')parser.add_option('-a', '--findall', action='store_true', dest='findall', default=False,help='Find all WAFs which match the signatures, do not stop testing on the first one')parser.add_option('-r', '--noredirect', action='store_false', dest='followredirect',default=True, help='Do not follow redirections given by 3xx responses')parser.add_option('-t', '--test', dest='test', help='Test for one specific WAF')parser.add_option('-o', '--output', dest='output', help='Write output to csv, json or text file depending on file extension. For stdout, specify - as filename.',default=None)parser.add_option('-f', '--format', dest='format', help='Force output format to csv, json or text.',default=None)parser.add_option('-i', '--input-file', dest='input', help='Read targets from a file. Input format can be csv, json or text. For csv and json, a `url` column name or element is required.',default=None)parser.add_option('-l', '--list', dest='list', action='store_true',default=False, help='List all WAFs that WAFW00F is able to detect')parser.add_option('-p', '--proxy', dest='proxy', default=None,help='Use an HTTP proxy to perform requests, examples: http://hostname:8080, socks5://hostname:1080, http://user:pass@hostname:8080')parser.add_option('--version', '-V', dest='version', action='store_true',default=False, help='Print out the current version of WafW00f and exit.')parser.add_option('--headers', '-H', dest='headers', action='store', default=None,help='Pass custom headers via a text file to overwrite the default header set.')options, args = parser.parse_args()logging.basicConfig(level=calclogginglevel(options.verbose))log = logging.getLogger('wafw00f')if options.output == '-':disableStdOut()print(randomArt())if options.list:print('[+] Can test for these WAFs:\r\n')try:m = [i.replace(')', '').split(' (') for i in wafdetectionsprio]print(R+' WAF Name'+' '*24+'Manufacturer\n '+'-'*8+' '*24+'-'*12+'\n')max_len = max(len(str(x)) for k in m for x in k)for inner in m:first = Truefor elem in inner:if first:text = Y+" {:<{}} ".format(elem, max_len+2)first = Falseelse:text = W+"{:<{}} ".format(elem, max_len+2)print(text, E, end="")print()sys.exit(0)except Exception:returnif options.version:print('[+] The version of WAFW00F you have is %sv%s%s' % (B, __version__, E))print('[+] WAFW00F is provided under the %s%s%s license.' % (C, __license__, E))returnextraheaders = {}if options.headers:log.info('Getting extra headers from %s' % options.headers)extraheaders = getheaders(options.headers)if extraheaders is None:parser.error('Please provide a headers file with colon delimited header names and values')# arg1# if len(args) == 0 and not options.input:# parser.error('No test target specified.')#check if input file is presentif options.input:log.debug("Loading file '%s'" % options.input)try:if options.input.endswith('.json'):with open(options.input) as f:try:urls = json.loads(f.read())except json.decoder.JSONDecodeError:log.critical("JSON file %s did not contain well-formed JSON", options.input)sys.exit(1)log.info("Found: %s urls to check." %(len(urls)))targets = [ item['url'] for item in urls ]elif options.input.endswith('.csv'):columns = defaultdict(list)with open(options.input) as f:reader = csv.DictReader(f)for row in reader:for (k,v) in row.items():columns[k].append(v)targets = columns['url']else:with open(options.input) as f:targets = [x for x in f.read().splitlines()]except FileNotFoundError:log.error('File %s could not be read. No targets loaded.', options.input)sys.exit(1)else:targets = argsresults = []# arg2targets = ["117.39.30.114"]for target in targets:if not target.startswith('http'):log.info('The url %s should start with http:// or https:// .. fixing (might make this unusable)' % target)target = 'https://' + targetprint('[*] Checking %s' % target)pret = urlParser(target)if pret is None:log.critical('The url %s is not well formed' % target)sys.exit(1)(hostname, _, path, _, _) = pretlog.info('starting wafw00f on %s' % target)proxies = dict()if options.proxy:proxies = {"http": options.proxy,"https": options.proxy,}# arg3attacker = WAFW00F(target, debuglevel=options.verbose, path=path,followredirect=options.followredirect, extraheaders=extraheaders,proxies=proxies)if attacker.rq is None:log.error('Site %s appears to be down' % hostname)continue# arg4# 测试指定的wafif options.test:if options.test in attacker.wafdetections:waf = attacker.wafdetections[options.test](attacker)if waf:print('[+] The site %s%s%s is behind %s%s%s WAF.' % (B, target, E, C, options.test, E))else:print('[-] WAF %s was not detected on %s' % (options.test, target))else:print('[-] WAF %s was not found in our list\r\nUse the --list option to see what is available' % options.test)returnwaf = attacker.identwaf(options.findall)log.info('Identified WAF: %s' % waf)if len(waf) > 0:for i in waf:results.append(buildResultRecord(target, i))print('[+] The site %s%s%s is behind %s%s%s WAF.' % (B, target, E, C, (E+' and/or '+C).join(waf), E))if (options.findall) or len(waf) == 0:print('[+] Generic Detection results:')if attacker.genericdetect():log.info('Generic Detection: %s' % attacker.knowledge['generic']['reason'])print('[*] The site %s seems to be behind a WAF or some sort of security solution' % target)print('[~] Reason: %s' % attacker.knowledge['generic']['reason'])results.append(buildResultRecord(target, 'generic'))else:print('[-] No WAF detected by the generic detection')results.append(buildResultRecord(target, None))print('[~] Number of requests: %s' % attacker.requestnumber)#print table of resultsif len(results) > 0:log.info("Found: %s matches." % (len(results)))if options.output:if options.output == '-':enableStdOut()if options.format == 'json':json.dump(results, sys.stdout, indent=2)elif options.format == 'csv':csvwriter = csv.writer(sys.stdout, delimiter=',', quotechar='"',quoting=csv.QUOTE_MINIMAL)count = 0for result in results:if count == 0:header = result.keys()csvwriter.writerow(header)count += 1csvwriter.writerow(result.values())else:print(os.linesep.join(getTextResults(results)))elif options.output.endswith('.json'):log.debug("Exporting data in json format to file: %s" % (options.output))with open(options.output, 'w') as outfile:json.dump(results, outfile, indent=2)elif options.output.endswith('.csv'):log.debug("Exporting data in csv format to file: %s" % (options.output))with open(options.output, 'w') as outfile:csvwriter = csv.writer(outfile, delimiter=',', quotechar='"',quoting=csv.QUOTE_MINIMAL)count = 0for result in results:if count == 0:header = result.keys()csvwriter.writerow(header)count += 1csvwriter.writerow(result.values())else:log.debug("Exporting data in text format to file: %s" % (options.output))if options.format == 'json':with open(options.output, 'w') as outfile:json.dump(results, outfile, indent=2)elif options.format == 'csv':with open(options.output, 'w') as outfile:csvwriter = csv.writer(outfile, delimiter=',', quotechar='"',quoting=csv.QUOTE_MINIMAL)count = 0for result in results:if count == 0:header = result.keys()csvwriter.writerow(header)count += 1csvwriter.writerow(result.values())else:with open(options.output, 'w') as outfile:outfile.write(os.linesep.join(getTextResults(results)))if __name__ == '__main__':if sys.hexversion < 0x2060000:sys.stderr.write('Your version of python is way too old... please update to 2.6 or later\r\n')main()
wafw00f上来就开大,一个main()函数集成了一大堆代码,这个确实不太好,个人认为应该还是把一些部分像IdentYwaf那样封装成一个参数,这样处理起来就不会出现大改而是把改代码局限在小区域内
读入参数部分
parser = OptionParser(usage='%prog url1 [url2 [url3 ... ]]\r\nexample: %prog http://www.victim.org/')parser.add_option('-v', '--verbose', action='count', dest='verbose', default=0,help='Enable verbosity, multiple -v options increase verbosity')parser.add_option('-a', '--findall', action='store_true', dest='findall', default=False,help='Find all WAFs which match the signatures, do not stop testing on the first one')parser.add_option('-r', '--noredirect', action='store_false', dest='followredirect',default=True, help='Do not follow redirections given by 3xx responses')parser.add_option('-t', '--test', dest='test', help='Test for one specific WAF')parser.add_option('-o', '--output', dest='output', help='Write output to csv, json or text file depending on file extension. For stdout, specify - as filename.',default=None)parser.add_option('-f', '--format', dest='format', help='Force output format to csv, json or text.',default=None)parser.add_option('-i', '--input-file', dest='input', help='Read targets from a file. Input format can be csv, json or text. For csv and json, a `url` column name or element is required.',default=None)parser.add_option('-l', '--list', dest='list', action='store_true',default=False, help='List all WAFs that WAFW00F is able to detect')parser.add_option('-p', '--proxy', dest='proxy', default=None,help='Use an HTTP proxy to perform requests, examples: http://hostname:8080, socks5://hostname:1080, http://user:pass@hostname:8080')parser.add_option('--version', '-V', dest='version', action='store_true',default=False, help='Print out the current version of WafW00f and exit.')parser.add_option('--headers', '-H', dest='headers', action='store', default=None,help='Pass custom headers via a text file to overwrite the default header set.')options, args = parser.parse_args()logging.basicConfig(level=calclogginglevel(options.verbose))log = logging.getLogger('wafw00f')
这样看有点太难看了,直接看-h吧

proxy、output、headers、findall是比较有可能用到的参数,但是我都不用,我只解析源码,哈哈
核心流程
咱们还是跳过大部分的无用代码部分吧,确实没啥好分析的,直接关注一下下面这部分代码:
if options.input:log.debug("Loading file '%s'" % options.input)try:if options.input.endswith('.json'):with open(options.input) as f:try:urls = json.loads(f.read())except json.decoder.JSONDecodeError:log.critical("JSON file %s did not contain well-formed JSON", options.input)sys.exit(1)log.info("Found: %s urls to check." %(len(urls)))targets = [ item['url'] for item in urls ]elif options.input.endswith('.csv'):columns = defaultdict(list)with open(options.input) as f:reader = csv.DictReader(f)for row in reader:for (k,v) in row.items():columns[k].append(v)targets = columns['url']else:with open(options.input) as f:targets = [x for x in f.read().splitlines()]except FileNotFoundError:log.error('File %s could not be read. No targets loaded.', options.input)sys.exit(1)else:targets = argsresults = []for target in targets:if not target.startswith('http'):log.info('The url %s should start with http:// or https:// .. fixing (might make this unusable)' % target)target = 'https://' + targetprint('[*] Checking %s' % target)pret = urlParser(target)if pret is None:log.critical('The url %s is not well formed' % target)sys.exit(1)(hostname, _, path, _, _) = pretlog.info('starting wafw00f on %s' % target)proxies = dict()if options.proxy:proxies = {"http": options.proxy,"https": options.proxy,}attacker = WAFW00F(target, debuglevel=options.verbose, path=path,followredirect=options.followredirect, extraheaders=extraheaders,proxies=proxies)if attacker.rq is None:log.error('Site %s appears to be down' % hostname)continueif options.test:if options.test in attacker.wafdetections:waf = attacker.wafdetections[options.test](attacker)if waf:print('[+] The site %s%s%s is behind %s%s%s WAF.' % (B, target, E, C, options.test, E))else:print('[-] WAF %s was not detected on %s' % (options.test, target))else:print('[-] WAF %s was not found in our list\r\nUse the --list option to see what is available' % options.test)returnwaf = attacker.identwaf(options.findall)log.info('Identified WAF: %s' % waf)if len(waf) > 0:for i in waf:results.append(buildResultRecord(target, i))print('[+] The site %s%s%s is behind %s%s%s WAF.' % (B, target, E, C, (E+' and/or '+C).join(waf), E))if (options.findall) or len(waf) == 0:print('[+] Generic Detection results:')if attacker.genericdetect():log.info('Generic Detection: %s' % attacker.knowledge['generic']['reason'])print('[*] The site %s seems to be behind a WAF or some sort of security solution' % target)print('[~] Reason: %s' % attacker.knowledge['generic']['reason'])results.append(buildResultRecord(target, 'generic'))else:print('[-] No WAF detected by the generic detection')results.append(buildResultRecord(target, None))print('[~] Number of requests: %s' % attacker.requestnumber)
哇塞,还是好长,来,跟着小弟我继续分解这段代码
if options.input:log.debug("Loading file '%s'" % options.input)try:if options.input.endswith('.json'):with open(options.input) as f:try:urls = json.loads(f.read())except json.decoder.JSONDecodeError:log.critical("JSON file %s did not contain well-formed JSON", options.input)sys.exit(1)log.info("Found: %s urls to check." %(len(urls)))targets = [ item['url'] for item in urls ]elif options.input.endswith('.csv'):columns = defaultdict(list)with open(options.input) as f:reader = csv.DictReader(f)for row in reader:for (k,v) in row.items():columns[k].append(v)targets = columns['url']else:with open(options.input) as f:targets = [x for x in f.read().splitlines()]except FileNotFoundError:log.error('File %s could not be read. No targets loaded.', options.input)sys.exit(1)else:targets = args
这部分就是说我们要检测的网站url读入,如果指定了一个多个网站检测的文件,它就从文件中读取url到targets中,否则直接从控制台的args里存储到targets中
for target in targets:if not target.startswith('http'):log.info('The url %s should start with http:// or https:// .. fixing (might make this unusable)' % target)target = 'https://' + targetprint('[*] Checking %s' % target)pret = urlParser(target)if pret is None:log.critical('The url %s is not well formed' % target)sys.exit(1)(hostname, _, path, _, _) = pretlog.info('starting wafw00f on %s' % target)proxies = dict()if options.proxy:proxies = {"http": options.proxy,"https": options.proxy,}attacker = WAFW00F(target, debuglevel=options.verbose, path=path,followredirect=options.followredirect, extraheaders=extraheaders,proxies=proxies)if attacker.rq is None:log.error('Site %s appears to be down' % hostname)continueif options.test:if options.test in attacker.wafdetections:waf = attacker.wafdetections[options.test](attacker)if waf:print('[+] The site %s%s%s is behind %s%s%s WAF.' % (B, target, E, C, options.test, E))else:print('[-] WAF %s was not detected on %s' % (options.test, target))else:print('[-] WAF %s was not found in our list\r\nUse the --list option to see what is available' % options.test)return
这个循环首先是从targets从获取每一个target
然后看看target是否有http开头,没有就默认给一个https://,这里其实是有问题的,IdentYwaf也是默认给https://,但是如果https://有问题会试一下http://,而wafw00f则没有这个处理,所以如果有网站的ssl证书过期了,且我们给的target只有hostname而没有指定协议的话,wafw00f就没法检测了,这里可以处理一下兼容http://的情况
接着就用了urlParser函数来解析target,使用pret存储返回的内容:
hostname = netloc.split(“:”)[0]
prot = netloc.split(“:”)[1]
path = path
query = query
ssl = True if scheme == “https” else False
pret如果不存在,说明url不合法,直接退出即可
存在则从pret中读取hostname和path信息
pret = urlParser(target)if pret is None:log.critical('The url %s is not well formed' % target)sys.exit(1)(hostname, _, path, _, _) = pret
配置代理
proxies = dict()if options.proxy:proxies = {"http": options.proxy,"https": options.proxy,}
重点来了,WAFW00F类是继承waftoolsengine类开发的一个类:
attacker = WAFW00F(target, debuglevel=options.verbose, path=path,followredirect=options.followredirect, extraheaders=extraheaders,proxies=proxies)
我们,我们看看WAFW00F类的初始化,看看这个实例化对象有什么稀奇的:
class WAFW00F(waftoolsengine):def __init__(self, target='www.example.com', debuglevel=0, path='/',followredirect=True, extraheaders={}, proxies=None):self.log = logging.getLogger('wafw00f')self.attackres = Nonewaftoolsengine.__init__(self, target, debuglevel, path, proxies, followredirect, extraheaders)self.knowledge = dict(generic=dict(found=False, reason=''), wafname=list())self.rq = self.normalRequest()
首先就是target,指定测试的对象
然后重点关注一下path、followredirect
这个path就是我们解析url整出来的path
followredirect应该就是允许处理重定向包的情况,这一个选择使得wafw00f在处理response上就比IdentYwaf要强上不少。
接着往下看,waftoolsengine此时也被初始化了一次,这个是直接对整个waftoolsengine初始化,也就是说,在这个target处理过程,关于引擎的使用都受这次初始化影响,直到下次初始化(遍历到下一个target)
self.knowledge = dict(generic=dict(found=False, reason=‘’), wafname=list())
是为WAFW00F类的实例化对象attacker整了一个知识属性,这个属性是一个类似json的格式存储的,第一个键是generic,第二个键是wafname,generic的值是一个字典,有两个键,一个是found,一个是reason,这个知识属性具体什么用我们后续再来看,主要是应用在输出上面的,与我们测试识别关系不大,不太重要
重点来了
接下来的内容重点挺多的,大家这里最好自己去调试跑一跑看看什么个情况。
self.rq = self.normalRequest()
实例化对象接下来就会直接调用这个rq,attacker.rq就是attacker.normalRequest()
我们来看看normalRequest
def normalRequest(self):return self.Request()
接着往下找,这个Request就是waftoolsengine的那个Request,我们什么都不传,直接按照默认的来:
def Request(self, headers=None, path=None, params={}, delay=0, timeout=7):try:time.sleep(delay)if not headers:h = self.headerselse: h = headersreq = requests.get(self.target, proxies=self.proxies, headers=h, timeout=timeout,allow_redirects=self.allowredir, params=params, verify=False)self.log.info('Request Succeeded')self.log.debug('Headers: %s\n' % req.headers)self.log.debug('Content: %s\n' % req.content)self.requestnumber += 1return reqexcept requests.exceptions.RequestException as e:self.log.error('Something went wrong %s' % (e.__str__()))
这里重点看这一段:
req = requests.get(self.target, proxies=self.proxies, headers=h, timeout=timeout,allow_redirects=self.allowredir, params=params, verify=False)
因为我们已经初始化过一次全局的引擎了,这里request的参数引擎都是知道的,所以我们是不需要传参的。
显然wafw00f很高明,它把请求和处理分开了,所以我们后面再看看它的处理是如何实现的(比IdentYwaf要好上不少)
回到我们的主流程中,接下来我们就要调用rq了
if attacker.rq is None:log.error('Site %s appears to be down' % hostname)continue
现在我们可以看出来rq是做什么的了,就是测试网站是否还存活的,IdentYwaf看是否存活是看返回包的情况,而wafw00f是看是否有返回包,我个人认为wafw00f的方法更加好,因为很多网站是需要加上特定的path才能正常访问的,wafw00f这样可以避免访问结果为400等状况外的情况而不处理了的情况。(如果网站不存活了,那么是什么包都不会返回的,对,404都没有哈哈)
而且wafw00f使用的是request,可以处理重定向的网站,而IdentYwaf用的是urllib3,处理不了重定向,不能处理重定向就不能处理返回包状态为300的情况,所以IdentYwaf被wafw00f簿杀不是没有原因的。
如果网站还存活,那么我就可以去看看它是否有WAF了
当然,接下来还有一段是测试指定waf
这段我调试时没怎么管
waf = attacker.wafdetections[options.test](attacker)
这段代码里关键就是这个玩意,那么关键就是attacker这个WAFW00F实例化对象里的wafdetections是什么咯,这里还是先不分析了,后面我们讲到identwaf的时候会详细分析这个东西的。
所以这一长段循环总结下来就是:测试target网站还是否存活
接下来我们将来到整个main中最最最最最重要的一段代码:
waf = attacker.identwaf(options.findall)log.info('Identified WAF: %s' % waf)
这段也是大部分现在网上那些wafw00f什么分析的重点部分,当然我肯定不会像网上那样讲的了,那么跟着我接着看看attacker要干什么吧
核心是WAFW00F类重点identwaf方法
WAFW00F.identwaf()
前置有些内容我先提一下,再来分析这个函数:
首先是WAFW00F的使用的攻击payload
xsstring = '<script>alert("XSS");</script>'sqlistring = "UNION SELECT ALL FROM information_schema AND ' or SLEEP(5) or '"lfistring = '../../../../etc/passwd'rcestring = '/bin/cat /etc/passwd; ping 127.0.0.1; curl google.com'xxestring = '<!ENTITY xxe SYSTEM "file:///etc/shadow">]><pwn>&hack;</pwn>'
其次是WAFW00F的攻击手段
def nonExistent(self):return self.Request(path=self.path + str(random.randrange(100, 999)) + '.html')def xssAttack(self):return self.Request(path=self.path, params= {'s': self.xsstring})def xxeAttack(self):return self.Request(path=self.path, params= {'s': self.xxestring})def lfiAttack(self):return self.Request(path=self.path + self.lfistring)def centralAttack(self):return self.Request(path=self.path, params={'a': self.xsstring, 'b': self.sqlistring, 'c': self.lfistring})def sqliAttack(self):return self.Request(path=self.path, params= {'s': self.sqlistring})def oscAttack(self):return self.Request(path=self.path, params= {'s': self.rcestring})
接下来开始详细讲解identwaf是怎么实现的
def identwaf(self, findall=False):detected = list()try:self.attackres = self.performCheck(self.centralAttack)except RequestBlocked:return detectedfor wafvendor in self.checklist:self.log.info('Checking for %s' % wafvendor)if self.wafdetections[wafvendor](self):detected.append(wafvendor)if not findall:breakself.knowledge['wafname'] = detectedreturn detected
首先identwaf初始化了一个detected为空列表,用于存储该网站探查到的WAF保护情况
尝试寻找所有的WAF(如果findall为True)
def performCheck(self, request_method):r = request_method()if r is None:raise RequestBlocked()return r
首先尝试centralAttack
def centralAttack(self):return self.Request(path=self.path, params={'a': self.xsstring, 'b': self.sqlistring, 'c': self.lfistring})
如果有返回值,return这个返回值,如果没有,报错
不报错情况
self.attackres就等于这个返回值
一些必要参数
我们接着关注一下另外一些场外因素(类内全局变量)
wafdetections = dict()plugin_dict = load_plugins()result_dict = {}for plugin_module in plugin_dict.values():wafdetections[plugin_module.NAME] = plugin_module.is_waf# Check for prioritized ones first, then check those added externallychecklist = wafdetectionspriochecklist += list(set(wafdetections.keys()) - set(checklist))
load_plugins()
def load_plugins():here = os.path.abspath(os.path.dirname(__file__))get_path = partial(os.path.join, here)plugin_dir = get_path('plugins')plugin_base = PluginBase(package='wafw00f.plugins', searchpath=[plugin_dir])plugin_source = plugin_base.make_plugin_source(searchpath=[plugin_dir], persist=True)plugin_dict = {}for plugin_name in plugin_source.list_plugins():plugin_dict[plugin_name] = plugin_source.load_plugin(plugin_name)return plugin_dict
here相当于wafw00f库的绝对路径
get_path 实际上是 os.path.join(here, *args),即here必是os.path.join的一个参数,至于*args则是后续新添加的内容(可以学习这里wafw00f的partial的应用)
下面plugin_dir 就是指插件的地址
这段代码的主要目的是动态加载指定目录(这里是 ‘plugins’ 目录)下的插件,并将这些插件存储在一个字典中返回。它使用了 pluginbase 库来实现插件的动态加载。下面是对代码各部分的详细解释:
- 导入需要的包:pluginbase.PluginBase、os、functiontools.partial
- 确定插件目录: ○ here = os.path.abspath(os.path.dirname(file)):获取当前脚本的绝对路径。 ○ get_path =
partial(os.path.join, here):使用 functools.partial 创建一个新的函数
get_path,这个函数将 here 作为第一个参数传递给 os.path.join,允许你轻松地添加相对于当前脚本的路径。 ○
plugin_dir = get_path(‘plugins’):使用 get_path 函数获取 ‘plugins’ 目录的绝对路径。- 创建插件基础: ○ plugin_base = PluginBase(package=‘wafw00f.plugins’, searchpath=[plugin_dir]):创建一个 PluginBase 实例。package
参数指定了插件包的名称(这里可能是用于插件导入的命名空间),searchpath 指定了插件的搜索路径(即前面获取的
plugin_dir)。- 创建插件源: ○ plugin_source = plugin_base.make_plugin_source(searchpath=[plugin_dir],
persist=True):通过 plugin_base 实例创建一个插件源。searchpath 同样指定了插件的搜索路径,persist
参数设置为 True 表示插件源将尝试持久化已加载的插件信息,以优化后续加载。- 加载插件: ○ 初始化一个空字典 plugin_dict 用于存储加载的插件。 ○ 使用 for 循环遍历 plugin_source.list_plugins() 返回的插件名称列表。 ○ 对于每个插件名称,使用
plugin_source.load_plugin(plugin_name) 加载插件,并将其存储在 plugin_dict
中,键为插件名称,值为插件对象。- 返回插件字典:最后,函数返回包含所有加载插件的字典。
总结来说,这段代码通过 pluginbase 库动态加载了一个指定目录(‘plugins’)下的所有插件,并将它们以名称到对象的映射形式存储在一个字典中返回。这种机制允许应用程序在不重启的情况下动态扩展功能,只需添加新的插件到 ‘plugins’ 目录即可。
wafdetections
for plugin_module in plugin_dict.values():wafdetections[plugin_module.NAME] = plugin_module.is_waf
因为我们返回的plugin_dict是通过pluginbase和PluginBase.make_plugin_source来生成的,里面key值为每个plugin的文件名,而value是一共module类,module.NAME是每个plugin对WAF的命名,module.is_waf指的就是每个waf插件的识别函数,所以这里module相当于一个plugin文件:
NAME = 'Armor Defense (Armor)'def is_waf(self):schemes = [self.matchContent(r'blocked by website protection from armor'),self.matchContent(r'please create an armor support ticket')]if any(i for i in schemes):return Truereturn False
wafdetectionsprio
就是一个列表,里面包含了各个waf的命名
checklist
checklist很简单,就是把所有需要检查的waf整成列表,因为plugin是可扩展的,所以这里有可扩展兼容
checklist += list(set(wafdetections.keys()) - set(checklist))
后续检测
for wafvendor in self.checklist:self.log.info('Checking for %s' % wafvendor)if self.wafdetections[wafvendor](self):detected.append(wafvendor)if not findall:break
checklist前面已说,就是waf检测列表(有插件的waf才能被检测)
wafdetections也已说,是waf检测插件集合,举例
def is_waf(self):schemes = [self.matchContent(r'blocked by website protection from armor'),self.matchContent(r'please create an armor support ticket')]if any(i for i in schemes):return Truereturn False
所以其实就是调用了WAFW00F自身的matchContent等match方法来检测。
matchContent
def matchContent(self, regex, attack=True):if attack:r = self.attackreselse:r = self.rqif r is None:return# We may need to match multiline context in response bodyif re.search(regex, r.text, re.I):return Truereturn False
matchHeader
def matchHeader(self, headermatch, attack=False):if attack:r = self.attackreselse:r = self.rqif r is None:returnheader, match = headermatchheaderval = r.headers.get(header)if headerval:# set-cookie can have multiple headers, python gives it to us# concatinated with a commaif header == 'Set-Cookie':headervals = headerval.split(', ')else:headervals = [headerval]for headerval in headervals:if re.search(match, headerval, re.I):return Truereturn False
显然,wafw00f在检测上面更加灵活,对于有些waf它可能现在变成了5s盾那种类型,identYwaf直接向网站url发包检测盲猜很容易被5s盾拦截,但是identYwaf却不会处理5s盾(因为5s盾返回的不是HTML而是js等其它的包),而wafw00f则通过matchHeaders方法巧妙的避开了identYwaf僵硬匹配HTML的弊端!!!
identwaf函数总结
- 有两种模式,一般默认是指匹配一个waf,可以通过设置findall来选择是否尝试匹配全部的waf
- 这里self.attackres不清楚是做什么用的,总之它会测试centralAttack,如果centralAttack测试失败了,就会抛出一个错误,成功了则返回get到的值
- 基于centralAttack测试成功的情况,对每个waf进行测试,如果findall是False,那么找到一个就退出,否则全部找一遍,用detected暂存所有找到的waf,找完后再存到类实例的knowledge中
回到主流程中,后面我就不再分析了,剩下都是wafw00f的一些输出。
总结
首先wafw00f中心攻击识别效果奇好无比,而且很神奇可以处理5s盾这种情况,因为它为每种waf设置了一种检测插件,检测插件是个性化的,对应waf的插件可以灵活处理不同waf的差异,使得识别效果远远好于IdentYwaf
例如cloudflare:
#!/usr/bin/env python
'''
Copyright (C) 2022, WAFW00F Developers.
See the LICENSE file for copying permission.
'''NAME = 'Cloudflare (Cloudflare Inc.)'def is_waf(self):schemes = [self.matchHeader(('server', 'cloudflare')),self.matchHeader(('server', r'cloudflare[-_]nginx')),self.matchHeader(('cf-ray', r'.+?')),self.matchCookie('__cfduid')]if any(i for i in schemes):return Truereturn False
基本所有的cloudflare都是5s盾了现在(世界出名),IdentYwaf还是基于http请求的正则匹配来实现cloudflare识别,显然是不可行的。而wafw00f专门匹配cloudflare的cookie(cloudflare会设置指定的cookie名__cfduid),专门匹配返回包的headers等。
其次是wafw00f使用到了request来实现发包抓包,这显然比使用urllib3库的IdentYwaf要强上不少,至少可以处理重定向这种情况,且wafw00f如果想要实现cookie维护的话也可以使用request的session类来实现。总之到了今天,使用对urllib3封装的request显然比直接使用urllib3要好得多方便得多。
其实我在语雀上的笔记还做了很多内容,一篇文章好像塞不下这么多内容了,所以我就不管了,反正主体该说的都说了,剩下的大家自己理一理也差不多了。
相关文章:
wafw00f源码详细解析
声明 本人菜鸟一枚,为了完成作业,发现网上所有的关于wafw00f的源码解析都是这抄那那抄这的,没有新东西,所以这里给出一个详细的源码解析,可能有错误,如果有大佬发现错误,可以在评论区平和的指出…...

什么是crm?3000字详细解析
在现代商业环境中,客户关系管理(CRM)已经成为企业驱动成功的关键工具。在复杂且竞争激烈的市场中,如何有效地管理客户关系、提升客户满意度,并增加客户忠诚度,越来越成为企业迫切关心的问题。而CRM系统&…...

WEB3.0介绍
Web3.0是对Web2.0的改进,被视为互联网潜在的下一阶段。 以下是对Web3.0的详细介绍: 一、定义与概念 Web3.0被描述为一个运行在区块链技术之上的去中心化互联网。它旨在构建一个更加自主、智能和开放的互联网环境,其中用户不必 在不同中心化…...

【深度学习】LSTM、BiLSTM详解
文章目录 1. LSTM简介:2. LSTM结构图:3. 单层LSTM详解4. 双层LSTM详解5. BiLSTM6. Pytorch实现LSTM示例7. nn.LSTM参数详解 1. LSTM简介: LSTM是一种循环神经网络,它可以处理和预测时间序列中间隔和延迟相对较长的重要事件。LSTM通…...
分子对接--软件安装
分子对接相关软件安装 一、软件 AutoDock,下载链接: linkMGLtools,下载链接: link 自行选择合适版本下载,这里主要叙述在win上的具体安装流程: 下载得到: 二、运行 运行autodocksuite-4.2.6.i86Windows得到&#…...

【Python无敌】在 QGIS 中使用 Python
QGIS 中有 Python 的运行环境,可以很好地执行各种任务。 这里的问题是如何在 Jupyter 中调用 QGIS 的功能。 首先可以肯定的是涉及到 GUI 的一些任务是无法在 Jupyter 中访问的, 这样可以用的功能主要是地处理工具。 按如下方式进行了尝试。 原想使用 gdal:hillshade ,但是…...

全面解读:低代码开发平台的必备要素——系统策划篇
在传统开发过程中,系统策划起着举足轻重的作用,它宛如一位幕后的总指挥,把控着整个软件开发项目的走向。而随着技术的不断进步,低代码开发平台逐渐崭露头角,它以快速开发、降低技术门槛等优势吸引了众多企业和开发者的…...

Vue开发自动生成验证码功能 前端实现不使用第三方插件实现随机验证码功能,生成的验证码添加干扰因素
Vue实现不使用第三方插件,开发随机生成验证码功能 效果图,其中包含了短信验证码功能,以及验证码输入是否正确功能 dom结构 <div class="VerityInputTu"><div class="labelClass">图形验证码</div><div class="tuxingInput…...

# filezilla连接 虚拟机ubuntu系统出错“尝试连接 ECONNREFUSED - 连接被服务器拒绝, 失败,无法连接服务器”解决方案
filezilla连接 虚拟机ubuntu系统出错“尝试连接 ECONNREFUSED - 连接被服务器拒绝, 失败,无法连接服务器”解决方案 一、问题描述: 当我们用filezilla客户端 连接 虚拟机ubuntu系统时,报错“尝试连接 ECONNREFUSED - 连接被服务…...

2024/11/13 英语每日一段
The new policy has drawn many critics. Data and privacy experts said the Metropolitan Transit Authority’s new initiative doesn’t address the underlying problem that causes fare evasion, which is related to poverty and access. Instead, the program tries “…...

【全栈开发平台】全面解析 StackBlitz 最新力作 Bolt.new:AI 驱动的全栈开发平台
文章目录 [TOC]🌟 Bolt.new 的独特价值1. **无需配置,立刻开发**2. **AI 驱动,智能生成代码**3. **极致的速度与安全性**4. **一键部署,轻松上线**5. **免费开放,生态丰富** 🛠️ Bolt.new 使用教程一、快速…...
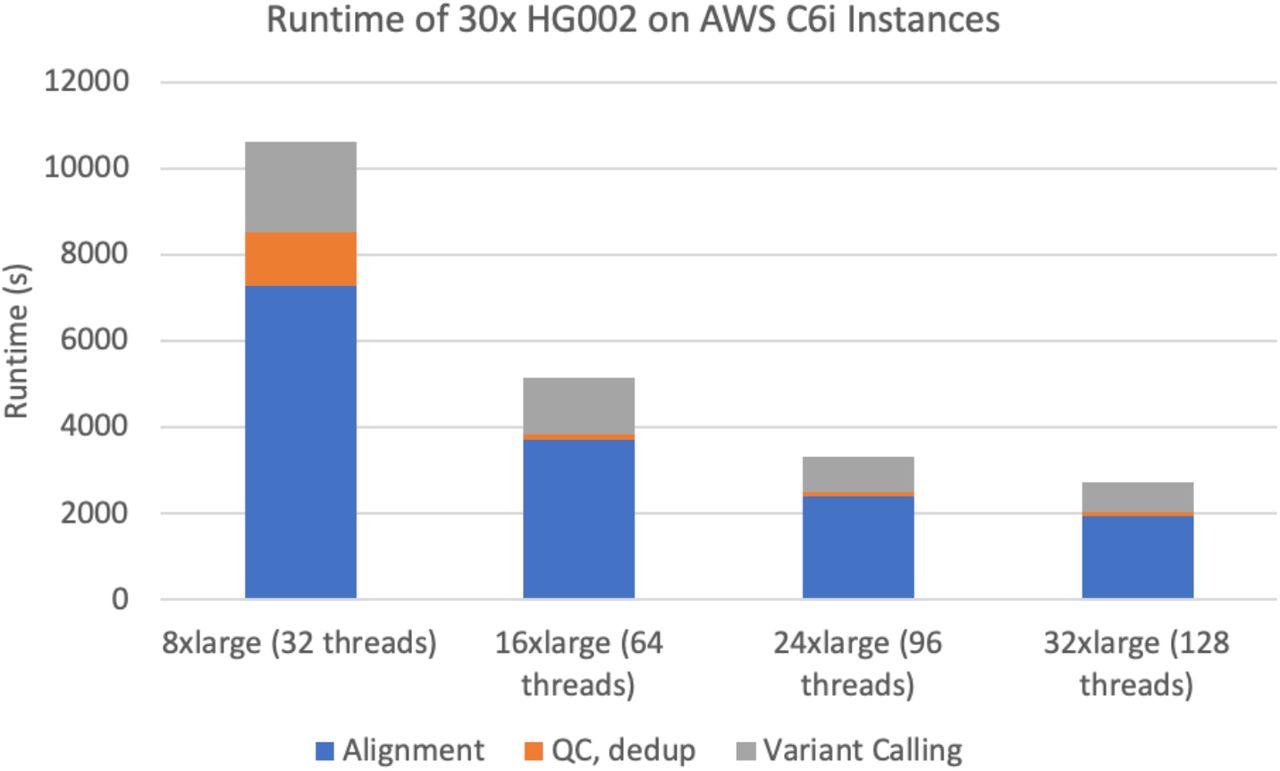
文献解读-DNAscope: High accuracy small variant calling using machine learning
关键词:基准与方法研究;基因测序;变异检测; 文献简介 标题(英文):DNAscope: High accuracy small variant calling using machine learning标题(中文):DNAsc…...

成都睿明智科技有限公司解锁抖音电商新玩法
在这个短视频风起云涌的时代,抖音电商以其独特的魅力迅速崛起,成为众多商家争夺的流量高地。而在这片充满机遇与挑战的蓝海中,成都睿明智科技有限公司犹如一颗璀璨的新星,以其专业的抖音电商服务,助力无数品牌实现从零…...

【操作系统】——调度算法
🌹😊🌹博客主页:【Hello_shuoCSDN博客】 ✨操作系统详见 【操作系统专项】 ✨C语言知识详见:【C语言专项】 目录 先来先服务(FCFS, First Come First Serve) 短作业优先(SJF, Shortest Job Fi…...

MySQL LOAD DATA INFILE导入数据报错
1.导入命令 LOAD DATA INFILE "merge.csv" INTO TABLE 报名数据 FIELDS TERMINATED BY , ENCLOSED BY " LINES TERMINATED BY \n IGNORE 1 LINES; 2.表结构 CREATE TABLE IF NOT EXISTS 报名数据 ( pid VARCHAR(100) NOT NULL, 查询日期 VARCHAR(25) NO…...

AI 写作(五)核心技术之文本摘要:分类与应用(5/10)
一、文本摘要:AI 写作的关键技术 文本摘要在 AI 写作中扮演着至关重要的角色。在当今信息爆炸的时代,人们每天都被大量的文本信息所包围,如何快速有效地获取关键信息成为了一个迫切的需求。文本摘要技术正是为了解决这个问题而诞生的&#x…...
贯穿软件开发生存周期中的测试)
CTFL(二)贯穿软件开发生存周期中的测试
贯穿软件开发生存周期中的测试 验收测试(acceptance testing),黑盒测试(black-box testing),组件集成测试(component integration testing),组件测试(compone…...

PMIC FS8405
FS8495 具有多个SMPS和LDO的故障安全系统基础芯片。 FS8X 大多数参数都是通过OTP寄存器设置的。 概述 FS85/FS84设备系列是按照ASIL D流程开发的,FS84具有ASIL B能力,而FS85具有ASIL D能力。所有的设备选项都是引脚到引脚和软件兼容的。 FS85/FS84是一种汽车功能安全…...
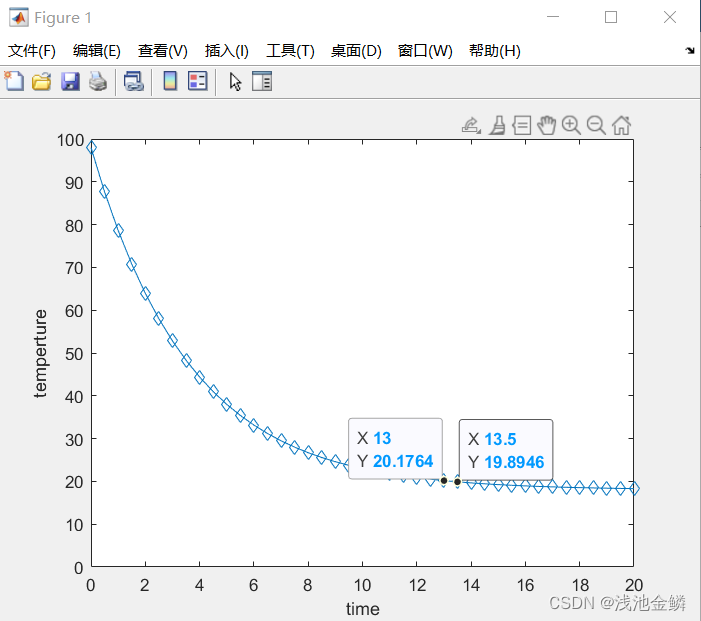
matlab建模入门指导
本文以水池中鸡蛋温度随时间的变化为切入点,对其进行数学建模并进行MATLAB求解,以更为通俗地进行数学建模问题入门指导。 一、问题简述 一个煮熟的鸡蛋有98摄氏度,将它放在18摄氏度的水池中,五分钟后鸡蛋的温度为38摄氏度&#x…...

微搭低代码入门03函数
目录 1 函数的定义与调用2 参数与返回值3 默认参数4 将功能拆分成小函数5 函数表达式6 箭头函数7 低代码中的函数总结 在用低代码开发软件的时候,除了我们上两节介绍的变量、条件语句外,还有一个重要的概念叫函数。函数是执行特定功能的代码片段…...

ComfyUI-Custom-Scripts自动完成终极指南:如何快速提升AI绘画提示词效率
ComfyUI-Custom-Scripts自动完成终极指南:如何快速提升AI绘画提示词效率 【免费下载链接】ComfyUI-Custom-Scripts Enhancements & experiments for ComfyUI, mostly focusing on UI features 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-Custom-Sc…...

3步掌握Sabaki围棋软件:从新手到高手的完整指南
3步掌握Sabaki围棋软件:从新手到高手的完整指南 【免费下载链接】Sabaki An elegant Go board and SGF editor for a more civilized age. 项目地址: https://gitcode.com/gh_mirrors/sa/Sabaki 在围棋的智慧世界里,一款优秀的软件能让您的学习和…...

魔兽争霸III终极优化指南:7大核心功能让经典游戏重获新生
魔兽争霸III终极优化指南:7大核心功能让经典游戏重获新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸III》在现代电脑…...

茉莉花插件:5分钟掌握Zotero中文文献管理终极方案
茉莉花插件:5分钟掌握Zotero中文文献管理终极方案 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在为中文文献管理…...

如何在5分钟内掌握Windows上最强大的屏幕标注工具ppInk
如何在5分钟内掌握Windows上最强大的屏幕标注工具ppInk 【免费下载链接】ppInk Fork from Gink 项目地址: https://gitcode.com/gh_mirrors/pp/ppInk 你是否曾在演示、教学或远程协作中,需要在屏幕上快速标注重点,却发现工具要么太复杂࿰…...
)
从main.cc到五大视图:手把手拆解QGC的UI启动流程(附QML与C++交互实例)
从main.cc到五大视图:手把手拆解QGC的UI启动流程(附QML与C交互实例) 当你第一次打开QGroundControl(QGC)时,那个简洁而功能强大的界面背后,隐藏着一套精妙的启动机制。作为一款广泛应用于无人机…...

用GoC画图搞定2018年5月那道‘场记板’编程题,附完整代码和思路拆解
用GoC画图还原2018年场记板编程题的完整解题思路 第一次看到这道场记板题目时,许多同学会被"n条竖线"的要求难住。其实只要拆解图形结构,用GoC的基础命令就能轻松实现。本文将从零开始,带你用分治法拆解这个经典考题,不…...

【独家首发】2026年AI知识管理工具淘汰预警:这7个曾上榜“年度创新”的产品已被头部科技公司集体弃用
更多请点击: https://kaifayun.com 第一章:2026年AI知识管理工具演进全景图 2026年,AI驱动的知识管理工具已从单点智能助手跃迁为组织级认知操作系统。其核心演进体现在三大维度:语义理解深度化、工作流原生融合、以及私有知识资…...

量子-经典混合计算平台架构:从监控溯源到弹性推理引擎
1. 项目概述:当量子计算遇见经典算力最近几年,我身边不少做高性能计算和AI的朋友,都开始把目光投向一个听起来有点“科幻”的领域——量子计算。但大家聊着聊着,总会回到一个非常现实的问题:我们实验室那台价值不菲的量…...

从能算到秒杀:零钱兑换与「最少硬币」的数学真相
如果说 279. 完全平方数 是在考你:👉 最少用几个平方数拼出一个数那 322. 零钱兑换 就是它的「现实版」:👉 最少用几枚硬币凑出一个金额这也是我第一次真正明白一句话:所有「最少数量」的问题,本质都是…...