【MongoDB】MongoDB的核心-索引原理及索引优化、及查询聚合优化实战案例(超详细)

文章目录
- 一、数据库查询效率问题引出索引需求
- 二、索引的基本原理及作用
- (一)索引的创建及数据组织
- (二)不同类型的索引
- (三)索引的额外属性
- 三、索引的优化与查询计划分析
- (一)通过profiling监测慢请求
- (二)查询计划分析优化索引使用
- 四、查询聚合优化
- (一)案例背景
- 问题描述
- 问题分析
- 1. 定位慢查询
- 2. 分析慢查询语句
- 第一步:`$match`操作
- 第二步:`$project`操作
- 第三步:`$group`操作
- 查看DB/Server/Collection的状态
- 1. DB状态
- 2. 查看`orders`这个collection的状态
- 性能优化
- 1. 性能优化 - 索引
- 2. 性能优化 - 聚合大量数据
- 小结
更多相关内容可查看
一、数据库查询效率问题引出索引需求
当在使用MongoDB等数据库进行集合查询时,如果遇到查询效率低下的情况,就可能需要考虑使用索引了。以MongoDB为例,在向集合插入多个文档后,每个文档经过底层存储引擎持久化会有一个位置信息(如mmapv1引擎里是『文件id + 文件内offset』,wiredtiger存储引擎里是其生成的一个key),通过这个位置信息能从存储引擎里读出该文档。
mongo-9552:PRIMARY> db.person.find()
{ "_id" : ObjectId("571b5da31b0d530a03b3ce82"), "name" : "jack", "age" : 19 }
{ "_id" : ObjectId("571b5dae1b0d530a03b3ce83"), "name" : "rose", "age" : 20 }
{ "_id" : ObjectId("571b5db81b0d530a03b3ce84"), "name" : "jack", "age" : 18 }
{ "_id" : ObjectId("571b5dc21b0d530a03b3ce85"), "name" : "tony", "age" : 21 }
{ "_id" : ObjectId("571b5dc21b0d530a03b3ce86"), "name" : "adam", "age" : 18 }
假设要执行一个查询操作,比如db.person.find( {age: 18} ),如果没有索引,就需要遍历所有的文档(即进行“全表扫描”),根据位置信息读出文档后,再对比age字段是否为18。当集合文档数量较少时,全表扫描的开销可能不大,但当文档数量达到百万、千万甚至上亿时,全表扫描的开销会非常大,一个查询耗费数十秒甚至几分钟都有可能。
二、索引的基本原理及作用
(一)索引的创建及数据组织
比如上面的例子里,person集合里包含插入了5个文档,假设其存储后位置信息如下
| 位置信息 | 文档 |
|---|---|
| pos1 | {“name” : “jack”, “age” : 19 } |
| pos2 | {“name” : “rose”, “age” : 20 } |
| pos3 | {“name” : “jack”, “age” : 18 } |
| pos4 | {“name” : “tony”, “age” : 21} |
| pos5 | {“name” : “adam”, “age” : 18} |
如果想加速 db.person.find( {age: 18} ),就可以考虑对person表的age字段建立索引。
db.person.createIndex( {age: 1} ) // 按age字段创建升序索引
建立索引后,MongoDB会额外存储一份按age字段升序排序的索引数据,索引结构类似如下,索引通常采用类似btree的结构持久化存储,以保证从索引里快速(O(logN)的时间复杂度)找出某个age值对应的位置信息,然后根据位置信息就能读取出对应的文档。
| age | 位置信息 |
|---|---|
| 18 | pos3 |
| 18 | pos5 |
| 19 | pos1 |
| 20 | pos2 |
| 21 | pos4 |
简单来说,索引就是将文档按照某个(或某些)字段顺序组织起来,以便能根据该字段高效地进行查询。它至少能优化以下场景的效率:
- 查询场景:比如查询年龄为18的所有人,有了索引就无需全表扫描,可直接通过索引快速定位到符合条件的文档。
- 更新/删除场景:在将年龄为18的所有人的信息进行更新或删除时,因为更新或删除操作需要先根据条件查询出所有符合条件的文档,所以本质上也是在优化查询环节。
- 排序场景:将所有人的信息按年龄排序时,如果没有索引,需要全表扫描文档,然后再对扫描的结果进行排序;而有了索引,可利用索引的有序性更高效地完成排序。
MongoDB默认会为插入的文档生成_id字段(如果应用本身没有指定该字段),并且为了保证能根据文档id快速查询文档,MongoDB默认会为集合创建_id字段的索引。
mongo-9552:PRIMARY> db.person.getIndexes() // 查询集合的索引信息
[{"ns" : "test.person", // 集合名"v" : 1, // 索引版本"key" : { // 索引的字段及排序方向"_id" : 1 // 根据_id字段升序索引},"name" : "_id_" // 索引的名称}
]
(二)不同类型的索引
MongoDB支持多种类型的索引,每种类型适用于不同的使用场合:
-
单字段索引(Single Field Index):
- 通过
db.person.createIndex( {age: 1} )语句可针对age创建单字段索引,能加速对age字段的各种查询请求,是最常见的索引形式,MongoDB默认创建的_id索引也属于这种类型。 {age: 1}代表升序索引,也可通过{age: -1}来指定降序索引,对于单字段索引,升序/降序效果是一样的。db.person.createIndex( {age: 1, name: 1} )
- 通过
-
复合索引 (Compound Index):
- 它是单字段索引的升级版本,针对多个字段联合创建索引,先按第一个字段排序,第一个字段相同的文档按第二个字段排序,依次类推。例如,通过
db.person.createIndex( {age: 1, name: 1} )可针对age、name这2个字段创建一个复合索引。 - 复合索引能满足的查询场景比单字段索引更丰富,不光能满足多个字段组合起来的查询(如
db.person.find( {age: 18, name: "jack"} )),也能满足匹配复合索引前缀的查询(如{age: 1}是{age: 1, name: 1}的前缀,所以db.person.find( {age: 18} )的查询也能通过该索引来加速),但像db.person.find( {name: "jack"} )这种只涉及部分字段且不符合前缀规则的查询则无法使用该复合索引。在创建复合索引时,字段的顺序除了受查询需求影响,还需考虑字段的值分布情况。比如age字段取值有限,相同age的文档较多,而name字段取值丰富,相同name的文档较少,此时先按name字段查找,再在相同name的文档里查找age字段会更为高效。db.person.createIndex( {name: 1, age: 1} )
- 它是单字段索引的升级版本,针对多个字段联合创建索引,先按第一个字段排序,第一个字段相同的文档按第二个字段排序,依次类推。例如,通过
-
多key索引 (Multikey Index):
- 当索引的字段为数组时,创建出的索引称为多key索引。例如,在
person表加入一个habbit字段(数组)用于描述兴趣爱好,通过db.person.createIndex( {habbit: 1} )可自动创建多key索引,用于查询有相同兴趣爱好的人。{"name" : "jack", "age" : 19, habbit: ["football, runnning"]}db.person.createIndex( {habbit: 1} ) // 自动创建多key索引db.person.find( {habbit: "football"} )
- 当索引的字段为数组时,创建出的索引称为多key索引。例如,在
-
其他类型索引:
- 哈希索引(Hashed Index):按照某个字段的hash值来建立索引,目前主要用于MongoDB Sharded Cluster的Hash分片,hash索引只能满足字段完全匹配的查询,不能满足范围查询等。
- 地理位置索引(Geospatial Index):能很好地解决O2O的应用场景,比如“查找附近的美食”、“查找某个区域内的车站”等。
- 文本索引(Text Index):能解决快速文本查找的需求,比如对于一个博客文章集合,可针对博客的内容建立文本索引,以便根据博客内容快速查找。
(三)索引的额外属性
MongoDB除了支持多种不同类型的索引,还能对索引定制一些特殊的属性:
- 唯一索引 (unique index):保证索引对应的字段不会出现相同的值,比如
_id索引就是唯一索引。 - TTL索引:可以针对某个时间字段,指定文档的过期时间(经过指定时间后过期 或 在某个时间点过期)。
- 部分索引 (partial index):只针对符合某个特定条件的文档建立索引,在3.2版本才支持该特性。
- 稀疏索引(sparse index):只针对存在索引字段的文档建立索引,可看做是部分索引的一种特殊情况。
三、索引的优化与查询计划分析
(一)通过profiling监测慢请求
MongoDB支持对DB的请求进行profiling,目前支持3种级别的profiling:
- 0级:不开启profiling。
- 1级:将处理时间超过某个阈值(默认100ms)的请求都记录到DB下的system.profile集合(类似于mysql、redis的slowlog),生产环境通常建议使用此级别,并根据自身需求配置合理的阈值,用于监测慢请求的情况,以便及时进行索引优化。
- 2级:将所有的请求都记录到DB下的system.profile集合,生产环境需慎用。
(二)查询计划分析优化索引使用
当索引已经建立了,但查询还是很慢时,就需要深入分析索引的使用情况,可通过查看详细的查询计划来决定如何优化。通过执行计划可以看出以下问题:
- 根据某个/些字段查询,但没有建立索引。
- 根据某个/些字段查询,但建立了多个索引,执行查询时没有使用预期的索引。
例如,建立索引前,db.person.find( {age: 18} )必须执行COLLSCAN(全表扫描);
mongo-9552:PRIMARY> db.person.find({age: 18}).explain()
{"queryPlanner" : {"plannerVersion" : 1,"namespace" : "test.person","indexFilterSet" : false,"parsedQuery" : {"age" : {"$eq" : 18}},"winningPlan" : {"stage" : "COLLSCAN","filter" : {"age" : {"$eq" : 18}},"direction" : "forward"},"rejectedPlans" : [ ]},"serverInfo" : {"host" : "localhost","port" : 9552,"version" : "3.2.3","gitVersion" : "b326ba837cf6f49d65c2f85e1b70f6f31ece7937"},"ok" : 1
}
建立索引后,通过查询计划可以看出,先进行[IXSCAN](从索引中查找),然后FETCH`,读取出满足条件的文档。
mongo-9552:PRIMARY> db.person.find({age: 18}).explain()
{"queryPlanner" : {"plannerVersion" : 1,"namespace" : "test.person","indexFilterSet" : false,"parsedQuery" : {"age" : {"$eq" : 18}},"winningPlan" : {"stage" : "FETCH","inputStage" : {"stage" : "IXSCAN","keyPattern" : {"age" : 1},"indexName" : "age_1","isMultiKey" : false,"isUnique" : false,"isSparse" : false,"isPartial" : false,"indexVersion" : 1,"direction" : "forward","indexBounds" : {"age" : ["[18.0, 18.0]"]}}},"rejectedPlans" : [ ]},"serverInfo" : {"host" : "localhost","port" : 9552,"version" : "3.2.3","gitVersion" : "b326ba837cf6f49d65c2f85e1b70f6f31ece7937"},"ok" : 1
}
需要注意的是,索引并不是越多越好,集合的索引太多,会影响写入、更新的性能,因为每次写入都需要更新所有索引的数据。所以system.profile里的慢请求可能是索引建立得不够导致,也可能是索引过多导致。
四、查询聚合优化
(一)案例背景
我们有一个电商订单分析系统,使用MongoDB存储订单数据。当执行一个分析接口,获取特定店铺在某一周内的订单商品分类统计信息时,发现查询速度非常慢,严重影响用户体验。
问题描述
执行订单分析接口,查询特定店铺(假设店铺ID为“20001”)在某一周(2024 - 05 - 01T00:00:00.000Z到2024 - 05 - 07T23:59:59.999Z)内的订单商品分类统计,需要花费约12秒,这明显不符合性能要求。
问题分析
1. 定位慢查询
首先查看当前mongo profile的级别,通过db.getProfilingLevel()发现其为0,即默认没有记录。设置profile级别为记录慢查询模式,设置阈值为1000ms,即db.setProfilingLevel(1, 1000)。再次执行订单分析查询接口,查看Profile记录。
2. 分析慢查询语句
通过查看Profile记录,发现执行的查询是一个聚合管道(pipeline):
第一步:$match操作
{"$match": {"storeId": "20001","$and": [{"orderTime": {"$gte": ISODate("2024-05-01T00:00:00.000Z"),"$lte": ISODate("2024-05-07T23:59:59.999Z")}}]}
}
用于匹配店铺ID为“20001”且订单时间在指定一周内的订单记录。
第二步:$project操作
{"$project": {"productCategory": 1,"orderDate": {"$concat": [{"$substr": [{"$year": ["$orderTime"]},0,4]},"-",{"$substr": [{"$month": ["$orderTime"]},0,2]},"-",{"$substr": [{"$dayOfMonth": ["$orderTime"]},0,2]}]}}
}
除了提取productCategory字段外,还对orderTime字段进行处理,拼接为“yyyy - MM - dd”格式,并将其命名为orderDate。
第三步:$group操作
{"$group": {"_id": {"orderDate": "$orderDate","productCategory": "$productCategory"},"count": {"$sum": 1}}
}
对orderDate和productCategory进行分组,统计不同日期和商品分类对应的订单数量。
从Profile中可以看到相关指标:
millis:花费了12010毫秒返回查询结果。ts:命令执行时间。info:命令内容。query:代表查询。ns:ecommerce.orders(代表查询的库与集合)。nreturned:返回记录数及用时。reslen:返回的结果集大小(字节数)。nscanned:扫描记录数量。
发现nscanned数很大,接近记录总数,可能没有使用索引查询。
查看DB/Server/Collection的状态
1. DB状态
查看数据库整体状态,包括服务器版本、运行时间、连接数、各种操作计数器(如插入、查询、更新、删除等操作的次数)、存储引擎信息等。示例部分信息如下:
{"host": "ECOMMONGODB","version": "6.0.5","process": "mongod","pid": NumberLong(2005),"uptime": 12345678.0,"uptimeMillis": NumberLong(12345678901),"uptimeEstimate": NumberLong(12345678),"localTime": ISODate("2024-05-08T10:20:30.123Z"),"asserts": {"regular": 0,"warning": 0,"msg": 0,"user": 12345,"rollovers": 0},"connections": {"current": 120,"available": 800,"totalCreated": 13000},// 其他更多信息..."ok": 1.0
}
2. 查看orders这个collection的状态
{"ns": "ecommerce.orders","size": 987654321,"count": 3500000,"avgObjSize": 282,"storageSize": 234567890,"capped": false,"wiredTiger": {// wiredTiger存储引擎相关详细信息...},"nindexes": 1,"totalIndexSize": 30123456,"indexSizes": {"_id_": 30123456},"ok": 1.0
}
性能优化
1. 性能优化 - 索引
目前只有_id索引,接下来对orders集合创建storeId、orderTime和productCategory字段的索引:
db.orders.ensureIndex({"storeId": 1, "orderTime": 1, "productCategory": 1});
db.orders.ensureIndex({"orderTime": 1});
db.orders.ensureIndex({"productCategory": 1});
db.orders.ensureIndex({"storeId": 1});
创建索引后,查询特定店铺一周内的订单商品分类统计信息,时间缩短到了500ms,效果显著。但当查询一个月的数据时,仍然需要15秒。
通过增加索引小结:添加索引解决了针对索引字段查询的效率问题,但对于大量数据的聚合操作,仅靠索引不能完全解决性能问题。例如,在没有索引的情况下,从500万条数据中找出特定店铺的订单可能需要全表扫描,耗时很长;而有了索引,命中索引查询(IXSCAN)速度提升明显。不过,对于聚合操作,随着数据量增大,性能问题依然存在。同时,判断效率优化情况应该看执行计划,而不仅仅是执行时间,因为执行时间可能受到多种因素影响。
2. 性能优化 - 聚合大量数据
对于这种查询聚合大量数据的问题,考虑到这是一个类似OLAP的操作,对其性能期望不能过高,因为大量数据的I/O操作远超OLTP操作。但仍有一定的优化空间:
- 在订单插入或更新时,对每个店铺每天的每个商品分类的订单数量进行实时计数,并存储在一个专门的缓存集合中。例如,以
{storeId: "20001", orderDate: "2024-05-01", productCategory: "Electronics", count: 10}的形式存储。 - 每隔一段时间(如每天凌晨)对缓存集合进行一次完整的统计和更新,确保数据的准确性。这样在查询订单商品分类统计信息时,可以直接从缓存集合中获取数据,大大减少了查询和聚合的时间。
小结
- 慢查询定位:通过Profile分析慢查询。
- 查询优化:通过添加相应索引提升查询速度。
- 聚合大数据方案:对于类似OLAP的聚合操作,要合理降低性能期望。从源头入手,在数据插入或更新时做好部分统计工作,缓存结果,以便在查询时直接使用,从而提升整体性能。同时,要结合执行计划来评估优化效果。
相关文章:
【MongoDB】MongoDB的核心-索引原理及索引优化、及查询聚合优化实战案例(超详细)
文章目录 一、数据库查询效率问题引出索引需求二、索引的基本原理及作用(一)索引的创建及数据组织(二)不同类型的索引(三)索引的额外属性 三、索引的优化与查询计划分析(一)通过prof…...

qt QProcess详解
1、概述 QProcess是Qt框架提供的一个类,它用于在应用程序中执行外部进程。QProcess提供了一系列函数来启动、控制和与外部进程进行交互,使得开发者能够在自己的应用程序中集成和调用其他程序或服务。这个类在需要执行系统命令、启动其他应用程序或进行文…...

软件测试面试2024最新热点问题
大厂面试热点问题 1、测试人员需要何时参加需求分析? 如果条件循序 原则上来说 是越早介入需求分析越好 因为测试人员对需求理解越深刻 对测试工作的开展越有利 可以尽早的确定测试思路 减少与开发人员的交互 减少对需求理解上的偏差 2、软件测试与调试的关系 测…...
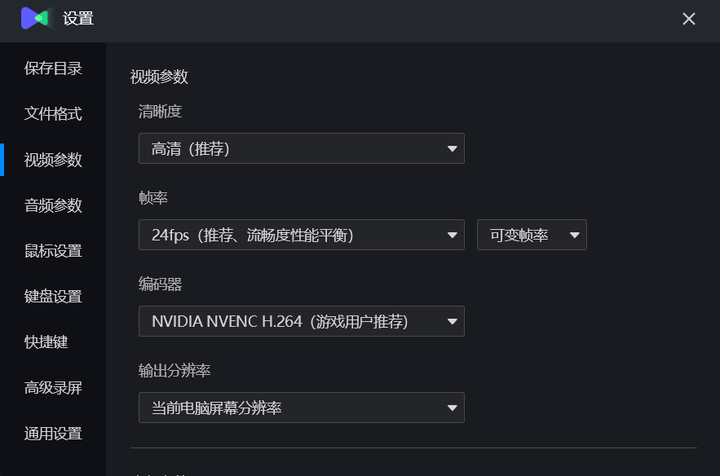
10款录屏工具推荐,聊聊我的使用心得!!!!
录屏软件已经成为我们的得力助手。不管是学习还是培训,或者工作会议等都时常需要录屏操作。经过深入实践和对比,我尝试了多款录屏软件。现在,我就来聊聊我个人使用过的几款录屏软件:我会尽量用最通俗的语言,分享我对这…...

VMware+Ubuntu+finalshell连接
安装教程:博客链接 下载地址:VMwareubuntu finalshell官网下载:finalshelll...

autodl+modelscope推理stable-diffusion-3.5-large
本篇介绍如何在服务器上实现SD3.5模型的加载及推理,不包含训练及微调。 磁盘扩容 autodl服务器在关机状态下,进行扩容: 选择要扩容的大小(比如我这里已经扩了80G,默认有50G免费的),就会有一…...

深度学习之 LSTM
1.1 LSTM的产生原因 RNN在处理长期依赖(时间序列上距离较远的节点)时会遇到巨大的困难,因为计算距离较远的节点之间的联系时会涉及雅可比矩阵的多次相乘,会造成梯度消失或者梯度膨胀的现象。为了解决该问题,研究人…...

LeetCode 3242.设计相邻元素求和服务:哈希表
【LetMeFly】3242.设计相邻元素求和服务:哈希表 力扣题目链接:https://leetcode.cn/problems/design-neighbor-sum-service/ 给你一个 n x n 的二维数组 grid,它包含范围 [0, n2 - 1] 内的不重复元素。 实现 neighborSum 类: …...

【AliCloud】ack + ack-secret-manager + kms 敏感数据安全存储
介绍 ack-secret-manager支持以Kubernetes Secret实例的形式向集群导入或同步KMS凭据信息,确保您集群内的应用能够安全地访问敏感信息。通过该组件,您可以实现密钥数据的自动更新,使应用负载通过文件系统挂载指定Secret实例来使用凭据信息&a…...

探索JavaScript的强大功能:从基础到高级应用
随着互联网技术的不断发展,JavaScript已经成为现代Web开发的基石。无论是简单的交互效果,还是复杂的前端框架,JavaScript都在其中扮演着不可或缺的角色。本文旨在对JavaScript进行深入探讨,从其基础概念到高级应用,并讨…...

新增支持Elasticsearch数据源,支持自定义在线地图风格,DataEase开源BI工具v2.10.2 LTS发布
2024年11月11日,人人可用的开源BI工具DataEase正式发布v2.10.2 LTS版本。 这一版本的功能变动包括:数据源方面,新增了对Elasticsearch数据源的支持;图表方面,对地图类和表格类图表进行了功能增强和优化,增…...

Spark的容错机制
1,Spark如何保障数据的安全 1、RDD容错机制:persist持久化机制 1)cache算子 - 功能:将RDD缓存在内存中 - 语法:cache() - 本质:底层调用的还是persist(StorageLevel.MEMORY_ONLY)&…...

YOLOv8改进 | 利用YOLOv8进行视频划定区域目标统计计数
简介 本项目旨在利用YOLOv8算法来实现视频中划定区域目标的统计计数。YOLOv8是一种目标检测算法,能够实现实时目标检测和定位。视频划定区域目标统计计数是指在一个视频中,对于指定的区域,统计出该区域内出现的目标物体数量。 该项目的工作流程如下:首先,利用YOLOv8算法…...

基于yolov8、yolov5的番茄成熟度检测识别系统(含UI界面、训练好的模型、Python代码、数据集)
摘要:番茄成熟度检测在农业生产及质量控制中起着至关重要的作用,不仅能帮助农民及时采摘成熟的番茄,还为自动化农业监测提供了可靠的数据支撑。本文介绍了一款基于YOLOv8、YOLOv5等深度学习框架的番茄成熟度检测模型,该模型使用了…...

wafw00f源码详细解析
声明 本人菜鸟一枚,为了完成作业,发现网上所有的关于wafw00f的源码解析都是这抄那那抄这的,没有新东西,所以这里给出一个详细的源码解析,可能有错误,如果有大佬发现错误,可以在评论区平和的指出…...

什么是crm?3000字详细解析
在现代商业环境中,客户关系管理(CRM)已经成为企业驱动成功的关键工具。在复杂且竞争激烈的市场中,如何有效地管理客户关系、提升客户满意度,并增加客户忠诚度,越来越成为企业迫切关心的问题。而CRM系统&…...

WEB3.0介绍
Web3.0是对Web2.0的改进,被视为互联网潜在的下一阶段。 以下是对Web3.0的详细介绍: 一、定义与概念 Web3.0被描述为一个运行在区块链技术之上的去中心化互联网。它旨在构建一个更加自主、智能和开放的互联网环境,其中用户不必 在不同中心化…...

【深度学习】LSTM、BiLSTM详解
文章目录 1. LSTM简介:2. LSTM结构图:3. 单层LSTM详解4. 双层LSTM详解5. BiLSTM6. Pytorch实现LSTM示例7. nn.LSTM参数详解 1. LSTM简介: LSTM是一种循环神经网络,它可以处理和预测时间序列中间隔和延迟相对较长的重要事件。LSTM通…...
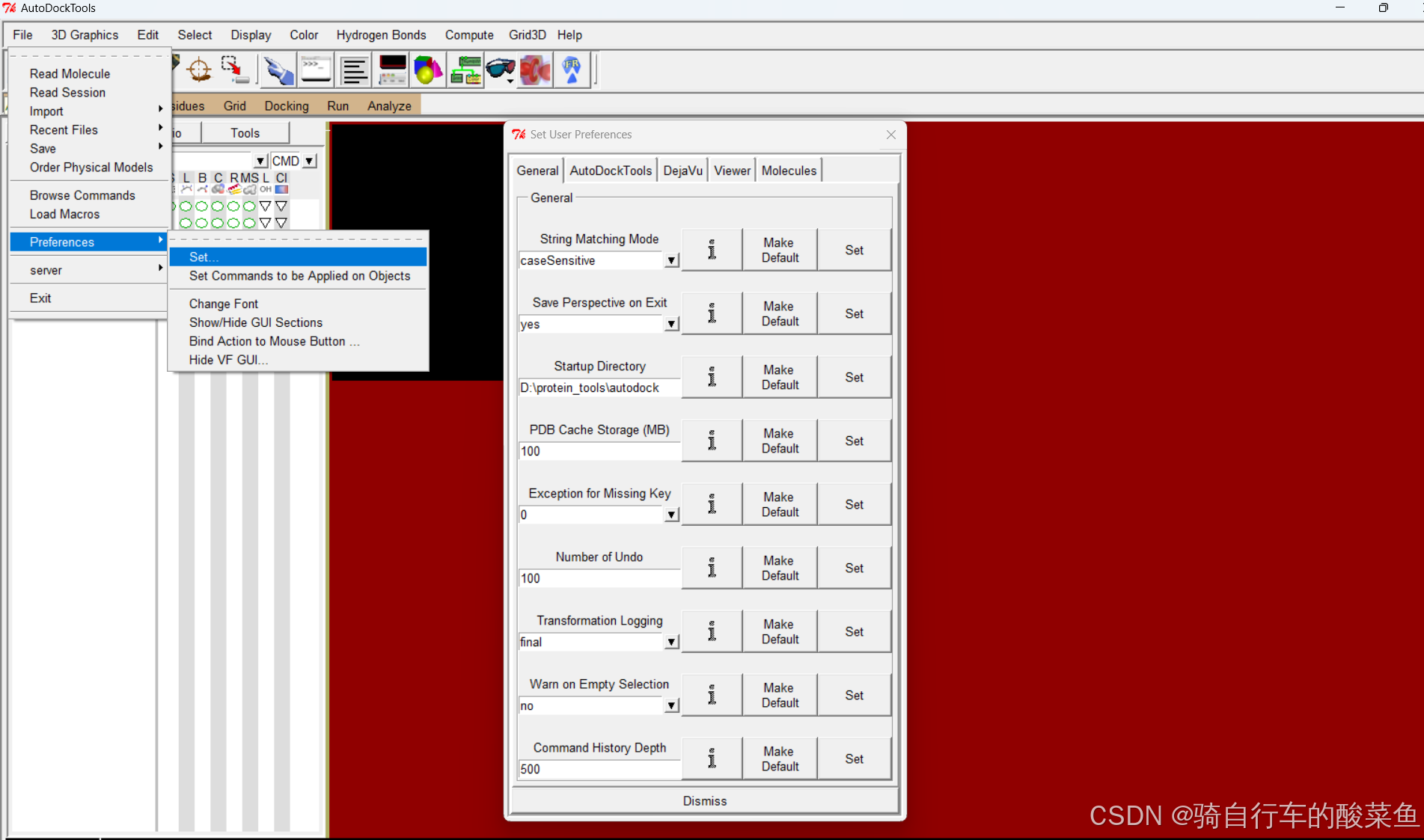
分子对接--软件安装
分子对接相关软件安装 一、软件 AutoDock,下载链接: linkMGLtools,下载链接: link 自行选择合适版本下载,这里主要叙述在win上的具体安装流程: 下载得到: 二、运行 运行autodocksuite-4.2.6.i86Windows得到&#…...

【Python无敌】在 QGIS 中使用 Python
QGIS 中有 Python 的运行环境,可以很好地执行各种任务。 这里的问题是如何在 Jupyter 中调用 QGIS 的功能。 首先可以肯定的是涉及到 GUI 的一些任务是无法在 Jupyter 中访问的, 这样可以用的功能主要是地处理工具。 按如下方式进行了尝试。 原想使用 gdal:hillshade ,但是…...

3分钟学会洛雪音乐音源配置:免费获取全网高品质音乐的终极指南
3分钟学会洛雪音乐音源配置:免费获取全网高品质音乐的终极指南 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 还在为找不到高质量免费音乐资源而烦恼吗?lxmusic-项目为你提…...

对比按量计费与套餐计划在长期项目中的成本差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按量计费与套餐计划在长期项目中的成本差异 在长期技术项目的规划中,成本管理是一个需要持续关注的环节。对于依赖…...

终极指南:如何用TQVaultAE管理你的泰坦之旅装备库
终极指南:如何用TQVaultAE管理你的泰坦之旅装备库 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 你是否曾在《泰坦之旅周年版》中因为背包空间不足而烦恼&#…...

微信小程序161~200
收货地址实现删除收货地址删除滑块SwipeCell自动收起调用之前的swipeCell商品管理配置商品管理分包-封装商品模块接口import http from "../utils/http"/*** description 获取商品列表数据* param {Object} param {page,limit,categoryId,category2Id}* returns Prom…...
格式为什么无处不在)
从手机拍照到视频播放:一文看懂YUV(NV12/YUV444)格式为什么无处不在
从手机拍照到视频播放:YUV格式的技术演进与行业实践 当你用手机拍摄一张照片或录制一段视频时,图像数据在传感器采集后经历了一系列复杂的格式转换过程。这些转换不仅关乎图像质量,更直接影响着存储空间、处理速度和传输效率。在众多色彩编码…...

DKC02.3-200-7-FW伺服驱动器
Rexroth DKC02.3-200-7-FW 是博世力士乐 Indramat 系列的高性能数字伺服驱动器,专为高动态响应的工业自动化场景设计。大电流输出:额定100A,峰值200A,满足高负载需求。宽压输入:支持200-480V AC,适应全球电…...

如何5分钟掌握SD-PPP:Photoshop AI插件完整入门指南
如何5分钟掌握SD-PPP:Photoshop AI插件完整入门指南 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp SD-PPP是一款革命性的Photoshop AI插件,它将强大的AI绘图能力无缝集成到Adobe Photoshop…...

5分钟掌握BepInEx游戏插件框架:Unity模组开发的完整解决方案
5分钟掌握BepInEx游戏插件框架:Unity模组开发的完整解决方案 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx(Bepis Injector Extensible࿰…...
第四章——成员变量的默认值)
Java程序设计(第3版)第四章——成员变量的默认值
成员变量的默认值 1.成员变量和局部变量不同,对于成员变量而言,系统会为其分配一个默认值 2.默认值的规则同数组: 整数类型0 小数类型:0.0 布尔类型:false 字符类型:‘\u0000’(空字符) 引用类型…...

7步搞定MASA全家桶汉化包:让你的Minecraft模组说中文
7步搞定MASA全家桶汉化包:让你的Minecraft模组说中文 【免费下载链接】masa-mods-chinese 一个masa mods的汉化资源包 项目地址: https://gitcode.com/gh_mirrors/ma/masa-mods-chinese 还在为MASA模组的英文界面而烦恼吗?作为中文Minecraft玩家&…...