【大数据测试HDFS + Flask详细教程与实例】
大数据测试HDFS + Flask
- 1. 环境准备
- 安装工具
- 安装Hadoop(以单机模式为例)
- 安装Flask和HDFS Python客户端
- 2. HDFS + Flask基本架构
- 基本文件结构
- 3. 创建Flask应用与与HDFS交互
- 步骤1:配置HDFS连接
- 步骤2:构建Flask应用
- 4. 创建前端界面
- index.html
- style.css(可选,添加一些样式)
- 5. 启动应用
- 6. 测试功能
- 7. 扩展功能
HDFS(Hadoop分布式文件系统)和Flask是两个非常常见的技术栈。在大数据领域,HDFS是用于存储海量数据的分布式文件系统,而Flask是一个轻量级的Python Web框架。结合HDFS和Flask,通常用于构建大数据应用,尤其是在数据处理和可视化过程中,提供一种接口来访问和展示存储在HDFS上的数据。
1. 环境准备
安装工具
-
Hadoop(HDFS)环境:
需要安装和配置Hadoop集群或单机模式。如果没有现成的Hadoop集群,可以通过Docker或者虚拟机搭建一个简单的Hadoop环境,或使用Hadoop单机模式进行测试。 -
Flask框架:
Flask是一个轻量级的Python Web框架,可以通过pip轻松安装。 -
Hadoop Python客户端(
hdfs):
为了通过Python与HDFS交互,我们需要安装hdfs客户端库,它是与HDFS进行交互的桥梁。
安装Hadoop(以单机模式为例)
- 下载并解压Hadoop:https://hadoop.apache.org/releases.html
- 配置Hadoop的环境变量,在
~/.bashrc中添加:export HADOOP_HOME=/path/to/hadoop export PATH=$PATH:$HADOOP_HOME/bin export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop - 配置Hadoop的XML配置文件(
core-site.xml,hdfs-site.xml)以启用HDFS。启动HDFS:$ hadoop namenode -format $ start-dfs.sh
安装Flask和HDFS Python客户端
- 安装Flask:
pip install flask - 安装
hdfs库(用于Python与HDFS交互):pip install hdfs
2. HDFS + Flask基本架构
Flask应用将提供HTTP接口,允许用户:
- 上传文件到HDFS
- 下载文件从HDFS
- 查看存储在HDFS上的文件列表
基本文件结构
project/
├── app.py # Flask应用
├── templates/ # HTML模板
│ ├── index.html # 上传与下载界面
└── static/ # 静态文件(如CSS、JavaScript)└── style.css # 页面样式
3. 创建Flask应用与与HDFS交互
步骤1:配置HDFS连接
在Flask应用中,我们通过hdfs库来连接HDFS。首先,我们需要配置HDFS的URL和端口。
from hdfs import InsecureClient# 配置HDFS的地址
HDFS_URL = 'http://localhost:50070' # HDFS Web UI 默认端口
client = InsecureClient(HDFS_URL)
步骤2:构建Flask应用
接下来,我们会创建一个Flask应用,允许用户上传文件到HDFS并展示上传的文件列表。
app.py:
from flask import Flask, render_template, request, redirect, url_for
from hdfs import InsecureClient
import osapp = Flask(__name__)# 配置HDFS客户端
HDFS_URL = 'http://localhost:50070' # HDFS Web UI 默认端口
client = InsecureClient(HDFS_URL)# HDFS存储的目标路径
HDFS_DIR = '/user/hadoop/test'# 确保HDFS上的目录存在
if not client.status(HDFS_DIR, strict=False):client.makedirs(HDFS_DIR)@app.route('/')
def index():# 获取HDFS上的文件列表files = client.list(HDFS_DIR)return render_template('index.html', files=files)@app.route('/upload', methods=['POST'])
def upload_file():# 获取上传的文件file = request.files['file']if file:local_file_path = os.path.join('/tmp', file.filename) # 临时保存上传的文件file.save(local_file_path)# 将文件上传到HDFShdfs_path = os.path.join(HDFS_DIR, file.filename)client.upload(hdfs_path, local_file_path)os.remove(local_file_path) # 删除临时文件return redirect(url_for('index'))@app.route('/download/<filename>')
def download_file(filename):# 从HDFS下载文件hdfs_path = os.path.join(HDFS_DIR, filename)local_path = os.path.join('/tmp', filename)client.download(hdfs_path, local_path)return send_from_directory('/tmp', filename)if __name__ == '__main__':app.run(debug=True)
4. 创建前端界面
使用Flask的render_template渲染HTML模板,构建简单的上传与下载页面。
index.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>HDFS File Management</title><link rel="stylesheet" href="{{ url_for('static', filename='style.css') }}">
</head>
<body><h1>HDFS File Management</h1><h2>Upload File to HDFS</h2><form action="/upload" method="POST" enctype="multipart/form-data"><input type="file" name="file" required><button type="submit">Upload</button></form><h2>Files in HDFS</h2><ul>{% for file in files %}<li>{{ file }}<a href="{{ url_for('download_file', filename=file) }}">Download</a></li>{% endfor %}</ul>
</body>
</html>
style.css(可选,添加一些样式)
body {font-family: Arial, sans-serif;
}h1 {color: #333;
}h2 {margin-top: 20px;
}form {margin-bottom: 20px;
}ul {list-style-type: none;
}li {margin: 10px 0;
}
5. 启动应用
- 启动HDFS(如果未启动)。
- 启动Flask应用:
python app.py - 打开浏览器,访问
http://localhost:5000,你应该能够看到上传文件到HDFS和下载文件的界面。
6. 测试功能
- 上传文件:选择文件并上传,文件会被存储到HDFS中的指定目录(如
/user/hadoop/test)。 - 查看文件列表:Flask页面会列出所有存储在HDFS中的文件。
- 下载文件:点击文件名旁边的“Download”链接,文件将从HDFS下载到本地。
7. 扩展功能
- 删除文件:你可以在页面中添加一个删除文件的按钮,使用
client.delete方法从HDFS中删除文件。 - 显示文件内容:对于小文件,可以直接显示文件内容或以某种格式(如CSV或JSON)展示文件内容。
- 多用户支持:在Flask中可以使用Session管理用户,允许不同用户上传和管理自己的文件。
推荐阅读:《大数据 ETL + Flume 数据清洗》,《大数据测试 Elasticsearch》,《大数据测试spark+kafka》,《大数据测试HBase数据库》
相关文章:

【大数据测试HDFS + Flask详细教程与实例】
大数据测试HDFS Flask 1. 环境准备安装工具安装Hadoop(以单机模式为例)安装Flask和HDFS Python客户端 2. HDFS Flask基本架构基本文件结构 3. 创建Flask应用与与HDFS交互步骤1:配置HDFS连接步骤2:构建Flask应用 4. 创建前端界面…...

高级java每日一道面试题-2024年10月31日-RabbitMQ篇-RabbitMQ中vhost的作用是什么?
如果有遗漏,评论区告诉我进行补充 面试官: RabbitMQ中vhost的作用是什么? 我回答: 在Java高级面试中,关于RabbitMQ中vhost(虚拟主机)的作用是一个重要且常见的考点。以下是对vhost的详细解释: 一、vhost的基本概念 vhost&am…...

【日常记录-Java】代码配置Logback
1. 简介 在Logback中,推荐使用配置文件(如logback.xml或logback-spring.xml)来设置日志记录的行为。但在实际应用中,会有动态配置logback的需求。此时可通过编程的方式直接操作LoggerContext以及相关的Logger、Appender、Encoder等…...

HTTP常见的请求头有哪些?都有什么作用?在 Web 应用中使用这些请求头?
HTTP 请求头(Request Headers)用于在 HTTP 请求中携带额外的信息,帮助服务器更好地处理请求。以下是一些常见的 HTTP 请求头及其作用: 常见请求头及其作用 1. Accept 作用:告知服务器客户端可以接受的内容类型。示例…...

电信数据清洗案例:利用MapReduce实现高效数据预处理
电信数据清洗案例:利用MapReduce实现高效数据预处理 在大数据时代,电信行业积累了大量的用户通话、短信、上网等行为数据。在数据分析和机器学习模型训练前,对这些数据进行清洗是至关重要的一步。MapReduce 是一种高效的数据处理模型&#x…...

react 中 FC 模块作用
React.FC 是一个泛型类型,用于定义函数组件的类型 一、类型定义和代码可读性 1. 明确组件类型 使用React.FC定义一个组件时,使得组件的输入(props)和输出(返回的 React 元素)都有明确的类型定义。 impo…...
--CLIP)
多模态大模型(1)--CLIP
CLIP(Contrastive Language-Image Pre-training)模型是一种多模态预训练神经网络,由OpenAI在2021年发布。它通过对比学习的方式,将图像和文本映射到同一个向量空间中,从而实现跨模态的检索和分类。下面介绍其基础功能&…...

opencv入门学习总结
opencv学习总结 不多bb,直接上代码!!! 案例一: import cv2 # 返回当前安装的 OpenCV 库的版本信息 并且是字符串格式 print(cv2.getVersionString()) """ 作用:它可以读取不同格式的图像文…...

C/C++内存管理 | new的机制 | 重载自己的operator new
一、C/C内存分布 1. 内存分区 栈又叫堆栈–非静态局部变量/函数参数/返回值等等,栈是向下增长的。内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享共享内存,做进程间通信 .堆用于程序运行时动态内…...

知识库管理系统:企业数字化转型的加速器
在数字化转型的大潮中,知识库管理系统(KBMS)已成为企业提升效率和创新能力的关键工具。本文将探讨知识库管理系统的定义、企业建立知识库的必要性,以及如何快速搭建企业知识库。 知识库管理系统是什么? 知识库管理系统…...
)
uniapp 如何使用vuex store (亲测)
首先是安装: npm install vuexnext --save 安装之后,Vue2 这样写 不管在哪里,建立一个JS文件,假设命名:store.js 代码这样写: import Vue from vue; import Vuex from vuex;Vue.use(Vuex);const store…...

[编译报错]ImportError: No module named _sqlite3解决办法
1. 问题描述: 在使用python进行代码编译时,提示下面报错: "/home/bspuser/BaseTools/Source/Python/Workspace/WorkspaceDatabase.py", line 18, in <module>import sqlite3File "/usr/local/lib/python2.7/sqlite3/_…...

【旷视科技-注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

python学习记录16
字符串总结 python程序使用unicode编码,中文字符与英文字符都占一个字符,但英文字符只占一个字节,中文字符若按照utf-8格式编码占3个字节。 (1)字符串常用方法 1)大小写转化 string.upper()#将所有字母…...

AI 大模型在软件开发中的角色

React中类组件和函数组件的理解和区别
react代码模块分为类组件和函数组件。 从语法和定义、内部状态管理、生命周期、性能、可读性和维护性、上下文、集成状态管理库等角度对比React中类组件和函数组件。 1、语法和定义 类组件: 使用 ES6 的类(class)语法定义的 React 组件。…...
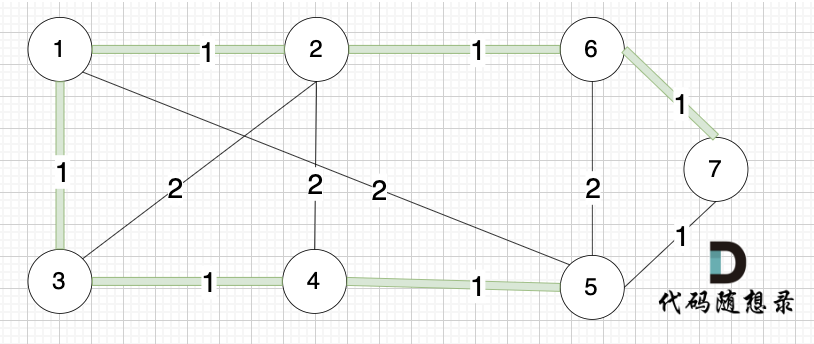
Day62||prim算法精讲 |kruskal算法精讲
prim算法精讲 53. 寻宝(第七期模拟笔试) 题目描述 在世界的某个区域,有一些分散的神秘岛屿,每个岛屿上都有一种珍稀的资源或者宝藏。国王打算在这些岛屿上建公路,方便运输。 不同岛屿之间,路途距离不同&…...

upload-labs通关练习
目录 环境搭建 第一关 第二关 第三关 第四关 第五关 第六关 第七关 第八关 第九关 第十关 第十一关 第十二关 第十三关 第十四关 第十五关 第十六关 第十七关 第十八关 第十九关 第二十关 总结 环境搭建 upload-labs是一个使用php语言编写的,…...

wordpress搭建主题可配置json
网站首页展示 在线访问链接 http://dahua.bloggo.chat/ 配置json文件 我使用的是argon主题,你需要先安装好主题,然后可以导入我的json文件一键配置。 需要json界面配置文件的,可以在评论区回复,看见评论我会私发给你。~...

RWKV-5/6 论文被 COLM 2024 收录
由 Bo PENG 和 RWKV 开源社区共同完成的 RWKV-5/6架构论文《Eagle and Finch: RWKV with Matrix-Valued States and Dynamic Recurrence》被顶级会议 COLM 2024 收录。 这是继 RWKV-4 架构论文《RWKV: Reinventing RNNs for the Transformer Era》被 EMNLP 2023 收录之后&…...

从 0 到 1:用魔珐星云打造真实可用的智能健身私教【技术原理文章】
> 我在学习具身智能的实战文章,本文为技术文章,非广告一、健身交互痛点:传统数字人 / 健身工具缺失沉浸式陪伴式互动日常健身长期存在行业共性痛点:不管是纯视频课程,还是传统云端实时交互数字人,都难以…...

初创团队如何利用 Taotoken Token Plan 有效控制 AI 实验成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用 Taotoken Token Plan 有效控制 AI 实验成本 对于资源有限的初创团队而言,在产品原型和概念验证阶段&…...

森林-服务器存档
对于想要自建游戏服务器的玩家,云鸢互联是一个不错的专业联机平台选择。它提供稳定、低延迟且724小时在线的服务器环境,助你轻松打造专属游戏世界。平台主打极致的新手友好——全图形化控制面板,无需编写代码,也无需掌握Linux命令…...

神州细胞递表港交所 创新生物制药领军者构筑A+H双平台全球化版图
5月22日,北京神州细胞生物技术集团股份公司(证券代码:688520,证券简称:神州细胞)正式向香港联合交易所有限公司递交上市申请,迈出“AH”双资本平台布局的关键一步。公司以科创板上市为根基&…...
)
【独家实测】ChatGPT-4 Turbo vs GPT-3.5 Turbo单位token成本对比:附Python自动核算脚本(限免24h)
更多请点击: https://codechina.net 第一章:ChatGPT API价格计算的底层逻辑与成本认知 ChatGPT API 的计费并非基于会话时长或请求次数,而是严格依据模型实际处理的 token 数量——包括输入(prompt)和输出(…...

ng-demos构建工具对比:Grunt vs Gulp在Angular项目中的实战应用
ng-demos构建工具对比:Grunt vs Gulp在Angular项目中的实战应用 【免费下载链接】ng-demos variety of angular demos 项目地址: https://gitcode.com/gh_mirrors/ng/ng-demos 在Angular项目开发中,构建工具的选择直接影响开发效率和项目维护性。…...

2026年,揭秘浙江废铝回收界的明星企业!
引言:废铝回收,绿色循环的先锋随着我国经济的快速发展和工业生产的不断扩大,废铝回收行业逐渐成为资源循环利用的重要环节。在浙江省,众多废铝回收企业脱颖而出,其中腾兰再生资源回收有限公司以其卓越的表现࿰…...

Flink 2.2集成Flink CDC 3.6
1 、部署Flink CDC tar -zxf flink-cdc-3.6.0-2.2-bin.tar.gz -C /usr/bigtop/3.3.0/usr/libln -s /usr/bigtop/3.3.0/usr/lib/flink-cdc-3.6...

HDLxGraph:图数据库与LLM在硬件设计中的应用
1. HDLxGraph:当硬件设计遇上图数据库与LLM 在芯片设计领域,硬件描述语言(HDL)如Verilog和VHDL是工程师们将电路构想转化为可执行代码的核心工具。然而,随着现代芯片设计复杂度的爆炸式增长,一个中等规模的…...
3PEAK思瑞浦 TP321-DF0R DFN1X1-4 运算放大器
特性 通用型,低成本: 增益带宽积:1MHz 低静态电流:45A/放大器 偏移电压:最大5.0毫伏 偏移电压温度漂移:2uV/C 输入偏置电流:10pA 共模抑制比/电源抑制比:90dB 单位增益稳定 轨到轨输入和输出 过驱动输入无相位反转 供电电压范围: TP321-DFOR: 2.1V 至 5.5V 其他部分…...