【pytorch】常用强化学习算法实现(持续更新)
持续更新常用的强化学习算法,采用单python文件实现,简单易读
- 2024.11.09 更新:PPO(GAE); SAC
- 2024.11.12 更新:OptionCritic(PPOC)
"PPO"
import copy
import time
import torch
import numpy as np
import torch.nn as nn
import torch.nn.functional as Fimport gymnasium as gym
import matplotlib.pyplot as pltfrom tqdm import trange
from torch.distributions import Normalclass Actor(nn.Module):def __init__(self, state_size, action_size):super().__init__()self.fc1 = nn.Linear(state_size, 256)self.fc2 = nn.Linear(256, 128)self.mu = nn.Linear(128, action_size)self.sigma = nn.Linear(128, action_size)def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))mu = F.tanh(self.mu(x))sigma = F.softplus(self.sigma(x))return mu, sigmaclass Critic(nn.Module):def __init__(self, state_size):super().__init__()self.fc1 = nn.Linear(state_size, 256)self.fc2 = nn.Linear(256, 128)self.fc3 = nn.Linear(128, 1)def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))return self.fc3(x)def ppo_training(trajectory, actor, critic, actor_optimizer, critic_optimizer,clip=0.2, k_epochs=10, gamma=0.99, lam=0.95, device='cpu', T=1e-2):states, actions, log_probs, rewards, next_states, dones = map(lambda x: torch.from_numpy(np.array(x)).to(device),zip(*trajectory))rewards = rewards.view(-1, 1)dones = dones.view(-1, 1).int()with torch.no_grad():next_values = critic(next_states.float())td_target = rewards + gamma * next_values * (1 - dones)td_value = critic(states.float())td_delta = td_target - td_valuetd_delta = td_delta.detach().cpu().numpy()adv = 0.0advantages = []for delta in td_delta[::-1]:adv = gamma * lam * adv + deltaadvantages.append(adv)advantages.reverse()advantages = torch.from_numpy(np.array(advantages)).float().to(device)advantages = (advantages - advantages.mean()) / advantages.std()for k in range(k_epochs):mu, sigma = actor(states.float())dist = Normal(mu, sigma)new_log_probs = dist.log_prob(actions)entropy = dist.entropy()ratio = torch.exp(new_log_probs - log_probs.detach())surr1 = ratio * advantagessurr2 = torch.clamp(ratio, 1.0 - clip, 1 + clip) * advantagesactor_loss = - torch.min(surr1, surr2).mean() - entropy.mean() * Tcritic_loss = F.mse_loss(critic(states.float()), td_target.float().detach())actor_optimizer.zero_grad()critic_optimizer.zero_grad()actor_loss.backward()actor_optimizer.step()critic_loss.backward()critic_optimizer.step()if __name__ == '__main__':device = torch.device("cpu")env = gym.make('Walker2d')episodes = 1000train_timesteps = 1024clip = 0.2k_epochs = 40gamma = 0.9lam = 0.95T = 1e-2lr = 1e-4actor = Actor(env.observation_space.shape[0], env.action_space.shape[0]).to(device)critic = Critic(env.observation_space.shape[0]).to(device)actor_optimizer = torch.optim.Adam(actor.parameters(), lr=lr)critic_optimizer = torch.optim.Adam(critic.parameters(), lr=lr)trajectory = []timestep = 0pbar = trange(1, episodes+1)score_list = []for e in pbar:state, _ = env.reset()scores = 0.0while True:timestep += 1s = torch.from_numpy(state).float().to(device)mu, sigma = actor(s)dist = Normal(mu, sigma)a = dist.sample()log_prob = dist.log_prob(a).detach().cpu().numpy()action = a.detach().cpu().numpy()next_state, reward, done, _, _ = env.step(action)scores += rewardtrajectory.append([state, action, log_prob, reward, next_state, done])if timestep % train_timesteps == 0:ppo_training(trajectory,actor,critic,actor_optimizer,critic_optimizer,clip,k_epochs,gamma,lam,device,T)trajectory = []state = copy.deepcopy(next_state)if done: breakscore_list.append(scores)pbar.set_description("Episode {}/{}: Score: {:.2f}, Timesteps: {}".format(e, episodes, scores, timestep))"SAC"
from torch.distributions import Normal
from collections import deque
from tqdm import trangeimport torch
import torch.nn as nn
import torch.nn.functional as Fimport copy
import time
import random
import numpy as np
import gymnasium as gym
import matplotlib.pyplot as pltclass ActorNetwork(nn.Module):def __init__(self, state_size, action_size):super().__init__()self.fc1 = nn.Linear(state_size, 256)self.fc2 = nn.Linear(256, 128)self.mu = nn.Linear(128, action_size)self.sigma = nn.Linear(128, action_size)def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))mu = self.mu(x)sigma = F.softplus(self.sigma(x))return mu, sigmaclass QNetwork(nn.Module):def __init__(self, state_size, action_size):super().__init__()self.fc1 = nn.Linear(state_size + action_size, 256)self.fc2 = nn.Linear(256, 128)self.fc3 = nn.Linear(128, 1)def forward(self, s, a):x = torch.cat((s, a), dim=-1)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))return self.fc3(x)class ReplayBuffer:def __init__(self, capacity):self.memory = deque(maxlen=capacity)def __len__(self):return len(self.memory)def save_memory(self, state, action, reward, next_state, done):self.memory.append([state, action, reward, next_state, done])def sample(self, batch_size):sample_size = min(len(self), batch_size)experiences = random.sample(self.memory, sample_size)return experiencesdef soft_update(target, source, tau=0.05):for param, target_param in zip(source.parameters(), target.parameters()):target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)def choice_action(actor, state):mu, sigma = actor(state)normal_dist = Normal(torch.zeros_like(mu), torch.ones_like(sigma))epsilon = normal_dist.sample()action = torch.tanh(mu + sigma * epsilon)log_prob = normal_dist.log_prob(epsilon)log_prob -= torch.log(1 - action.pow(2) + 1e-6)log_prob = log_prob.sum(-1, keepdim=True)return action, log_probdef training(gamma, replay_buffer, models, log_alpha, target_entropy, optimizers, batch_size, tau):(actor,q1_net,target_q1_net,q2_net,target_q2_net) = models(actor_optimizer,q1_optimizer,q2_optimizer,alpha_optimizer) = optimizersbatch_data = replay_buffer.sample(batch_size)states, actions, rewards, next_states, dones = map(lambda x: torch.from_numpy(np.array(x)).float().to(device),zip(*batch_data))with torch.no_grad():alpha = torch.exp(log_alpha)with torch.no_grad():next_state_actions, next_state_log_probs = choice_action(actor, next_states)target_q1_next = target_q1_net(next_states, next_state_actions)target_q2_next = target_q2_net(next_states, next_state_actions)min_q_next_target = torch.min(target_q1_next, target_q2_next) - alpha * next_state_log_probstd_target_value = rewards.view(-1, 1) + (1 - dones.view(-1, 1)) * gamma * min_q_next_targetq1 = q1_net(states, actions)q2 = q2_net(states, actions)q1_loss = F.mse_loss(q1, td_target_value)q2_loss = F.mse_loss(q2, td_target_value)q1_optimizer.zero_grad()q2_optimizer.zero_grad()q1_loss.backward()q2_loss.backward()q1_optimizer.step()q2_optimizer.step()state_actions, state_log_probs = choice_action(actor, states)q = torch.min(q1_net(states, state_actions), q2_net(states, state_actions))actor_loss = torch.mean((alpha * state_log_probs) - q)actor_optimizer.zero_grad()actor_loss.backward()actor_optimizer.step()with torch.no_grad():_, log_prob = choice_action(actor, states)alpha_loss = torch.mean(- log_alpha.exp() * (log_prob + target_entropy))alpha_optimizer.zero_grad()alpha_loss.backward()alpha_optimizer.step()soft_update(target_q1_net, q1_net, tau)soft_update(target_q2_net, q2_net, tau)if __name__ == '__main__':device = torch.device("cpu")env = gym.make('Walker2d')episodes = 1000train_timesteps = 4policy_lr = 1e-4q_lr = 1e-4alpha_lr = 1e-2tau = 0.05buffer_capacity = int(1e6)batch_size = 64gamma = 0.9state_size = env.observation_space.shape[0]action_size = env.action_space.shape[0]target_entropy = - torch.prod(torch.tensor(env.observation_space.shape, device=device))actor = ActorNetwork(state_size, action_size).to(device)q1_net = QNetwork(state_size, action_size).to(device)target_q1_net = QNetwork(state_size, action_size).to(device)q2_net = QNetwork(state_size, action_size).to(device)target_q2_net = QNetwork(state_size, action_size).to(device)target_q1_net.load_state_dict(q1_net.state_dict())target_q2_net.load_state_dict(q2_net.state_dict())log_alpha = torch.tensor(0.0, requires_grad=True, device=device)actor_optimizer = torch.optim.Adam(actor.parameters(), lr=policy_lr)q1_optimizer = torch.optim.Adam(q1_net.parameters(), lr=q_lr)q2_optimizer = torch.optim.Adam(q2_net.parameters(), lr=q_lr)alpha_optimizer = torch.optim.Adam([log_alpha], lr=alpha_lr)replay_buffer = ReplayBuffer(buffer_capacity)pbar = trange(1, episodes+1)timestep = 0score_list = []for episode in pbar:state, _ = env.reset()scores = 0.0while True:timestep += 1if timestep % train_timesteps == 0:training(gamma,replay_buffer,(actor,q1_net,target_q1_net,q2_net,target_q2_net),log_alpha,target_entropy,(actor_optimizer,q1_optimizer,q2_optimizer,alpha_optimizer),batch_size,tau)action, _ = choice_action(actor, torch.from_numpy(state).float().to(device))action = action.detach().cpu().numpy()next_state, reward, done, _, _ = env.step(action)scores += rewardreplay_buffer.save_memory(state, action, reward, next_state, done)state = copy.deepcopy(next_state)if done: breakscore_list.append(scores)pbar.set_description("Episode {}/{}: Score: {:.2f}, Timesteps: {}, Log Alpha: {:.2f}".format(episode, episodes, scores, timestep, log_alpha.item()))"OptionCritic(PPOC)"import torch
import torch.nn as nn
import torch.nn.functional as Ffrom torch.distributions import Bernoulli, Normal
from torch import optimfrom tqdm import trangeimport matplotlib.pyplot as plt
import gymnasium as gym
import numpy as np
import random
import copyclass QNetwork(nn.Module):def __init__(self, state_size, num_options):super().__init__()self.nn = nn.Sequential(nn.Linear(state_size, 256),nn.ReLU(),nn.Linear(256, 128),nn.ReLU(),nn.Linear(128, num_options))def forward(self, x):return self.nn(x)class ActorNetwork(nn.Module):def __init__(self, state_size, action_size):super().__init__()self.fc = nn.Sequential(nn.Linear(state_size, 256),nn.ReLU(),nn.Linear(256, 128),)self.mu = nn.Sequential(nn.ReLU(),nn.Linear(128, action_size),nn.Tanh())self.sigma = nn.Sequential(nn.ReLU(),nn.Linear(128, action_size),nn.Softplus())def forward(self, x):x = self.fc(x)return self.mu(x), self.sigma(x)class TerminationNetwork(nn.Module):def __init__(self, state_size, num_options):super().__init__()self.nn = nn.Sequential(nn.Linear(state_size, 256),nn.ReLU(),nn.Linear(256, 128),nn.ReLU(),nn.Linear(128, num_options),nn.Sigmoid())def forward(self, x):return self.nn(x)class OptionCritic(nn.Module):def __init__(self, state_size, action_size, num_options):super().__init__()self.upper_policy_q_net = QNetwork(state_size, num_options)self.termination_network = TerminationNetwork(state_size, num_options)self.options = nn.ModuleList([ActorNetwork(state_size, action_size)for _ in range(num_options)])self.num_options = num_optionsdef get_option_id(self, state, epsilon):if np.random.rand() > epsilon:return torch.argmax(self.upper_policy_q_net(state),dim=-1).detach().cpu().numpy().item()else:return random.sample(range(self.num_options), 1)[0]def is_option_terminated(self, state, option_id):option_termination_prob = self.termination_network(state)[option_id]option_termination = Bernoulli(option_termination_prob).sample()return bool(option_termination.item())def select_action(self, state, epsilon, option_id):if self.is_option_terminated(state, option_id):option_id = self.get_option_id(state, epsilon)else: option_id = option_idmu, sigma = self.options[option_id](state)normal_dist = Normal(mu, sigma)action = normal_dist.sample()log_prob = normal_dist.log_prob(action)action = action.detach().cpu().numpy()log_prob = log_prob.detach().cpu().numpy()return action, log_prob, option_iddef training(agent, optimizer, trajectory, gamma, k_epochs, clip, lam, T):states, actions, log_probs, option_id, rewards, next_states, dones = map(lambda x: torch.from_numpy(np.array(x)), zip(*trajectory))option_id = option_id.view(-1, 1)rewards = rewards.view(-1, 1)dones = dones.view(-1, 1).float()with torch.no_grad():option_terminated_prob = agent.termination_network(next_states.float()).gather(-1, option_id)next_q = agent.upper_policy_q_net(next_states.float())q_target = rewards + gamma * (1 - dones) * ((1 - option_terminated_prob) * next_q.gather(-1, option_id)+ option_terminated_prob * next_q.max(dim=-1, keepdim=True)[0])td_delta = q_target - agent.upper_policy_q_net(states.float()).gather(-1, option_id)td_delta = td_delta.detach().cpu().numpy()adv = 0.0advantages = []for delta in td_delta[::-1]:adv = gamma * lam * adv + deltaadvantages.append(adv)advantages.reverse()advantages = torch.from_numpy(np.array(advantages)).float()advantages = ((advantages - advantages.mean())/ (1e-6 + advantages.std()))for k in range(k_epochs):mus, sigmas = [], []for i in range(states.shape[0]):mu, sigma = agent.options[option_id[i]](states[i].float())mus.append(mu), sigmas.append(sigma)mu = torch.stack(mus, 0)sigma = torch.stack(sigmas, 0)normal_dist = Normal(mu, sigma)new_log_probs = normal_dist.log_prob(actions)entropy = normal_dist.entropy()ratio = torch.exp(new_log_probs - log_probs.detach())surr1 = ratio * advantagessurr2 = torch.clamp(ratio, 1.0 - clip, 1 + clip) * advantagespolicy_loss = - torch.min(surr1, surr2).mean() - entropy.mean() * Tcritic_loss = F.mse_loss(agent.upper_policy_q_net(states.float()).gather(-1, option_id),q_target.float())termination_loss = agent.termination_network(states.float()).gather(-1, option_id) * (agent.upper_policy_q_net(states.float()).gather(-1, option_id)- agent.upper_policy_q_net(states.float()).max(dim=-1, keepdim=True)[0]).detach()losses = policy_loss + critic_loss + termination_loss.mean()optimizer.zero_grad()losses.backward()optimizer.step()if __name__ == '__main__':env = gym.make('Walker2d')episodes = 1000train_timesteps = 1024clip = 0.2k_epochs = 10gamma = 0.9lam = 0.95T = 1e-2lr = 1e-4epsilon = 1.0epsilon_decay = 0.995mini_epsilon = 0.1state_size = env.observation_space.shape[0]action_size = env.action_space.shape[0]num_options = 4agent = OptionCritic(state_size, action_size, num_options)optimizer = optim.Adam(agent.parameters(), lr=lr)trajectory = []timestep = 0pbar = trange(1, episodes + 1)scores_list = []for e in pbar:state, _ = env.reset()scores = 0.0option_id = agent.get_option_id(torch.from_numpy(state).float(), epsilon)options = [option_id]while True:timestep += 1if timestep % train_timesteps == 0:training(agent, optimizer, trajectory, gamma, k_epochs, clip, lam, T)trajectory = []action, log_prob, option_id = agent.select_action(torch.from_numpy(state).float(), epsilon, option_id)options.append(option_id)next_state, reward, done, _, _ = env.step(action)scores += rewardtrajectory.append([state, action, log_prob, option_id, reward, next_state, done])state = copy.deepcopy(next_state)if done: breakscores_list.append(scores)epsilon = max(mini_epsilon, epsilon * epsilon_decay)pbar.set_description("Episode {}/{}: Score: {:.2f}, Timesteps: {}, Epsilon: {:.2f}".format(e, episodes, scores, timestep, epsilon))plt.plot(scores_list)plt.show()
相关文章:
)
【pytorch】常用强化学习算法实现(持续更新)
持续更新常用的强化学习算法,采用单python文件实现,简单易读 2024.11.09 更新:PPO(GAE); SAC2024.11.12 更新:OptionCritic(PPOC) "PPO" import copy import time import torch import numpy as np import torch.nn as …...
DAY59||并查集理论基础 |寻找存在的路径
并查集理论基础 并查集主要有两个功能: 将两个元素添加到一个集合中。判断两个元素在不在同一个集合 代码模板 int n 1005; // n根据题目中节点数量而定,一般比节点数量大一点就好 vector<int> father vector<int> (n, 0); // C里的一…...

Mybatis执行自定义SQL并使用PageHelper进行分页
Mybatis执行自定义SQL并使用PageHelper进行分页 基于Mybatis,让程序可以执行动态传入的SQL,而不需要在xml或者Select语句中定义。 代码示例 pom.xml 依赖 <dependency><groupId>org.mybatis.spring.boot</groupId><artifactId&g…...

OpenCV DNN
OpenCV DNN 和 PyTorch 都是常用的深度学习框架,但它们的定位、使用场景和功能有所不同。让我们来对比一下这两个工具: 1. 框架和功能 OpenCV DNN:OpenCV DNN 模块主要用于加载和运行已经训练好的深度学习模型,支持多种深度学习…...
和compartTo方法)
什么时候需要复写hashcode()和compartTo方法
在Java编程中,复写(重写)hashCode()和compareTo()方法的需求通常与对象的比较逻辑和哈希集合的使用紧密相关。但请注意,您提到的compartTo可能是一个拼写错误,正确的方法名是compareTo()。以下是关于何时需要复写这两个…...

PostgreSQL 日志文件备份
随着信息安全的建设,在三级等保要求中,要求日志至少保留半年 180 天以上。那么 PostgreSQL 如何实现这一要求呢。 我们需要配置一个定时任务,定时的将数据库日志 log 下的文件按照生成的规则将超过一定时间的日志拷贝到其它的路径下…...

2023年MathorCup数学建模B题城市轨道交通列车时刻表优化问题解题全过程文档加程序
2023年第十三届MathorCup高校数学建模挑战赛 B题 城市轨道交通列车时刻表优化问题 原题再现: 列车时刻表优化问题是轨道交通领域行车组织方式的经典问题之一。列车时刻表规定了列车在每个车站的到达和出发(或通过)时刻,其在实际…...
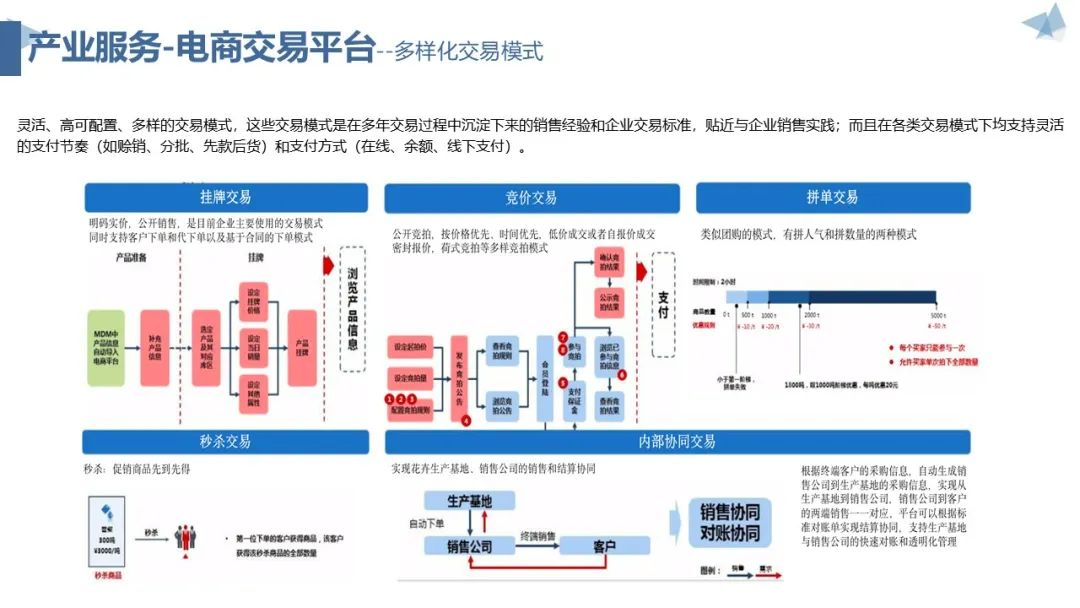
数字农业产业链整体建设方案
1. 引言 数字农业产业链整体建设方案旨在通过数字化手段提升农业产业效率与质量,推动农业现代化进程。方案聚焦于资源数字化、产业数字化、全局可视化与决策智能化的实现,构建农业产业互联网平台,促进农业全流程、全产业链线上一体化发展。 …...

awk那些事儿:在awk中使用shell变量的两种方式
awk是Linux中一款非常好用的程序,可以逐行处理文件,并提供了强大的语法和函数,和grep、sed一起被称为“Linux三剑客”。 在使用awk处理文件时,有时会用到shell中定义的变量,由于在shell中变量的调用方式是通过$符号进…...

大数据面试题--kafka夺命连环问(后10问)
目录 16、kafka是如何做到高效读写? 17、Kafka集群中数据的存储是按照什么方式存储的? 18、kafka中是如何快速定位到一个offset的。 19、简述kafka中的数据清理策略。 20、消费者组和分区数之间的关系是怎样的? 21、kafka如何知道哪个消…...

智能量化交易的多样化策略与风险控制:中阳模型的应用与发展
随着金融市场的不断创新与发展,智能量化交易正逐渐成为金融投资的重要手段。中阳智能量化交易模型通过技术优势、策略优化与实时风险控制等多方面结合,为投资者提供了强有力的工具支持。本文将对中阳量化模型的技术细节、多策略组合与市场适应性进行深入…...

小皮PHP连接数据库提示could not find driver
最近遇到一个奇怪的问题,我的小皮上安装的8.0.2版本的php连接数据库正常。下载使用8.2.9时,没有php.ini,把php-development.ini改成 php.ini后,就提示could not find driver。 网上查了说把php.ini里的这几个配置打开,我也打开了&…...
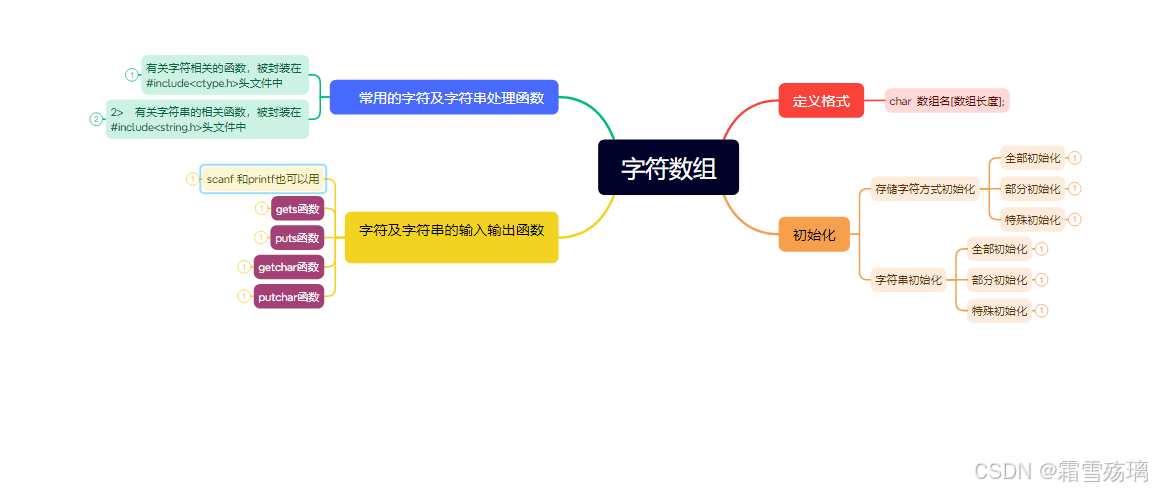
2024.11.13(一维数组相关)
思维导图 1> 提示并输入一个字符串,统计该字符串中大写字母、小写字母、数字字符、空格字符的个数并输出 2> 提示并输入一个字符串,将该字符串中的所有字母挑选到一个新数组中,将所有的数字字符挑选到另一个新数组中。并且将数字字符对…...

豆包MarsCode算法题:数组元素之和最小化
数组元素之和最小化 问题描述思路分析分析思路解决方案 参考代码(Python)代码分析1. solution 函数2. 计算 1 2 3 ... n 的和3. 乘以 k 得到最终的数组元素之和4. 主程序(if __name__ __main__:)代码的时间复杂度分析&#x…...

Hbase Shell
一、启动运行HBase 首先登陆SSH,由于之前在Hadoop的安装和使用中已经设置了无密码登录,因此这里不需要密码。然后,切换至/usr/local/hadoop,启动Hadoop,让HDFS进入运行状态,从而可以为HBase存储数据&#…...
激活函数解析:神经网络背后的“驱动力”
神经网络中的激活函数(Activation Function)是其运作的核心组件之一,它们决定了神经元如何根据输入信号进行“激活”,进而影响整个模型的表现。理解激活函数的工作原理对于设计和优化神经网络至关重要。本篇博客将深入浅出地介绍各…...

【开源免费】基于SpringBoot+Vue.JS水果购物网站(JAVA毕业设计)
博主说明:本文项目编号 T 065 ,文末自助获取源码 \color{red}{T065,文末自助获取源码} T065,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析…...
推荐一款多物理场模拟仿真软件:STAR-CCM+
Siemens STAR-CCM是一款功能强大的计算流体力学(CFD)软件,由西门子公司推出。它集成了现代软件工程技术、先进的连续介质力学数值技术和卓越的设计,为工程师提供了一个全面的多物理场仿真平台。主要特点与优势:多物理场仿真、自动化与高效、高…...
React Hooks在现代前端开发中的应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 React Hooks在现代前端开发中的应用 React Hooks在现代前端开发中的应用 React Hooks在现代前端开发中的应用 引言 React Hooks …...
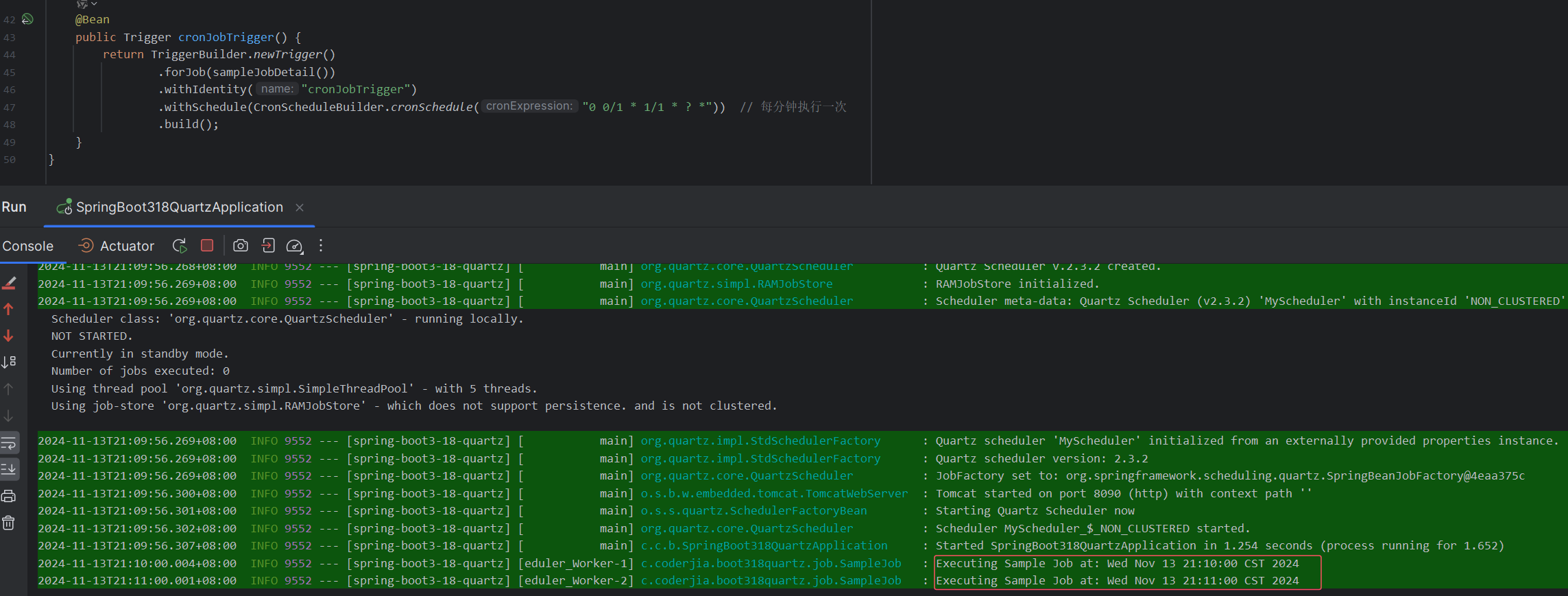
重学SpringBoot3-整合Quartz定时任务
更多SpringBoot3内容请关注我的专栏:《SpringBoot3》 期待您的点赞👍收藏⭐评论✍ Quartz 是一个开源的任务调度框架,用于在应用程序中创建、管理和调度定时任务。将 Quartz 和 Spring Boot 3 结合,可以轻松实现定时任务的灵活管理…...

技术人准备英文面试:除了刷题,这五个表达习惯更关键
许多软件测试工程师在准备英文面试时,往往会陷入一个误区:将大量时间花在背诵专业术语(如“Equivalence Partitioning”、“Regression Testing”),或者在技术问答环节机械地复述测试用例的设计逻辑。诚然,…...

Jetson Orin AGX INT4 推理优化实践:super 分支从 9 tok/s 到 24 tok/s
Jetson Orin AGX INT4 推理优化实践:super 分支从 9 tok/s 到 24 tok/s 项目地址:https://github.com/luogantt/LLM-inference-engine 本文总结 jetson-orin-agx-super 分支上的一次端侧大模型推理优化实践。目标设备是 Jetson Orin AGX,目…...

JMeter+DeepSeek实现性能测试报告自动化与智能脚本生成
1. 这不是“AI写报告”,而是把性能测试工程师从重复劳动里解放出来的实操路径 你有没有过这样的经历:凌晨两点还在手动整理JMeter的.jtl结果文件,Excel里堆着几十列响应时间、错误率、吞吐量,再复制粘贴到Word里写“本次压测在200…...

嵌入式Linux驱动移植:基于MAX31865与PT100的高精度温度采集方案
1. 项目概述与核心思路最近在做一个工业边缘计算网关的项目,需要高精度地监测几个关键节点的温度,精度要求至少达到0.5℃。市面上常见的DS18B20这类数字温度传感器,在精度和抗干扰能力上有点力不从心。于是,我把目光投向了铂电阻温…...

2026 AI 培训机构怎么选?6 类人群精准匹配 + 避坑指南
随着大模型、多模态、RAG、Agent 技术持续迭代,企业对于 AI 算法开发、计算机视觉、自然语言处理、工程落地类人才的需求持续上涨。目前国内主流AI学习平台包含咕泡科技、科大讯飞AI大学堂、腾讯云智学堂、深兰科技人工智能教育等,各家平台技术侧重点、课…...

Verilator仿真保姆级避坑指南:从安装最新版到用GTKWave看波形的完整流程
Verilator仿真实战手册:从源码编译到波形调试的深度解析 1. 为什么选择Verilator:开源EDA工具链的新选择 在数字电路设计领域,仿真验证环节往往决定着项目成败。传统商业仿真器虽然功能强大,但高昂的授权费用和复杂的配置流程让许…...

用达尔文进化论重构神经网络设计
1. 这不是科幻脑洞,而是一次严肃的思想实验 “What if Charles Darwin Built a Neural Network?”——这个标题乍看像咖啡馆里哲学系学生的即兴发问,但在我过去十年拆解过37个跨学科AI项目、亲手复现过12种生物启发式学习模型后,我敢说&…...

USACO历年青铜组真题解析 | 汇总
欢迎大家订阅我的专栏:算法题解:C与Python实现! 本专栏旨在帮助大家从基础到进阶 ,逐步提升编程能力,助力信息学竞赛备战! 专栏特色 1.经典算法练习:根据信息学竞赛大纲,精心挑选…...

Kolmogorov-Arnold网络:函数表示论驱动的可解释神经架构
1. 这不是又一个“万能网络”——Kolmogorov-Arnold 网络到底在解决什么真问题?你可能刚在某篇预印本论文里看到“Kolmogorov-Arnold Network”这个名词,心里一咯噔:又来?又是那种名字听着像数学史课件、实操起来连 loss 曲线都跑…...

5分钟搞定专业照片水印:Semi-Utils让你的摄影作品瞬间升级
5分钟搞定专业照片水印:Semi-Utils让你的摄影作品瞬间升级 【免费下载链接】semi-utils 一个批量添加相机机型和拍摄参数的工具,后续「可能」添加其他功能。 项目地址: https://gitcode.com/gh_mirrors/se/semi-utils 还在为照片添加水印而烦恼吗…...