2023年MathorCup数学建模B题城市轨道交通列车时刻表优化问题解题全过程文档加程序
2023年第十三届MathorCup高校数学建模挑战赛
B题 城市轨道交通列车时刻表优化问题
原题再现:
列车时刻表优化问题是轨道交通领域行车组织方式的经典问题之一。列车时刻表规定了列车在每个车站的到达和出发(或通过)时刻,其在实际运用过程中,通常用列车运行图来表示。图1为某一运行图的示例,图中每一条线表示一趟列车,横轴表示车站,纵轴表示时间,每一条线反映了一趟列车在不同时刻所处的相对位置,也称为运行线。比如,图中红色运行线表示,列车于9:02分从D站出发,于9:05分到达C站,停留1分钟后出发,于9:09分到达B站,停留1分钟后出发,于10:03分到达A站。

实际运营中,在铺画列车运行图之前,首先得先确定列车开行方案,列车开行方案包括列车编组方案、列车停站方案和列车交路计划三部分。
列车编组方案规定了列车的车型和编组数量(即列车的节数),在本问题中采用统一的车型和编组数量。
列车停站方案是规定列车在哪些站点停站的方案,在本问题中均采用站站停的停站方案(即列车在每个经过的车站都会停车)。
列车交路计划是指列车在规定的运行线路上往返运行的方式,即规定了列车在哪些站点之间运行以及开行的数量。大小交路模式是城轨运营中常用的交路模式,是指城市轨道交通运行线路的长短区间。通俗讲,大交路是指列车跑完全程,小交路是指将全程中的某两个站作为临时起点或终点来跑,需要注意的是,只有具有折返能力的车站(能让列车调头的车站)才能作为交路的起点或终点。图2为某大小交路方案示意图,表示以A站为起点的,D站为终点大交路区间开行10对列车,以A站为起点,C站为终点小交路区间开行5对列车。
在大小交路方案中,大小交路列车开行列数通常为1:n或n:1两种模式,即每开行n列大(小)交路列车后,开行一列小(大)交路列车,并且小交路所经过的车站数量需有一定限制:小交路区间过短会导致列车的折返频繁,使运营成本增加;小交路区间过长则无法体现大小交路运营模式的作用。

在大小交路的运营模式下,乘客通常会被分为6种类型,如图3所示,
其中𝑠1 −𝑠n为大交路区间,𝑠a −𝑠b为小交路区间。
第Ⅰ,Ⅱ,Ⅲ类乘客起点均位于[𝑠1 , 𝑠a ],终点无论位于哪个区间,乘客都只能乘坐大交路列车。
第Ⅳ,Ⅴ类乘客起点均位于[𝑠a , 𝑠b ]。其中第Ⅳ类乘客终点位于[𝑠a , 𝑠b ],乘客既可乘坐大交路列车,也可乘坐小交路列车;第Ⅴ类乘客终点位于[𝑠b ,𝑠n ],乘客可以乘坐小交路列车之后到𝑠b进行换乘,也可直接乘坐大交路列车。
第Ⅵ类乘客起点位于[𝑠b , 𝑠n ],终点位于[𝑠b , 𝑠n ],乘客只能乘坐大交路列车。

在列车开行方案的制定中,需要以最小的企业运营成本和最大的服务
水平(乘客在车时间和乘客等待时间)来满足客流的需求,企业的运营成本包括固定成本(所需车辆的数量)和变动成本(列车总走行公里)两部分组成。受到车站通过能力的制约和服务水平的要求,在一定时间内,列车的发车数量也有一定的限制。
在制定好列车开行方案后,可根据该方案同样以企业运营成本最小化
和服务水平最大化为目标铺画列车运行图,即确定每趟列车的出发和到达的具体时刻。现有的列车时刻表通常为等间隔的平行运行图,即发车间隔(如每5分钟开行一趟列车)和在同一站点的停站时间相等。发车间隔的长短会有一定的限制:发车间隔过短,则会影响列车运行的安全;发车间隔过长,则会增长乘客的平均等待时间,从而影响服务水平。同样地,停站时间也需受到一定限制,一般来说列车在车站的停站时间正比于在该站上、下车的乘客数量。另外,需要注意的是,两列车在同一区间追踪运行时,需保留一定的安全间隔(追踪间隔时间)。
采用大小交路运营模式的列车运行图,大交路列车和小交路列车一般
会交替开行,比如当大交路列车与小交路列车的比例为2:1时,则会以每3 列车为一个组合(前 2 列车为大交路列车,第三列车为小交路列车)滚动发车。
在下列问题中,只需制定单向的列车时刻表即可。
问题一:在满足客流需求的条件下,以企业运营成本最小化和服务水平最大化为目标,制定列车开行方案。即确定大交路区间列车的开行数量,小交路的运行区间以及开行数量。(输出格式详见附件6)
问题二:在问题一制定的列车开行方案下,同样以企业运营成本最小化和服务水平最大化且尽量满足客流需求为目标,制定等间隔的平行运行图。(输出格式详见附件7,并将附件7单独上传到竞赛系统中)
问题三:对于降低企业运营成本和提高服务水平,你们团队有哪些好的方法或建议?基于客流和车站数据,提供相应的量化分析支持。
输入输出数据:
所给数据为某实际轨道交通线路的真实数据,沿途共有30座车站,客流数据的时段为7:00 - 8:00。数据详见附件。
附件1:车站数据.xlsx
附件2:区间运行时间.xlsx
附件3:OD客流数据.xlsx
附件4:断面客流数据.xlsx
附件5:其他数据.xlsx
附件6:问题一输出示例.xlsx
附件7:问题二输出示例.xlsx
整体求解过程概述(摘要)
随着城市化进程的加快,轨道交通成为人们出行的重要一环。列车运营商在提高服务水平的同时,为尽可能的降低列车的运营成本,则需要对列车的开行方案进行优化。本文利用提供的数据,针对目前的问题,做出以下工作:
针对问题一:在满足客流需求的情况下,为达到企业运营成本最小和服务水平最高。首先,对提供的数据进行处理,得到每个时段的客流量和列车基本参数。其次,以运营成本和服务水平为优化目标,建立多元优化模型。其中运营成本和服务水平展开为:车辆成本、车辆里程、运营成本和车辆运行时间、乘客等待时间、乘客出行成本、乘车舒适度七个权重不同的相关因素。最后使用优化GA-SA(遗传-模拟退火)算法结合约束条件,求解开行方案为:大交路(1-30车站)开行列数为9、小交路(5-14站)开行列数为4、小交路(8-14站)开行列数为4、小交路(8-17站)开行列数为3、小交路(10-14站)开行列数为6和小交路(14-22站)开行列数为8并以图例展示。
针对问题二,在问题一求解的开行方案下,为达到企业运营成本最小和服务水平最高。首先,确定开行方案中的车辆里程。其次,以运营成本和服务水平为优化目标,建立多元优化模型。其中运营成本和服务水平展开为:每站发车时间、每站到达时间、每站停车时间以及追踪间隔时间等权重不同的相关因素。同样采用优化GA-SA(遗传-模拟退火)算法结合约束条件,求解列车平行时刻表,如:小交路(10-14站),第一辆列车于7:00:00时从10起点站出发,于7:01:36到达11站,停留02:19后出发,于7:05:09 到达12站,停留01:15后出发,于7:08:37到达13站,停留01:14后出发,于7:11:13到达14终点站。并以平行运营图展示。
针对问题三,为进一步降低企业运营成本和提高服务水平。根据数据可得,不同时间段的客流量差异巨大。以此为依据,从发车间隔、停站时间动态调整、列车站点起/终点优化出发,设定客流量阈值,将其划分为客流高峰、中峰和低峰时段,做出优化如下:
(1) 发车间隔:客流高峰6分钟、中峰10分钟和低峰时段15分钟;
(2) 停战时间:客流高峰110s、中峰74s和低峰时段15s;
(3) 起/终点列车:车站6、7、11设置为起始车站、车站27设置为非起始车站;得到了进一步降低企业运营成本和提高服务水平的开行方案。
最后,提出采用先进技术、加强客流管理等建立以及对模型进行了评价。
模型假设:
假设1:车辆在运行时不会发生交通事故。
假设2:无论在车站还是区间,都不允许列车发生越行或避让。
假设3:乘客在上车时遵守规则。
假设4:本文中车次的区间运行时分和车站停站时分均是提前给定好的。
假设5:车站中的基础设施不存在损耗。
假设6:列车编组固定后不再改变。
假设7:列车在行驶路线中匀速行驶。
问题分析:
问题一中提出,在满足客流需求的条件下,以企业运营成本最小化和服务水平最大化为目标,制定列车开行方案。首先结合问题和实际,将影响企业运营成本和影响服务水平的主要因素提取出。建立多目标优化模型,对问题一进行求解。
问题二要求在问题一制定的列车开行方案下,同样以企业运营成本最小化和服务水平最大化且尽量满足客流需求为目标,制定等间隔的平行运行图。与问题二不同的是,问题一中满足客流量需求是前提条件,问题一中制定的方案必须满足客流量的需求,问题二中要求尽量满足客流量的需求。因此结合问题一中的基于多元优化的SA-NA模型,将设置满足客流量的目标函数,将其输出的结果赋予较高的权重。最后任然使用加权平均的方式来制定出等间隔运行图。
问题三中提出,提出相关建议以及方法,以更好的降低企业运营成本和提高服务水平,同时基于客流和车站数据,提供相应的量化分析支持。结合第一,第二问建立的多目标优化模型以及结合对实际生活中列车发车的观察,我们提出了如下建议:
1.动态调整发车间隔
2.优化列车停站方案
3.优化列车起始点
模型的建立与求解整体论文缩略图


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:
import numpy as npimport matplotlib.pyplot as plt# Read data from fileimport pandas as pdimport numpy as np# 读取Excel文件
df = pd.read_excel('附件 3:OD 客流数据.xlsx', sheet_name='Sheet1', header=None)# 将DataFrame 转换为NumPy数组
df = df.fillna(0)data = df.to_numpy()[1:, 1:]num_stations = len(data)# Calculate the total number of passengers getting on/off at each stationpassengers_get_on = np.sum(data, axis=1)passengers_get_off = np.sum(data, axis=0)# Create x-axis values (stations) and y-axis values (passengers)x =np.arange(num_stations) + 1y_get_on = passengers_get_ony_get_off =-passengers_get_off # 将负数转为正数,后面在y轴上显示负号
plt.rcParams['font.size'] = 14# Plot the dataplt.rcParams['font.family'] = 'SimHei'plt.plot(x, y_get_on, label='上车')plt.plot(x, y_get_off, label='下车')#Add labels and legendplt.xlabel('车站')plt.ylabel('人数')plt.title('每个车站上下车人数')plt.legend()#Add minus sign to y-axis ticksplt.gca().yaxis.set_tick_params(which='both', direction='in')
plt.gca().yaxis.set_ticklabels([f'{abs(tick):.0f}' if tick != 0 else '0' for tick inplt.gca().get_yticks()])plt.gca().yaxis.get_ticklabels()[0].set_horizontalalignment('left')plt.gca().yaxis.get_ticklabels()[-1].set_horizontalalignment('right')plt.gca().yaxis.get_ticklabels()[int(len(plt.gca().get_yticks())/2)].set_horizontalalignment('center')plt.gca().yaxis.get_ticklabels()[int(len(plt.gca().get_yticks())/2)].set_verticalalignment('bottom')plt.gca().yaxis.get_ticklabels()[-1].set_verticalalignment('bottom')# Showthe plotplt.show()
import matplotlib.pyplot as pltplt.rcParams['font.family'] = 'SimHei'# 定义车站类型
stations = {1: 'square',2: 'square',3: 'circle',4: 'circle',5: 'square',6: 'circle',7: 'circle',8: 'square',9: 'circle',10: 'square',11: 'circle',12: 'circle',13: 'circle',14: 'square',15: 'circle',16: 'circle',17: 'square',18: 'square',19: 'circle',20: 'circle',21: 'square',22: 'square',23: 'circle',24: 'circle',25: 'square',26: 'square',27: 'square',28: 'circle',29: 'circle',30: 'square'}# 定义车站之间的连接关系
connections = [(1, 2), (2, 5), (5, 8), (8, 10), (10, 14), (14, 17), (17, 18),(18, 21), (21, 22), (22, 25), (25, 26), (26, 27), (27, 30)]# 绘制图像
fig, ax = plt.subplots(figsize=(10, 5))for i in range(1, 31):if stations[i] == 'square':ax.scatter(i, 0, marker='s', s=300, color='black')else:ax.scatter(i, 0, marker='o', s=300, color='gray')for c in connections:ax.plot([c[0], c[1]], [0, 0], linewidth=5, color='blue')ax.scatter(24, 0.8, marker='s', s=200, color='black')ax.text(25, 0.8, '可作为起点/终点', fontsize=12, color='black')ax.scatter(24, 0.6, marker='o', s=200, color='gray')ax.text(25, 0.6, '不可作为起点/终点', fontsize=12, color='black')ax.set_xlim([0, 31])ax.set_ylim([-1, 1])ax.set_xticks(range(1, 31))ax.set_yticks([])ax.set_title('车站示意图')ax.tick_params(labelsize=14)plt.show()
import pandas as pd# 假设您已经将文件读取到了以下数据框中
station_data = pd.read_excel("附件 1:车站数据.xlsx")section_time_data = pd.read_excel("附件 2:区间运行时间.xlsx")od_data = pd.read_excel("附件 3:OD 客流数据.xlsx")section_flow_data = pd.read_excel("附件 4:断面客流数据.xlsx")other_data = pd.read_excel("附件 5:其他数据.xlsx")# 提取车站间距离数据station_distances = {}for i, row in section_time_data.iterrows():section = f"车站{i+1}->车站{i+2}"station_distances[section] = row["站间距/km"]# 提取区间运行时间数据
section_times = {}for i, row in section_time_data.iterrows():section = f"车站{i+1}->车站{i+2}"section_times[section] = row["区间运行时间/s"]# 提取OD客流数据
od_matrix = od_data.to_numpy()# 提取断面客流量数据
section_flow = {}for i, row in section_flow_data.iterrows():section = f"车站{i+1}->车站{i+2}"section_flow[section] = row["断面客流量/人"]# 提取其他数据
min_max_departure_interval = [120, 360]min_tracking_interval = 108min_max_station_stay_time = [20, 120]train_capacity = 1860min_max_small_circuit_stations = [3, 24]avg_boarding_alighting_time = 0.04def decode_individual(individual):big_circuit_start = max(1, int(individual[0]))big_circuit_end = int(individual[1])small_circuit_start = max(1, int(individual[2]))small_circuit_end = int(individual[3])while big_circuit_end <= big_circuit_start or small_circuit_end <= small_circuit_start:big_circuit_start = max(1, int(individual[0]))big_circuit_end = int(individual[1])small_circuit_start = max(1, int(individual[2]))small_circuit_end = int(individual[3])big_circuit_distance = sum(station_distances[f"车站{i}->车站{i+1}"] for i inrange(big_circuit_start, big_circuit_end + 1))small_circuit_distance = sum(station_distances[f"车站{i}->车站{i+1}"] for i inrange(small_circuit_start, small_circuit_end + 1))solution = {'大交路': {'运行区间':(big_circuit_start, big_circuit_end),'运营里程':big_circuit_distance,'开行数量':individual[4]},'小交路': {'运行区间':(small_circuit_start, small_circuit_end),'运营里程':small_circuit_distance,'开行数量':individual[5]}}return solutiondef calculate_service_level(solution):big_circuit_start, big_circuit_end = solution['大交路']['运行区间']small_circuit_start, small_circuit_end = solution['小交路']['运行区间']big_circuit_service = od_matrix.iloc[big_circuit_start- 1:big_circuit_end,big_circuit_start- 1:big_circuit_end].sum().sum()small_circuit_service = od_matrix.iloc[small_circuit_start- 1:small_circuit_end,small_circuit_start- 1:small_circuit_end].sum().sum()service_level = (big_circuit_service + small_circuit_service) / total_passenger_flowreturn service_leveldef objective_function(individual):solution = decode_individual(individual)if solution is None:return float('inf'), float('-inf') # 如果解决方案为空(不满足限制条件),返回
极大的成本和极小的服务水平
big_circuit = solution['大交路']small_circuit = solution['小交路']# 计算成本
big_circuit_cost = big_circuit['运营里程'] * big_circuit['开行数量']small_circuit_cost = small_circuit['运营里程'] * small_circuit['开行数量']cost = big_circuit_cost + small_circuit_cost# 计算服务水平
service_level = calculate_service_level(solution)
return cost, service_level
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
2023年MathorCup数学建模B题城市轨道交通列车时刻表优化问题解题全过程文档加程序
2023年第十三届MathorCup高校数学建模挑战赛 B题 城市轨道交通列车时刻表优化问题 原题再现: 列车时刻表优化问题是轨道交通领域行车组织方式的经典问题之一。列车时刻表规定了列车在每个车站的到达和出发(或通过)时刻,其在实际…...
数字农业产业链整体建设方案
1. 引言 数字农业产业链整体建设方案旨在通过数字化手段提升农业产业效率与质量,推动农业现代化进程。方案聚焦于资源数字化、产业数字化、全局可视化与决策智能化的实现,构建农业产业互联网平台,促进农业全流程、全产业链线上一体化发展。 …...

awk那些事儿:在awk中使用shell变量的两种方式
awk是Linux中一款非常好用的程序,可以逐行处理文件,并提供了强大的语法和函数,和grep、sed一起被称为“Linux三剑客”。 在使用awk处理文件时,有时会用到shell中定义的变量,由于在shell中变量的调用方式是通过$符号进…...

大数据面试题--kafka夺命连环问(后10问)
目录 16、kafka是如何做到高效读写? 17、Kafka集群中数据的存储是按照什么方式存储的? 18、kafka中是如何快速定位到一个offset的。 19、简述kafka中的数据清理策略。 20、消费者组和分区数之间的关系是怎样的? 21、kafka如何知道哪个消…...

智能量化交易的多样化策略与风险控制:中阳模型的应用与发展
随着金融市场的不断创新与发展,智能量化交易正逐渐成为金融投资的重要手段。中阳智能量化交易模型通过技术优势、策略优化与实时风险控制等多方面结合,为投资者提供了强有力的工具支持。本文将对中阳量化模型的技术细节、多策略组合与市场适应性进行深入…...

小皮PHP连接数据库提示could not find driver
最近遇到一个奇怪的问题,我的小皮上安装的8.0.2版本的php连接数据库正常。下载使用8.2.9时,没有php.ini,把php-development.ini改成 php.ini后,就提示could not find driver。 网上查了说把php.ini里的这几个配置打开,我也打开了&…...
2024.11.13(一维数组相关)
思维导图 1> 提示并输入一个字符串,统计该字符串中大写字母、小写字母、数字字符、空格字符的个数并输出 2> 提示并输入一个字符串,将该字符串中的所有字母挑选到一个新数组中,将所有的数字字符挑选到另一个新数组中。并且将数字字符对…...

豆包MarsCode算法题:数组元素之和最小化
数组元素之和最小化 问题描述思路分析分析思路解决方案 参考代码(Python)代码分析1. solution 函数2. 计算 1 2 3 ... n 的和3. 乘以 k 得到最终的数组元素之和4. 主程序(if __name__ __main__:)代码的时间复杂度分析&#x…...

Hbase Shell
一、启动运行HBase 首先登陆SSH,由于之前在Hadoop的安装和使用中已经设置了无密码登录,因此这里不需要密码。然后,切换至/usr/local/hadoop,启动Hadoop,让HDFS进入运行状态,从而可以为HBase存储数据&#…...
激活函数解析:神经网络背后的“驱动力”
神经网络中的激活函数(Activation Function)是其运作的核心组件之一,它们决定了神经元如何根据输入信号进行“激活”,进而影响整个模型的表现。理解激活函数的工作原理对于设计和优化神经网络至关重要。本篇博客将深入浅出地介绍各…...

【开源免费】基于SpringBoot+Vue.JS水果购物网站(JAVA毕业设计)
博主说明:本文项目编号 T 065 ,文末自助获取源码 \color{red}{T065,文末自助获取源码} T065,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析…...
推荐一款多物理场模拟仿真软件:STAR-CCM+
Siemens STAR-CCM是一款功能强大的计算流体力学(CFD)软件,由西门子公司推出。它集成了现代软件工程技术、先进的连续介质力学数值技术和卓越的设计,为工程师提供了一个全面的多物理场仿真平台。主要特点与优势:多物理场仿真、自动化与高效、高…...
React Hooks在现代前端开发中的应用
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 React Hooks在现代前端开发中的应用 React Hooks在现代前端开发中的应用 React Hooks在现代前端开发中的应用 引言 React Hooks …...
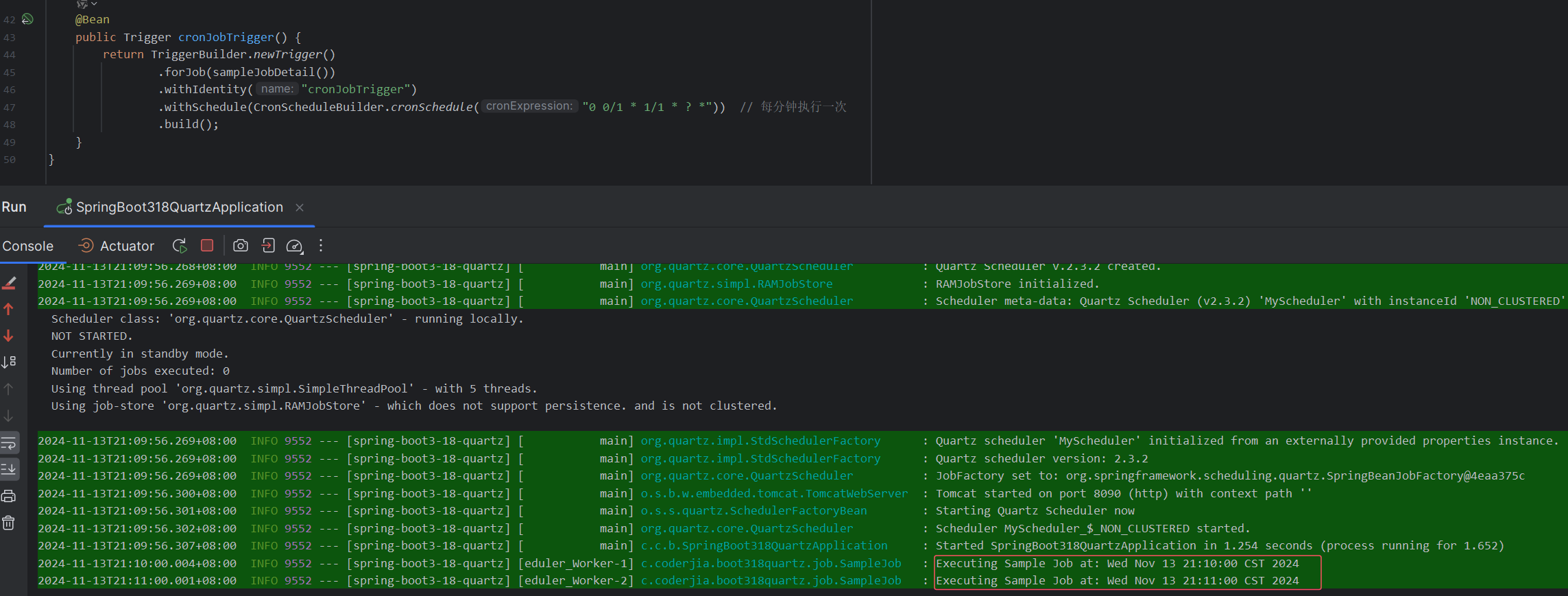
重学SpringBoot3-整合Quartz定时任务
更多SpringBoot3内容请关注我的专栏:《SpringBoot3》 期待您的点赞👍收藏⭐评论✍ Quartz 是一个开源的任务调度框架,用于在应用程序中创建、管理和调度定时任务。将 Quartz 和 Spring Boot 3 结合,可以轻松实现定时任务的灵活管理…...

STM32单片机WIFI语音识别智能衣柜除湿消毒照明
实践制作DIY- GC0196-WIFI语音识别智能衣柜 一、功能说明: 基于STM32单片机设计-WIFI语音识别智能衣柜 二、功能介绍: STM32F103C系列最小系统板LCD1602显示器ULN2003控制的步进电机(柜门开关)5V加热片直流风扇紫外消毒灯DHT11…...

spring中entity的作用
在Spring框架中,特别是结合Spring Data JPA(Java Persistence API)时,Entity类用于表示数据库中的表。这些类通常用于ORM(对象关系映射),即将对象模型与关系型数据库中的表进行映射。以下是Enti…...

2019年下半年试题二:论软件系统架构评估及其应用
论文库链接:系统架构设计师论文 论文题目 对于软件系统,尤其是大规模复杂软件系统而言,软件系统架构对于确保最终系统的质量具有十分重要的意义。在系统架构设计结束后,为保证架构设计的合理性、完整性和针对性,保证系…...

网络自动化04:python实现ACL匹配信息(主机与主机信息)
目录 背景分析代码代码解读代码总体结构1. load_pattern_from_excel 函数2. match_and_append_pattern 函数3. main 函数总结 最终的效果: 今天不分享netmiko,今天分享一个用python提升工作效率的小案例:acl梳理时的信息匹配。 背景 最近同事…...
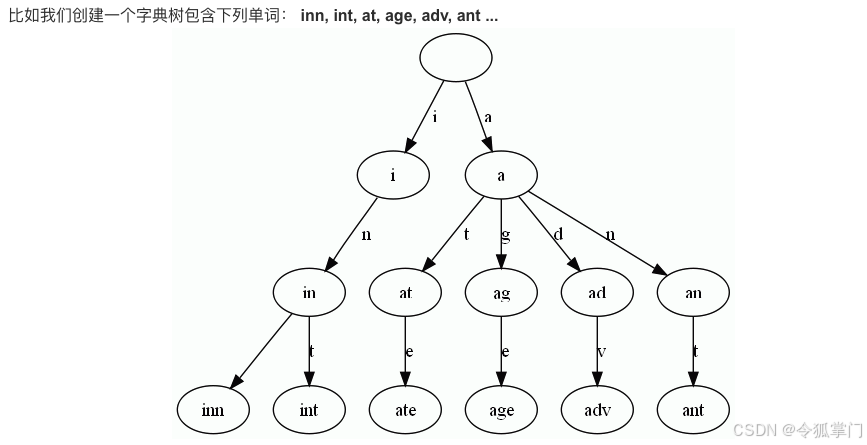
字典树介绍以及C++实现
字典树的概念 字典树(Trie),又称为前缀树或单词查找树,是一种树形数据结构,主要用于存储具有相同前缀的字符串集合。它特别适合用于词典中的单词查找、自动补全、拼写检查等应用。 字典树算法的核心思想就是每层存入…...

【C++】用红黑树封装set和map
在C标准库中,set容器和map容器的底层都是红黑树,它们的各种接口都是基于红黑树来实现的,我们在这篇文章中已经模拟实现了红黑树 ->【C】红黑树,接下来我们在此红黑树的基础上来看看如何封装set和map。 一、共用一颗红黑树 我…...

2026年南京Geo公司将有何新动态?一起探寻其发展新方向!
在数字化浪潮汹涌澎湃的当下,AI智能营销领域正经历着前所未有的变革。顺炫科技作为该领域的深耕者,一直致力于为全球客户提供高效、智能的数字化推广解决方案。随着2026年的到来,顺炫科技又将有哪些新动态,其发展新方向又将指向何…...

GitHub Copilot X:从代码补全到全流程AI协作者的实战指南
1. 项目概述:当代码编辑器遇见“副驾驶”如果你和我一样,每天有超过一半的时间是在代码编辑器里度过的,那你一定对“效率”这个词有着近乎偏执的追求。从语法高亮、代码补全,到后来的LSP(Language Server Protocol&…...
:RAG(检索增强生成))
LLM成长笔记(六):RAG(检索增强生成)
RAG(检索增强生成)全栈学习博客(通俗原理 详细注释 AI应用强化版) RAG 是让大模型“能回答它没学过的新知识”的核心架构。这篇博客从实际问题出发,用生活化类比建立直觉,通过术语详解深入概念本质&#…...

本地视频怎么去水印?2026本地视频去水印软件推荐与方法合集
不少朋友都会碰到一个烦恼:从抖音、快手、小红书下载的视频都带着水印,自己录制的视频也会被社交平台自动添加水印。想要去掉这些水印用于素材库或后期编辑,却不知道该怎么办。别急,今天就给你盘点2026年最实用的本地视频去水印方…...

给老系统装一层 “能办事的 AI”:企业 Agent 卡住的最后一步,SkillsUI 想补上
让我们从一个所有做企业 Agent 的人都遇到过的具体场景说起。某券商风控员要给客户开通融资融券账户,传统流程是这样的:登录 OA 提风控审批 → 跳到 CRM 拉客户资料 → 跳到风控系统填评估表 → 跳到电子签平台发签约链接 → 回 OA 关单。十几个字段反复…...

为什么你的DeepSeek微调收敛慢?揭秘Attention初始化偏差导致的3轮内loss震荡——附自动校准工具脚本
更多请点击: https://intelliparadigm.com 第一章:DeepSeek注意力机制优化 DeepSeek系列模型在长上下文建模中对标准Transformer注意力进行了系统性重构,核心聚焦于降低计算复杂度与提升内存局部性。其注意力优化并非单一技术点叠加…...

实力入选丨全知科技荣登嘶吼2026网络安全产业图谱
近日,嘶吼安全产业研究院正式发布《嘶吼2026网络安全产业图谱》。全知科技凭借在数据安全赛道的长期深耕积淀、持续技术创新能力与规模化行业落地实践,成功入选图谱数据安全核心板块,强势入围开发与应用安全、数据安全两大核心板块࿰…...

AI Agent落地10大避坑指南:从白皮书到生产环境的工程真相
1. 这不是技术文档翻译,而是一次“工程师对产品经理”的现场拆解 你点开这篇标题,大概率是因为刚看到Google那篇《AI Agents: A Whitepaper on Principles, Capabilities, and Limitations》——PDF文件名长得像法律条文,开头三段全是“auton…...

毕业论文难写?2026年AI论文平台排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重不过关?别慌!2026 年最新 AI 论文写作软件排行榜来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!Ἴ…...

2026年TOP5运营多年口碑平稳的金价查询app有哪些
前几天跟闺蜜约饭,她一坐下来就疯狂吐槽:前一周特意蹲了网上说的金价合适的时段,攒了好久的钱想去买那条种草了半年的金项链,结果到了线下门店才知道,当天大盘价已经涨了21块钱,比她查的那个三天没更新的小…...