网络自动化04:python实现ACL匹配信息(主机与主机信息)
目录
- 背景
- 分析
- 代码
- 代码解读
- 代码总体结构
- 1. `load_pattern_from_excel` 函数
- 2. `match_and_append_pattern` 函数
- 3. `main` 函数
- 总结
- 最终的效果:
今天不分享netmiko,今天分享一个用python提升工作效率的小案例:
acl梳理时的信息匹配。
背景
最近同事在梳理ACL,需要对每一条destination为主机的条目,针对该目的地址主机,标记出这台主机的作用。
工作量大,重复性高,易错率高。
所以使用python进行自动化。
分析
- 首先,同事给出了一版已经做好匹配的文档,如下图(模拟):

- 根据给出的excel,拆分出对应的数据,放在一个sheet中,我这里命名为
pattern
第一列为IP,第二列开始为给出的主机信息:

- 分析python脚本执行思路:
- 读取
patternsheet中的数据,以字典方式存入,key为第一列的IP,value为后续的主机信息(以列表存储); - 循环对
除了pattern sheet的其他sheet,每一行数据的第一列(即acl的每一个rule)去匹配刚刚第一步存储的字典的key,匹配成功后,在这一行后单元格中,填入key对应的value的值。
- 读取
代码
import pandas as pd
import numpy as npdef load_pattern_from_excel(file_path: str) -> dict:"""从指定的Excel文件中读取'pattern'表内容,并返回一个字典。字典的键为第一列的值,值为每行后续列的内容列表(去除NaN)。参数:file_path (str): Excel文件的路径。返回:dict: 包含键值对的字典,键为第一列的内容,值为该行后续列的列表(去除NaN)。"""# 读取Excel文件中的 'pattern' sheetdf = pd.read_excel(file_path, sheet_name='pattern')# 将第一列作为字典的键,后续列的内容作为值存储在字典中,去除NaNpattern = {row[0]: [item for item in row[1:] if pd.notna(item)] for row in df.itertuples(index=False, name=None)}return patterndef match_and_append_pattern(file_path: str, pattern: dict):"""读取Excel文件中除'pattern'和'indexsheet'之外的所有sheet,检查第一列是否包含pattern中的key,匹配后将对应value的每个元素写入相邻单元格(跳过NaN)。参数:file_path (str): Excel文件的路径。pattern (dict): 包含匹配模式的字典,键为要匹配的字符串,值为需要写入的列表(无NaN)。"""# 读取Excel文件xls = pd.ExcelFile(file_path)# 获取所有sheet名称,排除 'pattern' 和 'indexsheet'sheets_to_process = [sheet for sheet in xls.sheet_names if sheet not in ['pattern', 'indexsheet']]# 创建一个字典来存储每个sheet的更新内容updated_sheets = {}# 遍历需要处理的sheetfor sheet_name in sheets_to_process:# 读取当前sheet的数据df = pd.read_excel(xls, sheet_name=sheet_name)# 遍历第一列的每一行,检查是否包含pattern的keyfor idx, cell_value in enumerate(df.iloc[:, 0]):for key, values in pattern.items():if key in str(cell_value): # 检查第一列单元格是否包含key# 在匹配的行写入values中的每个非NaN元素start_col = 1 # 从B列开始写入for value in values:if pd.notna(value): # 仅写入非NaN的值if start_col >= df.shape[1]:df.insert(start_col, f'New_Col_{start_col}', None) # 添加新列df.iat[idx, start_col] = valuestart_col += 1break # 只匹配第一个找到的key并写入# 将更新后的DataFrame存储到字典中updated_sheets[sheet_name] = df# 将更新后的内容写回到新的Excel文件中with pd.ExcelWriter('Updated_ACL.xlsx') as writer:for sheet_name, updated_df in updated_sheets.items():updated_df.to_excel(writer, sheet_name=sheet_name, index=False)print("匹配和追加已完成,文件已保存为 'Updated_ACL.xlsx'.")def main():file_path = 'ACL.xlsx'# 加载 pattern 表内容pattern = load_pattern_from_excel(file_path)# 进行匹配并更新其他 sheetmatch_and_append_pattern(file_path, pattern)if __name__ == "__main__":main()代码解读
这版代码实现了从Excel文件中提取特定的模式(pattern),并将这些模式应用到其他工作表中,对匹配的内容进行扩展性写入。以下是对代码的逐步讲解,以便更详细地了解其逻辑和功能:
代码总体结构
load_pattern_from_excel函数:从Excel文件的patternsheet中读取数据,并生成一个以字典形式存储的pattern变量。match_and_append_pattern函数:将pattern变量的内容应用到ACL.xlsx中除pattern和indexsheet之外的所有sheet,找到匹配项后,将模式中对应的内容写入匹配行的指定位置。main函数:作为脚本的主函数,负责调用load_pattern_from_excel和match_and_append_pattern函数,完成整个流程。
1. load_pattern_from_excel 函数
def load_pattern_from_excel(file_path: str) -> dict:"""从指定的Excel文件中读取'pattern'表内容,并返回一个字典。字典的键为第一列的值,值为每行后续列的内容列表(去除NaN)。参数:file_path (str): Excel文件的路径。返回:dict: 包含键值对的字典,键为第一列的内容,值为该行后续列的列表(去除NaN)。"""# 读取Excel文件中的 'pattern' sheetdf = pd.read_excel(file_path, sheet_name='pattern')# 将第一列作为字典的键,后续列的内容作为值存储在字典中,去除NaNpattern = {row[0]: [item for item in row[1:] if pd.notna(item)] for row in df.itertuples(index=False, name=None)}return pattern
功能解释:
load_pattern_from_excel函数的作用是读取Excel文件中特定的sheet(在这里是pattern)并将其内容格式化为一个字典pattern。- 字典的键来自于
patternsheet 的第一列,表示需要在其他工作表中匹配的字符串。 - 字典的值是每行后续列的内容列表,并且过滤掉所有
NaN值。这意味着,如果有空白单元格,它们不会被纳入到pattern中。
实现细节:
pd.read_excel(file_path, sheet_name='pattern')读取指定的Excel文件的patternsheet。- 使用
itertuples遍历每一行,并构建一个字典推导式{row[0]: [item for item in row[1:] if pd.notna(item)]},通过列表推导式过滤掉NaN值。
2. match_and_append_pattern 函数
def match_and_append_pattern(file_path: str, pattern: dict):"""读取Excel文件中除'pattern'和'indexsheet'之外的所有sheet,检查第一列是否包含pattern中的key,匹配后将对应value的每个元素写入相邻单元格(跳过NaN)。参数:file_path (str): Excel文件的路径。pattern (dict): 包含匹配模式的字典,键为要匹配的字符串,值为需要写入的列表(无NaN)。"""# 读取Excel文件xls = pd.ExcelFile(file_path)# 获取所有sheet名称,排除 'pattern' 和 'indexsheet'sheets_to_process = [sheet for sheet in xls.sheet_names if sheet not in ['pattern', 'indexsheet']]# 创建一个字典来存储每个sheet的更新内容updated_sheets = {}# 遍历需要处理的sheetfor sheet_name in sheets_to_process:# 读取当前sheet的数据df = pd.read_excel(xls, sheet_name=sheet_name)# 遍历第一列的每一行,检查是否包含pattern的keyfor idx, cell_value in enumerate(df.iloc[:, 0]):for key, values in pattern.items():if key in str(cell_value): # 检查第一列单元格是否包含key# 在匹配的行写入values中的每个非NaN元素start_col = 1 # 从B列开始写入for value in values:if pd.notna(value): # 仅写入非NaN的值if start_col >= df.shape[1]:df.insert(start_col, f'New_Col_{start_col}', None) # 添加新列df.iat[idx, start_col] = valuestart_col += 1break # 只匹配第一个找到的key并写入# 将更新后的DataFrame存储到字典中updated_sheets[sheet_name] = df# 将更新后的内容写回到新的Excel文件中with pd.ExcelWriter('Updated_ACL.xlsx') as writer:for sheet_name, updated_df in updated_sheets.items():updated_df.to_excel(writer, sheet_name=sheet_name, index=False)print("匹配和追加已完成,文件已保存为 'Updated_ACL.xlsx'.")
功能解释:
- 该函数的主要功能是遍历
ACL.xlsx中所有的工作表(除pattern和indexsheet),然后检查每个工作表的第一列中是否包含pattern中的任何键。 - 一旦找到匹配的键,函数会从B列开始,按顺序将
pattern中对应的值逐个写入单元格,每个值占据一个单元格。如果值为NaN则跳过。
实现细节:
- 读取所有工作表:使用
pd.ExcelFile(file_path)读取Excel文件,然后过滤出需要处理的工作表。 - 遍历每个工作表:使用
for sheet_name in sheets_to_process逐个读取并处理每个工作表。 - 匹配和写入数据:
for idx, cell_value in enumerate(df.iloc[:, 0])遍历第一列的每一行,检查每个单元格是否包含pattern中的任何键。- 如果匹配成功,则按顺序将
values列表中的每个元素写入到匹配行的相邻单元格,从B列开始(即start_col = 1)。 - 在写入时,使用
pd.notna(value)跳过NaN值。 - 如果需要的列数超过现有列,则动态添加新列
df.insert(start_col, f'New_Col_{start_col}', None)。
- 保存更新后的工作表:处理完所有工作表后,将结果保存到新的Excel文件
Updated_ACL.xlsx。
3. main 函数
if __name__ == "__main__":file_path = 'ACL.xlsx'# 加载 pattern 表内容pattern = load_pattern_from_excel(file_path)# 进行匹配并更新其他 sheetmatch_and_append_pattern(file_path, pattern)
功能解释:
- 首先加载
patternsheet 的内容并生成pattern字典。 - 然后调用
match_and_append_pattern函数,对所有目标工作表进行处理并输出结果。
总结
- 代码逻辑:先构建模式数据字典
pattern,然后匹配并写入其他工作表。 - 数据写入:匹配成功的
value列表内容依次写入相邻单元格,跳过NaN值。 - 输出文件:最终将处理结果保存到新文件
Updated_ACL.xlsx。
最终的效果:
让每一个sheet都如下图一样:
相关文章:
网络自动化04:python实现ACL匹配信息(主机与主机信息)
目录 背景分析代码代码解读代码总体结构1. load_pattern_from_excel 函数2. match_and_append_pattern 函数3. main 函数总结 最终的效果: 今天不分享netmiko,今天分享一个用python提升工作效率的小案例:acl梳理时的信息匹配。 背景 最近同事…...
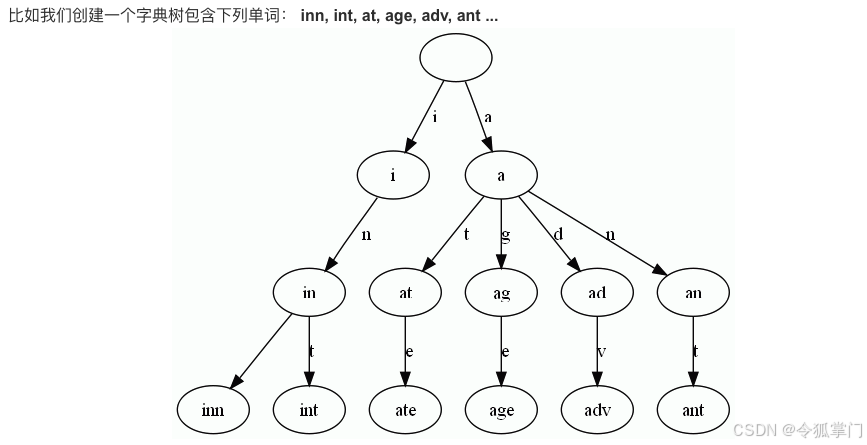
字典树介绍以及C++实现
字典树的概念 字典树(Trie),又称为前缀树或单词查找树,是一种树形数据结构,主要用于存储具有相同前缀的字符串集合。它特别适合用于词典中的单词查找、自动补全、拼写检查等应用。 字典树算法的核心思想就是每层存入…...

【C++】用红黑树封装set和map
在C标准库中,set容器和map容器的底层都是红黑树,它们的各种接口都是基于红黑树来实现的,我们在这篇文章中已经模拟实现了红黑树 ->【C】红黑树,接下来我们在此红黑树的基础上来看看如何封装set和map。 一、共用一颗红黑树 我…...

【大数据测试HDFS + Flask详细教程与实例】
大数据测试HDFS Flask 1. 环境准备安装工具安装Hadoop(以单机模式为例)安装Flask和HDFS Python客户端 2. HDFS Flask基本架构基本文件结构 3. 创建Flask应用与与HDFS交互步骤1:配置HDFS连接步骤2:构建Flask应用 4. 创建前端界面…...

高级java每日一道面试题-2024年10月31日-RabbitMQ篇-RabbitMQ中vhost的作用是什么?
如果有遗漏,评论区告诉我进行补充 面试官: RabbitMQ中vhost的作用是什么? 我回答: 在Java高级面试中,关于RabbitMQ中vhost(虚拟主机)的作用是一个重要且常见的考点。以下是对vhost的详细解释: 一、vhost的基本概念 vhost&am…...

【日常记录-Java】代码配置Logback
1. 简介 在Logback中,推荐使用配置文件(如logback.xml或logback-spring.xml)来设置日志记录的行为。但在实际应用中,会有动态配置logback的需求。此时可通过编程的方式直接操作LoggerContext以及相关的Logger、Appender、Encoder等…...

HTTP常见的请求头有哪些?都有什么作用?在 Web 应用中使用这些请求头?
HTTP 请求头(Request Headers)用于在 HTTP 请求中携带额外的信息,帮助服务器更好地处理请求。以下是一些常见的 HTTP 请求头及其作用: 常见请求头及其作用 1. Accept 作用:告知服务器客户端可以接受的内容类型。示例…...

电信数据清洗案例:利用MapReduce实现高效数据预处理
电信数据清洗案例:利用MapReduce实现高效数据预处理 在大数据时代,电信行业积累了大量的用户通话、短信、上网等行为数据。在数据分析和机器学习模型训练前,对这些数据进行清洗是至关重要的一步。MapReduce 是一种高效的数据处理模型&#x…...

react 中 FC 模块作用
React.FC 是一个泛型类型,用于定义函数组件的类型 一、类型定义和代码可读性 1. 明确组件类型 使用React.FC定义一个组件时,使得组件的输入(props)和输出(返回的 React 元素)都有明确的类型定义。 impo…...
--CLIP)
多模态大模型(1)--CLIP
CLIP(Contrastive Language-Image Pre-training)模型是一种多模态预训练神经网络,由OpenAI在2021年发布。它通过对比学习的方式,将图像和文本映射到同一个向量空间中,从而实现跨模态的检索和分类。下面介绍其基础功能&…...

opencv入门学习总结
opencv学习总结 不多bb,直接上代码!!! 案例一: import cv2 # 返回当前安装的 OpenCV 库的版本信息 并且是字符串格式 print(cv2.getVersionString()) """ 作用:它可以读取不同格式的图像文…...

C/C++内存管理 | new的机制 | 重载自己的operator new
一、C/C内存分布 1. 内存分区 栈又叫堆栈–非静态局部变量/函数参数/返回值等等,栈是向下增长的。内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口创建共享共享内存,做进程间通信 .堆用于程序运行时动态内…...

知识库管理系统:企业数字化转型的加速器
在数字化转型的大潮中,知识库管理系统(KBMS)已成为企业提升效率和创新能力的关键工具。本文将探讨知识库管理系统的定义、企业建立知识库的必要性,以及如何快速搭建企业知识库。 知识库管理系统是什么? 知识库管理系统…...
)
uniapp 如何使用vuex store (亲测)
首先是安装: npm install vuexnext --save 安装之后,Vue2 这样写 不管在哪里,建立一个JS文件,假设命名:store.js 代码这样写: import Vue from vue; import Vuex from vuex;Vue.use(Vuex);const store…...

[编译报错]ImportError: No module named _sqlite3解决办法
1. 问题描述: 在使用python进行代码编译时,提示下面报错: "/home/bspuser/BaseTools/Source/Python/Workspace/WorkspaceDatabase.py", line 18, in <module>import sqlite3File "/usr/local/lib/python2.7/sqlite3/_…...

【旷视科技-注册/登录安全分析报告】
前言 由于网站注册入口容易被黑客攻击,存在如下安全问题: 暴力破解密码,造成用户信息泄露短信盗刷的安全问题,影响业务及导致用户投诉带来经济损失,尤其是后付费客户,风险巨大,造成亏损无底洞…...

python学习记录16
字符串总结 python程序使用unicode编码,中文字符与英文字符都占一个字符,但英文字符只占一个字节,中文字符若按照utf-8格式编码占3个字节。 (1)字符串常用方法 1)大小写转化 string.upper()#将所有字母…...

AI 大模型在软件开发中的角色

React中类组件和函数组件的理解和区别
react代码模块分为类组件和函数组件。 从语法和定义、内部状态管理、生命周期、性能、可读性和维护性、上下文、集成状态管理库等角度对比React中类组件和函数组件。 1、语法和定义 类组件: 使用 ES6 的类(class)语法定义的 React 组件。…...
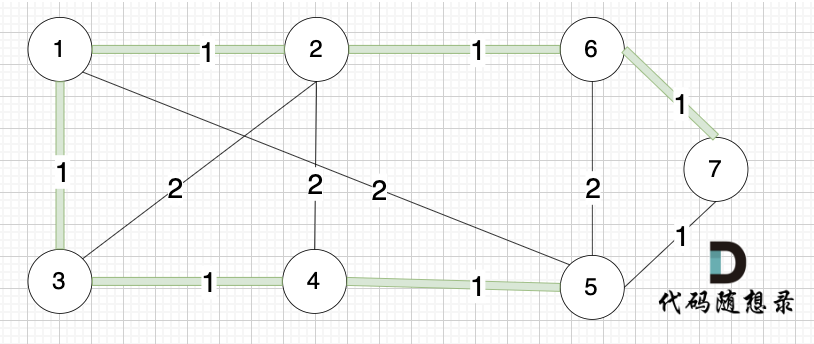
Day62||prim算法精讲 |kruskal算法精讲
prim算法精讲 53. 寻宝(第七期模拟笔试) 题目描述 在世界的某个区域,有一些分散的神秘岛屿,每个岛屿上都有一种珍稀的资源或者宝藏。国王打算在这些岛屿上建公路,方便运输。 不同岛屿之间,路途距离不同&…...

2026年南京Geo公司将有何新动态?一起探寻其发展新方向!
在数字化浪潮汹涌澎湃的当下,AI智能营销领域正经历着前所未有的变革。顺炫科技作为该领域的深耕者,一直致力于为全球客户提供高效、智能的数字化推广解决方案。随着2026年的到来,顺炫科技又将有哪些新动态,其发展新方向又将指向何…...

Logback 日志框架使用与配置指南
1. Logback 核心概念与架构 Logback 是 Java 生态中最主流的日志框架之一,其配置体系主要围绕以下三个核心概念展开: Logger(日志记录器):负责捕获日志事件。它通过 name 属性(通常是包名或类名)…...

测试工程师如何进行测试计划制定?这5个步骤让你的计划更合理
对于软件测试从业者而言,一份合理可行的测试计划是项目测试工作的核心纲领,它不仅决定了测试活动的范围、方向与资源分配,更直接影响着项目的交付质量与进度管控。很多初级测试工程师常常将测试计划等同于测试时间列表,要么写得过…...

免费高效的窗口放大神器:Magpie让Windows显示效果翻倍提升
免费高效的窗口放大神器:Magpie让Windows显示效果翻倍提升 【免费下载链接】Magpie A general-purpose window upscaler for Windows 10/11. 项目地址: https://gitcode.com/gh_mirrors/mag/Magpie 还在为老旧游戏或软件在4K显示器上显示模糊而烦恼吗&#x…...

我希望项目能像lisp那样只有少量而又足够的关键字,不希望后面再添加关键字,那样太繁琐了。 后面可以使用函数、宏等方式增加更多的功能和函数
补充一点设计需求,我希望项目能像lisp那样只有少量而又足够的关键字,不希望后面再添加关键字,那样太繁琐了。 后面可以使用函数、宏等方式增加更多的功能和函数关键在于将语法结构本身作为核心,而非定义大量特殊的关键字。这可…...

Jetpack Compose 动画使用指南
Jetpack Compose 动画使用指南 ⚡ 快速上手 Compose 动画,6 大核心 API 结合项目:仓库地址 目录 animate*AsState — 最基础的动画AnimatedVisibility — 显示/隐藏动画updateTransition — 多值协同过渡Crossfade — 页面/内容切换AnimatedContent —…...

港澳通行证照片怎么手机拍?2026港澳通行证照片规格要求与手机拍摄方法实测
出国、赴港澳的第一步就是办理港澳通行证,而一张符合规范的证件照是必不可少的。很多人都会问:港澳通行证照片能用手机拍吗?怎样才能拍出符合规范的照片?要不要去照相馆?今天就给大家详细讲解港澳通行证照片的拍摄全攻…...

AArch64架构SMCR_EL3寄存器详解与SME向量计算优化
1. AArch64系统寄存器与SMCR_EL3概述在Armv8-A/v9架构中,系统寄存器是处理器状态和功能控制的核心枢纽。作为特权级软件与硬件交互的接口,每个系统寄存器都承担着特定的控制、配置或状态监控职责。SMCR_EL3(SME Control Register at EL3&…...

贡献指南 | 参与 Harmonybrew 开源社区共建规范
贡献指南 | 参与 Harmonybrew 开源社区共建规范 欢迎大家加入鸿蒙PC社区 Harmonybrew 是面向 OpenHarmony/鸿蒙系统的 Homebrew 移植开源项目,依托多仓库协作模式,实现包管理器适配、软件包移植、工具适配、文档维护等全链路能力。为规范社区贡献流程、…...

Navicat Premium试用期重置终极指南:三步恢复完整14天试用
Navicat Premium试用期重置终极指南:三步恢复完整14天试用 【免费下载链接】navicat-premium-reset-trial Reset macOS Navicat Premium 15/16/17 app remaining trial days 项目地址: https://gitcode.com/gh_mirrors/na/navicat-premium-reset-trial 你是否…...