亚马逊评论爬虫+数据分析
爬取评论
做分析首先得有数据,数据是核心,而且要准确!
1、爬虫必要步骤,选好框架
2、开发所需数据
3、最后测试流程
这里我所选框架是selenium+request,很多人觉得selenium慢,确实不快,仅针对此项目我做过测试,相对于request要快,要方便一些!也可以用你们熟悉的框架,用的趁手就行!
最核心的要采用无浏览器模式,这样会快很多
安装浏览器对应webdriver版本
http://npm.taobao.org/mirrors/chromedriver/
获取评论数,评级数, 监控评论
·亚马逊产品评论分为5个等级,从1到5
def get_review_summarys(self):# 解析评论星级def parse(site, asin, rating, html):# 解析评论星级selector = etree.HTML(html)title = select(selector, "//a[@data-hook='product-link']/text()", 0, None)if not title:return site, asin, self.parent_asin, None, None, None, Nonereview_rating_count = select(selector, "//div[@data-hook='cr-filter-info-review-rating-count']/span/text()",0,None)if review_rating_count:review_rating_count = [s.strip() for s in review_rating_count.split("|")]rating_count = int(review_rating_count[0].split(" ")[0].replace(",", ""))review_count = int(review_rating_count[1].split(" ")[0].replace(",", ""))only_rating_count = rating_count - review_countelse:rating_count = Nonereview_count = Noneonly_rating_count = Noneprint(site, asin, rating, rating_count, review_count, only_rating_count, sep="\t")return site, asin, rating, rating_count, review_count, only_rating_countself.review_summarys = []run_successfully = 1star_map = {1: "one_star", 2: "two_star", 3: "three_star", 4: "four_star", 5: "five_star"}url_map = {"parent": "{}product-reviews/{}/?language={}&filterByStar={}&reviewerType=all_reviews"}try:for rating, star in star_map.items():index_url = 'https://www.amazon.com/'language = 'ref=cm_cr_arp_d_viewopt_sr?ie=UTF8'url_format = url_map.get(self.parent_asin,"{}product-reviews/{}/?language={}&filterByStar={}&reviewerType=all_reviews&formatType=current_format")self.re_url = url_format.format(index_url,self.asin, language, star)res = requests.get(self.re_url, headers=headers).textself.rating = ratingreview_summary = parse(self.site, self.asin, self.rating,res)self.review_summarys.append(review_summary)except Exception as err:print("请求中断:{}".format(err))run_successfully = 0finally:return run_successfully, self.review_summarys获取评论内容
def get_main_information(self):# 等待页面加载完毕while True:try:WebDriverWait(self.driver, 30).until(EC.presence_of_element_located((By.ID, 'cm_cr-review_list')))breakexcept Exception as e:print(e)self.driver.refresh()continueus = self.driver.find_element_by_id("cm_cr-review_list")# 获取每页的全部评论信息text = self.driver.page_sourceselector = etree.HTML(text)self.review_detail = []try:reviews = selector.xpath("//div[@data-hook='review']")for review in reviews:review_id = select(review, "./@id", 0, "")customer = select(review, ".//span[@class='a-profile-name']/text()", 0, "")review_title = select(review, ".//*[@data-hook='review-title']/span/text()", 0, "")review_date = select(review, ".//span[contains(@*,'review-date')]/text()", 0, None)if review_date:li = re.findall("\d+.\d+.\d+.\d+.", review_date)[0]yyyy = re.findall('\d\d\d\d',li)[0]mm = re.findall('年(\d+)',li)[0]dd = re.findall('月(\d+)',li)[0]review_date = "{}-{}-{}".format(yyyy, mm, dd)else:review_date = Noneverified_purchase = select(review, ".//span[@data-hook='avp-badge']/text()", 0, "")review_body = select(review, ".//span[@data-hook='review-body']/span/text()")review_rating = select(review, ".//i[contains(@data-hook, 'review-star-rating')]/span/text()", 0, "")review_rating = int(float(review_rating.split(" ")[0].replace(",", "."))) if review_rating else Nonereview_href = select(review, ".//a[@class='a-link-normal']/@href", 0, "")review_href = review_href if review_id in review_href else ""index_url = 'https://www.amazon.com/'review_url = index_url + review_href[1:] if review_href else ""asin = re.findall('ASIN=(.*)',review_url)[0]print(self.site,asin,self.product_name,review_id, customer, review_title, review_date,verified_purchase, review_body,review_rating, review_url, sep="\n")print("----------------------------------------------------------------------------------------------")self.review_detail.append((self.site,asin,self.product_name,review_id, customer, review_title, review_date,verified_purchase,review_body,review_rating, review_url))except Exception as e:print(e)# 判断是否还有下一页next_pagetry:WebDriverWait(self.driver, 5).until(EC.element_to_be_clickable((By.XPATH, '//li[@class = "a-last"]/a')))self.next_page = us.find_element_by_xpath('.//li[@class = "a-last"]/a').get_attribute("href")except NoSuchElementException:self.driver.find_elements_by_xpath('//li[@class = "a-disabled a-last"]')self.next_page = Noneprint("未有下一页")except TimeoutException:self.next_page = Noneself.driver.refresh()- 数据存储方式建议大家使用mysql,如果只是测试玩玩就用csv或者excel
数据有了,下面我们开始分析,怎么分析呢?这里我用到是tableau-BI工具,要结合业务需求来选择工具,BI更适合公司开发业务,实现企业化!
1、每日星级变动分析:评论数,星级数
每天实时更新评级数,把爬虫放到服务器上写一个定时任务!
通过tableau展示可视化报表
2、评论监控
每日实时更新有变动的评论数,评级数
重新建表,把计算逻辑写到函数中,通过比对的方法实现变动

3、最后通过BI展示
定时任务
def get_ratings(h=7, m=30):while True:now = datetime.datetime.now()# print(now.hour, now.minute)if now.hour == h and now.minute == m:spider_main()# 每隔60秒检测一次time.sleep(60)if __name__ == '__main__':# get_reviews()get_ratings()本文章若对你有帮助,烦请点赞,收藏,关注支持一下!
各位的支持和认可就是我最大的动力!
相关文章:
亚马逊评论爬虫+数据分析
爬取评论 做分析首先得有数据,数据是核心,而且要准确! 1、爬虫必要步骤,选好框架 2、开发所需数据 3、最后测试流程 这里我所选框架是seleniumrequest,很多人觉得selenium慢,确实不快,仅针对此…...

新手小白学习docker第六弹------Docker常规安装(安装tomcat、mysql、redis)
目录 1 总体步骤2 安装tomcat2.1 搜索镜像2.2 拉取镜像2.3 查看镜像2.4 启动镜像2.5 访问猫首页 3 安装mysql3.1 搜索镜像3.2 拉取镜像3.3 启动镜像 4 安装redis4.1 拉取镜像4.2 启动镜像(法1基础版)4.3 配置文件4.3.1 在宿主机下新建目录 /app/redis4.3…...
ReactPress与WordPress:两大开源发布平台的对比与选择
ReactPress与WordPress:两大开源发布平台的对比与选择 在当今数字化时代,内容管理系统(CMS)已成为各类网站和应用的核心组成部分。两款备受欢迎的开源发布平台——ReactPress和WordPress,各自拥有独特的优势和特点&am…...

机器情绪及抑郁症算法
🏡作者主页:点击! 🤖编程探索专栏:点击! ⏰️创作时间:2024年11月12日17点02分 点击开启你的论文编程之旅https://www.aspiringcode.com/content?id17230869054974 计算机来理解你的情绪&a…...

01-Ajax入门与axios使用、URL知识
欢迎来到“雪碧聊技术”CSDN博客! 在这里,您将踏入一个专注于Java开发技术的知识殿堂。无论您是Java编程的初学者,还是具有一定经验的开发者,相信我的博客都能为您提供宝贵的学习资源和实用技巧。作为您的技术向导,我将…...

第四十五章 Vue之Vuex模块化创建(module)
目录 一、引言 二、模块化拆分创建方式 三、模块化拆分完整代码 3.1. index.js 3.2. module1.js 3.3. module2.js 3.4. module3.js 3.5. main.js 3.6. App.vue 3.7. Son1.vue 3.8. Son2.vue 四、访问模块module的state 五、访问模块中的getters 六、mutati…...
[2024最新] macOS 发起 Bilibili 直播(不使用 OBS)
文章目录 1、B站账号 主播认证2、开启直播3、直播设置添加素材、隐私设置指定窗口添加/删除 窗口 4、其它说明官方直播帮助中心直播工具教程 目前搜到的 macOS 直播教程都比较古早,大部分都使用 OBS,一番探索下来,发现目前已经不需要 OBS了&a…...

Netty实现WebSocket Client三种典型方式
一、简单版本 package com.ptc.ai.box.biz.relay.client;import io.netty.bootstrap.Bootstrap; import io.netty.channel.Channel; import io.netty.channel.ChannelFuture; import io.netty.channel.ChannelFutureListener; import io.netty.channel.ChannelHandlerContext;…...
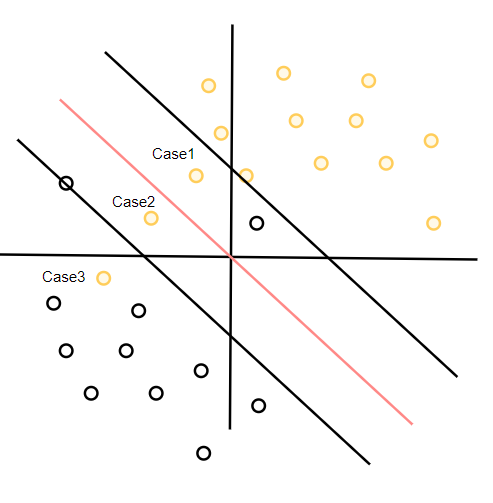
软间隔支持向量机
软间隔支持向量机 我们先直接给出软间隔支持向量机的形式: P min ω , b , ζ 1 2 ∥ ω ∥ 2 2 − C ∑ i 1 m ζ i s . t . y i ( ω x i b ) ≥ 1 − ζ i , i 1 , 2 , 3.. m ζ i ≥ 0 , i 1 , 2 , 3.. m P \min_{\omega,b,\zeta} \frac{1}{2}\Ve…...

在C++上实现反射用法
0. 简介 最近看很多端到端的工作,发现大多数都是基于mmdet3d来做的,而这个里面用的比较多的形式就是反射机制,这样其实可以比较好的通过类似plugin的形式完成模型模块的插入。当然我们这里不是来分析python的反射机制的。我们这篇文章主要来…...

【学术会议介绍,SPIE 出版】第四届计算机图形学、人工智能与数据处理国际学术会议 (ICCAID 2024,12月13-15日)
第四届计算机图形学、人工智能与数据处理国际学术会议 2024 4th International Conference on Computer Graphics, Artificial Intelligence and Data Processing (ICCAID 2024) 重要信息 大会官网:www.iccaid.net 大会时间:2024年12月13-15日 大会地…...
)
网络百问百答(一)
什么是链接? 链接是指两个设备之间的连接,它包括用于一个设备能够与另一个设备通信的电缆类型和协议。OSI参考模型的层次是什么? 有7个OSI层:物理层,数据链路层,网络层,传输层,会话层…...

【深圳大学】数据结构A+攻略(计软版)
1. 考试 1.1 形式 分为平时,笔试,机试三部分。其中: 平时占30%,包含平时OJ测验和课堂练习,注意这个可能会因老师的不同和课题组的新策略而改变。笔试占60%,是分值占比的主要部分。机试占10%。 1.2 题型…...

解读《ARM Cortex-M3 与Cortex-M4 权威指南》——第4章 架构
推荐大佬做的讲解 可以帮助加深理解 ARM架构及汇编 Cortex-M3 和 Cortex-M4 处理器都是基于ARMv7-M架构 需要完成对编程模型、异常(如中断)如何处理、存储器映射、如何使用外设以及如何使用微控制器供应商提供的软件驱动库文件等 Cortex-M3和Cortex-M4处理器有两种操作状态…...

探索 Python HTTP 的瑞士军刀:Requests 库
文章目录 探索 Python HTTP 的瑞士军刀:Requests 库第一部分:背景介绍第二部分:Requests 库是什么?第三部分:如何安装 Requests 库?第四部分:Requests 库的基本函数使用方法第五部分:…...

PostgreSQL 页损坏如何修复
PostgreSQL 错误:关系 base/46501/52712 中的块 480 存在无效的页。 当我们在使用 PostgreSQL 数据库的时候,如果服务器发生 CRASH 或者断电等异常情况的时候,有可能会遇到上面的这个报错信息。那么我们如何去修复这个数据呢,以及…...

Leetcode 75 Sort colors
题意:荷兰国旗问题,给一个数组[0,0,2,1,0],构造成[0,0,0,1,2]的形式,分成三块 https://leetcode.com/problems/sort-colors/description/ 题解: 在任意时刻,i 左边的数都是 0,k 右边的数都是 …...

如何进行数据库连接池的参数优化?
以下是进行数据库连接池参数优化的一些方法: 一、确定合适的初始连接数: 考虑因素:数据库的规模、应用程序的启动需求以及预期的初始负载。如果数据库规模较小且应用程序启动时对数据库的即时访问需求不高,可以将初始连接数设置…...
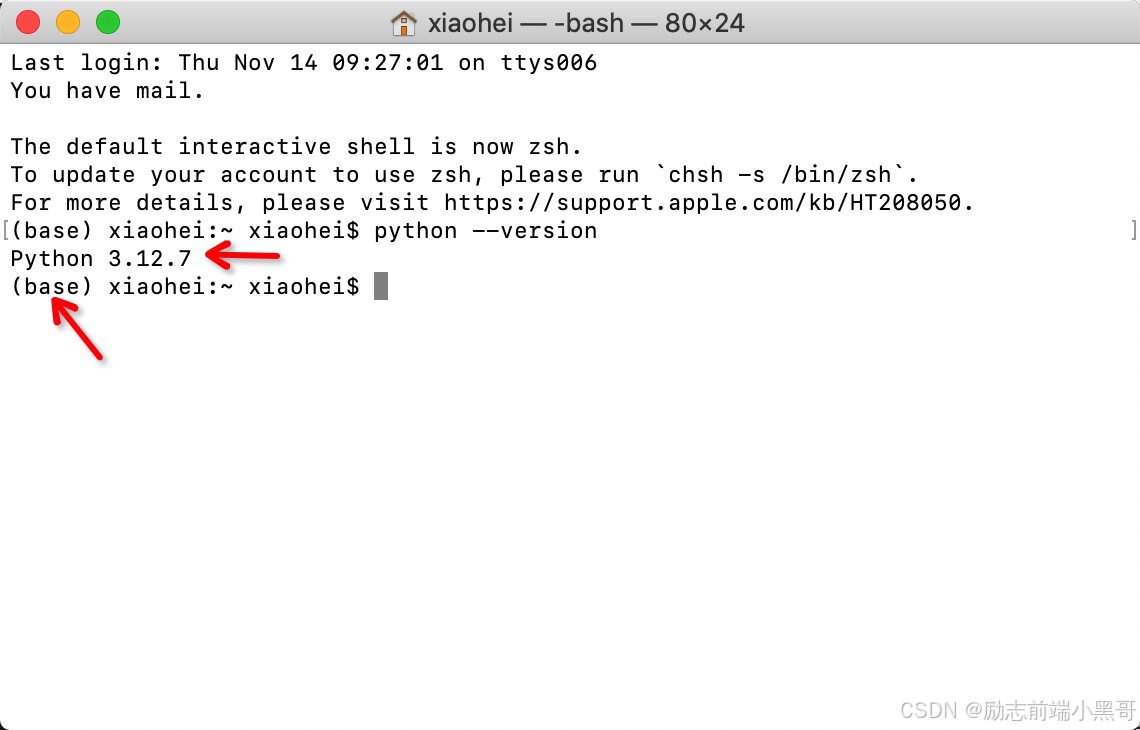
有了miniconda,再也不用担心python、nodejs、go的版本问题了
哈喽,大家好!我是「励志前端小黑哥」,我带着最新发布的文章又来了! 专注前端领域10年,专门分享那些没用的前端知识! 今天要分享的内容,是一个免费的环境管理工具,它叫Miniconda&…...

openresty入门教程:init_by_lua_block
init_by_lua_block 是 Nginx 配置中用于在 Nginx 启动时执行 Lua 脚本的一个指令。这个指令通常用于初始化全局变量、设置共享内存,或者执行一些需要在服务器启动时完成的准备工作。 以下是一个简单的 init_by_lua_block 使用示例: 1. 安装 Nginx 和 L…...

AI Agent 工具调用系统设计:让大模型掌控世界
AI Agent 工具调用系统设计:让大模型掌控世界 前言 工具调用(Tool Use / Function Calling)是 AI Agent 实现复杂任务的关键能力。通过工具调用,大模型可以与外部世界交互,执行计算、查询数据库、调用 API,…...

ConstraintLayout的‘隐藏技巧’:用百分比、比例和GoneMargin搞定复杂UI适配
ConstraintLayout高级适配技巧:百分比、比例与动态隐藏视图的完美解决方案 在Android开发中,ConstraintLayout已经成为构建复杂界面的首选布局方式。但许多开发者仅仅停留在基础使用层面,未能充分发挥其强大的适配能力。本文将深入探讨三个关…...

别再复制粘贴了!Element Plus 表格组件与SpringBoot后端数据联调实战
别再复制粘贴了!Element Plus 表格组件与SpringBoot后端数据联调实战 在前后端分离的开发模式中,前端表格组件与后端数据的动态联调是每个开发者必须掌握的技能。Element Plus作为Vue3生态中最受欢迎的UI组件库之一,其表格组件(el-table)的灵…...

观察Taotoken在不同网络环境下API调用的延迟表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在不同网络环境下API调用的延迟表现 在将大模型API集成到实际应用时,网络环境是影响开发者体验的关键因素…...

Agent_Skills_万千应用_第03篇_PPT 生成 Skill:从资料到可演示幻灯片
Agent Skills 万千应用 第03篇 PPT 生成 Skill:从资料到可演示幻灯片01|场景痛点:PPT 最难的不是做,而是“讲清楚” 你有没有遇到过这种情况? 老板临时说:“明天下午做个 10 分钟汇报。” 你手里有一堆资料…...

终极指南:macOS上轻松解密QQ音乐加密音频文件
终极指南:macOS上轻松解密QQ音乐加密音频文件 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默认转换结果存…...

乡村景区智慧垂钓破局增收!巨有科技激活乡村“渔乐”经济
垂钓作为国民级休闲活动,拥有超1.2亿爱好者,是乡村文旅中极具潜力的黄金业态。然而,多数乡村钓场仍停留在“一根竿、一个塘”的粗放运营阶段,面临计费混乱、管理成本高、体验同质化、增收乏力等困境。巨有科技聚焦乡村场景&#x…...

华硕笔记本终极控制神器:G-Helper轻量化替代方案完整指南
华硕笔记本终极控制神器:G-Helper轻量化替代方案完整指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook,…...

Marshall新款Milton ANC头戴式耳机来袭:音质续航皆优,售价229美元!
Marshall推出新款Milton ANC头戴式耳机Marshall推出了最新款头戴式耳机——Milton ANC。这款耳机在音质、耐用性和电池续航方面都毫不妥协,售价为229美元。耳机特点与升级Marshall宣布推出全新的头戴式耳机Milton ANC。它承诺在不牺牲电池续航的前提下,带…...

Mythos大模型:跨栈系统直觉与自主运维能力解析
1. 这不是一次普通升级:Mythos 的能力跃迁本质是什么?如果你过去三年持续关注大模型演进,大概率会记得2023年Claude 2发布时那种“稳扎稳打”的观感——推理更连贯、长文本更可靠、越狱难度更高,但没人会说它“颠覆了什么”。2024…...