使用热冻结数据层生命周期优化在 Elastic Cloud 中存储日志的成本
作者:来自 Elastic Jonathan Simon

收集数据对于可观察性和安全性至关重要,而确保数据能够快速搜索且获得低延迟结果对于有效管理和保护应用程序和基础设施至关重要。但是,存储所有这些数据会产生持续的存储成本,这为节省成本创造了一个关键机会。在 Elastic Cloud 中,你可以通过设置索引生命周期策略来优化存储费用。此策略允许你的数据从热(hot)数据层(提供超快搜索结果且存储成本较高)移动到具有成本效益的冻结(frozen)层(仍可搜索且获得相当快的结果)。
例如,在具有单个热层的部署中存储 90 天的日志将为你提供最佳性能,正如你对 Elasticsearch 所期望的那样。但在很多情况下,你不需要所有数据都具有超快的性能。有时,你只需要第一天的速度快;过去的日志检索速度可能会慢一点。这种方法将显著降低你的总拥有成本,因为冻结层可以以相同的成本存储高达热层 20 倍的数据量。

让我们开始吧。按照本分步指南为你的日志数据创建热冻结索引生命周期策略。
先决条件
- 具有冻结数据层的 Elastic Cloud 部署
- 在云中运行的本地计算机或虚拟机 (VM),我们将从中通过系统集成提取日志数据流 - Elastic 的 400 多个内置集成之一
创建 Elastic Cloud 部署
从创建 Elastic Cloud 部署开始,我们将在 Google Cloud 中运行的虚拟机上安装系统集成,以收集虚拟机的日志。然后,我们将逐步介绍如何配置存储在 Elastic Cloud 中的虚拟机日志以使用热数据层和冻结数据层。登录 Elastic Cloud 开始。

单击 Create deployment:

输入你的部署名称并展开 Advanced 部分。

单击 +Add capacity 为冻结数据层添加容量”。

单击 Create deployment:

收集日志
现在你已经拥有启用了冻结数据层的 Elastic Cloud 部署,让我们来收集一些日志。我们可以使用系统集成来执行此操作。在你的部署中,单击顶级菜单并选择 Add integrations 按钮。

在这里,在集成页面上,你可以看到我已经搜索了 System 集成。

选择 System 集成将显示其概览页面。要将此集成添加到客户端主机,你可以单击 Add System。

单击 Install Elastic Agent。

复制代理安装代码。我们将复制 Linux Tar 选项卡下的代码,因为我们的云 VM 运行的是 Linux 版本。

在连接到虚拟机的 SSH Cloud Shell 中,粘贴并运行刚刚复制的命令。



返回 Elastic Cloud 的系统集成页面,你应该会看到代理已成功安装的确认信息。单击 Add the integration。

在 “Set up System integration” 页面上,单击 “Advanced options”,然后输入你选择的 Namespace。对于这篇博文,我们将输入“vm_logs” 作为命名空间。单击 “Confirm incoming data”。

你将看到一个确认页面,其中预览了由虚拟机上运行的 Elastic Agent 发送的传入数据。

现在,单击顶层菜单并选择 Discover,以便我们可以看到现在正在收集的日志。

在 Discover 页面上,单击 data stream selector,从 metrics-* 更改为 logs-*。

展开其中一个日志条目以查看其详细信息。

复制日志条目的索引名称,该名称显示为日志条目详细信息中 _index 的值。

创建索引生命周期策略
单击顶层菜单并 Stack Management。

从左侧导航菜单中选择 Index Management。

在 “Index Management” 页面的 “Indices” 选项卡上,单击 “Include hidden indices”。

从 Discover 页面的日志条目详细信息中搜索你在上一步中复制的索引名称。复制 Data stream,我们将在下一步中使用该值创建热冻结索引策略。

从左侧导航菜单中选择 Index Lifecycle Policies:

单击 Create policy。

在 Create policy 页面上,单击热阶段部分下的 Advanced settings。

单击 “ Use recommended defaults” 切换按钮以编辑自定义选项。热阶段的默认持续时间为 30 天。

启用 “Frozen phase” 阶段,并在 “Move data into phase when” 输入框中输入数字零,以便值为 “0 days old.”。这意味着在 30 天的热(hot)阶段之后,受此策略控制的数据将立即移至冻结阶段。你的 “Create policy” 表单应类似于以下已完成的表单。单击 “Save policy” 以创建新的索引生命周期策略。

在索引生命周期策略页面,找到新创建的 Hot-Frozen-Policy 索引生命周期策略,然后单击其 “Add policy to index template” 按钮。

对于 index template,输入“logs-system.syslog”,这是我们在前面的步骤中看到的提取 System integration 日志的数据流的前缀。单击 Add policy。

让我们确认一下,现在我们已将索引生命周期策略设置为应用于日志数据流。从左侧导航菜单中选择 “Index Management”,在这里我们可以确认包含我们提取的日志的索引是否在新的热冻结索引生命周期策略下运行。

在索引管理页面上,单击 “Include hidden indices” 切换按钮以启用它,然后像之前一样再次搜索包含日志的索引名称。你应该在搜索结果中返回一个索引。单击其 Data stream 链接。

在 “Data Streams” 选项卡中,你应该看到此日志数据流由我们刚刚创建的热冻结(hot frozen policy)策略管理。做得好!

要查看每个数据层的总存储量及其当前状态的概览,请单击顶层菜单并选择 Manage this deployment。


立即优化你的日志存储成本
现在,你已经了解了创建索引生命周期策略的过程,这将降低数据在 Elastic Cloud 中老化时的存储成本。亲自尝试一下。将你的日志放入 Elastic Cloud,在那里你可以为你的数据提供自定义的生命周期策略,该策略针对你喜欢的可用性和可负担性级别进行了优化。
要了解更多信息,请参阅导览或查看索引生命周期管理文档。
本文中描述的任何特性或功能的发布和时间均由 Elastic 自行决定。任何当前不可用的特性或功能可能无法按时交付或根本无法交付。
原文:Optimize the cost of logs storage in Elastic Cloud using hot and frozen data tiers | Elastic Blog
相关文章:
使用热冻结数据层生命周期优化在 Elastic Cloud 中存储日志的成本
作者:来自 Elastic Jonathan Simon 收集数据对于可观察性和安全性至关重要,而确保数据能够快速搜索且获得低延迟结果对于有效管理和保护应用程序和基础设施至关重要。但是,存储所有这些数据会产生持续的存储成本,这为节省成本创造…...
)
LeetCode131. 分割回文串(2024冬季每日一题 4)
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。 示例 1: 输入:s “aab” 输出:[[“a”,“a”,“b”],[“aa”,“b”]] 示例 2: 输入:s “a…...

万字长文解读深度学习——训练(DeepSpeed、Accelerate)、优化(蒸馏、剪枝、量化)、部署细节
🌺历史文章列表🌺 深度学习——优化算法、激活函数、归一化、正则化深度学习——权重初始化、评估指标、梯度消失和梯度爆炸深度学习——前向传播与反向传播、神经网络(前馈神经网络与反馈神经网络)、常见算法概要汇总万字长文解读…...

STM32—独立看门狗(IWDG)和窗口看门狗(WWDG)
概述: WDG(Watchdog) 看门狗,看门狗可以监控程序的运行状态,当程序因为设计漏洞、硬件故障、电磁干扰等原因,出现卡死或跑飞现象时,看门狗能计时复位程序,避免程序陷入长时间的罢工状态,保证系…...
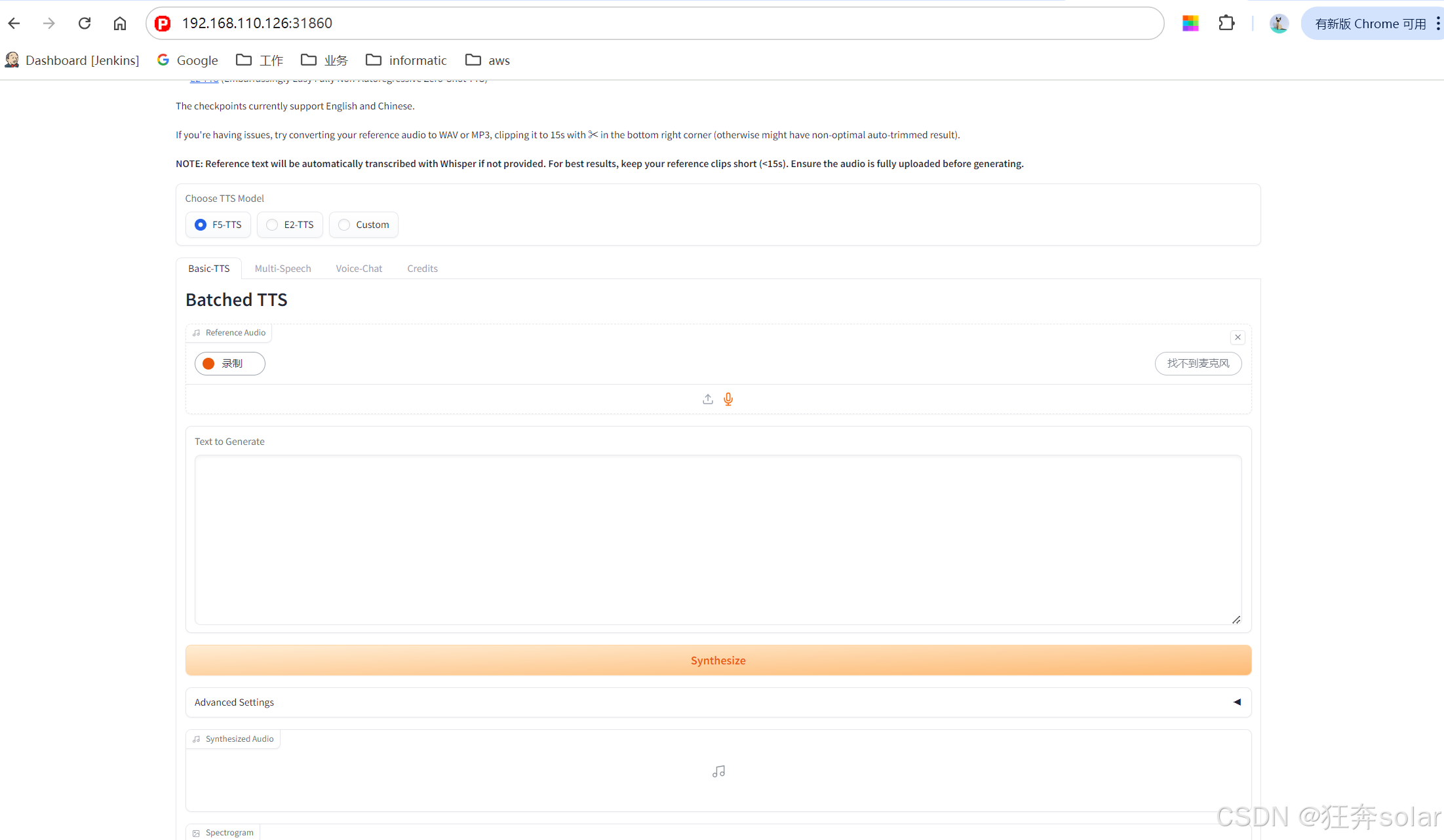
ks8 本地化部署 F5-TTS
huggingface上有一个demo可以打开就能玩 https://huggingface.co/spaces/mrfakename/E2-F5-TTS 上传了一段懂王的演讲片段,然后在 generate text框内填了点古诗词,生成后这语气这效果,离真懂王就差一个手风琴了。 F5-TTS 项目地址…...

Web组态大屏可视化编辑器
1、零代码、一键构建、一键下载 用户只需通过拖拉拽操作,即可在画布上添加、调整和排列各种设备组件、图表和控件。零代码拖拽方式让用户能够实时预览界面效果,直观地观察布局、样式和数据的变化。 2、实时展示,自动化连接数据,用…...
【comfyui教程】让模特换衣服,comfyui一键搞定!
前言 一键穿上别人的衣服?揭秘ComfyUI模特换装工作流! 你有没有想过,某天早晨你起床后,只需轻轻一点,就能穿上明星昨晚在红毯上的华丽礼服?这种听起来像是科幻电影的情节,如今通过ComfyUI模特…...

数据湖与数据仓库的区别
数据湖与数据仓库是两种不同的数据存储和管理方式,它们在多个方面存在显著的区别。以下是对数据湖与数据仓库区别的详细阐述: 一、数据存储方式 数据仓库 通常采用预定义的模式和结构来存储数据。数据在存储前通常经过清洗、转换和整合等处理࿰…...

golang分布式缓存项目 Day6 防止缓存击穿
该项目原作者:https://github.com/geektutu/7days-golang。本文旨在记录本人做该项目时的一些疑惑解答以及部分的测试样例以便于本人复习。 1 缓存雪崩、缓存击穿与缓存穿透 概念解析: 缓存雪崩:缓存在同一时刻全部失效,造成瞬…...

Redis高可用-主从复制
这里写目录标题 Redis主从复制主从复制过程环境搭建从节点配置常见问题主从模式缺点 Redis主从复制 虽然 Redis 可以实现单机的数据持久化,但无论是 RDB 也好或者 AOF 也好,都解决不了单点宕机问题,即一旦 redis 服务器本身出现系统故障、硬…...

Angular框架:构建现代Web应用的全面指南
文章目录 前言一、Angular简介二、Angular的核心特性三、Angular的应用场景四、Angular的发展趋势五、如何开始使用Angular结语 前言 在当今高度竞争的互联网环境中,构建高效、响应迅速且易于维护的Web应用成为企业成功的关键。Angular框架以其强大的功能、灵活的架…...

Golang | Leetcode Golang题解之第563题二叉树的坡度
题目: 题解: func findTilt(root *TreeNode) (ans int) {var dfs func(*TreeNode) intdfs func(node *TreeNode) int {if node nil {return 0}sumLeft : dfs(node.Left)sumRight : dfs(node.Right)ans abs(sumLeft - sumRight)return sumLeft sumRi…...

gdb编译教程(支持linux下X86和ARM架构)
1、下载源码 http://ftp.gnu.org/gnu/gdb/ 我下载的8.2版本。 2、下载完后拷贝到linux的x86系统。 3、解压,然后进入到目录下,打开当前目录的命令行窗口。 4、创建一个生成目录。 5、我们先开始x86版本,这个比较简单,不需要配置…...

Android 开发指南:初学者入门
Android 是全球最受欢迎的移动操作系统之一,为开发者提供了丰富的工具和资源来创建各种类型的应用程序。本文将为你提供一个全面的入门指南,帮助你从零开始学习 Android 开发。 目录 1. 了解 Android 平台[1]2. 设置开发环境[2]3. 学习基础知识[3]4. 创…...

镭速大文件传输软件向金融银行的文档管理提供高效的解决方案
随着数字化浪潮的推进,金融机构对文档处理和大文件传输的需求日益增长。无论是中央机构还是地方分行,他们都急需一套强大的文档管理系统来应对日益庞大的数据量和日益复杂的业务需求。如何有效地管理海量文档,成为了金融机构面临的一大挑战。…...
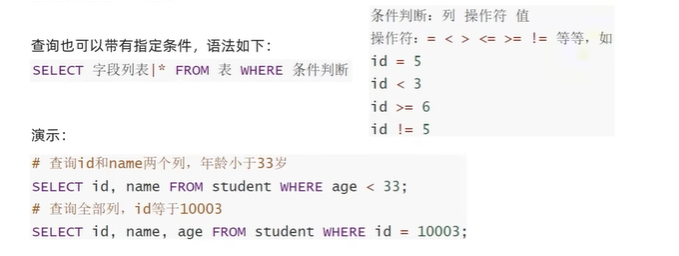
D64【python 接口自动化学习】- python基础之数据库
day64 SQL-DQL-基础查询 学习日期:20241110 学习目标:MySQL数据库-- 133 SQL-DQL-基础查询 学习笔记: 基础数据查询 基础数据查询-过滤 总结 基础查询的语法:select 字段列表|* from 表过滤查询的语法:select 字段…...

HTTP 客户端怎么向 Spring Cloud Sleuth 传输跟踪 ID
在 Spring Cloud Sleuth 的请求链路追踪中,X-B3-TraceId 是第二个 ID,X-B3-SpanId 是第三个 ID。以下是 Sleuth 中各个追踪标识的含义: X-B3-TraceId:表示整个请求链路的全局唯一 ID,用于跟踪请求在多个服务间的流转。…...

为什么hbase在大数据领域渐渐消失
HBase 曾是大数据存储领域的标杆之一,凭借其强大的分布式、列式存储和高扩展性,广泛应用于电商、社交网络、金融等需要海量数据管理的场景。然而,近年来 HBase 的使用确实在减少,这主要是因为数据技术栈的演变和用户需求的变化。以下是一些主要原因: 1. 复杂的运维和管理…...

【GPTs】EmojiAI:轻松生成趣味表情翻译
博客主页: [小ᶻZ࿆] 本文专栏: AIGC | GPTs应用实例 文章目录 💯GPTs指令💯前言💯EmojiAI主要功能适用场景优点缺点 💯小结 💯GPTs指令 中文翻译: 此 GPT 的主要角色是为英文文本提供幽默…...

中国车牌分类
从颜色和单双层分类(不考虑临时车牌) 黄单黄双黄绿单蓝单蓝双绿单绿双黑单黑双白单白双 #特殊文字 挂使港澳学警领临...

机器学习的几何本质:形状、距离与意义的三层重构
1. 这不是数学课,而是一场关于“机器如何看懂世界”的底层解剖你有没有想过,当一台机器识别出照片里是一只猫,它到底“看见”了什么?不是毛色、不是胡须、不是圆眼睛——它看见的是一组高维空间里的点云分布,是这些点之…...

QMCDecode终极指南:5分钟快速掌握QQ音乐加密格式转换技巧
QMCDecode终极指南:5分钟快速掌握QQ音乐加密格式转换技巧 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录,默…...

基于SpringBoot 的实验设备预约系统的设计及实现
摘 要 随着高校与科研院所实验教学规模扩大,传统人工预约实验设备效率低、易冲突、管理混乱,已无法满足师生需求。为提升设备利用率、规范预约流程、减少时间冲突与资源浪费,构建一套基于网络的实验设备预约系统十分必要。该系统可实现在线预…...

RLHF工程化实践:用合成反馈替代人工标注的完整闭环
1. 这不是“替代人类”的口号,而是一套可落地的RLHF工程闭环“Build Your Own RLHF LLM — Forget Human Labelers!” 这个标题一出来,很多同行第一反应是皱眉——不是质疑技术可行性,而是警惕它背后可能隐含的简化主义陷阱。我带过三轮大模型…...

Pure Live:3大平台聚合,打造你的专属纯净直播空间
Pure Live:3大平台聚合,打造你的专属纯净直播空间 【免费下载链接】pure_live A Flutter project can make you watch live with ease. 项目地址: https://gitcode.com/gh_mirrors/pu/pure_live 你是否厌倦了在多个直播应用间来回切换?…...

突破内存瓶颈:HBM、CXL与GPU新部署策略
训练生成式AI模型本身已是一项成本高昂、能耗巨大的工作。随着超大规模数据中心和前沿研究机构竞相扩展边缘推理与智能体AI能力,GPU的部署正变得愈加复杂,尤其是在内存层面。在数据中心中,对先进内存配置的需求日益迫切。不断增多的AI处理器正…...

利用Taotoken审计日志功能追踪与分析团队内部的模型使用情况
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken审计日志功能追踪与分析团队内部的模型使用情况 对于项目管理者或安全运维人员而言,清晰掌握团队内部大模…...

article-extractor项目架构解析:模块化设计与可扩展性指南
article-extractor项目架构解析:模块化设计与可扩展性指南 【免费下载链接】article-extractor To extract main article from given URL with Node.js 项目地址: https://gitcode.com/gh_mirrors/ar/article-extractor article-extractor是一个强大的Node.j…...

《CVPR2025-DEIM创新改进项目实战:从原理到部署的深度学习优化全攻略》020、从原理到部署的深度学习优化全攻略
CVPR2025-DEIM创新改进项目实战:从原理到部署的深度学习优化全攻略 020、DEIM在嵌入式设备上的部署:ONNX导出与TensorRT优化 一、凌晨三点的调试现场 上周五晚上,我盯着Jetson Orin的终端,看着DEIM模型推理速度卡在12.3ms纹丝不动。旁边同事的YOLOv8已经跑到3.2ms了,差…...

论云原生层次架构在自动驾驶云控平台中的应用
【摘要】2024年3月,我作为核心系统架构师,主导了某新能源车企“新一代自动驾驶云控与数据平台”的重构与研发工作。该平台主要负责接入现役50万辆在线车辆,处理海量的多模态工况数据,并支撑大规模自动驾驶算法的并行仿真与实时监控…...