解密复杂系统:理论、模型与案例(3)
第五章:复杂系统的应用案例
复杂系统理论在多个领域中展现出其独特的分析能力和广泛的应用前景。本章将详细探讨复杂系统在生态系统、经济与金融系统、社会网络以及生物系统中的具体应用,通过丰富的案例分析,揭示复杂系统理论在实际问题解决中的重要作用。
5.1 生态系统中的复杂系统应用
5.1.1 生态系统的定义与组成
生态系统是由生物群落与其所处的非生物环境通过物质循环和能量流动相互作用形成的一个功能整体。它包括生产者(如植物)、消费者(如动物)、分解者(如真菌和细菌)等不同层次的有机体,以及水、空气、土壤、阳光等非生物要素。生态系统的复杂性来源于其内部众多组件之间的多样化和动态的相互关系,这些关系不仅决定了系统的结构和功能,还影响着系统的稳定性和适应性。
复杂系统理论通过研究生态系统内部的相互作用,揭示其动态平衡与自组织机制。例如,能量流动可以用数学模型来描述,以理解不同生物体在生态系统中的能量获取和转换过程。物质循环则涉及碳循环、氮循环等关键生态过程,这些过程的数学建模有助于预测生态系统在不同环境条件下的响应。
5.1.2 复杂网络在生态系统中的应用
生态系统中的食物链和食物网本质上是复杂网络结构。食物网中的每一个节点代表一个物种,而边则表示物种之间的捕食关系。这种网络结构可以用图论中的图模型来描述,其中节点的连接方式反映了生态系统的相互依赖关系。
数学表示:
食物网可以用一个有向图 G = ( V , E ) G = (V, E) G=(V,E) 来表示,其中 V V V 是物种的集合, E E E 是捕食关系的集合。若物种 i i i 捕食物种 j j j,则在图中存在从 i i i 指向 j j j 的有向边。
关键指标:
- 度分布:描述物种的连接数,即捕食者和被捕食者的数量分布情况。度分布的形式可以揭示生态系统的网络特性,如是否存在“枢纽”物种。
- 聚集系数:衡量物种之间形成紧密群体的倾向,反映了生态系统中的模块化结构。
- 路径长度:描述物种之间的平均捕食链长度,影响能量和信息在生态系统中的传播效率。
公式与分析:
假设食物网中的物种数为 N N N,捕食关系数为 E E E。度分布 P ( k ) P(k) P(k) 表示具有度数 k k k 的物种所占比例。根据随机图理论,食物网的度分布可以用幂律分布近似:
P ( k ) ∝ k − γ P(k) \propto k^{-\gamma} P(k)∝k−γ
其中, γ \gamma γ 是幂律指数。这种分布表明,大多数物种具有较少的连接,而少数物种拥有大量连接,成为生态系统中的关键枢纽。
应用实例:
通过构建和分析珊瑚礁生态系统中的食物网,可以识别出关键物种,如顶级捕食者,它们在维持生态系统稳定性方面起着至关重要的作用。如果这些关键物种因环境变化或人为干扰而数量减少,可能触发食物网的“连锁反应”,导致整个生态系统功能的崩溃。
5.1.3 生态系统的稳定性与鲁棒性
生态系统的稳定性和鲁棒性是衡量其抵御外部扰动和内部波动能力的重要指标。复杂系统理论通过建立数学模型,分析生态系统在不同条件下的行为模式和响应机制。
稳定性分析:
生态系统的稳定性通常通过线性稳定性分析来评估。考虑一个简单的二元生态系统模型,包括一个生产者物种 x x x 和一个消费者物种 y y y,其动态方程可以表示为:
{ d x d t = r x ( 1 − x K ) − a x y d y d t = b x y − d y \begin{cases} \frac{dx}{dt} = r x \left(1 - \frac{x}{K}\right) - a x y \\ \frac{dy}{dt} = b x y - d y \end{cases} {dtdx=rx(1−Kx)−axydtdy=bxy−dy
其中:
- r r r 是生产者的内禀增长率。
- K K K 是生产者的环境承载力。
- a a a 是消费者捕食效率。
- b b b 是消费者转化效率。
- d d d 是消费者的死亡率。
雅可比矩阵:
为了分析系统在平衡点处的稳定性,需构建雅可比矩阵 J J J:
J = ( ∂ f ∂ x ∂ f ∂ y ∂ g ∂ x ∂ g ∂ y ) = ( r ( 1 − 2 x K ) − a y − a x b y b x − d ) J = \begin{pmatrix} \frac{\partial f}{\partial x} & \frac{\partial f}{\partial y} \\ \frac{\partial g}{\partial x} & \frac{\partial g}{\partial y} \end{pmatrix} = \begin{pmatrix} r \left(1 - \frac{2x}{K}\right) - a y & -a x \\ b y & b x - d \end{pmatrix} J=(∂x∂f∂x∂g∂y∂f∂y∂g)=(r(1−K2x)−ayby−axbx−d)
特征值分析:
计算雅可比矩阵的特征值,可以判断系统在平衡点的稳定性。若特征值的实部均为负,系统则在该平衡点处稳定。通过调整参数 r , K , a , b , d r, K, a, b, d r,K,a,b,d,可以研究系统在不同条件下的动态行为,如震荡、稳定或混沌状态。
鲁棒性评估:
生态系统的鲁棒性可以通过模拟不同扰动(如物种减少、环境变化)下系统的响应来评估。高鲁棒性的生态系统能够迅速恢复到原有状态,或适应新的平衡状态。例如,通过引入物种多样性,可以增强系统的鲁棒性,因为多样性提供了更多的生态位和功能冗余,减少了系统对单一物种的依赖。
公式推导:
考虑一个包含 n n n 个物种的生态系统,其动态方程为:
d x i d t = x i ( r i − ∑ j = 1 n a i j x j ) , i = 1 , 2 , … , n \frac{dx_i}{dt} = x_i \left( r_i - \sum_{j=1}^n a_{ij} x_j \right), \quad i = 1, 2, \ldots, n dtdxi=xi(ri−j=1∑naijxj),i=1,2,…,n
其中, r i r_i ri 是物种 i i i 的增长率, a i j a_{ij} aij 是物种 j j j 对物种 i i i 的影响系数。通过计算系统的雅可比矩阵并分析其特征值,可以评估整个生态系统的稳定性。
5.1.4 案例分析:珊瑚礁生态系统
珊瑚礁生态系统是高度复杂且脆弱的海洋生态系统,受到多种因素的共同影响。其健康状态取决于水温、海洋酸化、营养盐浓度、污染物浓度等多个变量的协同作用。复杂系统模型在此类生态系统的研究中发挥着重要作用。
多因素模型:
建立珊瑚礁生态系统的动力学模型,考虑以下变量:
- C C C:健康珊瑚的覆盖率。
- A A A:海藻的覆盖率。
- T T T:水温。
- p H pH pH:海洋酸化程度。
模型方程示例:
{ d C d t = r C C ( 1 − C + α A K C ) − d C C T d A d t = r A A ( 1 − A + β C K A ) − d A A p H d T d t = k T ( T e n v − T ) d p H d t = k p H ( p H e n v − p H ) \begin{cases} \frac{dC}{dt} = r_C C \left(1 - \frac{C + \alpha A}{K_C}\right) - d_C C T \\ \frac{dA}{dt} = r_A A \left(1 - \frac{A + \beta C}{K_A}\right) - d_A A pH \\ \frac{dT}{dt} = k_T (T_{env} - T) \\ \frac{dpH}{dt} = k_{pH} (pH_{env} - pH) \end{cases} ⎩ ⎨ ⎧dtdC=rCC(1−KCC+αA)−dCCTdtdA=rAA(1−KAA+βC)−dAApHdtdT=kT(Tenv−T)dtdpH=kpH(pHenv−pH)
其中:
- r C , r A r_C, r_A rC,rA 分别为珊瑚和海藻的增长率。
- K C , K A K_C, K_A KC,KA 分别为珊瑚和海藻的环境承载力。
- d C , d A d_C, d_A dC,dA 分别为珊瑚和海藻对水温和酸化的敏感度。
- α , β \alpha, \beta α,β 表示珊瑚与海藻之间的竞争程度。
- k T , k p H k_T, k_{pH} kT,kpH 表示水温和酸化程度的变化速率。
模型分析:
通过数值模拟,可以研究不同水温和酸化条件下,珊瑚礁生态系统的演化趋势。例如,增高的水温和降低的 p H pH pH 值可能导致珊瑚的健康状态迅速恶化,海藻快速扩张,进而引发生态系统的重组或崩溃。
保护策略制定:
基于模型结果,可以制定相应的保护策略,如控制污染物排放、减缓全球变暖、实施海洋酸化缓解措施等,以维持珊瑚礁生态系统的稳定性和健康状态。此外,模型还可以用于预测未来气候变化情景下珊瑚礁的响应,为政策制定提供科学依据。
公式推导与解释:
以珊瑚的增长方程为例:
d C d t = r C C ( 1 − C + α A K C ) − d C C T \frac{dC}{dt} = r_C C \left(1 - \frac{C + \alpha A}{K_C}\right) - d_C C T dtdC=rCC(1−KCC+αA)−dCCT
- 第一项 r C C ( 1 − C + α A K C ) r_C C \left(1 - \frac{C + \alpha A}{K_C}\right) rCC(1−KCC+αA) 描述了珊瑚的自我增长和受到海藻竞争抑制的影响。
- 第二项 − d C C T -d_C C T −dCCT 表示水温对珊瑚健康的负面影响,随着水温的升高,珊瑚健康状况恶化的速度加快。
通过求解该方程,可以分析珊瑚在不同水温下的增长趋势,进而评估环境变化对珊瑚礁生态系统的长期影响。
5.2 经济与金融系统中的复杂系统应用
5.2.1 经济系统的复杂性
经济系统由众多独立但相互关联的经济主体(如消费者、企业、政府)通过市场机制相互作用构成。这种系统内部存在复杂的互动和反馈机制,使得经济系统表现出高度的动态性和非线性特征。复杂系统理论通过建模这些互动,帮助理解经济波动、市场动态和系统性风险,为经济政策制定和风险管理提供科学依据。
5.2.2 金融市场的网络结构分析
金融市场中的金融机构和交易行为形成了复杂的网络结构。金融网络中的节点代表金融机构,如银行、投资公司等;边则表示金融交易关系,如贷款、投资等。网络科学的方法可以用于分析金融网络的拓扑特性,以识别系统中的关键节点和潜在风险源。
数学模型:
假设金融网络 G = ( V , E ) G = (V, E) G=(V,E) 中, V V V 是金融机构的集合, E E E 是金融交易关系的集合。每条边 e i j e_{ij} eij 表示机构 i i i 向机构 j j j 提供的贷款或投资金额。
关键指标:
- 中心性指标:包括度中心性、介数中心性和接近中心性,用于衡量金融机构在网络中的重要性。
- 连通性:分析网络的联通性,判断网络的整体稳定性和抗冲击能力。
- 集群系数:衡量网络中形成群集的倾向,反映金融机构之间的紧密互动。
系统性风险分析:
通过模拟金融机构的倒闭或资金链断裂,可以分析危机在金融网络中的传播路径。例如,某大型银行的倒闭可能通过其与其他银行的贷款关系,导致连锁反应,引发整个金融系统的动荡。
公式与应用:
金融网络的连通性可以通过邻接矩阵 A A A 来描述,其中 A i j = 1 A_{ij} = 1 Aij=1 表示存在从机构 i i i 到机构 j j j 的交易关系。网络的度分布 P ( k ) P(k) P(k) 可以用来评估系统的脆弱性:
P ( k ) ∝ k − γ P(k) \propto k^{-\gamma} P(k)∝k−γ
若金融网络呈现幂律分布,意味着大部分机构连接较少,而少数机构连接度极高,这些高连接度的机构在金融危机中扮演关键角色,其倒闭可能引发严重的系统性风险。
5.2.3 市场行为的非线性动力学
金融市场中的价格波动常表现出非线性和混沌特性,这使得市场行为难以预测和控制。复杂系统模型如随机游走和分形理论被广泛应用于描述和预测市场价格的波动行为。
随机游走模型:
假设股票价格 S t S_t St 随时间 t t t 的变化遵循随机游走过程:
S t = S t − 1 + ϵ t S_t = S_{t-1} + \epsilon_t St=St−1+ϵt
其中, ϵ t \epsilon_t ϵt 是均值为零的随机变量,表示价格的随机波动。虽然该模型简单,但无法捕捉市场中的复杂动态行为。
分形市场假说:
分形市场假说认为,金融市场具有自相似性和标度不变性,价格波动呈现分形几何结构。通过分形维数 D D D 来描述市场的复杂性:
D = log ( N ) log ( l ) D = \frac{\log(N)}{\log(l)} D=log(l)log(N)
其中, N N N 是覆盖网络所需的最小网格数, l l l 是网格的大小。较高的分形维数表明市场行为更为复杂和多变。
混沌理论应用:
混沌理论强调系统对初始条件的高度敏感性。金融市场中的微小信息变化可能引发价格的大幅波动。通过建立混沌映射模型,可以模拟和分析市场的复杂动态行为,如:
x n + 1 = r x n ( 1 − x n ) x_{n+1} = r x_n (1 - x_n) xn+1=rxn(1−xn)
该模型展示了简单双曲线方程如何在特定参数下产生混沌行为,反映出市场价格的不可预测性。
公式推导与解释:
以分形市场假说为例,考虑一段时间序列的数据 { S t } \{S_t\} {St},通过计算其分形维数,可以量化市场的复杂性。如果分形维数接近2,说明市场极为复杂和不可预测;若接近1,则市场行为较为规则和可预测。
5.2.4 案例分析:2008年金融危机
2008年的全球金融危机揭示了经济系统的高度复杂性和脆弱性。这场危机的爆发和扩散过程可以通过复杂系统理论进行深入解析。
金融网络的模拟:
通过建立包含全球主要金融机构的网络模型,模拟各机构之间的债务和持股关系。模型中,节点代表金融机构,边代表贷款、投资等交易关系。
连锁反应机制:
当某个大型金融机构(如雷曼兄弟)面临破产风险时,其持有的资产价值大幅下降,导致其无法偿还债务。这一事件通过网络中的交易关系传播,影响到其他金融机构的资产负债表,最终导致整个金融系统的动荡。
系统性风险评估:
利用风险传播模型,可以量化各金融机构对系统性风险的贡献。例如,计算每个机构的介数中心性,识别出在危机传播中起关键作用的机构。这有助于制定有效的金融监管政策,防止类似危机的再次发生。
公式与分析:
考虑一个简化的金融网络模型,节点 i i i 的倒闭概率 P i P_i Pi 随时间 t t t 变化:
P i ( t + 1 ) = P i ( t ) + ∑ j ∈ N ( i ) W j i P j ( t ) − λ P i ( t ) P_i(t+1) = P_i(t) + \sum_{j \in \mathcal{N}(i)} W_{ji} P_j(t) - \lambda P_i(t) Pi(t+1)=Pi(t)+j∈N(i)∑WjiPj(t)−λPi(t)
其中, N ( i ) \mathcal{N}(i) N(i) 是与节点 i i i 相连的所有邻居节点, W j i W_{ji} Wji 是节点 j j j 对节点 i i i 的影响权重, λ \lambda λ 是恢复机制的参数。该方程描述了节点 i i i 倒闭概率的动态变化,综合考虑了邻居节点的影响和系统的自我恢复能力。
通过求解该方程,可以模拟金融危机的传播路径和时间尺度,评估不同监管措施对危机扩散的抑制效果。
2008年金融危机的案例表明,经济系统作为一个复杂系统,其内部的高度互联性和非线性反馈机制使得系统对局部扰动极为敏感。复杂系统理论提供了有效的工具和方法,用于分析和理解金融危机的演变过程,为未来的金融监管和风险管理提供了重要的理论支持。
5.3 社会网络中的复杂系统应用
5.3.1 社会网络的结构与功能
社会网络由个体(节点)及其关系(边)组成,反映了社会互动的复杂性。个体之间的关系可以是友谊、合作、信息交流等多种形式。复杂系统理论通过社会网络分析方法,研究信息传播、社会影响和集体行为等现象,揭示社会系统的动态演化规律。
网络模型:
社会网络可以用无向图或有向图来表示。无向图适用于描述对称关系(如友谊),而有向图则适用于描述不对称关系(如信息传播方向)。
关键指标:
- 度中心性:衡量一个节点在网络中的连接数,反映其在网络中的重要性。
- 介数中心性:衡量一个节点在其他节点之间的最短路径上的出现频率,反映其在信息传播中的中介作用。
- 聚类系数:衡量一个节点的邻居之间互相连接的程度,反映网络的集群化特性。
- 平均路径长度:衡量网络中任意两节点之间的最短路径长度,反映信息传播的效率。
公式表示:
对于一个节点 i i i,其度中心性 C D ( i ) C_D(i) CD(i) 定义为:
C D ( i ) = k i C_D(i) = k_i CD(i)=ki
其中, k i k_i ki 是节点 i i i 的度数。
对于介数中心性 C B ( i ) C_B(i) CB(i),定义为:
C B ( i ) = ∑ s ≠ i ≠ t σ s t ( i ) σ s t C_B(i) = \sum_{s \neq i \neq t} \frac{\sigma_{st}(i)}{\sigma_{st}} CB(i)=s=i=t∑σstσst(i)
其中, σ s t \sigma_{st} σst 是节点 s s s 到节点 t t t 的最短路径数, σ s t ( i ) \sigma_{st}(i) σst(i) 是经过节点 i i i 的最短路径数。
功能分析:
通过计算这些网络指标,可以识别社会网络中的关键个体(如意见领袖)、子群体(如社群)以及网络的整体结构特征(如小世界效应、无标度网络等)。
5.3.2 信息传播与舆论形成
在社会网络中,信息的传播和舆论的形成是典型的复杂现象。信息在网络中的扩散可以通过传播模型来描述,舆论则是个体意见的集体体现,受到信息传播和社会影响的共同作用。
信息传播模型:
-
独立级联模型(Independent Cascade Model):
设定每个节点在被激活后,有一定概率 p p p 激活其邻居节点,传播过程独立进行。
P ( 传播成功 ) = p P(\text{传播成功}) = p P(传播成功)=p
-
阈值模型(Threshold Model):
每个节点有一个阈值 θ \theta θ,当其邻居中的激活节点比例超过 θ \theta θ 时,该节点被激活。
∑ j ∈ N ( i ) A i j x j k i ≥ θ \frac{\sum_{j \in \mathcal{N}(i)} A_{ij} x_j}{k_i} \geq \theta ki∑j∈N(i)Aijxj≥θ
其中, x j x_j xj 表示节点 j j j 是否被激活, A i j A_{ij} Aij 是邻接矩阵元素, k i k_i ki 是节点 i i i 的度数。
舆论形成机制:
舆论的形成受到个体之间的相互影响和信息传播的驱动。复杂系统模型如复制动力学和博弈论模型被用于描述和预测舆论的演变过程。
公式与解析:
考虑一个简单的舆论模型,设有两种意见 A A A 和 B B B。个体 i i i 的意见 x i ( t ) x_i(t) xi(t) 在时间 t t t 变化由周围个体的意见影响决定:
x i ( t + 1 ) = sign ( ∑ j ∈ N ( i ) w i j x j ( t ) ) x_i(t+1) = \text{sign}\left(\sum_{j \in \mathcal{N}(i)} w_{ij} x_j(t)\right) xi(t+1)=sign j∈N(i)∑wijxj(t)
其中, w i j w_{ij} wij 是个体 j j j 对个体 i i i 的影响权重, N ( i ) \mathcal{N}(i) N(i) 是节点 i i i 的邻居集合。
通过迭代计算,可以模拟舆论的动态变化,分析不同网络结构和影响力分布下舆论的稳定性和多样性。
应用实例:
利用模型预测社交媒体上的热点事件发展趋势和舆论变化路径,有助于政府和企业制定有效的公共政策和危机管理策略。
5.3.3 社会动力学与集体行为
社会网络中的个体行为通过相互影响形成集体行为模式。复杂系统模型如元胞自动机和多主体系统被用于模拟和分析群体行为,如示威运动的组织与扩散、流行文化的传播等,帮助理解社会现象的本质和驱动机制。
元胞自动机模型:
元胞自动机是一种离散的数学模型,用于模拟复杂系统中的空间和时间演化过程。每个元胞代表一个个体,其状态由邻居元胞的状态决定。
多主体系统模型:
多主体系统由多个自主的个体组成,这些个体通过一定的规则进行交互,产生复杂的集体行为。这类模型强调个体之间的局部交互和全球行为之间的关系。
公式与模拟:
设定每个个体 i i i 的状态 s i ( t ) s_i(t) si(t) 随时间 t t t 变化由其邻居状态 { s j ( t ) } \{s_j(t)\} {sj(t)} 决定,规则为:
s i ( t + 1 ) = f ( ∑ j ∈ N ( i ) w i j s j ( t ) , θ i ) s_i(t+1) = f\left( \sum_{j \in \mathcal{N}(i)} w_{ij} s_j(t), \theta_i \right) si(t+1)=f j∈N(i)∑wijsj(t),θi
其中, f f f 是一个非线性函数, θ i \theta_i θi 是个体 i i i 的阈值。
案例分析:
通过模拟示威运动的扩散过程,可以研究信息传播、群体动员和抗议行为的相互作用,帮助理解社会运动的形成和扩展机制。
5.3.4 案例分析:社交媒体中的信息传播
社交媒体平台如Twitter和微博成为信息传播的重要渠道。复杂系统理论通过分析社交网络中的信息流动,揭示了虚假信息的扩散机制和影响因素。
信息传播模型:
在社交媒体上,信息传播可以视为一种激励过程,使用独立级联模型和阈值模型来模拟信息的扩散。
虚假信息扩散机制:
虚假信息的扩散具有高传播速度和广泛影响力,易导致公众的误判和恐慌。通过分析信息的传播路径和关键节点,可以识别出潜在的虚假信息源和传播途径。
影响因素分析:
- 网络拓扑结构:网络的连接方式影响信息传播的速度和范围。高集聚度和短路径长度的网络有利于信息的快速扩散。
- 节点活跃度:活跃用户在信息传播中起到关键作用,他们的转发和评论能够显著影响信息的传播效力。
- 信息内容特征:信息的情感色彩、主题相关性和可信度等因素影响其传播速度和接受程度。
公式与分析:
考虑信息传播的概率 p p p,以及个体 i i i 对信息的接受概率 P i P_i Pi,可以建立如下模型:
P i ( t + 1 ) = P i ( t ) + [ 1 − P i ( t ) ] ( 1 − ∏ j ∈ N ( i ) ( 1 − p P j ( t ) ) ) P_i(t+1) = P_i(t) + [1 - P_i(t)] \left( 1 - \prod_{j \in \mathcal{N}(i)} (1 - p P_j(t)) \right) Pi(t+1)=Pi(t)+[1−Pi(t)] 1−j∈N(i)∏(1−pPj(t))
该方程描述了个体 i i i 在时间 t + 1 t+1 t+1 接受信息的概率,考虑了其所有邻居传播的信息影响。
模拟与应用:
通过数值模拟,可以预测虚假信息在社交媒体上的传播路径和影响范围,评估不同干预措施(如信息过滤、用户教育)的效果,为网络信息监管和虚假信息控制提供科学依据。
总结:
社交媒体中的信息传播是一个高度动态和复杂的过程,复杂系统理论提供了有效的工具和方法,用于分析信息的扩散机制和影响因素。通过深入理解这些机制,可以制定更加有效的策略,控制虚假信息的传播,维护网络空间的信息安全和社会稳定。
5.4 生物系统中的复杂系统应用
5.4.1 生物系统的复杂性特征
生物系统涵盖了从分子水平的基因调控到宏观层面的生态系统,其内部充满了高度复杂的相互作用和动态调控机制。这些系统具备多层次、多尺度的特点,使得其行为难以通过简单的线性模型进行描述。复杂系统理论通过整合大量生物学数据,构建多层次的生物网络模型,帮助科学家深入理解生物系统的功能、调控机制以及其在不同环境条件下的响应。
例如,细胞内的基因调控网络涉及数千个基因及其相互作用,这些相互作用决定了细胞的生长、分化和反应能力。生态系统中的物种间相互作用,如捕食、竞争和共生关系,则决定了整个生态系统的稳定性和多样性。复杂系统理论不仅揭示了这些相互作用的非线性特性,还通过模型预测系统在外界干扰下的行为,为生物学研究提供了强有力的工具。
5.4.2 基因调控网络与系统生物学
基因调控网络是生物系统中基因之间通过转录因子、信号分子等进行相互调控的复杂网络。这些网络中的基因表达受到多种因素的影响,表现出高度的非线性和动态变化。系统生物学通过复杂系统模型,对基因调控网络进行深入分析,揭示基因表达的动态变化规律和调控机制。
一个常见的基因调控模型是布尔网络模型(Boolean Network Model),其中每个基因的表达状态被简化为“开”或“关”两种状态。该模型通过逻辑规则描述基因之间的调控关系,例如:
s i ( t + 1 ) = f i ( { s j ( t ) } ) s_i(t+1) = f_i\left( \{s_j(t)\} \right) si(t+1)=fi({sj(t)})
其中, s i ( t ) s_i(t) si(t) 表示基因 i i i 在时间 t t t 的表达状态, f i f_i fi 是描述基因 i i i 表达状态的逻辑函数,依赖于其调控基因的当前状态。
为了更精确地描述基因表达的动态变化,微分方程模型被广泛应用。例如,基于转录-翻译过程的模型可以表示为:
d x i d t = α i ⋅ f i ( { x j } ) − β i x i \frac{dx_i}{dt} = \alpha_i \cdot f_i\left( \{x_j\} \right) - \beta_i x_i dtdxi=αi⋅fi({xj})−βixi
其中, x i x_i xi 是基因 i i i 的表达水平, α i \alpha_i αi 是基因 i i i 的最大表达速率, f i f_i fi 是基因调控函数, β i \beta_i βi 是基因 i i i 的降解速率。通过求解这些非线性微分方程,可以模拟基因表达的动态变化,预测系统在不同条件下的响应。
公式推导与解释:
考虑一个简单的基因调控网络,其中基因 A A A 调控基因 B B B,基因 B B B 又反馈调控基因 A A A。其动态方程可以表示为:
{ d x A d t = α A ⋅ 1 1 + e − k A x B − β A x A d x B d t = α B ⋅ 1 1 + e − k B x A − β B x B \begin{cases} \frac{dx_A}{dt} = \alpha_A \cdot \frac{1}{1 + e^{-k_A x_B}} - \beta_A x_A \\ \frac{dx_B}{dt} = \alpha_B \cdot \frac{1}{1 + e^{-k_B x_A}} - \beta_B x_B \end{cases} {dtdxA=αA⋅1+e−kAxB1−βAxAdtdxB=αB⋅1+e−kBxA1−βBxB
其中, 1 1 + e − k A x B \frac{1}{1 + e^{-k_A x_B}} 1+e−kAxB1 和 1 1 + e − k B x A \frac{1}{1 + e^{-k_B x_A}} 1+e−kBxA1 分别是基因 A A A 和基因 B B B 的调控函数,描述了非线性的激活过程。通过分析该系统的稳定性,可以揭示基因调控网络中的稳态行为和动态转变。
此类模型的求解通常依赖于数值方法,如Runge-Kutta方法,通过计算机模拟可以获得系统在不同初始条件下的行为轨迹,帮助理解基因网络的复杂动态。
5.4.3 蛋白质相互作用网络
蛋白质相互作用网络(Protein-Protein Interaction Networks, PPI)是细胞内蛋白质之间通过物理接触或功能关联形成的复杂网络。这些网络中的蛋白质通过相互作用执行生物功能,维持细胞的正常运行和响应外界刺激。复杂系统理论通过分析PPI网络,识别关键蛋白质和功能模块,深入理解细胞功能和生物过程的协调机制。
一个典型的PPI网络可以表示为图论中的无向图,其中节点代表蛋白质,边代表蛋白质之间的相互作用。网络的拓扑结构,如节点的度分布、聚集系数和模块化结构,反映了系统的功能特性。例如,中心节点(hub proteins)在网络中具有较高的连接度,往往扮演关键的调控角色,其异常可能导致严重的生物功能紊乱。
为了量化PPI网络的特性,常用的数学指标包括:
- 度分布:描述网络中各节点连接数的分布情况,通常服从幂律分布。
- 聚类系数:衡量网络中节点的局部聚集程度,反映了功能模块的存在。
- 最短路径长度:描述网络中任意两个节点之间的平均最短路径,反映了信息传播的效率。
通过这些指标,研究者可以识别出关键蛋白质和重要的功能模块,进一步通过实验验证其在生物过程中的作用。例如,利用系统生物学方法,可以发现某些关键蛋白质的异常表达或突变与特定疾病的发生密切相关,从而为疾病治疗提供潜在的靶点。
公式与分析:
考虑一个蛋白质相互作用网络中的信息传播模型,假设信息在网络中以随机游走的方式传播。设网络中有 N N N 个蛋白质,信息从蛋白质 i i i 传递到蛋白质 j j j 的概率为 P i j P_{ij} Pij。则信息传播的转移矩阵 P P P 可以表示为:
P i j = A i j ∑ k = 1 N A i k P_{ij} = \frac{A_{ij}}{\sum_{k=1}^{N} A_{ik}} Pij=∑k=1NAikAij
其中, A i j A_{ij} Aij 是邻接矩阵,表示蛋白质 i i i 与蛋白质 j j j 是否相互作用( A i j = 1 A_{ij}=1 Aij=1 表示相互作用, A i j = 0 A_{ij}=0 Aij=0 表示无相互作用)。
通过研究转移矩阵的特征值和特征向量,可以揭示网络的稳定态分布和信息传播的速率。例如,最大的特征值对应的信息传播速率,而其对应的特征向量则反映了网络中各蛋白质的重要性。
5.4.4 案例分析:癌症网络学
癌症作为一种高度复杂的疾病,其发生和发展涉及多种基因突变、信号通路异常以及细胞行为的失控。癌症网络学(Cancer Network Biology)通过构建和分析癌症相关的基因和蛋白质网络,揭示癌症进程中的关键节点和富集通路,为精准治疗提供理论支持。
癌症基因调控网络模型:
在癌症网络学中,基因调控网络模型通常包括致癌基因(Oncogenes)和抑癌基因(Tumor Suppressor Genes)。这些基因通过复杂的调控关系影响细胞的增殖、凋亡和迁移行为。一个典型的癌症基因调控模型可以表示为:
d x i d t = α i ⋅ f i ( { x j } ) − β i x i + ∑ k γ i k x k \frac{dx_i}{dt} = \alpha_i \cdot f_i\left( \{x_j\} \right) - \beta_i x_i + \sum_{k} \gamma_{ik} x_k dtdxi=αi⋅fi({xj})−βixi+k∑γikxk
其中, x i x_i xi 表示基因 i i i 的表达水平, α i \alpha_i αi 是基因 i i i 的激活速率, f i f_i fi 是基因 i i i 的调控函数, β i \beta_i βi 是基因 i i i 的降解速率, γ i k \gamma_{ik} γik 表示基因 k k k 对基因 i i i 的调控强度。
通过构建这样的模型,可以模拟癌症细胞中基因表达的动态变化,分析不同基因突变对网络行为的影响。例如,某些基因的过表达可能导致细胞无限增殖,而其他基因的失活则可能阻碍细胞凋亡,从而促进癌症的发展。
网络分析与靶点识别:
利用复杂系统理论中的网络分析方法,可以在癌症基因调控网络中识别出关键节点(关键基因)和关键路径(关键信号通路)。关键节点通常是网络中具有高连接度或高介数中心性的基因,它们在网络中扮演着核心的调控角色。通过干预这些关键节点,可以有效地抑制癌症的进展。
例如,研究发现某些关键基因如TP53、RAS和MYC在多种癌症中高度突变和激活,它们的异常表达直接影响细胞周期、DNA修复和代谢路线。通过针对这些基因设计特异性药物,可以提高癌症治疗的精准性和有效性。
药物组合策略优化:
癌症治疗通常需要多种药物的组合,以克服癌细胞的耐药性和多样性。复杂系统模型可以帮助优化药物组合策略,通过模拟不同药物在基因调控网络中的作用,找到最有效的药物组合方案。例如,利用博弈论和优化算法,可以在保证治疗效果的同时,最小化副作用和成本。
模拟与验证:
通过数值模拟,可以预测不同基因突变和药物干预对癌症网络的影响,指导实验验证。例如,利用Monte Carlo模拟方法,可以评估药物组合在不同患者基因背景下的效果,为个性化治疗提供依据。此外,网络模型的预测结果需要通过体外实验和临床试验进行验证,确保其在实际应用中的有效性和可靠性。
癌症网络学作为复杂系统理论在生物医学领域的重要应用,通过构建和分析癌症相关的基因和蛋白质网络,揭示了癌症发展的复杂机制。通过识别关键基因和优化药物组合策略,复杂系统模型为精准医学和个性化治疗提供了强有力的理论支持,显著提升了癌症治疗的效果和效率。
5.5 本章小结
本章通过深入分析生态系统、经济与金融系统、社会网络及生物系统中的复杂系统应用案例,展示了复杂系统理论在不同领域中的广泛适用性和强大分析能力。这些具体案例的探讨不仅加深了对复杂系统本质的理解,还为解决跨领域的复杂问题提供了宝贵的理论工具和方法论支持,促进了复杂系统理论在实际应用中的进一步发展。
第六章:复杂系统的前沿研究
随着科学技术的不断进步,复杂系统的研究也迈入了新的前沿领域。本章将深入探讨复杂系统在人工智能、量子计算、控制与优化等方面的最新进展与应用,展望复杂系统研究的未来发展方向。
6.1 人工智能与复杂系统
人工智能(Artificial Intelligence, AI)与复杂系统的交汇点为研究和解决复杂问题提供了全新的视角和工具。AI技术,尤其是机器学习和深度学习,能够从海量数据中提取隐藏的模式和规律,进而对复杂系统的行为进行预测和优化。复杂系统的多样性和非线性特征使得传统的分析方法往往难以应对,而AI方法凭借其强大的数据处理和模式识别能力,成为理解和控制复杂系统的重要手段。
6.1.1 机器学习在复杂系统中的应用
机器学习(Machine Learning, ML)算法通过对大量数据的学习,能够自动识别复杂系统中关键变量及其相互作用关系。在复杂系统中,变量之间通常存在高度的非线性和多重依赖关系,这使得手动建模变得异常困难。机器学习提供了数据驱动的方法,能够有效地解决这一难题。
例如,在气候模型中,深度学习通过多层神经网络能够处理大规模的气象数据,从中提取出影响气候变化的主要因素。具体而言,考虑气温、湿度、气压等多种气象变量的历史数据,深度神经网络可以学习这些变量之间的复杂关系,构建出准确的气候预测模型。公式如下:
y = f ( X ; θ ) y = f(\mathbf{X}; \theta) y=f(X;θ)
其中, X \mathbf{X} X 表示输入的多维气象数据, θ \theta θ 是模型的参数, f f f 是深度学习模型所学习的非线性映射函数。通过最优化算法,如梯度下降,调整参数 θ \theta θ 以最小化预测误差,实现对气候变化趋势的精确预测。
此外,强化学习(Reinforcement Learning, RL)在交通管理系统中的应用也展现了其强大的优化能力。强化学习通过智能体与环境的交互,学习如何在不同的交通状态下调整信号灯的切换时序,以最大限度地减少交通拥堵和提高通行效率。其基本原理可以通过马尔可夫决策过程(Markov Decision Process, MDP)来描述:
max π E [ ∑ t = 0 ∞ γ t R t ] \max_{\pi} \mathbb{E}\left[ \sum_{t=0}^{\infty} \gamma^t R_t \right] πmaxE[t=0∑∞γtRt]
其中, π \pi π 是策略, γ \gamma γ 是折扣因子, R t R_t Rt 是时刻 t t t 的奖励。通过迭代学习,智能体能够找到最优策略 π ∗ \pi^* π∗,有效优化交通流量。
6.1.2 深度学习与复杂系统的模拟
深度学习模型,尤其是神经网络,具备强大的非线性映射能力,能够模拟复杂系统中的非线性动态行为。在生物系统研究中,神经网络被用于模拟基因调控网络,揭示基因间的复杂交互作用;在经济系统中,深度学习帮助预测市场趋势,分析经济指标之间的复杂关联。
以基因调控网络为例,假设基因表达水平之间存在非线性关系,可以使用多层感知机(Multilayer Perceptron, MLP)来模拟这些关系。模型的输出可以表示为:
y = σ ( W 2 ⋅ σ ( W 1 x + b 1 ) + b 2 ) \mathbf{y} = \sigma( \mathbf{W}_2 \cdot \sigma(\mathbf{W}_1 \mathbf{x} + \mathbf{b}_1) + \mathbf{b}_2 ) y=σ(W2⋅σ(W1x+b1)+b2)
其中, x \mathbf{x} x 是基因表达的输入向量, W 1 \mathbf{W}_1 W1, W 2 \mathbf{W}_2 W2 是权重矩阵, b 1 \mathbf{b}_1 b1, b 2 \mathbf{b}_2 b2 是偏置项, σ \sigma σ 是激活函数,如ReLU或Sigmoid。通过训练网络,模型能够捕捉到基因间的复杂调控关系,提高对基因网络行为的理解和预测能力。
在经济系统中,深度学习同样发挥着重要作用。例如,利用卷积神经网络(Convolutional Neural Networks, CNNs)处理时间序列数据,能够识别出市场中的潜在模式和趋势。模型的损失函数通常为均方误差(Mean Squared Error, MSE):
L = 1 N ∑ i = 1 N ( y ^ i − y i ) 2 \mathcal{L} = \frac{1}{N} \sum_{i=1}^{N} (\hat{y}_i - y_i)^2 L=N1i=1∑N(y^i−yi)2
通过最小化损失函数,模型学习到经济指标之间的复杂关联,为投资决策提供科学依据。此外,生成对抗网络(Generative Adversarial Networks, GANs)在金融市场模拟中也展现出其独特的优势,通过生成逼真的市场数据,辅助风险评估和资产定价。
6.1.3 人工智能驱动的复杂系统优化
AI技术不仅用于分析和模拟,还在复杂系统的优化和控制中发挥重要作用。通过优化算法,AI能够在多目标、多约束下寻找复杂系统的最优解。例如,在智能电网中,人工智能优化算法能够实时调整能源分配,提高电网的效率和稳定性;在供应链管理中,AI优化系统可以协调不同环节的运作,降低库存成本,提升响应速度。
以智能电网优化为例,目标是最小化能源损耗,同时保证电网的稳定性。这可以通过以下优化问题来描述:
min P ∑ i , j f ( P i j ) \min_{\mathbf{P}} \sum_{i,j} f(P_{ij}) Pmini,j∑f(Pij)
subject to:
∑ j P i j = D i , ∀ i \sum_{j} P_{ij} = D_i, \quad \forall i j∑Pij=Di,∀i
P i j ≤ P i j m a x , ∀ i , j P_{ij} \leq P_{ij}^{max}, \quad \forall i,j Pij≤Pijmax,∀i,j
其中, P i j P_{ij} Pij 表示从节点 i i i 到节点 j j j 的电力传输量, D i D_i Di 表示节点 i i i 的电力需求, f ( P i j ) f(P_{ij}) f(Pij) 是电力损耗函数。利用遗传算法(Genetic Algorithm, GA)或粒子群优化(Particle Swarm Optimization, PSO)等AI优化方法,可以高效求解该问题,找到最优的电力传输方案。
在供应链管理中,AI优化系统通过协调供应商、制造商、分销商和零售商之间的运作,优化库存水平和配送路径。其目标函数通常包括库存成本、运输成本和响应时间等,形式如下:
min S , T ∑ i C i S i + ∑ j T j C j \min_{\mathbf{S}, \mathbf{T}} \sum_{i} C_i S_i + \sum_{j} T_j C_j S,Tmini∑CiSi+j∑TjCj
其中, S i S_i Si 是仓储成本, T j T_j Tj 是运输成本, C i C_i Ci 和 C j C_j Cj 是相应的成本系数。通过应用强化学习算法,AI系统能够在动态和不确定的环境中实时调整库存和运输策略,提升供应链的整体效率和响应能力。
此外,深度强化学习(Deep Reinforcement Learning, DRL)在复杂系统优化中展现出极大的潜力。DRL结合了深度学习和强化学习的优势,能够处理更复杂的决策问题。例如,在智能制造中,DRL可以优化生产流程,减少停机时间,提高生产效率;在智能交通系统中,DRL能够协调多个交通信号灯,实现整体交通流的优化。
人工智能通过其强大的数据分析、模拟和优化能力,为复杂系统的理解和管理提供了有力的支持。通过深入结合AI技术,复杂系统研究能够更准确地预测系统行为、揭示内在规律,并在实际应用中实现高效优化和控制,推动各领域的发展和进步。
6.2 量子计算与复杂系统
量子计算作为21世纪最具前瞻性的计算技术之一,凭借其独特的并行处理能力和在解决复杂问题上的潜力,正在为复杂系统的研究带来前所未有的变革。传统的经典计算依赖于比特(bit)进行信息处理,而量子计算则基于量子比特(qubit),利用量子叠加和量子纠缠等特性,实现对信息的高效处理。这些特性使得量子计算在处理大规模并行运算和高维度数据时,展现出无可比拟的优势,为复杂系统的模拟、优化和分析提供了强有力的工具。
6.2.1 量子算法在复杂系统模拟中的应用
复杂系统的模拟往往涉及大量的计算资源,特别是在处理非线性、动态变化和高维度的系统时,经典计算面临着效率低下和计算瓶颈的问题。量子算法通过利用量子并行性,能够显著提升复杂系统模拟的效率,缩短模拟时间。
量子傅里叶变换(Quantum Fourier Transform, QFT) 是量子计算中的基础算法之一,其在频域分析中的应用极为广泛。QFT 的时间复杂度为 O ( ( log N ) 2 ) O((\log N)^2) O((logN)2),相比于经典傅里叶变换的 O ( N log N ) O(N \log N) O(NlogN) 有显著的加速效果。在复杂系统的周期性分析和信号处理过程中,QFT 能够快速提取系统的频谱信息,提升模拟的精确度。
量子优化算法,如量子退火(Quantum Annealing)和变分量子算法(Variational Quantum Algorithms),在优化复杂系统的状态和参数方面表现出色。这些算法能够在庞大的搜索空间中迅速找到近似最优解。例如,量子蒙特卡洛方法(Quantum Monte Carlo)在大气模拟和材料科学中的应用,利用量子并行性加速随机采样过程,突破了经典方法在高维空间中的计算瓶颈。具体来说,量子蒙特卡洛方法通过量子叠加态同时进行多次随机采样,显著提高了模拟的效率和精度。
公式推导与解释:
在经典蒙特卡洛方法中,计算某一物理量的期望值通常表示为:
⟨ O ⟩ = 1 N ∑ i = 1 N O ( x i ) \langle O \rangle = \frac{1}{N} \sum_{i=1}^{N} O(x_i) ⟨O⟩=N1i=1∑NO(xi)
其中, O ( x i ) O(x_i) O(xi) 是观测量, x i x_i xi 是采样点, N N N 是采样次数。经典方法的收敛速度与 N N N 成正比,而量子蒙特卡洛方法通过量子叠加态实现多点并行采样,理论上可以将收敛速度提升到 O ( N ) O(\sqrt{N}) O(N),大幅缩短计算时间。
综上所述,量子算法在复杂系统模拟中的应用,不仅提升了计算效率,还拓展了模拟的规模和精度,为深入理解复杂系统的内在机制提供了新的途径。
6.2.2 量子机器学习与复杂系统分析
量子机器学习(Quantum Machine Learning, QML)将量子计算与机器学习相结合,旨在利用量子计算的优势提升机器学习算法在处理复杂系统数据时的性能。复杂系统的数据通常具有高维度、非线性和动态变化等特性,传统机器学习算法在这些数据上的表现有限,而QML则能够有效应对这些挑战。
量子支持向量机(Quantum Support Vector Machine, QSVM) 和 量子神经网络(Quantum Neural Networks, QNN) 是QML中的代表性模型。QSVM利用量子计算在高维特征空间中的快速运算能力,提升了支持向量机在大规模数据集上的分类性能。QNN则通过量子态的表示和量子门的操作,实现了模拟经典神经网络的深度学习模型,在图像识别、数据分类等任务中展现出强大的能力。
应用实例:
在金融市场分析中,量子机器学习可以通过处理更大规模和更高维度的数据集,识别市场中的潜在模式和异常行为。例如,利用QSVM对股票价格数据进行分类,可以更准确地预测市场趋势;而QNN则可以通过学习历史交易数据,构建更为精确的风险预测模型,从而提升投资决策的科学性和准确性。
公式推导与解释:
以QSVM为例,经典支持向量机的目标是找到一个最优超平面,使得不同类别的数据点之间的间隔最大化。其优化问题可以表述为:
min w , b 1 2 ∥ w ∥ 2 subject to y i ( w ⋅ x i + b ) ≥ 1 , ∀ i \min_{\mathbf{w}, b} \frac{1}{2} \|\mathbf{w}\|^2 \quad \text{subject to} \quad y_i (\mathbf{w} \cdot \mathbf{x}_i + b) \geq 1, \quad \forall i w,bmin21∥w∥2subject toyi(w⋅xi+b)≥1,∀i
在量子支持向量机中,通过量子态表示数据点 x i \mathbf{x}_i xi,并利用量子叠加和量子并行性提升内积计算的速度,从而加速优化过程。具体来说,利用量子线性代数子程序,QSVM 能够在指数级别的加速下解决支持向量机的优化问题,显著提升分类效率。
综上所述,量子机器学习在复杂系统分析中的应用,不仅提升了数据处理和模式识别的效率,还为复杂系统中的预测和决策提供了更为精准的工具。
6.2.3 量子计算的未来挑战与前景
虽然量子计算在复杂系统研究中展现出了巨大的潜力,但其发展仍面临诸多挑战,这些挑战主要集中在以下几个方面:
量子比特的稳定性:当前量子计算机所使用的量子比特在运行过程中容易受到外界环境干扰,导致量子态的退相干。量子比特的稳定性直接影响到量子计算的可靠性和准确性。解决这一问题需要在量子硬件设计和材料科学方面进行持续的研发。
量子纠错技术:量子纠错是确保量子计算准确无误的重要手段。目前,量子纠错算法尚未完全成熟,实现高效的量子纠错需要复杂的编码和大量的额外量子比特,这在资源有限的情况下尤为困难。
大规模量子系统的实际应用:尽管量子计算在理论上具备巨大的计算能力,但将其应用于实际的大规模复杂系统模拟和优化中,仍需克服量子计算机规模扩展和算法优化等方面的瓶颈。此外,实际应用中还需要开发更多适合量子计算的算法和工具,以充分发挥其优势。
硬件技术的进步:量子计算的进一步发展依赖于硬件技术的持续进步,包括量子比特的制备、操控和测量技术。随着超导量子计算、离子阱量子计算等技术的不断成熟,量子计算的实用化前景将更加明朗。
算法的优化与创新:当前许多量子算法仍处于理论阶段,如何将这些算法有效地应用于实际复杂系统的模拟与优化中,需要更多的算法创新和优化。研究者需要结合具体的应用场景,设计出高效且实用的量子算法,以充分利用量子计算的优势。
前景展望:
未来,随着硬件技术的不断进步和量子算法的不断优化,量子计算有望在复杂系统的模拟与优化中发挥更加重要的作用,推动相关领域的突破性进展。例如,在气候模型预测、材料设计、医疗数据分析等领域,量子计算将提供更为精确和高效的解决方案。此外,量子计算还将与人工智能、物联网等新兴技术深度融合,催生出更多创新性的应用,进一步推动复杂系统研究的发展。
综上所述,尽管量子计算在复杂系统研究中面临诸多挑战,但其巨大的潜力和广阔的应用前景,使其成为未来科技发展的重要方向。通过持续的科研投入和技术突破,量子计算有望在复杂系统的模拟、优化和分析中发挥关键性的作用,推动科学技术和社会经济的全面进步。
6.3 复杂系统的控制与优化
复杂系统的控制与优化在确保系统的稳定性与高效运行中扮演着至关重要的角色。随着系统规模的不断扩大和内部结构的日益复杂,传统的集中式控制方法逐渐暴露出其局限性,难以应对动态变化和多样化的需求。因此,新的控制理论和优化算法应运而生,以适应复杂系统的发展需求。
6.3.1 分布式控制策略
分布式控制策略通过将控制任务分散到系统的各个子部分,实现对复杂系统的全面管理。这种策略不仅提高了系统的鲁棒性和可扩展性,还能更好地适应系统结构的动态变化。相比于集中式控制,分布式控制减少了单点故障的风险,提升了系统的整体抗干扰能力。
数学模型与理论基础:
分布式控制通常基于网络控制理论,其中系统被视为一个由多个子系统组成的网络。假设一个复杂系统由 N N N 个子系统组成,每个子系统 i i i 的状态由向量 x i ( t ) x_i(t) xi(t) 描述,其动态行为可以表示为:
x ˙ i ( t ) = f i ( x i ( t ) , u i ( t ) ) + ∑ j ∈ N i g i j ( x i ( t ) , x j ( t ) ) ) \dot{x}_i(t) = f_i(x_i(t), u_i(t)) + \sum_{j \in \mathcal{N}_i} g_{ij}(x_i(t), x_j(t))) x˙i(t)=fi(xi(t),ui(t))+j∈Ni∑gij(xi(t),xj(t)))
其中:
- u i ( t ) u_i(t) ui(t) 是子系统 i i i 的控制输入,
- N i \mathcal{N}_i Ni 是与子系统 i i i 相连接的邻居子系统集合,
- f i f_i fi 和 g i j g_{ij} gij 分别描述了子系统内部和子系统之间的动态关系。
为了实现分布式控制,通常采用局部信息和邻居之间的通信,通过设计局部控制律 u i ( t ) u_i(t) ui(t) 来达到全局性能的优化。常见的方法包括分布式鲁棒控制、分布式自适应控制以及分布式优化算法。
应用案例:智能电网中的分布式控制:
在智能电网中,分布式控制策略被广泛应用于实时调整各个能源节点的输出,优化整体能源利用效率。例如,考虑一个由多个分布式能源资源(如太阳能、风能等)组成的智能电网系统。每个能源节点的输出功率 P i ( t ) P_i(t) Pi(t) 可以表示为:
P i ( t ) = P i max ⋅ α i ( t ) P_i(t) = P_i^{\text{max}} \cdot \alpha_i(t) Pi(t)=Pimax⋅αi(t)
其中, α i ( t ) \alpha_i(t) αi(t) 是控制参数,满足 0 ≤ α i ( t ) ≤ 1 0 \leq \alpha_i(t) \leq 1 0≤αi(t)≤1。分布式控制的目标是通过调整 α i ( t ) \alpha_i(t) αi(t) 来最小化整个电网的功率损耗,同时确保供需平衡。具体优化问题可以表述为:
min { α i ( t ) } ∑ i = 1 N ( P i ( t ) − P i desired ) 2 \min_{\{\alpha_i(t)\}} \sum_{i=1}^{N} (P_i(t) - P_i^{\text{desired}})^2 {αi(t)}mini=1∑N(Pi(t)−Pidesired)2
通过分布式优化算法,智能电网中的每个能源节点可以根据局部信息和邻居节点的反馈,独立地调整 α i ( t ) \alpha_i(t) αi(t),从而实现全局最优。
6.3.2 自适应控制与复杂系统的动态调整
自适应控制是一种能够根据系统状态和外部环境变化实时调整控制参数的方法,特别适用于复杂系统中的动态调整需求。自适应控制系统能够在不确定或变化的环境中,自动调节控制规则,以保持系统的稳定性和性能。
自适应控制的基本原理:
自适应控制系统通常由参数估计器和控制律两部分组成。参数估计器用于实时估计系统的未知参数,而控制律则根据这些估计参数调整控制输入。以自适应PID控制器为例,其控制律可以表达为:
u ( t ) = K p ( t ) e ( t ) + K i ( t ) ∫ 0 t e ( τ ) d τ + K d ( t ) d e ( t ) d t u(t) = K_p(t) e(t) + K_i(t) \int_{0}^{t} e(\tau) d\tau + K_d(t) \frac{d e(t)}{dt} u(t)=Kp(t)e(t)+Ki(t)∫0te(τ)dτ+Kd(t)dtde(t)
其中, K p ( t ) K_p(t) Kp(t)、 K i ( t ) K_i(t) Ki(t)、 K d ( t ) K_d(t) Kd(t) 分别是时间变化的比例、积分和微分增益, e ( t ) e(t) e(t) 是系统的控制误差。通过自适应算法,这些增益参数可以根据系统的实时表现进行调整,以优化控制效果。
公式推导与应用:
假设系统的动态行为可表示为:
x ˙ ( t ) = a ( t ) x ( t ) + b ( t ) u ( t ) + d ( t ) \dot{x}(t) = a(t) x(t) + b(t) u(t) + d(t) x˙(t)=a(t)x(t)+b(t)u(t)+d(t)
其中, a ( t ) a(t) a(t)、 b ( t ) b(t) b(t) 是系统参数,可能随时间变化, d ( t ) d(t) d(t) 是外部干扰。自适应控制的目标是通过调整控制输入 u ( t ) u(t) u(t),使得系统状态 x ( t ) x(t) x(t) 跟踪参考信号 r ( t ) r(t) r(t)。
采用自适应控制律,假设估计参数为 a ^ ( t ) \hat{a}(t) a^(t)、 b ^ ( t ) \hat{b}(t) b^(t),则控制输入可以设计为:
u ( t ) = 1 b ^ ( t ) ( r ˙ ( t ) − a ^ ( t ) r ( t ) + K e ( t ) ) u(t) = \frac{1}{\hat{b}(t)} \left( \dot{r}(t) - \hat{a}(t) r(t) + K e(t) \right) u(t)=b^(t)1(r˙(t)−a^(t)r(t)+Ke(t))
通过引入Lyapunov稳定性理论,可以推导出参数更新规律,以保证系统的稳定性和渐近跟踪性能。
应用实例:
在无人驾驶汽车系统中,自适应控制算法能够根据实时交通状况和道路条件调整车辆的行驶策略。例如,当车辆在雨天行驶时,路面摩擦系数 μ \mu μ 会减小,传统控制算法可能无法有效调节刹车力度。而自适应控制系统能够实时估计当前路况,调整刹车控制参数 K p K_p Kp、 K i K_i Ki、 K d K_d Kd,从而确保车辆在不同路况下的安全和稳定性。
6.3.3 优化算法在复杂系统中的应用
优化算法在复杂系统中广泛应用于资源分配、路径规划、参数调优等多个领域。这些算法通过模拟自然进化和群体行为,能够在复杂的搜索空间中找到近似最优解,提升系统的整体性能和效率。
遗传算法(Genetic Algorithm, GA):
遗传算法是一种基于自然选择和遗传机制的优化方法。其基本流程包括初始化、选择、交叉、变异和终止条件。遗传算法适用于解决高维、非凸优化问题,在复杂系统中的应用如生产流程优化、设计参数调优等。
粒子群优化(Particle Swarm Optimization, PSO):
粒子群优化模拟鸟群觅食的行为,通过粒子的位置和速度更新实现搜索最优解。PSO算法具有简单易实现、收敛速度快等优点,常用于路径规划、资源调度和网络优化等领域。
蚁群算法(Ant Colony Optimization, ACO):
蚁群算法灵感来源于蚂蚁觅食过程,通过信息素的分布和更新实现路径的优化。ACO算法在解决组合优化问题如旅行商问题、物流配送优化方面表现出色。
公式推导与案例分析:
以粒子群优化为例,假设目标函数为 f ( x ) f(\mathbf{x}) f(x),粒子的位置为 x i \mathbf{x}_i xi,速度为 v i \mathbf{v}_i vi。粒子的位置和速度更新公式为:
{ v i ( k + 1 ) = w v i ( k ) + c 1 r 1 ( p i − x i ( k ) ) + c 2 r 2 ( g − x i ( k ) ) x i ( k + 1 ) = x i ( k ) + v i ( k + 1 ) \begin{cases} \mathbf{v}_i^{(k+1)} = w \mathbf{v}_i^{(k)} + c_1 r_1 (\mathbf{p}_i - \mathbf{x}_i^{(k)}) + c_2 r_2 (\mathbf{g} - \mathbf{x}_i^{(k)}) \\ \mathbf{x}_i^{(k+1)} = \mathbf{x}_i^{(k)} + \mathbf{v}_i^{(k+1)} \end{cases} {vi(k+1)=wvi(k)+c1r1(pi−xi(k))+c2r2(g−xi(k))xi(k+1)=xi(k)+vi(k+1)
其中:
- w w w 是惯性权重,
- c 1 c_1 c1、 c 2 c_2 c2 是学习因子,
- r 1 r_1 r1、 r 2 r_2 r2 是随机数,
- p i \mathbf{p}_i pi 是粒子 i i i 的历史最佳位置,
- g \mathbf{g} g 是群体的全局最佳位置。
通过多次迭代,粒子群将逐步收敛到目标函数的最优解。
应用案例:
物流管理中的粒子群优化:在物流管理中,粒子群优化算法被用于高效规划配送路径,减少运输成本和时间。假设有 N N N 个配送站点,目标是找到一条最短路径使得每个站点仅访问一次并返回出发点。定义目标函数为路径总长度:
f ( x ) = ∑ i = 1 N d ( x i , x i + 1 ) f(\mathbf{x}) = \sum_{i=1}^{N} d(x_i, x_{i+1}) f(x)=i=1∑Nd(xi,xi+1)
其中, d ( x i , x i + 1 ) d(x_i, x_{i+1}) d(xi,xi+1) 是两个站点之间的距离。通过PSO算法,粒子群可以快速搜索路径空间,找到近似最优的配送路线,显著提升物流效率。
遗传算法在制造系统中的应用:
在制造系统中,遗传算法用于优化生产流程,提高生产效率和产品质量。假设生产流程涉及多个工序,每个工序的执行顺序和资源分配对整体效率有重大影响。定义染色体为工序的排列顺序,适应度函数为生产效率指标。通过选择、交叉和变异操作,遗传算法能够搜索最佳的工序排列,优化生产流程,减少生产周期和资源浪费。
优化算法在复杂系统中的广泛应用,不仅提升了系统的整体性能和效率,还为解决高维、非凸等复杂优化问题提供了有效的方法。未来,随着算法的不断创新和计算能力的提升,优化算法将在更多复杂系统中发挥重要作用,推动各行业的发展与进步。
6.4 复杂系统的未来发展方向
随着科学技术的迅猛发展和社会需求的不断变化,复杂系统研究的未来将朝着更深层次的理论探索和更广泛的跨学科应用方向迈进。这一领域将紧密结合最新的科技进展和实际问题,推动理论与实践的深度融合。以下是几个值得重点关注的未来发展方向:
6.4.1 多学科融合与综合研究
复杂系统本身具有高度的跨学科特性,未来的研究将更加注重多学科的融合,综合运用自然科学、社会科学、工程学等领域的理论和方法,全面分析和解决复杂问题。多学科融合不仅能够丰富复杂系统的理论基础,还能拓展其应用范围。例如,生物信息学就是将生物学与计算机科学相结合,通过大数据与算法分析基因组信息,推动个性化医疗的发展。而金融物理学则融合了物理学的方法论与经济学的理论,利用统计物理模型分析金融市场的动态行为,预测市场趋势。这些跨学科的研究不仅提升了复杂系统理论的深度和广度,也为应对现实世界中的复杂挑战提供了更加多样化和有效的解决方案。
6.4.2 大数据与复杂系统的协同发展
随着大数据技术的成熟和普及,复杂系统研究将更加依赖于海量数据的收集和分析。大数据技术不仅能够提供丰富的系统行为数据,还能够通过先进的数据处理和分析方法,揭示复杂系统中潜在的规律和模式。未来,基于大数据的复杂系统分析将实现更高的精度和更广的适用性。例如,在气候变化研究中,通过分析海量的气象数据和环境参数,可以更准确地预测气候趋势和极端天气事件的发生频率。此外,在智慧城市建设中,大数据技术可以整合交通、能源、环境等多个领域的数据,优化城市资源的配置,提高城市管理的效率和可持续性。大数据与复杂系统的协同发展,将推动个性化服务、精准预测和智能决策的发展,为各行各业带来深远的变革。
6.4.3 可持续性与复杂系统的关系
在全球环境变化和资源有限的背景下,可持续性成为复杂系统研究的重要议题。复杂系统理论提供了理解和优化资源利用、环境保护以及社会发展的强大工具。未来的研究将致力于通过复杂系统理论实现资源的高效利用、环境的可持续保护以及社会的稳健发展。例如,构建可持续发展的城市系统模型,能够模拟城市各个要素之间的相互作用,优化能源使用和交通管理,实现绿色城市的目标。此外,在农业系统中,复杂系统方法可以用于优化作物种植、灌溉和土壤管理,提高农业生产的可持续性和生态友好性。通过综合考虑生态、经济和社会等多方面因素,复杂系统理论将为实现全球可持续发展目标提供科学依据和决策支持。
6.4.4 人机协同与复杂系统的智能化
随着人工智能技术的飞速进步,人机协同将成为复杂系统研究的新趋势。人机协同不仅能够充分发挥人类智慧与机器计算能力的互补优势,还能够通过智能化手段提升复杂系统的自主决策能力和适应性。例如,在智能制造系统中,人工智能可以实时监控生产线的运行状态,自动调整生产参数,提高生产效率和产品质量。同时,机器人与人类工人的协同工作,可以实现更加灵活和高效的生产模式。在智慧医疗领域,人工智能辅助诊断系统可以帮助医生快速准确地分析病情,制定个性化的治疗方案。未来,智能化的复杂系统将具备更强的自主决策能力,能够在动态环境中实现自我优化和自主适应,推动各行业向智能化、自动化方向发展。
6.4.5 伦理与复杂系统的社会影响
复杂系统技术的发展不仅带来了技术进步和效率提升,也引发了诸多伦理和社会问题。隐私保护、算法公平性以及自动化对就业的影响等问题,亟需在复杂系统研究中得到深入探讨和解决。未来的研究将更加关注这些伦理和社会影响,致力于建立负责任的技术应用框架,确保复杂系统技术的可持续发展和社会福祉的提升。例如,在大数据分析和人工智能应用中,如何保障个人隐私,避免数据滥用,是亟待解决的重要问题。同时,算法公平性问题需要通过透明的算法设计和公正的评估机制来加以应对,确保复杂系统在决策过程中不产生偏见和歧视。此外,随着自动化技术的普及,如何应对潜在的就业结构变化,提供再教育和职业转型支持,是社会需要共同面对的挑战。通过在复杂系统研究中融入伦理考量,可以推动技术发展与社会进步的和谐共生,实现科技与人文的有机结合。
复杂系统的前沿研究涵盖了人工智能、量子计算、控制与优化等多个领域,并在多学科融合、大数据应用、可持续发展、人机协同和伦理社会等方面展现出广阔的发展前景。通过不断探索和创新,复杂系统理论将为应对全球性挑战提供更加有效的解决方案,推动科学技术和社会发展的进步。
6.5 本章小结
本章深入探讨了复杂系统在生态系统、经济与金融系统、社会网络以及生物系统中的具体应用,通过多个案例分析展示了复杂系统理论在实际问题解决中的重要作用。此外,章节还展望了复杂系统研究的未来发展方向,包括多学科融合、大数据应用、可持续性、智能化人机协同以及伦理与社会影响等方面。通过这些探索,可以看出复杂系统理论不仅在提升系统性能和效率方面具有巨大潜力,也在推动各领域的创新和可持续发展中发挥着关键作用。
说明
本文是作者学习复杂系统理论、模型与应用方面的学习笔记,部分内容由AI辅助创造,仅供参考,不对文章内容的准确性负责。
相关文章:
)
解密复杂系统:理论、模型与案例(3)
第五章:复杂系统的应用案例 复杂系统理论在多个领域中展现出其独特的分析能力和广泛的应用前景。本章将详细探讨复杂系统在生态系统、经济与金融系统、社会网络以及生物系统中的具体应用,通过丰富的案例分析,揭示复杂系统理论在实际问题解决…...

<项目代码>YOLOv8 番茄识别<目标检测>
YOLOv8是一种单阶段(one-stage)检测算法,它将目标检测问题转化为一个回归问题,能够在一次前向传播过程中同时完成目标的分类和定位任务。相较于两阶段检测算法(如Faster R-CNN),YOLOv8具有更高的…...

docker安装到D盘
双击安装docker默认是安装在c盘,并且安装时我们没法选择位置,如果我们要安装在其他盘可以通过命令行安装 1、下载docker https://docs.docker.com/desktop/setup/install/windows-install/ Docker Desktop 可以使用 WSL 和 Hyper-V任意一种架构…...

【Java语言】String类
在C语言中字符串用字符可以表示,可在Java中有单独的类来表示字符串(就是String),现在我来介绍介绍String类。 字符串构造 一般字符串都是直接赋值构造的,像这样: 还可以这样构造: 图更能直观的…...

【go从零单排】Directories、Temporary Files and Directories目录和临时目录、临时文件
🌈Don’t worry , just coding! 内耗与overthinking只会削弱你的精力,虚度你的光阴,每天迈出一小步,回头时发现已经走了很远。 📗概念 在 Go 语言中,path/filepath 包提供了一组用于处理文件路径的函数&am…...

Diff 算法的误判
起源: for循环的:key的值使用index绑定,当循环列表条目变化更新,导致虚拟 DOM Diff 算法认为原有项被替换,而不是更新。 // vue2写法 错误例子 <template><div><button click"addItem">添加项目<…...

odoo 17 后端路由接口认证自定义
odoo 17 后端路由接口认证自定义 在接口中, 我们都知道有3中常用的认证方式 user 用户级认证public 访问时赋予公共用户none 不做任何用户级处理 一般不做数据库重要数据校验, 仅做访问处理 以上是源码提供的三种方式 接下来我们自定义一个认证方式 首先找到的这认证是在…...

租赁回收系统小程序
1.需求分析:首先,需要明确系统的功能和特点。这包括确定租赁回收的物品类型、用户群体、业务流程等。通过需求分析,可以确保系统能够满足市场和用户的需求。 2.系统设计:在需求分析的基础上,进行系统的整体设计。这包…...

SQL 注入详解:原理、危害与防范措施
文章目录 一、什么是SQL注入?二、SQL注入的工作原理三、SQL注入的危害1. 数据泄露2. 数据篡改3. 拒绝服务4. 权限提升 四、SQL注入的类型1. 基于错误的信息泄露2. 联合查询注入3. 盲注(1). 基于布尔响应的盲注(2). 基于时间延迟的盲注 4. 基于带外的注入 五、防范SQ…...

如何用Java爬虫“采集”商品订单详情的编程旅程
在这个数据驱动的世界里,如果你不是数据,那么你一定是在收集数据。就像蜜蜂采集花粉一样,我们程序员也需要采集数据,以便分析、优化和做出明智的决策。今天,我们就来聊聊如何使用Java编写一个爬虫,这个爬虫…...

《FreeRTOS任务基础知识篇》
FreeRTOS任务基础知识 1. 什么是多任务系统?2. FreeRTOS任务3. 任务状态3.1 运行态3.2 就绪态3.3 阻塞态3.4 挂起态 4. 任务优先级5. 任务的实现6. 任务控制块7. 任务堆栈 FreeRTOS的核心是任务管理,以下介绍FreeRTOS任务的一些基础知识。 1. 什么是多任…...

前端面试笔试(二)
目录 一、数据结构算法等综合篇 1.HTTP/2、ETag有关 二、代码输出篇 1.new URL,url中的hostname,pathname,href 扩展说一下url的组成部分和属性 URL的组成部分 urlInfo 对象的属性 2.一个递归的输出例子 3.数组去重的不普通方法1 4.数…...

基于Python 和 pyecharts 制作招聘数据可视化分析大屏
在本教程中,我们将展示如何使用 Python 和 pyecharts 库,通过对招聘数据的分析,制作一个交互式的招聘数据分析大屏。此大屏将通过不同类型的图表(如柱状图、饼图、词云图等)展示招聘行业、职位要求、薪资分布等信息。 …...

探索光耦:晶体管光耦——智能家居的隐形桥梁,让未来生活更智能
在这个日新月异的科技时代,智能家居正以前所未有的速度融入我们的日常生活,从智能灯光到温控系统,从安防监控到语音助手,每一处细节都透露着科技的温度与智慧。而在这场智能化浪潮中,一个看似不起眼却至关重要的组件—…...

三、模板与配置(上)
三、模板与配置 1、WXML模板语法-数据、属性绑定 讲解: 1-1、数据绑定的基本原则 在data中定义数据 Page({data: {//这里是你需要定义的数据} })在WXML中使用数据 {{ 你定义的数据 }}1-2、在data中定义页面的数据 在页面对应的.js文件中,把数据定…...

基于SpringBoot和Vue的公司文档管理系统设计与开发(源码+定制+开发)
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...

Java21 Switch最全使用说明
Java21 Switch最全使用说明 Java 21 对 switch 语句进行了重大的改进和增强,使其变得更加灵活和强大。本文将详细介绍 Java 21 中 switch 语句的各种用法,包括基本语法、新特性、高级用法和最佳实践。 1. 基本语法 1.1 传统的 switch 语句 传统的 sw…...

普通电脑上安装属于自己的Llama 3 大模型和对话客户端
#大模型下载地址:# Llama3 因为Hugging Face官网正常无法访问,因此推荐国内镜像进行下载: 官网地址:https://huggingface.co 国内镜像:https://hf-mirror.com GGUF 模型文件名称接受,如上述列表中&…...

微信小程序原生 canvas画布截取视频帧保存为图片并进行裁剪
html页面: 视频尺寸过大会画布会撑开屏幕,要下滑 尺寸和视频链接是从上个页面点击传过来的,可自行定义 <canvas id"cvs1" type"2d" style"width: {{videoWidth}}px;height: {{videoHeight}}px;"><…...
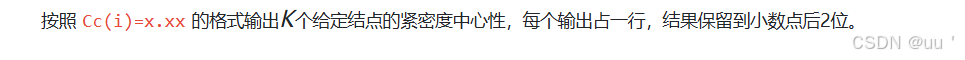
社交网络图中结点的“重要性”计算
题目描述 输入 输出 输入样例1 9 14 1 2 1 3 1 4 2 3 3 4 4 5 4 6 5 6 5 7 5 8 6 7 6 8 7 8 7 9 3 3 4 9 输出样例1 Cc(3)0.47 Cc(4)0.62 Cc(9)0.35 AC代码 #include <iostream> #include <vector> #include <queue> #include <iomanip>using na…...
)
别再手动标注了!用MakeSense一键导入YOLO标签,效率翻倍(附完整流程)
别再手动标注了!用MakeSense一键导入YOLO标签,效率翻倍(附完整流程) 在计算机视觉领域,目标检测(Object Detection)项目的效率瓶颈往往出现在数据标注环节。传统工作流中,开发者需要…...
-5月20日-第三题- 敏感实体动态遮蔽掩码】(题目+思路+JavaC++Python解析+在线测试))
【2026年华为暑期实习(AI)-5月20日-第三题- 敏感实体动态遮蔽掩码】(题目+思路+JavaC++Python解析+在线测试)
题目内容 为了防止大语言模型记忆并泄露输入上下文的敏感数据,安全框架会对输入的长文本进行预扫描,匹配预设的敏感词库(如 API_KEYAPI\_KEYAPI_KEY、身份证号码等)。...
零基础入门全攻略:原理、架构、手搓代码与实战落地)
Python+AI智能体(Agent)零基础入门全攻略:原理、架构、手搓代码与实战落地
PythonAI智能体(Agent)零基础入门全攻略:原理、架构、手搓代码与实战落地 文章目录: 【前言】 一、前言:为什么现在必须学PythonAI Agent智能体二、核心概念:彻底搞懂什么是AI Agent智能体 2.1 官方工程定义2.2 普通大模型LLM V…...

Perplexity语言学习资源实战手册:7天掌握高效外语输入+输出闭环的3大核心技巧
更多请点击: https://intelliparadigm.com 第一章:Perplexity语言学习资源的核心定位与适用场景 Perplexity 作为一款以深度推理与实时信息整合见长的AI协作工具,其语言学习资源并非传统词典或语法教程的简单复刻,而是聚焦于**真…...

以太网口模块PCB设计全解析:从信号完整性到EMC的实战指南
1. 项目概述:为什么以太网口模块的PCB设计值得深究?干了这么多年硬件设计,画过的板子不计其数,但每次遇到带以太网口的项目,心里还是会多一份谨慎。这玩意儿看着简单,RJ45插座加个变压器,再连到…...

基于ES32F0101的无传感器方波控制BLDC驱动方案设计与实践
1. 项目概述:从家庭草坪维护痛点出发家里有块小草坪的朋友,估计都经历过手动修剪的“痛苦”。蹲着、弯着,用剪刀或者手动推草机,折腾半天不仅腰酸背痛,剪出来的草坪还跟狗啃似的,高高低低,毫无美…...

CANN/asnumpy-docs 架构设计
Architecture 【免费下载链接】asnumpy-docs 项目地址: https://gitcode.com/cann/asnumpy-docs This document describes the internal architecture of AsNumpy, including the three-layer design, the core NPUArray data structure, the API module layout, and t…...

3分钟掌握OBS智能跟拍:告别手动调焦的直播神器
3分钟掌握OBS智能跟拍:告别手动调焦的直播神器 【免费下载链接】obs-face-tracker Face tracking plugin for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-face-tracker 您是否曾因直播时频繁调整镜头位置而分心?是否希望有一个…...

WPF-Control核心架构思想
WPF-Control 项目架构详解 一、核心架构思想 这个项目的架构可以用一句话概括:控件负责显示,服务负责能力,模块负责组合,主题负责外观,ApplicationBase 负责生命周期,IOC 负责连接所有对象。这是一种典型的…...

Word怎么转PDF?2026年各类场景转换方法对比指南
Word文档转换成PDF格式已成为办公日常的标配需求。无论是制作正式报告、投递简历、还是与他人共享文件,PDF格式都因其兼容性强、排版稳定的特点成为首选。本文整理了2026年最实用的Word转PDF官方方法和各类转换工具,帮你快速找到适合自己的转换方案。Wor…...