【人工智能】text2vec-large-chinese模型搭建本地知识库
本demo使用 text2vec-large-chinese 模型进行文本处理,然后再过 bge-reranker-v2-m3进行增强
1. 对文本进行向量处理,并保存只至本地
from sentence_transformers import SentenceTransformer
import torch
import numpy as np
import faiss
import os
import pickle
import fitz # PyMuPDF
import redevice = torch.device("cuda")
# 加载模型并移动到指定设备
model = SentenceTransformer('/home/sky/model_data/text2vec-large-chinese').to(device)def read_txt(file_path):with open(file_path, 'r', encoding='utf-8') as file:return file.read()def read_pdf(file_path):document = fitz.open(file_path)text = ""for page_num in range(len(document)):page = document.load_page(page_num)text += page.get_text()return textdef preprocess_text(text):# 去除多余的空格和换行符text = re.sub(r'\s+', ' ', text)# 去除特殊字符text = re.sub(r'[^\w\s]', '', text)return text.strip()# 对文本进行分块
def split_into_chunks(text, max_chunk_size=100):# 这里我们简单地以固定长度分块,实际应用中可以根据语义进行更智能的分割words = text.split()chunks = [' '.join(words[i:i + max_chunk_size]) for i in range(0, len(words), max_chunk_size)]return chunks# 读取文档内容
def read_document(file_path):if file_path.endswith('.txt'):return read_txt(file_path)elif file_path.endswith('.pdf'):return read_pdf(file_path)else:raise ValueError("Unsupported file type")# 生成向量
def generate_embeddings(chunks, model, device):embeddings = model.encode(chunks, convert_to_tensor=True, device=device).cpu().numpy()return chunks, embeddings# 保存向量为FAISS格式
def save_embeddings_faiss(chunks, embeddings, output_file):# 创建FAISS索引dimension = embeddings.shape[1]index = faiss.IndexFlatL2(dimension) # 使用L2距离index.add(embeddings)# 保存FAISS索引faiss.write_index(index, output_file + '.index')# 保存句子列表with open(output_file + '.pkl', 'wb') as f:pickle.dump(chunks, f)# 主函数
def build_knowledge_base(file_path, output_file):# 读取文档内容text = read_document(file_path)# 预处理文本text = preprocess_text(text)# 将文本分割成块chunks = split_into_chunks(text)# 生成向量chunks, embeddings = generate_embeddings(chunks, model, device)# 保存向量为FAISS格式save_embeddings_faiss(chunks, embeddings, output_file)print(f"Embeddings and FAISS index saved to {output_file}.index and {output_file}.pkl")# 使用示例
file_path = '/home/sky/model_data/code/pdf_dir/st.txt' # 或者 'path/to/your/document.txt'
output_file = '/home/sky/model_data/code/pdf_dir/xldb/textfaiss_new_index'
build_knowledge_base(file_path, output_file)2. 普通相似度匹配
import faiss
import pickle
import numpy as np
from sentence_transformers import SentenceTransformer
import torch# 检查是否有可用的GPU
device = "cuda"# 加载模型并移动到指定设备
model = SentenceTransformer('/home/sky/model_data/text2vec-large-chinese').to(device)# 加载FAISS索引
index = faiss.read_index('/home/sky/model_data/code/pdf_dir/xldb/textfaiss_index.index')# 加载句子列表
with open('/home/sky/model_data/code/pdf_dir/xldb/textfaiss_index.pkl', 'rb') as f:sentences = pickle.load(f)# 定义查询函数
def search_faiss(query, sentences, index, model, top_n=5):# 生成查询向量query_embedding = model.encode([query], convert_to_tensor=True, device=device).cpu().numpy()# 在FAISS索引中搜索D, I = index.search(query_embedding, top_n)# 返回结果results = []for i, distance in zip(I[0], D[0]):# 1 - L2距离近似于余弦相似度similarity = 1 - distanceresults.append((sentences[i], similarity))return results# 查询示例
query = '今天天气不错。'
results = search_faiss(query, sentences, index, model, top_n=5)# 打印结果
for sentence, score in results:print(f"句子: {sentence},相似度: {score:.4f}")3. 使用rerank增强 ,rerank模型:bge-reranker-v2-m3
import faiss
import pickle
import numpy as np
from sentence_transformers import SentenceTransformer, CrossEncoder
import torch# 检查是否有可用的GPU
device = "cuda"# 加载模型并移动到指定设备
model = SentenceTransformer('/home/sky/model_data/text2vec-large-chinese').to(device)# 加载FAISS索引
index = faiss.read_index('/home/sky/model_data/code/pdf_dir/xldb/textfaiss_index.index')# 加载句子列表
with open('/home/sky/model_data/code/pdf_dir/xldb/textfaiss_index.pkl', 'rb') as f:sentences = pickle.load(f)# 加载re-ranking模型
reranker = CrossEncoder('/home/sky/model_data/bge-reranker-v2-m3', device=device)# 定义查询函数
def search_faiss(query, sentences, index, model, reranker, top_n=5, rerank_top_n=5):# 生成查询向量query_embedding = model.encode([query], convert_to_tensor=True, device=device).cpu().numpy()# 在FAISS索引中搜索D, I = index.search(query_embedding, rerank_top_n)# 获取初始候选结果initial_results = [(sentences[i], 1 - d) for i, d in zip(I[0], D[0])]# 准备re-ranking的输入rerank_inputs = [(query, sentence) for sentence, _ in initial_results]# 使用re-ranking模型进行重新评分rerank_scores = reranker.predict(rerank_inputs, batch_size=8)# 合并初始分数和re-ranking分数final_results = [(sentence, rerank_score) for (sentence, _), rerank_score in zip(initial_results, rerank_scores)]# 按re-ranking分数排序并取前top_n个结果final_results.sort(key=lambda x: x[1], reverse=True)return final_results[:top_n]# 查询示例
query = '今天天气不错。'
results = search_faiss(query, sentences, index, model, reranker, top_n=5)# 打印结果
for sentence, score in results:print(f"句子: {sentence},相似度: {score:.4f}")相关文章:

【人工智能】text2vec-large-chinese模型搭建本地知识库
本demo使用 text2vec-large-chinese 模型进行文本处理,然后再过 bge-reranker-v2-m3进行增强 1. 对文本进行向量处理,并保存只至本地 from sentence_transformers import SentenceTransformer import torch import numpy as np import faiss import os …...

前端入门一之ES6--递归、浅拷贝与深拷贝、正则表达式、es6、解构赋值、箭头函数、剩余参数、String、Set
前言 JS是前端三件套之一,也是核心,本人将会更新JS基础、JS对象、DOM、BOM、ES6等知识点,这篇是ES6;这篇文章是本人大一学习前端的笔记;欢迎点赞 收藏 关注,本人将会持续更新。 文章目录 10、递归10.1、阶层案例10.…...

DevOps工程技术价值流:加速业务价值流的落地实践与深度赋能
DevOps的兴起,得益于敏捷软件开发的普及与IT基础设施代码化管理的革新。敏捷宣言虽已解决了研发流程中的诸多挑战,但代码开发仅是漫长价值链的一环,开发前后的诸多问题仍亟待解决。与此同时,虚拟化和云计算技术的飞跃,…...

IP数据云 识别和分析tor、proxy等各类型代理
在网络上使用代理(tor、proxy、relay等)进行访问的目的是为了规避网络的限制、隐藏真实身份或进行其他的不正当行为。 对代理进行识别和分析可以防止恶意攻击、监控和防御僵尸网络和提高防火墙效率等,同时也可以对用户行为进行分析ÿ…...

vue2 自动化部署 shell 脚本
需求场景:在云平台中进行开发时,由于无法连接外网,在部署前端项目时,是通过本地打包再上传到服务器的方式进行部署的。基于这种部署场景,通过 shell 脚本进行部署流程优化,具体如下: 1、服务器…...

服务器数据恢复——Ext4文件系统使用fsck后mount不上的数据恢复案例
关于Ext4文件系统的几个概念: 块组:Ext4文件系统的全部空间被划分为若干个块组,每个块组结构基本上相同。 块组描述符表:每个块组都对应一个块组描述符,这些块组描述符统一放在文件系统的前部,称为块组描述…...

CTF攻防世界小白刷题自学笔记14
fileclude,难度:1,方向:Web 题目来源:CTF 题目描述:好多file呀! 给一下题目链接:攻防世界Web方向新手模式第17题。 打开一看,这熟悉的味道,跟上一篇文章基本一摸一样的ÿ…...

家政服务小程序,家政行业数字化发展下的优势
今年以来,家政市场需求持续增长,市场规模达到了万亿级别,家政服务行业成为了热门行业之一! 家政服务种类目前逐渐呈现了多样化,月嫂、保姆、做饭保洁、收纳、维修等家政种类不断出现,满足了居民日益增长的…...

Springboot如何打包部署服务器
文章目的:java项目打包成jar包或war包, 放在服务器上去运行 一、编写打包配置 1. pom.xml 在项目中的pom.xml文件里面修改<build>...</build>的代码 >> 简单打包成Jar形式,参考示例: <build><fina…...

ubuntu将firewall-config导出为.deb文件
firewall-config ubuntu是canonial 公司维护的,用wireshark测过,开机会给他们公司发遥测(开了ufw阻塞所有连接也一样,canonial在里面把代码改了)firewall-config是fedora(爱好者维护,公益版本)自带的防火墙…...

C++算法练习-day40——617.合并二叉树
题目来源:. - 力扣(LeetCode) 题目思路分析 题目:给定两棵二叉树 root1 和 root2,请合并这两棵树,即将 root2 中的每个节点合并到 root1 中,合并的规则是如果两个节点在同一位置(即…...

2024数维杯国际赛C题【脉冲星定时噪声推断和大气时间信号的时间延迟推断的建模】思路详解
脉冲星是快速旋转的中子星,具有连续和稳定的旋转,因此被称为“宇宙的灯塔”。对脉冲星的空间观测在深空航天器导航和时间标准的维护中起着关键作用。 将脉冲星时间应用于原子时间的保持,预期可以提高本地原子钟的稳定性和可靠性,代…...

【Linux】MTD 分区
我在文章 计算机储存与分区 中讲了关于 GUID 分区和 MBR 分区,他们在 PC 上很常见,但是在嵌入式系统上,Linux 会使用 MTD 分区,至于什么是 MTD 分区,请看: NAND/MTD/UBI/UBIFS概念及使用方法 General MTD…...

MySQL(5)【数据类型 —— 字符串类型】
阅读导航 引言一、char🎯基本语法🎯使用示例 二、varchar🎯基本语法🎯使用示例 三、char 和 varchar 比较四、日期和时间类型1. 基本概念2. 使用示例 五、enum 和 set🎯基本语法 引言 之前我们聊过MySQL中的数值类型&…...

【数据搜集】初创企业获客,B端数据获取
在竞争激烈的商业世界中,初创企业面临着诸多挑战,而获取 B 端客户资源无疑是其中的关键一环。今天,就让我们深入了解一款专为解决此类难题而生的强大工具 —— 探商宝。 对于初创企业来说,B 端客户往往具有更高的价值和稳定性&am…...
)
hhdb数据库介绍(9-13)
函数与操作符 计算节点对函数的支持 此文档仅列出部分经特殊处理的函数,若需要了解所有计算节点支持的函数,请向官方获取《计算节点最新功能清单》。 函数名称支持状态是否拦截说明ABS()支持否ACOS()支持否ADDDATE()支持否ADDTIME()支持否AES_DECRYPT…...

Jmeter基础篇(24)Jmeter目录下有哪些文件夹是可以删除,且不影响使用的呢?
一、前言 Jmeter使我们日常做性能测试最常用的工具之一啦!但是我们在和其他同学协同工作的时候,偶尔也会遇到一些问题,例如我想要给别人发送一个Jmeter工具包,但这个文件包往往会很大,比较浪费流量和空间,…...

卷积、频域乘积和矩阵向量乘积三种形式之间的等价关系与转换
线性移不变系统 线性移不变系统(Linear Time-Invariant System, LTI系统)同时满足线性和时不变性两个条件。 线性:如果输入信号的加权和通过系统后,输出是这些输入信号单独通过系统后的输出的相同加权和,那么该系统就…...
 v-model 在原始Dom元素、自定义输入组件中双向绑定的底层实现原理详解)
【Vue】Vue3.0(二十二) v-model 在原始Dom元素、自定义输入组件中双向绑定的底层实现原理详解
上篇文章 【Vue】Vue3.0(二十一)Vue 3.0中 的$event使用示例 🏡作者主页:点击! 🤖Vue专栏:点击! ⏰️创作时间:2024年11月11日17点30分 文章目录 1. v-model 用于 HTML 标…...
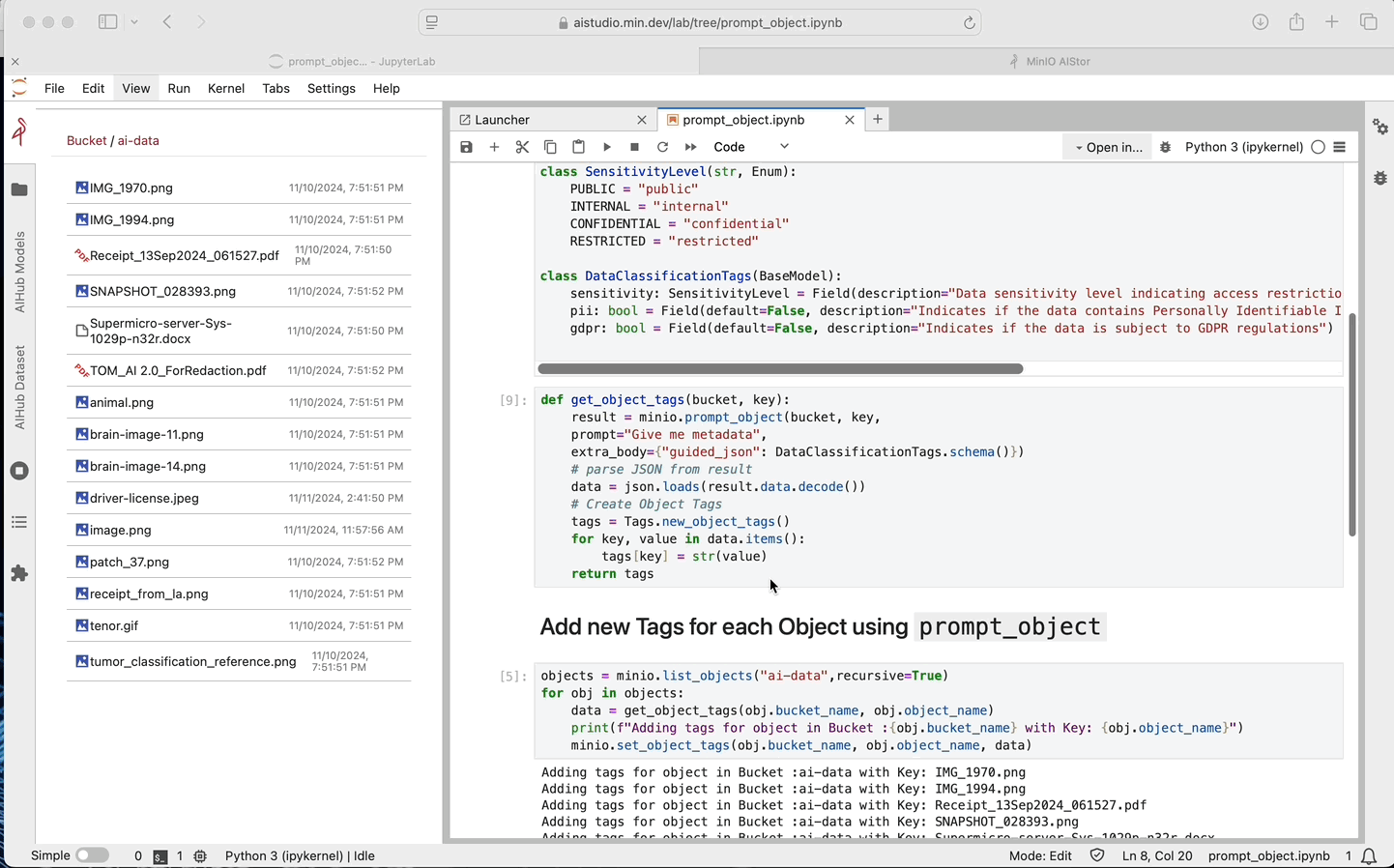
史上最强大的 S3 API?介绍 Prompt API。
迄今为止,对象存储世界已由 PUT 和 GET 的 S3 API 概念定义。然而,我们现在生活的世界需要更多。鉴于 MinIO 的 S3 部署甚至比 Amazon 还多,因此我们不得不提出下一个出色的 S3 API。 这个新 API 就是 Prompt API,它很可能成为有…...

2026 在线水印去除工具怎么选?6款实用方法对比测评
在短视频时代,去水印需求越来越普遍。无论是想要收藏喜欢的视频素材、整理图片库存,还是创作内容时需要的参考素材,高效的在线水印去除方法已经成为必需品。本文盘点了6款在线水印去除工具和方法,从处理速度、平台覆盖、易用性等维…...

Python初学者项目练习28--移除列表中的多个元素
一、练习题目 定义一个函数,该函数用于从第一个列表list1中移除所有存在于第二个列表list2中的元素 二、代码 1.初始版本 代码如下: def remove_number(list1, list2):for i in range(list1):for j in range(list2):if i j:list1.remove(j)return list1…...

从开题到定稿,okbiye 如何让本科毕业论文写作告别 “通宵焦虑”
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、本科毕业论文的 “三座大山”,正在拖垮你的毕业季 对于大多数本科生而言,毕业论文写作早已不是 “写一篇文章”…...

别再手动算镀膜了!用Ansys Zemax非序列模式,5分钟搞定二向分色分光镜仿真
5分钟极速仿真:Ansys Zemax非序列模式下二向分色分光镜的实战技巧 在光学系统设计中,二向分色分光镜的仿真往往成为效率瓶颈。传统方法需要手动计算镀膜参数、反复调试光线路径,消耗工程师大量时间。本文将揭示如何利用Ansys Zemax非序列模式…...

从MySQL到Neo4j:用你熟悉的SQL思维,快速上手CQL创建第一个知识图谱
从MySQL到Neo4j:用SQL思维快速构建知识图谱的实战指南 当你在MySQL中熟练编写JOIN查询时,是否想过这些表关系本质上就是一张网?图数据库将这种网状关系作为一等公民,而Neo4j正是这个领域的佼佼者。本文会带你用熟悉的SQL视角&…...

租房避坑|在成都,我从“凑合住”到“安心住”经历了什么
姐妹们,千万别被“凤凰大街包租”几个字骗了!我的真实租房血泪史是不是最近总刷到那种“凤凰大街包租”“拎包入住”的宣传?说实话,刚来成都那会儿,我也被这些词儿晃花了眼。想着省心省力,结果踩的坑一个接…...

大模型应用开发:小白程序员必备的收藏指南——Agent开发与算法岗界限全解析
本文探讨了在大模型应用开发、AI应用开发以及Agent开发中,开发和算法岗位的界限模糊问题。通过分析实习生的困惑、HR的挑战以及行业招聘趋势,指出Agent工程化通常需要开发与算法合作。文章还讨论了应用算法工程师是否会消失,认为虽然岗位可能…...

彻底告别iPhone过热降频!thermalmonitordDisabler让你的设备性能满血释放
彻底告别iPhone过热降频!thermalmonitordDisabler让你的设备性能满血释放 【免费下载链接】thermalmonitordDisabler A tool used to disable iOS daemons. 项目地址: https://gitcode.com/gh_mirrors/th/thermalmonitordDisabler 你是否曾经在游戏激战中突然…...

ICode竞赛Python闯关秘籍:用if else逻辑解锁三级训练场
1. ICode竞赛Python三级训练场通关指南 第一次接触ICode竞赛的Python三级训练场时,我和很多初学者一样被那些复杂的路径判断搞得晕头转向。直到我发现if else语句就像游戏中的"选择道具",整个编程过程突然变得清晰起来。ICode竞赛通过角色控制…...

TTK插件系统扩展指南:自定义Golden生成函数和输入数据生成函数的完整教程
TTK插件系统扩展指南:自定义Golden生成函数和输入数据生成函数的完整教程 【免费下载链接】ops-test-kit TTK(Ops Test Tool Kit)是CANN算子库提供的全链路、自动化、批量化算子测试框架,帮助开发者快速完成算子批量功能验证、性能…...