举例理解LSM-Tree,LSM-Tree和B+Tree的比较

写操作
write1:WAL
把操作同步到磁盘中WAL做备份(追加写、性能极高)
write2:Memtable
完成WAL后将(k,v)数据写入内存中的Memtable,Memtable的数据结构一般是跳表或者红黑树
内存内采用这种数据结构一方面支持内存内高速增删改查(时间复杂度O(logM)),另一方面可以保持有序,为写入磁盘中的SSTable打基础
write3:Immutable Memtable
Memtable存储的元素达到一定数量后,就会把它拷贝一份出来成为Immutable Memtable (不可变的Memtable)并且不能对其修改了,新增的数据都写入新的Memtable,这么做的好处是当需要将Memtable转化为Immutable Memtable时无需暂停工作,至于为什么要拷贝一个Immutable Memtable ,这主要是为了后续落盘时做准备
write4:Minor Compaction
内存中的数据不可能无线的扩张下去,需要把内存里面Immutable Memtable 定期dump到到硬盘上的SSTable level 0层中,此步骤也称为Minor Compaction
SSTable的数据结构是LSM-Tree设计的精髓,他一方面可以保持有序,一方面又能利用磁盘追加写的高性能
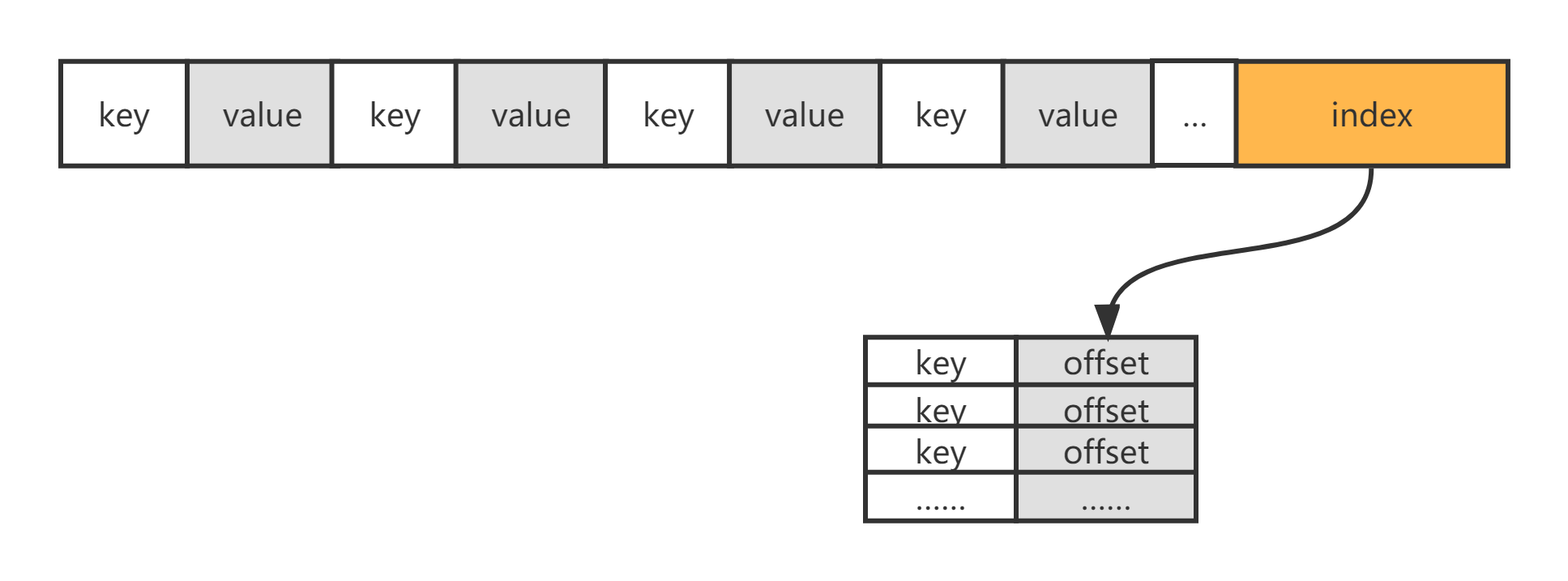
SSTable的数据结构为两部分,前半部分是key与value成对的数据连续存储,这部分数据的key是有序的,后半部分是前半部分的索引,值存储的是key所对应的offset,也是有序的,每次打开这个SSTable需要把索引加载到内存并利用二分搜索可以很快查找出要访问的key的值
dump的过程中每个Immutable Memtable会对应一个SSTable的segment且不会对多个Immutable Memtable进行合并,而是直接将Immutable Memtable中有序的跳表或者红黑树遍历并追加写入到segment,这个过程速度很快。由于不会合并level 0层中的SSTable可能会出现相同的key。
write5、write6:Major Compaction merge
当level 0中的segment越来越多,查询需要遍历的segment也就会越来越多,并且随着时间的推移,重复的key也会越来越多,在后面的步骤就需要对level 0层的segment进行合并merge
合并的过程中是吧多个有序的segment进行归并合并,所以性能不会很差,多个老的segment会合并成一个更长的同样有序的segment并设置到下一层
每一层的segment的数量和大小都会有限制,每当超出限制后,就会做合并操作
虽然定期合并可以有效的清除无效数据,缩短读取路径提升查询效率,提高磁盘利用空间。但Compaction操作是非常消耗CPU和磁盘IO的,尤其是在业务高峰期,如果发生了Major Compaction,则会降低整个系统的吞吐量,这也是一些NoSQL数据库,比如Hbase里面常常会禁用Major Compaction,并在凌晨业务低峰期进行合并的原因。
修改流程
write1:WAL
write2:找到key直接修改或新增key
write3:Immutable Memtable
write4:Minor Compaction
write5、write6…:较新的key(有序可以识别)会替代较老的key
删除流程
write1:WAL
write2:找到key设置状态为tombstone或新增key设置状态为tombstone
write3:Immutable Memtable
write4:Minor Compaction
write5、write6…:因为不确定下层是否有被删除的key,到最后一层merge时才真正删除
读操作
一、按照Memtable(内存)、Immutable Memtable(内存)、level 0 segments(磁盘)、level 1 segments(磁盘)、level 1 segments(磁盘)的顺序查询
二、每层先查新生成的segment
三、每个segment从后向前查
为什么LSM不直接顺序写入磁盘,而是需要在内存中缓冲一下?
单条写的性能没有批量写快,很多中间件比如elasticsearch、kafka、mysql都有类似的内存缓冲设计
在磁盘缓冲的另一个好处是,针对新增的数据,可以直接查询返回,能够避免一定的IO操作
LSM-Tree和B+Tree的比较
LSM-Tree的优点是支持高吞吐的写O1,这个特点在分布式系统上更为看重
针对读取普通的LSM-Tree结构,读取是On的复杂度
在使用索引或者缓存优化后的也可以达到O(logN)的复杂度。
适用于写多读少
B+tree的优点是支持高效的读(稳定的O(logN))
但是在大规模的写请求下(O(LogN)),效率会变得比较低,因为随着insert的操作,为了维护B+树结构,节点会不断的分裂和合并。操作磁盘的随机读写概率会变大,故导致性能降低。
适用于写少读多或写读平衡
log-structured merge-tree (LSM tree) 是一种被精心设计的数据结构,常用于处理大量写入的场景。通过对写入操作进行顺序写入优化实现性能提升。LSM tree 是很多数据库内部的核心数据结构,包括BigTable, Cassandra, Scylla,和 RocksDB。
SSTables
LSM tree 通过一种叫做 SSTable (Sorted Strings Table) 的格式,持久化到硬盘上。正如其名,SSTable 是一种用来存储有序的键值对的格式,其中键的组织是有序存储的。一个SSTable 会包括多个有序的子文件,被称为 segment 。 这些 segments 一旦被写入硬盘,就不可以再修改了。一个简单的SSTable 例子如下图所示:
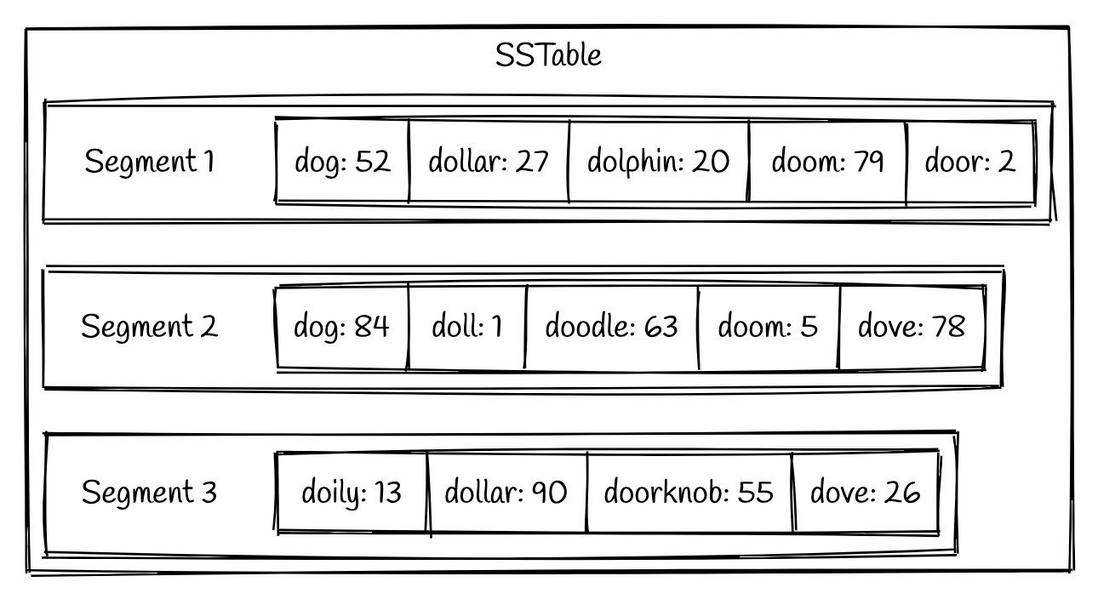
我们可以看到,在每个 segment 中的键值对都是按照键的顺序有序组织的。
写入数据
由于 LSM tree 只会进行顺序写入,所以自然而然地就会引出这样一个问题,写入的数据可能是任意顺序的,我们又如何保证数据能够保持 SSTable 要求的有序组织呢?
这就需要引入新的常驻内存 (in-memory) 数据结构: memtable_了, _memtable 的底层数据结构则有点像红黑树,当由新的写入操作则将数据插入到红黑树中。
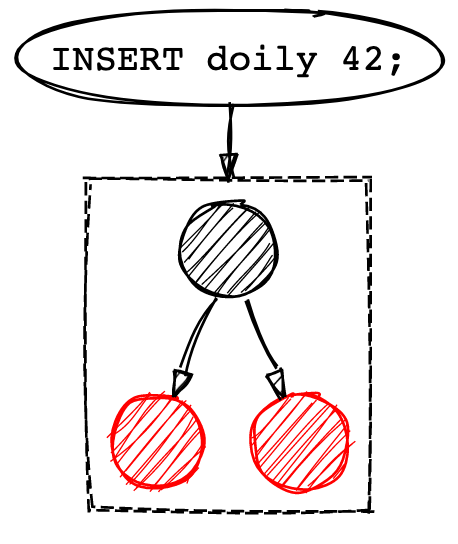
写入操作会先把数据存储到红黑树中,直至红黑树的大小达到了预先定义的大小。一旦红黑树的大小达到阈值,就会把数据整个刷到磁盘中,这个过程就可以把数据保证有序写入了。经过一层数据结构的承接,就可以保证单向顺序写入的同时,也能保证数据的有序了。
读取数据
那么我们是如何从SSTable中查找数据的呢?一种naive的方法就是遍历所有的 segments,寻找我们需要的key。从最新的 segment 到最老的 segment 一一遍历,知道找到目标key为止。显然,这种方式在寻找刚刚写入的数据是比较快的,但是文件一多就不太行了。因此也有针对这个问题的优化,稀疏索引 就是一种在内存中对数据检索进行优化的技术。
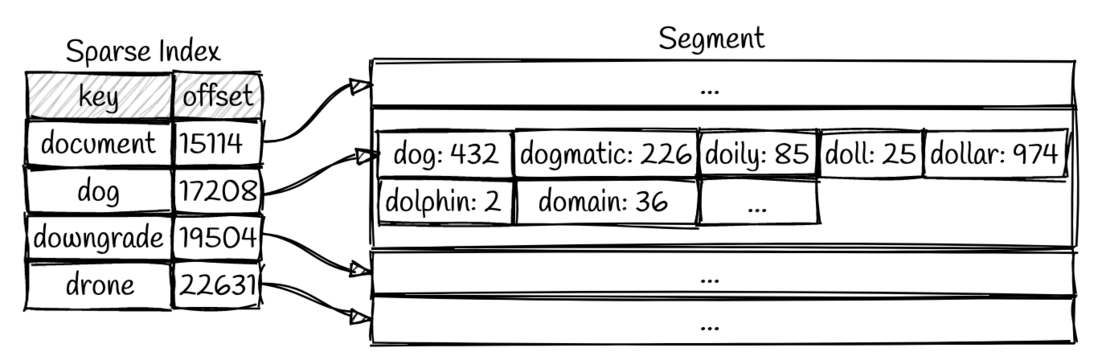
我们可以通过这个索引快速找到所需键的前面和后面的偏移量(就是最近的相邻值),这样我们就只需要扫描很小一部分的 segments 文件就可以了。以如图所示的场景举例,当我们需要搜索 dollar 这个值,我们可以通过二分查找搜索稀疏索引,可以知道 dollar 处于 dog 和 downgrade之间。因此我们只需要搜索 17208 和 19504 之间的 segment 来得到我们所需的值,如果搜索不到则可返回未命中。
译者注:稀疏索引和跳表都是为了解决快速索引的问题,根据不同设计具体选择。
上面优化在查找存在的数据其实已经不错了,但是在搜索不存在的key值的时候还是要遍历所有的 segment 才可以确定。为了解决这个问题,就需要引入 布隆过滤器 。布隆过滤器是一种以空间换时间的数据结构,能够帮助我们快速确定某个值是否不存在(如果布隆过滤器认为该值存在,也可能是实际不存在的)。我们可以在写入数据的时候同时更新布隆过滤器,来加速不存在数据的检索。
数据合并
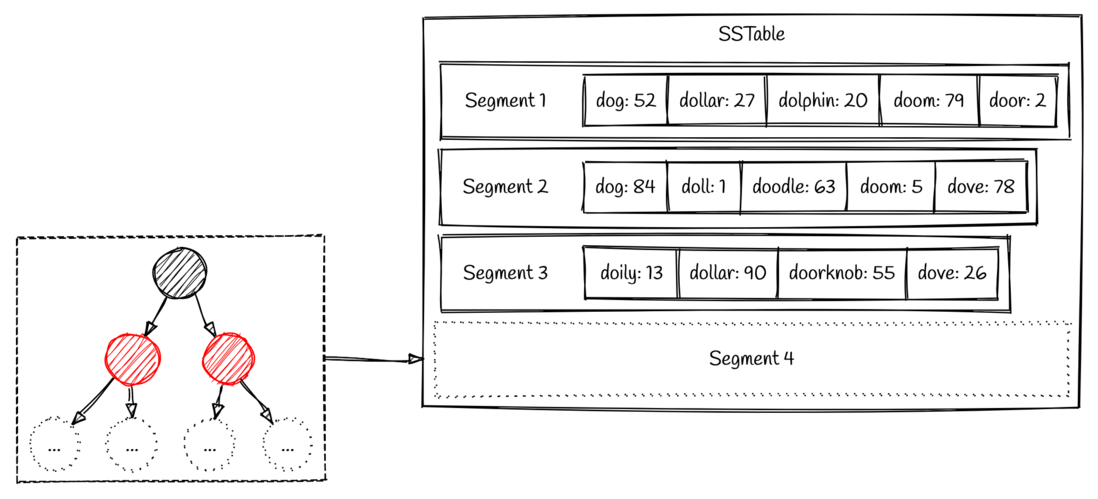
随着时间的推移,整个存储系统将会存储非常多的segment文件,所以这些文件需要进行一定的整理和合并,避免文件太多无法访问。这个文件整理的过程被称为“数据合并” (compaction)。数据合并是一个后台线程,将会持续地将老的segment 合并到一起变成新的 segment。
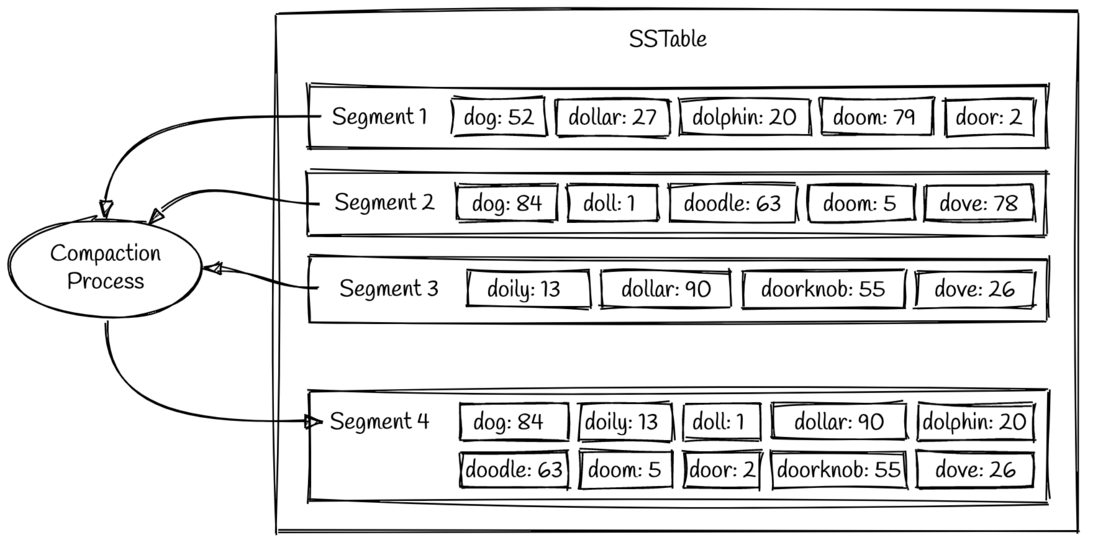
如图所示,我们可以看到 segment 1 和 segment 2 都有 key 为 dog 的两个值。合并后的新 segment 将会保留更新的值,因此会保留原有 segment 2 里面的值 84,即segment 4 中的值是 dog => 84。一旦合并过程已经完成新的 segment 写入,那么原有的老 segment 文件将会被删除。
删除数据
我们已经解释了读取数据和写入数据的过程,那么删除数据又是如何处理的呢?我们已经知道 SSTable 是不可变的,所以里面的数据当然也不能够删除。其实删除操作其实和写入数据的操作是一样的,当需要删除数据的时候,我们把一个特定的标记(我们称之为 墓碑(tombstone) )写入到这个key对应的位置,以标记为删除。
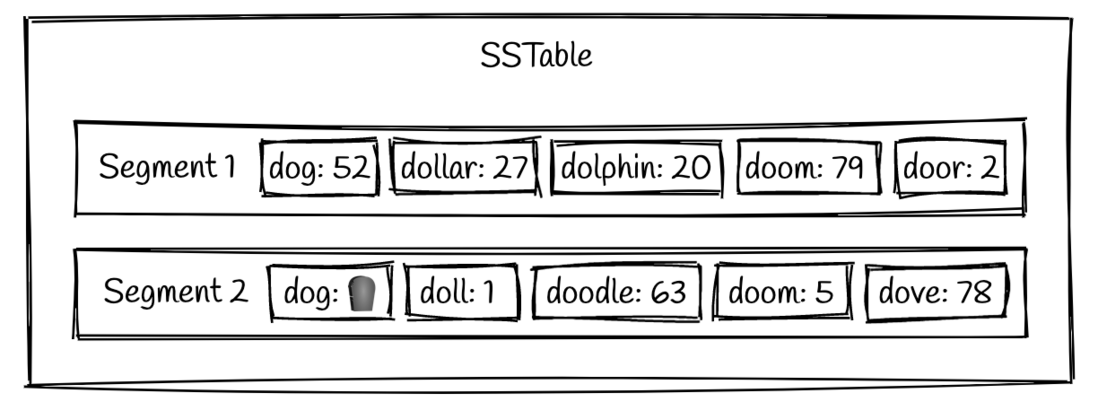
上图演示了原来 key 为 dog 的值为 52,而删除之后就会变成一个墓碑的标记。当我们搜索键 dog的时候,将会返回数据无法查询,这就意味着删除操作其实也是占用磁盘空间的,最后墓碑的值将会被压缩,最后将会从磁盘删除。
总结
我们已经基本描述了 LSM tree 引擎是如何工作的:
- 写入操作是先写入内存的(被成为 memtable)。所有的用于加速查询的数据结构(布隆过滤器和稀疏索引)都会被同时更新;
- 当内存中的 memtable 太大了,将会被刷到磁盘中,注意是有序的;
- 当查询时我们先回查询布隆过滤器,如果布隆过滤器返回说键不存在,则实际不存在,如果布隆过滤器说存在,进一步遍历 segment 文件;
- 对于遍历 segment 文件的过程,我们将会先通过稀疏索引找到最小的文件范围,并开始由新到老开始遍历,找到一个key则直接返回。
参考
https://www.cnblogs.com/zxporz/p/16021373.html
后端 - 理解 LSM Tree : 是什么让数据库这么能写? - codestack - SegmentFault 思否
相关文章:
举例理解LSM-Tree,LSM-Tree和B+Tree的比较
写操作 write1:WAL 把操作同步到磁盘中WAL做备份(追加写、性能极高) write2:Memtable 完成WAL后将(k,v)数据写入内存中的Memtable,Memtable的数据结构一般是跳表或者红黑树 内存内采用这种数据结构一方面支持内存…...

React Native 全栈开发实战班 - 核心组件与导航
在 React Native 中,组件是构建用户界面的基本单元。React Native 提供了丰富的内置组件,涵盖了从基础布局到复杂交互的各种需求。本章节将详细介绍常用的内置组件,并重点讲解列表与滚动视图的使用。 1. 常用内置组件详解 React Native 提供…...

Leecode热题100-35.搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 示例 1: 输入: nums [1,3,5,6], target 5 输出: 2示例 2: 输入:…...

密码学知识点整理二:常见的加密算法
常用的加密算法包括对称加密算法、非对称加密算法和散列算法。 对称加密算法 AES:高级加密标准,是目前使用最广泛的对称加密算法之一,支持多种密钥长度(128位、192位、256位),安全性高,加密效率…...
Linux如何将文件或目录打成rpm包?-- rpmbuild打包详解
👨🎓博主简介 🏅CSDN博客专家 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入!…...

RabbitMQ-死信队列(golang)
1、概念 死信(Dead Letter),字面上可以理解为未被消费者成功消费的信息,正常来说,生产者将消息放入到队列中,消费者从队列获取消息,并进行处理,但是由于某种原因,队列中的…...

爬虫开发工具与环境搭建——环境配置
第二章:爬虫开发工具与环境搭建 第二节:环境配置 在进行爬虫开发之前,首先需要配置好开发环境。一个良好的开发环境不仅能提高开发效率,还能避免因环境不一致带来的问题。以下是环境配置的详细步骤,涵盖了Python开发…...

15.UE5等级、经验、血条,魔法恢复和消耗制作
2-17 等级、经验、血条、魔法消耗_哔哩哔哩_bilibili 目录 1.制作UI,等级,经验,血条 2.为属性面板绑定角色真实的属性,实现动态更新 3.魔法的消耗和恢复 1.制作UI,等级,经验,血条 创建控…...

【Homework】【5】Learning resources for DQ Robotics in MATLAB
Lesson 5 代码-TwoDofPlanarRobot.m 表示一个 2 自由度平面机器人。该类包含构造函数、计算正向运动学模型的函数、计算平移雅可比矩阵的函数,以及在二维空间中绘制机器人的函数。 classdef TwoDofPlanarRobot%TwoDofPlanarRobot - 表示一个 2 自由度平面机器人类…...

vue3中 ref和reactive的区别
ref的主要作用 ref 函数接受的参数数据类型可以是原始数据类型也可以是引用数据类型。在模板中使用 ref 时,我们不需要加 .value,因为当 ref 在模板中作为顶层属性被访问时,它们会被自动解包, <p>count: {{ count }}</…...

第十四章 Spring之假如让你来写AOP——雏形篇
Spring源码阅读目录 第一部分——IOC篇 第一章 Spring之最熟悉的陌生人——IOC 第二章 Spring之假如让你来写IOC容器——加载资源篇 第三章 Spring之假如让你来写IOC容器——解析配置文件篇 第四章 Spring之假如让你来写IOC容器——XML配置文件篇 第五章 Spring之假如让你来写…...

群控系统服务端开发模式-应用开发-前端个人资料开发
一、总结 其实程序开发到现在,简单的后端框架就只剩下获取登录账号信息及获取登录账号菜单这两个功能咯。详细见下图: 1、未登录时总业务流程图 2、登录后总业务流程图 二、获取登录账号信息对接 在根目录下src文件夹下store文件夹下modules文件夹下的us…...

动态规划技巧点
动规五部曲(来自b站卡哥):1、确定DP数组中i、j…的含义。2、确定DP推导式。3、DP数组初始化。4、DP数组遍历顺序。5、DP数组打印校验。 父问题、子问题有些许区别:LeetCode343.整数拆分 今天在哔哩哔哩上刷到了一个非常有意思的l…...

深度学习之pytorch常见的学习率绘制
文章目录 0. Scope1. StepLR2. MultiStepLR3. ExponentialLR4. CosineAnnealingLR5. ReduceLROnPlateau6. CyclicLR7. OneCycleLR小结参考文献 https://blog.csdn.net/coldasice342/article/details/143435848 0. Scope 在深度学习中,学习率(Learning R…...
Spring Boot集成SQL Server快速入门Demo
1.什么是SQL Server? SQL Server是由Microsoft开发和推广的以客户/服务器(c/s)模式访问、使用Transact-SQL语言的关系数据库管理系统(DBMS),它最初是由Microsoft、Sybase和Ashton-Tate三家公司共同开发的&…...
低代码牵手 AI 接口:开启智能化开发新征程
一、低代码与 AI 接口的结合趋势 低代码开发平台近年来在软件开发领域迅速崛起。随着企业数字化转型的需求不断增长,低代码开发平台以其快速构建应用程序的优势,满足了企业对高效开发的需求。例如,启效云低代码平台通过范式化和高颗粒度的可配…...

【已解决】git push一直提示输入用户名及密码、fatal: Could not read from remote repository的问题
问题描述: 在实操中,git push代码到github上一直提示输入用户名及密码,并且跳出的输入框输入用户名和密码后,报错找不到远程仓库 实际解决中,发现我环境有两个问题解决: git push一直提示输入用户名及密码…...

python语言基础-4 常用模块-4.13 其他模块
声明:本内容非盈利性质,也不支持任何组织或个人将其用作盈利用途。本内容来源于参考书或网站,会尽量附上原文链接,并鼓励大家看原文。侵删。 4.13 其他模块 除此之外python中还有大量的功能模块,如: pill…...

微信小程序=》基础=》常见问题=》性能总结
文章目录 微信小程序开发应用 实例小程序生命周期 以及 各生命周期应用实例小程序图片 展示方案 小程序打包应用方案技术细节(分包应用实例)技术细节(压缩处理)一、准备工作二、JavaScript 代码压缩三、WXML 文件优化(…...

JWT深度解析:Java Web中的安全传输与身份验证
标题:JWT深度解析:Java Web中的安全传输与身份验证 引言 JSON Web Token(JWT)是一种轻量级的身份验证和授权标准,它允许在各方之间安全地传输信息。在Java Web开发中,JWT因其无状态、可扩展性和跨域支持而…...

C++-练习-109
题目:对Tv和Remote类进行如下修改a.让它们互为友元b.在Remote类中添加一个状态变量成员,该成员描述遥控器使处于常规状态还是互动模式c.在Remote中添加一个显式模式的方法d.在Tv类中添加一个对Remote中新成员进行切换的方法,该方法仅当Tv处于…...

Python开发者三步完成Taotoken接入并调用多模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者三步完成Taotoken接入并调用多模型 对于希望便捷使用多种大语言模型的Python开发者而言,通过一个统一的AP…...

SD-PPP:革命性Photoshop AI插件,彻底终结设计工作流断层
SD-PPP:革命性Photoshop AI插件,彻底终结设计工作流断层 【免费下载链接】sd-ppp A Photoshop AI plugin 项目地址: https://gitcode.com/gh_mirrors/sd/sd-ppp 还在Photoshop与AI绘图工具之间手动搬运素材吗?SD-PPP是一款开源免费的P…...

Nginx、Tengine、OpenRestry的http和tcp后端健康检查【20260520-003篇】
文章目录 一、Nginx 开源版(无第三方模块) 1. 被动健康检查(内置,默认) TCP 后端(stream 四层) HTTP 后端(http 七层) 2. Nginx + 第三方模块(主动检查) 编译 Nginx 加模块 HTTP 主动检查 TCP 主动检查 二、Tengine(原生带主动检查) HTTP 健康检查 TCP 健康检查 查…...

20+终极Obsidian模板:简单快速构建你的卡片盒笔记系统
20终极Obsidian模板:简单快速构建你的卡片盒笔记系统 【免费下载链接】Obsidian-Templates A repository containing templates and scripts for #Obsidian to support the #Zettelkasten method for note-taking. 项目地址: https://gitcode.com/gh_mirrors/ob/O…...

面试必问:AI 医疗平台怎么设计?这次彻底讲透
AI 医疗平台怎么设计?一次讲清医生辅助、知识库、问答系统与安全边界 大家好,我是一名有 4 年工作经验的 Java 后端开发。 AI 和医疗结合这个方向这两年非常热,但也正因为它太敏感,所以最怕两种极端:一种是把它吹成“万…...

ARM PMU性能监控机制与微架构事件解析
1. ARM PMU性能监控体系深度解析性能监控单元(PMU)是现代处理器中用于统计硬件事件的关键模块,它如同处理器的"听诊器",能够精确捕捉微架构层面的各类行为。在ARMv8/v9架构中,PMU通过事件计数器机制实现对指令流水线、缓存子系统、…...

浏览器Cookie本地导出实战指南:Get-cookies.txt-LOCALLY深度解析
浏览器Cookie本地导出实战指南:Get-cookies.txt-LOCALLY深度解析 【免费下载链接】Get-cookies.txt-LOCALLY Get cookies.txt, NEVER send information outside. 项目地址: https://gitcode.com/gh_mirrors/ge/Get-cookies.txt-LOCALLY 在Web开发和自动化测试…...

华为BGP路由实战:从原理到策略调优的深度解析
1. 华为BGP路由技术入门指南 第一次接触华为BGP路由配置时,我被那些专业术语搞得晕头转向。经过多次实战后才发现,BGP就像互联网世界的邮局系统,负责在不同自治系统(AS)之间传递路由信息。华为设备的BGP实现特别适合企…...

帆软FineReport 10升级实战:从路径映射到安全配置的完整指南
1. 从FineReport 9到10的升级背景与准备工作 最近接手了一个企业级报表系统的升级项目,需要将现有的FineReport 9环境迁移到最新的10版本。在实际操作过程中发现,这不仅仅是简单的版本替换,而是涉及到路径映射、参数调整、安全配置等多个关键…...