mac2019环境 Airflow+hive+spark+hadoop本地环境安装
1 环境介绍
本地安装可分为两个部分,mac软件环境, python开发环境
ps: 安装过程参考chatgpt、csdn文章

1.1 mac软件环境
目标安装的的软件是hive、apache-spark、hadoop,但是这三个软件又依赖java(spark依赖)、ssh(从warn日志看到,具体作用不明,可能是提交计算任务的时候依赖做权限验证)、数据库(hive依赖,postgres 实测问题较少)。zsh命令行解释器,用于执行指令, homebrew软件包管理器,安装卸载软件非常方便。接下来介绍各种软件情况。
1.1.1 环境变量
.zprofile 用来配置mac 用户登录时的环境变量,安装完软件后需要进行配置。 文档末尾提供一个参考示例。环境变量配置后才能方便的通过软件指令来进行操作。 同时python运行pyspark的时候也会使用到java的环境变量,配置错误会导致pyspark运行失败。
我都是把变量放.zprofile的,会比较省事
1.1.2 home-brew
安装过程涉及安装和删除,使用homebrew能解决很多不必要的问题。比如启动postgres
1.1.3 java
macos-sonoma 14.6.1自带hotspot 23版本,但是不满足spark运行环境要求,实测安装java openjdk 1.8 的版本可以使用。
1.1.4 ssh
目测是提交任务时候依赖,需要在~/.ssh 下面创建公钥、密钥同时把公钥备份重新命名才能让hadoop或spark使用到。
1.1.5 hive、spark、hadoop
需要解决的是账号密码、端口等配置,配置正确才能建立通讯。
1.2 Python 环境
1.2.1 miniforge3
python虚拟环境管理,因为公司不允许使用conda,所以用这个代替。 这个软件可以解决版本依赖冲突问题,同时管理python环境也很方便。 python开发环境和airflow 需要使用相同的python环境。
1.2.2 airflow
相当于python的一个组件,调用命令以后就能运行服务。python 代码里也会引用到这个组件。
写好的代码放到 airflow 组件的根目录下的 dags目录下就能被airflow识别。 代码文件复制过去后就会自动刷新调度任务。 可以在airflow上触发调度任务,验证执行结果。
1.2.3 python 开发环境
调试过程就能直接读到airflow的变量数据, 也可以调用pythonspark功能做调试。但是调试airflow不会把任务提交到airflow上。
所以验证要分两个阶段。
- 单独测试调度任务的逻辑 ,如果使用到了python 函数做任务的,参数需要自己设置一下传入。对使用xcom_push的还没实践过。
- 测试airflow dag代码逻辑。 验证就是运行有没有报错,变量取值是否正确。 任务依赖关系还得在airflow页面上查看。
2 安装步骤
经过反复调试成功,可能有些细节忘了。
如有遇到问题可以评论回复。或自行chat-gpt
有些服务启动会导致终端不能再输入指令了,command + T 创建新终端执行新指令,然后 source ~/.zprofile 更新环境变量即可
2.1 mac环境
2.1.1 homebrew
没有安装就用下面指令安装,打开终端
/bin/bash -c “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)”
安装成功以后终端运行brew 有下面提示即可

2.1.2 ssh
- cd ~/.ssh
- ssh-keygen -t rsa -b 4096 -C “your_email@example.com” 创建公钥
- cat id_rsa.pub >> authorized_keys 复制公钥
- sudo systemsetup -setremotelogin on 启动ssh服务
2.1.3 安装java 1.8
- 执行指令 brew install openjdk@8
- export JAVA_HOME=$(/usr/libexec/java_home -v 1.8) >> ~/.zprofile #这种方式不用自己去找java的目录
- source ~/.zprofile
- java -version #如果有打印java信息就安装成功了
2.1.4 安装postgres
- brew install postgresql@14 #指定版本吧,其他版本没试过
- 目录可能是/usr/local/var/postgresql@14、/opt/homebrew/opt/postgresql@14、/usr/local/opt/postgresql@14 验证一下即可,也可能没有@14,确认以后修改环境变量
- export PATH=“/opt/homebrew/opt/postgresql@14/bin:$PATH” >> ~/.zprofile
- source ~/.zprofile
- initdb /opt/homebrew/var/postgresql@14 初始化数据库, 可能没有@14,我装的都没有@14结尾
- brew services start postgresql@14 启动服务
- brew services list 验证服务是否启动
- psql postgres 登录数据库
- 创建hive用户信息
- CREATE DATABASE hive;
- CREATE USER hiveuser WITH PASSWORD ‘hivepassword’;
- GRANT ALL PRIVILEGES ON DATABASE hive TO hiveuser;
- \q 或者control + c 退出
- psql -U hiveuser -d hive -h localhost -p 5432 登录hiveuser账号,查看
2.1.5 安装hadoop
- brew install hadoop
- export HADOOP_HOME=/opt/homebrew/opt/hadoop/libexec >> ~/.zprofile
- export PATH= H A D O O P H O M E / b i n : HADOOP_HOME/bin: HADOOPHOME/bin:PATH >> ~/.zprofile
- 把下面环境变量写到 ~/.zprofile 文件里
export HADOOP_COMMON_HOME=/usr/local/opt/hadoop/libexec 或者 /opt/homebrew/opt/hadoop/libexec 看实际安装路径
export HADOOP_HOME=$HADOOP_COMMON_HOME
export HADOOP_HDFS_HOME=$HADOOP_COMMON_HOME
export HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME
export HADOOP_YARN_HOME=$HADOOP_COMMON_HOME
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# 指定用当前用户启动hdfs 就不用单独创建hdfs了
export HADOOP_NAMENODE_USER={mac登录用户的名字}
export HADOOP_DATANODE_USER={mac登录用户的名字}
- source ~/.zprofile
- hadoop version 查看安装情况
- start-dfs.sh 启动hadoop组件
- start-yarn.sh
- jps 查看是否启动成功,应该有ResourceManager
- HDFS Web 界面:http://localhost:9870
- YARN Web 界面:http://localhost:8088
- cd $HADOOP_HOME/etc/hadoop 进入到配置页面
- vim core-site.xml 我是这样配置的
<configuration>
<property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property>
</configuration>
- vim hdfs-site.xml
<configuration><property><name>dfs.namenode.name.dir</name><value>/Users/?自己的用户名?/hdfs/hadoop/tmp/dfs/name</value>
</property>
<property><name>dfs.datanode.data.dir</name><value>/Users/?自己的用户名?/hdfs/hadoop/tmp/dfs/data</value>
</property>
<property><name>dfs.namenode.http-address</name><value>localhost:9101</value>
</property>
<property><name>dfs.datanode.http.address</name><value>localhost:9102</value>
</property></configuration>
- hdfs namenode 终端启动
- hdfs datanode
2.1.6 安装hive
- brew install apache-hive
- export HIVE_HOME=/opt/homebrew/opt/apache-hive/libexec >> ~/.zprofile
- export PATH= H I V E H O M E / b i n : HIVE_HOME/bin: HIVEHOME/bin:PATH >> ~/.zprofile
- source ~/.zprofile
- 下载postgres驱动 https://jdbc.postgresql.org/download/ 。我使用的是42.7.4-java8 版本。 拷贝到$HIVE_HOME/lib目录
- 修改 $HIVE_HOME/conf/hive-site.xml 配置 使用postgres。 拷贝出来到文本编辑器里改方便。根据name来改
<property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:postgresql://localhost:5432/hive</value><description>JDBC connect string for a JDBC metastore.To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>org.postgresql.Driver</value><description>Driver class name for a JDBC metastore</description></property>
<property><name>javax.jdo.option.ConnectionUserName</name><value>hiveuser</value><description>Username to use against metastore database</description></property>
<property><name>javax.jdo.option.ConnectionPassword</name><value>hivepassword</value><description>The password for the database user.</description>
</property>
<property><name>hive.metastore.uris</name><value>thrift://localhost:9083</value><description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description></property>
- schematool -dbType postgres -initSchema 初始化数据库
- hive --service metastore 启动metastore服务
- hive --version 查看安装成功
- hive 启动, 如果hadoop的 namenode、datanode没启动会报错。
- show databases; --如果正常就可以一顿操作了
- PS: hive的xml配置可能有问题,需要手动删掉特殊字符,3215行
2.1.7 安装spark
- brew install apache-spark
- export SPARK_HOME=/opt/homebrew/opt/apache-spark/libexec >> ~/.zprofile
- export PATH= S P A R K H O M E / b i n : SPARK_HOME/bin: SPARKHOME/bin:PATH >> ~/.zprofile
- source ~/.zprofile
- cp $HIVE_HOME/conf/hive-site.xml $SPARK_HOME/conf/ 把hive配置复制到spark
- /usr/local/opt/apache-spark/libexec/sbin/stop-all.sh 停止spark
- /usr/local/opt/apache-spark/libexec/sbin/start-all.sh 启动spark
- spark-shell --version 验证安装
- spark.sql(“SHOW TABLES”).show() 执行看看是否能查到hive表
2.1.8 启动服务查看
- 终端输入jps 查看启动的服务有哪些
- 也可通过网页查看spark、 hadoop的情况

2.2 python环境安装
这个相对简单也独立
2.2.1 miniforge3
- https://github.com/conda-forge/miniforge 可以自己下载安装,指定目录 我使用的是 ~/miniforge 好找
- brew install miniforge 这个命令直接安装,之后复制/usr/local/miniforge3 到自己想要的目录。
- echo ‘export PATH=“/usr/local/miniforge3/bin:$PATH”’ >> ~/.zprofile 这个命令把miniforge,如果修改了目录自己改下路径
- source ~/.zprofile 更新环境变量
- conda --version 查看是否安装成功
- conda init zsh 初始化conda环境, 这个命令会把初始化代码放到~/.bashrc 或者 ~/.zshrc 里,复制出来到 ~/.zprofile
- conda create -n data_dev python=3.8 创建一个3.8的环境 环境名字data_dev可以自己改
- conda activate data_dev 激活环境,在这个环境里安装python组件
2.2.2 airflow 安装
- conda install apache-airflow==1.10.12 安装指定版本airflow
- airflow initdb db初始化,1.10x版本
- airflow scheduler 启动调度
- airflow webserver --port 8081 启动页面
- http://localhost:8081 访问页面
- 安装目录在: xxx /miniforge3/envs/data_dev/lib/python3.8/site-packages/airflow, data_dev跟conda创建的环境名一样
- 写完的脚本放到${AIRFLOW_HOME}/dags/下。这里我配置的AIRFLOW_HOME=上一步的安装路径
- ps 使用3.8 可以用conda 安装1.10.12的airflow,可能遇到itsdangerous版本问题,降级 conda install itsdangerous=1.1.0即可
- ps airflow默认使用sqlite3的数据存储方式,似乎不需要安装这个数据库。
2.2.3 python环境
- 指定xxx /miniforge3/envs/data_dev/ 目录下的python环境作为pycharm的python解释器
- 再安装一个pyspark 就行
- 可以直接运行python代码了
3 附录
3.1 启动服务指令
# 可以开启多个终端执行任务
#启动ssh hadoop依赖
# sudo launchctl stop com.openssh.sshd
# sudo launchctl start com.openssh.sshd
# 关闭ssh服务
sudo systemsetup -setremotelogin off
# 开启ssh服务
sudo systemsetup -setremotelogin on#停止postgres
brew services stop postgresql
#启用
brew services start postgresql # hadoop 集群服务
/usr/local/opt/hadoop/libexec/sbin/stop-dfs.sh
/usr/local/opt/hadoop/libexec/sbin/stop-yarn.sh
/usr/local/opt/hadoop/libexec/sbin/start-dfs.sh
/usr/local/opt/hadoop/libexec/sbin/start-yarn.sh#启动hdfs
hdfs namenode
hdfs datanode
#启动hive元数据管理
hive --service metastore
# 启动spark
/usr/local/opt/apache-spark/libexec/sbin/stop-all.sh
/usr/local/opt/apache-spark/libexec/sbin/start-all.sh#启动airflow在 conda环境执行 data_dev
conda activate data_dev
pkill -f airflow
airflow scheduler
airflow web --port 8081 #jps查看服务 运行的hadoop、hive
jps
#查看postgres服务
brew services list
3.2 环境变量配置
export JAVA_HOME=$(/usr/libexec/java_home -v 1.8)
export HIVE_HOME=/Users/{mac登录用户的名字}/apache-hive-3.1.2-bin
export PATH=$HIVE_HOME/bin:$PATH
export JAVA_OPTS="-Djava.io.tmpdir=/Users/{mac登录用户的名字}/logs -Duser.name={mac登录用户的名字}"
export SPARK_HOME=/usr/local/opt/apache-spark/libexec
export PATH=$PATH:$SPARK_HOME/bin
export HADOOP_COMMON_HOME=/usr/local/opt/hadoop/libexec
export HADOOP_HOME=$HADOOP_COMMON_HOME
export HADOOP_HDFS_HOME=$HADOOP_COMMON_HOME
export HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME
export HADOOP_YARN_HOME=$HADOOP_COMMON_HOME
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# 指定用当前用户启动hdfs 就不用单独创建hdfs了
export HADOOP_NAMENODE_USER={mac登录用户的名字}
export HADOOP_DATANODE_USER={mac登录用户的名字}
#export SPARK_SUBMIT_OPTS="-Djava.security.manager=allow" # >>> conda initialize >>>
# !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/Users/{mac登录用户的名字}/miniforge3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; theneval "$__conda_setup"
elseif [ -f "/Users/{mac登录用户的名字}/miniforge3/etc/profile.d/conda.sh" ]; then. "/Users/yuwang.lin/miniforge3/etc/profile.d/conda.sh"elseexport PATH="/Users/{mac登录用户的名字}/miniforge3/bin:$PATH"fi
fi
unset __conda_setup
# <<< conda initialize <<<
#这个home因为会放cfg文件,所以不能配置为airflow所在目录
export AIRFLOW_DIR="/Users/{mac登录用户的名字}/miniforge3/envs/data_dev/lib/python3.8/site-packages/airflow"
export AIRFLOW_HOME="/Users/{mac登录用户的名字}/airflow"
export POSTGRESQL_HOME="/usr/local/var/postgresql@14"
export PATH=$POSTGRESQL_HOME/bin:$PATH
export PGDATA='/usr/local/pgsql/data'
~
~
4 参考文献
- hdfs
- ssh 启动
相关文章:
mac2019环境 Airflow+hive+spark+hadoop本地环境安装
1 环境介绍 本地安装可分为两个部分,mac软件环境, python开发环境 ps: 安装过程参考chatgpt、csdn文章 1.1 mac软件环境 目标安装的的软件是hive、apache-spark、hadoop,但是这三个软件又依赖java(spark依赖)、ssh(…...

如何使用EasyExcel生成多列表组合填充的复杂Excel示例
作者:Funky_oaNiu 一、(需求)生成的表格效果:二、搞一个模板文件三、建立对应的表格实体类四、开始填充五、Vue3前端发起请求下载六、官方文档及AI问答 一、(需求)生成的表格效果: 其中只有顶部…...

【MySQL】MySQL在Centos环境安装
🔥个人主页: Forcible Bug Maker 🔥专栏: MySQL 目录 🌈前言🔥卸载不要的环境🔥检查系统安装包🔥卸载这些默认安装包🔥获取mysql官方yum源🔥安装mysql yum源…...

JDBC-Mysql 时区问题详解
目录 一、前置准备 1.1 版本号列表 1.2 Sql脚本 1.3 application.yaml配置 1.4 数据库时区设置 二、java Date类型与(jdbcType)TIMESTAMP类型的转换 2.1 jdbc对serverTimeZone的处理 2.2 java Date转(jdbcType)TIMESTAMP …...

前端页面一些小点
案例一: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>快递单号查询</title><…...

Postman接口测试(断言、关联、参数化、输出测试报告)
基本界面展示 Get、Post请求 Postman断言 使用postman来判断预期结果与实际结果是否一致 响应状态码断言 响应包含字符串 断言判断字符串的格式 关联 用于解决http请求之间存在依赖关系 依赖:一个http请求的响应结果中的数据,被另一个请求使用 登…...

redis和mongodb等对比分析
Redis 和 MongoDB 都是非常流行的 NoSQL 数据库,它们在数据存储模型、性能、扩展性等方面有很大的差异。下面是 Redis 和 MongoDB 的对比分析: 1. 数据模型 Redis: 键值存储:Redis 是一个内存数据结构存储,它支持多种数据类型,如字符串、哈希、列表、集合、有序集合等。…...

如何在 WordPress 中轻松强制所有用户退出登录
作为一名长期管理 WordPress 网站的站长,我深知维护网站安全性的重要性。尤其是在面对会员网站或付费内容平台时,确保所有用户的登录状态是最新的,是维持网站正常运营的关键之一。今天,我就分享一下如何通过简单的步骤,…...

移除元素(leetcode 27)
给定一个数组,在数组中删除等于这个目标值的元素,然后返回新数组的大小 数组理论: 数组是一个连续的类型相近的元素的一个集合,数组上的删除是覆盖,只能由后面的元素进行覆盖,而不能进行真正意义上的地理位…...

html5表单属性的用法
文章目录 HTML5表单详解与代码案例一、表单的基本结构二、表单元素及其属性三、表单的高级应用与验证四、表单布局与样式 HTML5表单详解与代码案例 HTML5表单是网页中用于收集用户输入并提交到服务器的重要元素,广泛应用于登录页面、客户留言、搜索产品等场景。本文…...

使用 Ant Design Vue 自定渲染函数customRender实现单元格合并功能rowSpan
使用 Ant Design Vue 自定渲染函数customRender实现单元格合并功能rowSpan 背景 在使用Ant Design Vue 开发数据表格时,我们常常会遇到需要合并单元格的需求。 比如,某些字段的值可能会在多行中重复出现,而我们希望将这些重复的单元格合并为…...
——ALL-PD和PDAF)
相机光学(四十四)——ALL-PD和PDAF
1.PDAF(Phase Detection Auto Focus) PDAF是相位检测自动对焦技术的缩写,它是一种在数码相机和智能手机摄像头中使用的自动对焦技术。 PDAF的原理是根据CIS(CMOS图像传感器)不同像素的相位差信息,判断出…...

Opengl光照测试
代码 #include "Model.h" #include "shader_m.h" #include "imgui.h" #include "imgui_impl_glfw.h" #include "imgui_impl_opengl3.h" //以上是放在同目录的头文件#include <glad/glad.h> #include <GLFW/glfw3.…...

OpenSIP2.4.11 向 FreeSWITCH 注册
应朋友要求做了个简单的测试,花费时间不过半小时,记录如下: OpenSIPS IP 地址:192.168.31.213 FreeSWITCH IP 地址:192.168.31.166 加载 uac_registrant 模块(这个模块依赖 uac_auth 模块,得…...

【C++】深入理解 C++ 优先级队列、容器适配器与 deque:实现与应用解析
个人主页: 起名字真南的CSDN博客 个人专栏: 【数据结构初阶】 📘 基础数据结构【C语言】 💻 C语言编程技巧【C】 🚀 进阶C【OJ题解】 📝 题解精讲 目录 前言📌 1. 优先级队列、容器适配器和 deque 概述✨1.1 什么是优…...

Android 开发与救砖工具介绍
Android 开发与救砖工具介绍 在 Android 开发和设备维护中,fastboot、adb 和 9008 模式是三个非常重要的工具和模式。它们各自有不同的用途和操作方式,对于开发者和技术支持人员来说,了解它们的功能和使用方法是必不可少的。 1. Fastboot …...

vue2和vue3:diff算法的区别?
Vue 2 和 Vue 3 在 diff 算法方面的主要区别是: Vue 2 使用普通的 diff 算法,它会遍历所有的节点进行比对。 Vue 3 引入了 patch flag 的概念,并且对 diff 算法进行了优化,比如在相同层级的节点间不会去递归比对已经被移除的节点…...

后端返回大数问题
这个问题并不难,但是在开发的时候没有注意到 后端返回了一个列表数据,包含id,这个id是一个大数,列表进入详情,需要将id传入到详情页面详情页面内部通过id获取数据一直404,id不正确找问题,从路由传参到请求数据发现id没有问题,然后和后端进行联调,发现后端返回的id和我获取的id…...

vue3: ref, reactive, readonly, shallowReactive
vue3: ref, reactive, readonly, shallowReactive 原文地址:https://mp.weixin.qq.com/s/S3jPZKEMBP8nQQObF5d2VA <template><!-- <ul><li v-for"item in list.arr">{{item}}</li></ul><button click.prevent"add"…...
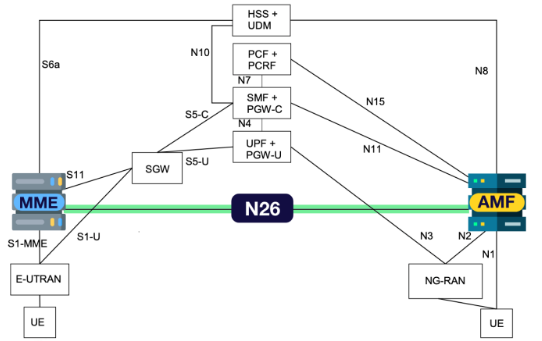
5G与4G互通的桥梁:N26接口
5G的商用部署进程将是一个基于4G系统进行的长期的替换、升级、迭代的过程,4G系统是在过渡到5G全覆盖过程中,作为保障用户业务连续性体验这一目的的最好补充。 因此4G/5G融合组网,以及互操作技术将是各大运营商在网络演进中需要重点考虑的问题…...

从数据驱动到物理约束:盘点神经网络求解偏微分方程的三大范式与核心进展
1. 神经网络求解偏微分方程的技术背景 偏微分方程(PDE)是描述自然界各种现象的核心数学工具,从流体力学中的纳维-斯托克斯方程到量子力学中的薛定谔方程,再到金融工程中的布莱克-斯科尔斯方程,PDE的身影无处不在。但传…...

【NotebookLM学术写作黄金法则】:20年科研老炮亲授5大避坑指南与3步合规提速法
更多请点击: https://intelliparadigm.com 第一章:NotebookLM学术写作规范的底层逻辑与认知革命 NotebookLM 并非传统意义上的文档编辑器,而是一个以“语义锚点”和“引用可追溯性”为基石的学术协作文本引擎。其底层逻辑颠覆了线性写作范式…...

终极指南:FigmaCN中文插件让设计师告别英文障碍
终极指南:FigmaCN中文插件让设计师告别英文障碍 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的全英文界面而烦恼吗?Figma中文插件FigmaCN正是为你…...

告别模组冲突:3分钟掌握Nexus Mods App终极游戏模组管理方案
告别模组冲突:3分钟掌握Nexus Mods App终极游戏模组管理方案 【免费下载链接】NexusMods.App Home of the development of the Nexus Mods App 项目地址: https://gitcode.com/gh_mirrors/ne/NexusMods.App 还在为《赛博朋克2077》的模组冲突而烦恼吗&#x…...

在Windows上直接安装APK的完整指南:告别模拟器时代
在Windows上直接安装APK的完整指南:告别模拟器时代 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾想过,在Windows电脑上直接运行Andro…...

WindowsCleaner终极指南:如何一键解决C盘爆红问题,让Windows系统重获新生
WindowsCleaner终极指南:如何一键解决C盘爆红问题,让Windows系统重获新生 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是不是也经常遇…...

逆向实战:用X32dbg条件断点精准定位MFC程序的窗口消息处理函数
逆向实战:用X32dbg条件断点精准定位MFC程序的窗口消息处理函数 在逆向分析领域,MFC程序因其复杂的消息映射机制和封装层次,常常让分析者感到无从下手。特别是当我们需要分析某个特定窗口消息(如按钮点击、菜单选择)的处…...

二叉搜索树:高效查找与增删详解
引言在上一篇树结构开篇文章中,我们建立了树的基本概念、二叉树的定义和四种遍历方式。本文将继续深入,讲解二叉搜索树(Binary Search Tree,BST)——它是最基础的"有组织"二叉树,也是后续学习 AV…...

BOX工控机在无人机机载系统中有什么优势?这 3 点是普通工控机比不了的
现在的无人机机载系统,越来越多的人选择用 BOX工控机。很多人问我,BOX工控机到底是什么?它和普通的工控机有什么区别?为什么大家都在用它?今天我就跟大家好好聊聊这个话题。我会从一个 17 年工控人的角度,给大家讲透 BOX工控机在无人机机载…...

用PCA给高维数据‘瘦身’:从鸢尾花数据集到人脸图像,实战对比降维效果与可视化技巧
用PCA给高维数据‘瘦身’:从鸢尾花数据集到人脸图像,实战对比降维效果与可视化技巧 当面对成百上千维的数据时,我们常会陷入"维度灾难"的困境——计算资源吃紧、模型训练缓慢,更糟的是噪声干扰导致分析结果失真。主成分…...