tdengine学习笔记
官方文档:用 Docker 快速体验 TDengine | TDengine 文档 | 涛思数据
整体架构
TDENGINE是分布式,高可靠,支持水平扩展的架构设计
TDengine分布式架构的逻辑结构图如下

一个完整的 TDengine 系统是运行在一到多个物理节点上的,包含应用(app) tdengine驱动(TAOSC) ,数据节点(dnode),多个数据节点组成一个集群。应用通过taosc的API与集群进行互动。
物理节点(pnode):pnode是物理机,虚拟机,或者docker容器。物理节点通过FQDN来标记,TDENGINE完全依赖FQDN来进行网络通讯。
数据节点(dnode):dnode 是 TDengine 服务器侧执行代码 taosd 在物理节点上的一个运行实例。在一个 TDengine 系统中,至少需要一个 dnode 来确保系统的正常运行。
dnode 在 TDengine 集群中的唯一标识由其实例的 endpoint(EP)决定。endpoint 是由dnode 所在物理节点的 FQDN 和配置的网络端口组合而成。通过配置不同的端口,一个pnode(无论是物理机、虚拟机还是 Docker 容器)可以运行多个实例,即拥有多个 dnode。
虚拟节点(vnode): 为了更好地支持数据分片、负载均衡以及防止数据过热或倾斜,TDengine 引入了 vnode(虚拟节点)的概念。虚拟节点被虚拟化为多个独立的 vnode 实例(如上面架构图中的 V2、V3、V4 等),每个 vnode 都是一个相对独立的工作单元,负责存储和管理一部分时序数据。
每个 vnode 都拥有独立的运行线程、内存空间和持久化存储路径,确保数据的隔离性和高效访问。一个 vnode 可以包含多张表(即数据采集点),这些表在物理上分布在不 同的 vnode 上,以实现数据的均匀分布和负载均衡。
当在集群中创建一个新的数据库时,系统会自动为该数据库创建相应的 vnode。一个dnode 上能够创建的 vnode 数量取决于该 dnode 所在物理节点的硬件资源,如 CPU、内存和存储容量等。需要注意的是,一个 vnode 只能属于一个数据库,但一个数据库可以包含多个 vnode。
除了存储时序数据以外,每个 vnode 还保存了其包含的表的 schema 信息和标签值等元数据。这些信息对于数据的查询和管理至关重要。
在集群内部,一个 vnode 由其所归属的 dnode 的 endpoint 和所属的 vgroup ID 唯一标识。管理节点负责创建和管理这些 vnode,确保它们能够正常运行并协同工作。
管理节点(mnode): mnode(管理节点)是 TDengine 集群中的核心逻辑单元,负责监控和维护所有 dnode的运行状态,并在节点之间实现负载均衡(如图 15-1 中的 M1、M2、M3 所示)。作为元数据(包括用户、数据库、超级表等)的存储和管理中心,mnode 也被称为 MetaNode。
计算节点(qnode): qnode(计算节点)是 TDengine 集群中负责执行查询计算任务的虚拟逻辑单元,同时也处理基于系统表的 show 命令。为了提高查询性能和并行处理能力,集群中可以配置多个 qnode,这些 qnode 在整个集群范围内共享使用(如图 15-1 中的 Q1、Q2、Q3 所示)。
与 dnode 不同,qnode 并不与特定的数据库绑定,这意味着一个 qnode 可以同时处理来自多个数据库的查询任务。每个 dnode 上最多有一个 qnode,并由其所归属的 dnode 的endpoint 唯一标识。
当客户端发起查询请求时,首先与 mnode 交互以获取当前可用的 qnode 列表。如果在集群中没有可用的 qnode,计算任务将在 vnode 中执行。当执行查询时,调度器会根据执行计划分配一个或多个 qnode 来共同完成任务。qnode 能够从 vnode 获取所需的数据,并将计算结果发送给其他 qnode 进行进一步处理。
通过引入独立的 qnode,TDengine 实现了存储和计算的分离。
流计算节点(snode): snode(流计算节点)是 TDengine 集群中专门负责处理流计算任务的虚拟逻辑单元(如上架构图 中的 S1、S2、S3 所示)。为了满足实时数据处理的需求,集群中可以配置多个 snode,这些 snode 在整个集群范围内共享使用。
与 dnode 类似,snode 并不与特定的流绑定,这意味着一个 snode 可以同时处理多个流的计算任务。每个 dnode 上最多有一个 snode,并由其所归属的 dnode 的 endpoint 唯一标识。
当需要执行流计算任务时,mnode 会调度可用的 snode 来完成这些任务。如果在集群中没有可用的 snode,流计算任务将在 vnode 中执行。
通过将流计算任务集中在 snode 中处理,TDengine 实现了流计算与批量计算的分离,从而提高了系统对实时数据的处理能力。
虚拟节点组(VGroup):
vgroup(虚拟节点组)是由不同 dnode 上的 vnode 组成的一个逻辑单元。这些 vnode之间采用 Raft 一致性协议,确保集群的高可用性和高可靠性。在 vgroup 中,写操作只能在 leader vnode 上执行,而数据则以异步复制的方式同步到其他 follower vnode,从而在多个物理节点上保留数据副本。
vgroup 中的 vnode 数量决定了数据的副本数。要创建一个副本数为 N 的数据库,集群必须至少包含 N 个 dnode。副本数可以在创建数据库时通过参数 replica 指定,默认值为 1。利用 TDengine 的多副本特性,企业可以摒弃昂贵的硬盘阵列等传统存储设备,依然实现数据的高可靠性。
vgroup 由 mnode 负责创建和管理,并为其分配一个集群唯一的 ID,即 vgroup ID。如果两个 vnode 的 vgroup ID 相同,则说明它们属于同一组,数据互为备份。值得注意的是,vgroup 中的 vnode 数量可以动态调整,但 vgroup ID 始终保持不变,即使 vgroup 被删除,其 ID 也不会被回收和重复利用。
通过这种设计,TDengine 在保证数据安全性的同时,实现了灵活的副本管理和动态扩展能力
Taosc
taosc(应用驱动)是 TDengine 为应用程序提供的驱动程序,负责处理应用程序与集群之间的接口交互。taosc 提供了 C/C++ 语言的原生接口,并被内嵌于 JDBC、C#、Python、Go、Node.js 等多种编程语言的连接库中,从而支持这些编程语言与数据库交互。
应用程序通过 taosc 而非直接连接集群中的 dnode 与整个集群进行通信。taosc 负责获取并缓存元数据,将写入、查询等请求转发到正确的 dnode,并在将结果返回给应用程序之前,执行最后一级的聚合、排序、过滤等操作。对于 JDBC、C/C++、C#、Python、Go、Node.js 等接口,taosc 是在应用程序所处的物理节点上运行的。
此外,taosc 还可以与 taosAdapter 交互,支持全分布式的 RESTful 接口。这种设计使得 TDengine 能够以统一的方式支持多种编程语言和接口,同时保持高性能和可扩展性。
一个典型的消息流程
为解释 vnode、mnode、taosc 和应用之间的关系以及各自扮演的角色,下面对写入数据这个典型操作的流程进行剖析。

图 2 TDengine 典型的操作流程
- 应用通过 JDBC 或其他 API 接口发起插入数据的请求。
- taosc 会检查缓存,看是否保存有该表所在数据库的 vgroup-info 信息。如果有,直接到第 4 步。如果没有,taosc 将向 mnode 发出 get vgroup-info 请求。
- mnode 将该表所在数据库的 vgroup-info 返回给 taosc。Vgroup-info 包含数据库的 vgroup 分布信息(vnode ID 以及所在的 dnode 的 End Point,如果副本数为 N,就有 N 组 End Point),还包含每个 vgroup 中存储数据表的 hash 范围。如果 taosc 迟迟得不到 mnode 回应,而且存在多个 mnode,taosc 将向下一个 mnode 发出请求。
- taosc 会继续检查缓存,看是否保存有该表的 meta-data。如果有,直接到第 6 步。如果没有,taosc 将向 vnode 发出 get meta-data 请求。
- vnode 将该表的 meta-data 返回给 taosc。Meta-data 包含有该表的 schema。
- taosc 向 leader vnode 发起插入请求。
- vnode 插入数据后,给 taosc 一个应答,表示插入成功。如果 taosc 迟迟得不到 vnode 的回应,taosc 会认为该节点已经离线。这种情况下,如果被插入的数据库有多个副本,taosc 将向 vgroup 里下一个 vnode 发出插入请求。
- taosc 通知 APP,写入成功。
对于第二步,taosc 启动时,并不知道 mnode 的 End Point,因此会直接向配置的集群对外服务的 End Point 发起请求。如果接收到该请求的 dnode 并没有配置 mnode,该 dnode 会在回复的消息中告知 mnode EP 列表,这样 taosc 会重新向新的 mnode 的 EP 发出获取 meta-data 的请求。
对于第四和第六步,没有缓存的情况下,taosc 无法知道虚拟节点组里谁是 leader,就假设第一个 vnodeID 就是 leader,向它发出请求。如果接收到请求的 vnode 并不是 leader,它会在回复中告知谁是 leader,这样 taosc 就向建议的 leader vnode 发出请求。一旦得到插入成功的回复,taosc 会缓存 leader 节点的信息。
上述是插入数据的流程,查询、计算的流程也完全一致。taosc 把这些复杂的流程全部封装屏蔽了,对于应用来说无感知也无需任何特别处理。
通过 taosc 缓存机制,只有在第一次对一张表操作时,才需要访问 mnode,因此 mnode 不会成为系统瓶颈。但因为 schema 有可能变化,而且 vgroup 有可能发生改变(比如负载均衡发生),因此 taosc 会定时和 mnode 交互,自动更新缓存。
存储模型与数据分区、分片
存储模型
TDengine 存储的数据包括采集的时序数据以及库、表相关的元数据、标签数据等,这些数据具体分为三部分:
时序数据:时序数据由data、head、sma、和stt 4类文件组成,采用了“一个数据采集点一张表”的模型来优化存储和查询性能
数据表元数据:包含标签信息和table scheme信息,存放于vnode里的meta文件,支持增删改查,支持标签数据的索引,元数据全内存存储,效率更快
数据库元数据:存放于mnode里包含系统节点、用户、DB、STable Schema等信息,支持增删改
与传统的 NoSQL 存储模型相比,TDengine 将标签数据与时序数据完全分离存储,它具有两大优势:
显著降低标签数据存储的冗余:标签和时序数据分离存储,降低冗余
实现极为高效的多表之间的聚合查询:通过标签过滤条件找出符合条件的表,减少了需要扫描的数据集大小,提高查询效率
数据分片
在进行海量数据管理时,为了实现水平扩展,通常需要采用数据分片(sharding)和数据分区(partitioning)策略。TDengine 通过 vnode 来实现数据分片,并通过按时间段划分数据文件来实现时序数据的分区。
vnode 不仅负责处理时序数据的写入、查询和计算任务,还承担着负载均衡、数据恢复以及支持异构环境的重要角色。为了实现这些目标,TDengine 将一个 dnode 根据其计算和存储资源切分为多个 vnode。这些 vnode 的管理过程对应用程序是完全透明的,由TDengine 自动完成。。
数据分区
除了通过 vnode 进行数据分片以外,TDengine 还采用按时间段对时序数据进行分区的策略。每个数据文件仅包含一个特定时间段的时序数据,而时间段的长度由数据库参数 duration 决定。这种按时间段分区的做法不仅简化了数据管理,还便于高效实施数据的保留策略。一旦数据文件超过了规定的天数(由数据库参数 keep 指定),系统将自动删除这些过期的数据文件。
此外,TDengine 还支持将不同时间段的数据存储在不同的路径和存储介质中。这种灵活性使得大数据的冷热管理变得简单易行,用户可以根据实际需求实现多级存储,从而优化存储成本和访问性能。
负载均衡与扩容
每个 dnode 都会定期向 mnode 报告其当前状态,包括硬盘空间使用情况、内存大小、CPU 利用率、网络状况以及 vnode 的数量等关键指标。这些信息对于集群的健康监控和资源调度至关重要。
关于负载均衡的触发时机,目前 TDengine 允许用户手动指定。当新的 dnode 被添加到集群中时,用户需要手动启动负载均衡流程,以确保集群在最佳状态下运行。
数据写入与复制流程
在一个具有 N 个副本的数据库中,相应的 vgroup 将包含 N 个编号相同的 vnode。在这些 vnode 中,只有一个被指定为 leader,其余的都充当 follower 的角色。这种主从架构确保了数据的一致性和可靠性。
当应用程序尝试将新记录写入集群时,只有 leader vnode 能够接受写入请求。如果 follower vnode 意外地收到写入请求,集群会立即通知 taosc 需要重新定向到 leader vnode。这一措施确保所有的写入操作都发生在正确的 leader vnode 上,从而维护数据的一致性和完整性。
通过这种设计,TDengine 确保了在分布式环境下数据的可靠性和一致性,同时提供高效的读写性能。
Leader Vnode 写入流程
Leader Vnode 遵循下面的写入流程:

图 3 TDengine Leader 写入流程
- 第 1 步: leader vnode 收到应用的写入数据请求,验证 OK,验证有效性后进入第 2 步;
- 第 2 步:vnode 将该请求的原始数据包写入数据库日志文件 WAL。如果
wal_level设置为 2,而且wal_fsync_period设置为 0,TDengine 还将 WAL 数据立即落盘,以保证即使宕机,也能从数据库日志文件中恢复数据,避免数据的丢失; - 第 3 步:如果有多个副本,vnode 将把数据包转发给同一虚拟节点组内的 follower vnodes,该转发包带有数据的版本号(version);
- 第 4 步:写入内存,并将记录加入到 skip list。但如果未达成一致,会触发回滚操作;
- 第 5 步:leader vnode 返回确认信息给应用,表示写入成功;
- 第 6 步:如果第 2、3、4 步中任何一步失败,将直接返回错误给应用;
Follower Vnode 写入流程
对于 follower vnode,写入流程是:

图 4 TDengine Follower 写入流程
- 第 1 步:follower vnode 收到 leader vnode 转发了的数据插入请求。
- 第 2 步:vnode 将把该请求的原始数据包写入数据库日志文件 WAL。如果
wal_level设置为 2,而且wal_fsync_period设置为 0,TDengine 还将 WAL 数据立即落盘,以保证即使宕机,也能从数据库日志文件中恢复数据,避免数据的丢失。 - 第 3 步:写入内存,更新内存中的 skip list。
与 leader vnode 相比,follower vnode 不存在转发环节,也不存在回复确认环节,少了两步。但写内存与 WAL 是完全一样的。
主从选择
每个 vnode 都维护一个数据的版本号,该版本号在 vnode 对内存中的数据进行持久化存储时也会被一并持久化。每次更新数据时,无论是时序数据还是元数据,都会使版本号递增,确保数据的每次修改都被准确记录。
当 vnode 启动时,它的角色(leader 或 follower)是不确定的,且数据处于未同步状态。为了确定自己的角色并同步数据,vnode 需要与同一 vgroup 内的其他节点建立 TCP连接。在连接建立后,vnode 之间会互相交换版本号、任期等关键信息。基于这些信息,vnode 将使用标准的 Raft 一致性算法完成选主过程,从而确定谁是 leader,谁应该作为follower。
这一机制确保在分布式环境下,vnode 之间能够有效地协调一致,维护数据的一致性和系统的稳定性
同步复制
在 TDengine 中,每次 leader vnode 接收到写入数据请求并将其转发给其他副本时,它并不会立即通知应用程序写入成功。相反,leader vnode 需要等待超过半数的副本(包括自身)达成一致意见后,才会向应用程序确认写入操作已成功。如果在规定的时间内未能获得半数以上副本的确认,leader vnode 将返回错误信息给应用程序,表明写入数据操作失败。
这种同步复制的机制确保了数据在多个副本之间的一致性和安全性,但同时也带来了写入性能方面的挑战。为了平衡数据一致性和性能需求,TDengine 在同步复制过程中引入了流水线复制算法。
流水线复制算法允许不同数据库连接的写入数据请求确认过程同时进行,而不是顺序等待。这样,即使某个副本的确认延迟,也不会影响到其他副本的写入操作。通过这种方式,TDengine 在保证数据一致性的同时,显著提升了写入性能,满足了高吞吐量和低延迟的数据处理需求。
1,用docker安装
docker pull tdengine/tdengine:3.3.3.0
启动镜像
docker run -d -p 6030:6030 -p 6041:6041 -p 6043:6043 -p 6044-6049:6044-6049 -p 6044-6045:6044-6045/udp -p 6060:6060 tdengine/tdengine:3.3.3.0
2,进入容器
docker ps 查看镜像的id
docker exec -it 镜像id bash
3,造数据
执行下列命令会造数据
taosBenchmark -y
系统将自动在数据库 test 下创建一张名为 meters的超级表。这张超级表将包含 10,000 张子表,表名从 d0 到 d9999,每张表包含 10,000条记录。每条记录包含 ts(时间戳)、current(电流)、voltage(电压)和 phase(相位)4个字段。时间戳范围从“2017-07-14 10:40:00 000” 到 “2017-07-14 10:40:09 999”。每张表还带有 location 和 groupId 两个标签,其中,groupId 设置为 1 到 10,而 location 则设置为 California.Campbell、California.Cupertino 等城市信息。
执行该命令后,系统将迅速完成 1 亿条记录的写入过程。实际所需时间取决于硬件性能,但即便在普通 PC 服务器上,这个过程通常也只需要十几秒。
taosBenchmark 提供了丰富的选项,允许用户自定义测试参数,如表的数目、记录条数等。要查看详细的参数列表,请在终端中输入如下命令
taosBenchmark --help
有关taosBenchmark 的详细使用方法,请参考taosBenchmark 参考手册
4,TDengine 命令行界面
执行taos;
体验查询
使用上述 taosBenchmark 插入数据后,可以在 TDengine CLI(taos)输入查询命令,体验查询速度。
- 查询超级表 meters 下的记录总条数
SELECT COUNT(*) FROM test.meters;
- 查询 1 亿条记录的平均值、最大值、最小值
SELECT AVG(current), MAX(voltage), MIN(phase) FROM test.meters;
- 查询 location = "California.SanFrancisco" 的记录总条数
SELECT COUNT(*) FROM test.meters WHERE location = "California.SanFrancisco";
- 查询 groupId = 10 的所有记录的平均值、最大值、最小值
SELECT AVG(current), MAX(voltage), MIN(phase) FROM test.meters WHERE groupId = 10;
- 对表 d1001 按每 10 秒进行平均值、最大值和最小值聚合统计
SELECT _wstart, AVG(current), MAX(voltage), MIN(phase) FROM test.d1001 INTERVAL(10s);
在上面的查询中,使用系统提供的伪列 _wstart 来给出每个窗口的开始时间。
相关文章:
tdengine学习笔记
官方文档:用 Docker 快速体验 TDengine | TDengine 文档 | 涛思数据 整体架构 TDENGINE是分布式,高可靠,支持水平扩展的架构设计 TDengine分布式架构的逻辑结构图如下 一个完整的 TDengine 系统是运行在一到多个物理节点上的,包含…...

机器学习-36-对ML的思考之机器学习研究的初衷及科学研究的期望
文章目录 1 机器学习最初的样子1.1 知识工程诞生(专家系统)1.2 知识工程高潮期1.3 专家系统的瓶颈(知识获取)1.4 机器学习研究的初衷2 科学研究对机器学习的期望2.1 面向科学研究的机器学习轮廓2.2 机器学习及其应用研讨会2.3 智能信息处理系列研讨会2.4 机器学习对科学研究的重…...

Linux 进程信号的产生
目录 0.前言 1. 通过终端按键产生信号 1.1 CtrlC:发送 SIGINT 信号 1.2 Ctrl\:发送 SIGQUIT 信号 1.3 CtrlZ:发送 SIGTSTP 信号 2.调用系统命令向进程发信号 3.使用函数产生信号 3.1 kill 函数 3.2 raise 函数 3.3 abort 函数 4.由软件条件产…...

CentOS8 在MySQL8.0 实现半同步复制
#原理 MySQL默认是异步的,不要求必须全部同步到从节点才返回成功结果; 同步复制: 用户发请求到代理, 代理收到请求后写/更新数据库写入到二进制日志bin_log, 然后必须等数据发到所有的从节点, 从节点全部收到数据后, 主节点才返回给客户端的成功结果。 弊端: 客…...

数据分析——Python绘制实时的动态折线图
最近在做视觉应用开发,有个需求需要实时获取当前识别到的位姿点位是否有突变,从而确认是否是视觉算法的问题,发现Python的Matplotlib进行绘制比较方便。 目录 1.数据绘制2.绘制实时的动态折线图3.保存实时数据到CSV文件中 import matplotlib.…...

【Redis】Redis的一些应用场景及使用策略
应用的场景 Redis 是一个高性能的内存数据库,广泛用于各种应用场景,以下是一些常见的应用场景: 缓存:Redis 的高读写性能使其非常适合作为缓存层,存储频繁访问的数据以减少数据库负载和加快响应时间。例如,…...
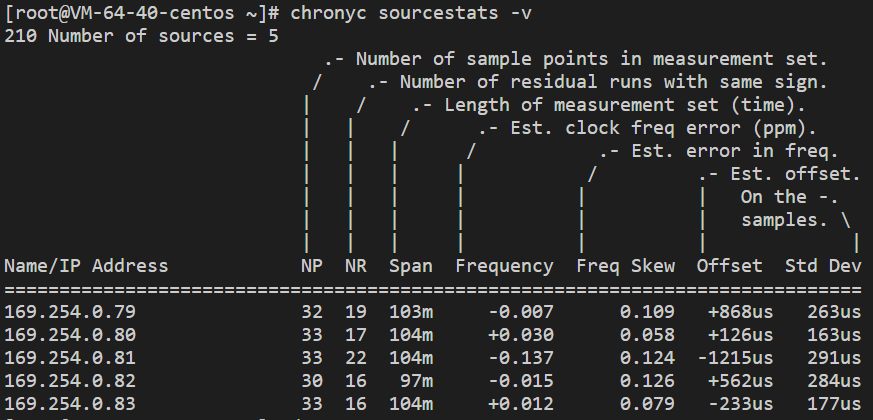
CentOS 8 安装 chronyd 服务
操作场景 目前原生 CentOS 8 不支持安装 ntp 服务,因此会发生时间不准的问题,需使用 chronyd 来调整时间服务。CentOS 8以及 TencentOS 3.1及以上版本的实例都使用 chronyd 服务实现时钟同步。本文介绍了如何在 CentOS 8 操作系统的腾讯云服务器上安装并…...

HarmonyOS ArkUI(基于ArkTS) 常用组件
一 Button 按钮 Button是按钮组件,通常用于响应用户的点击操作,可以加子组件 Button(我是button)Button(){Text(我是button)}type 按钮类型 Button有三种可选类型,分别为胶囊类型(Capsule)、圆形按钮(Circle…...
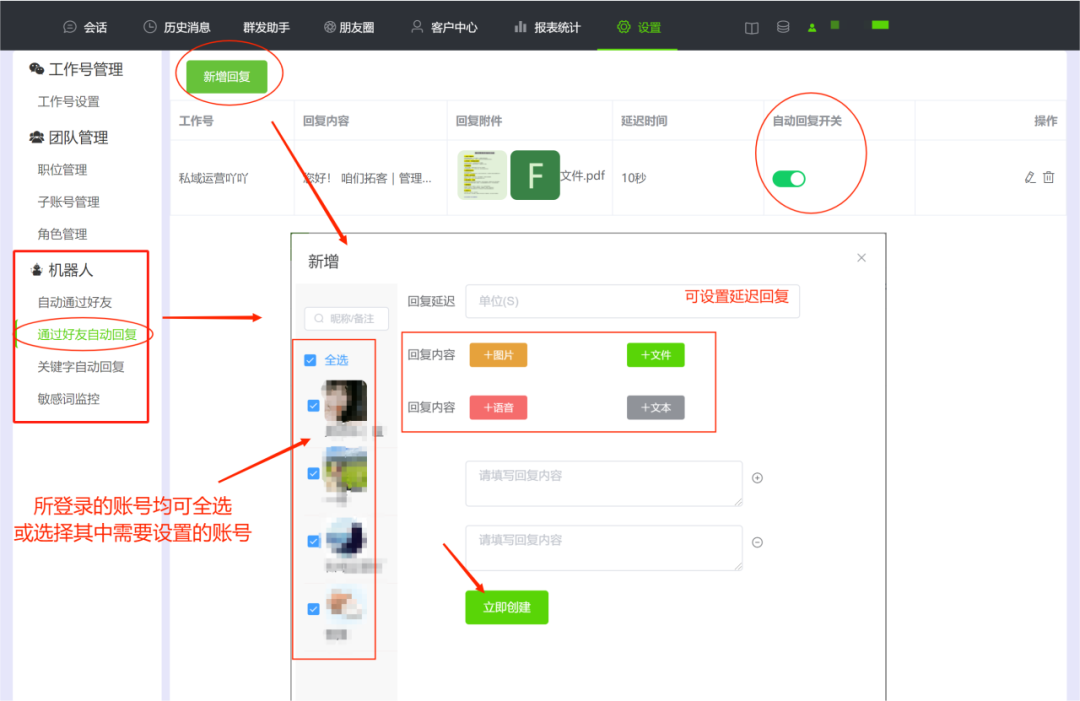
不用来回切换,一个界面管理多个微信
你是不是也有多个微信号需要管理? 是不是也觉得频繁切换账号很麻烦? 是不是也想提升多账号管理的效率? 在工作中,好的辅助工具,能让我们的效率加倍增长! 今天, 就给大家分享一个多微管理工具…...

MySQL系统优化
文章目录 MySQL系统优化第一章:引言第二章:MySQL服务架构优化1. 读写分离2. 水平分区与垂直分区3. 缓存策略 第三章:MySQL配置优化1. 内存分配优化Buffer Pool 的优化查询缓存与表缓存Key Buffer 2. 连接优化最大连接数会话超时连接池 3. 日志…...
:芋道的Docker容器化部署)
若依笔记(八):芋道的Docker容器化部署
目录 增加环境变量 DockerFile与镜像制作 nginx配置 vue3前端工程 首先搞个ECS阿里主机,1核4g足够,最大程度保证是docker运行来减少主机资源占用,同时因为是公有云,端口策略安全很重要,每个对外服务的端口要通过安全组放开; mysql的docker使用8版本,启动时候给my.cn…...

前端隐藏元素的方式有哪些?HTML 和 CSS 中隐藏元素的多种方法
当面试官突然问你:“前端隐藏元素的方式有哪些?”你还是只知道 display: none 吗? 其实,在前端开发的世界里,隐藏元素的方法非常多。每种方法都有自己的小技巧和使用场景,了解它们不仅能让你应对自如&…...

sqli—labs靶场 5-8关 (每日4关练习)持续更新!!!
Less-5 上来先进行查看是否有注入点,判断闭合方式,查询数据列数,用union联合注入查看回显位,发现到这一步的时候,和前四道题不太一样了,竟然没有回显位??? 我们看一下源…...

【Java】异常处理实例解析
文章目录 Java异常处理实例解析Example01_2023yang:未处理的异常Example02_2023yang:捕获并处理异常Example03_2023yang:finally块的使用Example04_2023yang:自定义异常Example05_2023yang:忽略异常信息Example06_2023…...

flutter调试
上面的调试The following FormatException was thrown while handling a gesture: Invalid double -Infinity874When the exception was thrown, this was the stack: #0 double.parse (dart:core-patch/double_patch.dart:113:28) #1 _CalculatorScreenState._butt…...
使用Web Workers提升JavaScript的并行处理能力
💓 博客主页:瑕疵的CSDN主页 📝 Gitee主页:瑕疵的gitee主页 ⏩ 文章专栏:《热点资讯》 使用Web Workers提升JavaScript的并行处理能力 使用Web Workers提升JavaScript的并行处理能力 使用Web Workers提升JavaScript的…...
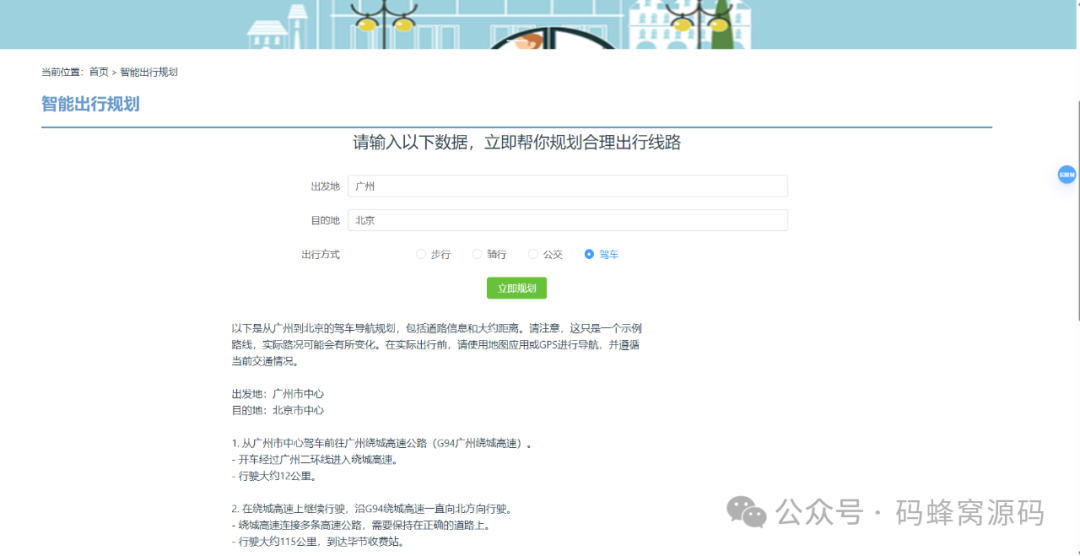
【含开题报告+文档+PPT+源码】基于Spring Boot智能综合交通出行管理平台的设计与实现
开题报告 随着城市规模的不断扩大和交通拥堵问题的日益严重,综合交通出行管理平台的研究与实现显得尤为重要。现代城市居民对于出行的需求越来越多样化,对于交通信息的获取和处理能力也提出了更高的要求。传统的交通管理方式已经难以满足这些需求&#…...

STM32寄存器结构体详解
一、寄存器结构体详解 对于STM32而言,使用一个结构体将一个外设的所有寄存器都放到一起 二、修改驱动 1、添加清除bss段代码 2、添加寄存器结构体 在寄存器结构体中添加寄存器的时候一定要注意地址的连续性,如果地址不连续的话,要添加占位…...

如何建立devops?
要建立DevOps系统,可以遵循以下步骤: 一、明确目标与确立原则 明确目标:确定DevOps系统的总体目标,例如提高软件发布频率、缩短反馈时间、提升软件质量等。确立原则:确立DevOps的核心原则,包括持续集成&a…...

shell基础(3)
声明! 学习视频来自B站up主 **泷羽sec** 有兴趣的师傅可以关注一下,如涉及侵权马上删除文章,笔记只是方便各位师傅的学习和探讨,文章所提到的网站以及内容,只做学习交流,其他均与本人以及泷羽sec团…...

杰理701N可视化SDK:从stream.bin生成到工程导入的EQ调音闭环
1. 杰理701N可视化SDK与EQ调音基础 第一次接触杰理701N的开发者可能会好奇,这个可视化SDK到底能做什么?简单来说,它就像给声学工程师配了一把"声音雕刻刀"。通过图形化界面,你可以实时调整蓝牙耳机、音箱等设备的音效表…...

用ZYNQ和LWIP搞定8路ADS8681数据采集:从Vivado Block Design到上位机TCP通信的完整流程
ZYNQ与LWIP构建的8通道高速数据采集系统实战指南 在工业自动化、测试测量和科研领域,多通道高精度数据采集系统正变得越来越重要。本文将详细介绍如何利用Xilinx ZYNQ SoC和LWIP协议栈,构建一个支持8路ADS8681同步采集的实时数据传输系统。不同于简单的代…...

QKeyMapper深度解析:现代输入设备管理系统的架构揭秘与实战指南
QKeyMapper深度解析:现代输入设备管理系统的架构揭秘与实战指南 【免费下载链接】QKeyMapper [按键映射工具] QKeyMapper,Qt开发Win10&Win11可用,不修改注册表、不需重新启动系统,可立即生效和停止。支持游戏手柄映射到键鼠&a…...

防火门安装与验收要点|闭门器、密封条、顺序器缺一不可
防火门安装与验收要点一、必备配件(缺一不可)闭门器:自动关门,火灾常态闭合防火密封条:遇火膨胀,隔烟阻火顺序器:双扇门专用,保证先后闭合二、安装要点门框墙体嵌实牢固,…...

多智能体的协作成本:沟通开销、上下文膨胀与优化手段
多智能体的协作成本:沟通开销、上下文膨胀与优化手段 1. 标题 (Title) 多智能体系统的协作困境:解析沟通开销与上下文膨胀 从理论到实践:优化多智能体协作成本的完整指南 协作的代价:多智能体系统中的沟通、上下文与优化策略 打破协作壁垒:如何有效降低多智能体系统的运行…...

从分布式到可分发:大规模软件制品分发架构设计与实践
1. 项目概述:从“分布式”到“可分发”的思维跃迁最近在梳理团队内部的基础设施时,又翻出了distr-sh/distr这个项目。说实话,第一次看到这个仓库名,我下意识地把它归类为又一个“分布式系统”框架。但当我真正点进去,花…...

Apex Legends进阶指南:结构化训练框架与技能模块化拆解
1. 项目概述:一个面向Apex Legends玩家的成长型技能库如果你是一位《Apex Legends》的玩家,并且对提升自己的游戏水平有持续的热情,那么你很可能和我一样,经历过一个漫长的摸索期。从最初落地成盒,到逐渐熟悉地图、枪械…...
,现在必须掌握的3种替代渲染方案)
像素艺术家紧急预警:Midjourney即将关闭--tile参数兼容性(倒计时14天),现在必须掌握的3种替代渲染方案
更多请点击: https://intelliparadigm.com 第一章:像素艺术家紧急预警:Midjourney即将关闭--tile参数兼容性(倒计时14天) Midjourney v6.5 已正式宣布将于 14 天后终止对 --tile 参数的原生支持,此举将直…...
)
设计师速存!Midjourney未公开的风格隐藏开关:--style raw、--s 750、--no texture三者协同作用的神经渲染原理(GPU显存占用下降41%实测)
更多请点击: https://intelliparadigm.com 第一章:设计师速存!Midjourney未公开的风格隐藏开关:--style raw、--s 750、--no texture三者协同作用的神经渲染原理(GPU显存占用下降41%实测) Midjourney v6.1…...

飞书自动化工具feishu-atuo:Python积木式开发与实战指南
1. 项目概述:飞书自动化,从零到一的效率革命 如果你和我一样,每天的工作流里都离不开飞书,那你肯定也经历过这些时刻:手动把日报、周报从文档复制到表格里归档;在多个群里重复发送同样的通知;为…...