51c扩散模型~合集1
我自己的原文哦~ https://blog.51cto.com/whaosoft/11541675
#Diffusion Forcing
无限生成视频,还能规划决策,扩散强制整合下一token预测与全序列扩散
当前,采用下一 token 预测范式的自回归大型语言模型已经风靡全球,同时互联网上的大量合成图像和视频也早已让我们见识到了扩散模型的强大之处。
近日,MIT CSAIL 的一个研究团队(一作为 MIT 在读博士陈博远)成功地将全序列扩散模型与下一 token 模型的强大能力统合到了一起,提出了一种训练和采样范式:Diffusion Forcing(DF)。
论文标题:Diffusion Forcing:Next-token Prediction Meets Full-Sequence Diffusion
论文地址:https://arxiv.org/pdf/2407.01392
项目网站:https://boyuan.space/diffusion-forcing
代码地址:https://github.com/buoyancy99/diffusion-forcing
如下所示,扩散强制在一致性和稳定性方面都明显胜过全序列扩散和教师强制这两种方法。

在该框架中,每个 token 都关联了一个随机的、独立的噪声水平,并且可使用一种共享的下一 token 预测模型或下几 token 预测模型根据任意的、独立的、每 token 的方案对 token 进行去噪。
该方法的研究灵感来自这一观察:对 token 加噪声的过程就是一种形式的部分掩码过程 —— 零噪声就意味着未对 token 加掩码,而完整噪声则是完全掩蔽 token。因此,DF 可强迫模型学习去除任何可变有噪声 token 集合的掩码(图 2)。

与此同时,通过将预测方法参数化为多个下一 token 预测模型的组合,该系统可以灵活地生成不同长度的序列,并以组合方式泛化到新的轨迹(图 1)。

该团队将用于序列生成的 DF 实现成了因果扩散强制(Causal Diffusion Forcing/CDF),其中未来 token 通过一个因果架构依赖于过去 token。他们训练该模型一次性去噪序列的所有 token(其中每个 token 都有独立的噪声水平)。
在采样期间,CDF 会将一个高斯噪声帧序列逐渐地去噪成洁净的样本,其中不同帧在每个去噪步骤可能会有不同的噪声水平。类似于下一 token 预测模型,CDF 可以生成长度可变的序列;不同于下一 token 预测,CDF 的表现非常稳定 —— 不管是预测接下来的一个 token,还是未来的数千 token,甚至是连续 token。
此外,类似于全序列扩散,它也可接收引导,从而实现高奖励生成。通过协同利用因果关系、灵活的范围和可变噪声调度,CDF 能实现一项新功能:蒙特卡洛树引导(MCTG)。相比于非因果全序列扩散模型,MCTG 能极大提升高奖励生成的采样率。图 1 给出了这些能力的概况。
Diffusion Forcing(扩散强制)
1、将加噪过程视为部分掩码
首先,我们可以将任意 token 集合(不管是否为序列)视为一个通过 t 索引的有序集合。那么,使用教师强制(teacher forcing)训练下一 token 预测便可被解释成掩蔽掉时间 t 的每个 token x_t 基于过去 x_{1:t−1} 预测它们。
对于序列,可将这种操作描述成:沿时间轴执行掩码。我们可以将全序列前向扩散(即逐渐向数据
![]()
添加噪声的过程)看作一种部分掩码(partial masking),这可被称为「沿噪声轴执行掩码)。
事实上,在 K 步加噪之后,
![]()
(大概)就是白噪声了,不再有任何有关原数据的信息。
如图 2 所示,该团队建立了一个统一视角来看待沿这两个轴的掩码。
2、扩散强制:不同 token 的噪声水平不同
扩散强制(DF)框架可用于训练和采样任意序列长度的有噪声 token

,其中的关键在于每个 token 的噪声水平 k_t 会随时间步骤而变化。
这篇论文关注的重点是时间序列数据,因此他们通过一种因果架构实例化了 DF,并由此得到了因果扩散强制(CDF)。简单来说,这是使用基础循环神经网络(RNN)获得的一种最小实现。
权重为 θ 的 RNN 维护着获悉过去 token 影响的隐藏状态 z_t,其会通过一个循环层根据动态
![]()
而演化。当获得输入噪声观察
![]()
时,就以马尔可夫方式更新该隐藏状态。
当 k_t=0 时,这就是贝叶斯过滤中的后验更新;而当 k_t= K(纯噪声、无信息)时,这就等价于建模贝叶斯过滤中的「后验分布」p_θ(z_t | z_{t−1})。
给定隐藏状态 z_t,观察模型 p_θ(x_t^0 | z_t) 的目标是预测 x_t;这个单元的输入 - 输出行为与标准的条件扩散模型一样:以条件变量 z_{t−1} 和有噪声 token 为输入,预测无噪声的 x_t=x_t^0,并由此间接地通过仿射重新参数化预测噪声 ε^{k_t}。因此,我们就可以直接使用经典的扩散目标来训练(因果)扩散强制。根据噪声预测结果 ε_θ,可以对上述单元进行参数化。然后,通过最小化以下损失来找到参数 θ:

算法 1 给出了伪代码。重点在于,该损失捕获了贝叶斯过滤和条件扩散的关键元素。该团队也进一步重新推断了用于扩散强制的扩散模型训练中的常用技术,详见原论文的附录部分。他们也得出了一个非正式的定理。

定理 3.1(非正式)。扩散强制训练流程(算法 1)是在期望对数似然
![]()
上优化证据下限(ELBO)的重新加权,其中期望值会在噪声水平上平均,而
![]()
是根据前向过程加噪。此外,在适当条件下,优化 (3.1) 式还可以同时最大化所有噪声水平序列的似然下限。
扩散强制采样和所得到的能力
算法 2 描述了采样过程,其定义是:在二维的 M × T 网格 K ∈ [K]^{M×T} 上指定噪声调度;其中列对应于时间步骤 t,m 索引的行则决定了噪声水平。

为了生成长度为 T 的整个序列,先将 token x_{1:T} 初始化为白噪声,对应于噪声水平 k = K。然后沿着网格逐行向下迭代,并从左到右逐列去噪,直到噪声水平达到 K。到最后一行 m = 0 时,token 的噪声已清理干净,即噪声水平为 K_{0,t} ≡ 0。
这个采样范式会带来如下新能力:
- 让自回归生成变得稳定
- 保持未来的不确定
- 长期引导能力
将扩散强制用于灵活的序列决策
扩散强制的新能力也带来了新的可能性。该团队基于此为序列决策(SDM)设计了一种全新框架,并且将其成功应用到了机器人和自主智能体领域。
首先,定义一个马尔可夫决策过程,该过程具有动态 p (s_{t+1}|s_t, a_t)、观察 p (o_t|s_t) 和奖励 p (r_t|s_t, a_t)。这里的目标是训练一个策略 π(a_t|o_{1:t}),使得轨迹
![]()
的预期累积奖励最大化。这里分配 token x_t = [a_t, r_t, o_{t+1}]。一条轨迹就是一个序列 x_{1:T},其长度可能是可变的;训练方式则如算法 1 所示。
在执行过程的每一步 t,都有一个隐藏状态 z_{t-1} 总结过去的无噪声 token x_{1:t-1}。基于这个隐藏状态,根据算法 2 采样一个规划
![]()
,其中
![]()
包含预测的动作、奖励和观察。H 是一个前向观察窗口,类似于模型预测控制中的未来预测。在采用了规划的动作之后,环境会得到一个奖励和下一个观察,从而得到下一个 token。其中隐藏状态可以根据后验 p_θ(z_t|z_{t−1}, x_t, 0) 获得更新。
该框架既可以作为策略,也可以作为规划器,其优势包括:
- 具有灵活的规划范围
- 可实现灵活的奖励引导
- 能实现蒙特卡洛树引导(MCTG),从而实现未来不确定性
实验
该团队评估了扩散强制作为生成序列模型的优势,其中涉及视频和时间序列预测、规划和模仿学习等多种应用。
视频预测:一致且稳定的序列生成和无限展开
针对视频生成式建模任务,他们基于 Minecraft 游戏视频和 DMLab 导航为因果扩散强制训练了一个卷积 RNN 实现。
图 3 展示了扩散强制与基准的定性结果。

可以看到,扩散强制能稳定地展开,甚至能超过其训练范围;而教师强制和全序列扩散基准会很快发散。
扩散规划:MCTG、因果不确定性、灵活的范围控制
扩散强制的能力能为决策带来独有的好处。该团队使用一种标准的离线强化学习框架 D4RL 评估了新提出的决策框架。

表 1 给出了定性和定量的评估结果。可以看到,扩散强制在全部 6 个环境中都优于 Diffuser 和所有基准。

可控的序列组合生成
该团队发现,仅需修改采样方案,就可以灵活地组合训练时间观察到的序列的子序列。
他们使用一个 2D 轨迹数据集进行了实验:在一个方形平面上,所有轨迹都是始于一角并最终到达对角,形成一种十字形。
如上图 1 所示,当不需要组合行为时,可让 DF 保持完整记忆,复制十字形的分布。当需要组合时,可让模型使用 MPC 无记忆地生成更短的规划,从而实现对这个十字形的子轨迹的缝合,得到 V 形轨迹。
机器人:长范围模仿学习和稳健的视觉运动控制
扩散强制也为真实机器人的视觉运动控制带来了新的机会。
模仿学习是一种常用的机器人操控技术,即学习专家演示的观察到动作的映射。但是,缺乏记忆往往会让模仿学习难以完成长范围的任务。DF 不仅能缓解这个短板,还能让模仿学习更稳健。
使用记忆进行模仿学习。通过遥控 Franka 机器人,该团队收集了一个视频和动作数据集。如图 4 所示,任务就是利用第三个位置交换苹果和橘子的位置。水果的初始位置是随机的,因此可能的目标状态有两个。

此外,当第三个位置有一个水果时,就无法通过当前观察推断出所需结果 —— 策略必须记住初始配置才能决定移动哪个水果。不同于常用的行为克隆方法,DF 可以自然地将记忆整合进自己的隐藏状态中。结果发现,DF 能实现 80% 的成功率,而扩散策略(当前最佳的无记忆模仿学习算法)却失败了。
此外,DF 还能更稳健地应对噪声并助益机器人预训练。
时间序列预测:扩散强制是一种优秀的通用序列模型
对于多变量时间序列预测任务,该团队的研究表明 DF 足以与之前的扩散模型和基于 Transformer 的模型媲美。
#定制适合自己的 Diffusers 扩散模型训练脚本
本文介绍了如何定制Diffusers库的训练脚本,通过重构使其更兼容多种模型训练,分享了作者的GitHub代码示例。作者提出了一套设计原则,通过创建数据类和接口类来解耦训练逻辑,简化添加新任务的过程,并讨论了重构代码的体会。
Diffusers 库为社区用户提供了多种扩散模型任务的训练脚本。每个脚本都平铺直叙,没有多余的封装,把训练的绝大多数细节都写在了一个脚本里。这种设计既能让入门用户在不阅读源码的前提下直接用脚本训练,又方便高级用户直接修改脚本。
可是,这种设计就是最好的吗?关于训练脚本的最佳设计风格,社区用户们往往各执一词。有人更喜欢更贴近 PyTorch 官方示例的写法,而有人会喜欢用 PyTorch Lightning 等封装度高、重复代码少的库。而在我看来,选择哪种风格的训练脚本,确实是个人喜好问题。但是,在开始使用训练脚本之前,我们要从细节入手,理解训练脚本到底要做哪些事。学懂了之后,不管是用别人的训练库,还是定制适合自己的训练脚本,都是很轻松的。不管怎么说,Diffusers 的这种训练脚本是一份很好的学习素材。
当然,我在用 Diffusers 的训练脚本时,发现一旦涉及多类任务的训练,比如既要能训练 Stable Diffusion,又要能训练 VAE,那么这份脚本就会用起来比较困难,而写两份训练脚本又会有很大的冗余。Diffusers 的训练脚本依然有改进的空间。
在这篇文章中,我会主要面向想系统性学习扩散模型训练框架的读者,先详细介绍 Diffusers 官方训练脚本,再分享我重构训练脚本的过程,使得脚本能够更好地兼容多类模型的训练。文章的末尾,我会展示几个简单的扩散模型训练实例。
在阅读本文时,建议大家用电脑端,一边看源代码一边读文章。「官方训练脚本细读」一节细节较多,初次阅读时可以快速浏览,看完「训练脚本内容总结」中的流程图,再回头仔细看一遍。
准备源代码
我们将以最简单的 DDPM 官方训练脚本 examples/unconditional_image_generation/train_unconditional.py 为例,学习训练脚本的通用写法。examples 文件夹在位于 Diffusers 官方 GitHub 仓库中,用 pip 安装的 Diffusers 可能没有这个文件夹,最好是手动 clone 官方仓库,再在本地查看这个文件夹。使用 Diffusers 训练时,可能还要安装其他库。官方在不同的训练教程里给了不同的安装指令,建议大家都安装上。
cd examples/text_to_image
pip install -r requirements.txt
pip install diffusers[training]我为本教程准备的脚本在仓库 https://github.com/SingleZombie/DiffusersExample 中。请 clone 这个仓库,再切换到 TrainingScript 目录下。train_official.py 是原官方训练脚本 train_unconditional.py,train_0.py 是第一次修改后的训练脚本 ,train_1.py 是第二次修改后的训练脚本。
官方训练脚本细读
先拉到文件的最底部,我们能在这找到程序的入口。在 parse_args 函数中,脚本会用 argparse 库解析命令行参数,并将所有参数保存在 args 里。args 会传进 main 函数里。稍后我们看到所有 args. 打头的变量调用,都表明该变量来自于命令行参数。
if __name__ == "__main__":args = parse_args()main(args)接着,我们正式开始学习训练主函数。一开始,函数会配置 accelerate 库及日志记录器。
logging_dir = os.path.join(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)# a big number for high resolution or big dataset
kwargs = InitProcessGroupKwargs(timeout=timedelta(seconds=7200))
accelerator = Accelerator(...)if args.logger == "tensorboard":if not is_tensorboard_available():...elif args.logger == "wandb":if not is_wandb_available():...import wandb在配置日志的中途,函数插入了一段修改模型存取逻辑的代码。为了让我们阅读代码的顺序与实际运行顺序一致,我们等待会用到了这段代码时再回头来读。
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):def save_model_hook(models, weights, output_dir):...def load_model_hook(models, input_dir):...跳过上面的代码,还是日志配置。
# Make one log on every process with the configuration for debugging.
logging.basicConfig(format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",datefmt="%m/%d/%Y %H:%M:%S",level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:datasets.utils.logging.set_verbosity_warning()diffusers.utils.logging.set_verbosity_info()
else:datasets.utils.logging.set_verbosity_error()diffusers.utils.logging.set_verbosity_error()之后其他版本的训练脚本会有一段设置随机种子的代码,我们给这份脚本补上。
# If passed along, set the training seed now.
if args.seed is not None:set_seed(args.seed)接着,函数会创建输出文件夹。如果我们想把模型推送到在线仓库上,函数还会创建一个仓库。这段代码还出现了一行比较重要的判断语句:if accelerator.is_main_process:。在多卡训练时,只有主进程会执行这个条件语句块里的内容。该判断在并行编程中十分重要。很多时候,比如在输出、存取模型时,我们只需要让一个进程执行操作就行了。这个时候就要用到这行判断语句。
# Handle the repository creation
if accelerator.is_main_process:if args.output_dir is not None:os.makedirs(args.output_dir, exist_ok=True)if args.push_to_hub:repo_id = create_repo(...).repo_id准备完辅助工具后,函数开始准备模型。输入参数里的 model_config_name_or_path 表示预定义的模型配置文件。如果该配置文件不存在,则函数会用默认的配置创建一个 DDPM 的 U-Net 模型。在写我们自己的训练脚本时,我们需要在这个地方初始化我们需要的所有模型。比如训练 Stable Diffusion 时,除了 U-Net,需要在此处准备 VAE、CLIP 文本编码器。
# Initialize the model
if args.model_config_name_or_path is None:model = UNet2DModel(...)
else:config = UNet2DModel.load_config(args.model_config_name_or_path)model = UNet2DModel.from_config(config)这份脚本还帮我们写好了维护 EMA(指数移动平均)模型的功能。EMA 模型用于存储模型可学习的参数的局部平均值。有时 EMA 模型的效果会比原模型要好。
# Create EMA for the model.
if args.use_ema:ema_model = EMAModel(model.parameters(),model_cls=UNet2DModel,model_config=model.config,...)此处函数还会根据 accelerate 配置自动设置模型的精度。
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":weight_dtype = torch.float16args.mixed_precision = accelerator.mixed_precision
elif accelerator.mixed_precision == "bf16":weight_dtype = torch.bfloat16args.mixed_precision = accelerator.mixed_precision函数还会尝试启用 xformers 来提升 Attention 的效率。PyTorch 在 2.0 版本也加入了类似的 Attention 优化技术。如果你的显卡性能有限,且 PyTorch 版本小于 2.0,可以考虑使用 xformers。
if args.enable_xformers_memory_efficient_attention:if is_xformers_available():...准备了 U-Net 后,函数会准备噪声调度器,即定义扩散模型的细节。
注意,扩散模型不是一个神经网络,而是一套定义了加噪、去噪公式的模型。扩散模型中需要一个去噪模型来去噪,去噪模型一般是一个神经网络。
# Initialize the scheduler
accepts_prediction_type = "prediction_type" in set(inspect.signature(DDPMScheduler.__init__).parameters.keys())
if accepts_prediction_type:noise_scheduler = DDPMScheduler(...)
else:noise_scheduler = DDPMScheduler(...)准备完所有扩散模型组件后,函数开始准备其他和训练相关的模块。其他版本的训练脚本会在这个地方加一段缓存梯度和自动放缩学习率的代码,我们给这份脚本补上。
if args.gradient_checkpointing:unet.enable_gradient_checkpointing()if args.scale_lr:args.learning_rate = (args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes)函数先准备的训练模块是优化器。这里默认使用的优化器是 AdamW。
optimizer = torch.optim.AdamW(model.parameters(),lr=args.learning_rate,betas=(args.adam_beta1, args.adam_beta2),weight_decay=args.adam_weight_decay,eps=args.adam_epsilon,
)函数随后会准备训练集。这个脚本用 HuggingFace 的 datasets 库来管理数据集。我们既可以读取在线数据集,也可以读取本地的图片文件夹数据集。自定义数据集的方法可以参考 https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder 。
if args.dataset_name is not None:dataset = load_dataset(args.dataset_name,args.dataset_config_name,cache_dir=args.cache_dir,split="train",)
else:dataset = load_dataset("imagefolder", data_dir=args.train_data_dir, cache_dir=args.cache_dir, split="train")# See more about loading custom images at# https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder有了数据集后,函数会继续准备 PyTorch 的 DataLoader。在这一步中,除了定义 DataLoader 外,我们还要编写数据预处理的方法。下面这段代码的编写顺序和执行顺序不同,我们按执行顺序来整理一遍下面的代码:
将预定义的预处理函数传给数据集对象 `dataset.set_transform(transform_images)`。在使用数据集里的数据时,才会调用这个函数预处理图像。使用 PyTorch API 定义 DataLoader。`train_dataloader = ...`每次用 DataLoader 获取数据时,一个数据词典 `examples` 会被传入预处理函数 `transform_images`。`examples` 里既包含了图像数据,也包含了数据的各种标签。而对于无约束图像生成任务,我们只需要图像数据,因此可以直接通过词典的 `"image"` 键得到 PIL 格式的图像数据。用 `convert("RGB")` 把图像转成三通道后,该 PIL 图像会被传入预处理流水线。图像预处理流水线 `augmentations` 是用 Torchvision 里的 `transform` API 定义的。默认的流水线包括短边缩放至指定分辨率、按分辨率裁剪、随机反转、归一化。处理过的数据会被存到词典的 `"input"` 键里。# Preprocessing the datasets and DataLoaders creation.
augmentations = transforms.Compose([transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.BILINEAR),transforms.CenterCrop(args.resolution) if args.center_crop else transforms.RandomCrop(args.resolution),transforms.RandomHorizontalFlip() if args.random_flip else transforms.Lambda(lambda x: x),transforms.ToTensor(),transforms.Normalize([0.5], [0.5]),]
)def transform_images(examples):images = [augmentations(image.convert("RGB"))for image in examples["image"]]return {"input": images}logger.info(f"Dataset size: {len(dataset)}")dataset.set_transform(transform_images)
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers
)在准备工作的最后,函数会准备学习率调度器。
# Initialize the learning rate scheduler
lr_scheduler = get_scheduler(args.lr_scheduler,optimizer=optimizer,num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,num_training_steps=(len(train_dataloader) * args.num_epochs),
)准备完了所有模块,函数会调用 accelerate 库来把所有模块变成适合并行训练的模块。
model, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(model, optimizer, train_dataloader, lr_scheduler
)if args.use_ema:ema_model.to(accelerator.device)之后函数还会用 accelerate 库配置训练日志。默认情况下日志名 run 由当前脚本名决定。如果不想让之前的日志被覆盖的话,可以让日志名 run 由当前的时间决定。
if accelerator.is_main_process:run = os.path.split(__file__)[-1].split(".")[0]accelerator.init_trackers(run)马上就要开始训练了。在此之前,函数会准备全局变量并记录日志。注意,这里函数会算一次总的 batch 数,它由输入 batch 数、进程数(显卡数)、梯度累计步数共同决定。梯度累计是一种用较少的显存实现大 batch 训练的技术。使用这项技术时,训练梯度不会每步优化,而是累计了若干步后再优化。
total_batch_size = args.train_batch_size * \accelerator.num_processes * args.gradient_accumulation_steps
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
max_train_steps = args.num_epochs * num_update_steps_per_epochlogger.info("***** Running training *****")
logger.info(f" Num examples = {len(dataset)}")
logger.info(f" Num Epochs = {args.num_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {max_train_steps}")global_step = 0
first_epoch = 0在开始训练前,如果设置了 args.resume_from_checkpoint,则函数会读取之前训练过的权重。负责读取训练权重的函数是 load_state。
if args.resume_from_checkpoint:if args.resume_from_checkpoint != "latest":path = ..else:# Get the most recent checkpoint...if path is None:...else:accelerator.load_state(os.path.join(args.output_dir, path))accelerator.print(f"Resuming from checkpoint {path}")...在每个 epoch 中,函数会重置进度条。接着,函数会进入每一个 batch 的训练迭代。
# Train!
for epoch in range(first_epoch, args.num_epochs):model.train()progress_bar = tqdm(total=num_update_steps_per_epoch,disable=not accelerator.is_local_main_process)progress_bar.set_description(f"Epoch {epoch}")for step, batch in enumerate(train_dataloader):如果是继续训练的话,训练开始之前会更新当前的步数 step。
# Skip steps until we reach the resumed step
if args.resume_from_checkpoint and epoch == first_epoch and step < resume_step:if step % args.gradient_accumulation_steps == 0:progress_bar.update(1)continue训练的一开始,函数会从数据的 "input" 键里取出图像数据。此处的键名是我们之前在数据预处理函数 transform_images 里写的。
clean_images = batch["input"].to(weight_dtype)之后函数会设置扩散模型训练中的其他变量,包含随机噪声、时刻。由于本文的重点并不是介绍扩散模型的原理,这段代码我们就快速略过。
noise = torch.randn(...)
timesteps =...
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)接下来,函数会用去噪网络做前向传播。为了让模型能正确累计梯度,我们要用 with accelerator.accumulate(model): 把模型调用与反向传播的逻辑包起来。在这段代码中,我们会先得到模型的输出 model_output,再根据扩散模型得到损失函数 loss,最后用 accelerate 库的 API accelerator 代替原来 PyTorch API 来完成反向传播、梯度裁剪,并完成参数更新、学习率调度器更新、优化器更新。
with accelerator.accumulate(model):# Predict the noise residualmodel_output = model(noisy_images, timesteps).sampleloss = ...accelerator.backward(loss)if accelerator.sync_gradients:accelerator.clip_grad_norm_(model.parameters(), 1.0)optimizer.step()lr_scheduler.step()optimizer.zero_grad()确保一步训练结束后,函数会更新和步数相关的变量。
if accelerator.sync_gradients:if args.use_ema:ema_model.step(model.parameters())progress_bar.update(1)global_step += 1在这个地方,函数还会尝试保存模型。默认情况下,每 args.checkpointing_steps 步保存一次中间结果。确认要保存后,函数会算出当前的保存点名称,并根据最大保存点数 checkpoints_total_limit 决定是否要删除以前的保存点。做完准备后,函数会调用 save_state 保存当前训练时的所有中间变量。
f accelerator.is_main_process:if global_step % args.checkpointing_steps == 0:if args.checkpoints_total_limit is not None:checkpoints = os.listdir(args.output_dir)checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))if len(checkpoints) >= args.checkpoints_total_limit:...save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")accelerator.save_state(save_path)logger.info(f"Saved state to {save_path}")在这个地方,主函数开头设置的存取模型回调函数终于派上用场了。在调用 save_state 时,会自动触发下面的回调函数来保存模型。如果不加下面的代码,所有模型默认会以 .safetensor 的形式存下来。而用了下面的代码后,模型能够被 save_pretrained 存进一个文件夹里,就像其他标准 Diffusers 模型一样。
这里的输入参数
models 来自于之前的 accelerator.prepare,感兴趣可以去阅读文档或源码。
def save_model_hook(models, weights, output_dir):if accelerator.is_main_process:if args.use_ema:ema_model.save_pretrained(os.path.join(output_dir, "unet_ema"))for i, model in enumerate(models):model.save_pretrained(os.path.join(output_dir, "unet"))# make sure to pop weight so that corresponding model is not saved againweights.pop()与上面的这段代码对应,脚本还提供了读取文件的回调函数。它会在继续中断的训练后调用 load_state 时被调用。
def load_model_hook(models, input_dir):if args.use_ema:load_model = EMAModel.from_pretrained(os.path.join(input_dir, "unet_ema"), UNet2DModel)ema_model.load_state_dict(load_model.state_dict())ema_model.to(accelerator.device)del load_modelfor i in range(len(models)):# pop models so that they are not loaded againmodel = models.pop()# load diffusers style into modelload_model = UNet2DModel.from_pretrained(input_dir, subfolder="unet")model.register_to_config(**load_model.config)model.load_state_dict(load_model.state_dict())del load_model两个回调函数需要用下面的代码来设置。
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)回到最新的代码处。训练迭代的末尾,脚本会记录当前步的日志。
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0], "step": global_step}
if args.use_ema:logs["ema_decay"] = ema_model.cur_decay_value
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)执行完了一个 epoch 后,脚本调用 accelerate API 保证所有进程均训练完毕。
progress_bar.close()
accelerator.wait_for_everyone()此处脚本可能会在主进程中验证模型或保存模型。如果当前是最后一个 epoch,或者达到了配置指定的验证/保存时刻,脚本就会执行验证/保存。
if accelerator.is_main_process:if epoch % args.save_images_epochs == 0 or epoch == args.num_epochs - 1:...if epoch % args.save_model_epochs == 0 or epoch == args.num_epochs - 1:...脚本默认的验证方法是随机生成图片,并用日志库保存图片。生成图片的方法是使用标准 Diffusers 采样流水线 DDPMPipeline。由于此时模型 model 可能被包裹成了一个用于多卡训练的 PyTorch 模块,需要用相关 API 把 model 解包成普通 PyTorch 模块 unet。如果使用了 EMA 模型,为了避免对 EMA 模型的干扰,此处需要先保存 EMA 模型参数,采样结束再还原参数。
if epoch % args.save_images_epochs == 0 or epoch == args.num_epochs - 1:unet = accelerator.unwrap_model(model)if args.use_ema:ema_model.store(unet.parameters())ema_model.copy_to(unet.parameters())pipeline = DDPMPipeline(unet=unet,scheduler=noise_scheduler,)generator = torch.Generator(device=pipeline.device).manual_seed(0)# run pipeline in inference (sample random noise and denoise)images = pipeline(...).imagesif args.use_ema:ema_model.restore(unet.parameters())# denormalize the images and save to tensorboardimages_processed = (images * 255).round().astype("uint8")if args.logger == "tensorboard":...elif args.logger == "wandb":...在保存模型时,脚本同样会先用去噪模型 model 构建一个流水线,再调用流水线的保存方法 save_pretrained 将扩散模型的所有组件(去噪模型、噪声调度器)保存下来。
if epoch % args.save_model_epochs == 0 or epoch == args.num_epochs - 1:# save the modelunet = accelerator.unwrap_model(model)if args.use_ema:ema_model.store(unet.parameters())ema_model.copy_to(unet.parameters())pipeline = DDPMPipeline(unet=unet,scheduler=noise_scheduler,)pipeline.save_pretrained(args.output_dir)if args.use_ema:ema_model.restore(unet.parameters())if args.push_to_hub:upload_folder(...)一个 epoch 训练的代码就到此结束了。所有 epoch 的训练结束后,脚本调用 API 结束训练。这个 API 会自动关闭所有的日志库。训练代码到这里也就结束了。
accelerator.end_training()训练脚本内容总结
大概熟悉了一遍这份训练脚本后,我们可以用下面的流程图概括训练脚本的执行顺序和主要内容。

去掉命令行参数
我不喜欢用命令行参数传训练参数,而喜欢把训练参数写进配置文件里,理由有:
- 我一般会直接在命令行里手敲命令。如果命令行参数过多,我则会把要运行的命令及其参数保存在某文件里。这样还不如把参数写在另外的文件里。
- 将大量参数藏在一个词典
args 里,而不是把所有需用的参数在某处定义好,是一种很差的编程方式。各个参数将难以追踪。
在正式重构脚本之前,我做的第一步是去掉脚本中原来的命令行参数,将所有参数先塞进一个数据类里面。脚本将只留一个命令行参数,表示参数配置文件的路径。具体做法如下:
先编写一个存命令行参数的数据类。这个类是一个 Python 的 dataclass。Python 中 dataclass 是一种专门用来放数据的类。定义数据类时,我们只需要定义类中所有数据的类型及默认值,不需要编写任何方法。初始化数据类时,我们只需要传一个词典或列表。一个示例如下(示例来源 https://www.geeksforgeeks.org/understanding-python-dataclasses/):
from dataclasses import dataclass# A class for holding an employees content
@dataclass
class employee:# Attributes Declaration# using Type Hintsname: stremp_id: strage: intcity: stremp1 = employee("Satyam", "ksatyam858", 21, 'Patna')
emp2 = employee("Anurag", "au23", 28, 'Delhi')
emp3 = employee({"name": "Satyam", "emp_id": "ksatyam858", "age": 21, "city": 'Patna'})print("employee object are :")
print(emp1)
print(emp2)
print(emp3)我们可以用 dataclass 编写一个存储所有命令行参数的数据类,该类开头内容如下:
from dataclasses import dataclass@dataclass
class BaseTrainingConfig:# Dirlogging_dir: stroutput_dir: str# Logger and checkpointlogger: str = 'tensorboard'checkpointing_steps: int = 500checkpoints_total_limit: int = 20valid_epochs: int = 100valid_batch_size: int = 1save_model_epochs: int = 100resume_from_checkpoint: str = None之后在训练脚本里,我们可以把旧的命令行参数全删了,再加一个命令行参数 cfg,表示训练配置文件的路径。我们可以用 omegaconf 打开这个配置文件,得到一个词典 data_dict,再用这个词典构建配置文件 cfg。接下来,只需要把原来代码里所有 args. 改成 cfg. 就行了。
from omegaconf import OmegaConf
from training_cfg_0 import BaseTrainingConfigparser = argparse.ArgumentParser()
parser.add_argument('cfg', type=str)
args = parser.parse_args()data_dict = OmegaConf.load(args.cfg)
cfg = BaseTrainingConfig(**data_dict)第一次修改过的训练脚本为 train_0.py,配置文件类在 training_cfg_0.py 里,示例配置文件为 cfg_0.json,一个简单 DDPM 模型配置写在 unet_cfg 目录里。可以直接运行下面的命令测试此训练脚本。
python train_0.py cfg_0.json在配置文件里,我们只需要改少量的训练参数就行了。如果想知道还有哪些参数可以改,可以去查看 training_cfg_0.py 文件。
{"logging_dir": "logs","output_dir": "models/ddpm_0","model_config": "unet_cfg","num_epochs": 10,"train_batch_size": 64,"checkpointing_steps": 5000,"valid_epochs": 1,"valid_batch_size": 4,"dataset_name": "ylecun/mnist","resolution": 32,"learning_rate": 1e-4
}读者感兴趣的话也可以尝试这样改一遍代码。这样做会强迫自己读一遍训练脚本,让自己更熟悉这份代码。
适配多种任务的训练脚本
如果只是训练一种任务,Diffusers 的这种训练脚本还算好用。但如果我们想用完全相同的训练流程训练多种任务,这种脚本的弊端就暴露出来了:
- 各任务的官方示例脚本本身就不完全统一。比如有的训练脚本支持设置随机种子,有的不支持。
- 一旦想修改训练过程,就得同时修改所有任务的脚本。这不符合编程中「代码复用」的思想。
为此,我想重构一下官方训练脚本,将训练流程和每种任务的具体训练过程解耦开,让一份训练脚本能够被多种任务使用。于是,我又从头过了一遍训练脚本,将代码分成两类:所有任务都会用到的代码、仅 DDPM 训练会用到的代码。如下图所示,我用红字表示了训练脚本中应该由具体任务决定的部分。

根据这个划分规则,我将仅和 DDPM 相关的代码剥离出来,并用一个描述某具体任务的训练器接口类的方法调用代替原有代码。这样,每次换一个训练任务,只需要重新实现一个训练器类就行了。如下图所示,原流程图中所有红字的内容都可以由接口类的方法代替。对于不同任务,我们需要实现不同的训练器类。

具体在代码中,我写了一个接口类 Trainer。
class Trainer(metaclass=ABCMeta):def __init__(self, weight_dtype, accelerator, logger, cfg):self.weight_dtype = weight_dtypeself.accelerator = acceleratorself.logger = loggerself.cfg = cfg@abstractmethoddef init_modules(self,enable_xformer: bool = False,gradient_checkpointing: bool = False):pass@abstractmethoddef init_optimizers(self, train_batch_size):pass@abstractmethoddef init_lr_schedulers(self, gradient_accumulation_steps, num_epochs):passdef set_dataset(self, dataset, train_dataloader):self.dataset = datasetself.train_dataloader = train_dataloader@abstractmethoddef prepare_modules(self):pass@abstractmethoddef models_to_train(self):pass@abstractmethoddef training_step(self, global_step, batch) -> dict:pass@abstractmethoddef validate(self, epoch, global_step):pass@abstractmethoddef save_pipeline(self):pass@abstractmethoddef save_model_hook(self, models, weights, output_dir):pass@abstractmethoddef load_model_hook(self, models, input_dir):pass根据类型名和初始化参数可以创建具体的训练器。
def create_trainer(type, weight_dtype, accelerator, logger, cfg_dict) -> Trainer:from ddpm_trainer import DDPMTrainerfrom sd_lora_trainer import LoraTrainer__TYPE_CLS_DICT = {'ddpm': DDPMTrainer,'lora': LoraTrainer}return __TYPE_CLS_DICT[type](weight_dtype, accelerator, logger, cfg_dict)原来训练脚本里的具体训练逻辑被接口类方法调用代替。比如:
# old
if cfg.model_config is None:model = UNet2DModel(...)
else:config = UNet2DModel.load_config(cfg.model_config)model = UNet2DModel.from_config(config)# Create EMA for the model.
if cfg.use_ema:ema_model = EMAModel(...)
...# new
trainer.init_modules(enable_xformers, cfg.gradient_checkpointing)原来仅和 DDPM 训练相关的代码全被我搬到了 DDPMTrainer 类中。与之对应,除了代码需要搬走外,原配置文件里的数据也需要搬走。我在 DDPMTrainer 类里加了一个 DDPMTrainingConfig 数据类,用来存对应的配置数据。
@dataclass
class DDPMTrainingConfig:# Diffuion Modelsmodel_config: strddpm_num_steps: int = 1000ddpm_beta_schedule: str = 'linear'prediction_type: str = 'epsilon'ddpm_num_inference_steps: int = 100...因此,我们需要用稍微复杂一点的方式来创建配置文件。现在全局训练配置和任务配置放在两组配置里。配置文件最外层除 "base" 外的那个键表明了训练器的类型。
{"base": {"logging_dir": "logs","output_dir": "models/ddpm_1","checkpointing_steps": 5000,"valid_epochs": 1,"dataset_name": "ylecun/mnist","resolution": 32,"train_batch_size": 64,"num_epochs": 10},"ddpm": {"model_config": "unet_cfg","learning_rate": 1e-4,"valid_batch_size": 4}
}__TYPE_CLS_DICT = {'base': BaseTrainingConfig,'ddpm': DDPMTrainingConfig,'lora': LoraTrainingConfig
}def load_training_config(config_path: str) -> Dict[str, BaseTrainingConfig]:data_dict = OmegaConf.load(config_path)# The config must have a "base" keybase_cfg_dict = data_dict.pop('base')# The config must have one another model configassert len(data_dict) == 1model_key = next(iter(data_dict))model_cfg_dict = data_dict[model_key]model_cfg_cls = __TYPE_CLS_DICT[model_key]return {'base': BaseTrainingConfig(**base_cfg_dict),model_key: model_cfg_cls(**model_cfg_dict)}这样改完过后,训练脚本开头也需要稍作更改,其他地方保持不变。
from training_cfg_1 import BaseTrainingConfig, load_training_config
from trainer import Trainer, create_trainerdef main():parser = argparse.ArgumentParser()parser.add_argument('cfg', type=str)args = parser.parse_args()cfgs = load_training_config(args.cfg)cfg: BaseTrainingConfig = cfgs.pop('base')trainer_type = next(iter(cfgs))trainer_cfg_dict = cfgs[trainer_type]...trainer: Trainer = create_trainer(trainer_type, weight_dtype, accelerator, cfg.logger, trainer_cfg_dict)这次修改过的训练脚本为 train_1.py,配置文件类在 training_cfg_1.py 里,DDPM 训练器在 TrainingScript/ddpm_trainer.py 里,示例配置文件为 cfg_1.json。可以直接运行下面的命令测试此训练脚本。
python train_1.py cfg_1.json运行这一版或者上一版的训练脚本后,我们都能很快训练完一个 MNIST 上的 DDPM 模型。从训练可视化结果可以看出,代码重构大概是没有出错,模型能正确生成图片。

对训练器类的程序设计思路感兴趣的话,欢迎阅读附录。
添加新的训练任务
为了验证这套新代码的可拓展性,我仿照 Diffusers 官方 SD LoRA 训练脚本 examples/text_to_image/train_text_to_image_lora.py,快速实现了一个 SD LoRA 训练器类。这个类在 sd_lora_trainer.py 文件里。
我来简单介绍添加新训练任务的过程。要添加新训练任务,要修改三处:
- 创建新文件,在文件里定义配置数据类及实现训练器类。
- 在
trainer.py 里导入新训练器类。 - 在
training_cfg_1.py 里导入新配置数据类。
先来看较简单的第二处和第三处修改。导入新训练器类只需要加一行 import 和一条词典项。
def create_trainer(type, weight_dtype, accelerator, logger, cfg_dict) -> Trainer:from ddpm_trainer import DDPMTrainerfrom sd_lora_trainer import LoraTrainer__TYPE_CLS_DICT = {'ddpm': DDPMTrainer,'lora': LoraTrainer}return __TYPE_CLS_DICT[type](weight_dtype, accelerator, logger, cfg_dict)导入新配置数据类也一样,一行 import 和一项词典项。
from sd_lora_trainer import LoraTrainingConfig__TYPE_CLS_DICT = {'base': BaseTrainingConfig,'ddpm': DDPMTrainingConfig,'lora': LoraTrainingConfig
}而实现一个训练器类会比较繁琐。我是先把 DDPM 训练器类复制了过来,在此基础上进行修改。由于 SD LoRA 训练器有官方训练脚本作为参考,我还是和之前实现 DDPM 训练器一样,从官方训练脚本里抠出对应代码,将其填入训练器类方法里。比如在初始化模块时,我们不仅需要初始化 U-Net,还有 VAE 等模块。在初始化优化器时,应该只优化 LoRA 参数。
class LoraTrainer(Trainer):def init_modules(self,enable_xformer=False,gradient_checkpointing=False):cfg = self.cfg# Load scheduler, tokenizer and models.self.noise_scheduler = DDPMScheduler...self.tokenizer = CLIPTokenizer...self.text_encoder = CLIPTextModel... self.vae = AutoencoderKL...self.unet = UNet2DConditionModel...# freeze parameters of models to save more memoryself.unet.requires_grad_(False)self.vae.requires_grad_(False)self.text_encoder.requires_grad_(False)for param in self.unet.parameters():param.requires_grad_(False)unet_lora_config = LoraConfig(...)self.lora_layers = filter(lambda p: p.requires_grad, self.unet.parameters())...def init_optimizers(self, train_batch_size):...self.optimizer = torch.optim.AdamW(self.lora_layers,...)SD LoRA 训练器类在 sd_lora_trainer.py 文件里,对应配置文件为 cfg_lora.json。用下面的代码即可尝试 LoRA 训练。
python train_1.py cfg_lora.json可能是 MNIST 数据集的图片太小了,而 SD 又是为较大的图片设计的,又或是 LoRA 的拟合能力有限,生成的效果不是很好。但可以看出,SD LoRA 学到了 MNIST 的图片风格。

就我自己使用下来,添加一个新的训练任务还是非常轻松的。我可以只关心初始化模型、训练、验证等实现细节,而不用关心那些通用的训练代码。当然,这份通用训练脚本还不够强大,还不能处理更复杂的数据集。SD LoRA 其实需要一个带文本标注的数据集,但由于我只是想测试添加新训练器的难度,就没有去改数据集,只是默认用了空文本来训练 LoRA。
总结
我自己在使用 Diffusers 训练脚本时,发现这种训练脚本难以适配多任务训练,于是重构了一份拓展性更强的训练脚本。在这篇文章中,我先是介绍了 Diffusers 训练脚本的通用框架,再分享了我改写脚本的过程。相信读者在读完本文后,不仅能够熟悉 Diffusers 训练脚本的具体原理,还能够动手修改它,或者基于我的这一版改进脚本,编写一份适合自己的训练脚本。
我重构的这套训练器也没有太多封装,在维持 Diffusers 那种平铺直叙风格的同时,将每种训练任务独有的代码、数据搬了出来,让开发者专注于编写新的逻辑。我没怎么用过别的训练框架,不太好直接对比。但至少相比于 PyTorch Lightning 那种模型和训练逻辑写在同一个类里的写法,我更认可 Diffusers 这种将模型结构和训练、采样分离的设计。这套框架的训练器也只有训练的逻辑,不会掺杂其他逻辑。
本文的代码链接为 https://github.com/SingleZombie/DiffusersExample/tree/main/TrainingScript
注意,这份代码是我随手写的,只测试了简单的训练命令。如果发现 bug,欢迎提 issue。这份代码仅供本文教学使用,功能有限,以后我会在其他地方更新这份代码。另外,以后我写其他训练教程时也会复用这套代码。
附录:训练器程序设计思路
在设计训练器接口类的接口时,其实我没有做多少主观设计,基本上都是按照一些设计原则,机械地将原来的训练脚本进行重构。我也不知道这些原则是怎么想出来的,只是根据我多年写代码的经验,我感觉按照这些规则做可以保证训练脚本和训练器之间耦合度更低,易于拓展。这些原则有:
- 如果在另一项任务里这行代码会变动,则这项代码应写入训练器类。
- 如果某一数据的调用全部都被放入了训练器类里,那么这个数据应该是训练器类的成员变量。如果该数据来自配置文件,则将该数据的定义从全局配置移入训练器配置。
- 如果某数据既要在训练脚本中使用,又要在训练器类里使用,则在训练脚本中初始化该数据,并以初始化参数或者接口参数两种方式将数据传入训练器。传入方式由数据被确定的时刻决定。比如脚本一开始就初始化好的日志对象应该作为初始化参数,而一些中途计算的当前 batch 数等参数应该作为接口参数。
- 原则上,训练脚本不从数据类里获取数据。
根据这些原则,在设计训练器接口类时,我并没有一开始就定下有哪些接口、接口的参数分别是什么,而是一边搬运代码,一边根据代码的实际内容动态地编写接口类。比如一开始,我的接口类构造函数并没有加入日志库类型。
class Trainer(metaclass=ABCMeta):def __init__(self, weight_dtype, accelerator, cfg):...后来写训练器验证方法时,我发现这里必须要获取日志类的类型,不得已在构造函数里多加了一个参数。
def validate(self, epoch, global_step):...if self.logger == "tensorboard":...def __init__(self, weight_dtype, accelerator, logger, cfg):原则 3 和原则 4 本质上是将训练脚本也看成一个对象。所有数据要么属于训练脚本,要么属于训练类。原则 4 不从训练器里获取信息,某种程度上体现了面向对象中的封装性,不让训练器去改训练脚本里的数据。我尽可能地遵守了原则 4,但只有一处例外。在调用 accelerate.prapare 后,train_dataloader 在训练器里发生了更改。而 train_dataloader 其实是属于训练脚本的。没办法,这里只能去训练器里获取一次数据。我没来得及仔细研究,说不定 accelerate.prapare 可以多次调用,这样我就能让训练脚本自己维护 train_dataloader。
trainer.prepare_modules()
train_dataloader = trainer.train_dataloader这样看下来,这份代码框架在各种角度上都有很大的改进空间。以后我会来慢慢改进这份代码。就目前的设计,训练中整体逻辑、数据集、训练器三部分应该是相互独立的。数据集我还没有单独拿出来写。应该至少实现纯图像、带文本标注图像这两种数据集。
这次重构之后,我也有一些程序设计上的体会。重构代码比从头做程序设计要简单很多。重构只需要根据已有代码,设计出一套更合理的逻辑,像我这样按照某些原则,无脑地修改代码就行了。而程序设计需要考虑未知的情况,为未来可能加入的功能铺路。也正因为从头设计更难,有时会出现设计过度或者设计不足的情况。感觉更合理的开发方式是从头设计与重构交替进行。
#StructLDM
南洋理工三维数字人生成新范式:结构扩散模型
该论文作者均来自于新加坡南洋理工大学 S-Lab 团队,包括博士后胡涛,博士生洪方舟,以及计算与数据学院刘子纬教授(《麻省理工科技评论》亚太地区 35 岁以下创新者)。S-Lab 近年来在顶级会议如 CVPR, ICCV, ECCV, NeurIPS, ICLR 上发表多篇 CV/CG/AIGC 相关的研究工作,和国内外知名高校、科研机构广泛开展合作。
三维数字人生成和编辑在数字孪生、元宇宙、游戏、全息通讯等领域有广泛应用。传统三维数字人制作往往费时耗力,近年来研究者提出基于三维生成对抗网络(3D GAN)从 2D 图像中学习三维数字人,极大提高了数字人制作效率。
这些方法往往在一维隐向量空间建模数字人,而一维隐向量无法表征人体的几何结构和语义信息,因此限制了其生成质量和编辑能力。
为了解决这一问题,来自新加坡南洋理工大学 S-Lab 团队提出结构化隐空间扩散模型(Structured Latent Diffusion Model)的三维数字人生成新范式 StructLDM。该范式包括三个关键设计:结构化的高维人体表征、结构化的自动解码器以及结构化的隐空间扩散模型。
StructLDM 是一个从图像、视频中学习的前馈三维生成模型(Feedforward 3D Generative Model),相比于已有 3D GAN 方法可生成高质量、多样化且视角一致的三维数字人,并支持不同层级的可控生成与编辑功能,如局部服装编辑、三维虚拟试衣等部位感知的编辑任务,且不依赖于特定的服装类型或遮罩条件,具有较高的适用性。
- 论文标题:StructLDM: Structured Latent Diffusion for 3D Human Generation
- 论文地址:https://arxiv.org/pdf/2404.01241
- 项目主页:https://taohuumd.github.io/projects/StructLDM
- 实验室主页:https://www.ntu.edu.sg/s-lab

方法概览

StructLDM 训练过程的包含两个阶段:
- 结构化自动解码:给定人体姿态信息 SMPL 和相机参数,自动解码器对训练集中每个人物个体拟合出一个结构化 UV latent。该过程的难点在于如何把不同姿态、不同相机视角、不同着装的人物图像拟合到统一的 UV latent 中,为此 StructLDM 提出了结构化局部 NeRF 对身体每个部位分别建模,并通过全局风格混合器把身体各部分合并在一起,学习整体的人物外观。此外,为解决姿态估计误差问题,自动解码器训练过程中引入了对抗式学习。在这一阶段,自动解码器把训练集中每个人物个体转化为一系列 UV latent。
- 结构扩散模型:该扩散模型学习第一阶段得到的 UV latent 空间,以此学习人体三维先验。
在推理阶段,StructLDM 可随机生成三维数字人:随机采样噪声并去噪得到 UV latent,该 latent 可被自动解码器渲染为人体图像。
实验结果
该研究在 4 个数据集上进行了实验评估:单视角图像数据集 DeepFashion [Liu et al. 2016],视频数据集 UBCFashion [Zablotskaia et al. 2019],真实三维人体数据集 THUman 2.0 [Yu et al. 2021], 及虚拟三维人体数据集 RenderPeople。
3.1 定性结果比较
StructLDM 在 UBCFashion 数据集上与已有 3D GAN 方法做了对比,如 EVA3D、 AG3D 及 StyleSDF。相比于已有方法,StructLDM 可生成高质量、多样化、视角一致的三维数字人,如不同肤色、不同发型,以及服饰细节(如高跟鞋)。

StructLDM 在 RenderPeople 数据集上与已有 3D GAN 方法(如 EG3D, StyleSDF, 及 EVA3D)及扩散模型 PrimDiff 对比。相比于已有方法,StructLDM 可生成不同姿态、不同外观的高质量三维数字人,并生成高质量面部细节。

3.2 定量结果比较
研究者在 UBCFashion, RenderPeople,及 THUman 2.0 上与已知方法做了定量结果比较,在每个数据集上随机选取 5 万张图像计算 FID ,StructLDM 可大幅降低 FID。此外,User Study 显示大约 73% 的用户认为 StructLDM 生成的结果在面部细节和全身图像质量上比 AG3D 更有优势。

3.3 应用
3.3.1 可控性生成
StructLDM 支持可控性生成,如相机视角、姿态、体型控制,以及三维虚拟试衣,并可在二维隐空间插值。

3.3.2 组合式生成
StructLDM 支持组合式生成,如把①②③④⑤部分组合起来可生成新的数字人,并支持不同的编辑任务,如身份编辑、衣袖(4)、裙子(5)、三维虚拟试衣(6)以及全身风格化(7)。

25
3.3.3 编辑互联网图片
StructLDM 可对互联网图片进行编辑,首先通过 Inversion 技术得到对应的 UV latent,然后通过 UV latent 编辑可对生成的数字人进行编辑,如编辑鞋、上衣、裤子等。

3.4 消融实验
3.4.1 隐空间扩散
StructLDM 提出的隐空间扩散模型可用于不同编辑任务,如组合式生成。下图探究了扩散模型参数(如扩散步数和噪声尺度)对生成结果的影响。StructLDM 可通过控制扩散模型参数来提高生成效果。

3.4.2 一维与二维人体表征
研究者对比了一维与二维 latent 人体表征效果,发现二维 latent 可生成高频细节(如衣服纹理及面部表情),加入对抗式学习可同时提高图片质量和保真度。

3.4.3 结构感知的归一化
为提高扩散模型学习效率,StructLDM 提出了结构感知的 latent 归一化技术 (structure-aligned normalization),即对每个 latent 做逐像素归一化。研究发现,归一化后的 latent 分布更接近于高斯分布,以此更利于扩散模型的学习。

#如何通俗理解扩散模型
实验室最近人人都在做扩散,从连续到离散,从 CV 到 NLP,基本上都被 diffusion 洗了一遍。但是观察发现,里面的数学基础并不是模型应用的必须。其实大部分的研究者都不需要理解扩散模型的数学本质,更需要的是对扩散模型的原理的经验化理解,从而应用到 research 里面去。笔者做 VAE 和 diffussion 也有一段时间了,就在这里通俗地解释一下 diffusion 的来龙去脉。
Variational AutoEncoder (VAE)
要讲扩散模型,不得不提 VAE。VAE 和 GAN 一样,都是从隐变量 生成目标数据 。它们假设隐变量服从某种常见的概率分布(比如正态分布),然后希望训练一个模型 ,这个模型将原来的概率分布映射到训练集的概率分布,也就是分布的变换。注意,VAE 和 GAN 的本质都是概率分布的映射。大致思路如下图所示:
换句话说,大致意思就是先用某种分布随机生成一组隐变量,然后这个隐变量会经过一个生成器生成一组目标数据。VAE 和 GAN 都希望这组数据的分布 和目标分布 尽量接近。
是不是听上去很 work?但是这种方法本质上是难以 work 的,因为“尽量接近”并没有一个确定的关于 XXX 和 X^\hat{X}\hat{X} 的相似度的评判标准。换句话说,这种方法的难度就在于,必须去猜测“它们的分布相等吗”这个问题,而缺少真正 interpretable 的价值判断。有聪明的同学会问,KL 散度不就够了吗?不行,因为 KL 散度是针对两个已知的概率分布求相似度的,而 和 XXX 的概率分布目前都是未知。
GAN 的做法就是直接把这个度量标准也学过来就行,相当生猛。但是这样做的问题在于依然不 interpretable,非常不优雅。VAE 的做法就优雅很多了,我们先来看 VAE 是怎么做的,理解了 VAE 以后再去理解 Diffussion 就很自然了。
到底什么是生成模型?
我们看回生成模型到底是个啥。我们拿到一批 sample(称为 ), 想要用 学到它的分布 , 这样就能同时学到没被 sample 到的数据了, 用这个分布 就能随意采样, 然后获得 生成结果。但是这个分布九曲回肠, 根本不可能直接获得。所以绕个弯, 整一个隐变量 , 这东西可以生成 。不妨假设 满足正态分布, 那就可以先从正态分布里面随便取一个 , 然后用 和 的关系算出 。这里不得不用一下数学公式, 因为后面一直要用到(其实也很简单, 学过概率学基础一下就看得懂) :
换句话说, 就是不直接求 , 而是造一个别的变量(好听的名字叫“隐变量"),获得这个隐变量和我要搞的 的关系, 也能搞到 。注意, 上式中, 称为后验分布, 称为先验分布。
VAE 的核心
VAE 的核心就是, 我们不仅假设 是正态分布, 而且假设每个 也是正态分布。 什么意思呢? 因为 是一组采样,其实可以表示成 , 而我们想要针对每个 获得一个专属于它和 的一个正态分布。换句话说, 有 个 sample, 就有 个正态分布 。其实也很好理解, 每一个采样点当然都需要一个相对 的分布, 因为没有任何两个采样点是完全一致的。
那现在就要想方设法获得这 个正态分布了。怎么搞? 学!拟合!但是要注意, 这里的拟合与 不同, 本质上是在学习 和 的关系, 而非学习比较 与 的标准。
OK, 现在问一个小学二年级就知道的问题, 已知是正态分布, 学什么才能确定这个正态分布? 没错, 均值和方差。怎么学? 有数据啊! 不是你自己假设的吗, 是已知的啊, 那你就用这俩去学个均值和方差。
好, 现在我们已经学到了这 个正态分布。那就好说了, 直接从 里面采样一个 , 学 一个 generator,就能获得 了。那接下来只需要最小化方差 就行。来看看下面的图, 仔细理解一下:
仔细理解的时候有没有发现一个问题? 为什么在文章最开头, 我们强调了没法直接比较 和 的分布, 而在这里, 我们认为可以直接比较这俩? 注意, 这里的 是专属于 (针对于) 的隐变量, 那么和 本身就有对应关系,因此右边的蓝色方框内的“生成器”, 是一一对应的生成。
另外,大家可以看到,均值和方差的计算本质上都是 encoder。也就是说,VAE 其实利用了两个 encoder 去分别学习均值和方差。
VAE 的 Variational 到底是个啥
这里还有一个非常重要的问题 (对于初学者而言可能会比较困难, 需要反复思考) : 由于我们通过最小化 来训练右边的生成器, 最终模型会逐渐使得 和 趋于一致。但是注 意, 因为 是重新随机采样过的, 而不是直接通过均值和方差 encoder 学出来的, 这个生成器的输入 是有噪声的。但是仔细思考一下, 这个噪声的大小其实就用方差来度量。为了使得分布的学习尽量接近, 我们希望噪声越小越好, 所以我们会尽量使得方差趋于 0。
但是方差不能为 0 , 因为我们还想要给模型一些训练难度。如果方差为 0 , 模型永远只需要学习高斯分布的均值, 这样就丟失了随机性, VAE 就变成 AE 了...... 这就是为什么 VAE 要在 AE 前面加一个 Variational:我们希望方差能够持续存在, 从而带来噪声! 那如何解决这个问题呢? 其实保证有方差就行, 但是 VAE 给出了一个优雅的答案: 不仅需要保证有方差, 还要让所有 趋于标准正态分布 !为什么要这么做呢? 这里又需要一个小小的数学推导:
这条式子大家想必都看得懂, 看不懂也没事......关键是结论: 如果所有 都趋于 , 那么我们可以保证 也趋于 , 从而实现先验的假设, 这样就形成了一个闭环! 太优雅了! 那怎么让所有 趋于 呢? 加 loss 呗, 具体的 loss 推导这里就不做深入了, 用到了很多数学知识, 又要被公式淹没了。到此为止, 我们可以把 VAE 进一步画成:
VAE 的本质
现在我们来回顾一下 VAE 到底做了啥。VAE 在 AE 的基础上对均值的 encoder 添加高斯噪声(正态分布的随机采样),使得 decoder(就是右边那个生成器)有噪声鲁棒性;为了防止噪声消失,将所有 趋近于标准正态分布,将 encoder 的均值尽量降为 0,而将方差尽量保持住。这样一来,当 decoder 训练的不好的时候,整个体系就可以降低噪声;当 decoder 逐渐拟合的时候,就会增加噪声。
本质上,是不是和 GAN 很像?!要我命名,我也可以叫 VAE 是生成对抗 encoder(手动滑稽
Diffusion Model(扩散模型,DM)
好了,到此为止,你已经理解了扩散模型的所有基础。现在我们来站在 VAE 的基础上讲讲扩散模型。目前的教程实在是太数学了,其实可以用更加通俗的语言讲清楚。从本质上说,Diffusion 就是 VAE 的升级版。
VAE 有一个做了好几年的核心问题。大家思考一下, 上面的 VAE 中, 变分后验 是怎么获得的? 是学出来的! 用 当 loss, 去学这个 。学这个变分后验就有五花八门的方法了, 除了上面说的拟合法, 还有用纯数学来做的, 甚至有用 BERT 这种 PLM 来做的。但是无论如何都逃不出这个 VAE 的框架:必须想办法设计一个生成器 , 使得变分后验分布 尽量真实。这种方法的问题在于, 这个变分后验 的表达能力与计算代价是不可兼得的。 换句话说, 简单的变分后验表达并不丰富(例如数学公式法), 而复杂的变分后验计算过于复杂(例如 PLM 法)。
现在回过头来看看 GAN 做了啥。前面也提到过,GAN 其实就是简单粗暴,没有任何 encoder,直接训练生成器,唯一的难度在于判别器(就是下图这个“它们的分布相等吗”的东西)不好做。
好了,聪明的你也已经知道我要说什么了。Diffusion 本质就是借鉴了 GAN 这种训练目标单一的思路和 VAE 这种不需要判别器的隐变量变分的思路,糅合一下,发现还真 work 了……下面让我们来看看到底是怎么糅合的。为什么我们糅合甚至还没传统方法好,大佬糅合揉出个 diffusion?
Diffusion 的核心
知道你们都懒得划上去,我再放一下 VAE 的图。
前面也已经提到,VAE 的最大问题是这个变分后验。在 VAE 中,我们先定义了右边蓝色的生成器 ,再学一个变分后验 来适配这个生成器。能不能反一下,先定义一个变分后验再学一个生成器呢?
如果你仔细看了上面的 VAE 部分,我相信你已经有思路了。VAE 的生成器,是将标准高斯映射到数据样本(自己定义的)。VAE 的后验分布,是将数据样本映射到标准高斯(学出来的)。那反过来,我想要设计一种方法 A,使得 A 用一种简单的“变分后验”将数据样本映射到标准高斯(自己定义的),并且使得 A 的生成器,将标准高斯映射到数据样本(学出来的)。注意,因为生成器的搜索空间大于变分后验,VAE 的效率远不及 A 方法:因为 A 方法是学一个生成器(搜索空间大),所以可以直接模仿这个“变分后验”的每一小步!
好,现在我告诉你,这个 A 方法就是扩散模型(Diffusion Model)的核心思路:定义一个类似于“变分后验”的从数据样本到高斯分布的映射,然后学一个生成器,这个生成器模仿我们定义的这个映射的每一小步。
Diffusion Model 的 Diffusion 到底是个啥
接触 diffusion 的你肯定知道马尔可夫链!这东西不仅 diffusion 里面有,各种怪异的算法里面也都出现了。为什么用它?因为它的一个关键性质:平稳性。一个概率分布如果随时间变化,那么在马尔可夫链的作用下,它一定会趋于某种平稳分布(例如高斯分布)。只要终止时间足够长,概率分布就会趋近于这个平稳分布。
这个逐渐逼近的过程被作者称为前向过程(forward process)。注意,这个过程的本质还是加噪声! 试想一下为什么……其实和 VAE 非常相似,都是在随机采样!马尔可夫链每一步的转移概率,本质上都是在加噪声。这就是扩散模型中“扩散”的由来:噪声在马尔可夫链演化的过程中,逐渐进入 diffusion 体系。随着时间的推移,加入的噪声(加入的溶质)越来越少,而体系中的噪声(这个时刻前的所有溶质)逐渐在 diffussion 体系中扩散,直至均匀。看看下面的图,你应该就恍然大悟了:
现在想想,为什么要用马尔可夫链。我们把问题详细地重述一下:为什么我们创造一个稳定分布为高斯分布的马尔可夫链,对于生成器模仿我们定义的某个映射的每一小步有帮助呢?这里你肯定想不出来,不然你也能发明 diffusion model ——答案是,基于马尔可夫链的前向过程,其每一个 epoch 的逆过程都可以近似为高斯分布。
懵了吧,我也懵了。真正的推导发了好几篇 paper,都是些数学巨佬的工作,不得不感叹基础科学的力量……相关工作主要用的是 SDE(随机微分方程),我们在这里不做深入,但是需要理解大致的思路,如下图所示。
下面的是前向过程,上面的是反向过程。前向过程通过马尔可夫链的转移概率不断加入噪音,从右边的采样数据到左边的标准高斯;反向过程通过 SDE 来“抄袭”对应正向过程的那一个 epoch 的行为(其实每一步都不过是一个高斯分布),从而逐渐学习到对抗噪声的能力。高斯分布是一种很简单的分布,运算量小,这一点是 diffusion 快的最重要原因。
Diffusion 的本质
现在回头看看 diffusion 到底做了个啥工作。我们着重看一下下图的 VAE 和 diffussion 的区别:
可以很清晰的认识到,VAE 本质是一个基于梯度的 encoder-decoder 架构,encoder 用来学高斯分布的均值和方差,decoder 用变分后验来学习生成能力,而将标准高斯映射到数据样本是自己定义的。而扩散模型本质是一个 SDE/Markov 架构,虽然也借鉴了神经网络的前向传播/反向传播概念,但是并不基于可微的梯度,属于数学层面上的创新。两者都定义了高斯分布 作为隐变量,但是 VAE 将 作为先验条件(变分先验),而 diffusion 将 作为类似于变分后验的马尔可夫链的平稳分布。
想要更深入的理解?
如评论区指出的,文章的定位本身就是让读者读懂 diffusion 而非对 diffusion 框架本身进行数学创新,是应用向而非结构向的,大佬们如果希望看到更深入的分析可以追更和评论区催更~
#扩散模型diffusion如何改进
1、∞-Brush : Controllable Large Image Synthesis with Diffusion Models in Infinite Dimensions
从错综复杂的领域特定信息中合成高分辨率图像仍是生成建模中的一个重大挑战,尤其适用于大图像域(如数字组织病理学和遥感)中的应用。现有方法面临着关键限制:像素空间或潜在空间中的条件扩散模型在超出它们训练的分辨率时就会失去保真度,并且对于更大的图像尺寸,计算需求会显著增加。
基于patch方法提供了计算效率,但由于过度依赖局部信息,无法捕捉长距离空间关系。本文引入一种新无限维条件扩散模型,∞-Brush,用于可控大图像合成。提出交叉注意力神经操作器,以实现函数空间中的条件化。模型克服了传统有限维扩散模型和基于patch方法的约束,提供可扩展性和在保持全局图像结构的前提下保持细节的卓越能力。∞-Brush 可控合成高达 4096 × 4096 像素分辨率图像的条件扩散模型。https://github.com/cvlab-stonybrook/infinity-brush

2、AccDiffusion: An Accurate Method for Higher-Resolution Image Generation
本文试图解决基于patch更高分辨率图像生成中的对象重复(object repetition)问题。提出AccDiffusion,无需训练,深入分析揭示了重复的对象生成,而没有提示会损害图像的细节。因此,AccDiffusion首次提出将图像内容感知提示解耦为一组分区内容感知提示,每个提示作为对图像分区的更准确描述。
AccDiffusion还引入了带窗口交互的dilated sampling,以更好提高更高分辨率图像生成中的全局一致性。与现有方法的实验比较表明,AccDiffusion有效解决了重复对象生成的问题,并在更高分辨率图像生成方面表现更好。

3、Efficient Diffusion Transformer with Step-wise Dynamic Attention Mediators
本文指出扩散Transformer模型的自注意机制中存在与查询-键交互的显著冗余,特别是在去噪扩散步骤的早期阶段。针对这一观察结果,提出一个新的扩散Transformer框架,包括一个额外的中介token集,用于分开处理查询和键。通过在去噪生成阶段调节中介token的数量,模型通过准确、明确的阶段开始去噪过程,并逐渐过渡到丰富细节的阶段。同时,整合中介token简化了注意模块的复杂度至线性尺度,增强了全局注意过程的效率。
此外,提出一个时间步动态中介token调整机制,进一步减少了生成所需的计算 FLOPs,同时促进了在各种推断预算的约束下生成高质量图像。实验证明,方法改善生成图像的质量,同时降低推断成本。与最近的 SiT 工作集成后,方法实现了 2.01 的最先进 FID 分数。等待开源在:https://github.com/LeapLabTHU/Attention-Mediators

4、Enhancing Diffusion Models with Text-Encoder Reinforcement Learning
文生图扩散模型通常被训练以优化对数似然目标,这在满足下游任务的特定要求,如图像美学和图像-文本对齐方面存在挑战。最近的研究通过强化学习或直接反向传播优化扩散 U-Net,利用人类奖励来解决这一问题。然而,许多研究忽视了文本编码器的重要性,该编码器通常在训练期间是预训练的且固定的。
本文证明通过强化学习微调文本编码器,可增强结果的文本-图像对齐,从而提高视觉质量。主要动机来自于观察到当前文本编码器并不是最佳的,通常需要仔细的提示调整。虽然微调 U-Net 可以部分改善性能,但仍受制于次优的文本编码器。因此,提出用低秩调整的强化学习来微调文本编码器,基于任务特定的奖励进行微调,称为 TexForce。首先展示微调文本编码器可以提高扩散模型的性能。然后,说明 TexForce 可简单地与现有微调模型结合,以获得更好的结果,无需额外训练。最后,展示了方法在各种应用中的适应性,包括生成高质量的人脸和手部图像。https://github.com/chaofengc/TexForce

5、Lost in Translation: Latent Concept Misalignment in Text-to-Image Diffusion Models
文生图扩散模型拓展了下游实际应用,但这些模型常在文本和图像之间遇到对齐问题。以生成两个解耦概念的组合为例,比如给定提示“一杯冰可乐”,现有模型通常会生成一个玻璃杯中的冰可乐,因为冰可乐通常在模型训练中与玻璃杯共现,而不是茶杯。这种对齐问题的根源在于文本到图像扩散模型在潜在语义空间中存在混淆,因此将“一杯冰可乐”现象称为潜在概念对齐失误(LC-Mis)。
利用大型语言模型(LLMs)彻底调查 LC-Mis 的范围,并开发一个自动化流程,用于将扩散模型的潜在语义与文本提示对齐。实证评估证实方法有效性,显著减少 LC-Mis 错误,增强了文本到图像扩散模型的韧性和通用性。https://github.com/RossoneriZhao/iced_coke

6、Navigating Text-to-Image Generative Bias across Indic Languages
本研究调查了针对印度广泛使用的印地语言的文生图(TTI)模型中的偏见。它评估并比较了这些语言中领先的 TTI 模型在生成性能和文化相关性方面与其在英语中的表现。利用提出的 IndicTTI 基准测试,全面评估了30种印地语言的两个开源扩散模型和两个商业生成 API 的性能。
该基准测试的主要目标是评估这些模型在这些语言中支持的程度,并确定需要改进的领域。鉴于印度使用的30种语言被14亿人口说着,该基准测试旨在提供对 TTI 模型在印地语言环境中效果的详细而独到的分析。IndicTTI 基准测试的数据和代码:https://iab-rubric.org/resources/other-databases/indictti

7、Post-training Quantization with Progressive Calibration and Activation Relaxing for Text-to-Image Diffusion Models
高计算负担是扩散模型面临的一个棘手问题。最近研究利用后训练量化(PTQ)来压缩扩散模型。然而,大多数研究仅集中在无条件模型上,未探索广泛使用的预训练文本到图像模型,如 Stable Diffusion 的量化。
本文提出一种扩散模型后训练量化方法 PCR(Progressive Calibration and Relaxing),该方法包括一个考虑跨时间步积累的量化误差的渐进校准策略,以及一个通过激活放松策略来提高性能而成本微乎其微的传动。此外,证明先前用于文本到图像扩散模型量化的指标并不准确,因为存在分布差异。为解决这个问题,提出一个新的 QDiffBench 基准测试,该基准测试利用相同领域的数据进行更准确的评估。

8、PreciseControl: Enhancing Text-To-Image Diffusion Models with Fine-Grained Attribute Control
文生图(T2I)扩散模型个性化方法的激增,用少量图像学习概念。现有方法在面部个性化领域受到困扰,很难实现带有身份保留的令人信服的逆映射生成,并依赖于生成的面部的基于语义文本的编辑。然而,对于面部属性编辑,更精细的控制是需要的,仅仅通过文本提示是具有挑战性的。
StyleGAN 模型学习了丰富的面部先验,并通过潜在操纵实现了朝着精细特征编辑的平滑控制。本文使用 StyleGAN 的 W+ 空间来对 T2I 模型进行条件设置。这种方法精确操纵面部属性,例如平滑地引入微笑,同时保留 T2I 模型中固有的基于文本的粗略控制。为使 T2I 模型在 W+ 空间上具有条件设置,训练了一个潜在映射器,将 W+ 空间的潜在代码转换为 T2I 模型的token嵌入空间。
方法在面部图像的inversion和属性保留方面表现出色,并有助于实现对精细特征编辑的持续控制。此外,方法可以方便地扩展到生成涉及多个个体的组合。大量实验证明方法对于面部个性化和精细特征编辑的验证。https://rishubhpar.github.io/PreciseControl.home/

9、Memory-Efficient Fine-Tuning for Quantized Diffusion Model
十亿参数扩散模型,如Stable Diffusion XL,Imagen和DALL-E 3,推动生成式人工智能领域。然而,大规模架构在微调和部署中存在挑战,因为资源需求高,推断速度慢。本文探讨相对未被探索但极具潜力的量化扩散模型微调领域。
分析显示,基线忽略了模型权重中的不同模式以及在微调扩散模型时各个时间步骤的不同角色。为解决这些限制,引入一种专门为量化扩散模型设计的新型内存高效微调方法,称为TuneQDM。方法引入量化比例作为可分离函数,以考虑通道间的权重模式。然后,它以时间步特定的方式优化这些比例,以有效反映每个时间步骤的作用。TuneQDM在与其全精度对应物相媲美的性能同时,还提供显著的内存效率。
实验结果表明,方法在单个/多个主体生成方面始终优于基线,表现出高主体忠实度和与全精度模型相媲prompt忠实度。

10、Reliable and Efficient Concept Erasure of Text-to-Image Diffusion Models
文生图模型面临安全问题,包括与版权和NSFW(不安全内容)相关的担忧。尽管已提出几种方法来从扩散模型中消除不合适的概念,但它们往往表现出不完全消除、消耗大量计算资源,并无意中损害了生成能力。
这项工作介绍一种名为可靠高效概念消除(RECE)的新方法,可在3秒内修改模型而无需额外微调。具体而言,RECE高效利用闭合形式解来推导出新的目标嵌入,能够在未学习的模型中重新生成已消除的概念。为了缓解由推导出的嵌入表示可能具有的不当内容,RECE进一步将它们与交叉注意力层中的无害概念对齐。为了保留模型的生成能力,RECE在推导过程中引入了额外的正则化项,从而最小化了消除过程中对不相关概念的影响。
保证仅需3秒极其高效的消除。与之前的方法进行基准测试,方法实现更高效和彻底的消除。https://github.com/CharlesGong12/RECE
11、Unmasking Bias in Diffusion Model Training
去噪扩散模型已成为图像生成的主要方法,然而它们在训练中收敛速度缓慢,采样中存在颜色偏移问题。这项工作发现这些障碍主要归因于扩散模型默认训练范式中固有的偏差和次优性。具体而言,提供理论见解,即扩散模型Ɛ-预测中普遍存在的恒定损失权重策略导致训练阶段估计偏见,阻碍了对原始图像的准确估计。
为解决这个问题,提出一个简单有效的加权策略,从解锁的偏置部分中推导而来。此外,进行了全面系统的探究,揭示了偏差问题在存在、影响和潜在原因方面的内在原因。这些分析有助于推动对扩散模型的理解。实证结果表明,方法显著提高样本质量,并且在训练和采样过程中提高了效率,仅通过调整损失加权策略。https://github.com/yuhuUSTC/Debias

12、SlimFlow: Training Smaller One-Step Diffusion Models with Rectified Flow
扩散模型在生成高质量方面表现出色,但由于迭代采样而导致推断速度缓慢。尽管最近的方法已成功将扩散模型转化为一步生成器,但它们忽略了模型尺寸的缩减,限制了在计算受限场景中的适用性。
本文旨在基于强大的矫正流框架,通过探索推断步骤和模型尺寸的联合压缩,开发小而高效的一步扩散模型。矫正流框架使用回流和蒸馏两种操作来训练一步生成模型。与原始框架相比,缩小模型尺寸带来了两个新挑战:(1)在回流过程中大型教师和小型学生之间的初始化不匹配;(2)小型学生模型上天真蒸馏的表现不佳。为克服这些问题,提出渐变回流和流引导蒸馏,二者共同构成我们的SlimFlow框架。
新框架训练了一个具有FID为5.02和15.7M参数的一步扩散模型,在CIFAR10上胜过了以前的最先进一步扩散模型(FID=6.47,19.4M参数)。在ImageNet 64×64和FFHQ 64×64上,方法得到了小型一步扩散模型,与较大模型相媲美,展示方法在创建紧凑、高效的一步扩散模型方面的有效性。

#扩散模型应用方向目录
- 1、扩散模型改进
- 2、可控文生图
- 3、风格迁移
- 4、人像生成
- 5、图像超分
- 6、图像恢复
- 7、目标跟踪
- 8、目标检测
- 9、关键点检测
- 10、deepfake检测
- 11、异常检测
- 12、图像分割
- 13、图像压缩
- 14、视频理解
- 15、视频生成
- 16、倾听人生成
- 17、数字人生成
- 18、新视图生成
- 19、3D相关
- 20、图像修复
- 21、草图相关
- 22、版权隐私
- 23、数据增广
- 24、医学图像
- 25、交通驾驶
- 26、语音相关
- 27、姿势估计
- 28、图相关
- 29、动作检测/生成
- 30、机器人规划/智能决策
- 31、视觉叙事/故事生成
- 32、因果生成
- 33、隐私保护-对抗估计
- 34、扩散模型改进-补充
- 35、交互式可控生成
- 36、图像恢复-补充
- 37、域适应-迁移学习
- 38、手交互
- 39、伪装检测
- 40、多任务学习
- 41、轨迹预测
- 42、场景生成
- 43、流估计-3D相关
一、扩散模型改进1、Accelerating Diffusion Sampling with Optimized Time Steps

扩散概率模型(DPMs)在高分辨率图像生成方面显示出显著性能,但由于通常需要大量采样步骤,其采样效率仍有待提高。高阶ODE求解在DPMs中的应用的最新进展使得能够以更少的采样步骤生成高质量图像。然而,大多数采样方法仍使用均匀的时间步长,在使用少量步骤时并不是最优的。
为解决这个问题,提出一个通用框架来设计一个优化问题,该优化问题寻求特定数值ODE求解器在DPMs中更合适的时间步长。该优化问题的目标是将基本解和相应的数值解之间的距离最小化。高效解决这个优化问题,所需时间不超过15秒。
在像素空间和潜空间DPMs上进行大量实验,无条件采样和有条件采样,结果表明,与用均匀时间步长相比,当与最先进的采样方法UniPC相结合时,对于CIFAR-10和ImageNet等数据集,以FID分数来衡量,优化时间步长显著提高图像生成性能。
2、DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models

用扩散模型生成高分辨率图像巨大计算成本,导致交互式应用的延迟不可接受。提出DistriFusion来解决这个问题,通过利用多个GPU之间的并行性。方法将模型输入分成多个patch,并每个分配给一个GPU。然而,简单地实现这种算法会破坏patch之间的交互并丢失保真度,而考虑这种交互将导致巨大的通信开销。
为解决这个困境,观察到相邻扩散步骤的输入之间具有很高的相似性,并提出位移patch并行性,它利用扩散过程的顺序性质,通过重复使用前一时间步的预计算特征图为当前步骤提供上下文。因此,方法支持异步通信,可以通过计算进行流水线处理。大量实验证明,方法可以应用于最近的Stable Diffusion XL,而不会降低质量,并且相对于一个NVIDIA A100设备,可以实现高达6.1倍的加速。已开源在:https://github.com/mit-han-lab/distrifuser
3、Balancing Act: Distribution-Guided Debiasing in Diffusion Models

扩散模型(DMs)会反映训练数据集中存在的偏差。在人脸情况下尤为令人担忧,DM更偏爱某个人口群体而不是其他人口群体(例如女性比男性)。这项工作提出一种在不依赖于额外数据或模型重新训练的情况下对DMs进行去偏置的方法。
具体而言,提出分布引导(Distribution Guidance)方法,该方法强制生成的图像遵循指定的属性分布。为实现这一点,建立在去噪UNet(denoising UNet)的潜在特征上具有丰富的人口群体语义,并且可以利用这些特征来引导去偏置生成。训练属性分布预测器(ADP),一个将潜在特征映射到属性分布的小型多层感知机。ADP是使用现有属性分类器生成的伪标签进行训练的。引入的Distribution Guidance与ADP能进行公平生成。
方法减少了单个/多个属性上的偏差,并且在无条件和文本条件下的扩散模型方面的基线效果明显优于过去的方法。此外,提出通过生成数据对训练集进行再平衡来训练公平属性分类器的下游任务。
4、Few-shot Learner Parameterization by Diffusion Time-steps

即使用大型多模态基础模型,少样本学习仍具有挑战性。如果没有适当的归纳偏差,很难保留微妙的类属性,同时删除与类标签啡不相关的显著视觉属性。
发现扩散模型(DM)的时间步骤可以隔离微妙的类属性,即随着前向扩散在每个时间步骤向图像添加噪声,微妙的属性通常在比显著属性更早的时间步骤丢失。基于此,提出了时间步骤少样本(TiF)学习器。为文本条件下的DM训练了类别特定的低秩适配器,以弥补丢失的属性,从而在给定提示的情况下可以准确地从噪声图像重建出原始图像。因此,在较小的时间步骤中,适配器和提示本质上是仅含有微妙的类属性的参数化。对于一个测试图像,可以使用这个参数化来仅提取具有微妙的类属性进行分类。在各种细粒度和定制的少样本学习任务上,TiF学习器在性能上明显优于OpenCLIP及其适配器。
5、Structure-Guided Adversarial Training of Diffusion Models

在各种生成应用中,扩散模型展示了卓越的有效性。现有模型主要侧重于通过加权损失最小化来对数据分布进行建模,但它们的训练主要强调实例级的优化,忽视了每个小批量数据内有价值的结构信息。
为解决这个限制,引入结构引导的扩散模型对抗训练(Structure-guided Adversarial training of Diffusion Models, SADM)方法。迫使模型在每个训练批次中学习样本之间的流形结构。为确保模型捕捉到数据分布中真实的流形结构,提出一种新的结构判别器,通过对抗训练与扩散生成器进行游戏,区分真实的流形结构和生成的流形结构。
SADM显著改进了现有的扩散transformer,在图像生成和跨域微调任务中的12个数据集上性能优于现有方法,对于256×256和512×512分辨率下的类条件图像生成,新FID记录分别为1.58和2.11。
6、Tackling the Singularities at the Endpoints of Time Intervals in Diffusion Models

大多数扩散模型假设反向过程服从高斯分布,然而,这种近似在奇异点处(t=0和t=1)尤其在奇异点singularities处尚未得到严格验证。不当处理这些点会导致应用中的平均亮度问题,并限制生成具有极端亮度或深暗度的图像。
本文从理论和实践的角度解决。首先,建立了反向过程逼近的误差界限,并展示了在奇异时间步骤时它的高斯特征。基于这个理论认识,确认t=1的奇异点是有条件可消除的,而t=0时是固有的属性。基于这些重要的结论,提出一种新的即插即用方法SingDiffusion来处理初始奇异时间步骤的采样,它不仅可以在没有额外训练的情况下有效解决平均亮度问题,而且还可以提高它们的生成能力,从而实现显著较低的FID得分。https://github.com/PangzeCheung/SingDiffusion
7、Boosting Diffusion Models with Moving Average Sampling in Frequency Domain

扩散模型大多依赖于当前样本来去噪下一个样本,可能导致不稳定。这篇论文将迭代的去噪过程重新解释为模型优化,并利用滑动平均机制将所有先前的样本集合起来。不仅仅将滑动平均应用于不同时间步的去噪样本,而是首先将去噪样本映射到数据空间,然后进行滑动平均,以避免时间步之间的分布偏移。
由于扩散模型将恢复从低频成分到高频细节,进一步将样本分解为不同的频率成分,并在每个成分上分别执行滑动平均。将完整的方法命名为“频域中的滑动平均采样 (Moving Average Sampling in Frequency domain,MASF)”。MASF可以无缝地集成到主流的预训练扩散模型和采样计划中。在无条件和有条件的扩散模型上进行的大量实验表明,与基线相比, MASF 在性能上表现出更高的水平,几乎没有额外的复杂度成本。
8、Towards Memorization-Free Diffusion Models

由于预训练的扩散模型及其输出具有出色的合成高质量图像的能力和开放源代码的特点,这些模型及其输出可广泛轻易获得。用户在推断过程中可能面临诉讼风险,因为模型容易记忆并复制训练数据。
为解决这个问题,引入一种新框架,称为“反记忆指导 (Anti-Memorization Guidance,AMG)”,它采用了针对记忆的三种有针对性的指导策略,以应对图像和caption重复,以及高度具体的用户提示等主要记忆原因。因此,AMG确保了无记忆输出,同时保持高图像质量和文本对齐,利用其指导方法的协同作用,每个方法在其自身领域都是不可或缺的。
AMG还具有创新的自动检测系统,用于在推断过程的每一步中检测潜在的记忆,允许选择性地应用指导策略,最大程度地不干扰原始的采样过程,以保留输出的实用性。将AMG应用于预训练的去噪扩散概率模型(DDPM)和稳定扩散的各种生成任务中。实验结果表明,AMG是第一个成功消除所有记忆实例而对图像质量和文本对齐几乎没有或轻微影响的方法,这一点可以通过FID和CLIP分数得到证明。
9、SD-DiT: Unleashing the Power of Self-supervised Discrimination in Diffusion Transformer

扩散Transformer(DiT)已成为图像生成趋势。 鉴于典型 DiT 的收敛速度极其缓慢,最近的突破是由掩模策略推动的,该策略通过额外的图像内上下文学习提高了训练效率。 但掩模策略仍然存在两个局限性:(a)训练推理差异和(b)掩模重建和生成扩散过程之间的模糊关系,导致 DiT 的训练不理想。
这项工作通过释放自监督的判别知识来促进 DiT 训练来解决这些局限性。 从技术上讲,以师生的方式构建 DiT。 师生判别对是沿着相同的概率流常微分方程(PF-ODE)建立在扩散噪声的基础上的。 不在 DiT 编码器和解码器上应用掩模重建损失,而是解耦 DiT 编码器和解码器以分别处理判别目标和生成目标。 特别是,通过使用学生和教师 DiT 编码器对判别对进行编码,设计了一种新的判别损失来鼓励自监督嵌入空间中的图像间对齐。 之后,学生样本被输入学生 DiT 解码器以执行典型的生成扩散任务。 在 ImageNet 数据集上进行了大量实验,方法在训练成本和生成能力之间实现了竞争性平衡。
二、可控文生图10、ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models

3D资产生成正受到大量关注,受到最近文本引导的2D内容创建成功的启发,现有的文本到3D方法使用预训练文本到图像扩散模型来解决优化问题,或在合成数据上进行微调,这往往会导致没有背景的非真实感3D物体。
本文提出利用预训练的文本到图像模型作为先验,并从真实世界数据中单一去噪过程中学习生成多视角图像。具体而言,将3D体渲染和跨帧注意力层集成到现有的文本到图像模型的每个块中。此外,设计一种自回归生成,可以从任意视点渲染出更具3D一致性的图像。使用真实世界的物体数据集来训练模型,并展示了它生成具有各种高质量形状和纹理的实例的能力。
与现有方法相比,生成的结果一致,并且具有良好的视觉质量(FID减少30%,KID减少37%)。https://lukashoel.github.io/ViewDiff/
11、NoiseCollage: A Layout-Aware Text-to-Image Diffusion Model Based on Noise Cropping and Merging

布局感知的文本到图像生成,是一种生成反映布局条件和文本条件的多物体图像的任务。当前的布局感知的文本到图像扩散模型仍然存在一些问题,包括文本与布局条件之间的不匹配以及生成图像的质量降低。
本文提出一种新的布局感知的文本到图像扩散模型,称为NoiseCollage,以解决这些问题。在去噪过程中,NoiseCollage独立估计各个物体的噪声,然后将它们裁剪和合并为一个噪声。这个操作有助于避免条件不匹配,换句话说,它可以将正确的物体放在正确的位置。
定性和定量评估结果表明,NoiseCollage优于几种最先进的模型。还展示了NoiseCollage可以与ControlNet集成,使用边缘、草图和姿势骨架作为附加条件。实验结果表明,这种集成可以提高ControlNet的布局准确性。https://github.com/univ-esuty/noisecollage
12、Discriminative Probing and Tuning for Text-to-Image Generation

尽管在文本-图像生成(text-to-image generation)方面取得了进步,但之前方法经常面临文本-图像不对齐问题,如生成图像中的关系混淆。现有解决方案包括交叉注意操作,以更好地理解组合或集成大型语言模型,以改进布局规划。然而,T2I模型的固有对齐能力仍然不足。
通过回顾生成建模和判别建模之间的联系,假设T2I模型的判别能力可能反映了它们在生成过程中的文本-图像对齐能力。鉴于此,提倡增强T2I模型的判别能力,以实现更精确的文本-图像对齐以进行生成。
提出一个基于T2I模型的判别适配器,以探索他们在两个代表性任务上的判别能力,并利用判别微调来提高他们的文本-图像校准。鉴别适配器的好处是,自校正机制可以利用鉴别梯度,在推理过程中更好地将生成的图像与文本提示对齐。
对三个基准数据集(包括分布内和分布外场景)的综合评估表明,方法具有优越的生成性能。同时,与其他生成模型相比,它在两个判别任务上实现了最先进的判别性能。https://github.com/LgQu/DPT-T2I
13、Dysen-VDM: Empowering Dynamics-aware Text-to-Video Diffusion with LLMs

文本到视频(T2V)合成在学术界越来越受关注,其中新出现的扩散模型(DM)在性能上显示出比以往方法更强大的表现。虽然现有的最先进DM在实现高分辨率视频生成方面表现出色,但在复杂的时间动态建模方面(如动作发生紊乱、粗糙的视频动作)仍然存在很大局限性。
这项工作研究强化DM对视频动态感知的方法,用于高质量的T2V生成。受人类直觉的启发,设计一种新的动态场景管理器(称为Dysen)模块,包括(步骤1)从输入文本中提取具有适当时间顺序的关键动作,(步骤2)将动作计划转化为动态场景图(DSG)表示,和(步骤3)丰富DSG中的场景以提供充分和合理的细节。通过在上下文学习中利用现有的强大LLMs(如ChatGPT),Dysen实现了(几乎)与人类水平的动态时间理解。最后,具有丰富动作场景细节的视频DSG被编码为细粒度的时空特征,集成到基础T2V DM中进行视频生成。
在流行的T2V数据集上的实验表明,Dysen-VDM始终以显着的优势超越以前的方法,特别是在复杂动作场景中。
14、Face2Diffusion for Fast and Editable Face Personalization

面部个性化,旨在将来自图像的特定面部插入预先训练的文本到图像扩散模型中。然而,以往的方法在保持身份相似性和可编辑性方面仍然具有挑战,因为它们过拟合于训练样本。
本文提出一种用于高可编辑性面部个性化的Face2Diffusion(F2D)方法。F2D背后的核心思想是从训练流程中去除与身份无关的信息,以防止过拟合问题并提高编码面部的可编辑性。F2D包含以下三个新颖的组成部分:1)多尺度身份编码器提供了良好分离的身份特征,同时保持多尺度信息的好处,从而提高了摄像机姿势的多样性。2)表情引导将面部表情与身份进行分离,提高了面部表情的可控性。3)类别引导的去噪正则化鼓励模型学习如何对面部进行去噪,从而提高了背景的文本对齐性。
在FaceForensics++数据集和各种提示上进行的广泛实验表明,与先前最先进的方法相比,方法在身份和文本保真度之间取得了更好的平衡。https://github.com/mapooon/Face2Diffusion
15、LeftRefill: Filling Right Canvas based on Left Reference through Generalized Text-to-Image Diffusion Model

本文提出LeftRefill,一种新方法,有效利用大型文本到图像(T2I)扩散模型进行参考引导图像合成。顾名思义,LeftRefill将参考视图和目标视图水平拼接在一起作为整体输入。参考图像占据左侧,而目标画布位于右侧。然后,LeftRefill根据左侧参考和特定的任务指令绘制右侧的目标画布。这种任务形式与上下文修复类似,类似于人工画家的操作。
这种新形式有效地学习了参考和目标之间的结构和纹理对应关系,而无需其他图像编码器或适配器。通过T2I模型中的交叉注意力模块注入任务和视图信息,并通过重新排列的自注意力模块进一步展示了多视图参考能力。这使得LeftRefill能够作为一个通用模型执行一致的生成,而无需在测试时进行微调或模型修改。因此,LeftRefill可以看作是一个简单而统一的框架来解决参考引导合成的问题。
作为示例,利用LeftRefill来解决两个不同的挑战:参考引导修复和新视角合成,基于预先训练的StableDiffusion模型。https://github.com/ewrfcas/LeftRefill
16、InteractDiffusion: Interaction Control in Text-to-Image Diffusion Models

大规模的图像到文本(T2I)扩散模型,展示出了生成基于文本描述的连贯图像能力,为内容生成提供广泛应用。尽管已有一定可控性,如对象定位、姿势和图像轮廓,但控制所生成内容中对象之间相互作用方面,仍存差距。在生成图像中控制对象之间的相互作用可能产生有意义的应用,例如创建具有交互式角色的现实场景。
这项工作研究将T2I扩散模型与Human-Object Interaction(HOI)信息进行条件化的问题,该信息由三元标签(人、动作、对象)和相应的边界框组成。提出一种名为InteractDiffusion的交互控制模型,它将现有的预训练T2I扩散模型扩展到能够更好地对交互进行条件控制。具体而言,对HOI信息进行tokenize,并通过交互嵌入来学习它们之间的关系。对训练HOI tokens到视觉tokens的条件化自注意层进行了训练,从而更好地对现有的T2I扩散模型进行条件化。
模型具有控制交互和位置的能力,并在HOI检测得分方面远远优于现有的基准模型,以及在FID和KID方面具有更好的保真度。https://jiuntian.github.io/interactdiffusion/
17、MACE: Mass Concept Erasure in Diffusion Models

大规模文本到图像扩散模型的快速扩张引起了人们对其潜在误用创造有害或误导性内容的日益关注。本文提出一种名为MACE的微调框架,用于MAss Concept Erasure(MACE)任务。该任务旨在防止模型在提示时生成具有不需要的概念的图像。现有的概念消除方法通常只能处理少于五个概念,同时很难在概念同义词(广义性)的消除和无关概念(特异性)的保留之间找到平衡。相比之下,MACE通过成功将消除范围扩大到100个概念,并在广义性和特异性之间实现了有效的平衡来实现差异。这是通过利用闭合形式的交叉注意力细化和LoRA微调来实现的,共同消除不需要的概念的信息。
此外,MACE在没有相互干扰的情况下整合了多个LoRA。在四个不同的任务中对MACE进行了广泛的评估:目标消除、名人消除、明确内容消除和艺术风格消除。结果表明,在所有评估任务中,MACE超过了之前的方法。https://github.com/Shilin-LU/MACE
18、MIGC: Multi-Instance Generation Controller for Text-to-Image Synthesis

提出一个多实例生成(MIG)任务,同时在一张图像中生成具有多样控制的多个实例。给定一组预定义的坐标及其相应的描述,该任务是确保生成的实例准确位于指定的位置,并且所有实例的属性都与其相应的描述相符。这扩展了当前单实例生成研究的范围,将其提升到一个更多样化和实用的维度。
受到分而治之思想的启发,引入了一种名为多实例生成控制器(MIGC)的创新方法来应对MIG任务的挑战。首先,将MIG任务分解为几个子任务,每个子任务涉及一个实例的着色。为了确保每个实例的精确着色,引入了一种实例增强注意力机制。最后,聚合所有着色的实例,为准确生成多个实例的稳定扩散提供必要的信息(SD)。为了评估生成模型在MIG任务上的表现,提供一个COCO-MIG基准测试以及一个评估流程。
在提出的COCO-MIG基准测试以及各种常用基准测试上进行了大量实验。评估结果展示了模型在数量、位置、属性和交互方面的出色控制能力。https://migcproject.github.io/
19、One-dimensional Adapter to Rule Them All: Concepts, Diffusion Models and Erasing Applications

商业和开源扩散模型(DMs)在文本到图像生成中的普遍使用引发了风险缓解,以防止不需要的行为。学术界已有的概念消除方法都是基于完全参数或基于规范的微调,从中观察到以下问题:1)向侵蚀方向的生成变化:目标消除过程中的参数漂移会导致生成过程中的变化和潜在变形,甚至会以不同程度侵蚀其他概念,这在多概念消除的情况下更为明显;2)无法转移和部署效率低下:以往的模型特定概念消除阻碍了概念的灵活组合和对其他模型的免费转移,导致部署的成本随着部署场景的增加而线性增长。
为实现非侵入式、精确、可定制和可转移的消除,将消除框架建立在一维适配器上,一次性从大多数DMs中消除多个概念,跨多种消除应用场景。概念-半渗透结构被注入到任何DM中作为膜(SPM),以学习有针对性的消除,并通过一种新的潜在锚定微调策略有效缓解变化和侵蚀现象。一旦获得,SPMs可以灵活组合并插入到其他DM中,无需特定的重新微调,能够及时高效地适应各种场景。在生成过程中,激活传输机制动态调节每个SPM的渗透性以响应不同的输入提示,进一步最小化对其他概念的影响。
在大约40个概念、7个DM和4个消除应用上的定量和定性结果证明了SPM的出色消除能力。https://lyumengyao.github.io/projects/spm
20、FlashEval: Towards Fast and Accurate Evaluation of Text-to-image Diffusion Generative Models

近年来,文本到图像生成模型的发展取得重大进展。 评估生成模型的质量是开发过程中的重要步骤之一。 评估过程可能会消耗大量的计算资源,使得所需的模型性能定期评估(例如监控训练进度)变得不切实际。 因此寻求通过选择文本图像数据集的代表性子集来提高评估效率。
本文系统研究设计选择,包括选择标准(纹理特征或基于图像的指标)和选择粒度(提示级别或集合级别)。发现之前关于训练数据子集选择的工作中的见解并不能推广到这个问题,因此提出 FlashEval,一种针对评估数据选择而定制的迭代搜索算法。 展示 FlashEval 对具有各种配置的扩散模型进行排名的有效性,包括 COCO 和 DiffusionDB 数据集上的架构、量化级别和采样器。 搜索的 50 项子集可以实现与随机采样的 500 项子集相当的评估质量,以在未见过的模型上进行 COCO 标注,从而实现 10 倍的评估加速。 后续将发布这些常用数据集的压缩子集,以帮助促进扩散算法的设计和评估,并开源 FlashEval 作为压缩未来数据集的工具。
三、风格迁移21、DEADiff: An Efficient Stylization Diffusion Model with Disentangled Representations

基于文本到图像扩散模型在迁移参考风格方面具有巨大潜力。然而,当前基于编码器的方法在迁移风格时显著损害了文本到图像模型的文本可控性。本文提出DEADiff来解决这个问题,采用以下两种策略:1)一种解耦参考图像的风格和语义的机制。解耦后的特征表示首先由不同文本描述指导的Q-Formers提取。然后,它们被注入到交叉注意力层的相互排除的子集中,以实现更好的分解。2)一种非重构学习方法。Q-Formers使用成对图像而不是相同的目标进行训练,其中参考图像和真实图像具有相同的风格或语义。
展示DEADiff在视觉风格化结果上取得了最佳效果,并在量化和定性上表现出文本可控性与与参考图像风格相似性之间的最佳平衡。https://tianhao-qi.github.io/DEADiff/
22、Deformable One-shot Face Stylization via DINO Semantic Guidance

本文针对One-shot人脸风格化问题进行研究,关注外观和结构的同时考虑。探索了与传统的单幅图像风格参考不同的变形感知人脸风格化。方法核心是利用自监督视觉transformer,具体来说是DINO-ViT,建立起强大而一致的人脸结构表示,涵盖真实和风格化领域。风格化过程首先通过将StyleGAN生成器适应到具有变形感知能力的状态,通过集成空间transformer(STN)来实现。然后,在DINO语义的引导下,引入两个创新的约束来指导生成器的微调:i)方向变形损失,调整DINO空间中的方向向量;ii)基于DINO令牌自相似性的相对结构一致性约束,确保多样化生成。此外,采用样式混合来使颜色生成与参考图像一致,减少不一致的对应关系。
方法为One-shot人脸风格化提供了更好的可变形性能,并在大约10分钟的微调时间内实现了显著的效率。广泛的定性和定量比较证明方法人脸风格化方法方面的优越性。https://github.com/zichongc/DoesFS
23、One-Shot Structure-Aware Stylized Image Synthesis

虽然基于GAN的模型在图像风格化任务上取得成功,但在对各种输入图像进行风格化时往往难以保持结构的完整性。最近,扩散模型已被用于图像风格化,但仍然缺乏保持输入图像原始质量的能力。
本文提出OSASIS:一种新的One-Shot风格化方法,具有结构保持的鲁棒性。展示了OSASIS能够有效地将图像的语义和结构解耦,使其能够控制给定输入中的内容和风格水平。将OSASIS应用于各种实验设置,包括使用域外参考图像进行风格化以及使用文本驱动的操作进行风格化。结果表明,OSASIS在风格化方法方面表现出色,特别是对于训练中很少遇到的输入图像,为扩散模型风格化提供了有希望的解决方案。
四、人像生成24、Coarse-to-Fine Latent Diffusion for Pose-Guided Person Image Synthesis

扩散模型已用于姿势引导的人物图像合成中。而现有方法仅仅将人物外貌与目标姿势对齐,由于在源人物图像上缺乏高层语义理解,容易出现过拟合的问题。
本文提出一种用于姿势引导的人物图像合成的新方法——粗到精的潜在扩散(CFLD)。在缺乏图像-文本配对和文本提示的情况下,开发一种纯粹基于图像的训练范式,用于控制预训练文本到图像扩散模型的生成过程。设计一个感知精化解码器,用于逐渐优化一组可学习的查询并提取人物图像的语义理解作为粗粒度提示。这使得在不同阶段解耦细粒度外貌和姿势信息控制成为可能,从而避免潜在的过拟合问题。
为生成更真实的纹理细节,提出一种混合粒度注意力模块,用于将多尺度的细粒度外貌特征编码为偏差项,以增强粗粒度提示。在DeepFashion基准测试上的定量和定性实验证明方法在PGPIS方面相对于现有技术的优越性。https://github.com/YanzuoLu/CFLD
25、High-fidelity Person-centric Subject-to-Image Synthesis

基于目标主体的图像生成方法,生成以人物为中心的图像面临着重大挑战。原因在于它们通过对共同预训练扩散进行微调来学习语义场景和人物生成,这涉及到无法调和的训练不平衡。为了生成逼真的人物,它们需要对预训练模型进行充分调整,这不可避免地导致模型忘记丰富的语义场景先验,并且使场景生成过度适应训练数据。此外,即使经过充分微调,这些方法仍然无法生成高保真度的人物,因为场景和人物生成的联合学习也会导致质量的折衷。
本文提出Face-diffuser,一种有效的协作生成流水线,以消除上述训练不平衡和质量折衷。具体而言,首先开发两种专门的预训练扩散模型,即文本驱动扩散模型(TDM)和主体增强扩散模型(SDM),用于场景和人物的生成。采样过程分为三个顺序阶段,即语义场景构建、主体-场景融合和主体增强。第一和最后阶段分别由TDM和SDM完成。主体-场景融合阶段通过一种新且高效的机制实现,即基于显著性自适应噪声融合(SNF)。具体来说,它基于本文核心观察结果,即分类器无关指导响应与生成图像的显著性之间存在强大的联系。在每个时间步骤中,SNF利用了每个模型的独特优势,并以一种自适应于显著性的方式自动地进行两个模型预测噪声的空间混合,所有这些都可以无缝地集成到DDIM采样过程中。
实验证实Face-diffuser在生成高保真度人物图像方面的卓越效果。https://github.com/CodeGoat24/Face-diffuser
26、Towards Effective Usage of Human-Centric Priors in Diffusion Models for Text-based Human Image Generation

传统的文本到图像扩散模型在生成准确的人物图像方面存在困难,例如不自然的姿势或不成比例的肢体。现有方法大多通过在模型微调阶段添加额外的图像或人体中心先验(例如姿势或深度图)来解决这个问题。本文探讨的是将这些人体中心先验直接集成到模型微调阶段,从而在推理阶段消除额外条件的需求。
通过引入人体中心对齐损失,在交叉注意力图中增强来自文本提示的与人相关的信息,实现了这一想法。为在微调过程中保证语义细节丰富性和人体结构准确性,根据对交叉注意力层的深入分析,引入尺度感知和分步约束。
实验结果表明,方法在基于用户编写的提示语生成高质量人物图像方面取得较大改进。https://hcplayercvpr2024.github.io/
27、A Unified and Interpretable Emotion Representation and Expression Generation

情绪,如快乐、悲伤和害怕,很容易理解和标注。情绪经常是复合的,例如快乐惊讶,并且可以映射到用于表达情绪的动作单元(AUs)。情绪是连续的,由arousal-valence(AV)模型表示。对于情绪的更好表示和理解,希望能够将这四种模态-即经典的、复合的、AUs和AV-统一起来。然而,这种统一仍未知。
这项工作提出一个可解释且统一的情绪模型,称为C2A2。还开发了一种方法,利用非统一模型的标签来标注新的统一模型。最后,修改文本条件的扩散模型,以理解连续数字,然后用统一情绪模型生成连续表达。
定量和定性实验,展示生成的图像丰富且捕捉到细微的表情。工作允许与其他文本输入一起精细生成表情,并同时为情绪提供了一个新的标签空间。https://emotion-diffusion.github.io/
28、CosmicMan: A Text-to-Image Foundation Model for Humans

提出CosmicMan,一种用于生成高保真人体图像的文本到图像基础模型。与当前困在人体图像质量和文本-图像不对齐困境中的通用基础模型不同,CosmicMan能够生成具有细致外貌、合理结构和精确文本-图像对齐的逼真人体图像,同时还提供详细的密集描述。CosmicMan关键在于对数据和模型的新的反思和观点:
(1)发现高质量的数据和可扩展的数据生成流程,对训练模型最终结果至关重要。因此,提出一个新的数据生成范式Annotate Anyone,作为一个持续的数据产生流程,通过经济高效的标注产生高质量数据。基于此,构建一个数据集CosmicMan-HQ 1.0,包含600万张高质量的真实人体图像,分辨率平均为1488×1255,并附带来自1.15亿个属性的精确文本标注,涵盖不同层次。
(2)一个专门用于生成人体图像的文本到图像基础模型必须是实用的,易于集成到下游任务中,同时在生成高质量人体图像方面有效。因此,提出以分解的方式建模密集文本描述和图像像素之间的关系,并提出Decomposed-Attention-Refocusing(Daring)训练框架。它无缝分解现有文本到图像扩散模型中的交叉注意力特征,并在不添加额外模块的情况下强制进行注意力重点调整。通过Daring,展示将连续文本空间明确离散化为与人体结构对齐的几个基本组是解决轻松解决不对齐问题的关键。https://cosmicman-cvpr2024.github.io/
29、DiffHuman: Probabilistic Photorealistic 3D Reconstruction of Humans

提出DiffHuman,一种从单个RGB图像中逼真重建人体的方法。这个问题本质上没有解,大多数方法是确定性的,并且输出一个单一的解决方案,通常导致未见或不确定区域缺乏几何细节和模糊。DiffHuman基于输入的2D图像预测了一个条件于3D重建的概率分布,这可以采样多个与输入图像一致的详细3D角色。
DiffHuman被实现为一个条件扩散模型,用于去噪像素对齐的2D观察结果,并通过迭代去噪预测的3D表示的2D渲染结果来采样3D角色。此外,还引入一个生成器神经网络,极大减少运行时间(加速55倍),从而实现一个新的双分支扩散框架。
实验结果表明,DiffHuman能够为输入图像中不可见或不确定的人物部位产生多样且详细的重建结果,同时在重建可见表面时与最先进方法竞争力十足。
30、Texture-Preserving Diffusion Models for High-Fidelity Virtual Try-On

图像虚拟试穿对于在线购物变得越来越重要。目标是合成一个指定人物穿着指定服装的图像。基于扩散模型的方法最近变得流行,因为它们在图像合成任务中表现出色。然而,这些方法通常会使用额外的图像编码器,并依赖于跨注意机制从服装到人物图像进行纹理迁移,这会影响试穿的效率和保真度。
为解决这些问题,提出一种保持纹理的扩散(TPD)模型用于虚拟试穿,以增强结果的保真度,并且不引入额外的图像编码器。因此,从两个方面做贡献。首先,将掩码的人物和参考服装图像沿空间维度进行连接,并利用生成模型的去噪UNet的输出图像作为输入。这使得扩散模型中原始的自注意力层能够实现高效而准确的纹理转移。其次,提出一种基于扩散方法,根据人像和参考服装图像预测一个精确的修复遮罩,进一步增强试穿结果的可靠性。此外,将遮罩预测和图像合成整合到一个紧凑的模型中。
实验结果表明,方法可以应用于各种试穿任务,例如从服装到人物的试穿和人物之间的试穿,并且在流行的 VITON、VITON-HD 数据库上明显优于现有方法。
五、图像超分31、Arbitrary-Scale Image Generation and Upsampling using Latent Diffusion Model and Implicit Neural Decoder

超分辨率(SR)和图像生成是计算机视觉中重要的任务,在现实应用中得到广泛采用。然而,大多数现有方法仅在固定放大倍数下生成图像,并且容易出现过平滑和伪影。此外,在输出图像的多样性和不同尺度下的一致性方面也不足。大部分相关工作应用了隐式神经表示(INR)到去噪扩散模型中,以获得连续分辨率的多样化且高质量的SR结果。由于该模型在图像空间中操作,所以产生分辨率越大的图像,需要的内存和推理时间也越多,并且它也不能保持尺度特定的一致性。
本文提出一种新流程,可在任意尺度上对输入图像进行超分辨率处理或从随机噪声生成新图像。方法由一个预训练的自编码器、一个潜在扩散模型和一个隐式神经解码器以及它们的学习策略组成。方法采用潜在空间中的扩散过程,因此高效且与由MLP在任意尺度上解码的输出图像空间保持对齐。更具体说,任意尺度解码器是由预训练自编码器的无上采样对称解码器和局部隐式图像函数(LIIF)串联而成的。通过去噪和对齐损失联合学习潜在扩散过程。输出图像中的误差通过固定解码器进行反向传播,提高输出质量。
通过在包括图像超分辨率和任意尺度上的新图像生成这两个任务上使用多个公共基准测试进行广泛实验,方法在图像质量、多样性和尺度一致性等指标上优于相关方法。在推理速度和内存使用方面,它比相关先前技术明显更好。
32、Diffusion-based Blind Text Image Super-Resolution

恢复退化的低分辨率文本图像是一项具有挑战性的任务,特别是在现实复杂情况下处理带有复杂笔画和严重退化的中文文本图像。保证文本的保真度和真实性风格对于高质量的文本图像超分辨率非常重要。最近,扩散模型在自然图像合成和恢复方面取得成功,因为它们具有强大的数据分布建模能力和数据生成能力。
这项工作提出一种基于图像扩散模型(IDM)的文本图像恢复方法,可以恢复带有真实风格的文本图像。对于扩散模型来说,它们不仅适用于建模真实的图像分布,而且也适用于学习文本的分布。由于文本先验对于根据现有艺术品保证恢复的文本结构的正确性非常重要,还提出了一种文本扩散模型(TDM)用于文本识别,可以指导IDM生成具有正确结构的文本图像。进一步提出一种多模态混合模块(MoM),使这两个扩散模型在所有扩散步骤中相互合作。
对合成和现实世界数据集的广泛实验证明,基于扩散的盲文本图像超分辨率(DiffTSR)可以同时恢复具有更准确的文本结构和更真实的外观的文本图像。
33、Text-guided Explorable Image Super-resolution

本文介绍零样本文本引导的开放域图像超分辨率解决方案的问题。目标是允许用户在不明确训练这些特定退化的情况下,探索各种保持与低分辨率输入一致的、语义准确的重建结果。
提出两种零样本文本引导超分辨率的方法,一种是修改文本到图像(T2I)扩散模型的生成过程,以促进与低分辨率输入的一致性,另一种是将语言引导融入零样本扩散式恢复方法中。展示了这些方法产生的多样化解决方案与文本提示所提供的语义意义相匹配,并且保持与退化输入的数据一致性。评估提出的基线方法在极端超分辨率任务上的任务表现,并展示了在恢复质量、多样性和解决方案的可探索性方面的优势。
34、Building Bridges across Spatial and Temporal Resolutions: Reference-Based Super-Resolution via Change Priors and Conditional Diffusion Model

基于参考的超分辨率(RefSR)有潜力在遥感图像的空间和时间分辨率之间建立桥梁。然而,现有的 RefSR 方法受到内容重建的忠实度和大比例因子下纹理传输的有效性的限制。 条件扩散模型为生成逼真的高分辨率图像开辟了新的机会,但在这些模型中有效利用参考图像仍然是进一步探索的领域。 此外,在没有相关参考信息的地区,内容保真度也难以保证。
为解决这些问题,提出一种名为 Ref-Diff for RefSR 的变化感知扩散模型,使用土地覆盖变化先验来明确指导去噪过程。 具体来说,将先验注入到去噪模型中,以提高未变化区域中参考信息的利用率,并规范变化区域中语义相关内容的重建。 借助这种强大的指导,将语义引导去噪和参考纹理引导去噪过程解耦,以提高模型性能。
实验表明,与最先进的 RefSR 方法相比,该方法在定量和定性评估方面均具有卓越的有效性和鲁棒性。https://github.com/dongrunmin/RefDiff
六、图像恢复35、Boosting Image Restoration via Priors from Pre-trained Models

以CLIP和稳定扩散为代表的使用大规模训练数据的预训练模型,在图像理解和从语言描述生成方面展现显著性能。然而,它们在图像恢复等低级任务中的潜力相对未被充分探索。本文探索这些模型来增强图像恢复。
由于预训练模型的现成特征(off-the-shelf features,OSF)并不能直接用于图像恢复,提出一个学习额外的轻量级模块——预训练引导细化模块(Pre-Train-Guided Refinement Module,PTG-RM),用于通过OSF改进目标恢复网络的恢复结果。PTG-RM由两个组成部分组成,预训练引导空间变化增强(Pre-Train-Guided Spatial-Varying Enhancement,PTG-SVE)和预训练引导通道-空间注意力(Pre-TrainGuided Channel-Spatial Attention,PTG-CSA)。PTG-SVE可以实现最佳的短和长距离神经操作,而PTG-CSA增强了与恢复相关的空间-通道注意力。
实验证明,PTG-RM以其紧凑的体积(小于1M参数)有效地增强了不同任务中各种模型的恢复性能,包括低光增强、去雨、去模糊和去噪。
36、Image Restoration by Denoising Diffusion Models with Iteratively Preconditioned Guidance

训练深度神经网络已成为解决图像恢复问题的常用方法。对于每个模型训练一个“任务特定”的网络的替代方法是,使用预训练的深度去噪器仅在迭代算法中强加信号先验,而无需额外训练。最近,这种方法基于采样的变体在扩散/基于分数的生成模型兴起时变得流行起来。
本文提出一种新的引导技术,基于预处理,可以沿着恢复过程从基于BP的引导过渡到基于最小二乘的引导。所提出方法对噪声具有鲁棒性,而且实施起来比替代方法更简单(例如,不需要SVD或大量迭代)。将其应用于优化方案和基于采样的方案,并展示其在图像去模糊和超分辨率方面相比现有方法的优势。
37、Diff-Plugin: Revitalizing Details for Diffusion-based Low-level Tasks

在大规模数据集上训练的扩散模型取得显著进展。然而,由于扩散过程中的随机性,它们经常难以处理需要保留细节的不同低层次任务。为克服这个限制,提出一个新的Diff-Plugin框架,使单个预训练的扩散模型能够在各种低层次任务中生成高保真度的结果。
具体来说,首先提出一个轻量级的Task-Plugin模块,采用双分支设计,提供任务特定的先验知识,引导扩散过程中的图像内容保留。然后,提出一个Plugin-Selector,可以根据文本指令自动选择不同的Task-Plugin,允许用户通过自然语言指示进行多个低层次任务的图像编辑。
在8个低层次视觉任务上进行大量实验结果表明,Diff-Plugin在现实场景中比现有方法表现优越。消融实验证实了Diff-Plugin在不同数据集大小下的稳定性、可调度性和支持鲁棒训练的特点。https://yuhaoliu7456.github.io/Diff-Plugin/
38、Selective Hourglass Mapping for Universal Image Restoration Based on Diffusion Model

通用图像恢复,一项实际且有潜力的计算机视觉任务,适用于实际应用。这一任务主要挑战是同时处理不同的退化分布。现有方法主要利用任务特定条件(例如提示)来指导模型单独学习不同的分布,称为多部分映射。然而,对于通用模型学习来说,这种方法并不适用,因为它忽视了不同任务之间的共享信息。
这项工作基于扩散模型提出一种先进的选择性沙漏映射策略,称为DiffUIR。DiffUIR具有两个新的考虑因素。首先,为模型提供强大的条件指导,以获得精确的扩散模型生成方向(选择性)。更重要的是,DiffUIR将一种灵活的共享分布项(SDT)巧妙地集成到扩散算法中,逐渐将不同的分布映射到一个共享分布中。在反向过程中,结合SDT和强大的条件指导,DiffUIR迭代地将共享分布引导到具有高图像质量的任务特定分布(沙漏)。
通过只修改映射策略,在五个图像恢复任务、通用设置的22个基准数据集和零样本泛化设置上实现了最先进的性能。令人惊讶的是,仅用轻量级模型(仅为0.89M),就能实现出色的性能。https://github.com/iSEE-Laboratory/DiffUIR
39、Shadow Generation for Composite Image Using Diffusion Model

在图像组合( image composition)领域,为插入的前景生成逼真的阴影仍是一个巨大的挑战。以往研究开发了基于图像之间的转换模型,这些模型是在成对的训练数据上进行训练的。然而,由于数据稀缺和任务本身的复杂性,它们在生成具有准确形状和强度的阴影方面遇到困难。
本文利用具有自然阴影图像丰富先验知识的基础模型。具体来说,首先将 ControlNet 调整为适应任务,然后提出强度调制模块来提高阴影的强度。此外,用一种新的数据采集流程,将小规模的 DESOBA 数据集扩展为 DESOBAv2。在DESOBA和DESOBAv2数据集以及真实的合成图像上的实验结果表明,模型在阴影生成任务上具有更强的能力。https://github.com/bcmi/Object-Shadow-Generation-Dataset-DESOBAv2
七、目标跟踪40、Delving into the Trajectory Long-tail Distribution for Muti-object Tracking

多目标跟踪(Multiple Object Tracking,MOT)是计算机视觉领域中一个关键领域,有广泛应用。当前研究主要集中在跟踪算法的开发和后处理技术的改进上。然而,对跟踪数据本身的特性缺乏深入的研究。
本研究首次对跟踪数据的分布模式进行探索,并发现现有 MOT 数据集中存在明显的长尾分布问题。发现不同行人分布存在显著不平衡现象,将其称为“行人轨迹长尾分布”。针对这一挑战,提出一种专门设计用于减轻这种分布影响的策略。具体而言,提出两种数据增强策略,包括静态摄像机视图数据增强(SVA)和动态摄像机视图数据增强(DVA),针对视点状态,以及面向 Re-ID 的 Group Softmax(GS)模块。SVA 是为了回溯并预测尾部类别的行人轨迹,而 DVA 则使用扩散模型改变场景的背景。GS 将行人划分为不相关的组,并对每个组进行 softmax 操作。
策略可以集成到许多现有的跟踪系统中,实验证实方法在降低长尾分布对多目标跟踪性能的影响方面的有效性。https://github.com/chen-si-jia/Trajectory-Long-tail-Distribution-for-MOT
八、目标检测41、SAFDNet: A Simple and Effective Network for Fully Sparse 3D Object Detection

基于 LiDAR 的三维物体检测,在自动驾驶中起关键作用。目前已有的高性能三维物体检测器通常在骨干网络和预测头中构建密集特征图。然而,随着感知范围增加,密集特征图带来的计算成本呈二次增长,使得这些模型很难扩展到长距离检测。最近一些研究尝试构建完全稀疏的检测器来解决这个问题,然而所得模型要么依赖于复杂的多阶段流水线,要么表现不佳。
本文提出 SAFDNet,简单高效,专为完全稀疏的三维物体检测而设计。在 SAFDNet 中,设计了一种自适应特征扩散策略来解决中心特征丢失的问题。在 Waymo Open、nuScenes 和 Argoverse2 数据集上进行大量实验证明,SAFDNet 在前两个数据集上的性能略优于先前的 SOTA,但在具有长距离检测特点的最后一个数据集上表现更好,验证 SAFDNet 在需要长距离检测的场景中的有效性。
在 Argoverse2 上,SAFDNet 在速度上比先前最好的混合检测器 HEDNet 快 2.1 倍,并且相对于先前最好的稀疏检测器 FSDv2 提高了 2.1% 的 mAP,速度提高了 1.3 倍。https://github.com/zhanggang001/HEDNet
42、DetDiffusion: Synergizing Generative and Perceptive Models for Enhanced Data Generation and Perception

当前的感知模型严重依赖于资源密集型数据集,因此需要创新性的解决方案。利用最近在扩散模型和合成数据方面的进展,通过构造各种标签图像输入,合成数据有助于下游任务。尽管之前的方法已经分别解决了生成和感知模型的问题,但是 DetDiffusion 是第一个在生成有效数据的感知模型方面进行了整合的方法。
为增强感知模型的图像生成能力,引入感知损失(P.A. loss)通过分割来改善质量和可控性。为提高特定感知模型的性能,方法通过提取和利用感知感知属性(P.A. Attr)来定制数据增强。来自目标检测任务的实验结果凸显了 DetDiffusion 在布局导向生成方面的出色性能,显著提高了下游检测性能。
43、SDDGR: Stable Diffusion-based Deep Generative Replay for Class Incremental Object Detection

在类别增量学习(CIL)领域,generative replay已成为缓解灾难性遗忘的方法,随着生成模型的不断改进,越来越受到关注。然而,在类别增量物体检测(CIOD)中的应用受到很大限制,主要是由于涉及多个标签的场景的复杂性。
本文提出一种名为stable diffusion deep generative replay(SDDGR)的用于 CIOD 的新方法。方法利用基于扩散的生成模型与预训练的文本到扩散网络相结合,生成真实多样的合成图像。SDDGR采用迭代优化策略,生成高质量的旧类别样本。此外,采用L2知识蒸馏技术,以提高合成图像中先前知识的保留。此外,方法还包括对新任务图像中的旧对象进行伪标签,以防止将其错误分类为背景元素。
对COCO 2017数据集的大量实验表明,SDDGR在各种CIOD场景下明显优于现有算法,达到了新的技术水平。
九、关键点检测44、Pose-Guided Self-Training with Two-Stage Clustering for Unsupervised Landmark Discovery

无监督的Unsupervised landmarks discovery(ULD)是具有挑战性的计算机视觉问题。为利用扩散模型在ULD任务中的潜力,首先,提出一种基于随机像素位置的简单聚类的零样本ULD基线,通过最近邻匹配提供了比现有ULD方法更好的结果。其次,在零样本性能的基础上,通过自训练和聚类开发了一种基于扩散特征的ULD算法,以显著超越以前的方法。第三,引入一个基于生成潜在姿势代码的新代理任务,并提出了一个两阶段的聚类机制,以促进有效的伪标签生成,从而显著提高性能。
总的来说,方法在四个具有挑战性的基准测试(AFLW、MAFL、CatHeads 和 LS3D)上一贯优于现有的最先进方法。
十、deepfake检测45、Latent Reconstruction Error Based Method for Diffusion-Generated Image Detection

扩散模型极大提高了图像生成质量,使得真实图像和生成图像之间越来越难以区分。然而,这一发展也引发了重大的隐私和安全问题。针对这一问题,提出一种新的潜变量重构误差引导特征优化方法(Latent REconstruction error guided feature REfinement, LaRE2),用于检测生成图像。
提出潜变量重构误差(Latent Reconstruction Error,LaRE),一种基于重构误差的潜在空间特征,用于生成图像检测。LaRE 在特征提取效率方面超过了现有方法,同时保留了区分真实与伪造图像所需的关键线索。为了利用 LaRE,提出一个带有误差引导特征优化模块(EGRE)的方法,通过 LaRE 引导图像特征的优化,以增强特征的辨别力。
EGRE 采用对齐然后细化机制,可以从空间和通道角度有效地细化图像特征,以进行生成图像检测。 在大规模 GenImage 基准测试上的大量实验证明LaRE2 的优越性,在 8 个不同的图像生成器中超过了最好的 SoTA 方法,平均 ACC/AP 高达 11.9%/12.1%。 LaRE 在特征提取成本方面也超越了现有方法,速度提升8倍。
十一、异常检测46、RealNet: A Feature Selection Network with Realistic Synthetic Anomaly for Anomaly Detection

自监督特征重建方法在工业图像异常检测和定位方面显示出有希望进展。这些方法在合成真实且多样化的异常样本以及解决预训练特征的特征冗余和预训练偏差方面仍然面临挑战。
这项工作提出 RealNet,一种具有现实合成异常和自适应特征选择的特征重建网络。 它包含三个关键创新:首先,提出强度可控扩散异常合成(SDAS),一种基于扩散过程的合成策略,能够生成具有不同异常强度的样本,模仿真实异常样本的分布。 其次,开发了异常感知特征选择(AFS),一种选择具有代表性和判别性的预训练特征子集的方法,以提高异常检测性能,同时控制计算成本。 第三,引入了重建残差选择(RRS),一种自适应选择判别残差以跨多个粒度级别全面识别异常区域的策略。
在四个基准数据集上评估 RealNet,结果表明与当前最先进的方法相比,图像 AUROC 和像素 AUROC 都有改进。https://github.com/cnulab/RealNet
十二、抠图/分割47、In-Context Matting

提出In-Context Matting上下文抠图,一种图像抠图的新任务设置。在给定某个前景参考图像和点、涂鸦和遮罩等引导先验的情况下,上下文抠图能够在一批具有相同前景类别的目标图像上进行自动alpha估计,而无需额外的辅助输入。这种设置,在基于辅助输入的抠图中具有良好的性能,在自动抠图的易用性之间取得良好平衡。
为克服准确前景匹配这一挑战,引入IconMatting,一种基于预训练的文本到图像扩散模型构建的上下文抠图模型。通过在相似性匹配中引入内部和外部相似性匹配,IconMatting可以充分利用参考上下文生成准确的目标alpha遮罩。为对该任务进行基准测试,还引入一个新的测试数据集ICM-57,包括57组真实世界图像。https://github.com/tiny-smart/in-context-matting/tree/master
十三、图像压缩48、Laplacian-guided Entropy Model in Neural Codec with Blur-dissipated Synthesis

将高斯解码器替换为条件扩散模型,可以增强神经图像压缩中重建图像的感知质量,但由于它们对图像数据缺乏归纳偏差,限制了它们实现最先进感知水平的能力。
为解决这个限制,采用non-isotropic的扩散模型在解码器端。该模型对区分频率内容施加了归纳偏差,从而便于生成高质量图像。此外配备一种新的熵模型,通过利用潜在空间中的空间通道相关性准确地建模潜在表示的概率分布,从而加速熵解码步骤。这种基于通道的熵模型利用每个通道块内的局部和全局空间上下文。全局空间上下文是基于Transformer构建的,专门用于图像压缩任务。设计的Transformer采用拉普拉斯形状的位置编码,其可学习的参数根据每个通道簇进行自适应调整。
实验证明,框架能够提供更好的感知质量,并且所提出的熵模型可显著节省比特率。
十四、视频理解49、Abductive Ego-View Accident Video Understanding for Safe Driving Perception

提出一个新的多模态事故视频理解数据集MM-AU(Multi-Modal Accident video Understanding)。MM-AU包含11,727个自然场景下的 ego-view事故视频,每个视频都有时间对齐的文本描述。标注了超过223万个物体框和58,650对基于视频的事故原因,涵盖了58个事故类别。MM-AU支持各种事故理解任务,特别是通过多模态视频扩散来理解安全驾驶的事故因果链。
使用MM-AU,提出一个用于安全驾驶感知的推论事故视频理解框架(Abductive accident Video understanding framework for Safe Driving perception,AdVersa-SD)。AdVersa-SD,一种由CLIP模型驱动的以对象为中心的视频扩散(Object-Centric Video Diffusion,OAVD)方法。该模型涉及对正常、接近事故和事故帧与相应文本描述之间的对比交互损失的学习,例如事故原因、预防建议和事故类别。OAVD在生成视频时强制执行因果区域学习,同时在视频生成中固定原始帧背景的内容,以找到某些事故的主要因果链。
实验证明AdVersa-SD的推理能力以及OAVD相对于最先进的扩散模型的优势。此外,还对物体检测和事故原因回答进行了仔细的基准评估,因为AdVersa-SD依赖于精确的物体和事故原因信息。http://www.lotvsmmau.net/
十五、视频生成50、FRESCO: Spatial-Temporal Correspondence for Zero-Shot Video Translation

文本到图像扩散模型激发对其在视频领域潜在应用的探索。零样本方法将图像扩散模型扩展到视频领域,而无需进行模型训练。最近方法主要侧重于将帧间对应关系纳入注意机制中。然而,决定在哪里关注有效特征的软约束有时可能不足,导致时间上的不一致性。
本文提出FRESCO,将帧内对应与帧间对应结合起来,建立更强大的时空约束。这种改进确保了在帧之间保持具有语义相似内容的一致转换。除注意引导之外,方法还涉及特征的显式更新,以实现与输入视频的高时空一致性,从而显著提高所生成视频的视觉连贯性。
实验证明提出的框架在生成高质量、连贯的视频方面的有效性,这在现有的零样本方法中取得了显著改进。
51、Grid Diffusion Models for Text-to-Video Generation

从文本生成视频,比从文本生成图像更具挑战性,因为需要更大数据集和更高计算成本。大多数现有的视频生成方法使用考虑时间维度的3D U-Net架构或自回归生成。与文本到图像生成相比,这些方法需要大数据集,且在计算成本方面有限制。
为应对这些挑战,提出一种简单有效的文本到视频生成的新方法,方法在架构中不考虑时间维度,且需具有大型的文本-视频配对数据集。可使用固定量的GPU内存生成高质量的视频,而不管帧数多少,方法是将视频表示为网格图像。此外,由于方法将视频的维度减小到图像的维度,可以将各种基于图像的方法应用于视频,如从图像操纵进行文本引导的视频操纵。方法在定量和定性评估方面优于现有方法,证明模型适用于实际视频生成。
52、TRIP: Temporal Residual Learning with Image Noise Prior for Image-to-Video Diffusion Models

将扩散模型应用于将静态图像转化为动态图像(即图像到视频生成)时,并非易事。困难之处在于,生成的连续动画帧的扩散过程不仅应保持与给定图像的对齐,还应在相邻帧之间追求时序连贯性。
为缓解这一问题,提出TRIP,一种基于图像噪声先验的图像到视频扩散范式的新方法。通过图像噪声先验从静态图像派生出来,通过一步反向扩散过程,基于静态图像和有噪视频潜码。接下来,TRIP执行类似于残差的双通路方案进行噪声预测:1)shortcut路径直接将图像噪声先验作为每一帧参考噪声,以增强第一帧和后续帧之间的对齐;2)残差路径利用3D-UNet对有噪视频和静态图像潜在代码进行研究,以实现帧间关系推理,从而减轻为每帧学习残差噪声。此外,每帧的参考噪声和残差噪声通过注意机制动态合并,用于最终视频生成。
在WebVid-10M、DTDB和MSRVTT数据集上的大量实验证明TRIP用于图像到视频生成的有效性。https://trip-i2v.github.io/TRIP/
53、Co-Speech Gesture Video Generation via Motion-Decoupled Diffusion Model

协同言语手势Co-speech gestures,如果以生动的视频形式呈现,可以在人机交互中实现更优视觉效果。之前研究主要生成结构化的人类骨架,导致外貌信息被省略。本文关注于直接生成音频驱动的co-speech gesture视频。
两个主要挑战:1)需要合适的运动特征来描述具有关键外貌信息的复杂人体动作。2)手势和语音表现出内在的依赖性,即使长度任意,也应该在时间上保持对齐。为解决这些问题,提出一种新的运动解耦框架来生成共同言语手势视频。首先引入一个经过精心设计的非线性TPS变换,以获取保留关键外貌信息的潜在运动特征。然后,提出基于Transformer的扩散模型,学习手势和语音之间的时间相关性,并在潜在运动空间中进行生成,随后通过最优运动选择模块产生长期连贯且一致的手势视频。
为更好的视觉感知,进一步设计一个着重于某些区域缺失细节的细化网络。实验结果表明,在运动和视频相关的评估中明显优于现有方法。https://github.com/thuhcsi/S2G-MDDiffusion
54、Video Interpolation With Diffusion Models

提出VIDIM,用于视频插值的生成模型,可以在给定起始和结束帧的情况下生成短视频。为实现高保真度并生成输入数据中未见过的运动,VIDIM使用级联扩散模型首先在低分辨率下生成目标视频,然后在低分辨率生成的视频的条件下生成高分辨率视频。
将VIDIM与先前的最先进方法在视频插值上进行比较,并展示在基于复杂、非线性或不确定运动的大多数情况下,这些方法如何失败,而VIDIM可以轻松处理这些情况。还展示在起始和结束帧上进行无分类器指导,并将超分辨率模型与原始高分辨率帧进行条件化,而无需额外的参数,从而实现高保真结果。
VIDIM的采样速度快,它联合去噪要生成的所有帧,每个扩散模型仅需要不到十亿个参数即可产生引人注目的结果,并且仍然在较大的参数数量下具有可扩展性和提高的质量。https://vidim-interpolation.github.io/
十六、倾听人生成55、CustomListener: Text-guided Responsive Interaction for User-friendly Listening Head Generation
Listening head生成,目的是通过模拟动态转换过程中说话者与听话者之间的关系,合成一个非言语反应型听话者头。虚拟交互中侦听代理生成技术的应用,促进许多实现多样化、细粒度运动生成的工作。然而,他们只能通过简单的情绪标签来操纵动作,而不能自由地控制听者的动作。因为监听代理应该具有类似人类的属性(如身份、个性),可以由用户自由定制,这限制了它们的现实性。
本文提出一个用户友好的名为CustomListener的框架来实现free-form text prior guided listener generation。为实现说话者和听者的协调,设计一个静态到动态画像模块(SDP),该模块与说话者信息交互,将静态文本转换为具有补全节奏和幅度信息的动态肖像token。为实现片段之间的一致性,设计一个过去引导生成模块(Past Guided Generation Module, PGG),通过运动先验来保持定制听者属性的一致性,并利用以人像token和运动先验为条件的基于扩散的结构来实现可控生成。
为训练和评估模型,基于ViCo和RealTalk构建了两个文本标注的listening head数据集,它们提供文本视频配对标签。大量的实验验证了该模型的有效性。https://customlistener.github.io/
十七、数字人生成56、Make-Your-Anchor: A Diffusion-based 2D Avatar Generation Framework

尽管基于说话人生成(talking-head)解决方案已经取得进展,但直接生成具有全身动作的anchor风格视频仍具有挑战性。本研究提出一种名为Make-Your-Anchor的新系统,只需要一个人的一分钟视频片段进行训练,随后就能自动生成具有精确躯干和手部动作的视频。
具体而言,在输入视频上对一个提出的结构引导扩散模型进行微调,将三维网格条件渲染成人体外貌。采用两阶段的训练策略来对扩散模型进行训练,有效地将动作与特定外貌绑定在一起。为了生成任意长的时间视频,将帧级扩散模型中的二维U-Net扩展为三维风格,而不需要额外的训练成本,在推理过程中引入了一个简单而有效的批次重叠的时间去噪模块,绕过对视频长度的约束。最后,引入了一种新的身份特定面部增强模块,以改善输出视频中面部区域的视觉质量。
对比实验表明,该系统在视觉质量、时间连贯性和身份保护方面具有有效性和优越性,胜过了目前最先进的扩散/非扩散方法。https://github.com/ICTMCG/Make-Your-Anchor
十八、新视图生成57、EscherNet: A Generative Model for Scalable View Synthesis

提出EscherNet,多视角条件扩散模型,用于视图合成。EscherNet学习隐式生成的三维表示,结合专门的相机位置编码,可以在任意数量的参考视图和目标视图之间精确而连续地控制相机变换。
EscherNet在视图合成方面具有卓越的普适性、灵活性和可扩展性,可以在单个普通消费级GPU上同时生成100多个一致的目标视图,尽管只训练了一组固定的3个参考视图到3个目标视图。因此,EscherNet不仅解决了零样本新视图合成的问题,还自然地将单幅和多幅图像的三维重建统一在一个连贯的框架中。
实验证明,EscherNet在多个基准测试中实现了最先进的性能,即使与针对每个单独问题专门设计的方法相比也是如此。这种卓越的多功能性为设计可扩展的三维视觉神经架构开辟了新的方向。https://kxhit.github.io/EscherNet
十九、3D相关58、Bayesian Diffusion Models for 3D Shape Reconstruction

提出贝叶斯扩散模型(BDM),一种通过联合扩散过程将自上而下(先验)信息与自下而上(数据驱动)过程紧密结合的预测算法,以实现有效的贝叶斯推断。展示BDM在3D形状重构任务上的有效性。与基于配对(监督)数据标签(例如图像-点云)数据集训练的典型深度学习数据驱动方法相比,BDM从独立标签(例如点云)中引入丰富的先验信息,以改善自下而上的3D重构。与需要显式先验和似然度的标准贝叶斯框架不同,BDM通过学习梯度计算网络执行无缝信息融合,通过联合扩散过程进行。
BDM的特色在于其能够参与自上而下和自下而上过程的积极和有效的信息交换和融合,其中每个过程本身都是扩散过程。在合成和真实世界的3D形状重构基准测试中展示最先进结果。
59、DreamControl: Control-Based Text-to-3D Generation with 3D Self-Prior

3D生成,近年来引起极大关注。随文本到图像扩散模型的成功,2D技术成为一条有前途的可控3D生成路径。然而这些方法往往会呈现出不一致的几何形状,这也被称为Janus问题。观察到这个问题主要由两个方面引起,即2D扩散模型中的视角偏差和优化目标的过拟合。
为解决这个问题,提出一个两阶段的2D-lifting框架,即DreamControl,它通过优化粗糙的NeRF场景作为3D自先验,然后利用基于控制的评分蒸馏生成细粒度的物体。具体而言,提出自适应视角采样和边界完整性度量来确保生成的先验的一致性。然后,这些先验被视为输入条件,以维持合理的几何形状,其中进一步提出了条件LoRA和加权评分来优化详细的纹理。
DreamControl能够生成几何一致性和纹理保真度都很高的高质量3D内容。此外基于控制的优化指导适用于更多的下游任务,包括用户引导生成和3D动画。https://github.com/tyhuang0428/DreamControl
60、DanceCamera3D: 3D Camera Movement Synthesis with Music and Dance

编舞师确定舞蹈的外观,而摄像师确定舞蹈的最终呈现。最近,各种方法和数据集展示了舞蹈生成的可行性。然而,将音乐和舞蹈的摄像移动合成仍是一个尚未解决的挑战性问题,因为配对数据的稀缺性。
提出DCM,一个新的多模态3D数据集,首次将摄像移动与舞蹈动作和音乐音频结合起来。该数据集包括来自动漫社区的108个舞蹈序列(3.2小时)的配对舞蹈-摄像-音乐数据,涵盖4个音乐流派。通过这个数据集,揭示舞蹈摄像移动是多层次且以人为中心的,并且具有多种影响因素,使得舞蹈摄像移动合成相比之下更具挑战性,与仅有摄像或舞蹈合成相比。
为克服这些困难,提出DanceCamera3D,一种基于Transformer的扩散模型,结合了一种新的身体注意力损失和条件分离策略。为评估,设计衡量摄像移动质量、多样性和舞者真实性的新指标。利用这些指标,在DCM数据集上进行大量实验,定量和定性展示DanceCamera3D模型有效性。https://github.com/Carmenw1203/DanceCamera3D-Official
61、DiffuScene: Denoising Diffusion Models for Generative Indoor Scene Synthesis

提出基于新场景配置去噪扩散模型的DiffuScene室内3D场景合成方法。它生成存储在无序对象集中的3D实例属性,并为每个对象配置检索最相似的几何形状,该形状被描述为不同属性(包括位置、大小、方向、语义和几何特征)的串联。
引入一个扩散网络,通过去噪无序对象属性合成一组3D室内对象。无序参数化Unordered parametrization简化联合分布的近似。形状特征扩散有助于自然对象布局,包括对称性。方法能够支持许多下游应用,包括场景完成、场景布置和基于文本的场景合成。在3DFRONT数据集上的实验证明,方法能够比最先进的方法合成出更符合物理规律且多样化的室内场景。
消融研究验证了在场景扩散模型中的设计选择的有效性。https://tangjiapeng.github.io/projects/DiffuScene/
62、IPoD: Implicit Field Learning with Point Diffusion for Generalizable 3D Object Reconstruction from Single RGB-D Images

从单视角RGB-D图像中进行通用的3D物体重构,仍是一项具有挑战性的任务,特别是对于真实世界的数据。现有方法采用基于Transformer的隐式场学习,需要一种密集的学习范式,在整个空间均匀采样的密集查询监督。
提出一种新方法IPoD,将隐式场学习与点扩散相结合。这种方法将用于隐式场学习的查询点视为噪声点云,用于迭代去噪,允许它们动态适应目标物体的形状。这样的自适应查询点利用了扩散学习的粗糙形状恢复能力,并增强了隐式表示描绘更精细细节的能力。
此外,还设计了额外的自条件机制,将隐式预测用作扩散学习的引导,形成一个合作系统。在CO3D-v2数据集上进行的实验验证了IPoD的优越性,相比现有方法,在F分数上提升了7.8%,在Chamfer距离上提升了28.6%。IPoD的普适性也在MVImgNet数据集上得到验证。https://yushuang-wu.github.io/IPoD/
63、Move as You Say, Interact as You Can: Language-guided Human Motion Generation with Scene Affordance

尽管文本到动作合成取得显著进展,但在3D环境中生成语言引导的人体动作还存在一些挑战。这些挑战主要源于两个方面:一是缺乏强大的生成模型,能够联合建模自然语言、3D场景和人体动作;二是生成模型的数据需求量大,而现有的综合、高质量的语言-场景-动作数据集非常稀缺。
为解决这些问题,引入一个新的两阶段框架,该框架以场景有效性作为中间表示,有效地连接了3D场景 grounding 和条件动作生成。框架包括用于预测显式有效性图的Affordance Diffusion Model (ADM)和用于生成合理人体动作的Affordance-to-Motion Diffusion Model (AMDM)。通过利用场景有效性图,方法克服在多模态条件信号下生成人体动作的困难,特别是在训练数据有限、缺乏广泛的语言-场景-动作对的情况下。
实验证明方法在已建立的基准测试中始终优于所有对照方法,包括HumanML3D和HUMANISE。此外,还在一个特别精心策划的评估集上验证模型的泛化能力,该评估集包含以前没有见过的描述和场景。https://afford-motion.github.io/
64、MicroDiffusion: Implicit Representation-Guided Diffusion for 3D Reconstruction from Limited 2D Microscopy Projections

提出MicroDiffusion,可以从有限的二维投影中实现高质量的深度重建三维。尽管现有隐式神经表示(INR)模型通常产生不完整的输出,去噪扩散概率模型(DDPM)擅长捕捉细节,方法将INR的结构一致性与DDPM的细节增强能力相结合。
预训练一个INR模型,将二维轴向投影的图像转化为初步的三维体积。这个预训练INR模型作为全局先验,通过INR输出和噪声输入之间的线性插值来引导DDPM的生成过程。这种策略丰富了扩散过程中的结构化三维信息,增强了局部二维图像中的细节并减少了噪声。通过将扩散模型条件化于最近的二维投影,MicroDiffusion大大提高了生成的三维重建结果的保真度,超过了INR和标准DDPM的输出。https://github.com/UCSC-VLAA/MicroDiffusion
65、Sculpt3D: Multi-View Consistent Text-to-3D Generation with Sparse 3D Prior

最近关于文本到三维生成的研究表明,仅使用二维扩散监督进行三维生成往往会产生外观不一致(例如,背面视图上的脸部)和形状不准确(例如,多出来的腿部的动物)的结果。
现有方法主要通过使用从三维数据渲染的图像重新训练扩散模型来解决这个问题以确保多视角一致性,同时努力平衡二维生成质量与三维一致性。本文提出一个新框架Sculpt3D,通过从检索的参考对象中显式注入3D先验,为当前的流程提供了装配能力,而无需重新训练二维扩散模型。具体而言,通过稀疏光线采样方法演示通过关键点监督可以保证高质量和多样化的3D几何。
此外,为确保不同视角的准确外观,进一步调节二维扩散模型的输出,使其与模板视图的正确模式相符,而不改变生成的对象风格。这两个解耦的设计有效地利用了参考对象的3D信息来生成3D对象,同时保持了二维扩散模型的生成质量。实验证明方法可以大大提高多视角一致性,同时保持保真度和多样性。https://stellarcheng.github.io/Sculpt3D/
66、Score-Guided Diffusion for 3D Human Recovery

提出评分引导的人体网格恢复(Human Mesh Recovery, ScoreHMR)方法,用于解决三维人体姿势和形状重建的逆问题。ScoreHMR模仿模型拟合方法,但通过扩散模型的潜在空间中的分数引导来实现与图像观察的对齐。扩散模型的训练目标是捕捉给定输入图像的人体模型参数的条件分布。通过使用特定任务的分数引导其去噪过程,ScoreHMR有效解决各种应用程序的逆问题,而无需重新训练与任务无关的扩散模型。
在三个设置/应用程序上评估方法。分别是:(i)单帧模型拟合;(ii)从多个未标定视图重建;(iii)在视频序列中重建人体。在所有设置中,ScoreHMR在流行的基准测试中始终优于所有优化基线。https://statho.github.io/ScoreHMR/
67、Towards Realistic Scene Generation with LiDAR Diffusion Models

扩散模型在照片逼真图像生成方面表现出色,但将其应用于LiDAR场景生成则存在很大的困难。这主要是因为在点空间中操作的扩散模型很难保持LiDAR场景的曲线样式和三维几何形状,这消耗了它们的表示能力。
本文提出LiDAR扩散模型(LiDMs),以生成与LiDAR真实场景相匹配的场景,通过将几何先验纳入学习流程的潜在空间中。方法针对三个目标设置:模式真实性、几何真实性和物体真实性。
方法在无条件的LiDAR生成中实现了竞争性的性能,在有条件的LiDAR生成上达到了最先进水平,同时与基于点的扩散模型相比保持了高效性(高达107倍的速度)。此外,通过将LiDAR场景压缩为潜在空间,使得扩散模型在各种条件下具有可控性,例如语义地图、相机视图和文本提示。https://github.com/hancyran/LiDAR-Diffusion
68、VP3D: Unleashing 2D Visual Prompt for Text-to-3D Generation

关于文本到三维生成的创新推出了得分蒸馏抽样(Score Distillation Sampling,SDS),通过直接从二维扩散模型中提取先验知识,实现隐式三维模型(NeRF)的零样本学习。然而,当前基于SDS的模型在处理复杂的文本提示时仍存在困难,并且通常会导致3D模型出现畸变,具有不真实的纹理或视角不一致的问题。
这项工作引入一种新的视觉提示引导的文本到三维扩散模型(VP3D),该模型明确了2D视觉提示中的视觉外观知识,以提升文本到三维生成的效果。VP3D不仅仅通过文本提示来监督SDS,而是首先利用二维扩散模型从输入文本生成高质量图像,然后将其作为视觉提示,通过显式视觉外观来增强SDS优化。同时,将SDS优化与附加的可微分奖励函数相结合,该函数鼓励渲染3D模型的图像与2D视觉提示更好地对齐,并在语义上与文本提示匹配。
大量实验证明,VP3D中的2D视觉提示显著简化了学习三维模型的视觉外观,并因此具有更高的视觉保真度和更详细的纹理。当将自动生成的视觉提示替换为给定的参考图像时,VP3D能够触发新的任务,即风格化的文本到三维生成。https://vp3d-cvpr24.github.io/
二十、图像修复69、Structure Matters: Tackling the Semantic Discrepancy in Diffusion Models for Image Inpainting

用于图像修复的去噪扩散概率模型(DDPMs),旨在在正向过程中向图像的纹理添加噪声,并通过反向去噪过程将掩蔽区域与纹理的未掩蔽区域恢复。尽管现有方法能生成有意义的语义,但存在着掩蔽区域和未掩蔽区域之间语义不一致的问题。
本文致力于未掩蔽语义如何指导纹理去噪过程的问题,以及如何解决语义差异问题,以促进一致而有意义的语义生成。提出一种名为StrDiffusion的图像修复结构引导扩散模型,以在结构引导下重新表述传统的纹理去噪过程,得到简化的图像修复去噪目标,同时:1)在早期阶段,语义稀疏结构有助于解决语义差异问题,而在后期阶段密集纹理生成了合理的语义;2)未掩蔽区域的语义实质上为纹理去噪过程提供了时间相关的结构指导,从结构语义的时间相关稀疏性中获益。对于去噪过程,训练一个结构引导的神经网络,通过利用掩蔽区域和未掩蔽区域之间去噪结构的一致性来估计简化的去噪目标。
此外,设计一种自适应重采样策略作为是否结构能够指导纹理去噪过程的一个正式准则,同时调节它们之间的语义相关性。大量实验证实StrDiffusion相对于目前最先进的方法的优点。https://github.com/htyjers/StrDiffusion
二十一、草图相关70、It’s All About Your Sketch: Democratising Sketch Control in Diffusion Models

本文揭示扩散模型中素描的潜力,解决生成人工智能中直接素描控制的误导性问题。使素人素描能够生成精确的图像,实现了“你描绘的就是你得到的”。
提出一个意识分级的框架,利用一个素描适配器、自适应时间步采样以及一个预先训练的细粒度素描图像检索模型的判别性指导,协同工作来加强细粒度素描-照片关联。方法在推理过程中可以无缝操作,无需文本提示;一个简单的、粗略的素描足以胜任我们普通人的创作!
71、Text-to-Image Diffusion Models are Great Sketch-Photo Matchmakers
本文首次探索零样本基于草图的图像检索(ZS-SBIR)中的文本到图像扩散模型。突出表明文本到图像扩散模型在草图和照片之间无缝桥接的能力。这种能力是由它们稳健的跨模态能力和形状偏倚支撑的,这些发现通过初步研究得到证实。
为有效利用预训练的扩散模型,引入一个简单但强大的策略,重点关注两个关键方面:选择最佳的特征层和利用视觉和文本提示。对于前者,确定哪些层富含信息并且最适合特定的检索要求(类别级别或细粒度级别)。然后,使用视觉和文本提示来指导模型的特征提取过程,使其生成更有区分性和上下文相关的跨模态表示。在几个基准数据集上进行的广泛实验证实了显著的性能改进。
二十二、版权隐私72、CGI-DM: Digital Copyright Authentication for Diffusion Models via Contrasting Gradient Inversion

扩散模型(DMs)用于少样本生成,其中预训练模型在少量样本图像上进行微调以捕捉特定的风格或对象。尽管取得成功,但人们对使用未经授权的数据可能导致侵权问题存在担忧。因此,提出一种名为CGI-DM的对比梯度反转扩散模型的新方法,具有生动的视觉表示,用于数字版权认证。
方法涉及去除图像的部分信息,并通过利用预训练模型和微调模型之间的概念差异来恢复丢失的细节。将二者的潜变量之间的差异形式化为KL散度,当给定相同的输入图像时,可以通过蒙特卡洛采样和投影梯度下降来最大化这种差异。原始图像和恢复图像之间的相似性可以作为潜在侵权行为的强有力指标。
在WikiArt和Dreambooth数据集上进行的大量实验证明了CGI-DM在数字版权认证中的高准确性,超过了其他验证技术。https://github.com/Nicholas0228/Revelio
73、CPR: Retrieval Augmented Generation for Copyright Protection

检索增强生成(Retrieval Augmented Generation,RAG)是一种灵活且强大的技术,可以在不进行训练的情况下,将模型适应私有用户数据,处理信用归因(credit attribution),并允许大规模高效machine unlearning。然而,图像生成的RAG技术可能导致检索样本的部分内容被复制到模型的输出中。
为减少泄漏检索集合中包含私人信息风险,提出带有检索的受版权保护生成(Copy-Protected generation with Retrieval,CPR),一种在混合私人环境中具有强版权保护保证的RAG新方法,适用于扩散模型。
CPR将扩散模型的输出与一组检索图像相关联,同时保证在生成的输出中不会暴露有关这些示例的唯一可识别信息。具体而言,它通过在推断时合并公共(安全)分布和私人(用户)分布的扩散分数,从公开(安全)分布和私有(用户)分布的混合中进行采样来实现。CPR满足接近访问无关性(NAF),该性质限制了攻击者可能从生成的图像中提取的信息量。提供两种用于版权保护的算法,CPR-KL和CPR-Choose。与之前提出的基于拒绝采样的NAF方法不同,方法能够通过单次向后扩散运行进行高效的版权受保护的采样。
展示了方法如何应用于任何预训练的条件扩散模型,例如Stable Diffusion或unCLIP。特别地,通过实验证明,将CPR应用于unCLIP上可以提高生成结果的质量和文本到图像的对齐性(在TIFA基准上从81.4提高到83.17)。
二十三、数据增广74、SatSynth: Augmenting Image-Mask Pairs through Diffusion Models for Aerial Semantic Segmentation

在最近几年中,语义分割已成为处理和解释卫星图像的关键工具。然而,监督学习技术的主要限制仍然是需要专家进行大量手动标注。本研究探索使用生成图像扩散来解决地球观测任务中标注数据稀缺性的潜力。主要思想是学习图像和标签的联合数据流形,借助于最近在去噪扩散概率模型中的进展。
本文自称是第一个为卫星分割生成图像和相应掩膜的工作。获得的图像和掩膜对不仅在细粒度特征上具有高质量,而且确保了广泛的采样多样性。这两个方面对于地球观测数据至关重要,因为语义类别在尺度和出现频率上可能有严重变化。将新的数据实例用于下游分割,作为数据增强的一种形式。
实验与基于辨别性扩散模型或GAN的之前的工作进行比较。证明整合生成样本可以显著改善卫星语义分割的定量结果,不仅与基线相比,在仅使用原始数据进行训练时。
75、ImageNet-D: Benchmarking Neural Network Robustness on Diffusion Synthetic Object

本文为视觉感知鲁棒性建立了严格基准。诸如ImageNet-C、ImageNet-9和Stylized ImageNet之类的合成图像提供了针对合成破坏、背景和纹理的特定类型评估,然而这些鲁棒性基准在指定的变化以及合成质量方面受到限制。这项工作引入生成模型作为用于合成检测深度模型鲁棒性的数据源。
借助扩散模型,生成具有比任何以前的工作更多样化的背景、纹理和材料的图像,将这个基准称为ImageNet-D。实验结果显示,ImageNet-D对于一系列视觉模型,从标准的ResNet视觉分类器到最新的基础模型如CLIP和MiniGPT-4,都导致了显著的精度降低,最高可降低60%。工作表明,扩散模型可以成为测试视觉模型的有效数据源。https://github.com/chenshuang-zhang/imagenet_d
二十四、医学图像76、MedM2G: Unifying Medical Multi-Modal Generation via Cross-Guided Diffusion with Visual Invariant

医学生成模型加快了医疗应用的快速增长。然而,最近研究集中在单独的医学生成模型上,针对不同的医学任务设计了不同的模型,而且对于医学多模态知识具有严重限制,限制了医学综合诊断。
本文提出MedM2G,一种医学多模态生成框架,其关键创新在于在统一模型中对医学多模态进行对齐、提取和生成。通过统一空间中的中央对齐方法有效对齐医学多模态,而不仅仅限于单个或两个医学模态。值得注意的是,框架通过维护每个成像模态的医学视觉不变性来提取有价值的临床知识,从而增强多模态生成的特定医学信息。通过将自适应的交叉引导参数条件到多流扩散框架中,模型促进了医学多模态之间的灵活交互用于生成。
MedM2G是第一个统一医学生成模型,可以完成文本到图像、图像到文本和医学模态(CT、MRI、X光)的统一生成,其可以在10个数据集上执行5个医学生成任务,并持续优于各种最先进的工作。
二十五、交通驾驶77、Controllable Safety-Critical Closed-loop Traffic Simulation via Guided Diffusion

评估自动驾驶规划算法的性能需要模拟长尾交通场景。传统的生成关键场景的方法往往在逼真性和可控性方面存在不足。此外,这些技术通常忽略了代理之间的动态交互。为减轻这些限制,提出一种根植于引导扩散模型的新型闭环模拟框架。
方法具有两个明显优势:1)生成与真实世界条件非常接近的逼真长尾场景,2)增强可控性,实现更全面和互动式的评估。通过增强道路进展、降低碰撞和离线率的导向目标实现了这一目标。通过在去噪过程中引入对抗性项来开发一种通过模拟关键安全场景的新方法,允许对车辆规划者进行挑战,并确保场景中的所有代理都表现出反应灵敏和逼真的行为。
基于NuScenes数据集进行了实证验证,证明了逼真性和可控性的提升。这些发现证实了引导扩散模型为安全关键、互动式交通仿真提供了强大而灵活的基础,扩展了其在自动驾驶领域的实用性。https://safe-sim.github.io/
78、Generalized Predictive Model for Autonomous Driving

本论文提出自动驾驶领域中第一个大规模视频预测模型。为消除高成本数据收集的限制,并增强模型泛化能力,从网络上获取大量数据,并与多样化和高质量的文本描述配对。
数据集积累了超过2000小时的驾驶视频,涵盖世界各地的各种天气条件和交通情景。继承了最近潜在扩散模型的优点,模型名为GenAD,通过新的时间推理模块处理驾驶场景中具有挑战性的动力学。展示了它可以以零样本的方式泛化到各种未见驾驶数据集,超过一般或仅针对驾驶的视频预测对手。此外,GenAD可以调整为一个动作条件的预测模型或动作规划器,在实际驾驶应用中具有巨大潜力。
二十六、语音相关79、FaceTalk: Audio-Driven Motion Diffusion for Neural Parametric Head Models
提出FaceTalk1,一种新生成方法,用于从输入的音频信号生成高保真度的三维运动序列的人头部。为捕捉人头部的表达、细节特征,包括头发、耳朵和细微的眼动,提出将语音信号与神经参数化头部模型的潜空间相结合,以创建高保真度、时间连贯的运动序列。
提出一种用于此任务的新型潜力扩散模型,在神经参数化头部模型的表情空间中操作,用于合成由音频驱动的真实头部序列。在没有具有相应NPHM表情到音频的数据集的情况下,优化这些对应关系,以产生一组与说话人不断优化的NPHM表情相适应的音视频记录数据集。本文声称这是首次提出一个用于实现体积性人头部真实、高质量运动合成的生成方法,表示在音频驱动三维动画领域的重要进展。
方法在生成能产生与NPHM形状空间相耦合的高保真度头部动画的可信运动序列方面表现出色。实验结果证实FaceTalk有效性,在感知用户评估中超过现有方法75%。https://shivangi-aneja.github.io/projects/facetalk/
80、ConvoFusion: Multi-Modal Conversational Diffusion for Co-Speech Gesture Synthesis

手势在人类交流中起着关键作用。最近方法可以生成与语音节奏对齐的动作,但在生成与话语语义对齐的手势方面仍存在困难。与自然对齐音频信号的节奏手势相比,语义上连贯的手势需要对语言和人体动作之间的复杂互动进行建模,并可以通过关注特定单词来进行控制。
提出CONVOFUSION,一种基于扩散的多模态手势合成方法,它不仅可以基于多模态语音输入生成手势,还可以在手势合成中提供可控性。方法提出两个指导目标,允许用户调节不同条件模态(如音频与文本)的影响,并选择在手势过程中强调特定单词。方法非常灵活,既可以训练用于生成独白手势,也可以生成对话手势。为进一步推进多方交互手势研究,发布了DND GROUP GESTURE数据集,其中包含6小时的手势数据,5个人之间的互动。将方法与几种近期工作进行比较,并展示方法在各种任务上的有效性。https://vcai.mpi-inf.mpg.de/projects/ConvoFusion/
81、Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners
视频和音频内容的创建是电影行业和专业用户的核心技术。最近,现有的基于扩散的方法单独处理视频和音频生成,这阻碍从学术界到工业界的技术转移。这项工作提出一个经过精心设计的基于优化的跨视听和联合视听生成框架。
提出利用已有的强大模型和一个共享的潜空间来搭建桥梁,而不是从头开始训练庞大的模型。具体来说,提出一个多模态潜空间对齐器,与预训练的ImageBind模型相似。潜空间对齐器与分类器引导具有相似的核心,在推理过程中引导扩散去噪过程。
通过精心设计的优化策略和损失函数,展示方法在联合视频音频生成、以视频为导向的音频生成和以音频为导向的视觉生成任务上的优越性能。https://yzxing87.github.io/Seeing-and-Hearing/
二十七、姿势估计82、Object Pose Estimation via the Aggregation of Diffusion Features

从图像中估计物体的姿态是三维场景理解的关键任务,近期方法在非常大的基准数据集上取得有希望结果。然而这些方法在处理未见过的物体时性能显著下降。这是由图像特征的有限通用性导致的。
为解决这个问题,对扩散模型的特征进行深入分析,如稳定扩散,这些特征在建模未见过的物体方面具有重要潜力。基于这个分析,引入这些扩散特征来进行物体姿态估计。为实现这一目标,提出三种不同的架构,可以有效地捕获和聚合不同粒度的扩散特征,极大地提高了物体姿态估计的通用性。
方法在LM、O-LM和T-LESS三个常用的基准数据集上的性能优于现有方法,特别是在未见过的物体上更是达到了更高的准确率:在未见过的LM数据集上,方法的准确率为98.2%,而之前最好的方法为93.5%;在未见过的O-LM数据集上,准确率为85.9%,而之前最好的方法为76.3%,展示方法强大通用性。https://github.com/Tianfu18/diff-feats-pose
二十八、图相关83、DiffAssemble: A Unified Graph-Diffusion Model for 2D and 3D Reassembly

Reassembly任务在许多领域中起着基础作用,并且存在多种方法来解决具体问题。在这种背景下,一个通用的统一模型可以有效解决所有这些问题,而不管输入数据类型是图像、三维等。
提出DiffAssemble,一种基于图神经网络(GNN)的架构,用扩散模型学习。方法将2D贴片或3D对象碎片的元素视为空间图的节点。训练过程中,将噪声引入元素的位置和旋转,并通过迭代去噪来重建一致的初始姿态。DiffAssemble在大多数2D和3D任务中取得最先进的结果,并且是第一个解决旋转和平移的2D拼图的基于学习的方法。此外,强调其在运行时间上的显著减少,比最快的基于优化的方法快11倍。https://github.com/IIT-PAVIS/DiffAssemble
二十九、动作检测或生成84、Action Detection via an Image Diffusion Process

动作检测,旨在定位视频中动作实例的起始点和终止点,并预测这些实例的类别。本文观察到动作检测任务的输出可以被表达为图像。因此,从一个新的角度出发,通过提出的Action Detection Image Diffusion(ADI-Diff)框架,通过三个图像生成过程生成起始点、终止点和动作类别的预测图像。
此外,由于本文所指图像与自然图像不同并且具有特殊属性,进一步探索离散动作检测扩散过程和行列Transformer设计,以更好处理它们的处理。ADI-Diff框架在两个广泛使用的数据集上取得了最先进的结果。
85、Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives

提出Lodge,根据给定音乐生成极长舞蹈序列的网络。将Lodge设计为一个两阶段的粗到精扩散架构,提出characteristic dance primitives,作为两个扩散模型之间的中间表示。
第一阶段是全局扩散,重点在于理解粗粒度的音乐-舞蹈关联性和生成特征舞蹈。第二阶段是局部扩散,通过舞蹈和编排规则的指导,同时生成详细的动作序列。此外,提出一个足部精炼模块,优化脚与地面之间的接触,增强了动作的物理逼真感。
方法平衡全局编舞模式和局部动作质量和表现力之间的关系。大量实验证实方法有效性。https://li-ronghui.github.io/lodge
86、OMG: Towards Open-vocabulary Motion Generation via Mixture of Controllers

近期在逼真的文本到运动生成方面取得进展。然而,现有方法在处理未见过的文本输入时往往失败或产生不合理的动作,限制了应用的范围。
本文提出一个新框架OMG,从零样本开放词汇的文本提示中生成引人注目的动作。关键思想是将预训练-微调范式精心调整为文本到运动生成。在预训练阶段,模型通过学习丰富的领域外内在运动特征来改善生成能力。为此,将一个大规模无条件扩散模型扩展到10亿个参数,以利用超过2000万个无标签的运动实例数据。在随后的微调阶段,引入运动控制网络(ControlNet),通过一个可训练的预训练模型和提出的新型混合控制器(MoC)块,将文本提示作为调节信息进行融合。MoC块通过交叉注意机制自适应地识别子运动的各个范围,并使用专门针对文本token的专家进行分段处理。这样的设计有效地将文本提示的CLIP令牌嵌入到各种范围的紧凑和富有表现力的运动特征中。
大量实验证明,OMG在零样本文本到运动生成上取得了显著改进,优于最先进方法。https://tr3e.github.io/omg-page/
三十、机器人规划/智能决策87、SkillDiffuser: Interpretable Hierarchical Planning via Skill Abstractions in Diffusion-Based Task Execution

扩散模型已展示在机器人轨迹规划方面的潜力。然而,从高级指令生成连贯的轨迹仍具有挑战性,特别是对于需要多个序列技能的长距离组合任务。
提出SkillDiffuser,一个端到端的分层规划框架,将可解释的技能学习与条件扩散规划相结合。在更高层面上,技能抽象模块从视觉观察和语言指令中学习离散、人类可理解的技能表示。然后,使用这些学习到的技能嵌入来调节扩散模型,以生成与技能相吻合的定制化潜在轨迹。这样可以生成符合可学习技能的多样化状态轨迹。通过将技能学习与条件轨迹生成结合起来,SkillDiffuser能够在不同任务中按照抽象指令生成连贯的行为。
在Meta-World和LOReL等多任务机器人操纵基准上的实验证明了SkillDiffuser在性能和人类可解释的技能表示方面的先进性。https://skilldiffuser.github.io/
三十一、视觉叙事-故事生成88、Intelligent Grimm - Open-ended Visual Storytelling via Latent Diffusion Models

生成模型最近在文本到图像生成方面展示了出色的能力,但仍然难以连贯地生成图像序列。这项工作关注一个新颖而具有挑战性的任务,即基于给定故事情节生成连贯的图像序列,被称为开放式视觉叙事。
做出了以下三个贡献:(i)为完成视觉叙事的任务,提出一种基于学习的自回归图像生成模型StoryGen,采用一个新的视觉-语言上下文模块,使得生成的当前帧能够以相关文本提示和之前的image-caption对作为条件;(ii)为解决视觉叙事数据的不足,通过在线视频和开源电子书收集成对的图像-文本序列,建立了一个包含多样化角色、故事情节和艺术风格的大规模数据集的处理流程,命名为StorySalon;(iii)定量实验和人类评估验证StoryGen的优越性,展示了StoryGen可以在没有任何优化的情况下推广到未见过的角色,并生成具有连贯内容和一致性的图像序列。https://haoningwu3639.github.io/StoryGen_Webpage/
三十二、因果归因89、 ProMark: Proactive Diffusion Watermarking for Causal Attribution

生成AI(GenAI)通过高级提示的能力,正在改变创意工作流程,合成和操作图像。然而,创意者们缺乏得到对他们在GenAI训练中使用的内容的认可或奖励的支持。为此,提出ProMark,一种因果归因技术,将生成图像归因于其训练数据中的概念,如对象、主题、模板、艺术家或风格。概念信息被主动嵌入到输入训练图像中,使用察觉不到的水印,扩散模型(无条件或条件)被训练以在生成的图像中保留相应的水印。
展示可以将多达2^16个独特的水印嵌入训练数据中,每个训练图像可以包含多个水印。ProMark可以保持图像质量,同时优于基于相关性的归因。最后,展示了一些定性的示例,提供了水印的存在传达了训练数据和合成图像之间的因果关系。
三十三、隐私保护-对抗估计90、Robust Imperceptible Perturbation against Diffusion Models

文本到图像扩散模型可从参考照片中生成个性化图像。然而这些工具如果落入不良之徒手中,可能制造误导性或有害内容,危及个人安全。为解决这个问题,现有防御方法对用户图像进行微不可察觉的扰动,使其对恶意使用者“无法学习”。这些方法两个局限性:一是由于手工设计的启发式方法导致sub-optimal结果;二是缺乏对简单数据转换(如高斯滤波)的鲁棒性。
为解决这些挑战,提出MetaCloak,用元学习框架,通过额外的转换采样过程来构建可转移和鲁棒的扰动。具体而言,用一组替代扩散模型来构建可转移和模型无关的扰动。此外,通过引入额外的转换过程,设计一个简单的去噪误差最大化损失,足以在个性化生成中引起转换鲁棒的语义失真和降级。
在VGGFace2和CelebA-HQ数据集上进行实验,表明MetaCloak优于现有方法。值得注意的是,MetaCloak能够成功欺骗Replicate等在线训练服务,以黑盒方式展示了MetaCloak在实际场景中的有效性。https://github.com/liuyixin-louis/MetaCloak
三十四、扩散模型改进-补充91、Condition-Aware Neural Network for Controlled Image Generation

提出Condition-Aware Neural Network (CAN),一种为图像生成模型添加控制的新方法。与以前的条件控制方法并行,CAN通过动态操纵神经网络的权重来控制图像生成过程。为此,引入一个条件感知的权重生成模块,根据输入条件生成用于卷积/线性层的条件权重。
在ImageNet上进行了类条件图像生成和在COCO上进行了文本到图像生成的测试。CAN一致地提供了对扩散transformer模型的显著改进,包括DiT和UViT。特别是,CAN结合EfficientViT(CaT)在ImageNet 512×512上实现了2.78 FID,超过了DiT-XL/2,同时每个采样步骤所需的MAC数量减少了52倍。https://github.com/mit-han-lab/efficientvit
三十五、交互式可控生成92、Drag Your Noise: Interactive Point-based Editing via Diffusion Semantic Propagation

基于点的交互式编辑,是一种重要工具,补充现有生成模型的可控性。DragDiffusion根据用户输入更新扩散潜在图,这导致原始内容的保存不精确和编辑失败。提出DragNoise,提供稳健且加速的编辑,无需追溯潜在图。
DragNoise核心在于将每个U-Net的预测噪声输出作为语义编辑器。这种方法基于两个关键观察:首先,U-Net的瓶颈特征本质上具有适于交互式编辑的语义丰富特征;其次,高级语义在去噪过程的早期阶段建立,随后在后续阶段显示出最小的变化。利用这些见解,DragNoise在单个去噪步骤中编辑扩散语义,并有效地传播这些变化,确保扩散编辑的稳定性和效率。
对比实验表明,与DragDiffusion相比,DragNoise实现了更好的控制和语义保留,并将优化时间缩短了50%以上。https://github.com/haofengl/DragNoise
三十六、图像恢复-补充93、Generating Content for HDR Deghosting from Frequency View

从多个低动态范围(High Dynamic Range,LDR)图像中恢复高动态范围(HDR)图像,在LDR图像出现饱和和显著运动时具有挑战性。最近,在HDR成像领域引入扩散模型(DM)。然而DM需要用大模型进行广泛迭代来估计整个图像,从而导致效率低下,阻碍实际应用。
为应对这一挑战,提出适用于HDR成像的低频感知扩散(LF-Diff)模型。LF-Diff的关键思想是在高度紧凑的潜在空间中实施DM,并将其整合到基于回归的模型中,以增强重建图像的细节。具体来说,鉴于低频信息与人的视觉感知密切相关,利用DM来创建紧凑的低频先验,用于重建过程。此外,为充分利用上述低频先验,通过基于回归的方式进行动态HDR重建网络(DHRNet),以获得最终的HDR图像。
在合成和真实世界基准数据集上进行的大量实验证明,LF-Diff相比几种最先进的方法表现出较好的性能,并且比之前基于DM的方法快10倍。
三十七、域适应/迁移学习94、Unknown Prompt, the only Lacuna: Unveiling CLIP’s Potential for Open Domain Generalization

深入研究开放领域泛化(Open Domain Generalization,ODG),其特点是训练标注好的源域和测试未标注的目标域之间的域和类别转换。现有ODG解决方案面临限制,因为传统CNN骨干的泛化受限,并且在没有先验知识的情况下,无法检测到目标开放样本的错误。为解决这些问题,提出ODG-CLIP,利用视觉-语言模型CLIP的语义能力。框架带来三个主要创新:
首先,与现有范例不同,将ODG概念化为一个多类分类挑战,包括已知类别和新类别。方法的核心在于设计了一个独特的用于检测未知类别样本的提示,并且为训练这个提示,采用一个易于获得的扩散模型,优雅地生成开放类别的代理图像proxy image。
其次,设计一种新的视觉风格中心的提示学习机制,以获得针对特定领域的分类权重,同时确保精度和简易性的平衡。
最后,将从提示空间衍生的类别区分知识注入图像中,以增强CLIP的视觉嵌入的准确性。引入了一种新目标,以确保这种注入的语义智能在不同领域间的连续性,特别是对于共享类别而言。
通过在涵盖封闭集和开放集DG上下文的多个数据集上进行严格测试,ODG-CLIP展示了明显的优势,性能提升在8%-16%之间,始终领先于同行方法。https://github.com/mainaksingha01/ODG-CLIP
三十八、手交互95、Text2HOI: Text-guided 3D Motion Generation for Hand-Object Interaction

本文介绍第一个文本导向的、生成3D环境中手-物体交互(hand-object interaction)序列的工作。主要挑战在于缺乏带标签的数据,现有实际数据集在交互类型和物体类别上都不具有普适性,限制从文本提示中对多样化3D手物体交互进行正确的物理推断(例如接触和语义)的建模。
为解决这个问题,将交互生成任务分解为两个子任务:手-物体接触生成、手-物体运动生成。对于接触生成,基于VAE的网络以文本和物体网格为输入,生成在交互过程中手部和物体表面之间接触的概率。该网络学习到了与对象类别无关的各种对象的本地几何结构变化,因此适用于一般对象。对于运动生成,基于Transformer的扩散模型利用这个3D接触图作为强先验,根据文本提示生成可能的手-物体运动,通过从扩充的带标签数据集中学习。
实验证明方法能够生成比其他基线方法更逼真和多样化的交互。还展示方法适用于未见过的对象。https://github.com/JunukCha/Text2HOI
96、InterHandGen: Two-Hand Interaction Generation via Cascaded Reverse Diffusion

提出InterHandGen,一个学习双手交互( two-hand interaction)生成式先验的新框架。从模型中进行采样可以得到在有或没有物体的情况下与之互动的双手形状。先验可以被融入到任何优化或学习方法中,以减少不适定问题中的模糊性。关键观察是,直接对多个实例的联合分布进行建模会导致学习复杂度高,因为它具有组合的特性。因此,提出将联合分布建模分解为分解单实例分布的无条件和条件建模。具体而言,引入一个扩散模型,该模型通过条件dropout学习单手的无条件和条件分布。对于采样,结合了抗穿透(anti-penetration)和无分类器指导,以实现合理的生成。
此外,建立严格的双手综合评估协议,其中方法在真实性和多样性方面明显优于基准生成模型。还证明了扩散先验可以提升从单目野外图像中的双手重建的性能,实现了最先进的准确性。https://jyunlee.github.io/projects/interhandgen/
三十九、伪装检测97、LAKE-RED: Camouflaged Images Generation by Latent Background Knowledge Retrieval-Augmented Diffusion

伪装视觉感知,是具有许多实际应用的重要视觉任务。由于收集和标注成本高昂,这个领域面临着一个主要瓶颈,即其数据集的物种类别仅限于少数几种物种。然而,现有伪装生成方法需要手动指定背景,因此无法以低成本方式扩展伪装样本的多样性。
本文提出一种用于伪装图像生成的基于潜在背景知识的扩散方法(LAKE-RED)。贡献主要包括:(1)首次提出一种不需要接收任何背景输入的伪装生成范式。(2)LAKE-RED是第一种具有可解释性的知识检索增强方法,提出一种将知识检索和推理增强明确分开的思想,以减轻任务特定挑战。此外,方法不局限于特定的前景目标或背景,为将伪装视觉感知扩展到更多不同的领域提供了潜力。(3)实验结果表明,方法优于现有方法,生成更逼真的伪装图像。https://github.com/PanchengZhao/LAKE-RED
四十、多任务学习98、DiffusionMTL: Learning Multi-Task Denoising Diffusion Model from Partially Annotated Data

最近,对从部分标注数据中学习多个密集场景理解任务( dense scene understanding task)的实际问题引起了越来越多的兴趣,其中每个训练样本只为一部分任务进行了标注。训练中任务标签的缺失导致预测质量低下且噪声较大。
为解决这个问题,将部分标注的多任务密集预测重新定义为像素级去噪问题,并提出一种新的多任务去噪扩散框架,称为DiffusionMTL。设计一种联合扩散和去噪模式,以对任务预测或特征图中的潜在噪声分布进行建模,并为不同任务生成修正输出。为在去噪中利用多任务一致性,进一步引入多任务条件策略,它可以隐式地利用任务的互补性来帮助学习未标注的任务,从而提高了不同任务的去噪性能。
定量和定性实验证明,所提出的多任务去噪扩散模型可以显著提高多任务预测图的性能,并在两种不同的部分标注评估设置下优于最先进的方法。https://prismformore.github.io/diffusionmtl/
四十一、轨迹预测99、SingularTrajectory: Universal Trajectory Predictor Using Diffusion Model

有五种类型的轨迹预测(trajectory prediction)任务:确定性、随机性、域适应、瞬时观察和少样本。这些关联任务由各种因素定义,如输入路径的长度、数据拆分和预处理方法。有趣的是,尽管它们通常将观察的连续坐标作为输入,并以相同坐标推断未来路径,但为每个任务设计专门的架构仍是必要的。对于其他任务,泛化问题可能导致次优性能。
本文提出SingularTrajectory,一种基于扩散的通用轨迹预测框架,以减少这五个任务之间的性能差距。SingularTrajectory的核心是统一关联任务中各种人体动力学表示形式。为此,首先建立一个Singular空间,将每个任务中的所有类型的运动模式投影到一个嵌入空间中。然后,引入一个适应性锚点来工作在Singular空间中。与有时会产生不可接受路径的传统固定锚点方法不同,适应性锚点可以根据一个可穿越性图将不正确放置的正确锚点纳入其中。最后,采用基于扩散的预测器,通过级联去噪过程进一步增强原型路径。
统一框架确保在各种基准设置(如输入模态和轨迹长度)下的泛化效果。在五个公共基准测试上的广泛实验表明,SingularTrajectory在估计人体运动的一般动态方面明显优于现有模型,凸显其在估计人体运动的一般动态方面的有效性。https://github.com/inhwanbae/SingularTrajectory
四十二、场景生成100、SemCity: Semantic Scene Generation with Triplane Diffusion

提出“SemCity”,一个用于语义场景在真实室外环境中生成的三维扩散模型。大多数三维扩散模型专注于生成单个对象、合成室内场景或合成室外场景,而生成真实室外场景的研究很少。本文致力于通过学习真实室外数据集上的扩散模型来生成真实室外场景。与合成数据不同,真实室外数据集通常由于传感器限制而包含更多的空白空间,这在学习真实室外分布时会带来挑战。
为解决这个问题,利用三平面表示(triplane representation)作为场景分布的代理形式,由扩散模型进行学习。实验结果,三平面扩散模型与现有工作相比在真实室外数据集SemanticKITTI上显示出有意义的生成结果。还可以轻松地添加、删除或修改场景中的对象,同时也能够实现场景扩展到城市规模。最后,将方法评估在语义场景完成细化上,其中扩散模型通过学习场景分布来提高语义场景完成网络的预测。https://github.com/zoomin-lee/SemCity
四十三、3D相关/流估计101、DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Iterative Diffusion-Based Refinement

场景流估计,是计算机视觉领域的一项基础任务,旨在预测动态场景的每个点的三维位移。然而,前期的工作通常由于局部限制的搜索范围导致相关性不可靠,并且由于粗到细结构而产生累积误差。
为缓解这些问题,提出一种新的基于扩散概率模型的场景流估计网络(DifFlow3D)来推断不确定性。设计迭代扩散的细化过程,以增强相关性的鲁棒性和对挑战性情况(如动态场景、噪声输入、重复图案等)的韧性。为抑制生成多样性,在扩散模型中使用了三个与流相关的关键特征作为条件。
此外,还在扩散中开发了一个不确定性估计模块,用于评估估计的场景流的可靠性。DifFlow3D实现了最先进的性能,在FlyingThings3D和KITTI 2015数据集上分别减少了6.7%和19.1%的EPE3D。值得注意的是,方法在KITTI数据集上实现了空前的毫米级准确性(EPE3D为0.0089m)。此外,基于扩散的细化范式可以轻松地作为即插即用模块集成到现有的场景流网络中,提高它们的估计准确性。
#用扩散模型diffusion生成训练数据
1、Data Augmentation via Latent Diffusion for Saliency Prediction

显著性预测模型受限于有限多样性和标注数据的数量。诸如旋转和裁剪等标准数据增强技术改变了场景构成。提出一种新的用于深度显著性预测的数据增强方法,编辑自然图像同时保持真实世界场景的复杂性和变化性。由于显著性取决于高级和低级特征,方法结合学习两者,包括颜色、对比度、亮度和类别等光度和语义属性。为此,引入一种显著性引导的交叉注意力机制,用于在光度特性上进行有针对性的编辑,从而增强特定图像区域内的显著性。
实验结果表明,数据增广方法始终提高各种显著性模型的性能。此外,利用增强特性进行显著性预测在公开可用的显著性基准测试中表现出更出色的性能。预测结果与经用户研究验证的编辑图像中的人类视觉注意模式紧密吻合。https://github.com/IVRL/Augsal
2、MacDiff: Unified Skeleton Modeling with Masked Conditional Diffusion

自监督学习已被证明对基于骨架的人体动作理解非常有效。然而,先前研究要么依赖于对比学习,存在错误负问题,要么基于重建,学习了太多不必要的低层线索,导致下游任务的表示受限。
最近,在生成学习方面取得巨大进展,这自然是一个具有挑战性但有意义的预训练任务,以建模一般性的潜在数据分布。然而,生成模型对具有空间稀疏性和时间冗余的骨架的表示学习能力尚未得到充分探索。因此,提出蒙蔽条件扩散(MacDiff)作为人体骨架建模的统一框架。首次利用扩散模型作为有效的骨架表示学习器。
具体而言,训练一个扩散解码器,其以语义编码器提取的表示为条件。对编码器输入进行随机屏蔽,引入信息瓶颈并消除骨架的冗余。此外在理论上证明,生成目标涉及对比学习目标,对齐了屏蔽和嘈杂视图。同时,它还强制表示来补充嘈杂视图,从而提高了泛化性能。MacDiff在表示学习基准上取得了最先进的性能,同时保持了生成任务的竞争力。此外用扩散模型进行数据增广,在数据稀缺的情况下显着增强微调性能。https://lehongwu.github.io/ECCV24MacDiff/
3、DataDream: Few-shot Guided Dataset Generation
文生图扩散模型在图像合成中取得最先进结果,但尚未证明在下游应用的有效性。先前工作提出通过提供有限的真实数据访问来生成图像分类器训练数据。这些方法难以生成符合分布的图像或描绘细粒度特征,阻碍在合成数据集上训练的分类模型泛化。
提出DataDream框架,在少量目标类别的少量真实示例引导下合成更忠实代表实际数据分布的分类数据集。在用适应后的模型生成训练数据之前,DataDream在少量真实图像上微调图像生成模型的LoRA权重。然后,通过用合成数据对CLIP的LoRA权重进行微调,以改善在各种数据集上相比先前方法的下游图像分类性能。
实验证明DataDream有效性,在10个数据集中的7个数据集上,用少量数据取得最先进的分类准确性,并在其他3个数据集上具有竞争力。此外,还提供有关各种因素的影响的见解,例如实际拍摄和生成图像的数量以及对模型性能的微调计算的影响。https://github.com/ExplainableML/DataDream

4、ProCreate, Don’t Reproduce! Propulsive Energy Diffusion for Creative Generation
提出ProCreate,一种简单易实现的方法,用于改善扩散式图像生成模型的样本多样性和创造力,并防止训练数据的复制式生成。ProCreate在一组参考图像上操作,并在生成过程中积极推动生成的图像嵌入远离参考嵌入。提出FSCG-8(Few-Shot Creative Generation 8),一个少样本创意生成数据集,涵盖了八个不同类别,包括不同概念、风格和设置,其中ProCreate实现了最高的样本多样性和保真度。此外,展示了ProCreate在使用训练文本提示进行大规模评估时有效地防止复制训练数据。https://procreate-diffusion.github.io/

5、Self-Guided Generation of Minority Samples Using Diffusion Models
提出一种用于生成那些在数据流形低密度区域的少样本的新方法。框架建立在扩散模型上,采样器的关键特征在于其self-contained性质,即仅用预训练模型即可实现。这使得采样器与需要昂贵的额外组件(如外部分类器)的现有技术有所区别。
在基准真实数据集上的实验表明,方法可以显著提高创造出现实中低可能性少数实例的能力,而无需依赖昂贵的额外元素。https://github.com/soobin-um/sg-minority

6、TP2O: Creative Text Pair-to-Object Generation using Balance Swap-Sampling
从两个看似不相关的对象文本中生成创造性的组合对象,是文本生成图像中的一项具有挑战性的任务,往往受到对模拟现有数据分布的关注的阻碍。本文开发了一种简单高效的方法,称为平衡交换采样。
首先,提出一个交换机制,通过扩散模型随机交换两个文本嵌入的内在元素,生成一个新的组合对象图像集。其次,引入一个平衡交换区域,通过平衡新生成的图像集中的CLIP距离来高效地从中取样一个小子集,增加接受高质量组合的可能性。最后,采用分割方法来比较分割组件之间的CLIP距离,最终选择来自取样子集中最有前途的对象。
实验表明,方法胜过最近的SOTA T2I方法。结果甚至可以与青蛙-西兰花等人类艺术家的作品匹敌。https://njustzandyz.github.io/tp2o/

#用diffusion扩散模型做3D视觉
1、3DEgo: 3D Editing on the Go!

提出3DEgo,解决一个新问题,即通过文本提示指导从单目视频直接合成逼真的3D场景。传统方法通过一个三阶段过程构建一个文本条件的3D场景,涉及使用诸如COLMAP的Structure-from-Motion(SfM)库进行姿态估计,使用未编辑的图像初始化3D模型,并通过迭代地使用编辑后的图像更新数据集,以实现文本保真度的3D场景。
通过克服对COLMAP的依赖和消除模型初始化的成本,将传统的多阶段3D编辑过程简化为单阶段工作流程。采用扩散模型在创建3D场景之前编辑视频帧,包括设计的噪声融合模块,以增强多视图编辑的一致性,这一步骤不需要额外训练或微调T2I扩散模型。3DEgo利用3D高斯扩散来从多视角一致的编辑帧创建3D场景,利用固有的时间连续性和显式点云数据。
3DEgo在各种视频来源上的编辑精度、速度和适应性,通过对六个数据集进行全面评估来验证,包括自建的GS25数据集。https://3dego.github.io/
2、COIN: Control-Inpainting Diffusion Prior for Human and Camera Motion Estimation

从移动相机中估计全局人类运动,由于人类运动和相机运动的耦合而具有挑战性。为减轻这种模糊,现有方法利用学习的人类运动先验,然而这经常导致运动过度平滑和不对齐的2D投影。为解决这一问题,提出COIN,一种控制-修补运动扩散先验,使得可以对人类和相机运动进行细粒度控制以解耦。
尽管预训练的运动扩散模型编码了丰富的运动先验,但难以利用此类知识来指导从RGB视频中对全局运动的估计。COIN引入一种新的控制-修补评分蒸馏抽样方法,以确保扩散先验中的控制-修补分数对齐、一致和高质量,同时在一个联合优化框架中。此外引入一个新的人类-场景关系损失,通过在人类、相机和场景之间强制一致性,减轻尺度模糊。
针对三个具有挑战性的基准测试,实验证明COIN有效性,在全局人类运动估计和相机运动估计方面优于最先进方法。https://nvlabs.github.io/COIN/
3、Diff3DETR: Agent-based Diffusion Model for Semi-supervised 3D Object Detection

三维物体检测对于理解三维场景至关重要。通常需要大量标注的训练数据,然而为点云获取逐点标注是耗时且劳动密集的。最近半监督方法通过用教师-学生框架为未标注的点云生成伪标签来缓解这一问题。然而,这些伪标签经常缺乏足够的多样性和较低质量。
为了克服这些障碍,引入一种基于代理的半监督三维物体检测模型(Diff3DETR)。具体来说,设计一个基于代理对象的查询生成器,用于生成能够有效适应动态场景的对象查询,同时在采样位置与内容嵌入之间取得平衡。此外,一个基于框的去噪模块利用了DDIM去噪过程和transformer解码器中的远程注意力,逐步精化边界框。
在ScanNet和SUN RGB-D数据集上进行的广泛实验表明,Diff3DETR优于现有半监督三维物体检测方法。
4、DiffSurf: A Transformer-based Diffusion Model for Generating and Reconstructing 3D Surfaces in Pose

本文提出DiffSurf,基于transformer的去噪扩散模型,用于生成和重建三维表面。具体来说,设计了一个扩散transformer架构,用于从嘈杂的三维表面顶点和法线预测噪声。借助这种架构,DiffSurf能够生成各种姿势和形状的三维表面,例如人体、手部、动物和人造物体。
此外,DiffSurf具有通用性,可以解决包括变形、体形变化和将三维人体网格拟合到二维关键点在内的各种三维下游任务。在三维人体模型基准上的实验结果表明,DiffSurf可以生成具有更大多样性和更高质量的形状,优于先前的生成模型。此外,当应用于单图像三维人体网格恢复任务时,DiffSurf以接近实时的速率达到可与先前技术相媲美的精度。https://github.com/yusukey03012/DiffSurf
5、CloudFixer: Test-Time Adaptation for 3D Point Clouds via Diffusion-Guided Geometric Transformation

由于各种障碍(如遮挡、有限分辨率和尺度变化)导致的实际传感器捕获的3D点云经常包含嘈杂点。虽然在 2D 领域中的测试时适应(TTA)策略已经在该问题上显示出有希望的结果,但是将这些方法应用于 3D 点云的情况仍未得到充分探讨。
在 TTA 方法中,一种输入适应方法直接将测试实例通过预训练扩散模型转换为源领域,在 2D 领域已被提出。尽管在实际情况下其对 TTA 的性能表现鲁棒,但是简单地将其应用到 3D 领域可能并不是最佳选择,因为忽略了点云的固有特性,以及其高昂的计算成本。
受到这些限制的启发,提出CloudFixer,一种专为 3D 点云量身定制的测试时输入适应方法,采用预训练扩散模型。具体来说,CloudFixer 通过优化几何转换参数,利用点云的几何属性精心设计的目标来提高计算效率。此外,通过避免通过扩散模型进行反向传播和耗时的生成过程,显著提高计算效率。此外,提出了一个在线模型适应策略,通过将原始模型预测与经过调整的输入的预测进行对齐。实验展示 CloudFixer 在各种 TTA 基线上的优越性。https://github.com/shimazing/CloudFixer
6、DreamDissector: Learning Disentangled Text-to-3D Generation from 2D Diffusion Priors

最近,文本到三维生成取得显著进展。为增强其在现实应用中的实用性,关键是生成具有相互作用的多个独立对象,类似于2D图像编辑中的图层合成。然而,现有的文本到三维方法在这一任务上存在困难,因为它们旨在生成非独立对象或缺乏空间合理互动的独立对象。
为解决这个问题,提出DreamDissector,一种能够生成具有交互作用的多个独立对象的文本到三维方法。DreamDissector接受一个多对象文本到三维NeRF作为输入,并生成独立的有纹理的网格。为实现这一点,引入神经类别场(NeCF)来解耦输入NeRF。此外,提出Category Score Distillation Sampling (CSDS),通过深度概念挖掘(DCM)模块实现,以解决扩散模型中的概念差距问题。通过利用NeCF和CSDS,可有效从原始场景中导出子NeRF。进一步细化增强几何和纹理。
7、DreamMesh: Jointly Manipulating and Texturing Triangle Meshes for Text-to-3D Generation

用强大的2D扩散模型学习Radiance Fields(NeRF)在文本到3D生成方面变得流行起来。然而,NeRF的隐式3D表示缺乏对网格和表面上的纹理的显式建模,这种表面未定义的方式可能会导致问题,例如具有模糊纹理细节或交叉视图不一致的嘈杂表面。
为缓解这一问题,提出DreamMesh,一种新的文本到3D架构,侧重于定义良好的表面来生成高保真的显式3D模型。在技术上,DreamMesh利用独特的由粗到精的方案。实验证明,DreamMesh在忠实生成具有更丰富文本细节和增强几何的3D内容方面明显优于当前文本到3D方法。https://dreammesh.github.io/
8、JointDreamer: Ensuring Geometry Consistency and Text Congruence in Text-to-3D Generation via Joint Score Distillation

经过良好训练的2D扩散模型在文本到三维生成中显示出巨大潜力。然而,这种范式将视角不可知的2D图像分布蒸馏为每个视角独立的3D表示的渲染分布,忽略了视角之间的一致性,导致生成中的3D不一致性。
本文提出Joint Score Distillation (JSD),一个确保一致3D生成的新范式。具体而言,建立了联合图像分布,引入能量函数来捕捉扩散模型中去噪图像之间的一致性。然后,在渲染的多个视角上推导联合分数蒸馏,而不是SDS中的单个视角。此外,实例化了三个通用的视角感知模型作为能量函数,展示了与JSD的兼容性。从经验上看,JSD明显缓解了SDS中的3D不一致性问题,同时保持文本的一致性。
JointDreamer在文本到三维生成中建立了一个新的基准,具有88.5%的CLIP R-Precision和27.7%的CLIP分数。https://jointdreamer.github.io/
9、Length-Aware Motion Synthesis via Latent Diffusion
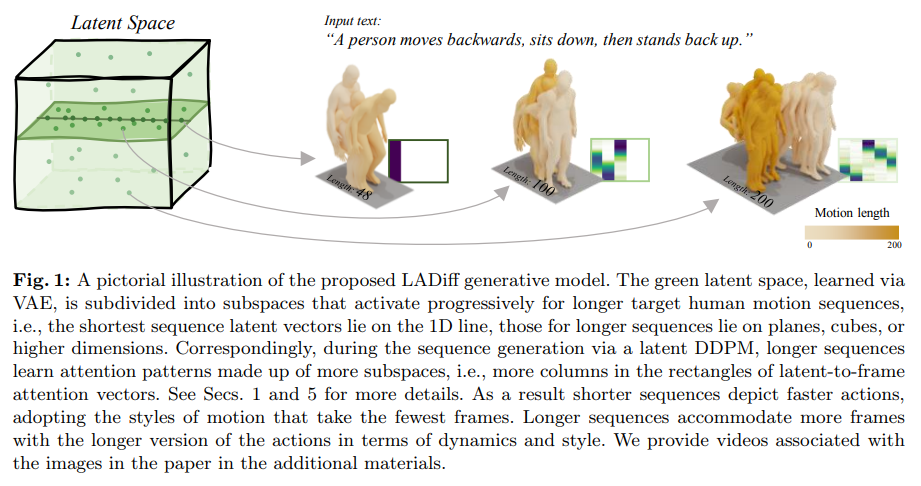
合成人类动作的目标持续时间是一个关键属性,需要对动作动态和风格进行建模控制。加快动作表现并不仅仅是加速它。然而,针对人类行为合成的现有技术在目标序列长度控制上存在局限。
从文本描述生成长度感知的3D人体运动序列的问题,提出一个新的模型来生成可变目标长度的动作,将其称为“Length-Aware Latent Diffusion”(LADiff)。LADiff包括两个新模块:1)一个长度感知变分自编码器,用于学习具有长度相关潜在码的运动表示;2)一个符合长度的潜在扩散模型,用于生成随着所需目标序列长度增加而增加细节丰富度的动作。在HumanML3D和KIT-ML两个建立的动作合成基准上,LADiff在大多数现有动作合成指标上显著优于现有技术。https://github.com/AlessioSam/LADiff
10、Local Action-Guided Motion Diffusion Model for Text-to-Motion Generation

文本到动作生成,不仅需要将局部动作与语言进行基础接触,还需要无缝地融合这些个别动作来综合多样且逼真的整体动作。然而,现有的动作生成方法主要集中于直接合成全局动作,却忽视了生成和控制局部动作的重要性。
本文提出局部动作引导的动作扩散模型,通过利用局部动作作为细粒度控制信号促进全局动作生成。具体而言,提供一种自动化的参考局部动作采样方法,并利用图注意力网络评估每个局部动作在整体动作合成中的引导权重。在合成全局动作的扩散过程中,计算局部动作梯度以提供条件指导。这种由局部到全局的范式减少了直接全局动作生成所带来的复杂性,并通过采样多样动作作为条件促进动作多样性。
在两个人类动作数据集(HumanML3D 和 KIT)上进行的大量实验表明了我们方法的有效性。此外,方法提供了在无缝组合各种局部动作和连续引导权重调整方面的灵活性,适应了各种用户偏好,可能对社区具有潜在的重要意义。https://jpthu17.github.io/GuidedMotion-project/
11、MonoWAD: Weather-Adaptive Diffusion Model for Robust Monocular 3D Object Detection

单目三维物体检测,是自动驾驶中一项重要而具有挑战性的任务。现有方法主要集中在理想天气条件下进行3D检测,这些情景具有清晰和最佳的可见性。然而,自动驾驶的挑战在于需要处理天气条件的变化,如有雾的天气,而不仅仅是晴天。
引入MonoWAD,一个具有天气自适应扩散模型的新型抗天气单目3D物体检测器。它包含两个组件:(1)天气codebook用于记忆晴天的知识并为任意输入生成一个天气参考特征,以及(2)天气自适应扩散模型,通过整合一个天气参考特征来增强输入特征的表示。这在指示根据天气条件需要对输入特征进行多少改进方面起着注意力作用。为了实现这一目标,引入了天气自适应增强损失,以增强特征在晴天和有雾天气条件下的表示。在各种天气条件下的大量实验表明,MonoWAD实现了抗天气的单目3D物体检测。https://github.com/VisualAIKHU/MonoWAD
12、NL2Contact: Natural Language Guided 3D Hand-Object Contact Modeling withDiffusion Model

对于调整不准确的手部姿势并生成三维手-物体重建中的新型人类抓取,建模手部与物体之间的物理接触是标准的。然而,现有方法依赖于无法指定或控制的几何约束。本文引入了一种新的可控3D手-物体接触建模任务与自然语言描述。挑战包括:i)从语言到接触的跨模态建模复杂性,以及ii)缺乏用于接触模式的描述性文本。
为解决这些问题,提出NL2Contact,一个通过利用分层扩散模型生成可控接触的模型。给定手部和接触的语言描述,NL2Contact生成逼真和忠实的3D手-物体接触。为训练模型,构建 ContactDescribe,这是第一个带有以手为中心的接触描述的数据集。它包含由基于精心设计的提示(如抓取动作、抓取类型、接触位置、自由手指状态)的大型语言模型生成的多层次且多样化的描述。展示了模型在抓取姿势优化和新型人类抓取生成方面的应用,这两者都基于文本接触描述。
13、NVS-Adapter: Plug-and-Play Novel View Synthesis from a Single Image

最近关于单一图像的新视角合成(NVS)已经通过利用预训练文本到图像(T2I)模型的生成能力取得令人印象深刻的结果。然而,先前NVS方法需要额外优化才能使用其他即插即用的图像生成模块,如ControlNet和LoRA,因为它们微调了T2I参数。
本研究提出一个高效的即插即用适配模块 NVS-Adapter,它与现有的即插即用模块兼容而无需进行大量微调。引入目标视图和参考视图对齐,以提高多视角预测的几何一致性。实验结果表明NVS-Adapter与现有即插即用模块兼容。此外,尽管没有对预训练的T2I模型的数十亿参数进行微调,NVS-Adapter在NVS基准测试中表现优越。https://postech-cvlab.github.io/nvsadapter/
14、Open-Vocabulary 3D Semantic Segmentation with Text-to-Image Diffusion Models

这篇论文研究预先在大规模图像-文本对上进行预训练的扩散模型在开放词汇三维语义理解中的使用。提出一种新方法,即 Diff2Scene,利用文本-图像生成模型的冻结表示以及敏锐感知和几何感知蒙版,用于开放词汇三维语义细分和视觉定位任务。
Diff2Scene 摆脱了任何标注的3D数据,并有效识别了三维场景中的对象、外观、材料、位置及其组合。展示它优于竞争基线,并且较现有的方法取得了显著提升。特别是,在 ScanNet200 数据集上,Diff2Scene 将现有方法的准确率提高了12%。
15、Realistic Human Motion Generation with Cross-Diffusion Models

这项工作介绍一种基于文本描述生成高质量人类动作的 Cross Human Motion Diffusion Model(CrossDiff3)。方法在扩散模型的训练中使用共享transformer整合了3D和2D信息,将运动噪音统一到一个特征空间中。这使得 CrossDiff 能够将特征解码为3D和2D运动表示,不管它们的原始维度如何。
CrossDiff 的主要优势在于其交叉扩散机制,允许模型在训练期间将2D或3D噪音反转为干净的运动。这种能力利用了两种运动表示中的互补信息,捕捉了仅仅依赖3D信息的模型常常错过的复杂人体运动细节。因此,CrossDiff 有效地结合了这两种表示的优势,生成更加逼真的运动序列。
在实验中,模型展示了竞争性的最先进性能,适用于文本到动作基准。此外,方法始终提供增强的运动生成质量,捕捉复杂全身运动细节。方法还适应使用在野外收集的2D运动数据而不需3D运动地面真相进行训练来生成3D运动,突显了其更广泛应用的潜力以及对现有数据资源的高效利用。https://wonderno.github.io/CrossDiff-webpage/
16、SMooDi: Stylized Motion Diffusion Model

引入一种新风格化运动扩散模型,名为 SMooDi,用于根据内容文字和风格运动序列生成风格化运动。与现有方法不同,现有方法要么生成多样内容的运动,要么从一个序列转移风格到另一个序列,SMooDi 可以快速地生成跨多样内容和不同风格的运动。
为此,为风格定制了一个预训练文本到动作模型。具体而言,提出风格引导来确保生成的动作与参考风格密切匹配,同时还提出了一个轻量级风格适配器,将运动引导到所需的风格,同时确保逼真性。在各种应用程序中的实验表明,框架在风格化运动生成方面优于现有方法。https://neu-vi.github.io/SMooDi/
17、TexGen: Text-Guided 3D Texture Generation with Multi-view Sampling and Resampling

给定3D mesh,如何生成对应文本描述的3D纹理外观?本文提出TexGen,一个全新的多视图抽样和重新抽样框架,用于纹理生成,利用预训练的文本到图像扩散模型。为解决这些问题,提出一种关注引导的多视图抽样策略,以在视图之间广播外观信息。为保留纹理细节,开发一种噪声重新抽样技术,用于估算噪声,生成用于后续去噪步骤的输入,由文本提示和当前纹理地图指导。
通过大量的定性和定量评估,展示了方法为具有高度视图一致性和丰富外观细节的各种3D对象产生了更好的纹理质量,优于当前最先进的方法。此外,提出的纹理生成技术还可以应用于保留原始身份的纹理编辑。https://dong-huo.github.io/TexGen/
18、Connecting Consistency Distillation to Score Distillation for Text-to-3D Generation

尽管最近文本到3D生成的质量已有提高,细节级别问题和低保真度仍然存在,需进一步改进。为理解这些问题本质,通过将一致性蒸馏理论连接到评分蒸馏,对当前的评分蒸馏方法进行了彻底分析。基于通过分析获得的见解,提出一个优化框架,引导一致性抽样(GCS),并结合3DGS以减轻这些问题。
此外,观察到生成的3D资产渲染视图中持续存在的过度饱和现象。通过实验,发现这是由于在优化过程中3DGS中不必要的累积亮度引起的。为减轻这一问题,在3DGS渲染中引入了一种亮度均衡生成(BEG)方案。实验结果表明,方法生成了更多细节和更高保真度的3D资产,优于目前最先进的方法。https://github.com/LMozart/ECCV2024-GCS-BEG
19、TPA3D: Triplane Attention for Fast Text-to-3D Generation

由于缺乏大规模文本-3D对应数据,最近的文本到3D生成方法主要依赖于利用2D扩散模型合成3D数据。由于基于扩散的方法通常需要大量的优化时间进行训练和推断,因此仍希望使用基于GAN的模型进行快速3D生成。
这项工作提出Triplane Attention用于文本引导的3D生成(TPA3D),一个端到端可训练的基于GAN的深度学习模型,用于快速文本到3D生成。通过训练观察的仅为3D形状数据及其渲染的2D图像,TPA3D旨在检索详细的视觉描述,以合成相应的3D网格数据。这是通过在提取的句子和词级文本特征上提出的注意机制实现的。
实验展示了TPA3D生成与精细描述对齐的高质量3D纹理形状,同时还能观察到令人印象深刻的计算效率。
20、Transferable 3D Adversarial Shape Completion using Diffusion Models

最近的研究将几何特征和transformers纳入3D点云特征学习中,显著提高3D深度学习模型的性能。然而,它们对抗性攻击的韧性尚未得到彻底探索。现有的攻击方法主要集中在白盒场景,很难迁移到最近提出的3D深度学习模型。更糟糕的是,这些攻击引入了对3D坐标的扰动,生成不太现实的对抗性示例,并导致对3D对抗性防御的性能不佳。
为增强攻击的可转移性,深入研究3D点云的特征并利用模型的不确定性来更好地推断通过对点云进行随机降采样实现模型分类的不确定性。采用集成对抗引导的方法,以改善跨不同网络架构的可转移性。为了保持生成质量,仅针对点云的关键点采用对抗引导,通过计算显著性分数。
大量实验证明,提出的攻击方法在黑盒模型和防御方面优于最先进的对抗攻击方法。黑盒攻击为评估各种3D点云分类模型的韧性建立了一个新的基准。
21、VividDreamer: Invariant Score Distillation For Hyper-Realistic Text-to-3D Generation

本文介绍不变分数蒸馏(ISD),一种用于高保真度文本到3D生成的新方法。ISD旨在解决得分蒸馏抽样(SDS)中的过度饱和和过度平滑问题。通过将SDS拆分为两个组件的加权和以此来解决这些问题。实验发现,过度饱和源于大的无分类器引导比例,过度平滑来自重构项。
为克服这些问题,ISD利用从DDIM抽样中派生的不变分数项来替代SDS中的重构项。这个操作允许利用一个中等的无分类器引导比例,并减轻与重构相关的错误,从而防止结果的过度平滑和过度饱和。
大量实验证明,方法极大地增强了SDS,并通过单阶优化产生了现实的3D物体。https://github.com/SupstarZh/VividDreamer
#Representation Alignment
训练扩散模型比你想象的更简单!谢赛宁老师:Representation matters!
表征的对齐真的很重要!之前我们训练扩散模型的路可能是错误的。
纽约大学谢赛宁老师团队最近的工作提出:
当我们训练扩散模型时,把扩散模型与自监督方法的表征"对齐" (Representation Alignment) ,使得扩散模型的训练比你想象的还简单。因为最近有些研究表明:扩散模型中包含的 (生成式) 去噪过程,可以诱导得到一些 (判别式) 的特征。虽然这些判别式的表征的质量落后于自监督学习 (DINO v2) 得到的表征。
图1:在生成模型和表征学习之间,还有很多东西有待发掘 (图源谢赛宁老师 Twitter)
作者认为:扩散模型训练的一个瓶颈是学习这些表征的过程没那么有效,并坦率直言,表征的对齐真的很重要!之前我们训练扩散模型的路可能是错误的。并进一步指明一条训练扩散模型更容易的道路:集成一些高质量的外部视觉表征,而不是仅仅靠扩散模型本身自己学习这些表征。
图2:表征对齐很重要 (图源谢赛宁老师 Twitter)
本文通过提出一个叫表征对齐的方法研究这个问题,将 "去噪网络中噪声输入隐藏状态的投影" 与 "来自外部预训练的视觉编码器获得的干净图像表征" 对齐。
更进一步,他也给出了一些核心观察:1) 扩散模型能够给出一些合理的表征,越好的扩散模型的 Representation 越强。2) 即便如此,这些 Representation 与自监督方法得到的视觉架构 (如 DINOv2, MAE) 的 Representation 相比还有所不足。3) 当把扩散模型和 DINOv2 的表征对齐时,扩散模型在训练时可以稳步提升。
图3:一些观察 (图源谢赛宁老师 Twitter)
这个方法带来的效益是:训练主流扩散模型 DiTs 和 SiTs 变得明显容易,在训练效率和生成质量方面都有显著的改进:ImageNet 256×256 实现了最先进的 FID=1.42。将 SiT 训练速度提高了 17.5 倍以上,本方法 400K 步训练的模型与常规条件下训练了 7M 步的 SiT-XL 模型的性能匹配。此外,这种方法还具有良好的扩展性,即对于更大的模型,改进幅度更大。
下面是对本文的详细介绍。
1 Representation Alignment:扩散模型与自监督方法的表征 "对齐"
论文名称:Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
论文地址:http://arxiv.org/pdf/2410.06940
代码链接:http://github.com/sihyun-yu/REPA
项目主页:http://sihyun.me/REPA/
1.1 REPA 研究背景
基于去噪的生成模型,例如 Diffusion Model[1][2]和 Flow-based Model[3][4]已成为生成高维视觉数据的可扩展方法。这些模型在文生图 (SDXL, SD3) 等有挑战性的任务中取得了不错的结果。
最近的工作探索了使用扩散模型做表征学习,比如[5][6]和恺明的 l-DAE[7],并表明扩散模型的 hidden state 可以学习到判别式的表征,而且更好的扩散模型往往可以学习到更好的表征。
1.2 DDPM 和 Flow-based Model 简介Diffusion Model
Diffusion Model 通过学习从高斯分布 到 的逐渐去噪过程来建模目标分布 。在形式上, 扩散模型的正向过程 : 从 开始, 对于 , 逐渐添加高斯噪声。扩散模型学习反向过程 。
对于给定的 可以被建模为 。其中 是预定义超参数。DDPM 表明,如果反向过程 ( , for 表示为:

在 DDPM 中,。
即:

其中,均值满足:

其中,可以使用由简单去噪自编码器目标进行训练:

IDDPM[8]进一步展示出如果模型通过下面的目标函数同步学习,则可以进一步提高性能:

其中, 表示每个维度的变量, 且有 。
在足够大的 和合适的 的调度下, 分布 几乎变成各向同性高斯分布。因此, 可以从随机噪声开始生成样本并执行迭代反向过程 来获得数据样本 。
Flow-based Model
Flow-based Model 处理连续时间相关过程 , 使用数据 和高斯噪声

其中, 和 分别为 的递减和递增函数。存在一个速度场的概率流常微分方程 (Probability Flow Ordinary Differential Equation, PF ODE):

其中这个 ODE 在 处的分布等于边际 。
速度 表示为两个条件期望的总和:

通过最小化以下训练目标,可以用模型 近似:

注意这也对应于以下反向随机微分方程 (Stochastic Differential Equation, SDE):

其中 score类似地变为条件期望:

与 类似, 可以用模型 近似, 目标如下:

这里, score 可以使用 的速度 直接计算为:

因此,只估计两个向量中的一个就足够了。
随机插值 (Stochastic interpolants) 显示任何 和 都满足 3 个条件:
and are differentiable,
导致在 和 之间进行插值而不产生偏差的过程。因此,可以通过在训练和推理期间将它们定义为一个简单的函数来使用一个简单的插值,例如:
- 线性插值器: 。
- 方差保持 (Variance-Preserving, VP) 插值器: 。
随机插值的另一个优点是扩散系数 在训练任何分数或速度模型时是独立的。因此, 当使用反向 SDE 进行采样时, 也可以在训练后明确选择 。
注意现有的基于分数的扩散模型,包括 DDPM,同样可以解释为 SDE。它们的前向扩散过程可以解释为预定义的
离散化的前向 SDE, 其平衡分布为 , 其中训练是在 上进行的 ( 足够大比如为 1000), 其中 几乎为各向同性高斯分布。生成是通过假设 , 并从随机高斯噪声开始求解相应的反向 SDE 来完成的, 其中 和扩散系数 是从前向扩散过程中隐式选择的, 这可能导致 Score-based Diffusion Model 的设计空间过于复杂。
1.3 本文观点总结
本文观点是:训练扩散模型的主要挑战和主要瓶颈是需要学习高质量的内部表征h。
本文证明了:在生成式扩散模型的训练过程中,当有外部表征支持时,训练会变得更加简单,更加有效。
本文贡献是:提出了一种简单的正则化技术,该技术利用自监督视觉表征,提高了训练效率和扩散模型的生成质量。
本文的探索过程:
发现预训练的扩散模型的确会学习到有意义的判别式表征 → 但是,这些表征明显不如 Dinov2 的表征 → 发现扩散模型学习的表征与 DINOv2 的表征之间的对齐仍然很弱(相比于 Dinov2 与自监督模型比如 MoCov3 这种表征之间的对齐) → 观察到扩散模型和 Dinov2 之间的对齐,随训练更长和模型更大而不断提高
这些发现启发本文通过结合外部自监督模型的表征来增强生成式扩散模型。
然而,使用现成的自监督视觉编码器 (比如通过对生成任务的编码器进行微调) 时,这种方法并不直接。
- 挑战1: 输入不匹配,扩散模型的输入是有噪声的,而大多数自监督学习编码器都是在干净的图像上训练的。
- 挑战2: 这些现成的视觉编码器不是为重建或生成等任务设计的。
为了克服这些技术问题,本文使用一种正则项技术表征对齐 (REPresentation Alignment, REPA) 来指导扩散模型的表征学习,将预训练的自监督表征蒸馏到扩散模型的表征中。
本质上, REPA 将干净图像 的预训练自监督视觉表征 蒸馏为噪声输入 的扩散模型的表征 。这种正则化减少了表征 中的语义差距,并更好地将其与目标自监督视觉表征 对齐。这种增强的对齐显着提高了扩散 Transformer 的生成性能。有趣的是, 对于 REPA, 作者观察到仅通过对齐前几个 Transformer Block 就可以实现足够的表征对齐。反过来, 这允许 Diffusion Transformer的后续层专注于基于对齐的表征来捕获高频细节,以进一步提高生成性能。
1.4 REPA 的三点观察
假设扩散模型为 , 其中 是 latent 变量, 满足 。作者把扩散模型 视为 2 个函数的组合: 。其中 Encoder 是 , Decoder 是 。其中编码器 隐式地学习 , 来重建 。
作者首先研究了 ImageNet 上预训练的 SiT[10]模型的逐层行为,该模型使用线性插值和速度预测进行训练。作者专注于测量 Diffusion Transformer 与最先进的自监督 DINOv2[11]模型之间的表征的差距。
作者从 3 个角度检查这一点:语义差距、特征对齐进展及其最终特征对齐。
对于语义差距,作者使用 DINOv2 特征与为 7M training iterations 训练的 SiT 模型的 linear probing 的结果进行比较。
对于特征对齐,作者使用 CKNNA[12],这是一种与 CKA 相关的内核对齐度量,但基于相互最近邻。这允许定量评估不同表示之间的对齐。

图4:预训练的 SiT 模型的对齐行为。作者研究了 DINOv2-g 和 7M 步 SiT-XL/2 之间的特征对齐。(a) 虽然 SiT 学习到了语义上有意义的表征,但与 DINOv2 相比仍然存在显着差距。(b) 使用 CKNNA,作者观察到 SiT 已经与 DINOv2 有一些对齐。(c) 随着训练更长,模型更大,对齐有所提升,但进展缓慢且不足
观察1:Diffusion Transformer 与最先进的 Visual Encoder 表现出显著的语义差距。
如图 4(a) 所示,与之前的工作[6][7]一致,作者观察到预训练的 Diffusion Transformer 的隐藏状态表征在第 20 层实现了相当高的 Linear Probing 峰值。然而,它的性能仍然远低于 DINOv2,这表明两种表征之间存在实质性的语义差距。此外,本文发现,在达到峰值后,Linear Probing 性能迅速下降,这表明 Diffusion Transformer 必须摆脱只关注学习语义丰富的表征,以生成高频细节的图像。
观察2:扩散表征与其他视觉表示已经较弱地完成对齐。
在图 4(b) 中,作者使用 CKNNA 报告了 SiT 和 DINOv2 之间的表征对齐。SiT 模型表示已经显示出比 MAE 更好的对齐。然而,绝对的对齐分数仍然低于在其他自监督学习方法 (例如 MoCov3 与 DINOv2)之间观察到的分数。这些结果表明,虽然 Diffusion Transformer 的表征表现出与自监督视觉表示的一些对齐,但对齐仍然很弱。

图5:弥合表征差距。(a) REPA 显著降低了 DiT 和 DINOv2 之间的 "语义差距" (ImageNet 上的 Linear Probing 结果)。(b) 使用 REPA 后,即使只有 8 层,DiT 和 DINOv2 之间的对齐显著提高。(c) 随着对齐的改进,可以推动 SiT 模型的生成质量和更强的 Linear Probing 结果
观察3:随着模型规模扩大,训练更多,对齐也会更好。
作者还测量了不同模型大小和训练迭代的 CKNNA 值。如图 4(c) 所示,作者观察到与模型更大,训练更长可以改进对齐水平。然而,绝对的对齐数值仍然很低,并且没有达到其他自监督视觉编码器 (例如 MoCov3 和 DINOv2) 的水平。
这些发现不是只对 SiT 模型有效,也对其他的扩散模型有用。比如作者也在 ImageNet 上预训练的 DiT 模型进行了类似的分析,也在图 4 中观察到了类似的结论。
1.6 特征对齐
REPA 将模型隐藏状态的 Patch 投影与预训练的自监督视觉表征对齐。作者使用干净的图像表征作为目标,研究这个影响。这个正则项的目的是为了 Diffusion Transformer 的隐藏层从带噪声的图片中预测干净的视觉表征,这些表征包含有用的语义信息。这为后续层重建目标提供了有意义的指导。

图6:表征的对齐使 Diffusion Transformer 的训练明显更容易。模型训练变得更加高效和有效,并且比原始模型实现了 >17.5 倍的收敛速度
如图 6 所示, 设 为预训练的编码器, 考虑干净的图像 。设 为编码器输出,其中 分别为 Patch 数量和 Embedding dimension。REPA 将 与 对齐,其中 是 Diffusion Transformer Encoder 的输出 通过可训练的投影头 的投影。在实践中, 作者简单地使用 MLP 作为 。
REPA 通过最大化预训练表征 和隐藏状态 之间的 Patch Similarity 来实现对齐:

其中 是 Patch index, 是预定义的相似度函数。
把这一项添加到原来训练扩散模型的目标函数 中:

其中 是一个超参数, 用于控制去噪和表示对齐之间的权衡。作者主要研究这个正则项 对两个流行目标的影响, 即:DiT 中使用的改进 DDPM 和 SiT 中使用的线性随机插值。
1.7 实验设置
在实验部分作者探究了下面 3 个问题:
- REPA 能否显着改善 Diffusion Transformer 的训练。
- REPA 在模型大小和表征的质量方面是否具有可扩展性。
- Diffusion Model 表示是否可以与各种视觉表征对齐?
作者严格遵循 DiT 和 SiT 的实验设置,使用 Stable Diffusion VAE 将每张图像编码为压缩向量 。对于模型配置,使用 DiT 和 SiT 论文中引入的 B/2、L/2 和 XL/2 架构,该架构处理 Patch Size 为 2 的输入。为了确保与 DiTs 和 SiTs 进行公平比较,作者在训练期间始终使用 256 的 Batch Size。
评测指标: FID、sFID,IS、精度 (Pre.) 和召回率 (Rec.)。使用 50,000 个样本。还包括 Linear Probing 结果 (Acc.) 和 CKNNA。
采样器: 遵循 SiT 的作者使用 SDE Euler-Maruyama Sampler (对于 w_t = \sigma_tw_t = \sigma_t 的 SDE),默认情况下将函数评估 (NFE) 的数量设置为 250。
基线模型 4 类:
- Pixel diffusion:ADM, VDM++, Simple diffusion, CDM
- Latent diffusion with U-Net: LDM
- Latent diffusion with transformer+U-Net hybrid models: U-ViT-H/2, DiffiT, 和 MDTv2-XL/2
- Latent diffusion with transformers: MaskDiT, SD-DiT, DiT, 和 SiT
如下图 7 所示,作者发现 REPA 在各种设计选择中始终可以显著提升生成性能,实现更好的 FID 分数。下面,我们对每个组件的影响进行了详细的分析。

图7:ImageNet 256×256 结果。所有模型都是400K 步训练的 SiT-L/2。除精度 (Acc.) 之外的所有指标均使用 NFE=250 的 SDE Euler-Maruyama Sampler 测量,without Classifier-free Guidance。Acc. 使用与目标表示对齐的 latent 特征在 ImageNet 验证集上 Linear Probing 结果
视觉编码器目标表征
如图 7 所示,作者首先分析了使用不同的预训练的自监督编码器作为目标表征的对比。视觉编码器的质量与 Diffusion Transformer 的性能之间存在很强的相关性。如果视觉编码器的表征更有意义,扩散模型不仅捕获了更好的语义,而且表现出增强的生成性能。
视觉编码器尺寸
如图 7 所示,作者评估不同尺寸 DINOv2 模型 (DINOv2-B, L, g) 来研究编码器大小的影响。可以观察到,性能差异是微不足道的,作者假设这是由于所有 DINOv2 模型都是从 DINOv2-g 模型中提取的,因此共享相似的表征。
对齐深度
如图 7 所示,作者还研究了将 REPA 损失附加到不同层的效果,发现在训练中只正则化前几个层 (例如8) 就足够了。有趣的是,将正则化限制在前几层进一步提高了生成性能 (例如,将REPA添加到第 6 层或第 8 层会产生最好的结果)。作者假设这个原因是剩余的层能够在强大的表征之上。专注于捕获高频细节。
对齐目标函数
如图 7 所示,作者比较了 2 种简单的对齐训练目标:Normalized Temperature-scaled Cross Entropy (NT-Xent)[13]或负余弦相似度 (cos. sim.)。作者发现 NT-Xent 在早期阶段 (例如 50-100K iteration) 更有优势,但差距随着时间的推移而减少。因此在未来的实验中选择 cos. sim.。
最后,作者通过改变 Visual Encoder 和 Diffusion Transformer 的大小来研究 REPA 的可扩展性。如图 8(a) 所示,与更强的表征对齐可以提高生成结果和 Linear Probing 性能。此外,随着 Diffusion Transformer 尺寸的增加,REPA 的收敛速度更显著。作者通过绘制图 8(b) 中有和没有 REPA 的不同 SiT 模型的 FID-50K 来证明这一点:REPA 使用更大的模型更快地实现了相同的 FID。最后,图 8(c),保持 Visual Encoder 固定为 DINOv2-B,该图显示了随 Diffusion Transformer 尺寸的变化而变化 Linear Probing 结果和 FID 之间的关系。更大的模型随着训练时间更长,表现出更陡峭的性能改进 (生成和 Linear Probing 的增益更快)。

图8:REPA 的扩展性。(a) 不同 Visual Encoder (400k 步) 的 REPA 精度和 FID。更强的 Encoder 提高了辨别力和生成性能。(b) 随着模型大小的增长,REPA 相对原始模型的改进越来越显著。(c) 使用固定 Visual Encoder,更大点模型更快地获得更好的性能。折线图点:50k, 100k, 200k, 400k 步的结果
系统级别对比
基于以上分析,作者对最先进的 Diffusion Model 和带有 REPA 的 Diffusion Transformer 进行了系统级的比较。首先比较了原始 DiT 或 SiT 模型与使用 REPA 训练的相同模型之间的 FID 值。如图 9 所示,REPA 在所有模型变体中显示出一致且显着的改进。特别是,在 SiT-XL/2 上,对齐表征只需训练 400k 步即可获得 FID=7.9,这已经在 超过了原始 SiT-XL 训练 7M 步的 FID。随着训练时间的延长,性能继续提高。使用 SiT-XL/2,FID 在 1M 步变为 6.4,在 4M 步变为 5.9。作者还在图 10 中定性地比较了生成结果,使用 REPA 训练的模型表现出更好的结果。

图9:ImageNet 256×256 上与普通 DiT 和 SiT 的 FID 比较。不使用无分类器指导 Classifier-free Guidance (CFG)

图10:REPA 提高了视觉缩放。作者在前 400k 步比较 2 个 SiT-XL/2 模型生成的图像,REPA 应用于其中一个模型。2 个模型共享相同的噪声、采样器和采样步骤的数量,并且都没有使用 Classifier-free Guidance
最后作者使用 Classifier-free Guidance 提供了 SiT-XL/2 与 REPA 和其他 Diffusion Model 之间的定量比较,如图 11 所示。本文方法已经超过了原始的 SiT-XL/2,Epoch 减少 7 倍,并且通过更长的训练进一步改进。在 800 个 Epoch,带有 REPA 的 SiT-XL/2 在使用 w = 1.35 w = 1.35 的 Classifier-free Guidance 时实现了 1.80 的 FID,并通过额外的 Classifier-free Guidance 调度算法 Guidance interval 实现了 1.42 的 FID。作者还在图 12 中提供了 SiT-XL/2 与 REPA 的定性结果。

图11:ImageNet 256×256 与 CFG 的系统级比较。包含额外 CFG 调度的结果用星号 (*) 标记,表示将 Guidance interval 方法应用于 REPA

图12:SiT-XL/2 + REPA 模型从 ImageNet 256×256 中选择样本。使用 w = 4.0 的 Classifier-free Guidance
消融实验结果
不同 timestep 的表征
作者首先对比了不同 noise scale (即不同 timestep) 下的 SiT 模型输出的语义差异 (通过 Linear Probing 精度衡量),与干净的 DINOv2-g 表征之间的最大 CKNNA 值。结果如下图 13 所示,在不同的噪声水平下,REPA 始终可以缩小表征的差距,比如获得更好的 Linear Probing 结果和更高的 CKNNA 值。

图13:不同 timestep 的表示差距。REPA 始终可以减少不同 noise scale 的表征差距
对齐到不同的 Visual Encoder。作者将 REPA 扩展到其他 Visual Encoder,不限于 Dinov2 模型。作者使用具有 MAE 或 MoCov3 的 REPA 训练 SiT-L/2 模型。如图 14 所示,这些模型显示出比原始模型更高的 CKNNA 值。这表明 REPA 在对齐各种 Visual Encoder 的表征方面都是有效的,不仅限于 Dinov2。

图14:对齐到不同的 Visual Encoder。无论 Visual Encoder 如何选择,REPA 都可以增强表征
#DiffusionModel(扩散模型)系列论文总结
文总结了DiffusionModel(扩散模型)系列论文,包含:检测、跟踪、分割、深度估计、BEV、NeRF、GS、蒸馏、LLIE、轨迹预测/生成、视频生成、点云匹配、语音、规划、数据增强等领域,总计56篇论文,可作为科研、开发的参考资料。
1.Efficient/高效
MobileDiffusion
题目:MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices
名称:MobileDiffusion:移动设备上的亚秒级文本到图像生成
论文:https://arxiv.org/abs/2311.16567
代码:
单位:谷歌
SparseDM
题目:SparseDM: Toward Sparse Efficient Diffusion Models
名称:稀疏DM:迈向稀疏高效扩散模型
论文:https://arxiv.org/abs/2404.10445
代码:
单位:清华、博世
AdaDiff
题目:AdaDiff: Accelerating Diffusion Models through Step-Wise Adaptive Computation
名称:AdaDiff:通过逐步自适应计算加速扩散模型
论文:https://arxiv.org/abs/2309.17074
代码:
单位:阿联酋人工智能大学、谷歌
DM-BlockCache
题目:Cache Me if You Can: Accelerating Diffusion Models through Block Caching
名称:如果可以的话缓存我:通过块缓存加速扩散模型
论文:https://arxiv.org/abs/2312.03209
代码:https://fwmb.github.io/blockcaching/
单位:
DistriFusion
题目:DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models
名称:DistriFusion:高分辨率扩散模型的分布式并行推理
论文:https://arxiv.org/abs/2402.19481
代码:https://github.com/mit-han-lab/distrifuser
单位:MIT
LW-DM-NAS
题目:Lightweight Diffusion Models with Distillation-Based Block Neural Architecture Search
名称:基于蒸馏的块段神经结构搜索的轻量级扩散模型
论文:https://arxiv.org/abs/2311.04950
代码:
单位:清华大学
2.Det/目标检测
Diff3DETR
题目:Diff3DETR:Agent-based Diffusion Model for Semi-supervised 3D Object Detection
名称:Diff3DETR:基于Agent的半监督3D目标检测扩散模型
论文:https://arxiv.org/abs/2408.00286
代码:
单位:中科大
MonoWAD
题目:MonoWAD: Weather-Adaptive Diffusion Model for Robust Monocular 3D Object Detection
名称:MonoWAD:用于鲁棒单目3D目标检测的天气自适应扩散模型
论文:https://arxiv.org/abs/2407.16448
代码:https://github.com/VisualAIKHU/MonoWAD
单位:庆熙大学
DifFUSER
题目:DifFUSER: Diffusion Model for Robust Multi-Sensor Fusion in 3D Object Detection and BEV Segmentation
名称:DifFUSER:3D目标检测和BEV分割中鲁棒多传感器融合的扩散模型
论文:https://arxiv.org/abs/2404.04629
代码:
单位:蒙纳士大学、湖南大学
DiffYOLO
题目:DiffYOLO: Object Detection for Anti-Noise via YOLO and Diffusion Models
名称:DiffYOLO:通过YOLO和扩散模型进行抗噪声目标检测
论文:https://arxiv.org/abs/2401.01659
代码:
单位:中国科学院大学
Diffusion-SS3D
题目:Diffusion-SS3D: Diffusion Model for Semi-supervised 3D Object Detection
名称:Diffusion-SS3D:半监督3D目标检测的扩散模型
论文:https://arxiv.org/abs/2312.02966
代码:https://github.com/luluho1208/Diffusion-SS3D
单位:台湾阳明交通大学
3DifFusionDet
题目:3DifFusionDet: Diffusion Model for 3D Object Detection with Robust LiDAR-Camera Fusion
名称:3DifFusionDet:基于稳健激光雷达相机融合的3D目标检测扩散模型
论文:https://arxiv.org/abs/2311.03742
代码:
单位:加利福尼亚大学
Diff3Det
题目:Diffusion-based 3D Object Detection with Random Boxes
名称:使用随机框进行基于扩散的 3D 对象检测
论文:https://arxiv.org/abs/2309.02049
代码:
单位:华中科技大学
SVDM
题目:SVDM: Single-View Diffusion Model for Pseudo-Stereo 3D Object Detection
名称:SVDM:伪立体3D目标检测的单视图扩散模型
论文:https://arxiv.org/abs/2307.02270
代码:
单位:南京大学
CamoDiffusion
题目:CamoDiffusion: Camouflaged Object Detection via Conditional Diffusion Models
名称:CamoDiffusion:基于条件扩散模型的伪装目标检测
论文:https://arxiv.org/abs/2305.17932
代码:
单位:厦门大学
DiffusionDet
题目:DiffusionDet: Diffusion Model for Object Detection
名称:DiffusionDet:目标检测的扩散模型
论文:https://arxiv.org/abs/2211.09788
代码:https://github.com/ShoufaChen/DiffusionDet
单位:香港大学
4.Trcking/跟踪
DaDiff
题目:DaDiff: Domain-aware Diffusion Model for Nighttime UAV Tracking
名称:DaDiff:夜间无人机跟踪的域感知扩散模型
论文:https://arxiv.org/abs/2410.12270
代码:https://github.com/vision4robotics/DaDiff
单位:香港大学
DiffusionTrack
题目:DiffusionTrack: Diffusion Model For Multi-Object Tracking
名称:扩散跟踪:多目标跟踪的扩散模型
论文:https://arxiv.org/abs/2308.09905
代码:https://github.com/RainBowLuoCS/DiffusionTrack
单位:中科院深圳先进技术研究院
5.Seg/分割
LaneSeg-DM
题目:Lane Segmentation Refinement with Diffusion Models
名称:基于扩散模型的车道分割细化
论文:https://arxiv.org/abs/2405.00620
代码:
单位:华为
DiffMap
题目:DiffMap: Enhancing Map Segmentation with Map Prior Using Diffusion Model
名称:DiffMap:使用扩散模型增强地图先验的地图分割
论文:https://arxiv.org/abs/2405.02008
代码:
单位:清华、戴姆勒
6.Depth/深度估计
Diffusion4RobustDepth
题目:Diffusion Models for Monocular Depth Estimation: Overcoming Challenging Conditions
名称:单目深度估计的扩散模型:克服挑战性条件
论文:https://arxiv.org/abs/2407.16698
代码:https://github.com/fabiotosi92/Diffusion4RobustDepth
单位:博洛尼亚大学
D4RD
题目:Digging into contrastive learning for robust depth estimation with diffusion models
名称:利用扩散模型进行鲁棒深度估计的对比学习研究
论文:https://arxiv.org/abs/2404.09831
代码:https://github.com/wangjiyuan9/D4RD
单位:南洋理工大学
MVDD
题目:MVDD: Multi-View Depth Diffusion Models
名称:MVDD:多视图深度扩散模型
论文:https://arxiv.org/abs/2312.04875
代码:
单位:谷歌
MonoDiffusion
题目:MonoDiffusion: Self-Supervised Monocular Depth Estimation Using Diffusion Model
名称:单扩散:基于扩散模型的自监督单目深度估计
论文:https://arxiv.org/abs/2311.07198
代码:https://github.com/ShuweiShao/MonoDiffusion
单位:北航、百度
OF-MDE-DM
题目:The Surprising Effectiveness of Diffusion Models for Optical Flow and Monocular Depth Estimation
名称:扩散模型在光流和单眼深度估计中的惊人有效性
论文:https://arxiv.org/abs/2306.01923
代码:https://diffusion-vision.github.io/
单位:DeepMind、谷歌
DepthGen
题目:Monocular Depth Estimation using Diffusion Models
名称:基于扩散模型的单目深度估计
论文:https://arxiv.org/abs/2302.14816
代码:https://depth-gen.github.io/
单位:谷歌
7.BEV/鸟瞰图
Diff-BEV
题目:DiffBEV: Conditional Diffusion Model for Bird's Eye View Perception
名称:DiffBEV:鸟瞰感知的条件扩散模型
论文:https://arxiv.org/abs/2303.08333
代码:https://github.com/JiayuZou2020/DiffBEV
单位:中科院自动化研究所
8.Gaussion/高斯
GaussianDiffusion
题目:GaussianDiffusion: 3D Gaussian Splatting for Denoising Diffusion Probabilistic Models with Structured Noise
名称:高斯扩散:用于去噪具有结构噪声的扩散概率模型的3D高斯散斑
论文:https://arxiv.org/abs/2311.11221
代码:
单位:哈尔滨工业大学(深圳)
9.NeRF/神经网络辐射场
Inpaint4DNeRF
题目:Inpaint4DNeRF: Promptable Spatio-Temporal NeRF Inpainting with Generative Diffusion Models
名称:Inpaint4DNeRF:基于生成扩散模型的可促进时空NeRF Inpainting
论文:https://arxiv.org/abs/2401.00208
代码:
单位:香港科技大学
Edit-DiffNeRF
题目:Edit-DiffNeRF: Editing 3D Neural Radiance Fields using 2D Diffusion Model
名称:编辑DiffNeRF:使用2D扩散模型编辑3D神经辐射场
论文:https://arxiv.org/abs/2306.09551
代码:
单位:詹姆斯·库克大学
DiffusioNeRF
题目:DiffusioNeRF: Regularizing Neural Radiance Fields with Denoising Diffusion Models
名称:扩散RF:用去噪扩散模型正则化神经辐射场
论文:https://arxiv.org/abs/2302.12231
代码:https://www.github.com/nianticlabs/diffusionerf
单位:NianticLabs
10.Diffusion/蒸馏
LoRA-Diffusion-DM
题目:LoRA-Enhanced Distillation on Guided Diffusion Models
名称:基于引导扩散模型的LoRA增强蒸馏
论文:https://arxiv.org/abs/2312.06899
代码:
单位:微软
11.LLIE/低照度图像增强
LightenDiffusion
题目:LightenDiffusion: Unsupervised Low-Light Image Enhancement with Latent-Retinex Diffusion Models
名称:LightenDiffusion:基于潜在视网膜扩散模型的无监督低光图像增强
论文:https://arxiv.org/abs/2407.08939
代码:https://github.com/JianghaiSCU/LightenDiffusion
单位:四川大学
Spatial-Entropy-Loss
题目:Equipping Diffusion Models with Differentiable Spatial Entropy for Low-Light Image Enhancement
名称:为扩散模型配备可微分空间熵以增强低光图像
论文:https://arxiv.org/abs/2404.09735
代码:https://github.com/shermanlian/spatial-entropy-loss
单位:乌普萨拉大学
LDM-ISP
题目:LDM-ISP: Enhancing Neural ISP for Low Light with Latent Diffusion Models
名称:LDM-ISP:利用潜在扩散模型增强低光下的神经ISP
论文:https://arxiv.org/abs/2312.01027
代码:https://csqiangwen.github.io/projects/ldm-isp/
单位:香港科技大学
LLDif
题目:LLDif: Diffusion Models for Low-light Emotion Recognition
名称:LLDif:低光情绪识别的扩散模型
论文:https://arxiv.org/abs/2408.04235
代码:澳大利亚国立大学
单位:
LLDiffusion
题目:LLDiffusion: Learning Degradation Representations in Diffusion Models for Low-Light Image Enhancement
名称:LLDiffusion:学习低光图像增强扩散模型中的退化表示
论文:https://arxiv.org/abs/2307.14659
代码:https://github.com/TaoWangzj/LLDiffusion
单位:南京大学
12.Trajectory/轨迹
TrajDiffuse
题目:TrajDiffuse: A Conditional Diffusion Model for Environment-Aware Trajectory Prediction
名称:轨迹扩散:一种用于环境感知轨迹预测的条件扩散模型
论文:https://arxiv.org/abs/2410.10804
代码:
单位:罗格斯大学
Map2Traj
题目:Map2Traj: Street Map Piloted Zero-shot Trajectory Generation with Diffusion Model
名称:Map2Traj:基于扩散模型的零样本轨迹生成街道地图
论文:https://arxiv.org/abs/2407.19765
代码:
单位:东南大学
SingularTrajectory
题目:SingularTrajectory: Universal Trajectory Predictor Using Diffusion Model
名称:SingularTrajectory:使用扩散模型的通用轨迹预测器
论文:https://arxiv.org/abs/2403.18452
代码:https://github.com/inhwanbae/SingularTrajectory
单位:光州科技大学
IDM
题目:Intention-aware Denoising Diffusion Model for Trajectory Prediction
名称:轨迹预测的意图感知去噪扩散模型
论文:https://arxiv.org/abs/2403.09190
代码:
单位:浙江大学
Diff-RNTraj
题目:Diff-RNTraj: A Structure-aware Diffusion Model for Road Network-constrained Trajectory Generation
名称:Diff-RNTrai:一种用于道路网络约束轨迹生成的结构感知扩散模型
论文:https://arxiv.org/abs/2402.07369
代码:
单位:北京交通大学
EquiDiff
题目:EquiDiff: A Conditional Equivariant Diffusion Model For Trajectory Prediction
名称:EquiDiff:一种用于轨迹预测的条件等变扩散模型
论文:https://arxiv.org/abs/2308.06564
代码:
单位:香港科技大学
13.Video/视频
4Diffusion
题目:4Diffusion: Multi-view Video Diffusion Model for 4D Generation
名称:4Diffusion:用于4D生成的多视图视频扩散模型
论文:https://arxiv.org/abs/2405.20674
代码:https://aejion.github.io/4diffusion/
单位:北航、上海AILab
DrivingDiffusion
题目:DrivingDiffusion: Layout-Guided multi-view driving scene video generation with latent diffusion model
名称:DrivingDiffusion:基于潜在扩散模型的布局引导多视图驾驶场景视频生成
论文:https://arxiv.org/abs/2310.07771
代码:DrivingDiffusion: Layout-Guided multi-view driving scene video generation with latent diffusion model
单位:百度
14.PointCloud/点云
PCRDiffusion
题目:PCRDiffusion: Diffusion Probabilistic Models for Point Cloud Registration
名称:PCRDDiffusion:点云配准的扩散概率模型
论文:https://arxiv.org/abs/2312.06063
代码:
单位:西安电子科技大学
SPVD
题目:Efficient and Scalable Point Cloud Generation with Sparse Point-Voxel Diffusion Models
名称:基于稀疏点体素扩散模型的高效可扩展点云生成
论文:https://arxiv.org/abs/2408.06145
代码:https://github.com/JohnRomanelis/SPVD
单位:派图拉斯大学
DiffusionPCR
题目:DiffusionPCR: Diffusion Models for Robust Multi-Step Point Cloud Registration
名称:DiffusionPCR:稳健多步点云配准的扩散模型
论文:https://arxiv.org/abs/2312.03053
代码:
单位:华中科技大学
15.Speech/语音
FastDiff
题目:FastDiff: A Fast Conditional Diffusion Model for High-Quality Speech Synthesis
名称:FastDiff:一种用于高质量语音合成的快速条件扩散模型
论文:https://arxiv.org/abs/2204.09934
代码:https://fastdiff.github.io/
单位:浙江大学、腾讯AILab
16.Planning/规划
AdaptDiffuser
题目:AdaptDiffuser: Diffusion Models as Adaptive Self-evolving Planners
名称:AdaptDiffuser:作为自适应自进化规划器的扩散模型
论文:https://arxiv.org/abs/2302.01877
代码:https://github.com/Liang-ZX/adaptdiffuser
单位:香港大学、加州大学伯克利
DiMSam
题目:DiMSam: Diffusion Models as Samplers for Task and Motion Planning under Partial Observability
名称:DiMSam:在部分可观测性下作为任务和运动规划采样器的扩散模型
论文:https://arxiv.org/abs/2306.13196
代码:
单位:MIT、英伟达
17.DataAug/数据增强
DatasetDM
题目:DatasetDM: Synthesizing Data with Perception Annotations Using Diffusion Models
名称:DatasetDM:使用扩散模型合成带有感知注释的数据
论文:https://arxiv.org/abs/2308.06160
代码:https://github.com/showlab/DatasetDM
单位:浙江大学
DreamDA
题目:DreamDA: Generative Data Augmentation with Diffusion Models
名称:DreamDA:基于扩散模型的生成数据增强
论文:https://arxiv.org/abs/2403.12803
代码:https://github.com/yunxiangfu2001/DreamDA
单位:香港大学、上海AILab
3D-VirtFusion
题目:3D-VirtFusion: Synthetic 3D Data Augmentation through Generative Diffusion Models and Controllable Editing
名称:3D虚拟融合:通过生成扩散模型和可控编辑进行合成3D数据增强
论文:https://arxiv.org/abs/2408.13788
代码:
单位:南洋理工大学
18.Scene/场景
RefFusion
题目:RefFusion: Reference Adapted Diffusion Models for 3D Scene Inpainting
名称:RefFusion:用于3D场景镶嵌的参考自适应扩散模型
论文:https://arxiv.org/abs/2404.10765
代码:https://reffusion.github.io/
单位:英伟达
LidarDiffusion
题目:Towards Realistic Scene Generation with LiDAR Diffusion Models
名称:基于激光雷达扩散模型的真实场景生成
论文:https://arxiv.org/abs/2404.00815
代码:https://lidar-diffusion.github.io/
单位:CMU
相关文章:
51c扩散模型~合集1
我自己的原文哦~ https://blog.51cto.com/whaosoft/11541675 #Diffusion Forcing 无限生成视频,还能规划决策,扩散强制整合下一token预测与全序列扩散 当前,采用下一 token 预测范式的自回归大型语言模型已经风靡全球,同时互联…...

从零开始深度学习:全连接层、损失函数与梯度下降的详尽指南
引言 在深度学习的领域,全连接层、损失函数与梯度下降是三块重要的基石。如果你正在踏上深度学习的旅程,理解它们是迈向成功的第一步。这篇文章将从概念到代码、从基础到进阶,详细剖析这三个主题,帮助你从小白成长为能够解决实际…...

Liebherr利勃海尔 EDI 需求分析
Liebherr 使用 EDI 技术来提高业务流程的效率、降低错误率、加快数据交换速度,并优化与供应商、客户和其他合作伙伴之间的业务沟通。通过 EDI,Liebherr 实现了与全球交易伙伴的自动化数据交换,提升了供应链管理和订单处理的透明度。 Liebher…...

java小练习
小练1.用while语句计算11/2!1/3!1/4!...1/20!的和 public class test_11_17_2 {public static void main(String[] args) {double sum 0;double item 1;int n 20;int i 1;while(i<n){sum item;i i1;item item*(1.0/i);}System.out.println(sum);} } 小练2.计算88888…...

go语言中的占位符有哪些
在Go语言中,占位符主要用于格式化字符串输出,特别是在使用fmt包中的Printf系列函数时。以下是Go语言中常用的占位符: %v:代表值的默认格式,对于字符串是直接输出,对于整型是十进制形式。%v:扩展…...

基于Windows安装opus python库
项目中需要用到一些opus格式的编解码功能,找到网上有opus的开源库。网址:Opus Codec 想着人生苦短,没想到遇上了错误!在这里记录一下过程 过程 安装python库 pip3 install opuslib验证 >>> import opuslib Tracebac…...

【设计模式】行为型模式(五):解释器模式、访问者模式、依赖注入
《设计模式之行为型模式》系列,共包含以下文章: 行为型模式(一):模板方法模式、观察者模式行为型模式(二):策略模式、命令模式行为型模式(三):责…...

使用nossl模式连接MySQL数据库详解
使用nossl模式连接MySQL数据库详解 摘要一、引言二、nossl模式概述2.1 SSL与nossl模式的区别2.2 选择nossl模式的场景三、在nossl模式下连接MySQL数据库3.1 准备工作3.2 C++代码示例3.3 代码详解3.3.1 初始化MySQL连接对象3.3.2 连接到MySQL数据库3.3.3 执行查询操作3.3.4 处理…...

【MySQL】ubantu 系统 MySQL的安装与免密码登录的配置
🍑个人主页:Jupiter. 🚀 所属专栏:MySQL初阶探索:构建数据库基础 欢迎大家点赞收藏评论😊 目录 📚mysql的安装📕MySQL的登录🌏MySQL配置免密码登录 📚mysql的…...

高级 SQL 技巧讲解
大家好,我是程序员小羊! 前言: SQL(结构化查询语言)是管理和操作数据库的核心工具。从基本的查询语句到复杂的数据处理,掌握高级 SQL 技巧不仅能显著提高数据分析的效率,还能解决业务中的复…...

浅论AI大模型在电商行业的发展未来
随着人工智能(AI)技术的快速发展,AI大模型在电商行业中扮演着越来越重要的角色。本文旨在探讨AI大模型如何赋能电商行业,包括提升销售效率、优化用户体验、增强供应链管理等方面。通过分析AI大模型在电商领域的应用案例和技术进展…...

【python笔记03】《类》
文章目录 面向对象基本概念对象的概念类的概念 类的定义类的创建(实例的模板)类的实例化--获取对象对象方法中的self关键字面试题请描述什么是对象,什么是类。请观阅读如下代码,判断是否能正常运行,如果不能正常运行&a…...

Flutter 应用在真机上调试的流程
在真机上调试 Flutter 应用的方法有很多,可以使用 USB 数据线连接设备到电脑进行调试,也可以通过无线方式进行 Flutter 真机调试。 1. 有线调试 设备准备 启用开发者模式: Android:进入 设置 > 关于手机,连续点击…...

以太坊基础知识结构详解
以太坊的历史和发展 初创阶段 2013年:Vitalik Buterin 发表了以太坊白皮书,提出了一个通用的区块链平台,不仅支持比特币的货币功能,还能支持更复杂的智能合约。2014年:以太坊项目启动,进行了首次ICO&…...
)
安全见闻(完整版)
目录 安全见闻1 编程语言和程序 编程语言 函数式编程语言: 数据科学和机器学习领域: Web 全栈开发: 移动开发: 嵌入式系统开发: 其他: 编程语言的方向: 软件程序 操作系统 硬件设备…...
LeetCode100之反转链表(206)--Java
1.问题描述 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表 示例1 输入:head [1,2,3,4,5] 输出:[5,4,3,2,1] 示例2 输入:head [1,2] 输出:[2,1] 示例3 输入:head [] 输…...

牛客周赛第一题2024/11/17日
链接:登录—专业IT笔试面试备考平台_牛客网 来源:牛客网 时间限制:C/C/Rust/Pascal 1秒,其他语言2秒 空间限制:C/C/Rust/Pascal 256 M,其他语言512 M 64bit IO Format: %lld 题目描述 小红这天来到了三…...
麒麟Server下安装东方通TongLINK/Q
环境 系统:麒麟Server SP3 2403 应用:TLQ8.1(Install_TLQ_Standard_Linux2.6.32_x86_64_8.1.17.0.tar.gz) 安装Server 将文件解压到/usr/local/tlq。 cd /opt/tlq/ mkdir /usr/local/tlq/ tar -zxvf Install_TLQ_Standard_Linux2.6.32_x86_64_8.1.1…...

BERT的中文问答系统33
我们在现有的代码基础上增加网络搜索的功能。我们使用 requests 和 BeautifulSoup 来从百度搜索结果中提取信息。以下是完整的代码,包括项目结构、README.md 文件以及所有必要的代码。 项目结构 xihe241117/ ├── data/ │ └── train_data.jsonl ├── lo…...

Ubuntu下的Eigen库的安装及基本使用教程
一、Eigen库介绍 简介 Eigen [1]目前最新的版本是3.4,除了C标准库以外,不需要任何其他的依赖包。Eigen使用的CMake建立配置文件和单元测试,并自动安装。如果使用Eigen库,只需包特定模块的的头文件即可。 基本功能 Eigen适用范…...
)
Midjourney 8x10高保真输出崩溃诊断:内存溢出日志解析、--sref跨模型参考失效、以及GPU显存碎片化导致的upscale中断(附实时监控脚本)
更多请点击: https://intelliparadigm.com 第一章:Midjourney 8x10高保真输出崩溃现象全景概览 近期,大量 Midjourney 用户在使用 --s 1000 --q 2 --v 6.3 配合 --ar 8:10 参数生成高分辨率人像/建筑类图像时,遭遇高频次任务中…...

BaiduNetdiskPlugin-macOS:三步破解百度网盘限速,实现SVIP级别下载体验
BaiduNetdiskPlugin-macOS:三步破解百度网盘限速,实现SVIP级别下载体验 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百…...

HuggingClaw:用开源模型模拟Claude API的本地开发与测试方案
1. 项目概述:当HuggingFace遇上Claude,一个AI模型管理新思路最近在GitHub上看到一个挺有意思的项目,叫“HuggingClaw”。光看名字,你大概就能猜到它想干什么——把HuggingFace和Claude这两个在AI领域响当当的名字结合到一起。作为…...

信息时代个人知识管理:从碎片化信息到结构化洞察的实践指南
1. 信息海洋中的航行:从碎片到洞察我们正漂浮在一片前所未有的信息海洋里。每天,无数的邮件、通知、文章、帖子像潮水般涌来,我们则像一个个拾贝者,快乐地捡拾着那些零碎的趣闻和知识的金块。这种感觉很奇妙,不是吗&am…...

观察taotoken用量看板如何帮助个人开发者精细化控制api成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察taotoken用量看板如何帮助个人开发者精细化控制api成本 对于个人开发者或小型团队而言,在使用大模型API进行项目开…...
)
小驴西藏旅游网站(10018)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

基于MCP协议构建AI驱动的Upwork自动化工作流:从工具化接口到安全实践
1. 项目概述:一个连接AI与自由职业平台的智能桥梁如果你是一名自由职业者,或者正在探索如何用AI来优化你的工作流程,那么你肯定对在Upwork、Fiverr这类平台上反复刷新、筛选项目、撰写提案的繁琐过程深有体会。每天花上几个小时,只…...

图像识别钻卡工况气囊点爆方法【附方案】
✨ 长期致力于钻卡工况、约束系统、图像识别、控制策略研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)双阶段融合点爆判别机制: 设计一种…...

【实测避坑】文科/理工科怎么选论文降AI工具?5款热门工具深度评测
最近看了一些行业报告,AI工具在写作方面的普及率真的已经超乎想象了。 很多大学生在写论文时也都习惯用AI来辅助寻找灵感、提高效率。 与此同时,相关部门针对人工智能写作出台了一系列规定,各大学术检测平台也都在不断升级AIGC检测算法。 现…...
)
别再纠结了!手把手教你根据项目需求选对Intel Realsense型号(D455/D435i/D415/T265实战对比)
深度视觉硬件选型指南:Intel RealSense全系型号实战解析 在计算机视觉和机器人领域,选择合适的3D感知硬件往往决定了项目成败。面对Intel RealSense系列中D455、D435i、D415和T265等不同型号,许多开发者常陷入"参数对比陷阱"——过…...