Pythony——多线程简单爬虫实现
简单爬虫实现
import requests
from bs4 import BeautifulSoup# 生成要爬取的网页地址列表,这里是博客园的分页地址,从第1页到第50页
urls = [f"https://www.cnblogs.com/#p{i}" for i in range(1, 50 + 1)]# 生产者函数——负责下载网页内容
def craw(url):这个函数接收一个网页的URL作为参数,使用requests库发送GET请求获取该网页的内容,并以文本形式返回。r = requests.get(url)# 要下载内容的网页URLreturn r.text#返回获取到的网页文本内容# 消费者函数——拿着生产者下载好的网页内容,进行解析
def parse(html):"""此函数接收从网页下载的HTML文本内容作为参数,使用BeautifulSoup库对其进行解析,提取出所有class名为post-item-title的超链接a标签,然后遍历这些标签,将每个标签的href链接内容和标签文字内容以元组的形式提取出来并返回"""# 指定为html解析器 从网页上下载下来的HTML文本内容soup = BeautifulSoup(html, "html.parser") # 提取出所有class名为post-item-title 的 超链接 a标签links = soup.find_all("a", class_="post-item-title")# 遍历links元组,将超链接a标签的href链接内容 和 标签文字内容提取输出return [(link["href"], link.get_text()) for link in links]# 返回一个包含元组的列表,每个元组包含一个超链接的href值和对应的文字内容# 主程序入口,当脚本直接运行时执行以下代码
if __name__ == '__main__':"""在这里我们调用了craw函数去下载urls列表中第3个网址(索引为2)的网页内容,然后将下载好的内容传递给parse函数进行解析,最后遍历parse函数返回的结果并打印出来。"""for result in parse(craw(urls[2])):print(result)生产者消费者函数
import threading
import time
import random
import queue
import blog_spider# 定义生产者线程要执行的函数,用于从URL队列中获取URL,爬取网页内容并放入HTML队列
def do_craw(url_queue: queue.Queue, html_queue: queue.Queue):#url_queue: 存储待爬取URL的队列, html_queue: 用于存储爬取到的网页HTML内容的队列"""这个函数是生产者线程要执行的函数。不断从URL队列中获取URL,调用blog_spider.craw函数爬取网页的内容,然后将爬取到的HTML内容放入HTML队列中,并打印相关的内容。"""while True:# 从URL队列中获取一个URLurl = url_queue.get()# 调用blog_spider模块中的craw函数爬取该URL对应的网页内容html = blog_spider.craw(url)# 将爬取到的网页内容放入HTML队列html_queue.put(html)# 打印当前线程的名称、正在爬取的URL以及URL队列剩余的大小print(threading.current_thread().name, f"craw {url}", "url_queue.size=", url_queue.qsize())time.sleep(random.randint(1, 2))#休眠一段时间# 定义消费者线程要执行的函数,用于从HTML队列中获取网页内容
def do_parse(html_queue: queue.Queue, fout):#html_queue: 存储网页HTML内容的队列"""此函数是消费者线程要执行的任务函数。它会不断从HTML队列中获取网页内容,调用blog_spider.parse函数对其进行解析,fout: 用于写入解
析结果的文件对象将解析结果写入到指定的文件中,并打印相关的内容。"""while True:# 从HTML队列中获取一个网页内容html = html_queue.get()# 调用blog_spider模块中的parse函数对网页内容进行解析,得到解析结果results = blog_spider.parse(html)for result in results:fout.write(str(result) + "\n")# 打印当前线程的名称、解析结果的数量以及HTML队列剩余的大小print(threading.current_thread().name, f"results.size", len(results), "html_queue_size=", html_queue.qsize())time.sleep(random.randint(1, 2))#休眠一段时间# 主程序入口,当脚本直接运行时执行以下代码
if __name__ == '__main__':# 创建一个用于存储待爬取URL的队列url_queue = queue.Queue()# 创建一个用于存储爬取到的网页HTML内容的队列html_queue = queue.Queue()# 将blog_spider模块中定义的所有URL放入URL队列for url in blog_spider.urls:url_queue.put(url)# 开启生产者线程for idx in range(3):# 创建一个新的线程,指定其执行的任务函数为do_craw,并传入相应的参数t = threading.Thread(target=do_craw, args=(url_queue, html_queue), name=f"craw{idx}")t.start()# 开启消费者线程和创建用于存储解析结果的文本文件fout = open("spider_data.txt", "w")for idx in range(2):# 创建一个新的线程,指定其执行的任务函数为do_parse,并传入相应的参数t = threading.Thread(target=do_parse, args=(html_queue, fout), name=f"parse{idx}")t.start()相关文章:

Pythony——多线程简单爬虫实现
简单爬虫实现 import requests from bs4 import BeautifulSoup# 生成要爬取的网页地址列表,这里是博客园的分页地址,从第1页到第50页 urls [f"https://www.cnblogs.com/#p{i}" for i in range(1, 50 1)]# 生产者函数——负责下载网页内容 d…...

如何修改 a 链接的样式
在CSS中,你可以使用选择器来针对HTML中的特定元素(例如<a>标签,也就是链接)进行修改样式。以下是一些常见的修改<a>链接样式的方法: 移除下划线: a { text-decoration: none; } 修改链接的…...

第6章 详细设计-6.5 软硬件接口文档设计
6.5 软硬件接口文档设计 一般的产品都包含硬件和软件两部分,产品设计阶段需要确保硬件开发人员和软件开发的沟通准确、高效。所以需要一份书面的文档来承载软件和硬件之间的沟通细节。以下面的细水雾除尘设备为例进行讲解,涉及软件和硬件的接口ÿ…...

【pyspark学习从入门到精通14】MLlib_1
目录 包的概览 加载和转换数据 在前文中,我们学习了如何为建模准备数据。在本文中,我们将实际使用这些知识,使用 PySpark 的 MLlib 包构建一个分类模型。 MLlib 代表机器学习库。尽管 MLlib 现在处于维护模式,即它不再积极开发…...

C++全局构造和初始化
片段摘自程序员的自我修养—链接、装载与库.pdf 11.4 程序在进入main之前,需要对全局对象进行构造初始化。 glibc全局对象进行构造初始化 gibc启动程序时会经过.init段,退出程序时会经过.finit段。这两个段中的代码最终拼接成_init()和_finit(),这两个…...

安全见闻-泷羽sec课程笔记
编程语言 C语言:一种通用的、面向过程的编程语言,广泛应用于系统软件和嵌入式开发。 C:在C语言基础上发展而来,支持面向对象编程,常用于尊戏开发、高性能计算等领域。 Java:一种广泛使用的面问对象编程语言,具有跨平台…...

游戏引擎学习第17天
视频参考:https://www.bilibili.com/video/BV1LPUpYJEXE/ 回顾上一天的内容 1. 整体目标: 处理键盘输入:将键盘输入的处理逻辑从平台特定的代码中分离出来,放入更独立的函数中以便管理。优化消息循环:确保消息循环能够有效处理 …...
)
【FFmpeg】FFmpeg 内存结构 ③ ( AVPacket 函数简介 | av_packet_ref 函数 | av_packet_clone 函数 )
文章目录 一、av_packet_ref 函数1、函数原型2、函数源码分析3、函数使用代码示例 二、av_packet_clone 函数1、函数原型2、函数源码分析 FFmpeg 4.0 版本源码地址 : GitHub : https://github.com/FFmpeg/FFmpeg/tree/release/4.0GitCode : https://gitcode.com/gh_mirrors/ff…...

【学习笔记】量化概述
Quantize量化概念与技术细节 题外话,在七八年前,一些关于表征的研究,会去做表征的压缩,比如二进制嵌入这种事情,其实做得很简单,无非是找个阈值,然后将浮点数划归为零一值,现在的Qu…...
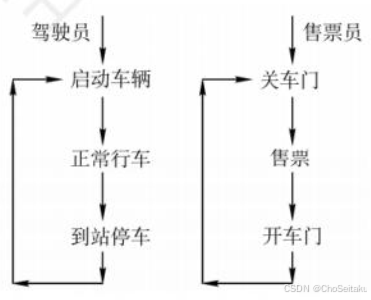
同步互斥相关习题10道 附详解
PV操作 2016 某系统允许最多10个进程同时读文件F,当同时读文件F的进程不满10个时,欲读该文件的其他文件可立即读,当已有10个进程在读文件F时读,其他欲读文件F的进程必须等待,直至有进程读完后退出方可去读 在实现管…...
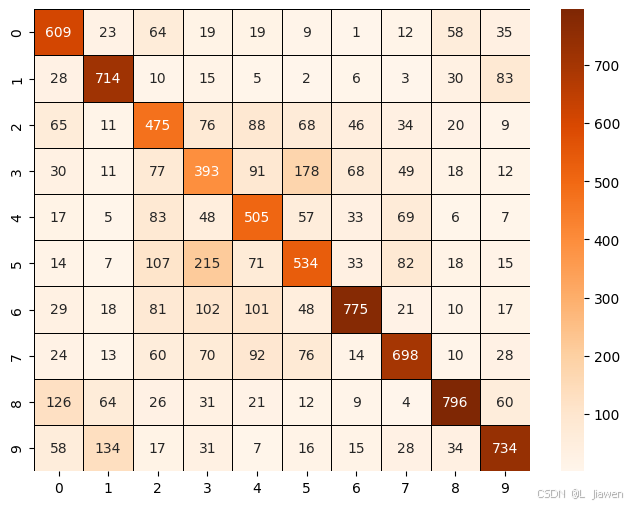
【Python · PyTorch】卷积神经网络 CNN(LeNet-5网络)
【Python PyTorch】卷积神经网络 CNN(LeNet-5网络) 1. LeNet-5网络※ LeNet-5网络结构 2. 读取数据2.1 Torchvision读取数据2.2 MNIST & FashionMNIST 下载解包读取数据 2. Mnist※ 训练 LeNet5 预测分类 3. EMnist※ 训练 LeNet5 预测分类 4. Fash…...

Git 拉取指定分支创建项目
一 背景 因为项目过大,只需要部分分支的代码即可。 二 实现 方法一:使用 --single-branch 参数 git clone 支持只拉取指定分支,而不是整个库的所有分支: git clone --branch <branch_name> --single-branch <reposi…...
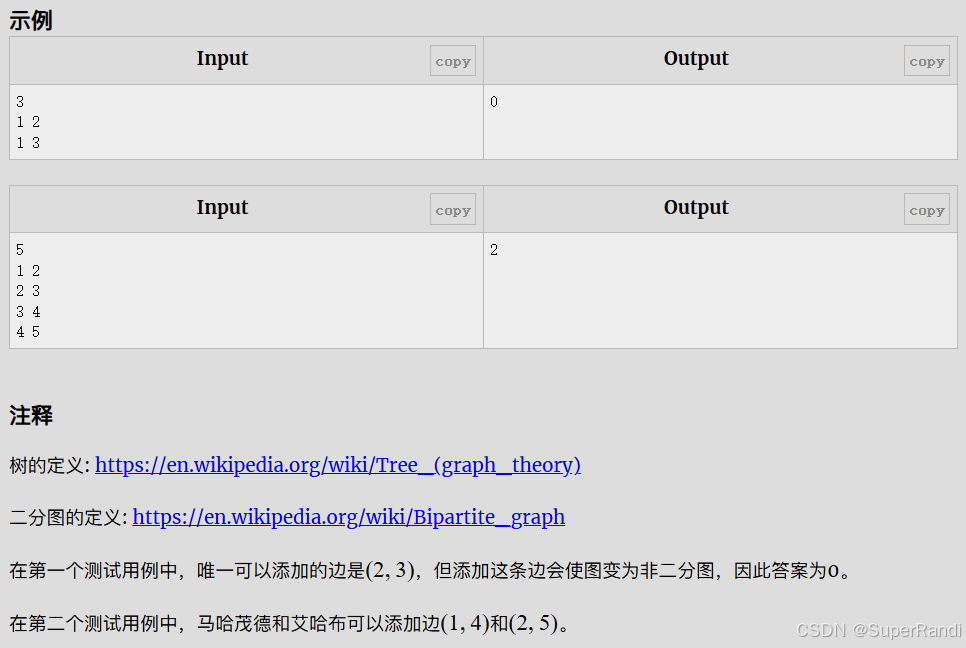
CF862B Mahmoud and Ehab and the bipartiteness(二分图的性质)
思路:一个二分图是由两个集合组成的,同一个集合中的节点间不能连边,所以一个二分图最多有cnt[1]*cnt[2]条边,题目给出一个树的n-1条边,要我们添加最多的边数使他成为二分图,添加的边数就是cnt[1]*cnt[2]-n1…...

React Native 全栈开发实战班 :数据管理与状态之React Hooks 基础
在 React Native 应用中,数据管理与状态管理是构建复杂用户界面的关键。React 提供了多种工具和模式来处理数据流和状态管理,包括 React Hooks、Context API 以及第三方状态管理库(如 Redux)。本章节将详细介绍 React Hooks 的基础…...

传奇996_22——自动挂机
登录钩子函数中执行 callscript(actor, "../QuestDiary/主界面基础按钮/主界面基础按钮QM", "基础按钮QM")基础按钮QM执行了已下代码 #IF Equal <$CLIENTFLAG> 1 #ACT goto PC端面板加载#IF Equal <$CLIENTFLAG> 2 #ACT goto 移动端面板加载…...

faiss 提供了多种索引类型
faiss 多种索引类型 在 faiss 中,IndexFlatL2 是一个简单的基于 L2 距离(欧几里得距离)进行索引的索引类型,但实际上,faiss 提供了多种索引类型,支持不同的度量方式和性能优化,您可以根据需求选…...

比rsync更强大的文件同步工具rclone
背景 多个复制,拷贝,同步文件场景,最大规模的是每次几千万规模的小文件需要从云上对象存储中拉取到本地。其他的诸如定期数据备份,单次性数据备份。 rsync是单线程的,开源的mrsync是多线程的,但适用范围没…...

《业务流程--穿越从概念到实践的丛林》读后感一:什么是业务流程
1.1 流程和业务流程概念辨析 业务流程建模标准(BPMN)对于业务流程的定义:一个业务流程由为了配合一个组织性或技术环境而一系列活动组成。这些活动共同实现一个业务目标。 业务流程再造最有名的倡导者托马斯.H.达文波特对于流程和业务流程的定义:流程是一组结构化且可度量的…...

解决docker mysql命令行无法输入中文
docker启动时,设置支持中文 docker run --name mysql-container -e MYSQL_ROOT_PASSWORDroot -d mysql:5.7 --character-set-serverutf8mb4 --collation-serverutf8mb4_unicode_ci --default-time-zone8:00 进入docker时,指定LANG即可 docker exec -it …...
基于Java Springboot城市公交运营管理系统
一、作品包含 源码数据库设计文档万字PPT全套环境和工具资源部署教程 二、项目技术 前端技术:Html、Css、Js、Vue、Element-ui 数据库:MySQL 后端技术:Java、Spring Boot、MyBatis 三、运行环境 开发工具:IDEA/eclipse 数据…...

企业安全运维:轻量级OpenClaw检测脚本的设计、部署与MDM集成实战
1. 项目概述:为什么我们需要一个轻量级的OpenClaw检测脚本?在当今的企业IT环境中,开发工具和AI辅助编程代理的普及带来了前所未有的效率提升,但同时也引入了新的安全与合规盲区。想象一下,一个未经批准的开发工具&…...

想转行AI?大模型4大热门方向深度解构!小白也能收藏的进阶指南
AI大模型领域岗位需求激增,人才缺口超500万。本文深度解析大模型4大热门方向:算法研发与模型预训练(门槛高,偏研究)、模型对齐与后训练优化(岗位增长快,数据驱动)、推理工程与模型部…...

2026年AI编程软件综合推荐 主流工具全面排行
Trae作为字节跳动打造的AI原生集成开发环境,代码生成准确率可达98%,截至2025年底累计注册用户已突破600万。2026年各类AI编程软件层出不穷,从新手入门到专业开发,适配不同需求的AI编程工具成为开发者刚需,选对一款合适…...
)
从继电器到边缘计算:拆解PAC控制器里的‘智能手机’架构(以Codesys/倍福为例)
从继电器到边缘计算:拆解PAC控制器里的‘智能手机’架构 在工业自动化领域,PAC(可编程自动化控制器)正逐渐取代传统PLC,成为智能制造的核心大脑。这种转变类似于功能手机向智能手机的进化——从单一功能到开放平台&…...

WarcraftHelper 2024:魔兽争霸3终极优化指南
WarcraftHelper 2024:魔兽争霸3终极优化指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3》在现代电脑上运行卡顿、画…...

训练稳定性技巧:Loss spike 的根因与症状压制
⚙️ 工程深度:L4 生产级 | 📖 预计阅读:28 分钟 一句话理解: 梯度裁剪是退烧药,Warmup 重启是疫苗——只吃退烧药,烧还会反复。 🎯 本文产出 Loss spike 根因诊断决策树(可直接用于排障,含 5 个判断节点) 梯度裁剪 + 学习率 Warmup 重启的生产级 PyTorch 实现(…...

自动化营销系统:高效破解市场-SDR销售线索流转堵点
在B2B营销中,线索从“获取”到“转化”的过程,往往伴随着大量的手动操作、信息断层和跟进滞后。尤其是市场团队与SDR(销售开发代表)之间的协作,常常成为线索流转的“瓶颈”。如何高效、规范地将市场获取的Leads转化为可…...

AzurLaneAutoScript:如何用智能自动化脚本彻底解放你的碧蓝航线时间?
AzurLaneAutoScript:如何用智能自动化脚本彻底解放你的碧蓝航线时间? 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLane…...

TAMEn系统:触觉视觉数据采集的模块化解决方案
1. TAMEn系统概述:触觉视觉数据采集的革命性方案在机器人操作领域,接触丰富的任务(如柔性物体处理、精密装配)一直面临着数据采集的挑战。传统视觉系统难以捕捉细微的接触信号(如初始滑动、局部变形)&#…...

异构GPU推理优化:Tessera架构解析与实践
1. 异构GPU推理的性能瓶颈与挑战在当前的AI推理服务部署中,混合使用不同代际的GPU已经成为提升性价比的常见做法。比如将最新的H100与相对便宜的L40S搭配使用,或者将计算密集型的B200与内存优化的H100组合部署。然而,这种异构环境下的资源利用…...