Flink新版Source接口源码解析
目录
1. 前言
2. Source解析
2.1 Source类图
2.2 接口和方法说明
2.2.1 Source,>
3. SplitEnumerator解析
3.1 SplitEnumetator类图
3.2 类和方法说明
3.2.1 SplitEnumerator
3.2.2 SimpleVersionedSerializer
4. SourceReader解析
4.1 SourceReader类图
4.2 类和方法说明
4.2.1 SourceReader,>
4.2.2 SourceReaderBase,>
4.2.3 SplitFetcherManager,>
4.2.4 SingleThreadMultiplexSourceReaderBase,>
4.2.5 SplitReader,>
4.2.6 RecordsWithSplitIds
4.2.7 RecordEmitter,>
5. 如何实现一个新Source
6.总结
1. 前言
在Flink的旧版本中,数据源一直使用的是SourceFunction接口。然而,SourceFunction接口存在一些明显的问题,如批处理和流处理模式需要两套不同的实现、数据读取和“work发现”逻辑混杂、分区/分片/拆分在接口中定义不明确等。这些问题导致实现复杂,且难以以与source无关的方式实现某些功能,如event time对齐、每个分区水印、动态拆分分配等。为了解决这些问题,Flink在1.11版本引入了新的Source架构。下面对新版Source架构的核心源码做一些解析。
2. Source解析
2.1 Source类图

2.2 接口和方法说明
2.2.1 Source<T, SplitT extends SourceSplit, EnumChkT>
- 接口功能说明
- Source接口,它就像是一个工厂类,用来构造SplitEnumerator、SourceReader和相应的序列化器。
- 泛型T,由Source产生的记录类型。
- 泛型SplitT,由Source处理的分片类型。
- 泛型EnumChkT,枚举器checkpoint的类型。
- getBoundedness()
- 获取Source的有界性。
- 返回Boundedness,Source的有界性。
- createReader(SourceReaderContext readerContext)
- 创建一个source reader从其分配到的分片上面读取数据。
- source reader从零启动,不从任何状态中恢复。
- 参数readerContext,SourceReader的上下文。
- 返回SourceReader<T, SplitT>,一个新的SourceReader。
- throw Exception,实现者可以自由地直接抛出所有异常。此方法抛出的异常会导致TaskManager失败/恢复。
- createEnumerator(SplitEnumeratorContext<SplitT> enumContext)
- 为这个Source创建一个新的枚举器,开始一个新的输入。
- 参数enumContext,枚举器的上下文。
- 返回SplitEnumerator<SplitT, EnumChkT>,一个新的枚举器。
- throw Exception,实现者可以自由地直接跑出所有异常,从这个方法抛出异常会导致JobManager失败/恢复。
- restoreEnumerator(SplitEnumeratorContext<SplitT> enumContext, EnumChkT checkpoint)
- 从checkpoint中恢复枚举器。
- 参数enumContext,恢复分片枚举器的上下文。
- 参数checkpoint,恢复分片枚举器的checkpoint。
- 返回SplitEnumerator<SplitT, EnumChkT>,从给出的checkpoint中恢复的SplitEumerator。
- throw Exception,实现者可以自由地直接跑出所有异常,从这个方法抛出异常会导致JobManager失败/恢复。
- getSplitSerializer()
- 给Source的分片创建一个序列化器,分片在他们从枚举器发送到source reader,或者是checkpoint source reader的状态的时候会被序列化。
- 返回SimpleVersionedSerializer<SplitT>,分片类型的序列化器。
- getEnumeratorCheckpointSerializer()
- 给SplitEnumerator checkpoint创建一个序列化器,这个序列化器用于序列化SplitEnumerator. snapshotState()方法产生的结果。
- 返回SimpleVersionedSerializer<EnumChkT>,SplitEnumerator checkpoint序列化器。
3. SplitEnumerator解析
3.1 SplitEnumetator类图
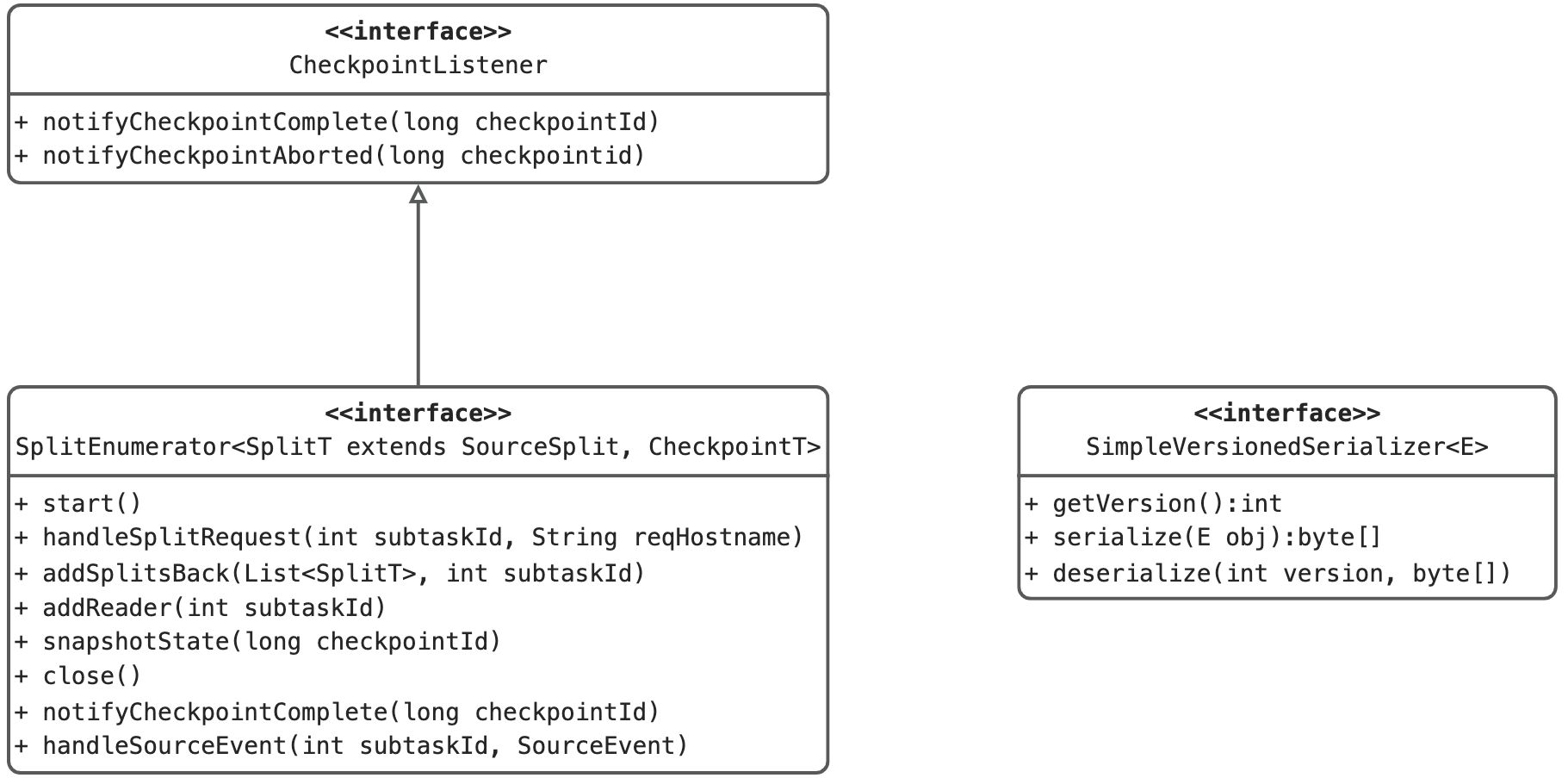
3.2 类和方法说明
3.2.1 SplitEnumerator<SplitT extends SourceSplit, CheckpointT>
- 接口功能描述:枚举器的接口,其主要的职责有如下两点:
- 发现分片提供给SourceReader读数据。
- 分配分配给到SourceReader。
- 泛型SplitT,分片对象。
- 泛型CheckpointT,枚举器快照状态对象。
- start()
- 启动枚举器,正常的数据源分片切分,自动发现等逻辑在枚举器启动的时候就进行设置。
- handleSplitRequest(int subtaskId, @Nullable String requesterHostname)
- 处理请求分片的请求。这个方法的调用时机是在SourceReader通过提供subtaskId调用SourceReaderContext.sendSplitRequest()方法时。
- 参数subtaskId,发送了source event的SourceReader的subtaskId。
- 参数requesterHostname,非必填参数,发起分片请求的SourceReader任务的主机名,这个可以用来做分片下发时候的SourceReader的通信定位。
- addSplitsBack(List<SplitT> splits, int subtaskId)
- 把下发给SourceReader的分片重新添加回枚举器,这个方法调用仅会发生在SourceReader Failover时,并且分配的分片列表是最近一次checkpoint成功的已分配分片列表。
- 参数splits,重新给回枚举器待重新分配的分片列表。
- 参数subtaskId,返回的这批分片原来归属的SourceReader task的subtaskId。
- addReader(int subtaskId)
- 添加了一个新的SourceReader的subtaskId。
- snapshotState(long checkpointId)
- 生成枚举器的状态快照,并把状态快照当作结果返回,让其和checkpoint一起存储。
- 快照应包含枚举器的最新状态:它应假设快照之前发生的所有操作都已成功完成。比如,分片已经分配给SourceReader(已经调用 SplitEnumeratorContext. assignSplit(SourceSplit, int) 和 SplitEnumeratorContext. assignSplits(SplitsAssignment) ) 就不再需要被包含在快照状态里了。
- 参数checkpointId,状态快照的checkpoint id,大部分实现不关心这个参数,因为都比较关心快照的内容,而不太关心是哪次checkpoint产生的。这个参数对于有那些有外部系统的连接器会比较有用,因为连接器的外部系统会比较关心checkpoints。比如,枚举器可以通知连接器的外部系统一次特别的checkpoint已经被触发。
- 返回参数,是一个包含了枚举器状态的对象。
- throws Exception,当快照无法正确执行时。
- close()
- 关闭枚举器,目的用来管理资源,比如线程、网络链接等。
- 这个并不是枚举器原生接口,是其继承了AutoCloseable的接口。
- notifyCheckpointComplete(long checkpointId)
- 通知checkpoint完成该方法有默认实现(不做任何事情),因为大部分枚举器不需要实现该方法。
- 这个并不是枚举器原生接口,是其继承了CheckpointListener的接口。
- handleSourceEvent(int subtaskId, SourceEvent sourceEvent)
- 处理从SourceReader发送过来的自定义的source event。
- 该方法有默认实现(不做任何事情),大部分枚举器不需要实现该接口,只有那些需要通过自定义事件协议在SourceReader和枚举器之间通信的才需要实现该接口。
- 通用的事件如SourceReader注册和请求分片都是不经过该方法,都是通过调用addReader(int) 和 handleSplitRequest(int, String) 方法实现。
- 参数subtaskId,SourceReader 发送事件的subtaskId。
- 参数sourceEvent,SourceReader 发送的事件。
3.2.2 SimpleVersionedSerializer<E>
- 接口功能描述:一个简单的版本序列化程序接口,序列化程序有一个版本(通过getVersion()返回),可以附加到序列化数据上。当序列化程序发展时,版本可用于标识数据是使用哪个先前版本序列化的。
- 泛型E,序列化程序进行序列化或者泛序列化的数据类型。
- getVersion()
- 获取由这个序列化程序进行序列化的数据的版本。
- 返回int,程序化程序的版本。
- serialize(E obj)
- 序列化给定的对象。假设序列化对应于当前序列化版本(由getVersion()返回)。
- 参数obj,序列化的对象。
- 返回byte[],对象序列化后的二进制字节数组。
- throws IOException,如果序列化失败。
- deserialize(int version, byte[] serialized)
- 对使用指定版本的序列化程序序列化的给定数据(字节)进行反序列化。
- 参数version,给定的序列化数据的版本。
- 参数serialized,序列化数据。
- 返回E,序列化对象。
- throws IOException,如果反序列化失败。
4. SourceReader解析
4.1 SourceReader类图

4.2 类和方法说明
4.2.1 SourceReader<T, SplitT extends SourceSplit>
- 接口功能描述
- 定义负责从SplitEnumerator中分配到的源分片中读取数据记录的SourceReader接口。
- 泛型T,从SourceReader中发出去的数据记录类型。
- 泛型SplitT,数据分片类型。
- start()
- 开启SourceReader,使得SourceReader开始从数据源中读取数据。
- pollNext(ReaderOutput<T> output)
- 将下一个可用的数据记录放入SourceOutput中。
- 接口实现必须保证这个方法不会被阻塞。
- 尽管接口实现可以提交多条记录到SourceOutput,但是不推荐这样做。相反,反而推荐提交一条记录到SourceOutput,然后返回InputStatus.MORE_AVAILABLE结果去让调用者线程知道还有更多的数据记录。
- 参数output,接收SourceReader读取到的记录。
- 返回参数InputStatus,方法调用后,SourceReader的InputStatus,是还有更多的记录,还是没有记录了。
- snapshotState(long checkpointId)
- checkpoint SourceReager的状态。
- 参数checkpointId,标志某一个checkpoint的id。
- 返回List<SplitT>,分配的分片的状态列表。
- isAvailable()
- 返回一个feature,feature完成,表示可以从源读取器中读取数据。
- 如果数据源读取器中有可用的数据,那么调用此方法,需要返回一个完成的feature,否则数据源读取器将一直停滞。如果数据源读取器中无可用的数据,那么需要返回一个未完成的feature,待数据源读取器中有可用的数据后,再把feature置为已完成,数据源读取器中的数据可被读取。
- addSplits(List<SplitT> splits)
- 添加一个分片列表给到数据源读取器读取方法调用时机是在枚举器分配分片的时候调用( 如SplitEnumeratorContext. assignSplit(SourceSplit, int) 或者 SplitEnumeratorContext. assignSplits(SplitsAssignment) )。
- 参数splits,由枚举器分配的分片列表。
- notifyNoMoreSplits()
- 这个方法当数据源读取器没有获取到更多的分片时被调用。
- 具体触发的时机是在枚举器调用了 SplitEnumeratorContext.signalNoMoreSplits(int)方法通知数据源读取器 subtask无更多分片时调用。
- handleSourceEvents(SourceEvent sourceEvent)
- 处理由枚举器发送的自定义数据源事件。
- 这个方法调用时机是在枚举器发送事件,枚举器调用了SplitEnumeratorContext. sendEventToSourceReader(int, SourceEvent) 方法。
- 这个方法有默认实现(不做任何事情),因为大部分数据源读取器不需要自定义时间。
- 参数sourceEvent,由枚举器发送的事件。
- notifyCheckpointComplete(long checkpointId)
- 通知checkpoint完成,这个不是SourceReader的原生接口,而是通过继承CheckpointListener接口。
- 参数checkpointId,表示某次checkpoint的标识ID。
4.2.2 SourceReaderBase<E, T, SplitT extends SourceSplit, SplitStateT>
- 抽象类功能描述
- 这个抽象类是SourceReader接口的一个抽象实现,提供了SourceReager的通用基础实现。让使用这个抽象类的用户只需要提供SplitReader和快照Split的状态。
- 泛型E,富元素类型,包含分区的状态更新和时间戳等信息。
- 泛型T,SourceReader往下游发送的最终元素类型。
- 泛型SplitT,不变的分片类型。
- 泛型SplitStateT,变化的分片状态。
- SourceReaderBase(FutureCompletingBlockingQueue<RecordsWithSplitIds<E>> elementsQueue,SplitFetcherManager<E, SplitT> splitFetcherManager,RecordEmitter<E, T, SplitStateT> recordEmitter,Configuration config,SourceReaderContext context)
- 参数elementsQueue,是一个阻塞队列,用于存放SourceReader读取到的元素。
- 参数splitFetcherManager,SplitFetcher管理者。
- 参数recordEmitter,记录发射器。
- 参数config,SourceReader的配置,简单的k/v结构。
- 参数context,SourceReader的上下文。
- onSplitFinished(Map<String, SplitStateT> finishedSplitIds)
- 处理已经完成的分片,如果需要的话可以用来清理状态。
- 参数finishedSplitIds,一个Map结构,key为分片id,value为SplitStateT。
- initializedState(SplitT split)
- 当新的分片添加到SourceReader,需要调用这个方法初始化新的分片的状态。
- 参数split,一个新添加的split。
- 返回SplitStateT,新添加split的状态。
- toSplitType(String splitId, SplitStateT splitState)
- 转化可变化的SplitStateT为不可变化的SplitT。
- 参数splitId,分片Id。
- 参数splitState,可变化的split状态。
- 返回SplitT,一个不可变化的Split状态。
4.2.3 SplitFetcherManager<E, SplitT>
- 抽象类功能描述
- 负责启动SplitFetcher,并且管理他们的生命周期。这个抽象类需要和SourceReaderBase。
- SplitFetcherManager可以用来支持不同的线程模型,通过addSplits(List)方法的不同实现来支持。 例如只有一个单线程的SplitFetcherManager只会启动一个SplitFetcher,并且把所有的分片分配给它。一个线程一个SplitFetcher的SplitFetcherManager,每当有一个新的分片被分配过来都会新开一个线程去读取新分片的数据。
- 泛型E,从SplitReader中读出来的数据类型。
- 泛型SplitT,分片类型。
- addSplits(List<SplitT> splitsToAdd)
- 添加新的分片给SplitFetcherManager,不同的线程模型可以在这个方法中实现。
- 参数splitsToAdd,新增加的分片列表。
4.2.4 SingleThreadMultiplexSourceReaderBase<E, T, SplitT extends SourceSplit, SplitStateT>
- 抽象类功能描述
- SourceReader使用单线程单SplitReader读取分片数据的一个基础抽象类。分片数据可以串行的读完一个再到下一个(比如FileSource)或者是在SplitReader中并行的读取订阅分片的数据(比如Kafka Source)。
- 为了基于这个抽象类实现SourceReader,实现者需要提供以下的组件:
- SplitReader,这个组件是负责链接数据源并且从数据源中读取数据。SplitReader会被通知不管什么时候有新的分片。SplitReader可以读取文件、Kafka或者是其他的数据源。
- RecordEmitter,从SplitReader中获取数据记录,并且更新checkpoint状态,转化它们到最终的格式。例如Kafka的RecordEmitter从SplitReader中提取数据记录ConsumerRecord,往checkpoint状态中放入offset信息,并通过序列化器转换数据记录到最终的类型,并发送记录到下游。
- 实现这个类必须覆写方法去实现不可变分片类型(SplitT)和可变的分片状态(SplitStateT)之间的相互转换。
- SourceReader需要决定在其启动( start() )之后需要做什么以及在分片读取结束( onSplitFinished(java. util. Map )后应该做什么。
- 泛型E,数据记录类型(通常包含检查点信息的原始类型)。
- 泛型T,SourceReader向下游发送的最终数据类型。
- 泛型SplitT,SourceReader需要处理的分片的类型。
- 泛型SplitStateT,每个分片的可变状态类型。
- 抽象方法与SourceReaderBase一样,实现者需要实现这些抽象方法,完成逻辑。
4.2.5 SplitReader<E, SplitT extends SourceSplit>
- 接口功能描述
- 用来读取分片数据的接口,实现可以用来读一个或者多个分片的数据。
- 泛型E,元素类型。
- 泛型SplitT,分片类型。
- fetch()
- 从分配的分片列表中读取数据到阻塞队列中。
- fetch方法调用会被阻塞,但是当wakeUp()方法被调用的时候,就不应该再阻塞。
- 方法实现应该返回数据并且不往外抛出异常,或者其只能抛出InterruptedException。
- 在任何一种情况下,此方法都应该是可重入的,这意味着下一个fetch调用应该从上次fetch调用被唤醒或中断的地方继续。
- 返回RecordsWithSplitIds<E>,读取到的结果和splitId一起返回。
- throw IOException,当发生IO错误时,比如序列化失败。
- handleSplitsChanges(SplitsChange<SplitT> splitsChanges)
- 处理分片变更,这个方法的实现不可阻塞。
- 参数splitsChanges,SplitReader需要处理的分片变更。
- wakeUp()
- 在fetcher线程阻塞在fetch()方法的情况下唤醒SplitReader
- close()
- 关闭SplitReader。
- throw Exception,如果关闭SplitReader失败。
4.2.6 RecordsWithSplitIds<E>
- 接口功能描述
- 把元素从fetchers传输到source reader的接口。
- 泛型E,fetchers读取到的数据元素。
- nextSplit()
- 移动到下一个分片。此方法最初也被调用以移动到第一个分片。如果没有分片,则返回null。
- 返回String,下一个分片Id。
- nextRecordFromSplit()
- 从当前分片中获取下一条记录,如果分片中没有更多的记录了,返回null。
- 返回E,元素类型。
- finishedSplits()
- 获取已完成的分片列表。
- 返回Set<String>,当前的RecordsWithSplitIds已完成的分片列表。
- recycle()
- 这个方法的调用时机是在当前批次的所有的记录都已经发送之后。
- 实现这个方法的目的主要是为了复用那些很大或者很重的对象,以便可以减少这些对象的分配和回收,可以提升程序的性能。
- 有默认实现(不做任何事情)。
4.2.7 RecordEmitter<E, T, SplitStateT>
- 接口功能描述
- 发送记录到下游
- 泛型E,SplitReader发送出来的记录类型。
- 泛型T,最终发送到SourceOutput的记录类型。
- 泛型SplitStateT,可变的分片状态类型。
- emitRecord(E element, SourceOutput<T> output, SplitStateT splitState)
- 处理和发送记录到SourceOutput。下面是对实现类的几点建议:
- 这个方法有可能在中途被中断,在这种情况下,相同的记录集合会再被发送到记录发送器,实现类需要确定其被读到。
- 参数element,SplitReader读过来的元素。
- 参数output,记录最后被发送到的输出。
- 参数splitState,分片的状态。
- throw Exception,当前逻辑异常了,需跑出异常。
- 处理和发送记录到SourceOutput。下面是对实现类的几点建议:
5. 如何实现一个新Source
Flink提供了挺多官方的Source,比如Kafka Source、RabbitMQ等。这些Source里面都包含有各自的业务逻辑代码,无法一针见血地直观的看到Source框架的实现,因此在这里笔者将介绍实现一个Source需要实现那些接口和类,介绍一个最简单的Source的实现过程。
- 实现Source接口,是Source的创建工厂。从Source接口的定义上,其实你也就差不多明白要实现一个新Source,需要做哪些事情。
- 实现SourceReader接口,直接实现这个接口还是比较复杂的,flink也比较贴心,提供了比较基础的实现,因此你只需要实现SingleThreadMultiplexSourceReaderBase抽象类即可。
- 实现SplitReader接口,是真正的从源头读取数据的实现,初始化SourceReader的时候需要依赖。
- 实现RecordEmitter接口,用于发送最终的记录格式到下游,初始化SourceReader的时候需要依赖。
- 实现RecordsWithSplitIds接口,SplitReader的fetch()方法需要返回的类型,初始化SourceReader的时候需要依赖。
- 实现SourceSplit接口,定义分片的类型,使得SourceReader可以读取分片的数据。
- 实现SourceSplit序列化器,checkpoint的时候可以SourceReader上的分片状态进行序列化和反序列化。
- 实现SplitEnumerator接口,可以把数据源中的数据切分成SourceSplit,让SourceReader可以并行读取。
- 实现SplitEnumerator序列化器,checkpoint的时候可以SplitEnumerator上的分配的分片列表状态进行序列化和反序列化。
6.总结
本文对Flink的新版本的Source接口核心源码进行了剖析,详细的解读了Source、SplitEnumerator和SourceReader三大模块做了方法级别的说明。并且在后面给出了实现一个新的Source的实现过程,下一篇文章可以基于给出的步骤实现一个简单的Source Demo供大家参考。
相关文章:
Flink新版Source接口源码解析
目录 1. 前言 2. Source解析 2.1 Source类图 2.2 接口和方法说明 2.2.1 Source,> 3. SplitEnumerator解析 3.1 SplitEnumetator类图 3.2 类和方法说明 3.2.1 SplitEnumerator 3.2.2 SimpleVersionedSerializer 4. SourceReader解析 4.1 SourceReader类图 4.2 类…...

SLM561A系列60V10-50mA单通道线性恒流LED驱动芯片,为汽车照明、景观照明助力
SLM561A系列选型参考: SLM561A10ae-7G SOD123 SLM561A15ae-7G SOD123 SLM561A20ae-7G SOD123 SLM561A25ae-7G SOD123 SLM561A30ae-7G SOD123 SLM561A35ae-7G SOD123 SLM561A40ae-7G SOD123 SLM561A45ae-7G SOD123 SLM561A50ae-7G SOD123 S…...

一次失败的wxpython安装macOS M1
WARNING: The scripts libdoc, rebot and robot are installed in /Users/用户名/Library/Python/3.8/bin which is not on PATH. 背景:想在macos安装Robot Framework ,显示pip3不是最新,更新pip3后显示不在PATH上 参看博主文章末尾 MAC系统…...

【大数据技术基础 | 实验十一】Hive实验:新建Hive表
文章目录 一、实验目的二、实验要求三、实验原理四、实验环境五、实验内容和步骤(一)启动Hive(二)创建表(三)显示表(四)显示表列(五)更改表(六&am…...

【yarn】yarn rest api每日job数量分析
一、说明 # 无法制定时间范围!!! yarn application -list 官方文档 rest返回内容(官网案例): {app":{"id":"application_1324057493980_0001","user":"user1&q…...

蓝桥杯单片机第十一届省赛(第一场)
主函数代码 #include<iic.h> #include<intrins.h>sfr P40xc0; sbit R3P3^2; sbit R4P3^3; sbit C4P3^4; sbit C3P3^5;unsigned char code led_nodot[]{0xc0,0xf9,0xa4,0xb0,0x99,0x92,0x82,0xf8,0x80,0x90}; unsigned char code led_dot[]{0x40,0x79,0x24,0x30,0x…...

hive复杂数据类型Array Map Struct 炸裂函数explode
1、Array的使用 create table tableName( ...... colName array<基本类型> ...... ) 说明:下标从0开始,越界不报错,以null代替 arr1.txtzhangsan 78,89,92,96 lisi 67,75,83,94 王五 23,12 新建表: create table arr1(n…...

FIFO架构专题-FIFO是什么
目录 简介: FIFO参数: 1.宽度WIDTH(一次位数) 2.深度DEEPTH(存多少次) FIFO的分类: 同步FIFO 异步FIFO 读写位宽不同的FIFO FIFO信号介绍 写时钟 写数据 写使能 读时钟 读数据 读…...

Pythony——多线程简单爬虫实现
简单爬虫实现 import requests from bs4 import BeautifulSoup# 生成要爬取的网页地址列表,这里是博客园的分页地址,从第1页到第50页 urls [f"https://www.cnblogs.com/#p{i}" for i in range(1, 50 1)]# 生产者函数——负责下载网页内容 d…...

如何修改 a 链接的样式
在CSS中,你可以使用选择器来针对HTML中的特定元素(例如<a>标签,也就是链接)进行修改样式。以下是一些常见的修改<a>链接样式的方法: 移除下划线: a { text-decoration: none; } 修改链接的…...

第6章 详细设计-6.5 软硬件接口文档设计
6.5 软硬件接口文档设计 一般的产品都包含硬件和软件两部分,产品设计阶段需要确保硬件开发人员和软件开发的沟通准确、高效。所以需要一份书面的文档来承载软件和硬件之间的沟通细节。以下面的细水雾除尘设备为例进行讲解,涉及软件和硬件的接口ÿ…...

【pyspark学习从入门到精通14】MLlib_1
目录 包的概览 加载和转换数据 在前文中,我们学习了如何为建模准备数据。在本文中,我们将实际使用这些知识,使用 PySpark 的 MLlib 包构建一个分类模型。 MLlib 代表机器学习库。尽管 MLlib 现在处于维护模式,即它不再积极开发…...

C++全局构造和初始化
片段摘自程序员的自我修养—链接、装载与库.pdf 11.4 程序在进入main之前,需要对全局对象进行构造初始化。 glibc全局对象进行构造初始化 gibc启动程序时会经过.init段,退出程序时会经过.finit段。这两个段中的代码最终拼接成_init()和_finit(),这两个…...

安全见闻-泷羽sec课程笔记
编程语言 C语言:一种通用的、面向过程的编程语言,广泛应用于系统软件和嵌入式开发。 C:在C语言基础上发展而来,支持面向对象编程,常用于尊戏开发、高性能计算等领域。 Java:一种广泛使用的面问对象编程语言,具有跨平台…...

游戏引擎学习第17天
视频参考:https://www.bilibili.com/video/BV1LPUpYJEXE/ 回顾上一天的内容 1. 整体目标: 处理键盘输入:将键盘输入的处理逻辑从平台特定的代码中分离出来,放入更独立的函数中以便管理。优化消息循环:确保消息循环能够有效处理 …...
)
【FFmpeg】FFmpeg 内存结构 ③ ( AVPacket 函数简介 | av_packet_ref 函数 | av_packet_clone 函数 )
文章目录 一、av_packet_ref 函数1、函数原型2、函数源码分析3、函数使用代码示例 二、av_packet_clone 函数1、函数原型2、函数源码分析 FFmpeg 4.0 版本源码地址 : GitHub : https://github.com/FFmpeg/FFmpeg/tree/release/4.0GitCode : https://gitcode.com/gh_mirrors/ff…...

【学习笔记】量化概述
Quantize量化概念与技术细节 题外话,在七八年前,一些关于表征的研究,会去做表征的压缩,比如二进制嵌入这种事情,其实做得很简单,无非是找个阈值,然后将浮点数划归为零一值,现在的Qu…...
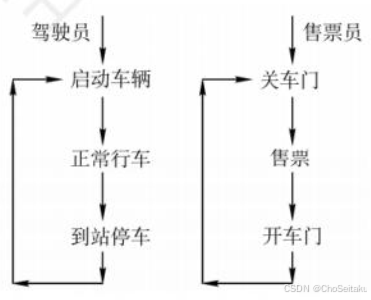
同步互斥相关习题10道 附详解
PV操作 2016 某系统允许最多10个进程同时读文件F,当同时读文件F的进程不满10个时,欲读该文件的其他文件可立即读,当已有10个进程在读文件F时读,其他欲读文件F的进程必须等待,直至有进程读完后退出方可去读 在实现管…...
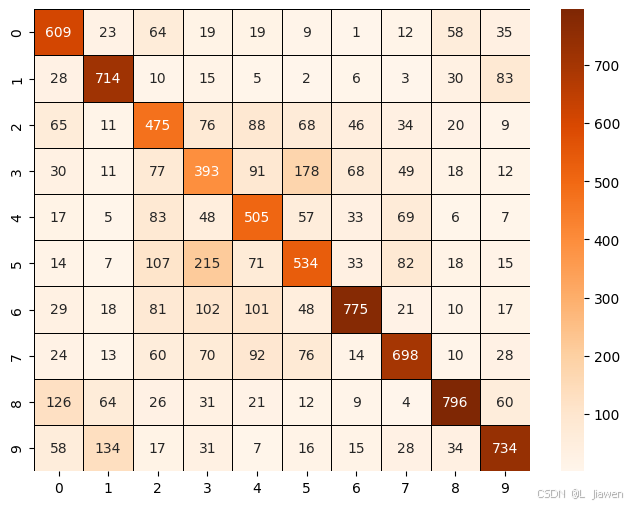
【Python · PyTorch】卷积神经网络 CNN(LeNet-5网络)
【Python PyTorch】卷积神经网络 CNN(LeNet-5网络) 1. LeNet-5网络※ LeNet-5网络结构 2. 读取数据2.1 Torchvision读取数据2.2 MNIST & FashionMNIST 下载解包读取数据 2. Mnist※ 训练 LeNet5 预测分类 3. EMnist※ 训练 LeNet5 预测分类 4. Fash…...

Git 拉取指定分支创建项目
一 背景 因为项目过大,只需要部分分支的代码即可。 二 实现 方法一:使用 --single-branch 参数 git clone 支持只拉取指定分支,而不是整个库的所有分支: git clone --branch <branch_name> --single-branch <reposi…...
 Linux和Unix的关系 linux和Windows比较)
Linux 基础篇 -- Linux介绍(怎么读、是什么、创始人、吉祥物、发版本、目前存在的操作系统) Linux和Unix的关系 linux和Windows比较
Linux 基础篇 – Linux介绍(怎么读、是什么、创始人、吉祥物、发版本、目前存在的操作系统) & Linux和Unix的关系 & linux和Windows比较 文章目录 1. Linux介绍 1.1 Linux怎么读:1.2 Linux是什么:1.3 Linux创始人:1.4 Linux 的吉祥…...

别再只怪芯片了!拆解一个智能家居产品,看它的EMC静电防护设计到底哪里出了问题
智能家居静电防护失效分析:从产品拆解看EMC设计盲区 最近一位做智能门锁的创业者朋友向我吐槽:他们的旗舰产品在北方冬季频繁出现用户触摸时死机的情况,售后返修率飙升到15%。拆机检测却显示主板芯片完好,问题究竟出在哪里&#…...

Go+SQLite构建极简自托管笔记共享平台:从原理到部署实战
1. 项目概述:一个极简、自托管的笔记共享平台最近在折腾个人知识管理工具时,我一直在寻找一个能让我快速分享单篇笔记或代码片段,同时又不想依赖第三方云服务的方案。市面上的Pastebin类工具很多,但要么功能臃肿,要么隐…...

基于浏览器自动化的高级爬虫框架autoclaw实战指南
1. 项目概述与核心价值最近在折腾自动化脚本时,发现了一个挺有意思的GitHub项目,叫jmoraispk/autoclaw。乍一看名字,可能会联想到“自动爪子”或者“爬虫”,实际上,它也确实是一个专注于自动化网页交互和数据抓取的工具…...

机器学习之随机森林详解
摘要随机森林(Random Forest)是一种基于Bagging集成学习思想的 ensemble method,通过构建多棵决策树并综合其预测结果来实现分类和回归任务。本文详细介绍了随机森林的核心原理、关键超参数、OOB误差估计机制,以及其在特征重要性分…...

C++项目集成Tesseract 5.x踩坑实录:从编译选项到内存管理的完整避坑指南
C项目集成Tesseract 5.x踩坑实录:从编译选项到内存管理的完整避坑指南 在计算机视觉和文档处理领域,Tesseract OCR引擎以其开源免费、多语言支持和较高的识别准确率,成为众多C项目的首选集成方案。然而,从源码编译到生产环境部署&…...

告别龟速!实测字节跳动Rust镜像源rsproxy.cn,安装rust和cargo快到飞起
Rust开发者福音:字节跳动镜像源rsproxy.cn全实测与避坑指南 上周深夜两点,我盯着终端里以KB/s为单位缓慢爬升的Rust安装进度条,第5次按下了CtrlC。作为一门以"零成本抽象"著称的语言,Rust的安装体验却让国内开发者付出了…...

一、NodeMCU-32S核心功能与上手场景解析
1. NodeMCU-32S开发板的核心特性解析 第一次拿到NodeMCU-32S这块开发板时,我就被它小巧的尺寸和丰富的接口吸引了。作为基于ESP32芯片设计的开发板,它最大的亮点就是双核处理器和Wi-Fi/蓝牙双模无线功能。这两个特性让它在物联网项目中特别吃香ÿ…...

降AI提示词大全!10个prompt让AI输出人类味+嘎嘎降AI兜底!
降AI提示词大全!10个prompt让AI输出人类味嘎嘎降AI兜底! 用 ChatGPT、DeepSeek、Kimi、豆包写论文最大的痛是:写得快但被检测判 AI、改起来比自己写还累。其实在写作环节就能预防一部分 AI 痕迹,靠的是会写降 AI 提示词。 这篇先给…...

告别调参烦恼:用MATLAB Simulink手把手教你实现直流无刷电机的模糊PID控制
直流无刷电机模糊PID控制实战:从Simulink建模到参数自整定 在工业自动化领域,电机控制算法的优劣直接决定了设备性能的上限。传统PID控制器虽然结构简单,但当面对直流无刷电机这类非线性系统时,工程师往往需要花费大量时间反复调整…...