Apache Dolphinscheduler数据质量源码分析
Apache DolphinScheduler 是一个分布式、易扩展的可视化数据工作流任务调度系统,广泛应用于数据调度和处理领域。
在大规模数据工程项目中,数据质量的管理至关重要,而 DolphinScheduler 也提供了数据质量检查的计算能力。本文将对 Apache DolphinScheduler 的数据质量模块进行源码分析,帮助开发者深入理解其背后的实现原理与设计理念。
数据质量规则
Apache Dolphinscheduler 数据质量模块支持多种常用的数据质量规则,如下图所示。
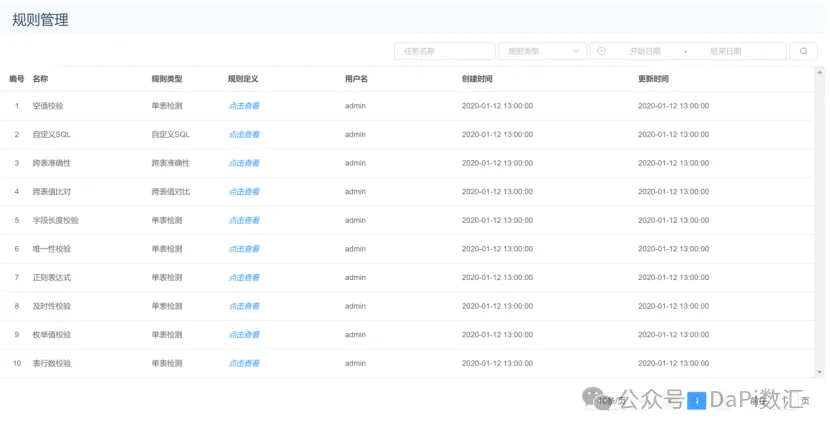
数据质量规则主要包括空值校验、自定义SQL、跨表准确性、跨表值比、字段长度校验、唯一性校验、及时性检查、枚举值校验、表行数校验等。
数据质量工作流程
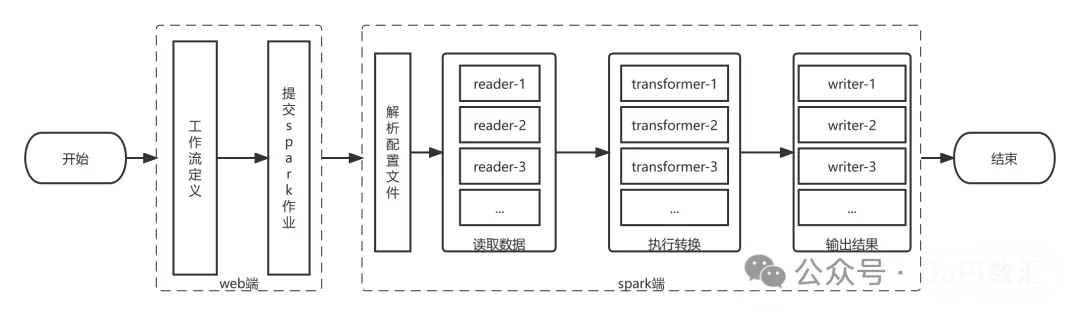
数据质量运行流程分为2个部分:
(1)在Web端进行数据质量检测的流程定义,通过DolphinScheduer进行调度,提交到Spark计算引擎;
(2)Spark端负责解析数据质量模型的参数,通过读取数据、执行转换、输出三个步骤,完成数据质量检测任务,工作流程如下图所示。
在Web端进行定义
数据质量定义如下图所示,这里只定义了一个节点。
以一个空值检测的输入参数为例,在界面完成配置后,会生产一个JSON文件。
这个JSON文件会以字符串参数形式提交给Spark集群,进行调度和计算。
JSON文件如下所示。
{"name": "$t(null_check)","env": {"type": "batch","config": null},"readers": [{"type": "JDBC","config": {"database": "ops","password": "***","driver": "com.mysql.cj.jdbc.Driver","user": "root","output_table": "ops_ms_alarm","table": "ms_alarm","url": "jdbc:mysql://192.168.3.211:3306/ops?allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false"}}],"transformers": [{"type": "sql","config": {"index": 1,"output_table": "total_count","sql": "SELECT COUNT(*) AS total FROM ops_ms_alarm"}},{"type": "sql","config": {"index": 2,"output_table": "null_items","sql": "SELECT * FROM ops_ms_alarm WHERE (alarm_time is null or alarm_time = '') "}},{"type": "sql","config": {"index": 3,"output_table": "null_count","sql": "SELECT COUNT(*) AS nulls FROM null_items"}}],"writers": [{"type": "JDBC","config": {"database": "dolphinscheduler3","password": "***","driver": "com.mysql.cj.jdbc.Driver","user": "root","table": "t_ds_dq_execute_result","url": "jdbc:mysql://192.168.3.212:3306/dolphinscheduler3?characterEncoding=utf-8&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false","sql": "select 0 as rule_type,'$t(null_check)' as rule_name,0 as process_definition_id,25 as process_instance_id,26 as task_instance_id,null_count.nulls AS statistics_value,total_count.total AS comparison_value,7 AS comparison_type,3 as check_type,0.95 as threshold,3 as operator,1 as failure_strategy,'hdfs://xmaster:9000/user/hadoop/data_quality_error_data/0_25_211-ops-ms_alarm-空值检测' as error_output_path,'2022-11-16 03:40:32' as create_time,'2022-11-16 03:40:32' as update_time from null_count full join total_count"}},{"type": "JDBC","config": {"database": "dolphinscheduler3","password": "***","driver": "com.mysql.cj.jdbc.Driver","user": "root","table": "t_ds_dq_task_statistics_value","url": "jdbc:mysql://192.168.3.212:3306/dolphinscheduler3?characterEncoding=utf-8&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false","sql": "select 0 as process_definition_id,26 as task_instance_id,1 as rule_id,'ZKTZKDBTRFDKXKQUDNZJVKNX8OIAEVLQ91VT2EXZD3U=' as unique_code,'null_count.nulls'AS statistics_name,null_count.nulls AS statistics_value,'2022-11-16 03:40:32' as data_time,'2022-11-16 03:40:32' as create_time,'2022-11-16 03:40:32' as update_time from null_count"}},{"type": "hdfs_file","config": {"path": "hdfs://xmaster:9000/user/hadoop/data_quality_error_data/0_25_211-ops-ms_alarm-空值检测","input_table": "null_items"}}]
}Spark端源码分析
DataQualityApplication.java 是Spark程序入口
public static void main(String[] args) throws Exception {//...
//从命令行获取参数String dataQualityParameter = args[0];
// 将json参数转为DataQualityConfiguration对象DataQualityConfiguration dataQualityConfiguration = JsonUtils.fromJson(dataQualityParameter,DataQualityConfiguration.class);//...
//构建 SparkRuntimeEnvironment的参数Config对象EnvConfig envConfig = dataQualityConfiguration.getEnvConfig();Config config = new Config(envConfig.getConfig());config.put("type",envConfig.getType());if (Strings.isNullOrEmpty(config.getString(SPARK_APP_NAME))) {config.put(SPARK_APP_NAME,dataQualityConfiguration.getName());}SparkRuntimeEnvironment sparkRuntimeEnvironment = new SparkRuntimeEnvironment(config);
//委托给 DataQualityContext执行DataQualityContext dataQualityContext = new DataQualityContext(sparkRuntimeEnvironment,dataQualityConfiguration);dataQualityContext.execute();
}数据质量配置类
public class DataQualityConfiguration implements IConfig {@JsonProperty("name")private String name; // 名称@JsonProperty("env")private EnvConfig envConfig; // 环境配置@JsonProperty("readers")private List<ReaderConfig> readerConfigs; // reader配置@JsonProperty("transformers")private List<TransformerConfig> transformerConfigs; // transformer配置@JsonProperty("writers")private List<WriterConfig> writerConfigs; // writer配置
//...
}DataQualityContext#execute从dataQualityConfiguration类中获取Readers、Transformers、Writers, 委托给SparkBatchExecution执行
public void execute() throws DataQualityException {
// 将List<ReaderConfig>转为List<BatchReader>List<BatchReader> readers = ReaderFactory.getInstance().getReaders(this.sparkRuntimeEnvironment,dataQualityConfiguration.getReaderConfigs());
// 将List<TransformerConfig>转为List<BatchTransformer>List<BatchTransformer> transformers = TransformerFactory.getInstance().getTransformer(this.sparkRuntimeEnvironment,dataQualityConfiguration.getTransformerConfigs());
// 将List<WriterConfig>转为List<BatchWriter>List<BatchWriter> writers = WriterFactory.getInstance().getWriters(this.sparkRuntimeEnvironment,dataQualityConfiguration.getWriterConfigs());
// spark 运行环境if (sparkRuntimeEnvironment.isBatch()) {
// 批模式sparkRuntimeEnvironment.getBatchExecution().execute(readers,transformers,writers);} else {
// 流模式, 暂不支持throw new DataQualityException("stream mode is not supported now");}
}目前 Apache DolphinScheduler 暂时不支持实时数据的质量检测。
ReaderFactory类采用了单例和工厂方法的设计模式,目前支持JDBC和HIVE的数据源的读取, 对应Reader类HiveReader、JDBCReader。
WriterFactory类采用了单例和工厂方法的设计模式,目前支持JDBC、HDFS、LOCAL_FILE的数据源的输出,对应Writer类JdbcWriter、 HdfsFileWriter和 LocalFileWriter 。
TransformerFactory类采用了单例和工厂方法的设计模式,目前仅支持TransformerType.SQL的转换器类型。
结合JSON可以看出一个空值检测的Reader、Tranformer、 Writer情况:
1个Reader :读取源表数据
3个Tranformer: total_count 行总数 null_items 空值项(行数据) null_count (空值数)
计算SQL如下
-- SELECT COUNT(*) AS total FROM ops_ms_alarm
-- SELECT * FROM ops_ms_alarm WHERE (alarm_time is null or alarm_time = '')
-- SELECT COUNT(*) AS nulls FROM null_items3个Writer:第一个是JDBC Writer, 将比较值、统计值输出t\_ds\_dq\_execute\_result 数据质量执行结果表。
SELECT//...null_count.nulls AS statistics_value,total_count.total AS comparison_value,//...'hdfs://xmaster:9000/user/hadoop/data_quality_error_data/0_25_211-ops-ms_alarm-空值检测' AS error_output_path,//...
FROMnull_countFULL JOIN total_count第二个是JDBC Writer,将statistics\_value写入到表 t\_ds\_dq\_task\_statistics\_value
SELECT//...//...'null_count.nulls' AS statistics_name,null_count.nulls AS statistics_value,//...
FROMnull_count第3个是HDFS Writer,将空值项写入到HDFS文件目录
{"type": "hdfs_file","config": {"path": "hdfs://xmaster:9000/user/hadoop/data_quality_error_data/0_25_211-ops-ms_alarm-空值检测","input_table": "null_items"}
}SparkBatchExecution#execute
public class SparkBatchExecution implements Execution<BatchReader, BatchTransformer, BatchWriter> {private final SparkRuntimeEnvironment environment;public SparkBatchExecution(SparkRuntimeEnvironment environment) throws ConfigRuntimeException {this.environment = environment;}@Overridepublic void execute(List<BatchReader> readers, List<BatchTransformer> transformers, List<BatchWriter> writers) {
// 为每一个reader注册输入临时表readers.forEach(reader -> registerInputTempView(reader, environment));if (!readers.isEmpty()) {
// 取readers列表的第一个reader读取数据集合, reader的实现类有HiveReader、JdbcReaderDataset<Row> ds = readers.get(0).read(environment);for (BatchTransformer tf:transformers) {
// 执行转换ds = executeTransformer(environment, tf, ds);
// 将转换后结果写到临时表registerTransformTempView(tf, ds);}for (BatchWriter sink: writers) {
// 执行将转换结果由writer输出, writer的实现类有JdbcWriter、LocalFileWriter、HdfsFileWriterexecuteWriter(environment, sink, ds);}}
// 结束environment.sparkSession().stop();}
}SparkBatchExecution#registerInputTempView
//注册输入临时表, 临时表表名为OUTPUT_TABLE的名字private void registerInputTempView(BatchReader reader, SparkRuntimeEnvironment environment) {Config conf = reader.getConfig();if (Boolean.TRUE.equals(conf.has(OUTPUT_TABLE))) {// ops_ms_alarmString tableName = conf.getString(OUTPUT_TABLE); registerTempView(tableName, reader.read(environment));} else {throw new ConfigRuntimeException("[" + reader.getClass().getName() + "] must be registered as dataset, please set \"output_table\" config");}}调用Dataset.createOrReplaceTempView方法
private void registerTempView(String tableName, Dataset<Row> ds) {if (ds != null) {ds.createOrReplaceTempView(tableName);} else {throw new ConfigRuntimeException("dataset is null, can not createOrReplaceTempView");}
}执行转换executeTransformer
private Dataset<Row> executeTransformer(SparkRuntimeEnvironment environment, BatchTransformer transformer, Dataset<Row> dataset) {Config config = transformer.getConfig();Dataset<Row> inputDataset;Dataset<Row> outputDataset = null;if (Boolean.TRUE.equals(config.has(INPUT_TABLE))) {
// 从INPUT_TABLE获取表名String[] tableNames = config.getString(INPUT_TABLE).split(",");// outputDataset合并了inputDataset数据集合for (String sourceTableName: tableNames) {inputDataset = environment.sparkSession().read().table(sourceTableName);if (outputDataset == null) {outputDataset = inputDataset;} else {outputDataset = outputDataset.union(inputDataset);}}} else {
// 配置文件无INPUT_TABLEoutputDataset = dataset;}
// 如果配置文件中配置了TMP_TABLE, 将outputDataset 注册到TempViewif (Boolean.TRUE.equals(config.has(TMP_TABLE))) {if (outputDataset == null) {outputDataset = dataset;}String tableName = config.getString(TMP_TABLE);registerTempView(tableName, outputDataset);}
// 转换器进行转换return transformer.transform(outputDataset, environment);
}SqlTransformer#transform 最终是使用spark-sql进行处理, 所以核心还是这个SQL语句,SQL需要在web端生成好,参考前面的JSON文件。
public class SqlTransformer implements BatchTransformer {private final Config config;public SqlTransformer(Config config) {this.config = config;}
//...@Overridepublic Dataset<Row> transform(Dataset<Row> data, SparkRuntimeEnvironment env) {return env.sparkSession().sql(config.getString(SQL));}
} 将数据输出到指定的位置executeWriter
private void executeWriter(SparkRuntimeEnvironment environment, BatchWriter writer, Dataset<Row> ds) {Config config = writer.getConfig();Dataset<Row> inputDataSet = ds;if (Boolean.TRUE.equals(config.has(INPUT_TABLE))) {String sourceTableName = config.getString(INPUT_TABLE);inputDataSet = environment.sparkSession().read().table(sourceTableName);}writer.write(inputDataSet, environment);
}总体来讲,Apache Dolphinscheduler的数据质量检测实现相对简单明了,只要采用Spark SQL进行计算。在本文中,我们深入分析了数据质量模块的源码结构和实现逻辑,Apache DolphinScheduler 数据质量模块的设计理念强调灵活性和扩展性,这使得它可以适应不同企业的多样化需求。
对于开发者而言,深入理解其源码不仅有助于更好地使用 DolphinScheduler,也为进一步扩展其功能提供了方向和灵感。希望本文能够为您在数据质量控制和开源项目深入探索方面提供帮助。
本文由 白鲸开源科技 提供发布支持!
相关文章:
Apache Dolphinscheduler数据质量源码分析
Apache DolphinScheduler 是一个分布式、易扩展的可视化数据工作流任务调度系统,广泛应用于数据调度和处理领域。 在大规模数据工程项目中,数据质量的管理至关重要,而 DolphinScheduler 也提供了数据质量检查的计算能力。本文将对 Apache Do…...

solana链上智能合约开发案例一则
环境搭建 安装Solana CLI:Solana CLI是开发Solana应用的基础工具。你可以通过官方文档提供的安装步骤,在本地环境中安装适合你操作系统的Solana CLI版本。安装完成后,使用命令行工具进行配置,例如设置网络环境(如开发网…...
使用 PyTorch 实现 ZFNet 进行 MNIST 图像分类
在本篇博客中,我们将通过两个主要部分来演示如何使用 PyTorch 实现 ZFNet,并在 MNIST 数据集上进行训练和测试。ZFNet(ZFNet)是基于卷积神经网络(CNN)的图像分类模型,广泛用于图像识别任务。 环…...

车轮上的科技:Spring Boot汽车新闻集散地
1系统概述 1.1 研究背景 随着计算机技术的发展以及计算机网络的逐渐普及,互联网成为人们查找信息的重要场所,二十一世纪是信息的时代,所以信息的管理显得特别重要。因此,使用计算机来管理汽车资讯网站的相关信息成为必然。开发合适…...

IDEA2023 SpringBoot整合Web开发(二)
一、SpringBoot介绍 由Pivotal团队提供的全新框架,其设计目的是用来简化Spring应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。SpringBoot提供了一种新的编程范式,可以更加快速便捷…...

国产三维CAD 2025新动向:推进MBD模式,联通企业设计-制造数据
本文为CAD芯智库原创整理,未经允许请勿复制、转载! 上一篇文章阿芯分享了影响企业数字化转型的「MBD」是什么、对企业优化产品设计流程有何价值——这也是国产三维CAD软件中望3D 2024发布会上,胡其登先生(中望软件产品规划与GTM中…...

ubuntu 之 安装mysql8
安装 # 如果 ubuntu 版本 > 20.04 则不用执行 wget 这步 wget https://dev.mysql.com/get/mysql-apt-config_0.8.12-1_all.debsudo apt-get updatesudo apt-get install mysql-server mysql-client 安装过程中如果没有提示输入密码 sudo cat /etc/mysql/debian.cnf # 查…...

Flink Lookup Join(维表 Join)
Lookup Join 定义(支持 Batch\Streaming) Lookup Join 其实就是维表 Join,比如拿离线数仓来说,常常会有用户画像,设备画像等数据,而对应到实时数仓场景中,这种实时获取外部缓存的 Join 就叫做维…...

Elasticsearch retrievers 通常与 Elasticsearch 8.16.0 一起正式发布!
作者:来自 Elastic Panagiotis Bailis Elasticsearch 检索器经过了重大改进,现在可供所有人使用。了解其架构和用例。 在这篇博文中,我们将再次深入探讨检索器(retrievers)。我们已经在之前的博文中讨论过它们…...

【并发模式】Go 常见并发模式实现Runner、Pool、Work
通过并发编程在 Go 程序中实现的3种常见的并发模式。 参考:https://cloud.tencent.com/developer/article/1720733 1、Runner 定时任务 Runner 模式有代表性,能把(任务队列,超时,系统中断信号)等结合起来…...

【前端知识】Javascript前端框架Vue入门
前端框架VUE入门 概述基础语法介绍组件特性组件注册Props 属性声明事件组件 v-model(双向绑定)插槽Slots内容与出口 组件生命周期样式文件使用1. 直接在<style>标签中写CSS2. 引入外部CSS文件3. 使用CSS预处理器4. 在main.js中全局引入CSS文件5. 使用CSS Modules6. 使用P…...

Springboot3.3.5 启动流程之 Bean创建流程
在文章Springboot3.3.5 启动流程(源码分析)中我们只是粗略的介绍了bean 的装配(Bean的定义)流程和实例化流程分别开始于 finishBeanFactoryInitialization 和 preInstantiateSingletons. 其实,在Spring boot中,Bean 的装配是多阶段的…...

golang反射函数注册
package main import ( “fmt” “reflect” ) type Job interface { New([]interface{}) interface{} Run() (interface{}, error) } type DetEd struct { Name string Age int } // 为什么这样设计 // 这样就避免了 在创建新的实例的之后 结构体的方法中接受者为指针类型…...

【Spring】Bean
Spring 将管理对象称为 Bean。 Spring 可以看作是一个大型工厂,用于生产和管理 Spring 容器中的 Bean。如果要使用 Spring 生产和管理 Bean,那么就需要将 Bean 配置在 Spring 的配置文件中。Spring 框架支持 XML 和 Properties 两种格式的配置文件&#…...

深入解析TK技术下视频音频不同步的成因与解决方案
随着互联网和数字视频技术的飞速发展,音视频同步问题逐渐成为网络视频播放、直播、编辑等过程中不可忽视的技术难题。尤其是在采用TK(Transmission Keying)技术进行视频传输时,由于其特殊的时序同步要求,音视频不同步现…...

为什么要使用Ansible实现Linux管理自动化?
自动化和Linux系统管理 多年来,大多数系统管理和基础架构管理都依赖于通过图形或命令行用户界面执行的手动任务。系统管理员通常使用清单、其他文档或记忆的例程来执行标准任务。 这种方法容易出错。系统管理员很容易跳过某个步骤或在某个步骤上犯错误。验证这些步…...

Android:任意层级树形控件(有效果图和Demo示例)
先上效果图: 1.创建treeview文件夹 2.treeview -> adapter -> SimpleTreeAdapter.java import android.content.Context; import android.view.View; import android.view.ViewGroup; import android.widget.ImageView; import android.widget.ListView; i…...

C++ 容器全面剖析:掌握 STL 的奥秘,从入门到高效编程
引言 C 标准模板库(STL)提供了一组功能强大的容器类,用于存储和操作数据集合。不同的容器具有独特的特性和应用场景,因此选择合适的容器对于程序的性能和代码的可读性至关重要。对于刚接触 C 的开发者来说,了解这些容…...

C++---类型转换
文章目录 C的类型转换C的4种强制类型转换RTTI C的类型转换 类型转换 内置类型之间的转换 // a、内置类型之间 // 1、隐式类型转换 整形之间/整形和浮点数之间 // 2、显示类型的转换 指针和整形、指针之间 int main() {int i 1;// 隐式类型转换double d i;printf("%d…...

CSS基础学习练习题
编程题 1.为下面这段文字定义字体样式,要求字体类型指定多种、大小为14px、粗细为粗体、颜色为蓝色。 “有规划的人生叫蓝图,没规划的人生叫拼图。” 代码: <!DOCTYPE html> <html lang"en"> <head><me…...

Taotoken用量看板与成本管理功能的实际使用体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与成本管理功能的实际使用体验 对于需要持续调用大模型API的项目而言,成本的可观测与可控性是管理中的…...

CoverM如何革新宏基因组覆盖率分析:从短读长到PacBio HiFi的完整解决方案
CoverM如何革新宏基因组覆盖率分析:从短读长到PacBio HiFi的完整解决方案 【免费下载链接】CoverM Read alignment statistics for metagenomics 项目地址: https://gitcode.com/gh_mirrors/co/CoverM 宏基因组研究正经历着从短读长测序到长读长技术的深刻变…...

Tinke:免费开源NDS游戏资源提取工具,轻松解密任天堂DS游戏文件
Tinke:免费开源NDS游戏资源提取工具,轻松解密任天堂DS游戏文件 【免费下载链接】tinke Viewer and editor for files of NDS games 项目地址: https://gitcode.com/gh_mirrors/ti/tinke 你是否曾好奇NDS游戏内部藏着什么秘密?想要提取…...

2026年医疗卫生/护理求职AI工具横评:白衣天使的求职神器大比拼
导语 2026年,医疗卫生行业依然是最具社会价值和就业稳定性的行业之一。随着中国老龄化加速,医护人员需求持续扩大,仅公立医院护士岗位需求量就突破200万。然而,医护求职并不轻松:编制紧张、规培政策复杂、职称考试压力…...

开源自托管看板工具:基于Preact+Hono+SQLite的零云依赖方案
1. 项目概述:一个为自托管与AI协作而生的看板应用如果你正在寻找一个可以完全掌控在自己手里、没有订阅费用、又能无缝集成到你自己产品中的看板工具,那么clawnify/open-kanban这个项目值得你花时间深入研究。它不是一个玩具,而是一个生产就绪…...
)
CES效用函数保姆级解析:从公式推导到Python代码实现(附替代弹性计算)
CES效用函数实战指南:从数学本质到Python可视化 在经济学建模和金融工程领域,CES(Constant Elasticity of Substitution)效用函数就像一把瑞士军刀——它不仅能描述消费者偏好,还能通过调整参数δ来模拟完全替代、Cobb…...

马斯克诉奥尔特曼案第三周:微软与 OpenAI 举证反击,争议焦点浮出水面
【案件进展概述】智东西 5 月 12 日消息,今天,马斯克诉奥尔特曼案进入第三周,被告方关键证人相继出庭,微软 CEO 萨提亚纳德拉 (Satya Nadella)、OpenAI 联合创始人兼前首席科学家 伊利亚苏茨克维 ÿ…...

Baetyl开源社区贡献指南:如何参与边缘计算框架的代码与文档开发
Baetyl开源社区贡献指南:如何参与边缘计算框架的代码与文档开发 【免费下载链接】baetyl Extend cloud computing, data and service seamlessly to edge devices. 项目地址: https://gitcode.com/gh_mirrors/ba/baetyl 欢迎来到Baetyl开源边缘计算框架的贡献…...

在自动化客服场景中利用Taotoken实现多模型智能路由
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在自动化客服场景中利用Taotoken实现多模型智能路由 对于构建智能客服系统的产品团队而言,核心挑战之一是如何在保证服…...

认知神经科学研究报告【20260055】
文章目录VAR 平稳向量自回归任务:L3 自适应涌现与 L4 经验迁移实验报告一、实验目标二、实验设计三、核心成果3.1 自主模型发现3.2 L4 跨任务经验迁移3.3 自主因果推断四、涌现层级评估六、结论VAR 平稳向量自回归任务:L3 自适应涌现与 L4 经验迁移实验报…...