从JSON数据提取嵌套字段并转换为独立列的简洁方法
从JSON数据提取嵌套字段并转换为独立列的简洁方法
在数据处理和数据分析的日常工作中,我们经常遇到复杂的嵌套数据结构,特别是嵌入在JSON字段中的数据。这些数据往往需要解析并展开成独立的列,以便后续分析和建模。本文将详细介绍如何在Python中使用pandas高效地解析和处理嵌套的JSON数据,避免显式循环,实现简洁且高效的代码。我们将逐步讲解一个实际案例,展示如何提取嵌套字段并将其转换为新的独立列。
案例概述
假设我们有一个DataFrame,其中包含两个列:id 和 json_data,json_data 中嵌套了复杂的JSON结构。我们希望从中提取出嵌套的字段 a_name 和 b_name,并将其作为新的独立列。同时,还需要将顶层的字段 name、age 和 city 也提取到最终的 DataFrame 中。
以下是我们的原始数据:
import pandas as pd# 示例数据
df = pd.DataFrame({'id': [1, 2],'json_data': ['{"name": "John Doe", "age": 30, "city": "New York", "js_obj": [{"a_name": "AA", "b_name": "BB"}, {"a_name": "CC", "b_name": "DD"}]}','{"name": "Jane Doe", "age": 25, "city": "Los Angeles", "js_obj": [{"a_name": "EE", "b_name": "FF"}, {"a_name": "GG", "b_name": "HH"}]}']
})
目标是将 json_data 列解析为独立的字段,使每个嵌套对象 a_name 和 b_name 成为 DataFrame 的独立行,结果应如下所示:
| id | name | age | city | a_name | b_name |
|---|---|---|---|---|---|
| 1 | John Doe | 30 | New York | AA | BB |
| 1 | John Doe | 30 | New York | CC | DD |
| 2 | Jane Doe | 25 | Los Angeles | EE | FF |
| 2 | Jane Doe | 25 | Los Angeles | GG | HH |
步骤一:加载和解析JSON数据
首先,我们需要将 json_data 列从字符串转换为字典格式。可以使用 json.loads() 函数来实现这一点。
import json# 将 json_data 列解析为字典
df['json_data'] = df['json_data'].apply(json.loads)
此时,每个 json_data 字段已转换为字典格式,便于进一步处理。
步骤二:提取顶层字段
我们可以使用 pd.json_normalize() 轻松提取 json_data 中的顶层字段 name、age 和 city。
# 提取顶层字段
df[['name', 'age', 'city', 'js_obj']] = pd.json_normalize(df['json_data'])[['name', 'age', 'city', 'js_obj']]
这一步会创建新的 name、age、city 和 js_obj 列,并将 js_obj 保留为嵌套的列表对象。
步骤三:展开嵌套列表
为了将 js_obj 列中的嵌套列表展开为独立行,我们可以使用 explode() 方法。此方法能够将列表内的每个元素分解为独立的行,从而实现数据扁平化。
# 展开 js_obj 列
expanded_df = df.explode('js_obj').reset_index(drop=True)
此时,每个 js_obj 列中的嵌套对象都变成了 DataFrame 的独立行。接下来需要将 js_obj 字段进一步展开为 a_name 和 b_name 列。
步骤四:将嵌套对象展开为独立列
使用 pd.json_normalize() 可以将嵌套字典对象展开为独立列。我们再次应用该方法来提取 js_obj 字段中的 a_name 和 b_name。
# 将 js_obj 列展开为单独的列
expanded_df[['a_name', 'b_name']] = pd.json_normalize(expanded_df['js_obj'])
步骤五:清理数据
为了获得最终结果,我们删除原始的 json_data 和 js_obj 列,只保留所需的字段。
# 删除不需要的列
expanded_df = expanded_df.drop(columns=['json_data', 'js_obj'])# 查看结果
print(expanded_df)
最终结果
| id | name | age | city | a_name | b_name |
|---|---|---|---|---|---|
| 1 | John Doe | 30 | New York | AA | BB |
| 1 | John Doe | 30 | New York | CC | DD |
| 2 | Jane Doe | 25 | Los Angeles | EE | FF |
| 2 | Jane Doe | 25 | Los Angeles | GG | HH |
详细解释
为什么使用 pd.json_normalize()
pd.json_normalize() 是 pandas 中处理嵌套JSON数据的强大工具。它能在不显式编写循环的情况下,将嵌套字典或列表展开为平面表格结构,从而显著减少代码量并提高可读性。
explode() 的作用
explode() 方法能够将列表列展开为多个独立行。对于处理嵌套数据特别有用,如本例中的 js_obj 字段。如果没有该方法,我们将需要编写显式循环来手动展开,这样不仅繁琐,而且容易出错。
总结
通过本文的讲解,你已经掌握了如何在Python中使用 pandas 处理嵌套的JSON数据并将其展开为独立列。本文中的方法避免了显式循环,使用 pandas 内置的 json_normalize() 和 explode() 函数,使代码更简洁、更高效。
扩展阅读
- 官方文档:pandas.json_normalize
- 官方文档:pandas.DataFrame.explode
这些工具和方法为处理复杂JSON结构的数据提供了极大的便利,是数据工程师和数据分析师的重要技能。希望这篇文章能帮助你在日常工作中更高效地处理数据!
相关文章:

从JSON数据提取嵌套字段并转换为独立列的简洁方法
从JSON数据提取嵌套字段并转换为独立列的简洁方法 在数据处理和数据分析的日常工作中,我们经常遇到复杂的嵌套数据结构,特别是嵌入在JSON字段中的数据。这些数据往往需要解析并展开成独立的列,以便后续分析和建模。本文将详细介绍如何在Pyth…...

湘潭大学软件工程算法设计与分析考试复习笔记(四)
回顾 湘潭大学软件工程算法设计与分析考试复习笔记(一)湘潭大学软件工程算法设计与分析考试复习笔记(二)湘潭大学软件工程算法设计与分析考试复习笔记(三) 前言 现在是晚上十一点,我平时是十…...

特征交叉-DeepCross Network学习
一 tensorflow官方实现 tensorflow的官方实现已经是V2版本 class Cross(tf.keras.layers.Layer):"""Cross Layer in Deep & Cross Network to learn explicit feature interactions.Args:projection_dim: int,低秩矩阵的维度,应该小…...
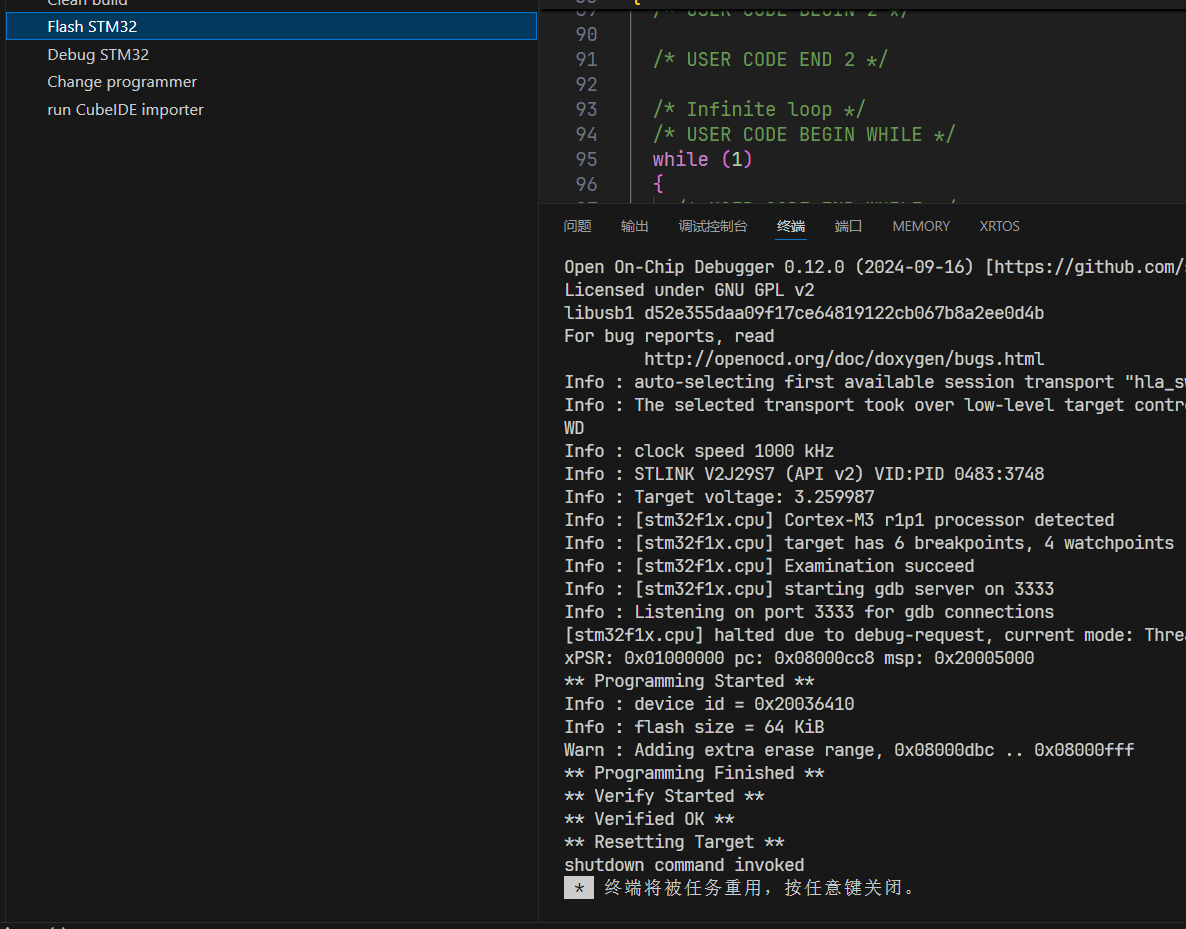
stm32cubemx+VSCODE+GCC+makefile 开发环境搭建
title: stm32cubemxVSCODEGCCmakefile 开发环境搭建 tags: FreertosHalstm32cubeMx 文章目录 内容往期内容导航第一步准备环境vscode 插件插件配置点灯 内容 往期内容导航 第一步准备环境 STM32CubeMXVSCODEMinGWOpenOcdarm-none-eabi-gcc 然后把上面下载的软件 3 4 5 bin 文…...

Go语言中的Defer机制详解与示例
在Go语言中,defer是一个关键字,用于确保资源的清理和释放,特别是在函数中创建的资源。defer语句会将其后的函数调用推迟到包含它的函数即将返回时执行。这使得defer成为处理文件关闭、数据库连接释放、解锁等资源清理操作的理想选择。 Defer…...

H.265流媒体播放器EasyPlayer.js H5流媒体播放器如何验证视频播放是否走硬解
随着技术的不断进步和5G网络的推广,中国流媒体播放器行业市场规模以及未来发展趋势都将持续保持稳定的增长,并将在未来几年迎来新的发展机遇。流媒体播放器将继续作为连接内容创作者和观众的重要桥梁,推动数字媒体产业的创新和发展。 EasyPla…...

ms-hot目录
1. ms-hot1...

vulfocus在线靶场:骑士cms_cve_2020_35339:latest 速通手册
目录 一、启动环境,访问页面,ip:端口号/index.php?madmin,进入后台管理页面,账号密码都是adminadmin 二、进入之后,根据图片所示,地址后追加一下代码,保存修改 三、新开标签页访问:①ip:端…...

AI Large Language Model
AI 的 Large Language model LLM , 大语言模型: 是AI的模型,专门设计用来处理自然语言相关任务。它们通过深度学习和庞大的训练数据集,在理解和生成自然语言文本方面表现出色。常见的 LLM 包括 OpenAI 的 GPT 系列、Google 的 PaLM 和 Meta…...

React Native的`react-native-reanimated`库中的`useAnimatedStyle`钩子来创建一个动画样式
React Native的react-native-reanimated库中的useAnimatedStyle钩子来创建一个动画样式,用于一个滑动视图的每个项目(SliderItem)。useAnimatedStyle钩子允许你根据动画值(在这个例子中是scrollX)来动态地设置组件的样…...

FastJson反序列化漏洞(CVE-2017-18349)
漏洞原理 原理就不多说了,可以去看我这篇文章,已经写得很详细了。 Java安全—log4j日志&FastJson序列化&JNDI注入-CSDN博客 影响版本 FastJson<1.2.24 复现过程 这里我是用vulfocus.cn这个漏洞平台去复现的,比较方便&#x…...

【优选算法篇】分治乾坤,万物归一:在重组中窥见无声的秩序
文章目录 分治专题(二):归并排序的核心思想与进阶应用前言、第二章:归并排序的应用与延展2.1 归并排序(medium)解法(归并排序)C 代码实现易错点提示时间复杂度和空间复杂度 2.2 数组…...

C++:探索AVL树旋转的奥秘
文章目录 前言 AVL树为什么要旋转?一、插入一个值的大概过程1. 插入一个值的大致过程2. 平衡因子更新原则3. 旋转处理的目的 二、左单旋1. 左单旋旋转方式总处理图2. 左单旋具体会遇到的情况3. 左单旋代码总结 三、右单旋1. 右单旋旋转方式总处理图2. 右单旋具体会遇…...

2. Django中的URL调度器 (自定义路径转换器)
在 Django 中,URL 路由通常使用路径转换器(path converters)来匹配和捕获 URL 中的特定模式,例如整数、字符串或 slug 等。默认情况下,Django 提供了一些内置的路径转换器,如 <int>、<str>、&l…...

深度学习:神经网络中线性层的使用
深度学习:神经网络中线性层的使用 在神经网络中,线性层(也称为全连接层或密集层)是基础组件之一,用于执行输入数据的线性变换。通过这种变换,线性层可以重新组合输入数据的特征,并将其映射到新…...

【刷题】算法设计题+程序设计题【2】2019-2024
11.202019年真题*2BST二叉排序树分裂、双向冒泡排序 2019 真题 【2019 1】编写算法,将一棵二叉排序树 分解成两棵二叉排序树 t1和t2,使得t1中的所有结点关键字的值都小于x,t2中所有结点关键字都大于x。 typedef struct BSTNode{int data;str…...

搭建es环境
centos7搭建elasticsearch环境 首先考虑使用 Docker 来安装 Elasticsearch、Kibana 和 Logstash。在安装过程中,可能会遇到一些问题,但通过适当的方法可以解决。 docker pull docker.elastic.co/elasticsearch/elasticsearch:8.14.3 首先创建一个网络&a…...

阿里云和七牛云对象存储区别和实现
七牛云对象存储操作(QiniuUtil) 配置:使用 com.qiniu.storage.Configuration 类来配置上传设置,如指定区域(Region)和分片上传版本。上传管理器:通过 UploadManager 类来处理文件上传。认证&am…...

uniapp微信小程序接入airkiss插件进行WIFI配网
本文可参考uniapp小程序插件 一.申请插件 微信公众平台设置页链接:微信公众平台 登录您的小程序微信公众平台,进入设置页,在第三方设置->插件管理->添加插件中申请AiThinkerAirkissforWXMini插件,申请的插件appId为【wx6…...

03 —— Webpack 自动生成 html 文件
HtmlWebpackPlugin | webpack 中文文档 | webpack中文文档 | webpack中文网 安装 npm install --save-dev html-webpack-plugin 下载html-webpack-plugin本地软件包 npm i html-webpack-plugin --save-dev 配置webpack.config.js让webpack拥有插件功能 const HtmlWebpack…...

如何用AI智能分层工具告别繁琐的PSD手动制作
如何用AI智能分层工具告别繁琐的PSD手动制作 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider 还在为复杂的插画作品手动创建PSD分层文件而烦恼吗ÿ…...

B站缓存视频终极转换指南:3分钟将m4s文件无损转为通用MP4格式
B站缓存视频终极转换指南:3分钟将m4s文件无损转为通用MP4格式 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经遇到过这样的…...
的实战配置指南与避坑)
别再乱调了!AUTOSAR DEM中Debounce参数(步长、阈值)的实战配置指南与避坑
AUTOSAR DEM中Debounce参数实战:从电压过压到通讯超时的精准调优 在汽车电子系统的故障诊断中,误报和漏报就像一对难以调和的矛盾体。我曾见过一个项目因为电压过压检测过于敏感,导致车辆在颠簸路面频繁误报故障;也遇到过通讯超时…...

基于模型的测试在汽车行业的应用
作 者 | 路国光出 品 | 汽车电子与软件摘要:为解决汽车电子软件开发中传统测试效率低、覆盖不足、验证滞后等问题,本文以基于模型的系统工程(MBSE)为背景,研究基于模型的测试(MBT)在汽车行业的应…...

如何快速部署Apache Traffic Server:10分钟上手完整教程
如何快速部署Apache Traffic Server:10分钟上手完整教程 【免费下载链接】trafficserver Apache Traffic Server™ is a fast, scalable and extensible HTTP/1.1 and HTTP/2 compliant caching proxy server. 项目地址: https://gitcode.com/gh_mirrors/traf/tra…...

SteamCleaner终极指南:3步轻松释放100GB游戏磁盘空间
SteamCleaner终极指南:3步轻松释放100GB游戏磁盘空间 【免费下载链接】SteamCleaner :us: A PC utility for restoring disk space from various game clients like Origin, Steam, Uplay, Battle.net, GoG and Nexon :us: 项目地址: https://gitcode.com/gh_mirr…...
—— 递归树如何看懂分治算法的运行时间)
算法基础(十一)—— 递归树如何看懂分治算法的运行时间
1. 定位导航 前面已经学习了分治思想: 分解 → 解决 → 合并分治算法经常可以写成递归式。 例如归并排序: 先把数组拆成左右两半; 分别排序左右两半; 再合并两个有序数组。它的运行时间可以粗略写成: T(n)2T(n/2)n T(n…...

ClawGuard Web:构建AI技能安全扫描平台,从代码安全到信任生态
1. 项目概述:ClawGuard Web 安全技能注册平台如果你在 OpenClaw 生态里开发或使用技能,那你肯定遇到过这个头疼的问题:从 ClawHub 或者 GitHub 上找到一个看起来不错的技能,但心里总犯嘀咕——这代码里会不会藏着恶意后门…...

微信网页版终极解决方案:三步实现浏览器端微信完整使用指南
微信网页版终极解决方案:三步实现浏览器端微信完整使用指南 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为繁琐的微信安装流程而烦…...

半导体设备再流通:破解成熟制程产能瓶颈与供应链韧性难题
1. 项目概述:为什么晶圆厂需要工具再流通?在芯片行业摸爬滚打了十几年,我见过太多因为一台关键设备宕机,导致整条产线停摆,最终引发下游客户“断粮”数月的惨痛案例。大家可能觉得,疫情时期的“芯片荒”已经…...