表格不同类型的数据如何向量化?
在进行机器学习项目时,首先需要获取数据,这些数据可以来自数据库、API、网络抓取,或从CSV、Excel等文件中读取。数据可能包含数值、文本和类别等多种特征,但原始数据通常无法直接用于训练模型。
数据预处理包括清洗、填补缺失值和处理异常值。之后,数据向量化将原始表格数据转换为机器学习模型能理解的数值格式。由于大多数算法只能处理数值数据,向量化是至关重要的一步,常用的方法包括独热编码和标签编码。
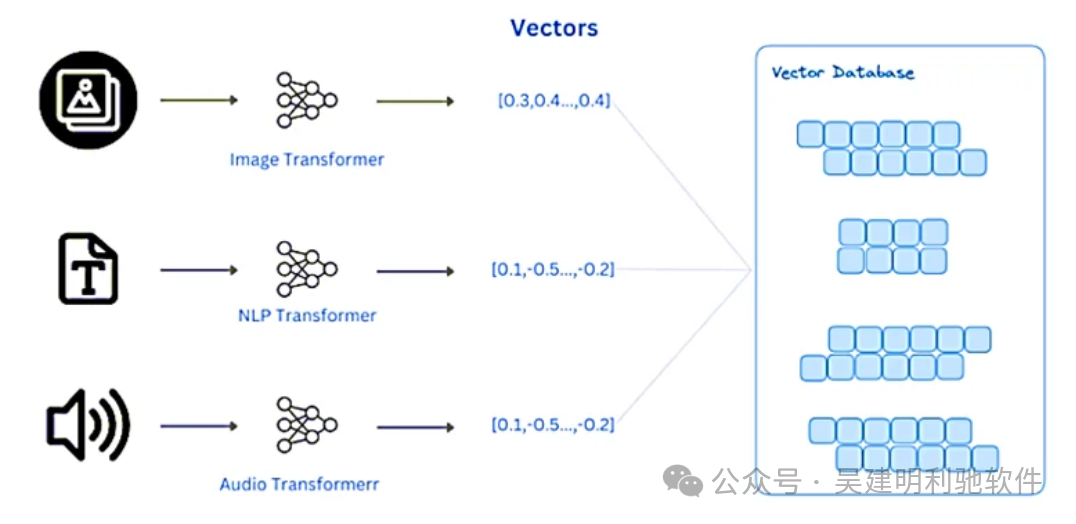
这个步骤对于模型的训练和预测至关重要,因为大多数机器学习算法(如线性回归、决策树、神经网络等)只能处理数值数据,而不是文本、类别或其他非数值数据。
数据向量化有啥用?
- • 机器学习模型的输入 :大多数机器学习模型只能接受数值形式的数据。向量化将原始数据转换成模型可接受的输入形式,使模型能够进行学习和预测。
- • 提高模型性能 :通过合理的向量化处理,模型可以更好地捕捉数据中的信息,提高学习和预测的准确性。例如,将类别变量转换为数值后,算法可以通过数值关系理解类别之间的区别。
- • 数据一致性和规范化 :向量化可以标准化不同格式的输入数据,如将分类、文本或其他类型的特征转换为数值,确保所有输入特征都能够被模型一致地处理。
什么是向量化?
向量化通常指的是将表格中的不同类型的数据(如数值、分类、文本等)转换为向量形式的过程。
常见的向量化方法包括:
数值特征标准化
直接对原始数值进行标准化处理,如归一化、Z-score 标准化,使数据保持在相同的量级上。
在机器学习中,标准化是一种常见的数据预处理技术,旨在将数值特征转换为具有相同尺度的分布。
使用标准化可以提高模型的收敛速度和性能,特别是在使用基于距离的算法(如K-近邻、SVM等)时。
标准化是将 特征的均值转换为0,方差转换为1的过程。
公式如下:
其中:
- • 是标准化后的值。
- • 是原始值。
- • 是特征的均值。
- • 是特征的标准差。
类别特征的编码
对类别数据进行编码,使其能够被机器学习模型处理。
1、 独热编码(One-Hot Encoding) :将每个类别表示为一个二进制向量,适用于没有顺序关系的分类特征,如性别、城市、颜色等。
2、 标签编码(Label Encoding) :将类别变量转换为整数表示,适用于类别有顺序关系的情况。
文本特征的向量化
对文本特征进行处理,通常使用以下方法:
1、 词袋模型(Bag of Words) :统计文本中出现的词汇,形成词频向量。
2、 TF-IDF :基于词语在文档中的频率和其在整个语料库中的逆频率,将文本表示为向量。
词频(TF) :某个词在文档中出现的频率。
逆文档频率(IDF) :衡量词在整个语料库中的普遍重要性,通常通过以下公式计算:
其中, 是文档总数,是包含词 (t) 的文档数。
TF-IDF 计算公式:
其中,是词, 是文档。
3、 词向量(Word Embeddings) :使用预训练的词向量模型(如Word2Vec、GloVe)将文本表示为向量。
如何实现向量化?
向量化可以通过编程实现,下面以Python的常用库为例说明实现过程。
1. 数值特征标准化
示例:
import pandas as pd
from sklearn.preprocessing import StandardScaler# 创建示例数据
data = pd.DataFrame({'用户ID': [1, 2, 3, 4],'浏览时长(秒)': [120, 300, 180, 240]
})# 实例化标准化器
scaler = StandardScaler()# 选择要标准化的特征
num_feature = data[['浏览时长(秒)']]# 执行标准化
scaled_feature = scaler.fit_transform(num_feature)# 打印标准化后的特征
print(scaled_feature)# 输出
# [[-1.34164079]
# [ 1.34164079]
# [-0.4472136 ]
# [ 0.4472136 ]]
2. 类别特征的独热编码
import pandas as pd# 创建示例数据
data = pd.DataFrame({'颜色': ['红', '绿', '蓝', '绿']
})# 进行独热编码
one_hot_encoded_data = pd.get_dummies(data, columns=['颜色'])# 打印编码后的数据
print(one_hot_encoded_data)# 颜色_红 颜色_绿 颜色_蓝
# 0 1 0 0
# 1 0 1 0
# 2 0 0 1
# 3 0 1 0
3. 文本特征向量化(TF-IDF)
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer# 定义文档
documents = ["我爱学习机器学习","机器学习非常有趣","我喜欢学习编程"
]# 使用 jieba 进行分词
def tokenize(text):return " ".join(jieba.cut(text))# 对每个文档进行分词
tokenized_documents = [tokenize(doc) for doc in documents]# 创建 TF-IDF 向量化器
vectorizer = TfidfVectorizer()# 拟合并转换文档
tfidf_matrix = vectorizer.fit_transform(tokenized_documents)# 获取特征名称(词汇)
feature_names = vectorizer.get_feature_names_out()# 转换为数组并打印
tfidf_array = tfidf_matrix.toarray()# 输出结果
for i in range(len(documents)):print(f"文档 {i + 1} 的 TF-IDF 向量:")for j in range(len(feature_names)):print(f"{feature_names[j]}: {tfidf_array[i][j]:.4f}")print()
输出:

在机器学习项目中,表格数据通常会混合多种类型的特征(数值、类别、文本等)。
向量化的关键在于根据特征的类型选择适合的编码方式,并将所有特征统一到一个数值向量中。
完整的处理流程可能涉及多个步骤的向量化组合,然后将其作为机器学习模型的输入。
一个完整示例
下面是一个完整的模拟用户活动日志数据,包含了多种类型的数据,包括数值型、类别型和日期型。这个数据集可以用于用户活动分析的向量化。
模拟数据集:用户活动日志

向量化示例代码
接下来,我们将使用这份数据来进行向量化处理。以下是 Python 代码示例,展示如何对这个数据集进行预处理和向量化。
import pandas as pd
from sklearn.preprocessing import OneHotEncoder# 创建示例数据
data = pd.DataFrame({'用户ID': [1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 5, 5, 5, 5],'活动类型': ['登录', '浏览商品', '添加到购物车', '购买商品','登录', '浏览商品', '添加到购物车', '购买商品','登录', '浏览商品', '添加到购物车', '购买商品','登录', '浏览商品', '添加到购物车','登录', '浏览商品', '浏览商品', '购买商品'],'日期': pd.to_datetime(['2024-10-01', '2024-10-01', '2024-10-02', '2024-10-02','2024-10-01', '2024-10-03', '2024-10-03', '2024-10-04','2024-10-02', '2024-10-02', '2024-10-02', '2024-10-02','2024-10-01', '2024-10-03', '2024-10-03','2024-10-01', '2024-10-01', '2024-10-02', '2024-10-03']),'浏览时长(秒)': [0, 120, 90, 30, 0, 300, 50, 20, 0, 180, 60, 15, 0, 240, 10, 0, 150, 300, 40],'购买金额(元)': [0, 0, 0, 299, 0, 0, 0, 150, 0, 0, 0, 499, 0, 0, 0, 0, 0, 0, 250],'用户设备': ['手机', '手机', '平板', '手机', '电脑', '电脑', '手机', '电脑','平板', '手机', '手机', '平板', '手机', '电脑', '电脑','手机', '手机', '平板', '手机']
})# 提取日期特征
data['年'] = data['日期'].dt.year
data['月'] = data['日期'].dt.month
data['日'] = data['日期'].dt.day
data['星期几'] = data['日期'].dt.weekday # 0=星期一, 6=星期日
data['是否为周末'] = data['星期几'].apply(lambda x: 1 if x >= 5 else 0) # 1=周末, 0=工作日# 进行独热编码
encoder_活动类型 = OneHotEncoder(sparse=False)
活动类型_encoded = encoder_活动类型.fit_transform(data[['活动类型']])encoder_设备 = OneHotEncoder(sparse=False)
设备_encoded = encoder_设备.fit_transform(data[['用户设备']])# 创建一个新的DataFrame,将独热编码的结果和其他特征合并
活动类型_df = pd.DataFrame(活动类型_encoded, columns=encoder_活动类型.get_feature_names_out(['活动类型']))
设备_df = pd.DataFrame(设备_encoded, columns=encoder_设备.get_feature_names_out(['用户设备']))# 合并数据
data = pd.concat([data, 活动类型_df, 设备_df], axis=1)# 删除原始列
data = data.drop(columns=['活动类型', '日期', '用户设备'])# 打印处理后的数据
print(data)
处理后的数据
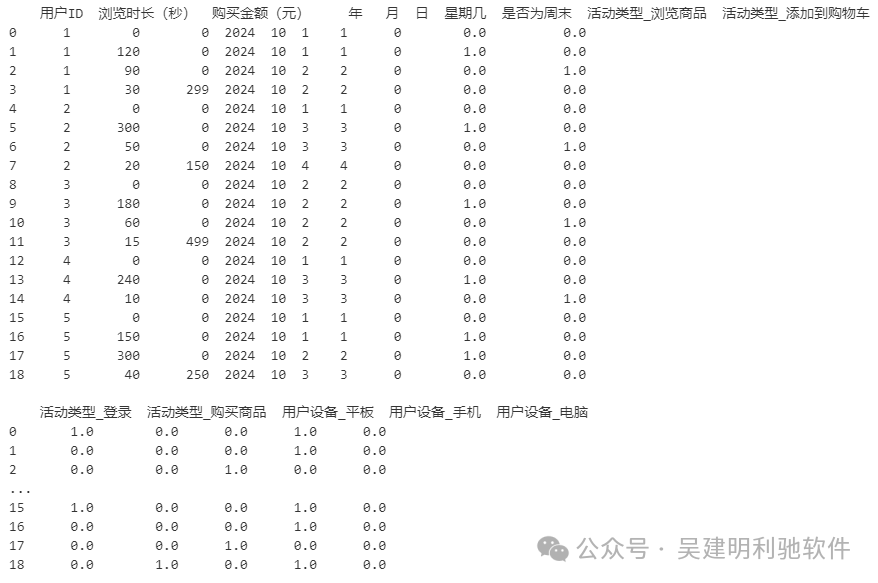
这个模拟数据集为用户活动分析提供了一个基础,涵盖用户行为、时间、花费以及设备等多维度信息。
总结
向量化是机器学习模型应用的前提步骤,它确保了模型能够处理不同类型的特征数据,并且在训练和预测中提高模型的性能和准确性。
通过对数值、类别、文本等特征进行合适的向量化处理,可以有效地提升模型的效果。
相关文章:
表格不同类型的数据如何向量化?
在进行机器学习项目时,首先需要获取数据,这些数据可以来自数据库、API、网络抓取,或从CSV、Excel等文件中读取。数据可能包含数值、文本和类别等多种特征,但原始数据通常无法直接用于训练模型。 数据预处理包括清洗、填补缺失值和…...

成都栩熙酷,电商服务新选择
在当今数字经济蓬勃发展的时代,电商平台已成为推动商业创新、促进消费升级的重要力量。抖音小店,作为短视频与电商深度融合的产物,凭借其独特的社交属性和内容营销优势,迅速吸引了大量用户和商家的关注。在这场变革中,…...

【java基础】微服务篇
参考黑马八股视频。 目录 Spring Cloud 5大组件 注册中心 负载均衡 限流 CAP和BASE 分布式事务解决方案 分布式服务的接口幂等性 分布式任务调度 Spring Cloud 5大组件 注册中心 Eureka的作用 健康监控 负载均衡 限流 漏桶固定速率,令牌桶不限速 CAP和BA…...

【LLM训练系列02】如何找到一个大模型Lora的target_modules
方法1:观察attention中的线性层 import numpy as np import pandas as pd from peft import PeftModel import torch import torch.nn.functional as F from torch import Tensor from transformers import AutoTokenizer, AutoModel, BitsAndBytesConfig from typ…...
uni-app快速入门(八)--常用内置组件(上)
uni-app提供了一套基础组件,类似HTML里的标签元素,不推荐在uni-app中使用使用div等HTML标签。在uni-app中,对应<div>的标签是view,对应<span>的是text,对应<a>的是navigator,常用uni-app…...

基于Amazon Bedrock:一站式多模态数据处理新体验
目录 引言 关于Amazon Bedrock 基础模型体验 1、进入环境 2、发现模型及快速体验 3、打开 Amazon Bedrock 控制台 4、通过 Playgrounds 体验模型 (1)文本生成 (2)图片生成 关于资源清理 结束语 引言 在云计算和人工智能…...
)
FAX动作文件优化脚本(MAX清理多余关键帧插件)
大较好,为大家介绍一个节省FBX容量的插件!只保留有用的动画轴向,其他不参与动画运动的清除! 一.插件目的:: 1.我们使用的U3D引擎产生的游戏资源包容量太大,故全方位优化动画资源; 2.在max曲线编辑器内,点取轴向太过麻烦,费事,直观清除帧大大提高效率。 如: 二:…...

Chapter 2 - 16. Understanding Congestion in Fibre Channel Fabrics
Transforming an I/O Operation to FC frames A read or write I/O operation (Figure 2-28) between an initiator and a target undergoes a series of transformations before being transmitted on a Fibre Channel link. 启动程序和目标程序之间的读取或写入 I/O 操作(图…...
pymysql、视图、触发器、存储过程、函数、流程控制、数据库连接池)
mysql数据库(六)pymysql、视图、触发器、存储过程、函数、流程控制、数据库连接池
pymysql、视图、触发器、存储过程、函数、流程控制、数据库连接池 文章目录 pymysql、视图、触发器、存储过程、函数、流程控制、数据库连接池一、pymysql二、视图三、触发器四、存储过程五、函数六、流程控制七、数据库连接池 一、pymysql 可以使用pip install pymysql安装py…...

RFdiffusion EuclideanDiffuser类解读
EuclideanDiffuser 是 RFdiffusion 中的一个关键类,专门设计用于对**三维空间中的点(如蛋白质的原子坐标)**进行扩散处理。它通过逐步向这些点添加噪音来实现扩散过程,从而为扩散模型提供输入数据,并通过逆扩散还原这些数据。 get_beta_schedule函数源代码 def get_beta…...

Flutter实现气泡提示框学习
前置知识点学习 GlobalKey GlobalKey 是 Flutter 中一个非常重要的概念,它用于唯一标识 widget 树中的特定 widget,并提供对该 widget 的访问。这在需要跨越 widget 树边界进行交互或在 widget 树重建时保持状态时尤其有用。 GlobalKey 的作用 唯一标…...

vue3 路由守卫
在Vue 3中,路由守卫是一种控制和管理路由跳转的机制。它允许你在执行导航前后进行一些逻辑处理,比如权限验证、数据预取等,从而增强应用的安全性和效率。路由守卫分为几种不同的类型,每种类型的守卫都有其特定的应用场景。 其实路…...
【MATLAB源码-第218期】基于matlab的北方苍鹰优化算法(NGO)无人机三维路径规划,输出做短路径图和适应度曲线.
操作环境: MATLAB 2022a 1、算法描述 北方苍鹰优化算法(Northern Goshawk Optimization,简称NGO)是一种新兴的智能优化算法,灵感来源于北方苍鹰的捕猎行为。北方苍鹰是一种敏捷且高效的猛禽,广泛分布于北…...

如何控制自己玩手机的时间?两台苹果手机帮助自律
对一些人来说,被智能手机“绑架”是一件心甘情愿的事,和它相处的一天中,不必面对现实的压力,它就像个“舒适区”。这是因为在使用手机的过程中,应用程序(尤其是游戏和社交媒体应用)会不断刺激大…...

【java-Neo4j 5开发入门篇】-最新Java开发Neo4j
系列文章目录 前言 上一篇文章讲解了Neo4j的基本使用,本篇文章对Java操作Neo4j进行入门级别的阐述,方便读者快速上手对Neo4j的开发。 一、开发环境与代码 1.docker 部署Neo4j #这里使用docker部署Neo4j,需要镜像加速的需要自行配置 docker run --name…...
简介和模块功能概览)
Python的3D可视化库 - vedo (1)简介和模块功能概览
文章目录 1. vedo和它支持的功能简介1.1 安装vedo1.2 命令行接口1.3 导出3D文件1.4 文件格式转换 2. vedo模块功能概览2.1 绘制和渲染visual 管理可视化、对象及其属性的显示的基类plotter 3D渲染colors 定义和显示颜色dolfin FEniCS/Dolfin库的支持 2.2 图形数据管理mesh 多边…...

全面解析:HTML页面的加载全过程(一)--输入URL地址,与服务器建立连接
用户输入URL地址,与服务器建立连接 用户在浏览器地址栏输入一个URL 浏览器开始执行以下三步操作操作:url解析、DNS查询、TCP连接 第一步:URL解析 什么是URL? URL(Uniform Resource Locator,统一资源定位符)是互联网…...

elasticsearch的倒排索引是什么?
大家好,我是锋哥。今天分享关于【elasticsearch的倒排索引是什么?】面试题。希望对大家有帮助; elasticsearch的倒排索引是什么? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 倒排索引(Inverted Index&a…...

Ubuntu VNC Session启动chromium和firefox报错
问题描述 VNC客户端连接到Ubuntu Server后,启动chromium和firefox时报错: $ chromium [348564:348564:1117/102143.085649:ERROR:ozone_platform_x11.cc(244)] Missing X server or $DISPLAY [348564:348564:1117/102143.085732:ERROR:env.cc(258)] Th…...

【Tealscale + Headscale + 自建服务器】异地组网笔记
文章目录 效果为什么要用 Headscale云服务器安装 Headscale配置 config.yaml创建反向代理搭建管理 UI授权管理 UI添加互联设备参考 效果 首先是连接情况,双端都连接上自建的 Headscale, 手机使用移动流量,测试一下 ping 值 再试试进入游戏 可…...

Wan2.2-I2V-A14B开源大模型:支持ONNX导出与边缘设备轻量化部署
Wan2.2-I2V-A14B开源大模型:支持ONNX导出与边缘设备轻量化部署 1. 开箱即用的文生视频解决方案 Wan2.2-I2V-A14B是一款强大的文生视频开源大模型,能够将文本描述直接转化为高质量视频内容。这个专为RTX 4090D 24GB显卡优化的私有部署镜像,让…...

Apollo配置中心实战:从零到一的Docker化部署与核心配置详解
1. 为什么选择Apollo配置中心 在微服务架构中,配置管理一直是个让人头疼的问题。记得我第一次尝试用传统properties文件管理配置时,光是同步不同环境的配置就浪费了大半天时间。后来接触到Apollo,才发现原来配置管理可以这么优雅。 Apollo作为…...

Face3D.ai Pro零基础入门:5分钟从照片到3D人脸,小白也能玩转
Face3D.ai Pro零基础入门:5分钟从照片到3D人脸,小白也能玩转 1. 引言:从照片到3D人脸的魔法 想象一下,用手机随手拍一张自拍,5分钟后就能得到一个可以360度旋转的3D人脸模型。这不是科幻电影里的场景,而是…...

手机生成剧本杀软件2025推荐,创新剧情设计工具助力创作
手机生成剧本杀软件2025推荐,创新剧情设计工具助力创作随着剧本杀市场的蓬勃发展,越来越多的创作者和爱好者希望借助科技的力量来提升创作效率和质量。在2025年,一款名为量子探险AI剧本杀工坊的手机生成剧本杀软件脱颖而出,成为众…...
)
告别BLAST卡顿!用FastANI和Skani快速搞定微生物基因组ANI计算(附实战对比)
微生物基因组分析提速指南:FastANI与Skani的性能对决与实战应用 当实验室的测序仪日夜不停地吐出海量微生物基因组数据时,生物信息学分析流程中的ANI计算环节往往成为效率瓶颈。传统BLAST-based方法在应对数十甚至上百个基因组比较时,不仅耗时…...

AudioSeal保姆级教学:Gradio界面多文件批量上传与异步检测队列设置
AudioSeal保姆级教学:Gradio界面多文件批量上传与异步检测队列设置 1. 引言 你是不是遇到过这样的场景?手里有一堆音频文件,需要挨个检查它们是不是AI生成的,或者想给一批音频文件批量加上水印。手动操作不仅效率低,…...

OpenClaw+千问3.5-9B数据清洗:Excel复杂表格自动化处理
OpenClaw千问3.5-9B数据清洗:Excel复杂表格自动化处理 1. 为什么需要自动化Excel处理 每次面对上百行的Excel表格时,我总会在合并单元格和异常值上浪费大量时间。作为数据分析师,最痛苦的莫过于收到业务部门发来的"美化版"报表—…...

OpenClaw自动化写作对比:千问3.5-35B-A3B-FP8与纯文本模型的产出差异
OpenClaw自动化写作对比:千问3.5-35B-A3B-FP8与纯文本模型的产出差异 1. 为什么需要对比不同模型的写作表现 上周我在用OpenClaw自动生成技术文档时,发现一个有趣的现象:同样的任务指令,交给不同的大模型处理,产出的…...

Windows下OpenClaw极简安装:Qwen3.5-9B-AWQ-4bit镜像10分钟体验
Windows下OpenClaw极简安装:Qwen3.5-9B-AWQ-4bit镜像10分钟体验 1. 为什么选择这个组合? 最近在折腾本地AI自动化时,发现很多工具要么配置复杂,要么对硬件要求太高。直到遇到OpenClawQwen3.5-9B-AWQ-4bit这个组合,才…...

OpenClaw硬件优化:Qwen2.5-VL-7B在低配设备上的运行技巧
OpenClaw硬件优化:Qwen2.5-VL-7B在低配设备上的运行技巧 1. 为什么要在低配设备上运行OpenClaw? 去年夏天,我在一台2018款MacBook Air(8GB内存)上第一次尝试部署OpenClaw时,系统几乎瞬间卡死。这让我意识…...