Stable Diffusion核心网络结构——CLIP Text Encoder

🌺系列文章推荐🌺
扩散模型系列文章正在持续的更新,更新节奏如下,先更新SD模型讲解,再更新相关的微调方法文章,敬请期待!!!(本文及其之前的文章均已更新)
SD模型原理:
- Stable Diffusion概要讲解
- Stable diffusion详细讲解
- Stable Diffusion的加噪和去噪详解
- Diffusion Model
- Stable Diffusion核心网络结构——VAE
- Stable Diffusion核心网络结构——CLIP Text Encoder
- Stable Diffusion核心网络结构——U-Net
- Stable Diffusion中U-Net的前世今生与核心知识
- SD模型性能测评
- Stable Diffusion经典应用场景
- SDXL的优化工作
微调方法原理:
- DreamBooth
- LoRA
- LORA及其变种介绍
- ControlNet
- ControlNet文章解读
- Textual Inversion 和 Embedding fine-tuning

Stable Diffusion核心网络结构
摘录来源:https://zhuanlan.zhihu.com/p/632809634
目录
Stable Diffusion核心网络结构
SD模型整体架构初识
CLIP Text Encoder模型
微调文本映射
原始CLIP、BLIP
SD模型整体架构初识
Stable Diffusion模型整体上是一个End-to-End模型,主要由VAE(变分自编码器,Variational Auto-Encoder),U-Net以及CLIP Text Encoder三个核心组件构成。
本文主要介绍CLIP Text Encoder,VAE和U-Net请参考:
- Stable Diffusion核心网络结构——VAE
- Stable Diffusion核心网络结构——U-Net
在FP16精度下Stable Diffusion模型大小2G(FP32:4G),其中U-Net大小1.6G,VAE模型大小160M以及CLIP Text Encoder模型大小235M(约123M参数)。其中U-Net结构包含约860M参数,FP32精度下大小为3.4G左右。

CLIP Text Encoder模型
作为文生图模型,Stable Diffusion中的文本编码模块直接决定了语义信息的优良程度,从而影响到最后图片生成的质量和与文本的一致性。
在这里,多模态领域的神器——CLIP(Contrastive Language-Image Pre-training),跨过了周期,从传统深度学习时代进入AIGC时代,成为了SD系列模型中文本和图像之间的“桥梁”。并且从某种程度上讲,正是因为CLIP模型的前置出现,加速推动了AI绘画领域的繁荣。
那么,什么是CLIP呢?CLIP有哪些优良的性质呢?为什么是CLIP呢?
首先,CLIP模型是一个基于对比学习的多模态模型,主要包含Text Encoder和Image Encoder两个模型。其中Text Encoder用来提取文本的特征,可以使用NLP中常用的text transformer模型作为Text Encoder;而Image Encoder主要用来提取图像的特征,可以使用CNN/Vision transformer模型(ResNet和ViT等)作为Image Encoder。与此同时,他直接使用4亿个图片与标签文本对数据集进行训练,来学习图片与本文内容的对应关系。
与U-Net的Encoder和Decoder一样,CLIP的Text Encoder和Image Encoder也能非常灵活的切换,庞大图片与标签文本数据的预训练赋予了CLIP强大的zero-shot分类能力。
灵活的结构,简洁的思想,让CLIP不仅仅是个模型,也给我们一个很好的借鉴,往往伟大的产品都是大道至简的。更重要的是,CLIP把自然语言领域的抽象概念带到了计算机视觉领域。

CLIP在训练时,从训练集中随机取出一张图片和标签文本,接着CLIP模型的任务主要是通过Text Encoder和Image Encoder分别将标签文本和图片提取embedding向量,然后用余弦相似度(cosine similarity)来比较两个embedding向量的相似性,以判断随机抽取的标签文本和图片是否匹配,并进行梯度反向传播,不断进行优化训练。

上面讲了Batch为1时的情况,当我们把训练的Batch提高到 N 时,其实整体的训练流程是不变的。只是现在CLIP模型需要将N个标签文本和N个图片的两两组合预测出N^2个可能的文本-图片对的余弦相似性,即下图所示的矩阵。这里共有N个正样本,即真正匹配的文本和图片(矩阵中的对角线元素),而剩余的N^2−N个文本-图片对为负样本,这时CLIP模型的训练目标就是最大化N个正样本的余弦相似性,同时最小化N^2−N个负样本的余弦相似性。

完成CLIP的训练后,输入配对的图片和标签文本,则Text Encoder和Image Encoder可以输出相似的embedding向量,计算余弦相似度就可以得到接近1的结果。同时对于不匹配的图片和标签文本,输出的embedding向量计算余弦相似度则会接近0。
就这样,CLIP成为了计算机视觉和自然语言处理自然语言处理这两大AI方向的“桥梁”,从此AI领域的多模态应用有了经典的基石模型。
上面我们讲到CLIP模型主要包含Text Encoder和Image Encoder两个部分,在Stable Diffusion中主要使用了Text Encoder部分。CLIP Text Encoder模型将输入的文本Prompt进行编码,转换成Text Embeddings(文本的语义信息),通过U-Net网络的CrossAttention模块嵌入Stable Diffusion中作为Condition条件,对生成图像的内容进行一定程度上的控制与引导,目前SD模型使用的是CLIP ViT-L/14CLIP ViT-L/14中的Text Encoder模型。
CLIP ViT-L/14 中的Text Encoder是只包含Transformer结构的模型,一共由12个CLIPEncoderLayer模块组成,模型参数大小是123M,具体CLIP Text Encoder模型结构如下图所示。其中特征维度为768,token数量是77,所以输出的Text Embeddings的维度为77x768。
CLIPEncoderLayer((self_attn): CLIPAttention((k_proj): Linear(in_features=768, out_features=768, bias=True)(v_proj): Linear(in_features=768, out_features=768, bias=True)(q_proj): Linear(in_features=768, out_features=768, bias=True)(out_proj): Linear(in_features=768, out_features=768, bias=True))(layer_norm1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)(mlp): CLIPMLP((activation_fn): QuickGELUActivation()(fc1): Linear(in_features=768, out_features=3072, bias=True)(fc2): Linear(in_features=3072, out_features=768, bias=True))(layer_norm2): LayerNorm((768,), eps=1e-05, elementwise_affine=True))下图是Rocky梳理的Stable Diffusion CLIP Text Encoder的完整结构图,大家可以感受一下其魅力,看着这个完整结构图学习Stable Diffusion CLIP Text Encoder部分,相信大家脑海中的思路也会更加清晰:

一般来说,我们提取CLIP Text Encoder模型最后一层特征作为CrossAttention模块的输入,但是开源社区的不断实践为我们总结了如下经验:当我们生成二次元内容时,可以选择提取CLIP Text Encoder模型倒数第二层特征;当我们生成写实场景内容时,可以选择提取CLIP Text Encoder模型最后一层的特征。这让Rocky想起了SRGAN以及感知损失,其也是提取了VGG网络的中间层特征才达到了最好的效果,AI领域的“传承”与共性,往往在这些不经意间,让人感到人工智能的魅力与美妙。
由于CLIP训练时所采用的最大Token数是77,所以在SD模型进行前向推理时,当输入Prompt的Token数量超过77时,将通过Clip操作拉回77x768,而如果Token数不足77则会使用padding操作得到77x768。如果说全卷积网络的设计让图像输入尺寸不再受限,那么CLIP的这个设置就让输入的文本长度不再受限(可以是空文本)。无论是非常长的文本,还是空文本,最后都将得到一样维度的特征矩阵。
同时在SD模型的训练中,一般来说CLIP的整体性能是足够支撑我们的下游细分任务的,所以CLIP Text Encoder模型参数是冻结的,我们不需要对其重新训练。
【如果我们想要一个新的embeeding词对应新特征向量,可以进行Textual Inversion 或 embedding fine-tuning微调】
注意:
Textual Inversion 或 embedding fine-tuning 微调的部分并不是 Stable Diffusion 模型中的 CLIP Text Encoder,而是训练新的词汇嵌入(embedding),这些嵌入会被用在 CLIP Text Encoder 的输入层,但CLIP Text Encoder 本身的参数是冻结的,并不会在这个过程中被调整。
在AIGC时代,我们使用语言文字表达的创意与想法,可以轻松让Stable Diffusion生成出一幅幅精美绝伦、创意十足、飞速破圈的图片。而这些背后,都有CLIP的功劳,CLIP不仅仅连接了文本和图像,也连接了AI行业与千万个需要生成图片和视频的行业,AI绘画的ToC普惠如此之强,Rocky认为CLIP就是那个“隐形冠军”。
微调文本映射
Textual Inversion 和 embedding fine-tuning
原始CLIP、BLIP
参考:万字长文解读深度学习——多模态模型CLIP、BLIP、ViLT-CSDN博客

相关文章:
Stable Diffusion核心网络结构——CLIP Text Encoder
🌺系列文章推荐🌺 扩散模型系列文章正在持续的更新,更新节奏如下,先更新SD模型讲解,再更新相关的微调方法文章,敬请期待!!!(本文及其之前的文章均已更新&…...

C语言-11-18笔记
1.C语言数据类型 类型存储大小值范围char1 字节-128 到 127 或 0 到 255unsigned char1 字节0 到 255signed char1 字节-128 到 127int2 或 4 字节-32,768 到 32,767 或 -2,147,483,648 到 2,147,483,647unsigned int2 或 4 字节0 到 65,535 或 0 到 4,294,967,295short2 字节…...

数据结构_图的遍历
深度优先搜索遍历 遍历思想 邻接矩阵上的遍历算法 void Map::DFSTraverse() {int i, v;for (i 0; i < MaxLen; i){visited[i] false;}for (i 0; i < Vexnum; i){// 如果顶点未访问,则进行深度优先搜索if (visited[i] false){DFS(i);}}cout << endl…...

设计LRU缓存
LRU缓存 LRU缓存的实现思路LRU缓存的操作C11 STL实现LRU缓存自行设计双向链表 哈希表 LRU(Least Recently Used,最近最少使用)缓存是一种常见的缓存淘汰算法,其基本思想是:当缓存空间已满时,移除最近最少使…...

python中的base64使用小笑话
在使用base64的时候将本地的图片转换为base64 代码如下,代码绝对正确 import base64 def image_to_data_uri(image_path):with open(image_path, rb) as image_file:image_data base64.b64encode(image_file.read()).decode(utf-8)file_extension image_path.sp…...

Python之time时间库
time时间库 概述获取当前时间time库datetime库区别 时间元组处理获取时间元组的各个部分时间戳和时间元组的转换 格式化时间格式化时间解析时间格式符号说明 暂停程序计时操作简单计时高精度计时计时器类的实现 UTC时间操作time库datetime库 概述 time是Python标准库中的一个模…...

Easyexcel(4-模板文件)
相关文章链接 Easyexcel(1-注解使用)Easyexcel(2-文件读取)Easyexcel(3-文件导出)Easyexcel(4-模板文件) 文件导出 获取 resources 目录下的文件,使用 withTemplate 获…...

国产linux系统(银河麒麟,统信uos)使用 PageOffice 动态生成word文件
PageOffice 国产版 :支持信创系统,支持银河麒麟V10和统信UOS,支持X86(intel、兆芯、海光等)、ARM(飞腾、鲲鹏、麒麟等)、龙芯(LoogArch)芯片架构。 数据区域填充文本 数…...

Window11+annie 视频下载器安装
一、ffmpeg环境的配置 下载annie之前需要先配置ffmpeg视频解码器。 网址下载地址 https://ffmpeg.org/download.html1、在网址中选择window版本 2、点击后选择该版本 3、下载完成后对压缩包进行解压,后进行环境的配置 (1)压缩包解压&#…...
配置篇(七))
SAP GR(Group Reporting)配置篇(七)
1.7、合并处理的配置 1.7.1 定义方法 菜单路径 组报表的SAP S4HANA >合并处理的配置>定义方法 事务代码 SPI4...

共建智能软件开发联合实验室,怿星科技助力东风柳汽加速智能化技术创新
11月14日,以“奋进70载,智创新纪元”为主题的2024东风柳汽第二届科技周在柳州盛大开幕,吸引了来自全国的汽车行业嘉宾、技术专家齐聚一堂,共襄盛举,一同探寻如何凭借 “新技术、新实力” 这一关键契机,为新…...
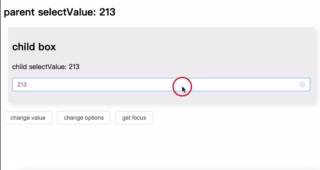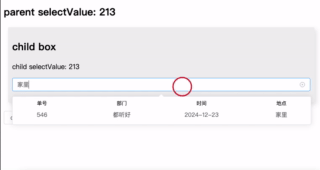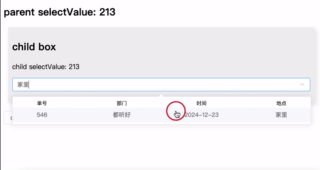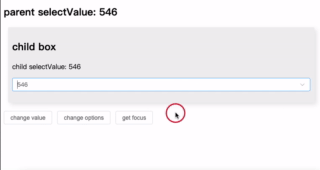
优化表单交互:在 el-select 组件中嵌入表格显示选项
介绍了一种通过 el-select 插槽实现表格样式数据展示的方案,可更直观地辅助用户选择。支持列配置、行数据绑定及自定义搜索,简洁高效,适用于复杂选择场景。完整代码见GitHub 仓库。 背景 在进行业务开发选择订单时,如果单纯的根…...

每日一题 LCR 079. 子集
LCR 079. 子集 主要应该考虑遍历的顺序 class Solution { public:vector<vector<int>> subsets(vector<int>& nums) {vector<vector<int>> ans;vector<int> temp;dfs(nums,0,temp,ans);return ans;}void dfs(vector<int> &…...

cocos creator 3.8 Node学习 3
//在Ts、js中 this指向当前的这个组件实例 //this下的一个数据成员node,指向组件实例化的这个节点 //同样也可以根据节点找到挂载的所有组件 //this.node 指向当前脚本挂载的节点//子节点与父节点的关系 // Node.parent是一个Node,Node.children是一个Node[] // th…...

微信小程序底部button,小米手机偶现布局错误的bug
预期结果:某button fixed 到页面底部,进入该页面时,正常显示button 实际结果:小米13pro,首次进入页面,button不显示。再次进入时,则正常展示 左侧为小米手机第一次进入。 遇到bug的解决思路&am…...

【计组】复习题
冯诺依曼型计算机的主要设计思想是什么?它包括哪些主要组成部分? 主要设计思想: ①采用二进制表示数据和指令,指令由操作码和地址码组成。 ②存储程序,程序控制:将程序和数据存放在存储器中,计算…...

Apache Maven 标准文件目录布局
Apache Maven 采用了一套标准的目录布局来组织项目文件。这种布局提供了一种结构化和一致的方式来管理项目资源,使得开发者更容易导航和维护项目。理解和使用标准目录布局对于有效的Maven项目管理至关重要。本文将探讨Maven标准目录布局的关键组成部分,并…...
Android 功耗分析(底层篇)
最近在网上发现关于功耗分析系列的文章很少,介绍详细的更少,于是便想记录总结一下功耗分析的相关知识,有不对的地方希望大家多指出,互相学习。本系列分为底层篇和上层篇。 大概从基础知识,测试手法,以及案例…...

【Xbim+C#】创建圆盘扫掠IfcSweptDiskSolid
基础回顾 https://blog.csdn.net/liqian_ken/article/details/143867404 https://blog.csdn.net/liqian_ken/article/details/114851319 效果图 代码示例 在前文基础上,增加一个工具方法: public static IfcProductDefinitionShape CreateDiskSolidSha…...
IntelliJ+SpringBoot项目实战(四)--快速上手数据库开发
对于新手学习SpringBoot开发,可能最急迫的事情就是尽快掌握数据库的开发。目前数据库开发主要流行使用Mybatis和Mybatis Plus,不过这2个框架对于新手而言需要一定的时间掌握,如果快速上手数据库开发,可以先按照本文介绍的方式使用JdbcTemplat…...

别再手动搬虚拟机了!手把手教你配置vSphere DRS集群,实现ESXi主机负载自动均衡
企业级虚拟化资源调度实战:vSphere DRS集群的智能配置与优化策略 虚拟化技术已成为现代企业IT基础设施的核心支柱,而资源的高效调度则是保障业务连续性和性能的关键。在传统虚拟化环境中,管理员往往需要手动监控主机负载并迁移虚拟机…...

告别MobaXterm!VSCode Remote-SSH + SFTP插件,实现本地与Linux服务器的无缝代码同步
VSCode全栈远程开发:SSH连接、代码同步与Python环境管理一体化实战 远程开发已成为现代工作流的重要组成部分,但传统工具链的割裂体验让许多开发者头疼。本文将展示如何用VSCode构建完整的远程开发环境,从SSH连接到代码同步,再到P…...

拆解Xilinx UltraScale GTH收发器时钟网络:从QPLL/CPLL选择到TXUSRCLK生成的全链路分析
拆解Xilinx UltraScale GTH收发器时钟网络:从QPLL/CPLL选择到TXUSRCLK生成的全链路分析 在高速串行通信领域,时钟网络的稳定性直接决定了系统性能上限。当我们面对25Gbps甚至更高速率的设计需求时,Xilinx UltraScale架构中的GTH收发器便成为工…...
)
GD32 vs STM32:除了参数表,新手选型还得看这几点(附快速上手指南)
GD32与STM32实战选型指南:新手避坑与快速上手指南 当你在电子市场拿起一片GD32开发板和一片STM32开发板时,它们看起来几乎一模一样——同样的引脚排列,同样的封装尺寸,甚至连丝印字体都相似。但当你真正开始项目开发时,…...
怎么选?实测对比告诉你答案)
Ollama三大嵌入模型(mxbai/nomic/all-minilm)怎么选?实测对比告诉你答案
Ollama三大嵌入模型深度评测:mxbai/nomic/all-minilm技术选型实战指南 当你在构建RAG(检索增强生成)系统时,嵌入模型的选择往往决定了整个应用的核心性能。Ollama作为当前最热门的本地大模型运行框架,支持mxbai-embed-…...

无王无帝定乾坤,来自田间第一人 大道同行赴新程
无王无帝定乾坤,来自田间第一人。 ——题记一、旧世终章:王权尽头的暮色朝代崛起方式落幕原因秦铁血征伐暴政失心汉布衣起义外戚乱政唐门阀更迭藩镇割据……………… “千秋岁月流转,世道几经更迭,无数王朝踏着烽烟崛起࿰…...
)
别再只用ARIMA了!用Facebook Prophet快速搞定业务时间序列预测(附Python实战代码)
用Facebook Prophet三行代码完成高精度业务预测:电商场景实战指南 当市场部门的同事又在周五下午5点发来"下周销售预测急用"的邮件时,你是否还在为ARIMA模型的参数调优焦头烂额?时间序列预测本应是数据科学中最具商业价值的技能之一…...

STM32F407 UART4串口DMA接收不定长数据与中断发送的实战配置与避坑指南
1. 为什么需要DMAUART组合方案 在嵌入式开发中,串口通信就像快递员送货上门。传统中断方式相当于每送一个包裹(字节)就按一次门铃,快递员(CPU)必须放下手头工作去开门。当数据量大时,这种频繁中…...

SteamAutoCrack终极指南:5步掌握游戏DRM自动移除技术
SteamAutoCrack终极指南:5步掌握游戏DRM自动移除技术 【免费下载链接】Steam-auto-crack Steam Game Automatic Cracker 项目地址: https://gitcode.com/gh_mirrors/st/Steam-auto-crack 你是否曾为Steam游戏的DRM保护而烦恼?每次运行游戏都需要启…...

ESJsonFormat-Xcode泛型支持:Xcode 7及以上版本的优化特性
ESJsonFormat-Xcode泛型支持:Xcode 7及以上版本的优化特性 【免费下载链接】ESJsonFormat-Xcode 将JSON格式化输出为模型的属性 项目地址: https://gitcode.com/gh_mirrors/es/ESJsonFormat-Xcode 如果你是一位iOS开发者,那么你一定遇到过将JSON数…...